文章目录
- 背景
- [一、Pulsar 基础核心概念](#一、Pulsar 基础核心概念)
-
- [1. 基础架构:实例与集群](#1. 基础架构:实例与集群)
- [2. 核心组件](#2. 核心组件)
-
- (1)Broker:无状态的消息中转站
- (2)BookKeeper
- (3)ZooKeeper
- [(4)Pulsar Proxy](#(4)Pulsar Proxy)
- (5)服务发现
- [3. 核心存储概念:账本机制](#3. 核心存储概念:账本机制)
- [4. 关键特性概念](#4. 关键特性概念)
- [二、Pulsar 核心工作流程](#二、Pulsar 核心工作流程)
- 三、Pulsar实操
-
-
- [1. 环境准备](#1. 环境准备)
- [2. 消息生产者代码(模拟订单系统发消息)](#2. 消息生产者代码(模拟订单系统发消息))
- [3. 消息消费者代码(模拟库存系统消费消息)](#3. 消息消费者代码(模拟库存系统消费消息))
-
- [四、Pulsar 消息流转流程图](#四、Pulsar 消息流转流程图)
- 总结
官方网站:https://pulsar.apache.org/
背景
需要的MQ种类多,业务复杂,集合了多种MQ特性,比如消息,批处理...
Pulsar 2012 年诞生于雅虎,核心是解决内部多 MQ 混乱、运维复杂、无法支撑大规模 / 跨地域业务的问题:
- 内部同时在用 ActiveMQ、RabbitMQ、Kafka 等多种 MQ,每种 MQ 适配不同场景,导致技术栈割裂、运维成本极高。
- 业务覆盖全球、多数据中心,需要百万级 Topic、强多租户隔离、跨地域复制、无限消息堆积,而当时 Kafka/RabbitMQ 均无法原生满足。
- 目标:用一套系统统一所有消息场景,同时适配传统队列、流处理、批处理、事件驱动等复杂业务。
Pulsar 是为解决企业多 MQ 割裂、业务复杂、传统 MQ 扩展性 / 多租户 / 跨地域能力不足而设计的云原生统一消息流平台,它集合了 RabbitMQ 的队列特性、Kafka 的流处理能力,并原生补齐多租户、存算分离、跨地域、分层存储、轻量计算等能力,让一套系统就能支撑从简单队列到复杂流批一体的全场景业务。
一、Pulsar 基础核心概念
Apache Pulsar 是一款云原生分布式消息队列 ,有点类似分布式系统里的"消息快递中转站",专门负责在不同业务系统、不同服务之间传递数据,解决服务解耦、流量削峰、数据同步等问题。和 Kafka、RabbitMQ 这些传统消息队列相比,Pulsar 最大的特点是计算和存储彻底分家,扩展性、可靠性、容错性拉满,特别适合云环境、容器化、超大规模业务场景使用。
1. 基础架构:实例与集群
Pulsar 的整体架构是分层设计,先搞懂两个基础单位:实例和集群。一个 Pulsar 实例可以包含一个或多个 Pulsar 集群,相当于"总公司"下辖多个"分公司",集群之间可以实现数据互通。
单个 Pulsar 集群是核心运行单元,所有消息的生产、转发、存储、消费全在集群里完成。而且 Pulsar 支持地理复制,比如北京集群、上海集群、广州集群部署在不同地域,北京集群收到的订单消息,能自动同步到其他集群,既可以做异地容灾,也能让不同区域的业务系统共享数据,避免数据孤岛。例如,跨国电商的欧美集群和亚洲集群,通过地理复制就能同步全球订单,用户在任何地区下单,后台都能实时感知。
2. 核心组件
一个完整的 Pulsar 集群,主要靠三大核心组件+两个辅助组件配合干活,每个组件只做自己擅长的事,互不干扰,这也是 Pulsar 稳定好用的关键。
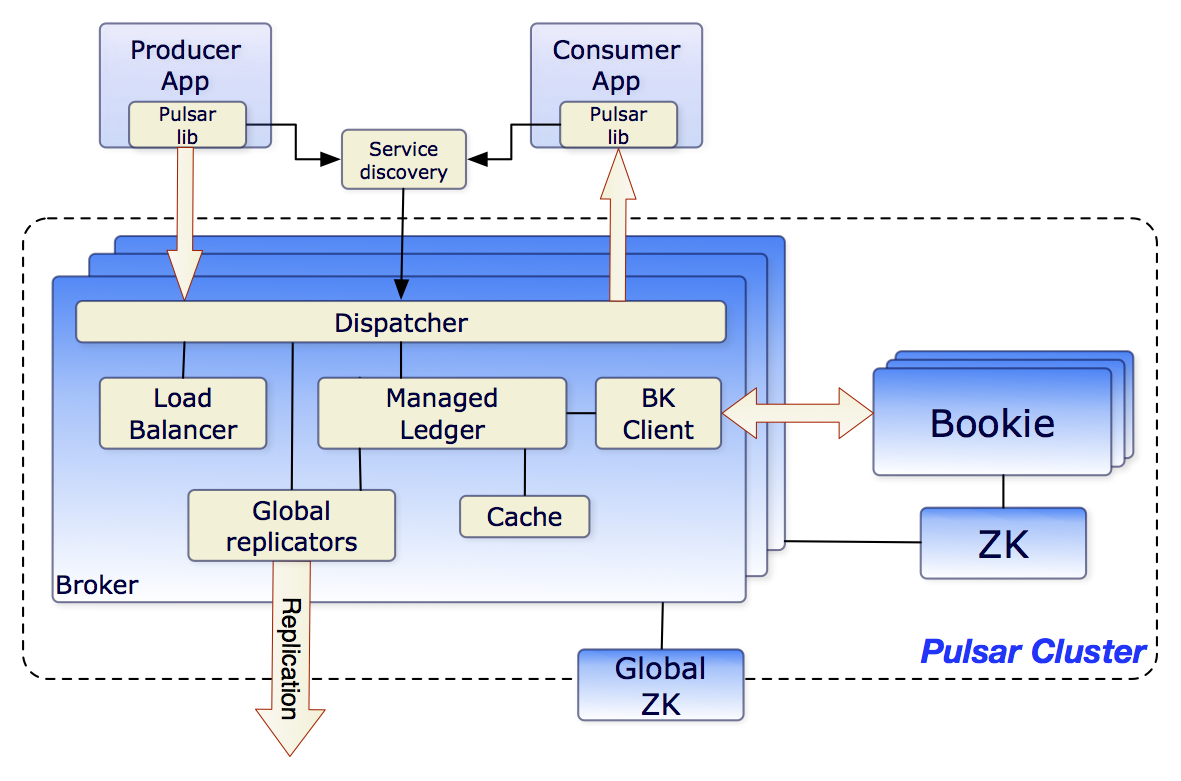
具体可以查看:https://pulsar.apache.org/docs/3.3.x/concepts-architecture-overview/
(1)Broker:无状态的消息中转站
Broker 是 Pulsar 的"核心跑腿员",而且是无状态的,意思就是它不存任何消息数据,只负责处理消息流转。具体包括:接收生产者发来的消息;把消息精准分发给对应的消费者;管理跨集群的消息复制;对外提供接口做集群管理。
无状态这个设计特别棒,某一个 Broker 节点宕机了,其他 Broker 能直接接手它的工作,不用迁移数据、不用重启集群,业务完全无感。比如电商大促时,10台Broker同时运转,其中一台突然故障,剩下9台立刻分摊任务,不会出现消息堵塞或丢失。
(2)BookKeeper
BookKeeper 是 Pulsar专属的分布式预写日志(WAL)系统,以 Bookie 为最小存储节点,相当于集群的"硬盘+保险柜",专门负责消息持久化存储。Broker 只转发不存数据,所有消息最终都会落到 BookKeeper 里,而且会存多份副本(默认至少2-3份),分散在不同 Bookie 节点上。
就算个别 Bookie 节点损坏,只要还有一个副本在,消息就不会丢,还能保证读取到的消息完全一致,不会出现乱序、重复的问题。
(3)ZooKeeper
ZooKeeper 是分布式协调组件,相当于 Pulsar 集群的"大脑+管家",不参与消息流转,只管元数据和集群协调。比如记录哪个 Broker 负责哪个主题、集群负载情况、存储节点状态、权限配置、订阅位置等关键信息,保证整个集群有条不紊运行。
它分为集群级和实例级,集群级管单个分公司的事,实例级管总公司的全局配置,跨集群同步数据时,全靠它协调指挥。现在新版 Pulsar 也支持 etcd 替代 ZooKeeper,部署更灵活。
(4)Pulsar Proxy
这是可选组件,相当于集群的"前台接待"。在云服务器、K8s 容器环境里,Broker 节点都是内部地址,外部客户端没法直接访问,这时候就需要 Proxy 做统一入口。客户端只需要连接 Proxy 的地址,不用管内部 Broker 有多少、地址是什么,所有请求都由 Proxy 转发,既安全又方便。
(5)服务发现
服务发现就是简化客户端连接,不用手动配置所有 Broker 地址,只需要一个集群域名或地址,就能自动找到可用的 Broker 节点。比如用 Java 客户端连接时,只写一个 pulsar://集群地址:6650,系统自动分配节点,就算集群扩容缩容,客户端配置也不用改。
3. 核心存储概念:账本机制
Pulsar 的存储逻辑不靠普通文件,而是靠Ledger(账本)和Managed Ledger(托管账本):
Ledger(账本):是 BookKeeper 的核心数据结构,是单写入、多读取的追加写日志,由一个 Broker 负责创建、写入,写满或者 Broker 故障后,即关闭后仅支持只读操作,不再接受写入,会新开一个账本继续写。;当账本中的消息被全部消费后,可在所有 Bookie 节点中统一删除。账本的所有条目会复制到多个 Bookie 节点,保证数据可靠性。
Managed Ledger(托管账本):Pulsar 给每个主题配的"总账本",一个主题对应一个托管账本,里面包含N个小账本。好处是,单个小账本消息消费完后,可以单独删除,不用清理整个主题数据;就算某个账本损坏,也不影响其他账本,故障恢复超快。
4. 关键特性概念
持久化主题:日常用的最多的主题类型,命名以 persistent:// 开头,消息发到 Broker 后,立刻同步存到 BookKeeper 磁盘,就算集群重启,消息也不会丢,适合核心业务数据。
多租户与命名空间:企业级资源隔离功能,租户相当于不同业务部门(比如电商部、支付部、物流部),命名空间相当于部门下的业务模块(比如电商部下的订单模块、商品模块)。不同租户资源完全隔离,权限、存储策略、配额都能单独配置,避免不同业务互相干扰。
二、Pulsar 核心工作流程
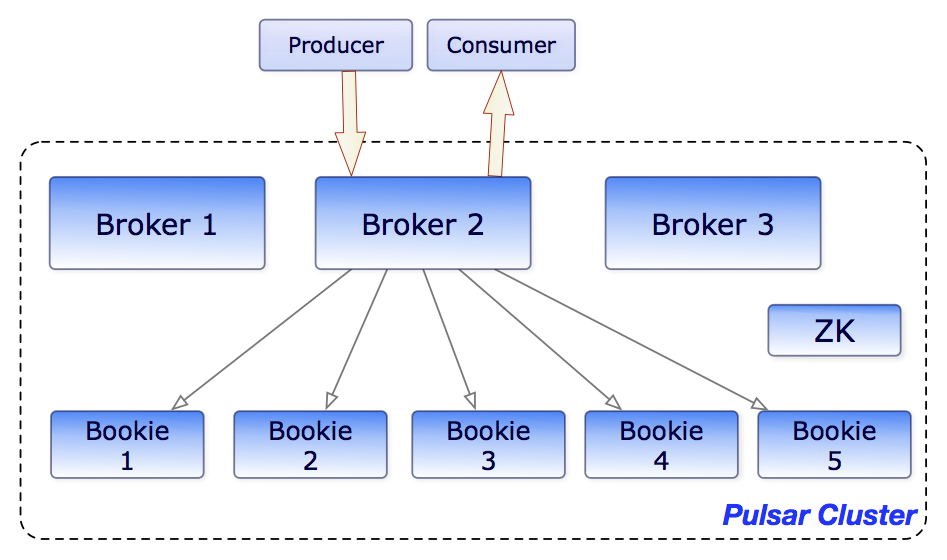
就是把组件都串起来,Pulsar 的消息流转逻辑特别清晰,全程傻瓜式运转:
第一步,生产者(业务系统)把消息发送给 Broker 节点;
第二步,Broker 先把消息放进缓存,快速响应生产者,同时异步把消息同步到 BookKeeper 做持久化;
第三步,消费者监听对应主题,Broker 从缓存或 BookKeeper 里读取消息,推送给消费者;
第四步,消费者收到消息后,回复确认信号,Broker 标记消息已消费;
第五步,已消费完毕的账本,到期自动清理,释放存储空间。
如果是跨集群场景,Broker 会额外把消息同步到远程集群,实现地理复制;
如果客户端无法直连 Broker,就通过 Proxy 转发请求,服务发现自动匹配可用节点,全程不用人工干预。
三、Pulsar实操
下面结合代码能更快理解消息生产消费逻辑,模拟电商订单消息的生产与消费,代码带详细注释,新手也能看懂。
1. 环境准备
先引入 Maven 依赖,对接 Pulsar 集群:
xml
<!-- Pulsar 客户端依赖 -->
<dependency>
<groupId>org.apache.pulsar</groupId>
<artifactId>pulsar-client</artifactId>
<version>3.3.0</version>
</dependency>2. 消息生产者代码(模拟订单系统发消息)
生产者负责把订单数据发送给 Pulsar Broker,指定持久化主题,保证消息不丢失。
java
import org.apache.pulsar.client.api.Producer;
import org.apache.pulsar.client.api.PulsarClient;
import org.apache.pulsar.client.api.Schema;
public class PulsarOrderProducer {
public static void main(String[] args) throws Exception {
// 1. 创建 Pulsar 客户端,连接集群地址(服务发现地址,无需配所有Broker)
PulsarClient client = PulsarClient.builder()
.serviceUrl("pulsar://127.0.0.1:6650") // 集群地址
.build();
// 2. 创建生产者,指定持久化主题:租户/命名空间/主题名
Producer<String> producer = client.newProducer(Schema.STRING)
.topic("persistent://my-tenant/my-namespace/order-topic") // 持久化主题
.create();
// 3. 发送订单消息(模拟电商下单)
String orderMsg = "订单号:20260312001,商品:手机,金额:3999元";
producer.send(orderMsg);
System.out.println("订单消息发送成功:" + orderMsg);
// 4. 关闭资源
producer.close();
client.close();
}
}3. 消息消费者代码(模拟库存系统消费消息)
消费者监听对应主题,接收订单消息并处理,完成库存扣减逻辑。
java
import org.apache.pulsar.client.api.Consumer;
import org.apache.pulsar.client.api.Message;
import org.apache.pulsar.client.api.PulsarClient;
import org.apache.pulsar.client.api.Schema;
public class PulsarOrderConsumer {
public static void main(String[] args) throws Exception {
// 1. 创建Pulsar客户端
PulsarClient client = PulsarClient.builder()
.serviceUrl("pulsar://127.0.0.1:6650")
.build();
// 2. 创建消费者,绑定主题和订阅名称
Consumer<String> consumer = client.newConsumer(Schema.STRING)
.topic("persistent://my-tenant/my-namespace/order-topic")
.subscriptionName("order-sub") // 订阅名,标记消费进度
.subscribe();
// 3. 循环监听消息,模拟库存扣减
while (true) {
Message<String> msg = consumer.receive();
try {
System.out.println("收到订单消息,开始扣减库存:" + msg.getValue());
// 手动确认消息,告知Broker已消费,避免重复消费
consumer.acknowledge(msg);
} catch (Exception e) {
// 消费失败,重新消费
consumer.negativeAcknowledge(msg);
}
}
}
}四、Pulsar 消息流转流程图
生产者 → Broker(缓存转发) → BookKeeper(持久化存盘) → Broker(读取消息) → 消费者
细化分步流程:
-
生产阶段:业务系统(生产者)构建消息,发送至Pulsar Broker节点;
-
中转阶段:Broker接收消息,先存入内存缓存提升响应速度,同时异步将消息同步至BookKeeper;
-
存储阶段:BookKeeper将消息拆分为多个Ledger账本,多副本存储在不同Bookie节点;
-
消费阶段:消费者监听主题,Broker从缓存或BookKeeper读取消息,推送给消费者;
-
确认阶段:消费者成功处理消息后,发送ACK回执,Broker标记消息已消费,ZooKeeper同步更新消费进度;
-
清理阶段:Ledger账本内消息全部消费完毕,自动清理释放存储空间。
总结
Apache Pulsar 作为新一代云原生消息队列,核心竞争力就是计算存储分离的架构设计,彻底打破了传统消息队列"计算存储耦合"的瓶颈,这也是它能适配超大规模场景的核心原因。传统消息队列的 Broker 既要处理消息又要存储数据,扩容时必须整体扩容,成本高、效率低;而 Pulsar 里 Broker 只管处理、BookKeeper 只管存储,两者可以独立扩容,消息量暴涨时,只需要加 Bookie 存储节点,流量暴涨时,只需要加 Broker 处理节点,弹性伸缩完全贴合云原生需求。
从实际使用来看,Pulsar 的优势非常突出:
高可靠,多副本存储+持久化机制,保证消息零丢失,适合金融、电商、医疗等核心业务;
高可用,无状态 Broker+故障自动转移,集群节点宕机不影响业务,可用性可达99.99%;
易扩展,分层架构支持无限水平扩容,轻松应对亿级消息流转;
企业级能力强,多租户隔离、地理复制、权限管控、生命周期管理,满足大型企业复杂业务需求。
当然,Pulsar 也不是万能的,小规模业务、低成本部署场景下,它的部署复杂度和资源占用比 RabbitMQ 高,优势不明显。但在云原生架构、跨地域部署、海量消息流转、多业务线隔离的场景中,Pulsar 的优势碾压传统消息队列。
总得来说,Pulsa运用分布式系统的核心设计思想:组件解耦、单一职责、容错优先、弹性扩展。把复杂功能拆分成独立组件,每个组件只做一件事,通过协调机制配合运转,同时用多副本、无状态设计规避故障风险, 是一款兼顾先进性和实用性的消息中间件,也是云原生架构中数据流转的首选工具。