理解硬件
磁盘最基本的层次概念
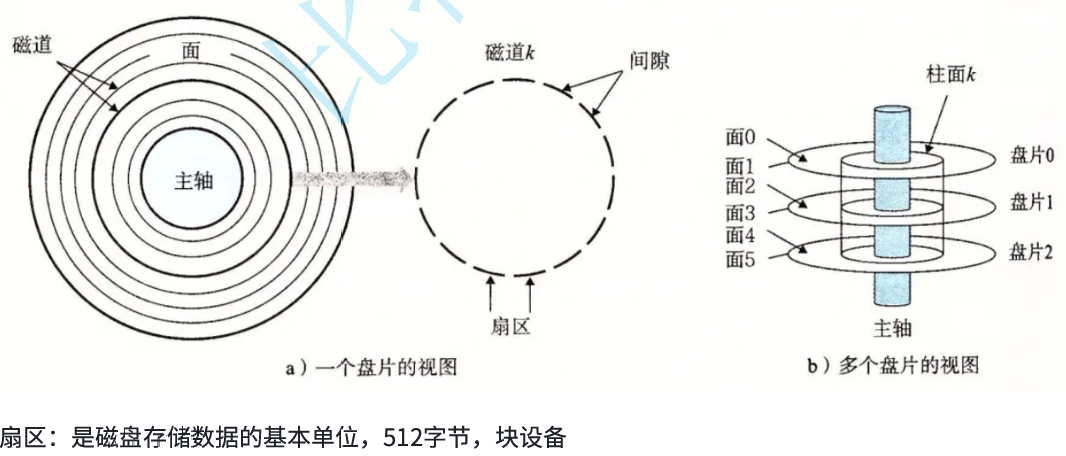
CHS地址定位 ⽂件=内容+属性都是数据,⽆⾮就是占据那⼏个扇区的问题!能定位⼀个扇区了,能不能定位多个扇 区呢?
柱⾯(cylinder),磁头(head),扇区(sector),显然可以定位数据了,这就是数据定位(寻址)⽅ 式之⼀,CHS寻址⽅式。
• 扇区是从磁盘读出和写⼊信息的最⼩单位,通常⼤⼩为 512 字节。
-
8 个 512B 扇区 = 4KB
-
1MB = 1024 * 1024 B
• 磁头(head)数:每个盘⽚⼀般有上下两⾯,分别对应1个磁头,共2个磁头
• 磁道(track)数:磁道是从盘⽚外圈往内圈编号0磁道,1磁道...,靠近主轴的同⼼圆⽤于停靠磁 头,不存储数据
• 柱⾯(cylinder)数:磁道构成柱⾯,数量上等同于磁道个数
• 扇区(sector)数:每个磁道都被切分成很多扇形区域,每道的扇区数量相同
• 圆盘(platter)数:就是盘⽚的数量 • 磁盘容量=磁头数× 磁道(柱⾯)数× 每道扇区数× 每扇区字节数
• 细节:传动臂上的磁头是共进退的(这点⽐较重要,后⾯会说明)
CHS 和 LBA,只要理解,不必深算
-
CHS:老式按柱面/磁头/扇区定位
-
LBA:现代更常用的线性编号定位
只要扇区有编号,那么块也一定能编号。
-
把磁盘看成一维数组
-
下标就是 LBA
-
每个元素是一个扇区
这个思路非常重要。它想表达的是: 磁盘在逻辑上可以被看成线性编号的空间。既然扇区能编号,那块由多个扇区组成,也就能编号。
比如:
-
1 个块 = 8 个扇区
-
那么块号和 LBA 之间就能换算:
-
已知 LBA,可算 块号 = LBA / 8
-
已知 块号,可算块内各扇区的大致范围
块不是虚构出来的,它最终一定落在一串连续扇区上。
-
现代系统更偏向逻辑编号
-
这和后面 block、inode 编号思路一致
引⼊⽂件系统
"块"概念
硬盘是典型的"块"设备,操作系统读取硬盘数据的时候,其实是不会⼀个个扇区地读取,这样 效率太低,⽽是⼀次性连续读取多个扇区,即⼀次性读取⼀个"块"(block)。
硬盘的每个分区是被划分为⼀个个的"块"。⼀个"块"的⼤⼩是由格式化的时候确定的,并且不可 以更改,最常⻅的是4KB,即连续⼋个扇区组成⼀个"块"。"块"是⽂件存取的最⼩单位。
总结:
-
块是文件系统操作磁盘的基本单位
-
块通常由多个扇区组成
-
常见块大小是 4KB
-
常见扇区大小是 512B
-
所以常见情况下 1 block = 8 sectors
-
逻辑上磁盘可以按 LBA 编号
-
块号和扇区编号之间可以换算
-
硬盘是块设备,文件系统通常按块而不是按字节管理磁盘。
-
块是文件系统存取数据的基本单位。
-
一个块通常由多个连续扇区组成。
-
常见情况下:1 block = 4KB = 8 * 512B sector
-
扇区有 LBA 编号,块也可以由扇区编号推导出来。
引入"分区"概念
磁盘不是只能整体使用,通常会被切分成多个区域,每个区域就是一个分区
柱⾯是分区的最⼩单位,我们可以利⽤参考柱⾯号码的⽅式来进⾏分区,其本质就是设置每个区的起 始柱⾯和结束柱⾯号码。
分区的本质就是在磁盘逻辑空间里划出一段连续范围。
**- 分区是对磁盘逻辑空间的切分。
- 文件系统通常创建在分区上。
- 不同分区可以分别格式化、分别挂载、分别管理。
- 后续 inode、block、super block 等概念通常都要放在"某个分区内"去理解。**
引入 inode 概念
⽂件 = 数据 + 属性
我们使⽤ls -l 的时候看到的除了看到⽂件名,还能看到⽂件元 数据(属性)。
cpp
[root@localhost linux]# ls -l
-rwxr-xr-x. 1 root root 7438 "9⽉13 14:56" a.out
-rw-r--r--. 1 root root 654 "9⽉14:56" test.c每⾏包含7列:
- 权限 - 硬链接数 - 所有者 - 所属组 - 大小 - 时间 - inode 号
文件 = 数据 + 属性。这里的"属性",在 Linux 文件系统里就主要由 inode 负责保存。
注意: 文件名不在 inode 里。文件名以后由目录来保存,目录负责建立"文件名 -> inode号"的映射
⽂件数据都储存在"块"中,那么很显然,我们还必须找到⼀个地⽅储存 ⽂件的元信息(属性信息),⽐如⽂件的创建者、⽂件的创建⽇期、⽂件的⼤⼩等等。这种储存⽂件 元信息的区域就叫做inode,中⽂译名为"索引节点"。
Linux下⽂件的存储是属性和内容分离存储的 ,Linux下,保存⽂件属性的集合叫做inode,⼀个⽂件,⼀个inode,inode内有⼀个唯⼀ 的标识符,叫做inode号
总结:
-
Linux 下文件的属性信息保存在 inode 中。
-
inode 是索引节点,是文件元信息的数据结构。
-
inode 中保存权限、大小、时间、链接数、数据块位置等信息。
-
每个文件都有 inode 号。
-
文件内容和属性是分离存储的。
-
文件名不在 inode 中,文件名与 inode 的对应关系由目录维护。
文件系统要先解决"空间怎么组织"和"文件属性怎么管理"这两个问题,然后才能谈文件名和路径。
具体来说:
-
块 解决"磁盘空间按什么单位管理"
-
分区 解决"在哪个范围内建立文件系统"
-
inode 解决"文件属性和索引信息存在哪"
ext2 ⽂件系统
宏观认识
我们想要在硬盘上储⽂件,必须先把硬盘格 式化为某种格式的⽂件系统,才能存储⽂件。⽂件系统的⽬的就是组织和管理硬盘中的⽂件。
ext 文件系统是在分区内部,用一套固定的数据结构,把"空间管理、文件属性、文
件内容、文件名、路径访问"全部组织起来。
ext2 不会把整个分区当成一团混乱空间来管理,而是把整个分区切成多个 Block
Group。
Block Group
文件系统内部重复出现的一个"管理分区小单元"。ext2 的思路是:把整个分区切成很多个小组,每组内部都有自己的管理信息和数据区域。
块组内部构成
-
超级块 Super Block
-
GDT Group Descriptor Table
-
块位图 Block Bitmap
-
inode 位图 Inode Bitmap
-
inode 表 Inode Table
-
数据块 Data Block
一个完整流程:
-
文件系统先要知道自己总体长什么样
-
再要知道每个组内部结构长什么样
-
再要知道哪些块空闲、哪些 inode 空闲
-
再要有地方真正存 inode
-
再要有地方真正存文件内容
超级块(Super Block)
超级块保存整个文件系统的全局信息。注意是"整个文件系统"的信息,不是某一个文件的信息。
里面大概会记录:
-
inode 总数
-
block 总数
-
空闲 block 数
-
空闲 inode 数
-
block 大小
-
每组多少 block
-
每组多少 inode
-
文件系统状态
-
最近挂载时间
-
最近写入时间
-
inode 大小等
-
Super Block = 文件系统全局元数据
-
记录总量、空闲量、block/inode 参数、状态、时间等
-
超级块极其重要,因此有冗余备份
GDT(Group Descriptor Table)
它记录什么?比如:
-
这个块组的 block bitmap 在哪
-
inode bitmap 在哪
-
inode table 在哪
-
这个组还有多少空闲 block
-
这个组还有多少空闲 inode
块组描述符表,描述块组属性信息,整个分区分成多个块组就对应有多少个块组描述符。
如果说: 超级块是"全局总账本",那 GDT 就是:每个块组的导航表。GDT 管每个块组的细节位置和资源情况。GDT = Block Group 的描述信息表
块位图(Block Bitmap)
BlockBitmap中记录着DataBlock中哪个数据块已经被占⽤,哪个数据块没有被占⽤
-
Block Bitmap:记录数据块空闲/占用状态
-
一个 bit 对应一个 block
-
用 0/1 记录这个块是否被占用
inode 位图(Inode Bitmap)
-
Inode Bitmap:记录 inode 是否已分配
-
创建文件 = 分发inode + 分发block
它记录:
-
哪些 inode 已经分配给文件
-
哪些 inode 还空闲
节点表(Inode Table)
inode 不仅是概念,而且在磁盘上有固定、可定位的存储区域。
-
Inode Table 存放 inode 结构本体
-
inode 大小通常固定
-
知道 inode 号后可以定位到 inode 表中的具体位置
-
inode 号的意义依赖于所在分区/文件系统
-
Inode Table = inode 的磁盘存储区
-
inode号在分区内有意义,不可脱离分区单独谈
Data Block
这里正式落地:
-
普通文件内容,比如代码、文本、图片字节流
-
最终都放在数据块中
所以一个文件可以理解成两层:
-
inode:记录文件属性、大小、权限、数据块位置等
-
data block:真正存放文件内容
-
文件内容存储在 Data Block
-
inode 记录的是内容在哪里
-
文件本质上是 inode 和数据块共同构成的
-
Data Block:存真正的文件内容
-
inode:存属性 + 内容位置
inode 和 datablock 映射
不必细究,知道了解即可
inode 是文件属性和文件内容之间的桥梁。
inode 里面保存了"这个文件内容在哪些块里"的映射信息。也就是说,inode 不只是存权限、大小,它还像一张索引表:
-
第一个内容块在哪
-
第二个内容块在哪
-
后面块在哪
于是系统流程就是:
-
先通过文件名找到 inode 号
-
再从 inode 表中找到 inode
-
再从 inode 中找到对应的数据块列表
-
最后读出内容
总结:
-
inode 中有 data block 的映射关系
-
系统读文件时,不是直接靠文件名找内容,而是靠 inode 找 block
-
文件名只是入口,inode 才是核心索引
-
inode 的核心职责之一:记录文件内容所在的数据块位置
-
读文件流程本质:文件名 -> inode号 -> inode -> data blocks
目录与文件名
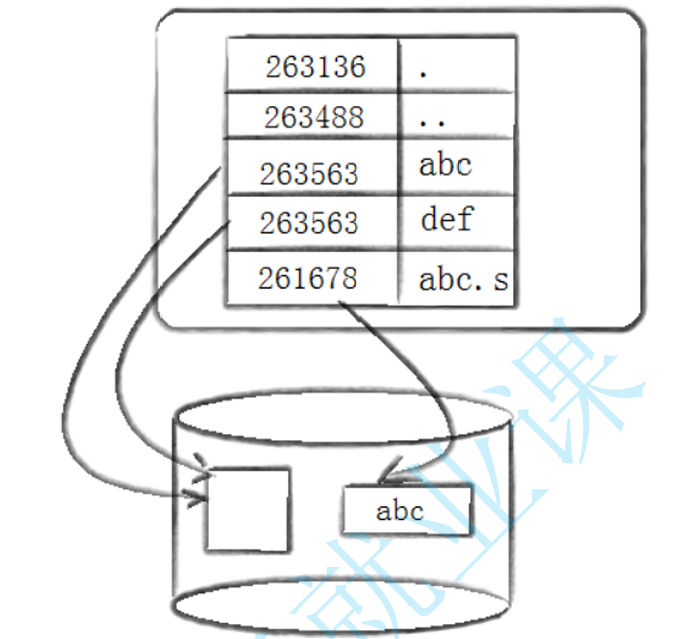
目录的本质作用,不是"装文件内容",而是维护文件名到 inode 号的映射。
文件名不是存在 inode 里的。而是放在目录里。 而且目录本身也是文件。 目录文件里保存的是一条条目录项,每个目录项大致就是: 文件名 ,对应 inode 号
-
目录也是文件
-
目录中保存目录项
-
目录项建立"文件名 -> inode号"的对应关系
-
文件名和 inode 分开存储
-
目录的本质:维护文件名与 inode 号的映射关系
-
文件名不在 inode 中
路径解析
路径解析本质上是:逐级目录查表的过程。路径访问本质是目录递归查找 inode。
路径缓存
如果每次路径解析都重新从磁盘一级一级找,会非常慢,所以内核会做缓存。
-
路径查找可能被缓存加速
-
缓存的是路径/目录项相关结果
-
这是为了减少频繁磁盘访问
-
路径缓存用于加速目录项查找和路径解析
挂载分区
它回答了一个很现实的问题:
如果 inode、block、super block 这些都只在某个分区里有意义,那 Linux 为什么
看起来像只有一棵统一目录树?
答案就是:**挂载 mount。**挂载的本质,记成一句话:把某个分区上的文件系统接到某个目录上。
挂载的本质意义:Linux 的统一目录树,不是因为只有一个文件系统,而是因为多个文件系统通过挂载拼接到了同一棵树上。即:把一个文件系统接入目录树
-
文件系统通常建立在分区或设备上
-
挂载后才能方便纳入 Linux 统一目录树
-
挂载点是目录
-
用户看到的是统一树,底层可能是多个文件系统拼起来的
总结:
ext 文件系统整个访问过程:
-
磁盘被切成分区
-
某个分区上建立 ext 文件系统
-
ext 文件系统把分区划成多个 Block Group
-
每个块组里有超级块/GDT/位图/inode表/数据块
-
文件内容存 data block
-
文件属性和内容位置存 inode
-
目录维护"文件名 -> inode号"
-
路径解析逐级查目录找到目标 inode
-
挂载把这个文件系统接入 Linux 统一目录树
ext 文件系统的本质,就是在分区上用一套分组、索引、映射和目录结构,把原始磁盘空间变成"可按文件名访问的文件世界"。
-
ext2 按 Block Group 管理分区
-
Super Block:全局元数据
-
GDT:每组描述信息
-
Block Bitmap:块分配状态
-
Inode Bitmap:inode 分配状态
-
Inode Table:inode 存储区
-
Data Block:文件内容存储区
-
inode -> data block 映射
-
目录维护"文件名 -> inode号"
-
路径解析逐级查找
-
挂载把多个文件系统接入统一目录树
软硬连接
这一章到底想表达什么?:在 Linux 里,文件名和文件本体不是一回事。
更准确地说:
-
真正代表文件本体的是 inode
-
文件名只是目录里的一个映射项
-
所以可以出现:
-
多个文件名指向同一个 inode
-
一个文件去指向另一个文件的路径
这就分别对应: 硬链接 软链接
所以这一章真正要讲清楚的是:"名字"和"文件"到底是什么关系。
硬链接
硬链接就是让多个文件名对应同一个 inode:
cpp
ln abc def这条命令不是"复制一个新文件"。
它做的事情是:
-
原来有个名字叫 abc
-
现在再增加一个名字叫 def
-
这两个名字都指向同一个 inode
所以本质上是:
abc -> inode 100
def -> inode 100
这就是硬链接。 删除一个硬链接,不一定删除文件本身
inode 的硬链接数会增加创建硬链接前,可能是:Links: 1创建后,可能变成: Links: 2。这也是为什么 ls -l 的第二列会变化。
软链接
⾯解释⼀下三个时间: • Access最后访问时间 • Modify⽂件内容最后修改时间 • Change属性最后修改时间
软链接是一个独立的新文件,这个文件里保存的是目标文件的路径或名字信息。
cpp
ln -s abc def这时 def 就是一个软链接。 它和硬链接最大的区别是:软链接不会和目标共享 inode。 也就是说:
abc -> inode 100
def -> inode 200
def 自己有自己的 inode。它不是 abc 的第二个名字。 它只是"指向 abc 的一个特殊文件"。
软链接和硬链接看起来都像"指向另一个文件",但底层完全不是一回事。
硬链接是:直接共享 inode
软链接是:通过名字/路径去引用目标
所以它们的层次不一样:硬链接是 inode 级别,软链接是路径级别
总结:- 软链接是一个独立文件
-
软链接有自己的 inode
-
软链接通过路径引用目标
-
软链接不共享目标文件的 inode
-
目标删除后,软链接可能悬空失效
软硬连接对⽐
| 对比项 | 硬链接 (Hard Link) | 软链接 (Symbolic Link) |
|---|---|---|
| 1. inode 是否相同 | 相同 inode | 不同 inode |
| 2. 本质是什么 | 多个文件名映射到同一个 inode | 一个独立文件 ,其内容是目标文件的路径信息 |
| 3. 删除目标文件后的表现 | 删除其中一个文件名,只要该inode还有其它链接(文件名),文件数据依然存在。 | 若目标文件被删除或移动,软链接将失效(成为"悬空链接")。 |
| **4. 是否是真正的"同一个文件"** | 是,它们指向同一个inode,是同一个文件对象的多个别名。 | 不是,它是一个独立的文件,通过路径指向另一个文件。 |
| 5. 原因/引用层次 | 在 inode 层 建立引用。 | 在 文件路径(目录)层 建立引用。 |
硬链接的用途
硬链接更适合:
-
给同一个文件提供多个名字入口
-
不复制内容而共享同一个文件实体
-
从理解文件系统角度,帮助你看清"文件名和 inode 的关系"
软链接在实际中更常用。适合做:
-
快捷入口
-
版本切换
-
目录映射
-
兼容旧路径
-
给一个深路径起一个短名字
例如实际系统里很常见:
-
某个 current 指向某个版本目录
-
某个命令路径是另一个位置的软链接
因为软链接本质上是"路径级别的引用",所以它非常灵活。
总结:
Linux 中文件名只是目录中的映射项,真正的文件核心是 inode;硬链接和软链接分别从 inode 层和路径层证明了这一点。
-
硬链接 = 多个文件名 -> 同一个 inode
-
软链接 = 一个独立文件 -> 保存目标路径
-
硬链接共享 inode,软链接不共享 inode
-
删除硬链接只是删一个名字映射
-
软链接目标删掉后可能失效
-
文件名不在 inode 中,目录负责维护名字与 inode 的关系
-
真正标识文件的是 inode,不是文件名。
-
硬链接是多个文件名对应同一个 inode。
-
软链接是保存目标路径的独立文件。
-
硬链接不创建新的文件本体。
-
软链接有自己的 inode。
-
硬链接和软链接的根本区别在于:一个是 inode 级引用,一个是路径级引用。