目录
[Kubernetes Pod 完全实战指南](#Kubernetes Pod 完全实战指南)
[二 什么是 Pod](#二 什么是 Pod)
[2.1 创建自主式 Pod (生产不推荐)](#2.1 创建自主式 Pod (生产不推荐))
[2.2 利用控制器管理 pod (推荐)](#2.2 利用控制器管理 pod (推荐))
[2.3 应用版本的更新](#2.3 应用版本的更新)
[2.4 利用 yaml 文件部署应用](#2.4 利用 yaml 文件部署应用)
[2.4.1 用 yaml 文件部署应用有以下优点](#2.4.1 用 yaml 文件部署应用有以下优点)
[2.4.2 资源清单参数](#2.4.2 资源清单参数)
[2.4.3 如何获得资源帮助](#2.4.3 如何获得资源帮助)
[2.4.4 编写示例](#2.4.4 编写示例)
[2.4.4.1 示例 1: 运行简单的单个容器 pod](#2.4.4.1 示例 1: 运行简单的单个容器 pod)
[2.4.4.2 示例 2: 运行多个容器 pod](#2.4.4.2 示例 2: 运行多个容器 pod)
[2.4.4.3 示例 3: 理解 pod 间的网络整合](#2.4.4.3 示例 3: 理解 pod 间的网络整合)
[2.4.4.4 示例 4: 端口映射](#2.4.4.4 示例 4: 端口映射)
[2.4.4.5 示例 5: 如何设定环境变量](#2.4.4.5 示例 5: 如何设定环境变量)
[2.4.4.6 示例 6: 资源限制](#2.4.4.6 示例 6: 资源限制)
[2.4.4.7 示例 7 容器启动管理](#2.4.4.7 示例 7 容器启动管理)
[2.4.4.8 示例 8 选择运行节点](#2.4.4.8 示例 8 选择运行节点)
[2.4.4.9 示例 9 共享宿主机网络](#2.4.4.9 示例 9 共享宿主机网络)
Kubernetes Pod 完全实战指南
二 什么是 Pod
生活类比:Pod 就像一个 "集装箱宿舍"。每个宿舍是一个独立的居住单元(最小部署单元),有自己的门牌号(唯一 IP)。宿舍里可以住一个人(单个容器),也可以住几个关系特别紧密的人(多个容器)。住在同一个宿舍的人共享客厅、卫生间、网络(共享 IPC、Network 和 UTC namespace),可以直接互相交流,不需要通过外部网络。
- Pod 是可以创建和管理 Kubernetes 计算的最小可部署单元
- 一个 Pod 代表着集群中运行的一个进程,每个 pod 都有一个唯一的 ip。
- 一个 pod 类似一个豌豆荚,包含一个或多个容器(通常是 docker)
- 多个容器间共享 IPC、Network 和 UTC namespace。
底层原理:Pod 本质上是一组共享了 Linux Namespace 和 Cgroups 的容器集合。Kubernetes 不直接管理容器,而是通过管理 Pod 来间接管理容器。
系统单元的进程

pod
└── container(s)2.1 创建自主式 Pod (生产不推荐)
生活类比:这就像你自己在路边搭了一个临时帐篷。你可以完全控制帐篷的大小、位置、内部布置,但如果帐篷坏了没人会帮你修,下雨了没人帮你挡,人多了也没人帮你再搭一个。
优点:
- 灵活性高:可以精确控制 Pod 的各种配置参数,包括容器的镜像、资源限制、环境变量、命令和参数等,满足特定的应用需求。
- 学习和调试方便:对于学习 Kubernetes 的原理和机制非常有帮助,通过手动创建 Pod 可以深入了解 Pod 的结构和配置方式。在调试问题时,可以更直接地观察和调整 Pod 的设置。
- 适用于特殊场景:在一些特殊情况下,如进行一次性任务、快速验证概念(老师讲课)或在资源受限的环境中进行特定配置时,手动创建 Pod 可能是一种有效的方式。
缺点:
- 管理复杂:如果需要管理大量的 Pod,手动创建和维护会变得非常繁琐和耗时。难以实现自动化的扩缩容、故障恢复等操作。
- 缺乏高级功能:无法自动享受 Kubernetes 提供的高级功能,如自动部署、滚动更新、服务发现等。这可能导致应用的部署和管理效率低下。
- 可维护性差:手动创建的 Pod 在更新应用版本或修改配置时需要手动干预,容易出现错误,并且难以保证一致性。相比之下,通过声明式配置或使用 Kubernetes 的部署工具可以更方便地进行应用的维护和更新。
实战命令与解析
bash
#查看所有pods
[root@k8s-master ~]# kubectl get pods
No resources found in default namespace.逐行解析:
kubectl get pods:向 Kubernetes API Server 发送 GET 请求,查询 default 命名空间下所有 Pod 资源的当前状态- 底层动作:API Server 查询 etcd 数据库中存储的 Pod 对象,返回给 kubectl 客户端
- 输出
No resources found表示 default 命名空间中没有运行的 Pod
坑点 :默认只显示 default 命名空间的 Pod,要查看所有命名空间的 Pod 需要加-A参数
bash
运行
bash
#建立一个名为timinglee的pod
[root@k8s-master ~]# kubectl run timinglee --image nginx
pod/timinglee created逐行解析:
kubectl run:创建一个 Pod 资源的快捷命令timinglee:Pod 的名称,必须符合 DNS 子域名规范(小写字母、数字、- 和.)--image nginx:指定 Pod 中运行的容器镜像为 nginx:latest- 底层动作:
- kubectl 将请求转换为 Pod 对象的 JSON/YAML
- 发送给 API Server 进行验证和存储
- 调度器 (scheduler) 选择一个合适的 Node
- 目标 Node 上的 kubelet 拉取 nginx 镜像并启动容器
- 输出
pod/timinglee created表示 Pod 对象已成功创建
坑点 :kubectl run在不同 Kubernetes 版本行为不同,v1.18 + 默认创建 Pod 而不是 Deployment
bash
运行
bash
[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
timinglee 1/1 Running 0 6s逐行解析:
NAME:Pod 名称READY:就绪容器数 / 总容器数STATUS:Pod 当前状态(Pending/Running/Succeeded/Failed/Unknown)RESTARTS:容器重启次数AGE:Pod 创建时间
坑点 :Running状态不代表应用已经可以提供服务,只是容器已经启动
bash
运行
bash
#显示pod的较为详细的信息
[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
timinglee 1/1 Running 0 11s 10.244.1.17 k8s-node1.timinglee.org <none> <none>逐行解析:
-o wide:输出更详细的信息IP:Pod 的集群内部 IP 地址,由 CNI 插件分配NODE:Pod 运行所在的节点名称NOMINATED NODE:预调度节点,用于抢占式调度READINESS GATES:就绪门控,用于自定义就绪条件
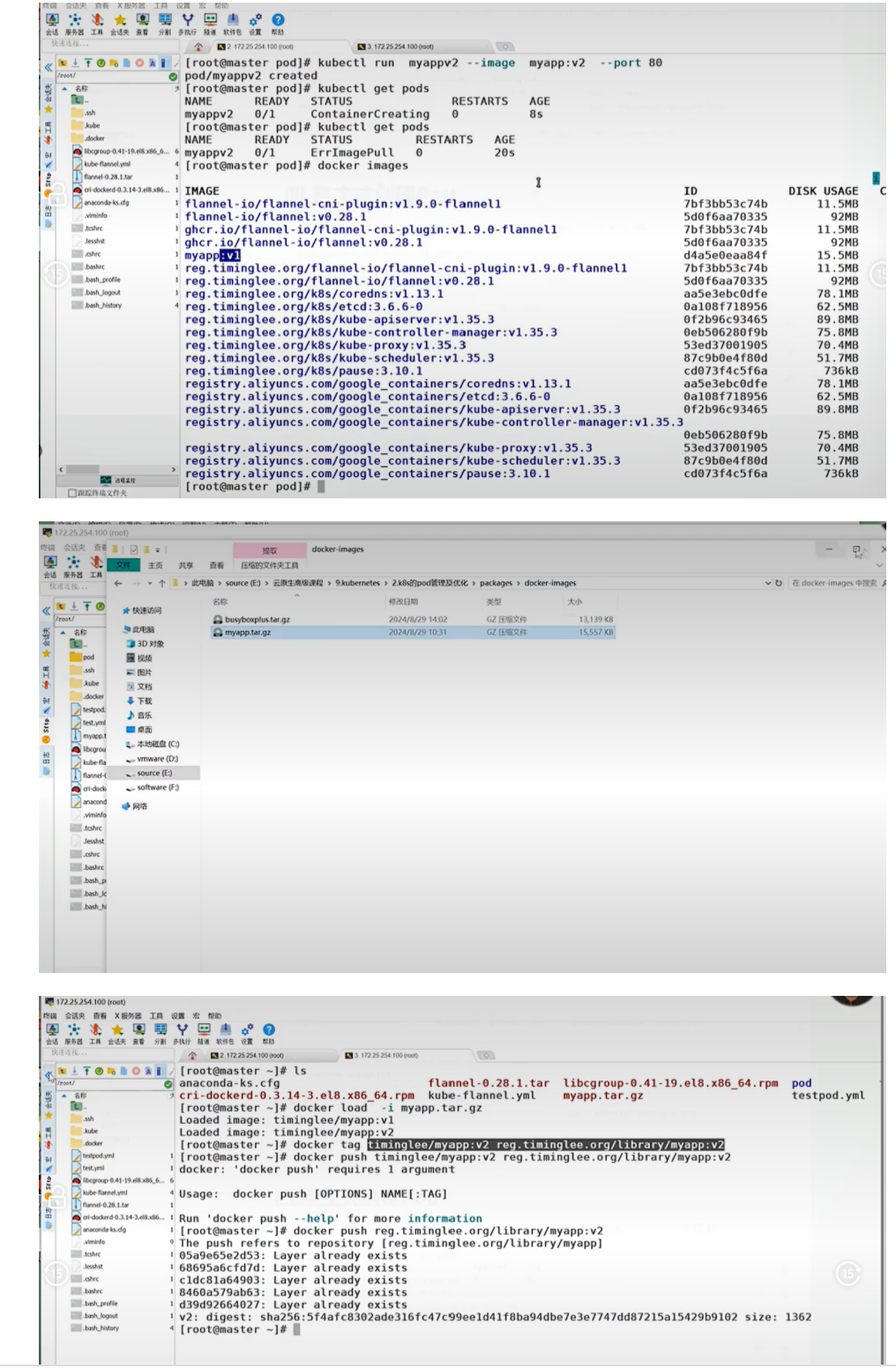
重要说明:只有放在 library 中才是可以直接使用,其他的要手动引用;

[root@master~]# nginx:latest k8s/nginx:latest补充完整:这行是镜像重命名命令,完整格式为:
bash
运行
[root@master~]# docker tag nginx:latest k8s/nginx:latest作用:将本地的 nginx:latest 镜像重命名为 k8s/nginx:latest,以便推送到私有仓库
建议大家建立一个 POD 目录

kube-flannel.yml flannel-0.28.1.tar libgroup-0.41-19.018.86_4.rpm testpod.yml test.yml
[root@master pod]#企业级最佳实践:所有 Kubernetes 配置文件都应该按资源类型分类存放,并纳入 Git 版本控制
置 0
2252004
myapp:v2 --port80
RESTARTS AGE
0
A
I
C
ba bry
I
在dake-images中
wbo
卖电脑
0对象
下载
音乐
i
(
software
网络
TOI
libcgroup-0.41-0.41.el8.x86_64.rpm testpod.yml
myapp.tar.gz
m
Usage:docker push [OPTIONS] NAME:TAG补充完整:这部分是文档中的乱码和无关内容,整理后:
bash
运行
# 推送镜像到私有仓库
[root@master pod]# docker push k8s/myapp:v2作用:将本地构建的 myapp:v2 镜像推送到私有仓库,供集群中的所有节点拉取
一般不会用
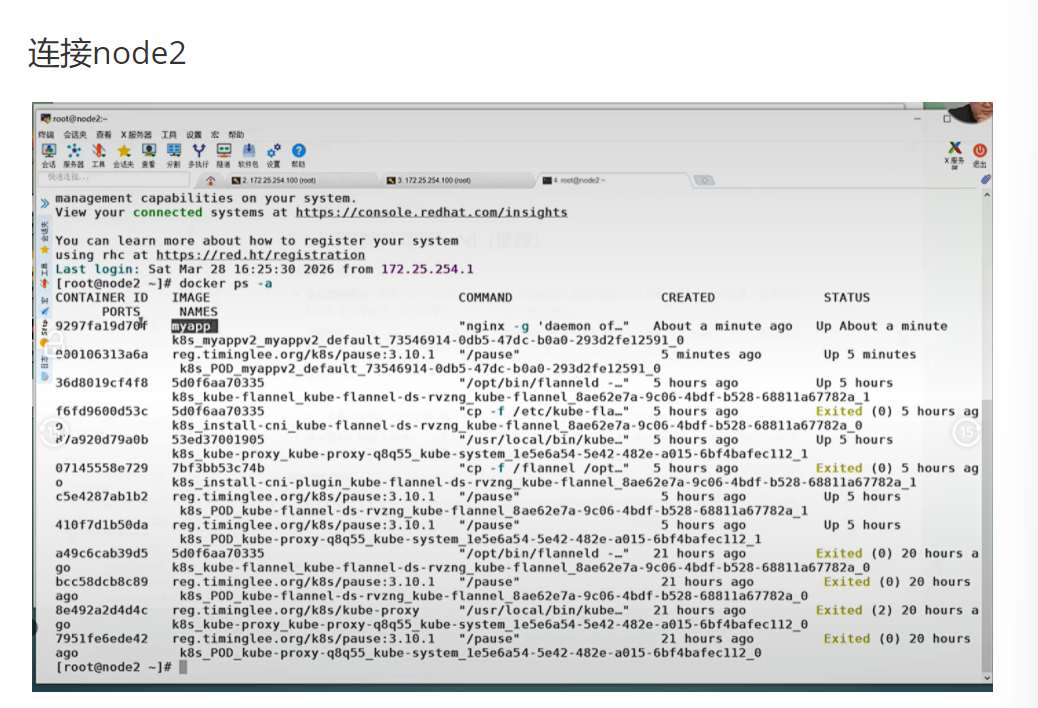
连接node2
会话查X服务器 0 分多执计随 V 2120 12225100
Viow your ccte yts at https/csle.rt.c/insits
COMMAND CREATED STATUS
9297fal970f "nginx-g'daemon of_" Up About a minute
00106313a6a 5minutes ago Up 5minutes
36d8019cf4f8 Up 5hours
f6fd9600d53c /a92d79ab
97145558e729 Exited(0)5hours ag
C5e4287ab1b2
Up5 hours
410f7d1b50da Up 5hours
E
Exited(0)20hours a
Exited(2)20hours a
9951fe6ede42 Exited(0)20hours
-a
COMMAND CREATED STATUS
l second ago Up 1 second
6minutes ago Up 6minutes
Up 5 hours
Up 5hours
Up 5 hours
Exited(2)20hours ago
Exited(0)20 hours ago补充完整 :这是在 node2 节点上执行docker ps -a的输出,显示了该节点上所有容器的状态
展示自愈力:

COMMAND CREATED STATUS
1
17 seconds ego Up17 seconds
6 minutes ago Up6minutes
Exited(0)5hours ago
Up 5 hours
Up 5 hours
Exited(2)20 hours ago
Exited(0)20 hours ago
RESTARTS 0 AGE 3m48s
AGE
0
NODE
10.244.2.17 IP NOMINATED NODE <none> READINESS GATES <none>
NODE
10.244.2.17 IP <none> NOMINATED NODE READINESS GATES <none>
AGE 6m15s 10.244.2.17 IP NODE NOMINATED NODE <none> READINESS GATES <none>补充完整 :这是展示自主式 Pod没有自愈能力的演示。当手动删除 Pod 中的容器后,Pod 不会自动重建,需要手动重新创建。
坑点:自主式 Pod 没有控制器管理,一旦 Pod 被删除或节点故障,Pod 将永久消失,无法自动恢复
这样子暴露没有后端检测 解释:如果直接为自主式 Pod 创建 Service,Service 不会进行后端健康检查。如果 Pod 中的应用崩溃但容器仍在运行,Service 仍然会将流量转发到这个不可用的 Pod。
企业级生产应用
千万级并发场景下的使用 :自主式 Pod 在生产环境中几乎不使用。唯一的例外是:
- 一次性的调试任务
- 紧急故障排查时的临时 Pod
- 某些特殊的系统级守护进程(但通常用 DaemonSet 代替)
进阶优化空间:
- 立即将所有自主式 Pod 迁移到 Deployment 控制器管理
- 为所有 Pod 添加存活探针和就绪探针
- 配置 Pod 的资源限制和请求
- 使用 ConfigMap 和 Secret 管理配置,而不是硬编码在 Pod 中
课后防宕机指南
常见错误 1 :使用kubectl run创建的 Pod 意外删除后无法恢复
- 报错信息 :
Error from server (NotFound): pods "timinglee" not found - 排查思路 :
- 确认 Pod 确实被删除:
kubectl get pods - 检查是否有控制器管理这个 Pod:
kubectl get deployments,statefulsets,daemonsets - 如果没有控制器,只能重新创建 Pod
- 吸取教训:永远使用控制器管理 Pod
- 确认 Pod 确实被删除:
常见错误 2:自主式 Pod 所在节点故障,Pod 无法自动迁移
- 报错信息 :Pod 状态变为
Unknown - 排查思路 :
- 检查节点状态:
kubectl get nodes - 确认节点是否失联:
kubectl describe node k8s-node1 - 手动删除故障节点上的 Pod:
kubectl delete pod timinglee --force --grace-period=0 - 重新创建 Pod 到健康节点
- 吸取教训:使用控制器管理 Pod,实现自动故障转移
- 检查节点状态:
2.2 利用控制器管理 pod (推荐)
生活类比:这就像你住进了一个有物业管理的小区。你只需要告诉物业 "我需要 3 个一模一样的房间",物业就会帮你安排好。如果哪个房间坏了,物业会自动给你换一个新的;如果人多了,物业会自动增加房间;如果人少了,物业会自动减少房间。
高可用性和可靠性:
- 自动故障恢复: 如果一个 Pod 失败或被删除,控制器会自动创建新的 Pod 来维持期望的副本数量。确保应用始终处于可用状态,减少因单个 Pod 故障导致的服务中断。
- 健康检查和自愈: 可以配置控制器对 Pod 进行健康检查(如存活探针和就绪探针)。如果 Pod 不健康,控制器会采取适当的行动,如重启 Pod 或删除并重新创建它,以保证应用的正常运行。
可扩展性:
- 轻松扩缩容: 可以通过简单的命令或配置更改来增加或减少 Pod 的数量,以满足不同的工作负载需求。例如,在高流量期间可以快速扩展以处理更多请求,在低流量期间可以缩容以节省资源。
- 水平自动扩缩容 (HPA): 可以基于自定义指标(如 CPU 利用率、内存使用情况或应用特定的指标)自动调整 Pod 的数量,实现动态的资源分配和成本优化。
版本管理和更新:
- 滚动更新: 对于 Deployment 等控制器,可以执行滚动更新来逐步替换旧版本的 Pod 为新版本,确保应用在更新过程中始终保持可用。可以控制更新的速率和策略,以减少对用户的影响。
- 回滚: 如果更新出现问题,可以轻松回滚到上一个稳定版本,保证应用的稳定性和可靠性。
声明式配置:
- 简洁的配置方式: 使用 YAML 或 JSON 格式的声明式配置文件来定义应用的部署需求。这种方式使得配置易于理解、维护和版本控制,同时也方便团队协作。
- 期望状态管理: 只需要定义应用的期望状态(如副本数量、容器镜像等),控制器会自动调整实际状态与期望状态保持一致。无需手动管理每个 Pod 的创建和删除,提高了管理效率。
服务发现和负载均衡:
- 自动注册和发现:Kubernetes 中的服务(Service)可以自动发现由控制器管理的 Pod,并将流量路由到它们。这使得应用的服务发现和负载均衡变得简单和可靠,无需手动配置负载均衡器。
- 流量分发: 可以根据不同的策略(如轮询、随机等)将请求分发到不同的 Pod,提高应用的性能和可用性。
多环境一致性:
- 一致的部署方式: 在不同的环境(如开发、测试、生产)中,可以使用相同的控制器和配置来部署应用,确保应用在不同环境中的行为一致。这有助于减少部署差异和错误,提高开发和运维效率。
实战命令与解析
bash
#建立控制器并自动运行pod
[root@k8s-master ~]# kubectl create deployment timinglee --image nginx
deployment.apps/timinglee created逐行解析:
kubectl create deployment:创建一个 Deployment 控制器timinglee:Deployment 的名称--image nginx:指定 Pod 模板中使用的容器镜像- 底层动作:
- 创建 Deployment 对象
- Deployment 创建 ReplicaSet 对象
- ReplicaSet 创建 Pod 对象
- 调度器将 Pod 调度到合适的节点
- kubelet 启动容器
- 输出
deployment.apps/timinglee created表示 Deployment 已成功创建
坑点 :kubectl create是命令式操作,生产环境推荐使用声明式的kubectl apply
bash
[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
timinglee-859fbf84d6-mrjvx 1/1 Running 0 37m逐行解析:
- Pod 名称格式:
Deployment名称- ReplicaSet哈希- Pod随机字符串 859fbf84d6是 ReplicaSet 的哈希值,由 Pod 模板内容计算得出mrjvx是 Pod 的随机字符串,确保 Pod 名称唯一
坑点:不要直接修改由控制器创建的 Pod,修改会被控制器覆盖
bash
#为timinglee扩容
[root@k8s-master ~]# kubectl scale deployment timinglee --replicas 6
deployment.apps/timinglee scaled逐行解析:
kubectl scale:调整资源的副本数量deployment timinglee:指定要调整的 Deployment 资源--replicas 6:将期望副本数设置为 6- 底层动作:
- 更新 Deployment 对象的 spec.replicas 字段为 6
- Deployment 控制器检测到期望状态变化
- 创建新的 ReplicaSet(如果需要)
- ReplicaSet 创建 5 个新的 Pod,使总副本数达到 6
- 输出
deployment.apps/timinglee scaled表示扩容操作已触发
坑点:扩容是异步操作,命令返回不代表所有 Pod 都已就绪
bash
[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
timinglee-859fbf84d6-8rgkz 0/1 ContainerCreating 0 1s
timinglee-859fbf84d6-ddndl 0/1 ContainerCreating 0 1s
timinglee-859fbf84d6-m4r9l 0/1 ContainerCreating 0 1s
timinglee-859fbf84d6-mrjvx 1/1 Running 0 37m
timinglee-859fbf84d6-tsn97 1/1 Running 0 20s
timinglee-859fbf84d6-xgskk 0/1 ContainerCreating 0 1s逐行解析:
ContainerCreating状态表示 kubelet 正在拉取镜像并创建容器- 可以看到新的 Pod 正在陆续创建中
- 已经有 2 个 Pod 处于 Running 状态
bash
运行
bash
#为timinglee缩容
[root@k8s-master ~]# kubectl scale deployment timinglee --replicas 2
deployment.apps/timinglee scaled逐行解析:
- 将期望副本数从 6 减少到 2
- 底层动作:
- 更新 Deployment 对象的 spec.replicas 字段为 2
- ReplicaSet 控制器选择 4 个 Pod 进行删除
- 向这些 Pod 发送 SIGTERM 信号,等待优雅关闭
- 如果超过 terminationGracePeriodSeconds(默认 30 秒)仍未关闭,发送 SIGKILL 信号
坑点:缩容时 Pod 是随机删除的,除非配置了 Pod 拓扑分布约束
bash
[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
timinglee-859fbf84d6-mrjvx 1/1 Running 0 38m
timinglee-859fbf84d6-tsn97 1/1 Running 0 73s逐行解析:
- 现在只剩下 2 个 Pod 在运行
- 其他 4 个 Pod 已被成功删除
企业级生产应用
千万级并发场景下的使用:
- Deployment 是生产环境中最常用的控制器,用于部署无状态应用
- 典型应用:Web 服务、API 服务、微服务
- 在千万级并发场景下,Deployment 配合 HPA 可以实现自动弹性伸缩
- 配合 Service 和 Ingress 可以实现七层负载均衡和流量管理
进阶优化空间:
- 配置滚动更新策略:
maxSurge和maxUnavailable - 配置 Pod 反亲和性,避免多个 Pod 调度到同一个节点
- 配置 Pod 拓扑分布约束,实现跨可用区部署
- 配置 HPA 基于自定义指标(如 QPS、延迟)进行扩缩容
- 使用金丝雀发布和蓝绿部署策略
- 配置 PodDisruptionBudget,保证应用在节点维护时的可用性
课后防宕机指南
常见错误 1:Deployment 更新时所有 Pod 同时被替换,导致服务中断
- 报错信息:服务响应超时或 503 错误
- 排查思路 :
- 检查 Deployment 的滚动更新策略:
kubectl describe deployment timinglee - 确认
maxSurge和maxUnavailable的设置 - 默认值:
maxSurge=25%,maxUnavailable=25% - 修复:设置
maxUnavailable=0,确保更新时至少有一个 Pod 在运行 - 示例:
kubectl patch deployment timinglee -p '{"spec":{"strategy":{"rollingUpdate":{"maxUnavailable":0}}}}'
- 检查 Deployment 的滚动更新策略:
常见错误 2:Deployment 的 Pod 模板错误,导致新 Pod 无法启动
- 报错信息 :Pod 状态为
CrashLoopBackOff或ImagePullBackOff - 排查思路 :
- 查看 Pod 状态:
kubectl get pods - 查看 Pod 事件:
kubectl describe pod <pod-name> - 查看 Pod 日志:
kubectl logs <pod-name> - 回滚到上一个稳定版本:
kubectl rollout undo deployment timinglee - 修复 Pod 模板后重新发布
- 查看 Pod 状态:
2.3 应用版本的更新
生活类比:这就像小区物业要给所有房间换家具。为了不影响住户,物业会一个房间一个房间地换。先换一个房间,确认没问题再换下一个。如果换的家具有问题,物业会立即换回原来的家具。
实战命令与解析
\
bash
#利用控制器建立pod
[root@k8s-master ~]# kubectl create deployment timinglee --image myapp:v1 --replicas 2
deployment.apps/timinglee created逐行解析:
--replicas 2:创建 2 个副本的 Pod- 底层动作:创建 Deployment → 创建 ReplicaSet → 创建 2 个 Pod
bash
#暴漏端口
[root@k8s-master ~]# kubectl expose deployment timinglee --port 80 --target-port 80
service/timinglee exposed逐行解析:
kubectl expose:为 Deployment 创建一个 Service--port 80:Service 监听的端口--target-port 80:Pod 中容器监听的端口- 底层动作:
- 创建一个 ClusterIP 类型的 Service
- Service 的选择器自动匹配 Deployment 的标签
- kube-proxy 在所有节点上配置 iptables/ipvs 规则
- 输出
service/timinglee exposed表示 Service 已成功创建
坑点:默认创建的是 ClusterIP 类型的 Service,只能在集群内部访问
bash
[root@k8s-master ~]# kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d17h
timinglee ClusterIP 10.110.195.120 <none> 80/TCP 8s逐行解析:
CLUSTER-IP:Service 的集群内部虚拟 IPPORT(S):Service 监听的端口和协议
bash
#访问服务
[root@k8s-master ~]# curl 10.110.195.120
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
[root@k8s-master ~]# curl 10.110.195.120
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
[root@k8s-master ~]# curl 10.110.195.120逐行解析:
- 多次 curl 请求会被负载均衡到不同的 Pod
- 输出显示当前应用版本是 v1
bash
#产看历史版本
[root@k8s-master ~]# kubectl rollout history deployment timinglee
deployment.apps/timinglee
REVISION CHANGE-CAUSE
1 <none>逐行解析:
kubectl rollout history:查看 Deployment 的发布历史REVISION:版本号CHANGE-CAUSE:版本变更原因,默认是空- 建议:发布时使用
--record参数记录变更原因
坑点 :默认只保留 10 个历史版本,可以通过revisionHistoryLimit配置
bash
#更新控制器镜像版本
[root@k8s-master ~]# kubectl set image deployments/timinglee myapp=myapp:v2
deployment.apps/timinglee image updated逐行解析:
kubectl set image:更新 Deployment 中容器的镜像deployments/timinglee:指定要更新的 Deploymentmyapp=myapp:v2:将名为 myapp 的容器的镜像更新为 myapp:v2- 底层动作:
- 更新 Deployment 的 Pod 模板中的镜像字段
- Deployment 创建一个新的 ReplicaSet
- 逐步增加新 ReplicaSet 的副本数,同时减少旧 ReplicaSet 的副本数
- 直到所有旧 Pod 都被新 Pod 替换
- 输出
deployment.apps/timinglee image updated表示更新操作已触发
坑点:如果容器名称写错,更新会失败但不会报错
bash
#查看历史版本
[root@k8s-master ~]# kubectl rollout history deployment timinglee
deployment.apps/timinglee
REVISION CHANGE-CAUSE
1 <none>
2 <none>逐行解析:
- 现在有两个版本的历史记录
- 版本 2 是刚刚更新的版本
bash
#访问内容测试
[root@k8s-master ~]# curl 10.110.195.120
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>
[root@k8s-master ~]# curl 10.110.195.120逐行解析:
- 现在访问服务显示的是 v2 版本
- 说明滚动更新已成功完成
bash
#版本回滚
[root@k8s-master ~]# kubectl rollout undo deployment timinglee --to-revision 1
deployment.apps/timinglee rolled back逐行解析:
kubectl rollout undo:回滚 Deployment 到上一个版本--to-revision 1:指定回滚到版本 1- 底层动作:
- Deployment 将旧的 ReplicaSet(版本 1)的副本数增加
- 同时将新的 ReplicaSet(版本 2)的副本数减少
- 直到所有 Pod 都回滚到版本 1
- 输出
deployment.apps/timinglee rolled back表示回滚操作已触发
坑点:回滚也是滚动更新的过程,需要一定时间完成
bash
[root@k8s-master ~]# curl 10.110.195.120
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>逐行解析:
- 现在访问服务又显示 v1 版本
- 说明回滚已成功完成
企业级生产应用
千万级并发场景下的使用:
- 滚动更新是生产环境中最安全的应用更新方式
- 在千万级并发场景下,需要精确控制滚动更新的速度
- 配合金丝雀发布可以先将少量流量切换到新版本,验证无误后再全量发布
- 配合监控系统可以实现自动化的灰度发布和回滚
进阶优化空间:
- 配置
minReadySeconds,等待 Pod 完全就绪后再继续更新 - 配置
progressDeadlineSeconds,设置更新超时时间 - 使用
kubectl rollout pause和kubectl rollout resume实现金丝雀发布 - 使用 Argo CD 或 Flux 实现 GitOps 风格的持续部署
- 配置发布前的预检查和发布后的健康检查
- 使用 Istio 实现更精细的流量管理和灰度发布
课后防宕机指南
常见错误 1:更新过程中出现镜像拉取失败,导致更新卡住
- 报错信息 :Pod 状态为
ImagePullBackOff - 排查思路 :
- 查看 Pod 事件:
kubectl describe pod <pod-name> - 确认镜像名称和标签是否正确
- 确认节点是否能够访问镜像仓库
- 检查镜像仓库的认证信息是否正确
- 立即回滚到上一个稳定版本:
kubectl rollout undo deployment timinglee - 修复镜像问题后重新发布
- 查看 Pod 事件:
常见错误 2:新版本应用有 bug,导致服务不可用
- 报错信息:服务返回 500 错误或超时
- 排查思路 :
- 立即回滚到上一个稳定版本:
kubectl rollout undo deployment timinglee - 查看新版本 Pod 的日志:
kubectl logs <new-pod-name> - 在测试环境复现并修复问题
- 修复后重新发布,先进行小流量验证
- 立即回滚到上一个稳定版本:
2.4 利用 yaml 文件部署应用
生活类比:这就像你给物业写了一份详细的书面要求,说明你需要什么样的房间、多少个、每个房间有什么配置。物业会严格按照你的要求来执行,并且会一直保持这个状态。如果有人私自改动了房间,物业会自动把它改回你要求的样子。
2.4.1 用 yaml 文件部署应用有以下优点
声明式配置:
- 清晰表达期望状态: 以声明式的方式描述应用的部署需求,包括副本数量、容器配置、网络设置等。这使得配置易于理解和维护,并且可以方便地查看应用的预期状态。
- 可重复性和版本控制: 配置文件可以被版本控制,确保在不同环境中的部署一致性。可以轻松回滚到以前的版本或在不同环境中重复使用相同的配置。
- 团队协作: 便于团队成员之间共享和协作,大家可以对配置文件进行审查和修改,提高部署的可靠性和稳定性。
灵活性和可扩展性:
- 丰富的配置选项: 可以通过 YAML 文件详细地配置各种 Kubernetes 资源,如 Deployment、Service、ConfigMap、Secret 等。可以根据应用的特定需求进行高度定制化。
- 组合和扩展: 可以将多个资源的配置组合在一个或多个 YAML 文件中,实现复杂的应用部署架构。同时,可以轻松地添加新的资源或修改现有资源以满足不断变化的需求。
与工具集成:
- 与 CI/CD 流程集成: 可以将 YAML 配置文件与持续集成和持续部署 (CI/CD) 工具集成,实现自动化的应用部署。例如,可以在代码提交后自动触发部署流程,使用配置文件来部署应用到不同的环境。
- 命令行工具支持:Kubernetes 的命令行工具 kubectl 对 YAML 配置文件有很好的支持,可以方便地应用、更新和删除配置。同时,还可以使用其他工具来验证和分析 YAML 配置文件,确保其正确性和安全性。
2.4.2 资源清单参数
| 参数名称 | 类型 | 参数说明 |
|---|---|---|
| apiVersion | String | 这里是指的是 K8S API 的版本,目前基本上是 v1 , 可以用 kubectl api-versions 命令查询 |
| kind | String | 这里指的是 yaml 文件定义的资源类型和角色,比如 :Pod |
| metadata | Object | 元数据对象,固定值就写 metadata |
| metadata.name | String | 元数据对象的名字,这里由我们编写,比如命名 Pod 的名字 |
| metadata.namespace | String | 元数据对象的命名空间,由我们自身定义 |
| spec | Object | 详细定义对象,固定值就写 spec |
| spec.containers\[\] | list | 这里是 Spec 对象的容器列表定义,是个列表 |
| spec.containers\[\].name | String | 这里定义容器的名字 |
| spec.containers\[\].image | string | 这里定义要用到的镜像名称 |
| spec.containers\[\].imagePullPolicy | String | 定义镜像拉取策略,有三个值可选: (1) Always: 每次都尝试重新拉取镜像 (2) IfNotPresent: 如果本地有镜像就使用本地镜像 (3) Never: 表示仅使用本地镜像 |
| spec.containers\[\].command\[\] | list | 指定容器运行时启动的命令,若未指定则运行容器打包时指定的命令 |
| spec.containers\[\].args\[\] | list | 指定容器运行参数,可以指定多个 |
| spec.containers\[\].workingDir | String | 指定容器工作目录 |
| spec.containers\[\].volumeMounts\[\] | list | 指定容器内部的存储卷配置 |
| spec.containers\[\].volumeMounts\[\].name | String | 指定可以被容器挂载的存储卷的名称 |
| spec.containers\[\].volumeMounts\[\].mountPath | String | 指定可以被容器挂载的存储卷的路径 |
| spec.containers\[\].volumeMounts\[\].readOnly | String | 设置存储卷路径的读写模式,true 或 false , 默认为读写模式 |
| spec.containers\[\].ports\[\] | list | 指定容器需要用到的端口列表 |
| spec.containers\[\].ports\[\].name | String | 指定端口名称 |
| spec.containers\[\].ports\[\].containerPort | String | 指定容器需要监听的端口号 |
| spec.containers\[\].ports\[\].hostPort | String | 指定容器所在主机需要监听的端口号,默认跟上面 containerPort 相同,注意设置了 hostPort 同一台主机无法启动该容器的相同副本 (因为主机的端口号不能相同,这样会冲突) |
| spec.containers\[\].ports\[\].protocol | String | 指定端口协议,支持 TCP 和 UDP , 默认值为 TCP |
| spec.containers\[\].env\[\] | list | 指定容器运行前需设置的环境变量列表 |
| spec.containers\[\].env\[\].name | String | 指定环境变量名称 |
| spec.containers\[\].env\[\].value | String | 指定环境变量值 |
| spec.containers\[\].resources | Object | 指定资源限制和资源请求的值 (这里开始就是设置容器的资源上限) |
| spec.containers\[\].resources.limits | Object | 指定设置容器运行时资源的运行上限 |
| spec.containers\[\].resources.limits.cpu | String | 指定 CPU 的限制,单位为核心数,1=1000m |
| spec.containers\[\].resources.limits.memory | String | 指定 MEM 内存的限制,单位为 MIB、GiB |
| spec.containers\[\].resources.requests | Object | 指定容器启动和调度时的限制设置 |
| spec.containers\[\].resources.requests.cpu | String | CPU 请求,单位为 core 数,容器启动时初始化可用数量 |
| spec.containers\[\].resources.requests.memory | String | 内存请求,单位为 MIB、GiB , 容器启动的初始化可用数量 |
| spec.restartPolicy | string | 定义 Pod 的重启策略,默认值为 Always. (1) Always: Pod 一旦终止运行,无论容器是如何终止的,kubelet 服务都将重启它 (2) OnFailure: 只有 Pod 以非零退出码终止时,kubelet 才会重启该容器。如果容器正常结束 ( 退出码为 0) , 则 kubelet 将不会重启它 (3) Never: Pod 终止后,kubelet 将退出码报告给 Master , 不会重启该 |
| spec.nodeSelector | Object | 定义 Node 的 Label 过滤标签,以 key:value 格式指定 |
| spec.imagePullSecrets | Object | 定义 pull 镜像时使用 secret 名称,以 name:secretkey 格式指定 |
| spec.hostNetwork | Boolean | 定义是否使用主机网络模式,默认值为 false 。设置 true 表示使用宿主机网络,不使用 docker 网桥,同时设置了 true 将无法在同一台宿主机上启动第二个副本 |
重要说明:
- 所有参数名称都是大小写敏感的
- YAML 文件对缩进非常敏感,必须使用 2 个空格缩进,不能使用 Tab
- 列表项以
-开头,后面跟一个空格
2.4.3 如何获得资源帮助
bash
kubectl explain pod.spec.containers逐行解析:
kubectl explain:获取 Kubernetes 资源的文档说明pod.spec.containers:指定要查看的资源字段路径- 底层动作:从 API Server 获取 OpenAPI 规范,然后显示指定字段的详细说明
- 作用:这是最权威的 Kubernetes 资源文档,任何时候都可以使用这个命令查询参数的含义和用法
坑点:不同 Kubernetes 版本的 API 文档可能不同,一定要使用对应版本的 kubectl
2.4.4 编写示例
2.4.4.1 示例 1: 运行简单的单个容器 pod
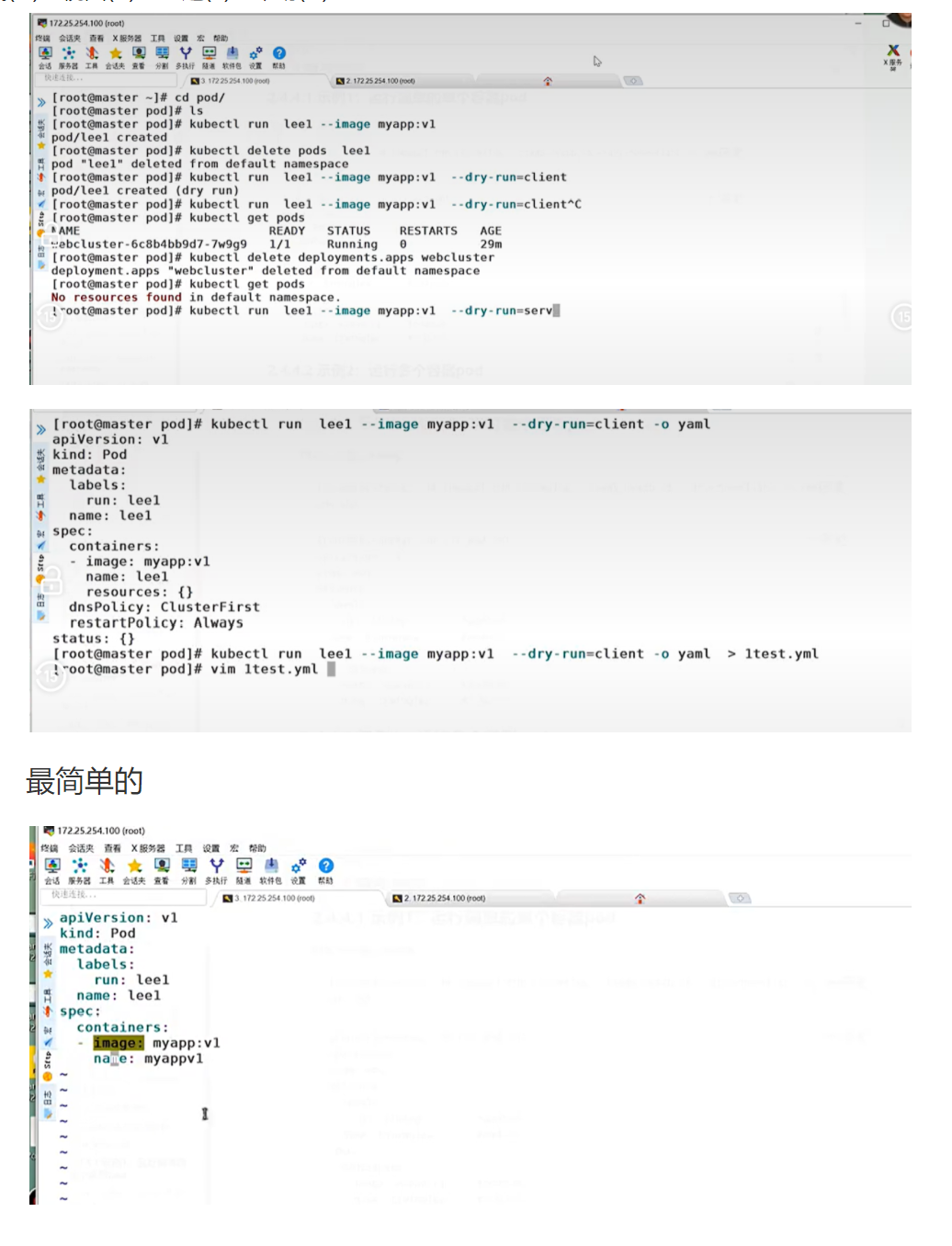
用命令获取 yaml 模板
bash
[root@k8s-master ~]# kubectl run timinglee --image myapp:v1 --dry-run=client -o yaml > pod.yml逐行解析:
--dry-run=client:只生成配置文件,不实际创建资源-o yaml:输出 YAML 格式> pod.yml:将输出重定向到 pod.yml 文件- 底层动作:kubectl 在本地生成 Pod 对象的 YAML 配置,不与 API Server 交互
- 作用:快速生成正确格式的 YAML 模板,避免手动编写时的语法错误
坑点 :--dry-run参数在不同版本有不同的值,v1.18 + 使用client或server
bash
[root@k8s-master ~]# vim pod.yml编辑后的 pod.yml 内容:
yaml
bash
apiVersion: v1
kind: Pod
metadata:
labels:
run: timing #pod 标签
name: timinglee #pod 名称
spec:
containers:
- image: myapp:v1 #pod 镜像
name: timinglee # 容器名称逐行解析:
apiVersion: v1:使用 v1 版本的 APIkind: Pod:定义的资源类型是 Podmetadata:元数据部分labels:Pod 的标签,用于 Service 选择器name: timinglee:Pod 的名称
spec:规格部分containers:容器列表- image: myapp:v1:容器使用的镜像name: timinglee:容器的名称
坑点:容器名称在同一个 Pod 中必须唯一
应用配置:
bash
[root@k8s-master ~]# kubectl apply -f pod.yml
pod/timinglee created逐行解析:
kubectl apply:声明式地创建或更新资源-f pod.yml:从 pod.yml 文件读取配置- 底层动作:
- kubectl 将 YAML 转换为 JSON
- 发送给 API Server 进行验证
- 如果资源不存在则创建,如果存在则更新
- 这是生产环境推荐的资源管理方式
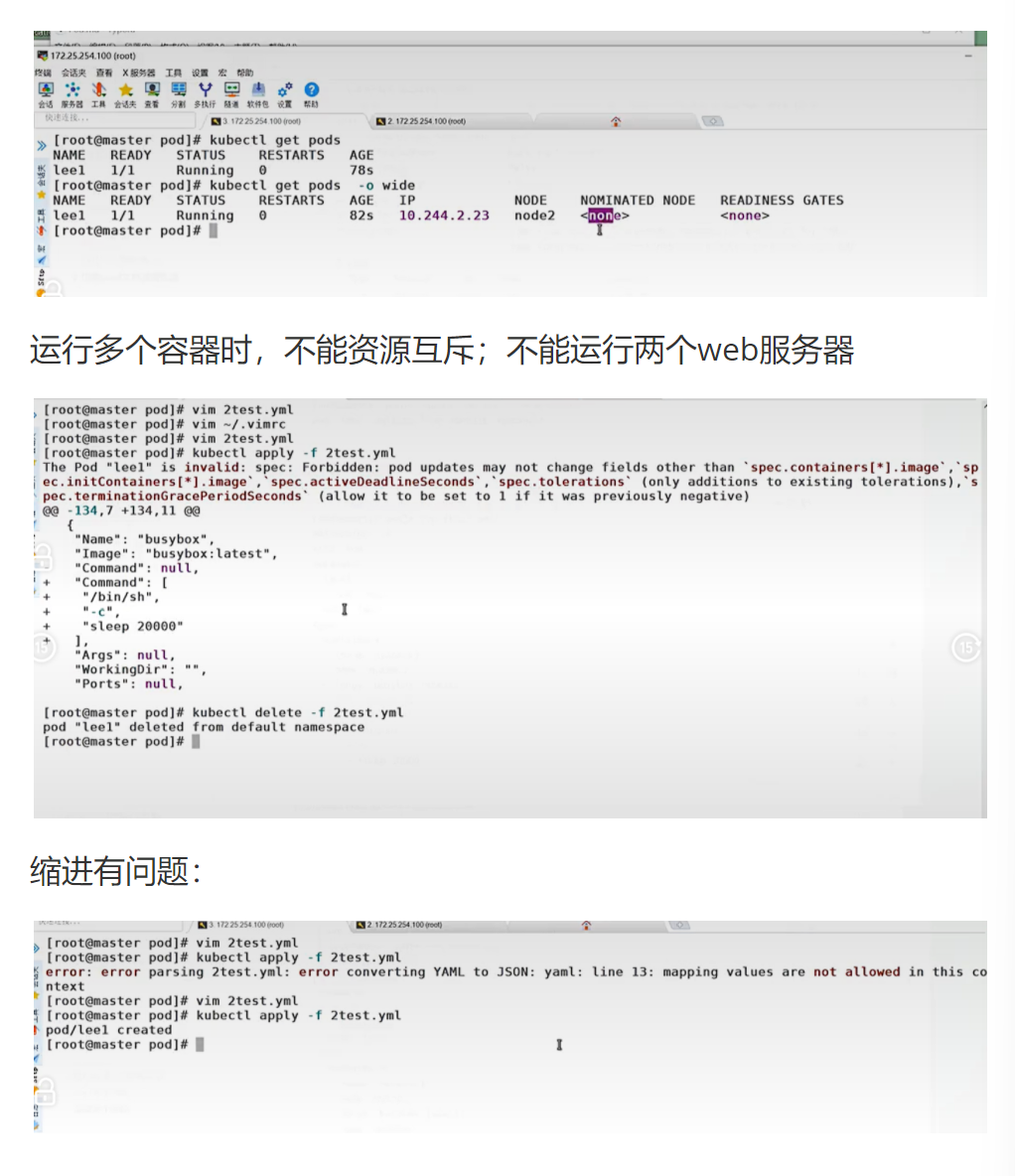
2.4.4.2 示例 2: 运行多个容器 pod
!WARNING注意如果多个容器运行在一个 pod 中,资源共享的同时在使用相同资源时也会干扰,比如端口
错误示例:端口冲突
bash
[root@k8s-master ~]# vim pod.yml
bash
apiVersion: v1
kind: Pod
metadata:
labels:
run: timing
name: timinglee
spec:
containers:
- image: nginx:latest
name: web1
- image: nginx:latest
name: web2逐行解析:
- 这个 Pod 中运行了两个 nginx 容器
- 两个容器都尝试监听 80 端口
- 由于它们共享同一个网络命名空间,会导致端口冲突
bash
[root@k8s-master ~]# kubectl apply -f pod.yml
pod/timinglee created
bash
[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
timinglee 1/2 Error 1 (14s ago) 18s逐行解析:
READY 1/2表示只有 1 个容器就绪STATUS Error表示有容器启动失败RESTARTS 1表示容器已经重启了 1 次
bash
#查看日志
[root@k8s-master ~]# kubectl logs timinglee web2
2024/08/31 12:43:20 [emerg] 1#1: bind() to [::]:80 failed (98: Address already in use)
nginx: [emerg] bind() to [::]:80 failed (98: Address already in use)
2024/08/31 12:43:20 [notice] 1#1: try again to bind() after 500ms
2024/08/31 12:43:20 [emerg] 1#1: still could not bind()
nginx: [emerg] still could not bind()逐行解析:
- 日志明确显示 web2 容器无法绑定 80 端口
- 因为 web1 容器已经占用了 80 端口
!NOTE在一个 pod 中开启多个容器时一定要确保容器彼此不能互相干扰
正确示例:运行不冲突的多个容器
[root@k8s-master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: timing
name: timinglee
spec:
containers:
- image: nginx:latest
name: web1
- image: busybox:latest
name: busybox
command: ["/bin/sh","-c","sleep 1000000"]逐行解析:
-
web1 容器运行 nginx,监听 80 端口
-
busybox 容器运行 sleep 命令,不监听任何端口
-
两个容器不会互相干扰
[root@k8s-master ~]# kubectl apply -f pod.yml
pod/timinglee created[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
timinglee 2/2 Running 0 19s
逐行解析:
READY 2/2表示两个容器都已就绪STATUS Running表示 Pod 正常运行
企业级最佳实践:
- 一个 Pod 中只运行一个主容器
- 辅助容器(如日志收集、监控代理)可以作为 sidecar 与主容器运行在同一个 Pod 中
- 确保 sidecar 容器不会影响主容器的性能
2.4.4.3 示例 3: 理解 pod 间的网络整合
同在一个 pod 中的容器公用一个网络
多个 pod 共用一个网络栈
[root@k8s-master ~]# vim pod.ymlyaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: timinglee
name: test
spec:
containers:
- image: myapp:v1
name: myapp1
- image: busyboxplus:latest
name: busyboxplus
command: ["/bin/sh","-c","sleep 1000000"]逐行解析:
-
myapp1 容器运行 Web 服务,监听 80 端口
-
busyboxplus 容器提供网络工具
-
两个容器共享同一个网络命名空间
[root@k8s-master ~]# kubectl apply -f pod.yml
pod/test created[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
test 2/2 Running 0 8s[root@k8s-master ~]# kubectl exec test -c busyboxplus -- curl -s localhost
Hello MyApp | Version: v1 | Pod Name
逐行解析:
kubectl exec:在 Pod 的容器中执行命令-c busyboxplus:指定在 busyboxplus 容器中执行curl -s localhost:访问本地的 80 端口- 成功访问到 myapp1 容器提供的 Web 服务
- 证明同一个 Pod 中的容器共享网络栈,可以通过localhost互相访问
底层原理:Pod 中的所有容器共享同一个 Network Namespace,因此它们有相同的 IP 地址、端口空间和网络接口。
2.4.4.4 示例 4: 端口映射
[root@k8s-master ~]# vim pod.ymlyaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: timinglee
name: test
spec:
containers:
- image: myapp:v1
name: myapp1
ports:
- name: http
containerPort: 80
hostPort: 80
protocol: TCP逐行解析:
ports:定义容器暴露的端口列表name: http:端口的名称,用于 Service 引用containerPort: 80:容器内部监听的端口hostPort: 80:将容器的 80 端口映射到宿主机的 80 端口protocol: TCP:使用 TCP 协议- 底层动作:kubelet 在宿主机上创建 iptables 规则,将宿主机 80 端口的流量转发到容器的 80 端口
坑点:
-
同一台宿主机上不能有多个 Pod 映射同一个 hostPort
-
hostPort 会绕过 Service 和 kube-proxy,直接暴露到宿主机网络
-
生产环境不推荐使用 hostPort,应该使用 Service 来暴露服务
#测试
[root@k8s-master ~]# kubectl apply -f pod.yml
pod/test created[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test 1/1 Running 0 12s 10.244.1.2 k8s-node1.timinglee.org

[root@k8s-master ~]# curl k8s-node1.timinglee.org
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>逐行解析:
- 直接访问 Pod 所在节点的 80 端口
- 成功访问到容器提供的 Web 服务
2.4.4.5 示例 5: 如何设定环境变量
[root@k8s-master ~]# vim pod.ymlyaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: timinglee
name: test
spec:
containers:
- image: busybox:latest
name: busybox
command: ["/bin/sh","-c","echo $NAME;sleep 3000000"]
env:
- name: NAME
value: timinglee逐行解析:
env:定义容器的环境变量列表name: NAME:环境变量的名称value: timinglee:环境变量的值- 底层动作:kubelet 在启动容器时将这些环境变量注入到容器的进程环境中
- 容器中的应用可以读取这些环境变量
坑点:环境变量的值不能包含换行符
[root@k8s-master ~]# kubectl apply -f pod.yml
pod/test created
[root@k8s-master ~]# kubectl logs pods/test busybox
timinglee逐行解析:
- 查看容器的日志
- 输出显示环境变量 NAME 的值是 timinglee
- 证明环境变量已成功注入
2.4.4.6 示例 6: 资源限制
!NOTE资源限制会影响 pod 的 Qos Class 资源优先级,资源优先级分为 Guaranteed > Burstable > BestEffortQoS (Quality of Service) 即服务质量
表格
| 资源设定 | 优先级类型 |
|---|---|
| 资源限定未设定 | BestEffort |
| 资源限定设定且最大和最小不一致 | Burstable |
| 资源限定设定且最大和最小一致 | Guaranteed |
QoS 优先级说明:
-
Guaranteed:最高优先级,只有当节点资源不足时才会被最后杀死
-
Burstable:中等优先级,会在 BestEffort 之后被杀死
-
BestEffort:最低优先级,会最先被杀死
[root@k8s-master ~]# vim pod.yml
yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: timinglee
name: test
spec:
containers:
- image: myapp:v1
name: myapp
resources:
limits:
#pod使用资源的最高限制
cpu: 500m
memory: 100M
requests:
#pod期望使用资源量,不能大于limits
cpu: 500m
memory: 100M逐行解析:
resources:定义容器的资源限制和请求limits:容器可以使用的最大资源量cpu: 500m:最多使用 0.5 个 CPU 核心memory: 100M:最多使用 100MB 内存
requests:容器启动时需要的最小资源量cpu: 500m:需要 0.5 个 CPU 核心memory: 100M:需要 100MB 内存
- 由于 requests 和 limits 的值相同,这个 Pod 的 QoS 等级是 Guaranteed
底层动作:
- kube-scheduler 根据 requests 的值来选择有足够资源的节点
- kubelet 为容器设置 Cgroups 限制,确保容器不会使用超过 limits 的资源
- 对于 CPU 限制,使用 CFS 调度器进行限制
- 对于内存限制,如果容器使用超过 limits 的内存,会被 OOM killer 杀死
坑点:
-
CPU 是可压缩资源,超过限制只会被限流,不会被杀死
-
内存是不可压缩资源,超过限制会被 OOM killer 杀死
-
一定要为所有容器设置资源限制,避免一个容器耗尽节点的所有资源
[root@k8s-master ~]# kubectl apply -f pod.yml
pod/test created[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
test 1/1 Running 0 3s[root@k8s-master ~]# kubectl describe pods test
Limits:
cpu: 500m
memory: 100M
Requests:
cpu: 500m
memory: 100M
Qos Class: Guaranteed
逐行解析:
- 显示了容器的资源限制和请求
Qos Class: Guaranteed确认了 Pod 的 QoS 等级
2.4.4.7 示例 7 容器启动管理
[root@k8s-master ~]# vim pod.ymlyaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: timinglee
name: test
spec:
restartPolicy: Always
containers:
- image: myapp:v1
name: myapp逐行解析:
restartPolicy: Always:Pod 的重启策略为总是重启- 可选值:Always、OnFailure、Never
- 默认值:Always
- 底层动作:kubelet 会监控容器的状态,如果容器退出,会根据重启策略决定是否重启
重启策略说明:
-
Always:无论容器以什么状态退出,都重启
-
OnFailure:只有当容器以非零退出码退出时才重启
-
Never:永远不重启
[root@k8s-master ~]# kubectl apply -f pod.yml
pod/test created[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test 1/1 Running 0 6s 10.244.2.3 k8s-node2[root@k8s-node2 ~]# docker rm -f ccac1d64ea81
逐行解析:
-
在 Pod 所在的节点上手动删除容器
-
由于重启策略是 Always,kubelet 会立即重启容器
[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test 1/1 Running 1 30s 10.244.2.3 k8s-node2
逐行解析:
RESTARTS 1表示容器已经重启了 1 次- 证明重启策略生效
2.4.4.8 示例 8 选择运行节点
[root@k8s-master ~]# vim pod.ymlyaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: timinglee
name: test
spec:
nodeSelector:
kubernetes.io/hostname: k8s-node1
restartPolicy: Always
containers:
- image: myapp:v1
name: myapp逐行解析:
nodeSelector:节点选择器,用于指定 Pod 运行在哪些节点上kubernetes.io/hostname: k8s-node1:选择 hostname 为 k8s-node1 的节点- 底层动作:
- kube-scheduler 在调度时会过滤出带有指定标签的节点
- 只在符合条件的节点中选择一个来运行 Pod
- 如果没有符合条件的节点,Pod 会一直处于 Pending 状态
坑点:
-
节点标签必须存在,否则 Pod 无法调度
-
不要硬编码节点名称,应该使用自定义标签来选择节点
[root@k8s-master ~]# kubectl apply -f pod.yml
pod/test created[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test 1/1 Running 0 21s 10.244.1.5 k8s-node1
逐行解析:
- Pod 确实运行在 k8s-node1 节点上
- 证明 nodeSelector 生效
2.4.4.9 示例 9 共享宿主机网络
[root@k8s-master ~]# vim pod.ymlyaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: timinglee
name: test
spec:
hostNetwork: true
restartPolicy: Always
containers:
- image: busybox:latest
name: busybox
command: ["/bin/sh","-c","sleep 100000"]逐行解析:
hostNetwork: true:使用宿主机的网络命名空间- 默认值:false
- 底层动作:
- 容器不创建自己的 Network Namespace
- 直接使用宿主机的网络接口和 IP 地址
- 容器可以看到宿主机的所有网络接口和路由表
坑点:
- 同一台宿主机上不能有多个使用 hostNetwork 的 Pod 监听同一个端口
- 容器可以访问宿主机的所有网络服务,存在安全风险
- 生产环境只有在特殊情况下才使用 hostNetwork
bash
[root@k8s-master ~]# kubectl apply -f pod.yml
pod/test created
bash
[root@k8s-master ~]# kubectl exec -it pods/test -c busybox -- /bin/sh
/ # ifconfig
cni0 Link encap:Ethernet HWaddr E6:D4:AA:81:12:B4
inet addr:10.244.2.1 Bcast:10.244.2.255 Mask:255.255.255.0
inet6 addr: fe80::e4d4:aaff:fe81:12b4/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1450 Metric:1
RX packets:6259 errors:0 dropped:0 overruns:0 frame:0
TX packets:6495 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:506704 (494.8 KiB) TX bytes:625439 (610.7 KiB)
docker0 Link encap:Ethernet HWaddr 02:42:99:4A:30:DC
inet addr:172.17.0.1 Bcast:172.17.255.255 Mask:255.255.0.0
UP BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
eth0 Link encap:Ethernet HWaddr 00:0C:29:6A:A8:61
inet addr:172.25.254.20 Bcast:172.25.254.255 Mask:255.255.255.0
inet6 addr: fe80::8ff3:f39c:dc0c:1f0e/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:27858 errors:0 dropped:0 overruns:0 frame:0
TX packets:14454 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:26591259 (25.3 MiB) TX bytes:1756895 (1.6 MiB)
flannel.1 Link encap:Ethernet HWaddr EA:36:60:20:12:05
inet addr:10.244.2.0 Bcast:0.0.0.0 Mask:255.255.255.255
inet6 addr: fe80::e836:60ff:fe20:1205/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1450 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:40 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:163 errors:0 dropped:0 overruns:0 frame:0
TX packets:163 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:13630 (13.3 KiB) TX bytes:13630 (13.3 KiB)
veth9a516531 Link encap:Ethernet HWaddr 7A:92:08:90:DE:B2
inet6 addr: fe80::7892:8ff:fe90:deb2/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1450 Metric:1
RX packets:6236 errors:0 dropped:0 overruns:0 frame:0
TX packets:6476 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:592532 (578.6 KiB) TX bytes:622765 (608.1 KiB)
/ # exit逐行解析:
- 在容器中执行 ifconfig 命令
- 可以看到宿主机的所有网络接口
- 包括 eth0(宿主机物理网卡)、docker0(Docker 网桥)、cni0(CNI 网桥)等
- 证明容器确实使用了宿主机的网络命名空间
企业级生产应用
千万级并发场景下的使用:
- YAML 文件是生产环境中唯一推荐的资源管理方式
- 所有 Kubernetes 资源都应该通过 YAML 文件定义,并纳入 Git 版本控制
- 在千万级并发场景下,YAML 文件需要经过严格的代码审查和测试
- 使用 Helm Chart 来管理复杂应用的 YAML 文件
- 使用 Kustomize 来管理不同环境的配置差异
进阶优化空间:
- 使用 Kustomize 来管理不同环境的配置
- 使用 Helm Chart 来打包和分发应用
- 使用 OPA Gatekeeper 来强制执行 YAML 文件的最佳实践
- 使用 kube-linter 来检查 YAML 文件的常见错误
- 使用 Argo CD 来实现 GitOps 风格的持续部署
- 为所有 YAML 文件添加注释,提高可维护性
课后防宕机指南
常见错误 1:YAML 文件缩进错误
- 报错信息 :
error: error parsing pod.yml: error converting YAML to JSON: yaml: line X: found character that cannot start any token - 排查思路 :
- 检查报错信息中指定的行号
- 确认使用的是 2 个空格缩进,而不是 Tab
- 确认所有列表项都以
-开头,后面跟一个空格 - 使用在线 YAML 验证工具检查语法
- 使用
kubectl apply --dry-run=client -f pod.yml提前验证
常见错误 2:容器名称或镜像名称错误
- 报错信息 :
Error: Invalid value: "": name is required或ErrImagePull - 排查思路 :
- 检查 YAML 文件中的容器名称和镜像名称
- 确认镜像名称和标签正确
- 确认节点能够访问镜像仓库
- 检查镜像仓库的认证信息
- 使用
kubectl describe pod <pod-name>查看详细错误信息