TL;DR
- 场景:离线数仓中需要低成本保存订单历史状态,同时支持按天回溯与变化分析。
- 结论:用 ODS 日增量表 + DWD 拉链表,比"只留最新"与"每天存全量"更平衡。
- 产出:给出 Hive 拉链表初始化、增量刷新 SQL、闭链规则与常见错误速查。

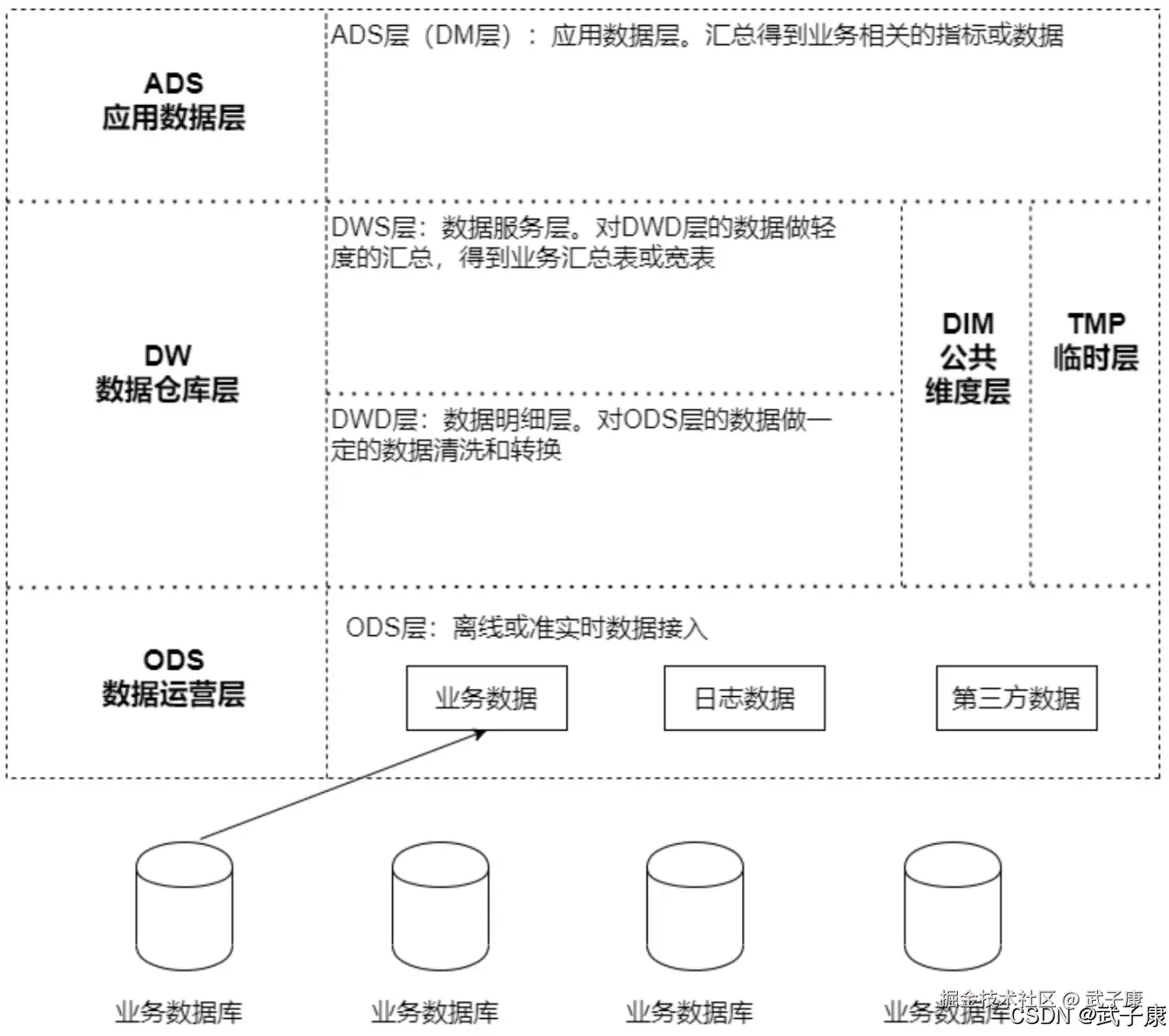
周期性事实表
定义
周期性事实表记录的是定期发生的业务事件或度量数据,例如每天、每月或每季度的数据。其设计目的在于帮助用户快速查询和分析这些周期性数据的趋势和变化。
时间周期性
周期性事实表以时间为主要维度,每一条记录都与某一时间点或时间段对应。例如:
- 每天的销售总额
- 每月的库存水平
- 每季度的客户新增量
粒度
粒度是指事实表中数据记录的最小单位。在周期性事实表中,粒度通常基于时间维度。例如:
- 日粒度:每天一条记录。
- 月粒度:每月一条记录。
数据聚合
周期性事实表中的数据通常是从事务型事实表中聚合得到的。例如:
- 事务型事实表记录每笔交易的信息。
- 周期性事实表可以按天或按月汇总交易额。
与时间维度的紧密关联
周期性事实表通常会与一个时间维度表连接,时间维度表包含详细的时间信息,如日期、周数、月份、季度和年份等。
结构
周期性事实表的结构通常包含以下关键部分:
外键
- 时间维度键:链接到时间维度表,标识记录对应的时间段。
- 其他维度键:如产品维度、区域维度或客户维度,标识数据的业务上下文。
度量指标
存储业务相关的聚合度量数据,例如:
- 销售额
- 客户数量
- 产品库存水平
衍生字段
- 同比变化:与去年同期相比的数据变化。
- 环比变化:与上一个周期相比的数据变化。
常见用途
周期性事实表的主要用途是支持时间序列分析和报表生成,常见场景包括:
- 趋势分析:如销售额随时间的变化趋势。
- 绩效监控:如每月的利润率和成本比。
- 预测模型输入:如基于历史周期性数据进行业务预测。
设计原则
- 时间维度的选择:时间粒度的选择取决于业务需求。如果用户需要分析每天的趋势,应选择日粒度;如果关注季度变化,应选择季度粒度。
- 预聚合与性能优化:为了提高查询性能,数据通常需要预先聚合。
- 历史数据的存储:确保存储足够的历史数据,以支持长期趋势分析。
- 一致性和准确性:定期加载和更新数据,确保事实表中的数据与实际业务数据一致。
优点
- 数据聚合后体积较小,查询性能高。
- 支持时间序列分析和趋势预测。
- 结构简单,便于与时间维度整合。
缺点
- 缺乏事务级别的详细数据,不能支持细粒度分析。
- 如果时间粒度选择不合理,可能无法满足用户需求。
举例描述
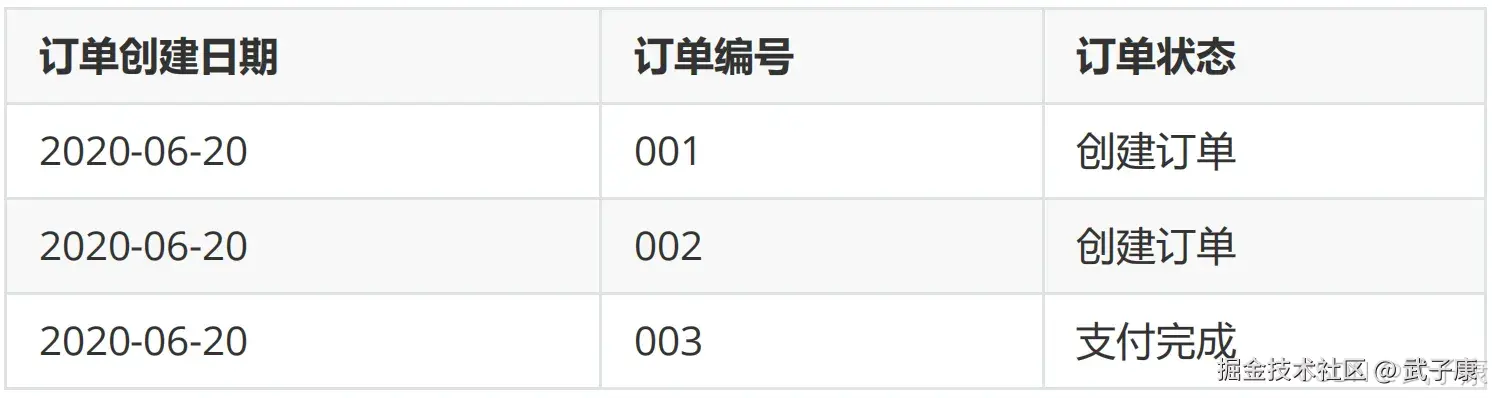
假设有如下订单表,6月20日有3条记录(001/002/003)
6月21日,表中有5条记录,其中新增2条记录(004/005),修改1条记录(001): 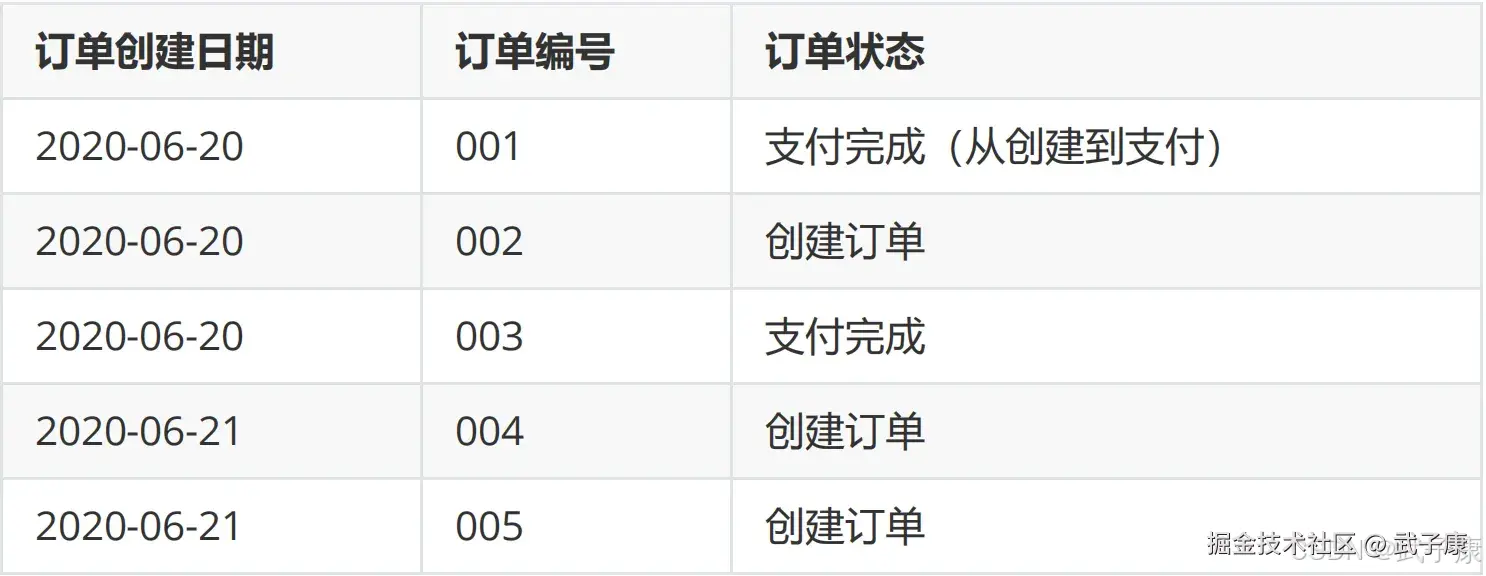
6月22日,表中有6条记录,其中新增1条记录(006),修改2条记录(003/005): 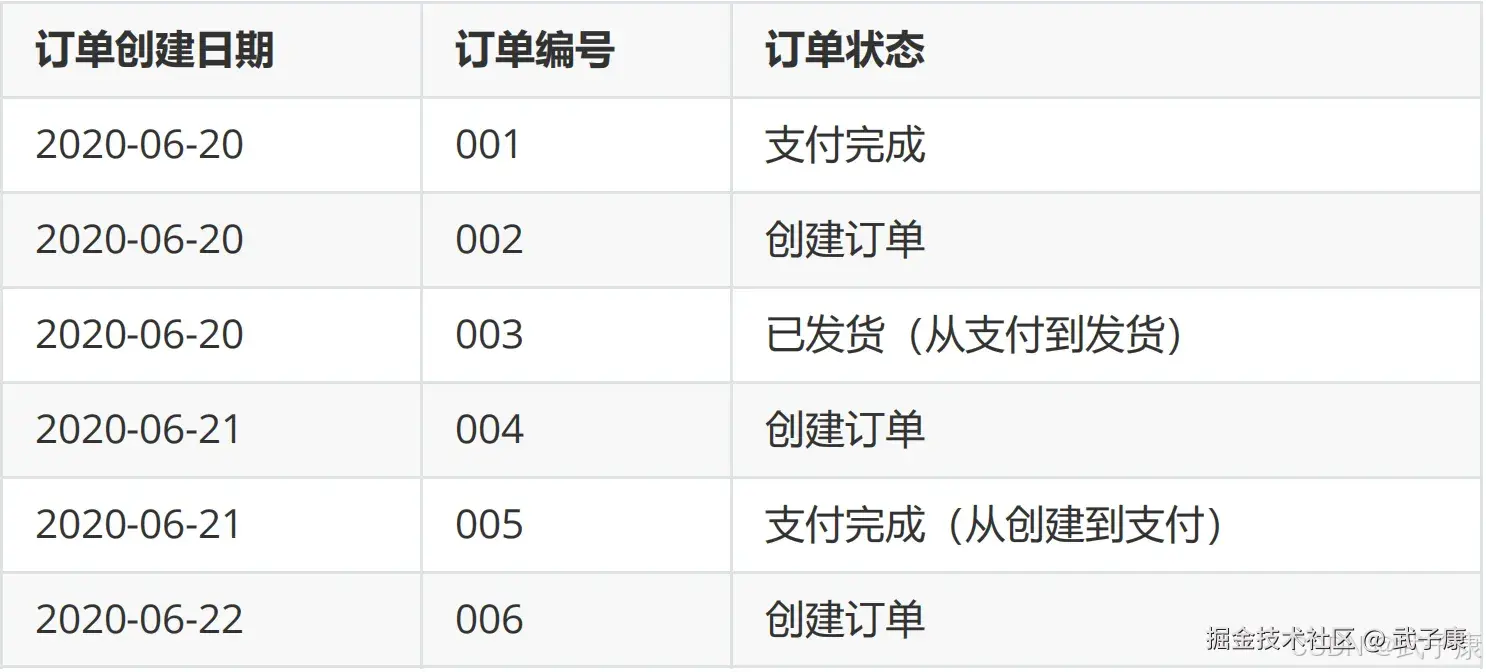
订单事实表的处理方法:
- 只保留一份全量,数据和6月22日的记录一样,如果需要查看6月21日订单001的状态,则无法满足
- 每天都保留一份全量,在数据仓库中可以在找到所有的历史信息,但数据量大了,而且很多信息都是重复的,会造成较大的存储浪费
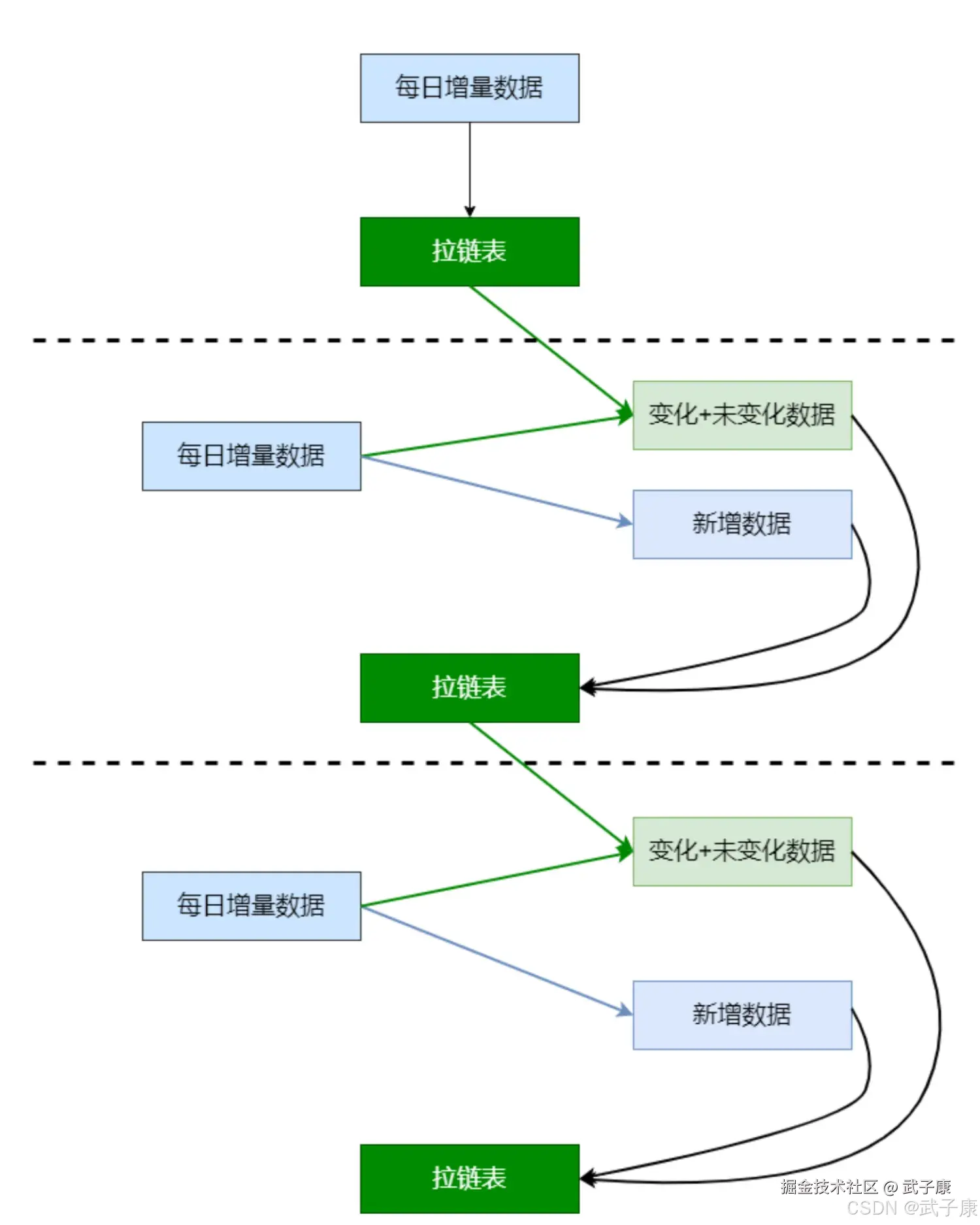
使用拉链表保存历史信息,会有下面这张表,历史拉链表,既能满足保存历史数据的需求,也能节省存储资源。 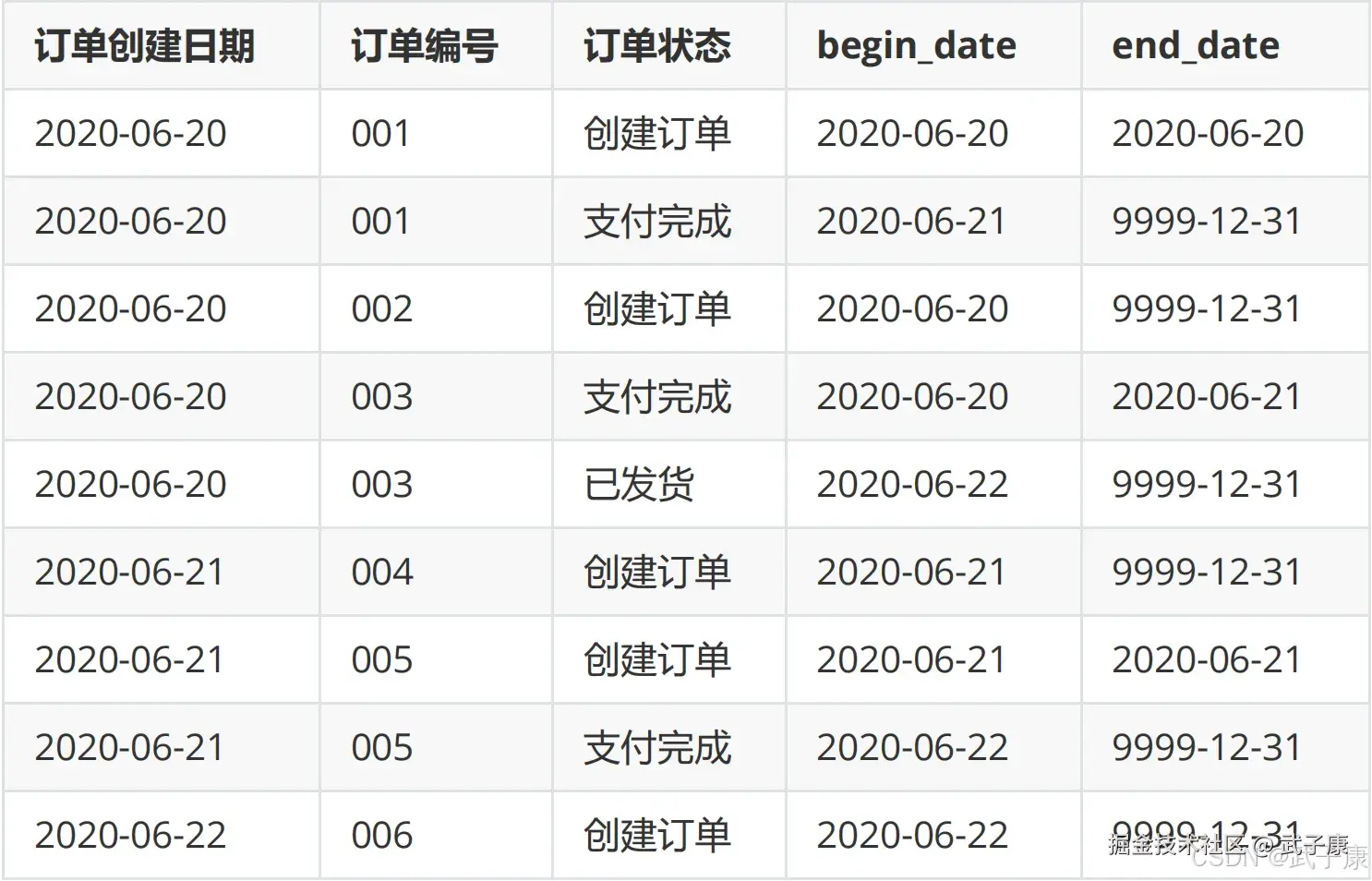
前提条件
- 订单表的刷新频率为一天,当天获取前一天的增量数据
- 如果一个订单在一天内有多次状态变化,只记录最后一个状态的信息
- 订单状态包括3个:创建、支付、完成
- 创建时间和修改时间只取到天,如果源订单表中没有状态修改时间,那么抽取增量就比较麻烦,需要有个机制来确保能抽取到每天的增量数据
数仓ODS层有订单表,数据按日分区,存放每天的增量数据:
sql
DROP TABLE test.ods_orders;
CREATE TABLE test.ods_orders(
orderid INT,
createtime STRING,
modifiedtime STRING,
status STRING
) PARTITIONED BY (dt STRING)
row format delimited fields terminated by ',';数仓DWD层有订单拉链表,存放订单的历史状态数据:
sql
DROP TABLE test.dwd_orders;
CREATE TABLE test.dwd_orders(
orderid INT,
createtime STRING,
modifiedtime STRING,
status STRING,
start_date STRING,
end_date STRING
)
row format delimited fields terminated by ',';周期性事实表拉链表的实现
全量初始化
操作是在Hive中完成的,别搞错了
sql
-- 数据文件order1.dat
001,2020-06-20,2020-06-20,创建
002,2020-06-20,2020-06-20,创建
003,2020-06-20,2020-06-20,支付
load data local inpath '/data/lagoudw/data/order1.dat' into
table test.ods_orders partition(dt='2020-06-20');
INSERT overwrite TABLE test.dwd_orders
SELECT orderid, createtime, modifiedtime, status,
createtime AS start_date,
'9999-12-31' AS end_date
FROM test.ods_orders
WHERE dt='2020-06-20';增量抽取
shell
-- 数据文件order2.dat
001,2020-06-20,2020-06-21,支付
004,2020-06-21,2020-06-21,创建
005,2020-06-21,2020-06-21,创建
load data local inpath '/data/lagoudw/data/order2.dat' into
table test.ods_orders partition(dt='2020-06-21');增量刷新历史数据
sql
-- 处理新增数据
SELECT
orderid,
createtime,
modifiedtime,
status,
modifiedtime AS start_date,
'9999-12-31' AS end_date
FROM
test.ods_orders
WHERE
dt = '2020-06-21';
-- 处理历史数据,包括有修改、无修改的数据
-- ods_orders 与 dwd_orders 进行表连接
-- 连接上,说明数据被修改;未连接上,说明数据未被修改
SELECT
A.orderid,
A.createtime,
A.modifiedtime,
A.status,
A.start_date,
CASE
WHEN B.orderid IS NOT NULL AND A.end_date > '2020-06-21' THEN '2020-06-20'
ELSE A.end_date
END AS end_date
FROM
dwd_orders A
LEFT JOIN
(SELECT * FROM ods_orders WHERE dt = '2020-06-21') B
ON
A.orderid = B.orderid;
-- 覆写拉链表
INSERT OVERWRITE TABLE test.dwd_orders
SELECT
orderid,
createtime,
modifiedtime,
status,
modifiedtime AS start_date,
'9999-12-31' AS end_date
FROM
test.ods_orders
WHERE
dt = '2020-06-21'
UNION ALL
SELECT
A.orderid,
A.createtime,
A.modifiedtime,
A.status,
A.start_date,
CASE
WHEN B.orderid IS NOT NULL AND A.end_date > '2020-06-21' THEN '2020-06-20'
ELSE A.end_date
END AS end_date
FROM
dwd_orders A
LEFT JOIN
(SELECT * FROM ods_orders WHERE dt = '2020-06-21') B
ON
A.orderid = B.orderid;拉链表小结
错误速查
| 症状 | 根因定位 | 修复 |
|---|---|---|
| 拉链表出现同一订单多条"9999-12-31"未闭合记录 | 增量刷新时只插入新数据,旧链未正确闭链 | 查 orderid 分组后 end_date='9999-12-31' 数量是否大于 1 |
| 历史区间重叠 | start_date、end_date 计算不一致,闭链日期写错 | 按 orderid 排序检查日期区间是否交叉 |
| 查询某天快照结果不对 | 快照筛选条件写错 | 检查是否用 dt 查 DWD,或没按日期区间过滤 |
| 新增订单正常,修改订单丢失历史 | 直接覆盖了原记录,没有保留旧版本 | 比较刷新前后同一 orderid 记录条数 |
| 每日跑批后数据翻倍 | UNION ALL 前后集合边界不清,历史表全量重复拼接 | 检查增量日是否重复执行,检查是否缺少幂等控制 |
| 当天多次状态变化只保留一条但结果不稳定 | ODS 当日增量未先去重,保留哪条记录不确定 | 查同一 orderid, dt 是否存在多条不同 modifiedtime |
| 拉链表首日初始化后查询不到历史 | start_date / end_date 初始化错误 | 检查首日是否写成空值或错列初始化 |
| SQL 能跑但结果异常 | 表名引用不完整或库表前缀混用 | 检查 test.ods_orders 与 ods_orders 是否混写 |
| 分区数据已加载但查询不到 | dt 分区值与业务日期不一致 | 查 show partitions 与样例日期是否匹配 |
| 周期性事实表和拉链表概念混淆 | 标题与正文案例不是同一建模对象 | 拆成两篇,或明确"本文重点实际是拉链表,不是周期性事实表" |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地 🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-218 RocketMQ Java API 实战:同步/异步 Producer 与 Pull/Push Consumer MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ已完结,RocketMQ正在更新... 深入浅出助你打牢基础! 🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解 🔗 大数据模块直达链接