本篇博客介绍大模型的api调用方法及其常见的提示词用法。
主播这里使用的是阿里云平台的大模型api,新用户注册有很多免费额度可以白嫖。
一、阿里云百炼创建api
注册阿里云平台,进入阿里云百炼,进入api参考页面,按照教程即可创建自己的api-key: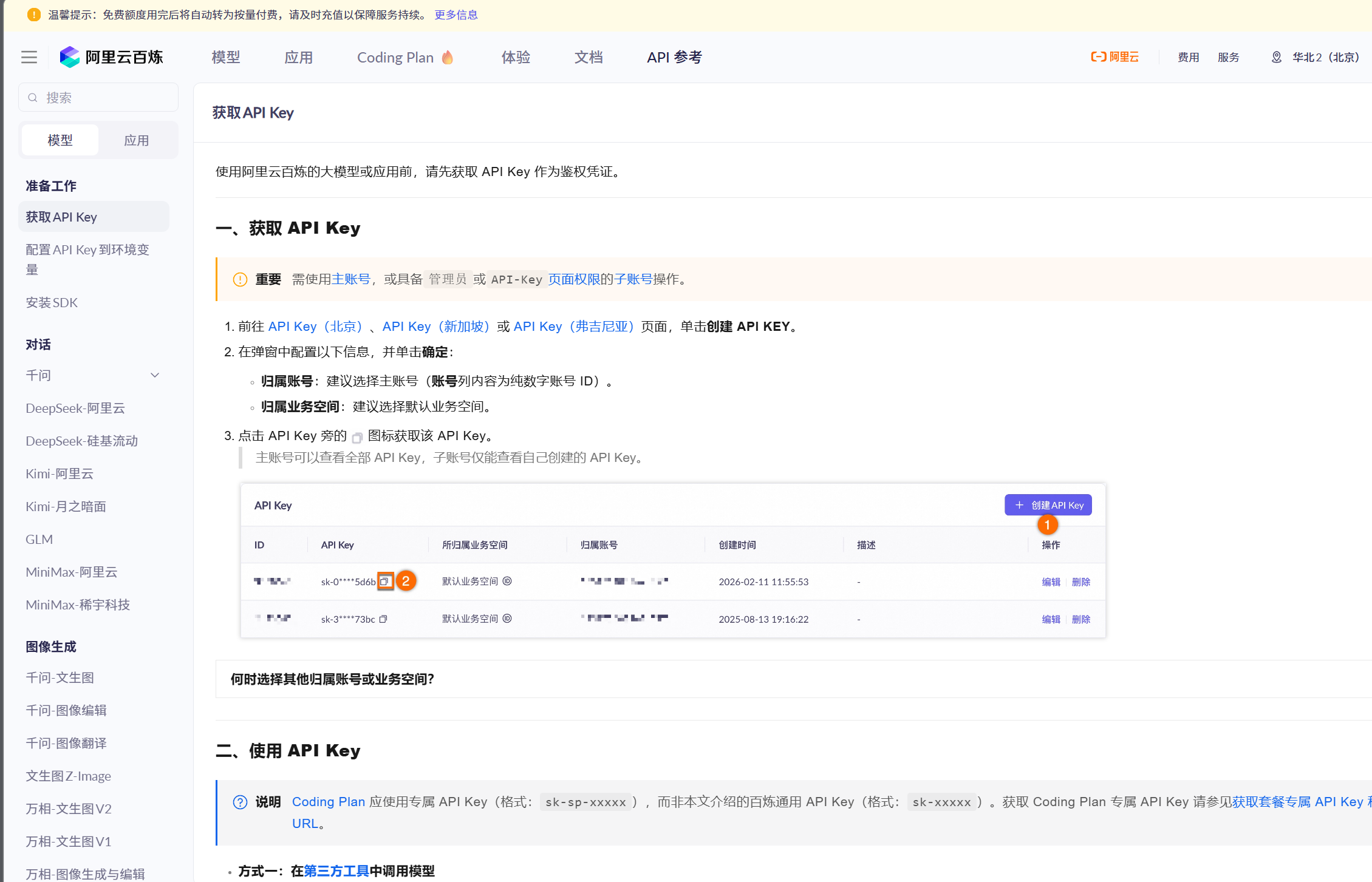
二、通过api-key调用大模型
1、基础调用模型进行对话
代码:
python
import os
from openai import OpenAI
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx"
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
# 模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
model="qwen-max",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你是谁?"},
]
)
print(completion.choices[0].message.content)注释:
1、运行之前需要安装openai的第三方库,因为openai是最早做大模型服务的公司,很多市面上模型的api都兼容他的api接口库,当然也可以使用阿里云自己的库: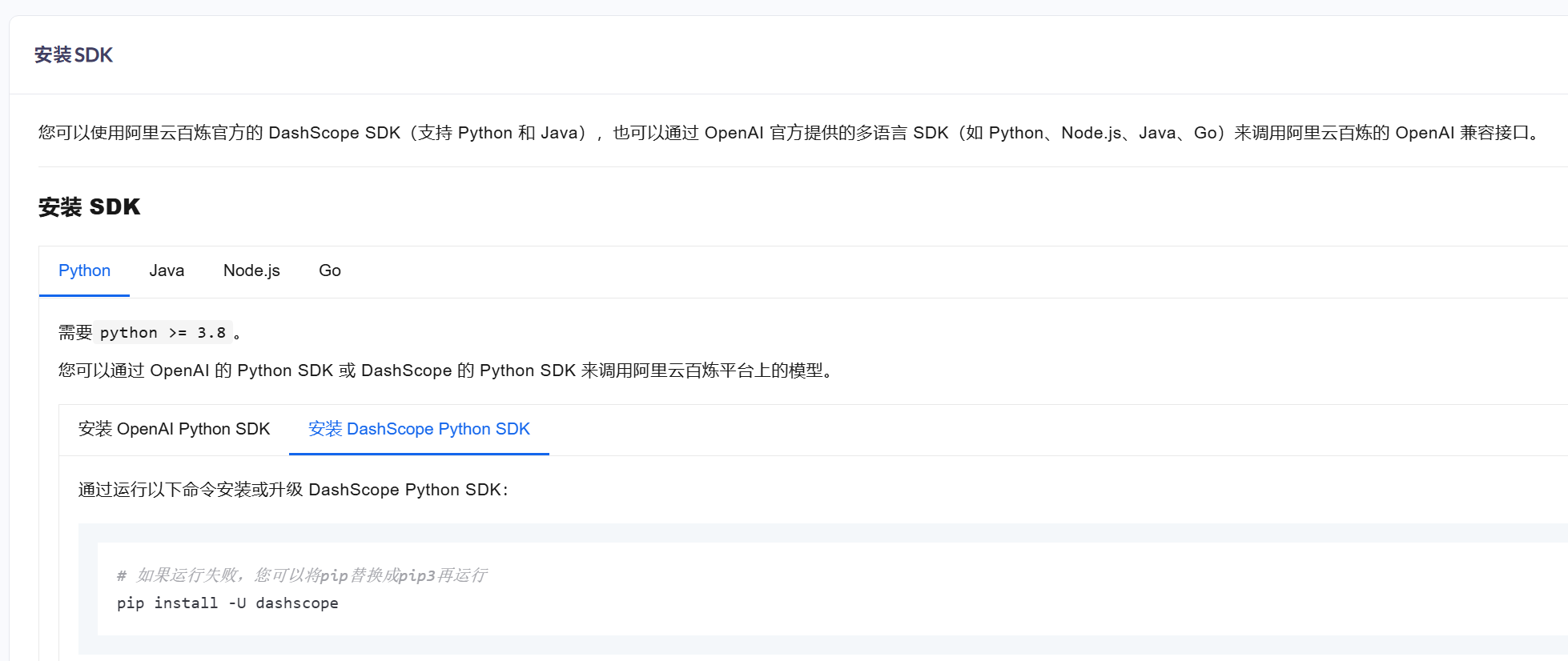
2、我这里把我的api-key设置成了环境变量,直接在代码中使用api-key当然也可以。
配置方法参考阿里云百炼: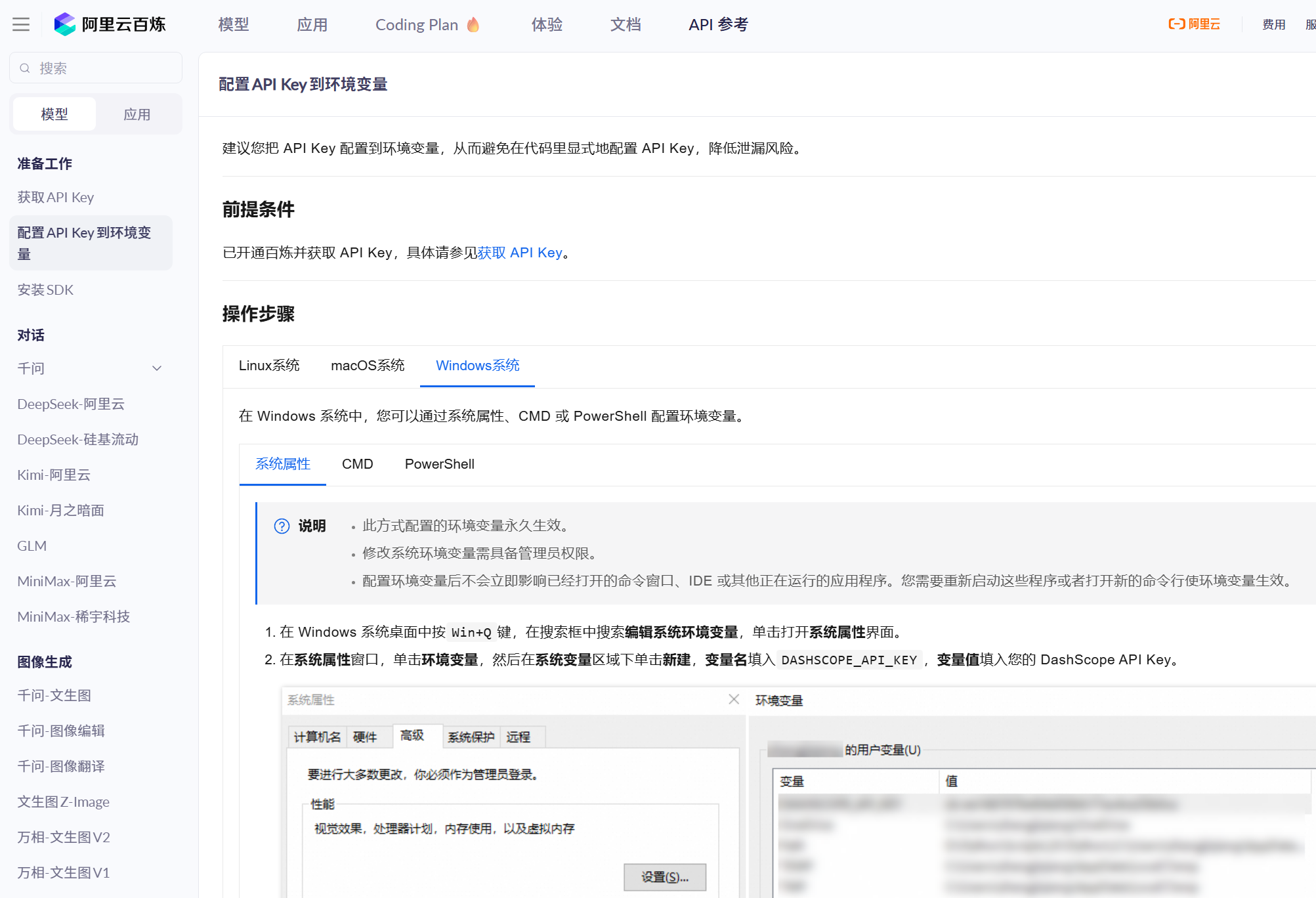
运行结果:
2、少样本提示
代码:
python
from openai import OpenAI
client = OpenAI(api_key="sk-0b717f29b6ee4852a2331cf1ffa30d4f",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
#来自用户的提示,不添加任何示范
response = client.chat.completions.create(
model="qwen-plus",
messages=[
{
"role": "user",
"content": "格式化以下信息:\n姓名 -> 张三\n年龄 -> 27\n学号 -> 001"
}
]
)
print(response.choices[0].message.content)
response = client.chat.completions.create(
model="qwen-plus",
messages=[
{
"role": "user",
"content": "格式化以下信息:\n姓名 -> 张三\n年龄 -> 17\n学号 -> 001" #来自用户的提示例子
},
{
"role": "assistant",
"content": "##学生信息\n- 学生姓名:张三\n- 客户年龄:17岁\n- 学号:001" #来自用户的理想回答例子
},
{
"role": "user",
"content": "格式化以下信息:\n姓名 -> 李四\n年龄 -> 12\n学号 -> 002"
},
{
"role": "assistant",
"content": "##学生信息\n- 学生姓名:李四\n- 客户年龄:12岁\n- 学号:002"
},
{
"role": "user",
"content": "格式化以下信息:\n姓名 -> 王五\n年龄 -> 13\n学号 -> 003"
}
]
)
print(response.choices[0].message.content)运行结果: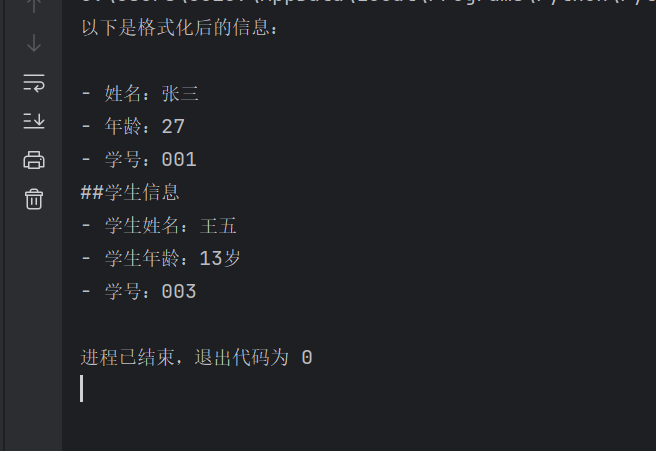
3、设置模型的参数
代码:
python
from openai import OpenAI
import os
client = OpenAI(api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
response = client.chat.completions.create(
model="qwen-plus",
messages=[
{
"role": "user",
"content": "生成一个豆瓣高分电影清单,包含至少20部电影,每个电影名称打上书名号,每个物品之间用顿号进行分隔,例如:《肖申克的救赎》、《这个杀手不太冷》、《泰坦尼克号》"
}
],
max_tokens=300,
frequency_penalty=-2
)
print(response.choices[0].message.content)
response = client.chat.completions.create(
model="qwen-plus",
messages=[
{
"role": "user",
"content": "生成一个豆瓣高分电影清单,包含至少20部电影,每个电影名称打上书名号,每个物品之间用顿号进行分隔,例如:《肖申克的救赎》、《这个杀手不太冷》、《泰坦尼克号》"
}
],
max_tokens=300,
frequency_penalty=2
)
print(response.choices[0].message.content)注释:
max_tokens=300:限制生成的最大令牌数(可简单理解为 "字符数",300 足够容纳 20+ 部电影名称);frequency_penalty=-2:核心对比参数 ------ 频率惩罚,取值范围通常是[-2, 2]:- 负值(如
-2):鼓励重复 / 保守输出,模型会优先生成大众熟知、重复度高的热门高分电影(比如《肖申克的救赎》《霸王别姬》等经典爆款); - 你可以理解为:"惩罚值为负 = 奖励重复,模型懒得想新的,只挑最常见的"。
- 负值(如
还有很多参数,可自行查阅
运行结果:
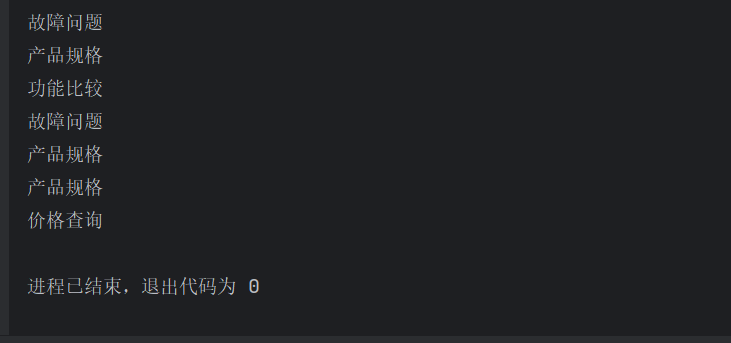
4、文本分类
代码:
python
from openai import OpenAI
client = OpenAI(api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
def get_openai_response(client, prompt, model="qwen-plus"):
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
)
return response.choices[0].message.content
q1 = "我刚买的智能手表无法同步我的日历,我应该怎么办?"
q2 = "手表的电池可以持续多久?"
q3 = "品牌的手表和ABC品牌的手表相比,有什么特别的功能吗?"
q4 = "安装智能手表的软件更新后,手表变得很慢,这是啥原因?"
q5 = "智能手表防水不?我可以用它来记录我的游泳数据吗?"
q6 = "我想知道手表的屏幕是什么材质,容不容易刮花?"
q7 = "请问手表标准版和豪华版的售价分别是多少?还有没有进行中的促销活动?"
q_list = [q1, q2, q3, q4, q5, q6, q7]
category_list = ["产品规格", "使用咨询", "功能比较", "用户反馈", "价格查询", "故障问题", "其它"]
classify_prompt_template = """
你的任务是为用户对产品的疑问进行分类。
请仔细阅读用户的问题内容,给出所属类别。类别应该是这些里面的其中一个:{categories}。
直接输出所属类别,不要有任何额外的描述或补充内容。
用户的问题内容会以三个#符号进行包围。
###
{question}
###
"""
# 遍历问题列表 q_list 中的每一个问题
for q in q_list:
# 使用 prompt 模板对当前问题进行格式化处理
# classify_prompt_template 是一个字符串模板,其中包含占位符 {categories} 和 {question}
# 这里将 category_list 中的类别用中文顿号连接,并替换模板中的 {categories}
# 同时将当前问题 q 替换模板中的 {question}
formatted_prompt = classify_prompt_template.format(
categories=",".join(category_list), # 将类别列表用中文顿号连接成一句话
question=q # 当前问题文本
)
# 调用 OpenAI API 获取对格式化后 prompt 的响应
# client 是预先初始化好的 OpenAI 客户端实例
# get_openai_response 是自定义函数,用于封装 OpenAI API 调用
response = get_openai_response(client, formatted_prompt)
# 打印 API 返回的响应结果
print(response)运行结果: