论文 :
Qwen-vl: https://arxiv.org/pdf/2308.12966
qwen2-vl: https://arxiv.org/pdf/2409.12191
代码:https://github.com/QwenLM/Qwen2-VL
1、为什么要做这个研究(理论走向和目前缺陷) ?
Qwen-vl的图像输入需要固定分辨率,其实对很多需要理解细节的任务效果不友好,且不支持场视频裂解。
2、他们怎么做这个研究 (方法,尤其是与之前不同之处) ?
引入动态分辨率+多模态旋转位置编码(NaViT+ M-RoPE),以支持动态分辨率+原始高宽比+长视频输入的处理。特别的,在编码图像和文本输入时,用的是3D卷积同时处理两张临近图像,对于单张图像图像先复制一份再输入到3D卷积层提取特征,这样就实现了提取图像和视频特征的统一。
3、发现了什么(总结结果,补充和理论的关系)?
能够处理20min+的长视频输入,效果相对qwen-vl有大幅提升,碾压所有开源多模态模型,比肩GPT-4o和Claude3.5-Sonnet。
摘要
Qwen2-VL系列模型引入了朴素动态分辨率机制(Naive Dynamic Resolution mechanism),可以把不同分辨率的图像处理成不同数目的视觉token,进而实现更加准确和高效的表达,比较贴合人类的感知系统。此外,还引入了多模态旋转位置编码(M-RoPE),有利于将文本、图像及视频的位置信息进行高效的融合,在处理图像和视频输入的时候,采用统一的处理范式,增强了模型的视觉感知能力。此外,还做了一下不同模型大小+不同数据大小训练的实验,验证scaling law。最终Qwen2-VL-72B效果达到了GPT-4o和Claude3.5的水平。
1 引言
最近的多模态的研究工作基本遵循 视觉编码器提取特征->跨模态特征链接->LLM,以及next-token预测的范式,结合大规模的高质量的数据集,模型效果上已经有了较大的进步。此外,其他的技巧,如:更大的模型架构,更高的分辨率,模型集成(model ensembles),更复杂的连接器(连接图像和视觉token)也在增强多模态模型能力方面扮演了重要的角色。
但是,现在的模型一般都把图像输入限制在固定的尺寸,如224x224,这就导致对一些需要较多细节信息的任务有很大负面影响。
此外,现有的多模态模型多采用clip系列的预训练模型直接提特征,而不再微调,不禁让人怀疑用预训练的模型提的特征是否够用。本文为了增强模型对不同分辨率的图像的处理能力,采用了动态分辨率输入训练策略,并且在ViT中引入了2D的旋转位置编码,使得模型能够更好的捕获不同空间尺度的信息。
处理视频输入不像处理文本输入,文本数据是一维的,而视频数据是三维的(w,h,t),故引入了多模态旋转位置编码处理这种数据。
Qwen2-VL模型共有3个,即2B, 7B和72B, 如下图所示
注:模型的命名是依据LLM的大小来命名的,不用考虑视觉编码器的大小。
本文贡献总结如下:
- 对不同分辨率和高宽比的图像输入理解能力最强。
- 支持对超长视频(20min+)的理解。
- 更强的agent能力:对手机、机器人的操作更加丝滑。
- 支持多语言。
2 方案
2.1 模型架构
模型架构下图所示,重新实现了一个6.75亿参数的ViT,以处理各种大小的图像和视频数据。
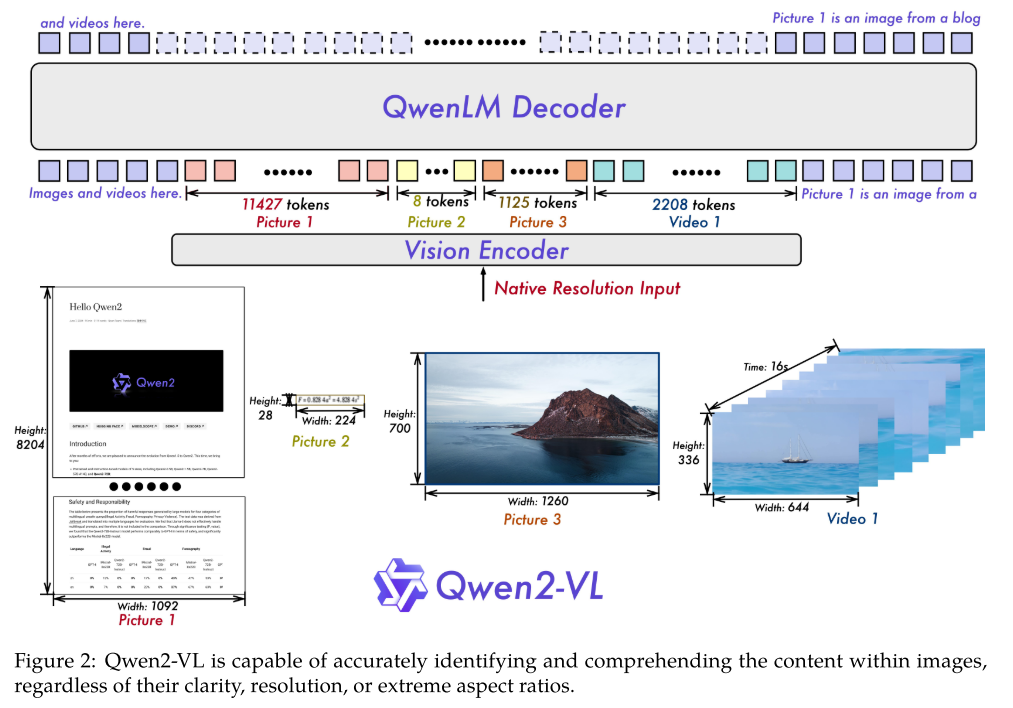
朴素动态分辨率 (Naive Dynamic Resolution):即NaViT(Native Resolution ViT)改了个名字,根据图像的大小和高宽比确定每张图像提取的token数目,而不是固定的resize到224x224提取固定的token数目。同时引入2D-RoPE位置编码。注意NaViT + 2D-RoPE可以支持任意大小任意高宽比的图像提取特征。这里为了避免每张图的token过多,会应用一个MLP在临近的4个patch token上,使其转化为1个token,使其总的token数目变为原来的1/4。这样的话,一个224x224输入的图像,patch_size=14,最终进入LLM的token数目就是 (224/14)*(224/14)/4 + 2个边角料token = 66.
多模态旋转位置编码 (Multimodal Rotary Position Embedding (M-RoPE)):原始的RoPE只针对1维序列编码,针对视频输入现改为了3个维度,即时间,高度,宽度。对于一维的文本序列输入,时间,高度,和宽度编码是一样的,即退化为一维位置编码。对于二维的图像输入,时间维度是一样的,即退化为二维位置编码。对于视频输入,时间维度(帧ID)才会发挥作用。如果是同时有多个模态的输入,每个模态的位置会在前一个模态的最大位置基础上加一,比如第一张图的所有token的时间位置都是0,到第二张图时所有token的时间位置都是1。
统一图像与视频理解: 对于视频输入,每秒采样两帧,临近的两帧使用一个3D卷积先提取特征,再分patch进视觉编码器,而不是每张图单独分patch后进视觉编码器。对于图像输入,为了和视频输入保持一致,先把图像复制一份,再进3D卷积,之后再进视觉编码器。如果视频太长的话,会对其分辨率进行缩小,限制视频总的token数目最大为16384.
2.2 训练
同qwen-vl一样,三阶段训练策略,第一阶段仅放开视觉编码器(ViT)的参数在图像文本对数据上预训练训练,第二阶段全部参数放开(包含LLM)在大量数据上预训练,第三阶段冻结视觉编码器放开LLM在指令数据集上微调。
注:qwen-vl有一个单独的图像特征转换为LLM输入的投影器,而qwen-vl没有显式的投影器,而是直接把这个投影过程放到ViT中,ViT输出直接拼接就可以输入到LLM中了。
2.2.1 数据格式
chat-ML格式,图像的token会用<|vision_start|>和<|vision_end|>这两个token包住。
对话数据 :如下图所示,蓝色内容部分是训练时需要监督的部分,每段对话用<|im_start|>和<|im_end|>包裹。

视觉grounding : 为了赋予模型grounding能力,每个边界框需要归一化到0, 1000),用左上和右下角点"(Xtop left, Ytop left), (Xbottom right, Ybottom right)"表示,并用特殊token \<\|box_start\|\>和\<\|box_end\|\>包裹,对于图像的描述内容用\<\|object_ref_start\|\>和\<\|object_ref_end\|\>包裹,下图所示。 
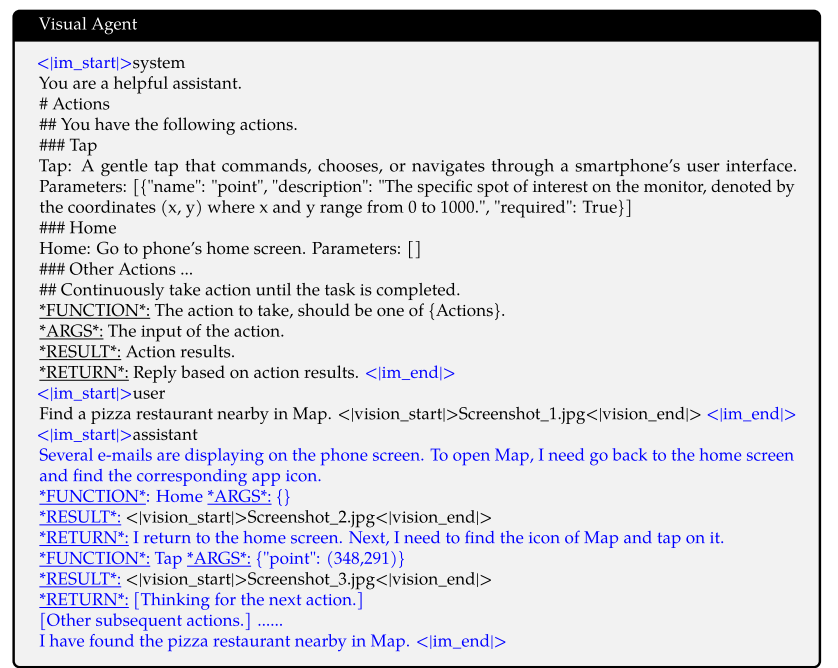
视觉Agent :数据形式如下
2.3 多模态模型基础架构
阿里云基础设施
3 实验
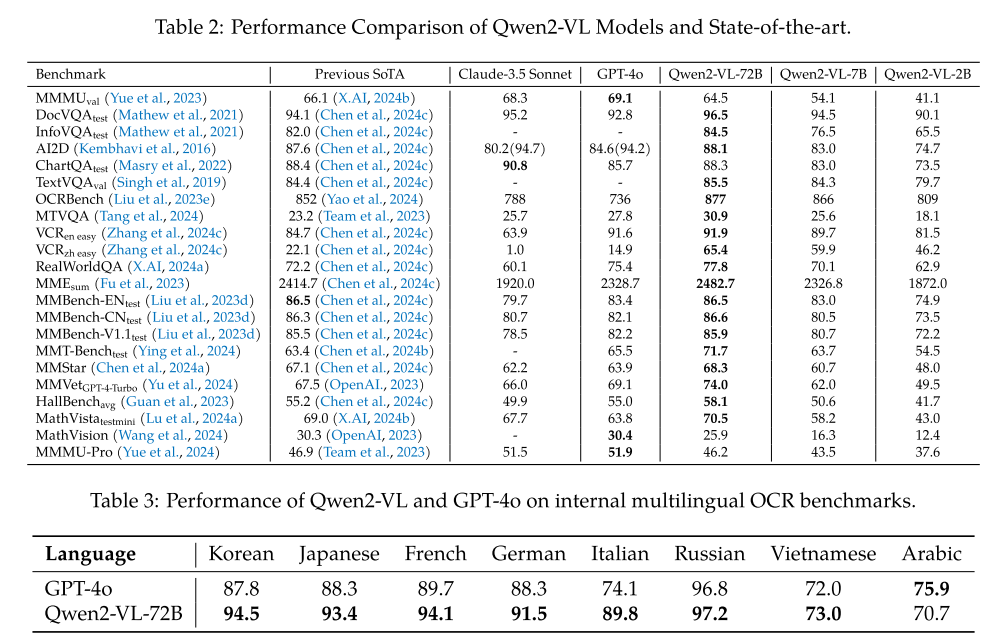
3.1 和SOTA对比
超越大多开源和闭源模型。
3.2 高质量结果
这里仅展示grounding任务效果,72B的模型在coco的grounding数据指标上已经超越的专有模型了,但是实际用下来效果还是不行,和专有模型仍有较大差距。
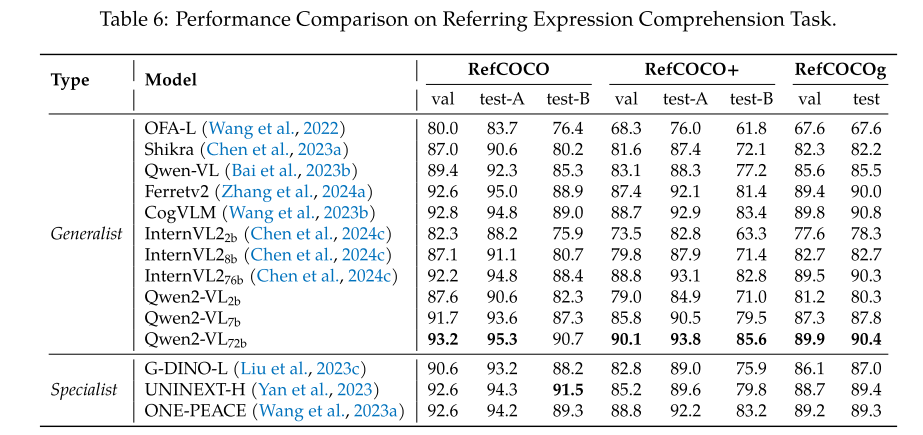
3.3 消融实验
即NaViT + M-RoPE.
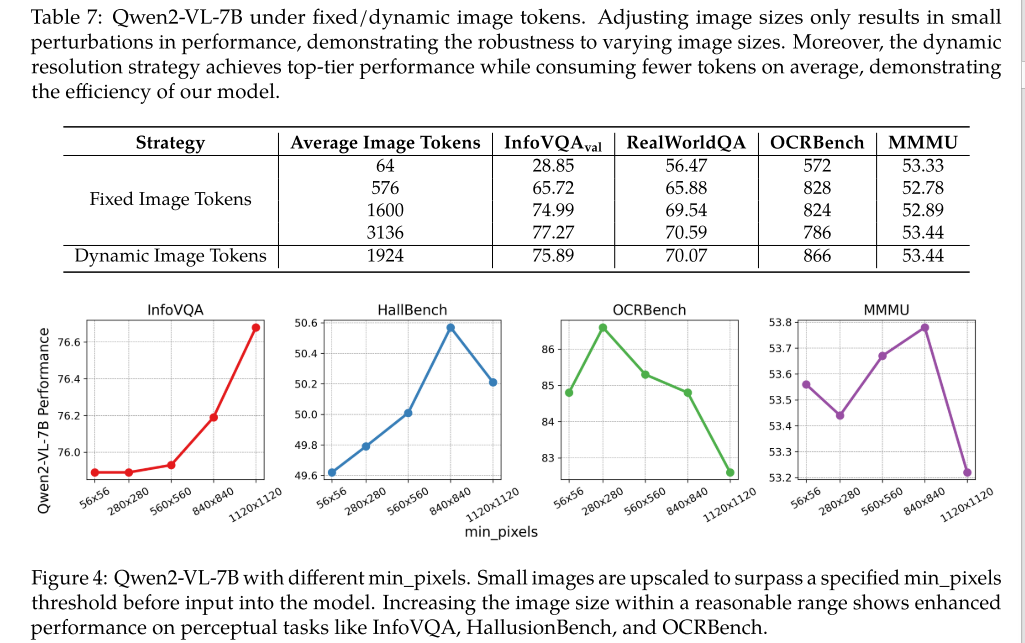
3.3.1 动态分辨率
动态分辨率输入效果最好且效率最高。
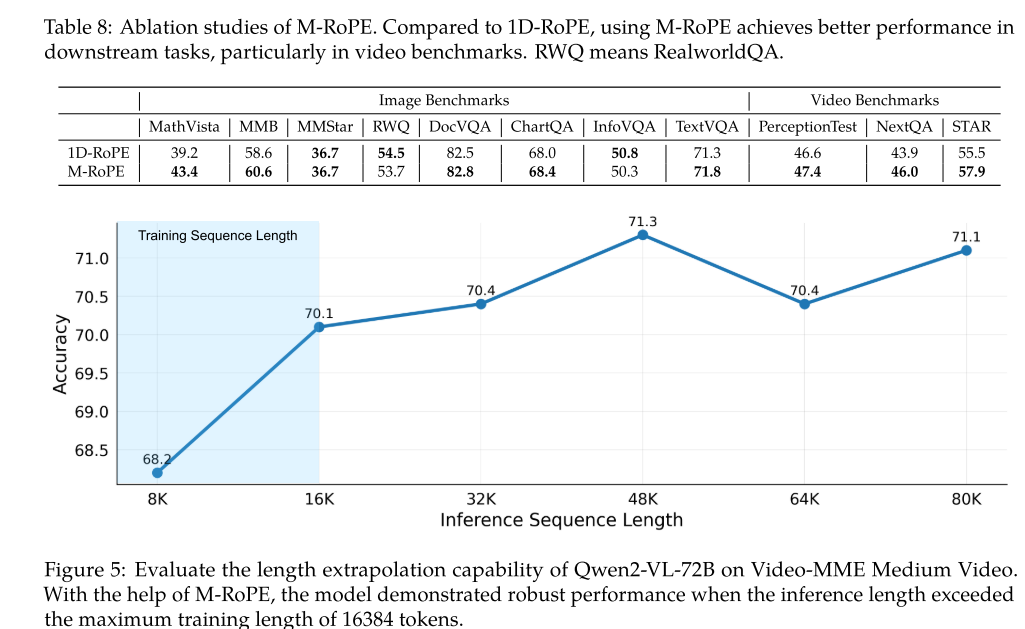
3.3.2 M-RoPE
相对于1维的RoPE, 3维的RoPE效果很好。
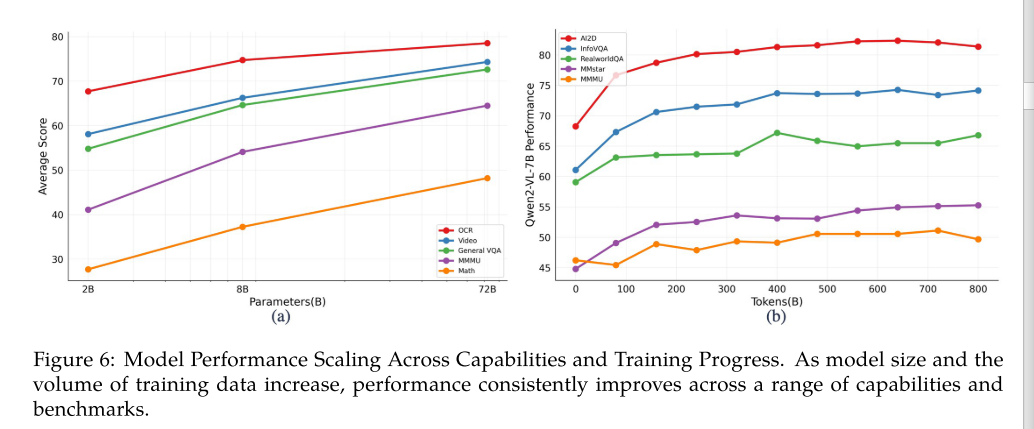
3.3.3 模型大小和训练数据多少的影响
总体上是模型越大、数据越多、效果越好。
4 结论
Qwen2-VL共三种参数量2B,8B和72B,效果碾压所有开源多模态模型,比肩GPT-4o和Claude3.5-Sonnet。主要改进点就是引入NaViT+M-RoPE,支持动态分辨率+原始高宽比+长视频输入的理解。