前言
在真实的业务系统中,SQL 往往远比教科书示例复杂。随着业务逻辑的不断演进,CTE、多层子查询、窗口函数、聚集计算被广泛用于组织查询逻辑,极大地提升了 SQL 的可读性与表达能力。然而,这类复杂 SQL 也给查询优化器带来了严峻挑战------尤其是在 JOIN 条件无法有效提前过滤数据 的场景下,性能问题往往成为系统瓶颈。
本文聚焦于一个在真实客户场景中高频出现的问题:复杂查询中 JOIN 条件下推失败所导致的性能瓶颈,并系统介绍一种基于代价模型的连接条件下推(Cost-based Join Predicate Pushdown)的设计思路与实现方案。
一、问题背景
1.1 客户场景中的典型痛点
在许多客户的业务系统中,SQL 通常遵循如下模式来组织查询逻辑:
- 在子查询或 CTE 中完成大量预处理计算(去重、聚集、窗口函数等)
- 在外层再与其他表进行 JOIN,并施加高选择性的过滤条件
以如下查询为例:
sql
SELECT *
FROM (
SELECT DISTINCT * FROM s1
) s
JOIN s2 ON s.a = s2.a
WHERE s2.b = 3;从业务语义上看,这条 SQL 完全正确;但从执行角度审视,却隐藏着严重的性能隐患:
- 子查询
s需要对s1进行全量扫描并去重,产生庞大的中间结果集 - 外层
s2.b = 3的高选择性过滤条件,无法反向约束子查询的扫描范围 - 后续的 JOIN、聚集等操作全部建立在"大数据量"之上,性能急剧下降
根本问题不在 JOIN 本身,而在于过滤发生得太晚。
1.2 业界普遍面临的两大难点
将 JOIN 条件下推到子查询内部,看似是一个直观有效的优化方向,但在数据库内核层面,这一问题远比想象中复杂,主要体现在以下两个维度:
1.2.1 语义安全性(Equivalence)
JOIN 条件下推的本质,是改变谓词生效的位置。若处理不当,极易破坏 SQL 的原有语义,尤其在以下场景中风险较高:
- 聚集操作(GROUP BY)
- 窗口函数(Window Function)
- DISTINCT / UNION
- 含有副作用或非确定性函数的表达式
因此,并非所有 JOIN 条件都可以安全下推,必须建立严格的等价性判定机制。
1.2.2 代价评估(Cost)
即便语义上等价,下推也未必"划算":
- 下推后可能触发参数化执行路径
- 当外层基数较大时,子查询可能被重复执行 N 次
- 极端情况下,性能反而出现灾难性下降
这意味着:JOIN 条件下推不仅要"能推",还要"值得推"。
二、传统方案的局限
面对上述场景,传统优化器通常采用如下执行策略:
- 完整执行子查询:扫描基表,执行 DISTINCT / UNION / 窗口函数等复杂操作
- 生成大规模中间结果集
- 再与外层表进行 JOIN,最后施加过滤条件
这一策略的致命缺陷在于:外层的高选择性 JOIN / WHERE 条件,无法反向约束子查询的扫描范围。当子查询计算复杂、数据量庞大时,这条执行路径几乎必然成为性能瓶颈。
三、金仓数据库基于代价的连接条件下推设计
在金仓数据库 V009R002C014 版本中,我们针对上述问题引入了一套 "等价性 + 代价模型" 双重约束 的连接条件下推机制。整体设计思路可概括为两个核心步骤:
3.1 能不能推:等价性判定(Equivalence)
在这一阶段,优化器的目标并非"尽可能多地下推",而是只识别绝对安全的下推机会:
- 分析子查询结构,判断是否满足语义等价条件
- 对包含聚集、窗口函数、UNION 等复杂结构的子查询进行约束性判定
- 将 JOIN 条件拆分为:可参数化部分(依赖外层列)与子查询内部列
通过等价性校验的 JOIN 谓词,将被改写为参数化过滤条件,注入到子查询的扫描或过滤阶段。
这一步回答的是:"推下去之后,结果会不会变?"
3.2 值不值推:代价模型(Cost)
通过等价性校验后,优化器并不会立即选择下推,而是进入代价评估阶段:
- 评估下推前后的完整执行路径
- 对比子查询扫描行数与中间结果规模的变化
- 量化参数化执行带来的重复计算成本
- 选择整体代价最低的执行计划
若代价模型判断下推收益不足,甚至可能引发性能回退,优化器将自动放弃下推,转而选择其他执行路径。
这一步回答的是:"推下去之后,真的会更快吗?"
详细工作流程如下图所示: 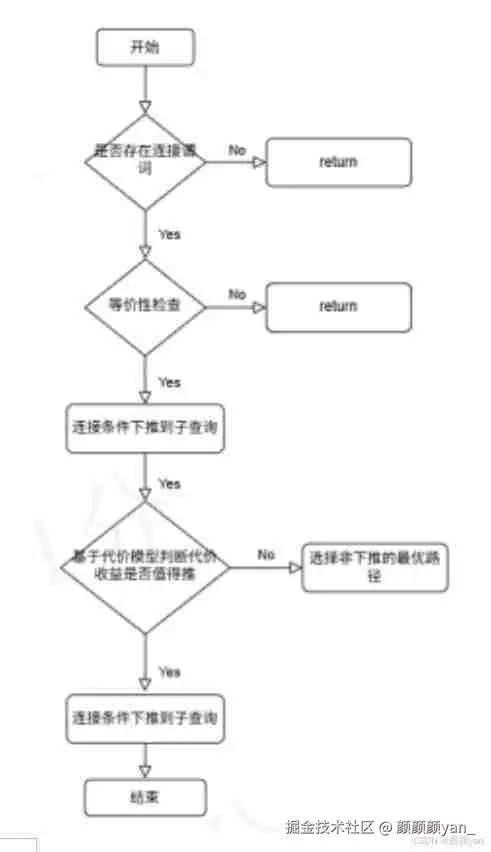
四、效果验证
4.1 最小化用例
sql
SELECT * FROM (SELECT DISTINCT * FROM s3) s3, s1
WHERE s1.s1a = s3.s3a;测试结果对比:
| 场景 | 执行策略 | 执行时间 |
|---|---|---|
| 未下推 | 子查询全表扫描 + 去重,再与 s1 JOIN | ~84ms |
| 下推后 | 子查询扫描阶段即被 JOIN 条件裁剪 | ~0.14ms |
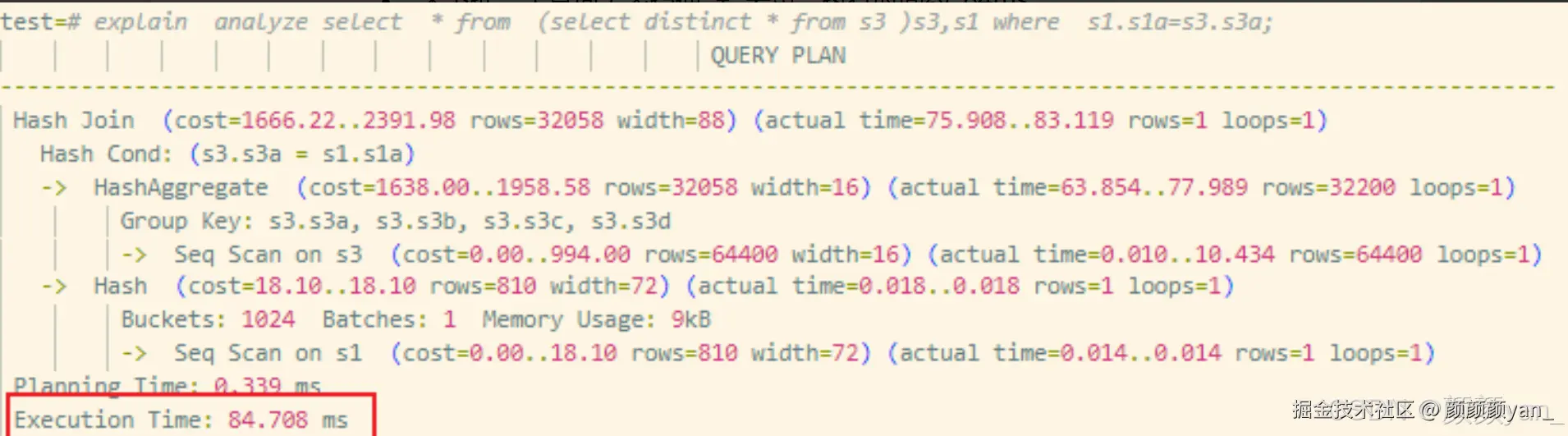
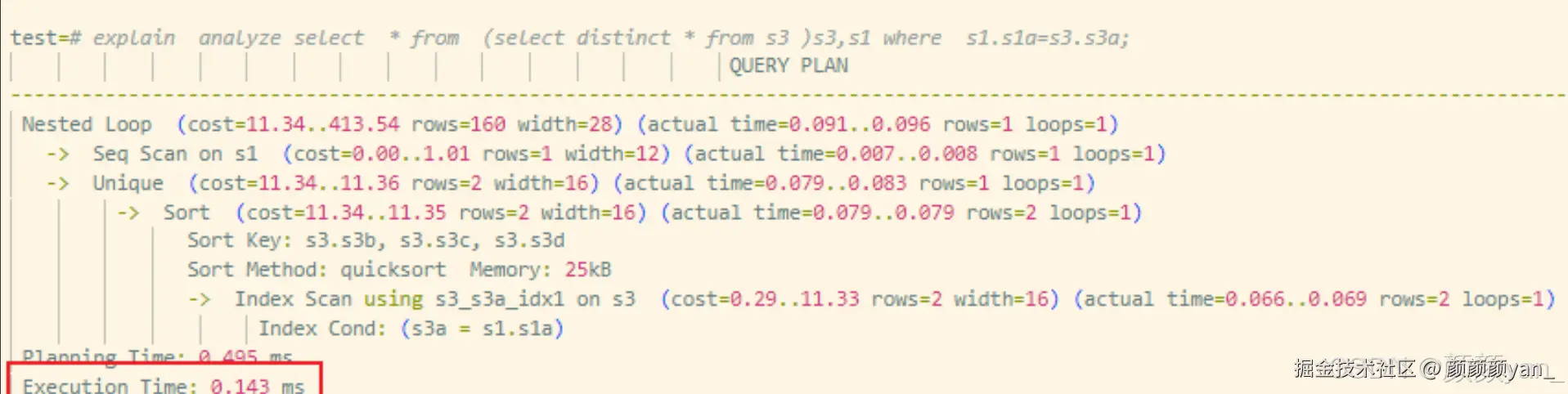
中间结果规模显著收缩,性能提升幅度达数量级。
作为对比,我们同样测试了 D 厂商(不支持下推)在相同场景下的表现:
sql
EXPLAIN SELECT /*+use_nl(s3 s1)*/ *
FROM (SELECT DISTINCT * FROM s3) s3, s1
WHERE s1.s1a = s3.s3a;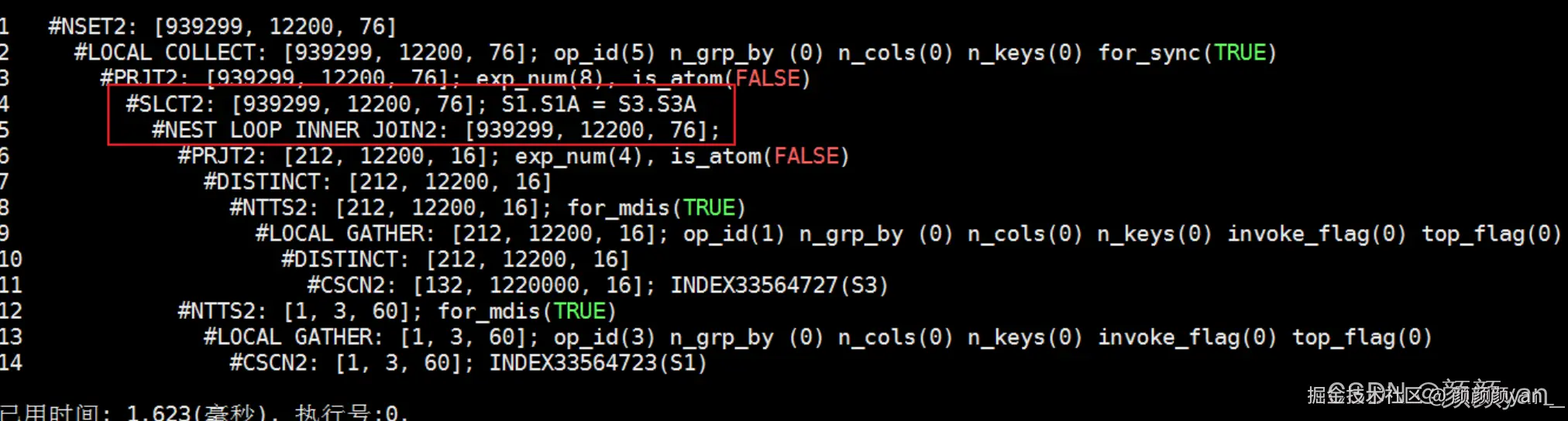
执行时间约 1.62ms,与金仓下推后的 0.14ms 相比,差距明显。
4.2 复杂场景验证
sql
EXPLAIN ANALYZE
SELECT *
FROM (
SELECT * FROM (
SELECT DISTINCT * FROM s3
UNION
SELECT DISTINCT * FROM s3 a
) s3, s1
WHERE s1.s1d = s3.s3a
) s
JOIN (
SELECT * FROM (
SELECT s3a, SUM(s3b) OVER (PARTITION BY s3a) s3d FROM s3
) s3, s1
WHERE s1.s1a = s3.s3a
) j ON s.s3d = j.s3a;该 SQL 涵盖 UNION、DISTINCT、窗口函数、多层子查询等复杂结构,是典型的高难度优化场景。
未下推时的执行路径:
- 处理内层 UNION 查询,左右两侧分别对基表
s3进行去重全扫描,生成大规模结果集 A - 结果集 A 与基表
s1进行 JOIN,生成中间结果集 B - 执行右侧子查询,对
s3进行分组并计算窗口函数,生成大规模结果集 C - 结果集 C 与基表
s1进行 JOIN,生成中间结果集 D - 最终对两个大规模中间结果集 B 与 D 执行 JOIN
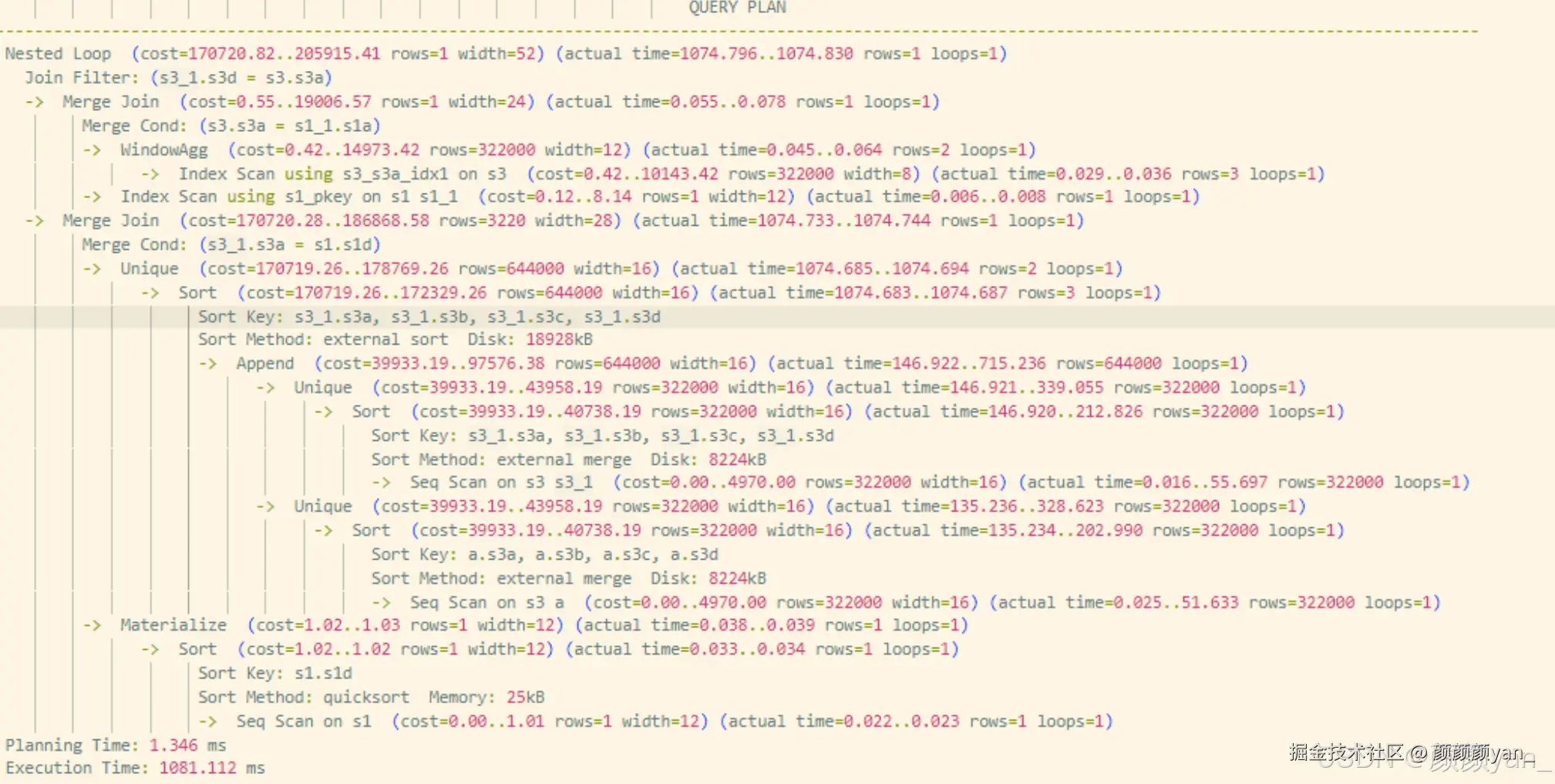
整个过程中,子查询几乎全程依赖全表扫描,I/O 与计算开销极高,执行时间约 1081ms。
下推后的执行路径:
- JOIN 条件提前注入子查询扫描阶段,数据在读取时即被裁剪
- 多个子查询由"全量扫描"转为"选择性扫描",中间结果集规模大幅缩减
- 后续 JOIN 操作建立在小数据集之上,执行效率显著提升
执行时间从 1081ms 降至 0.23ms ,性能提升超过 4000 倍 。 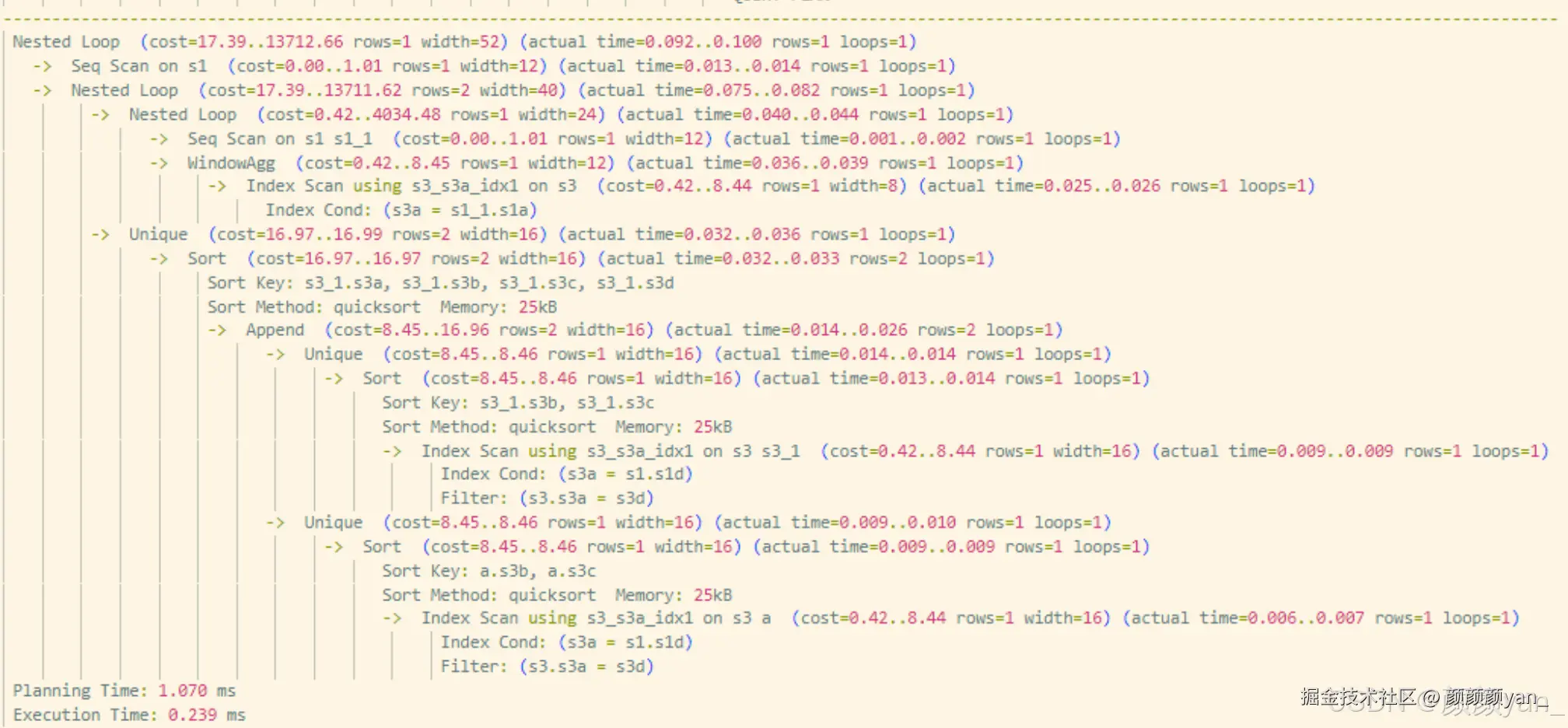
五、总结
在复杂查询优化领域,连接条件下推并非一个简单的规则改写问题,而是一个典型的成本驱动型优化问题:
- 只做规则改写、不考虑代价,可能引发灾难性的性能回退
- 只关注代价、不保证语义等价,则会直接破坏 SQL 的正确性
通过 "等价性保障 + 基于代价的决策" 的组合设计,金仓数据库实现了:
- 在语义安全的前提下,最大化 JOIN 条件的提前过滤能力
- 显著压缩子查询阶段的数据扫描量与中间结果规模
- 在复杂 SQL 场景中获得数量级乃至万倍级的性能提升
这类优化对于 OLAP、混合负载以及复杂报表型查询场景尤为关键,也将是未来查询优化器持续演进的重要方向之一。