在 AI 辅助编程逐渐成为主流的今天,业界已经达成了一个共识:Spec Coding(规格驱动开发)是提升 AI 代码质量的必经之路。
然而,横亘在开发者面前的现实却很骨感。一提到 Spec Coding,大家脑海中浮现的往往是复杂、沉重的文档维护负担。
以近期在 GitHub 上备受关注的开源框架 OpenSpec 为例。尽管它已经极力标榜自己"流式而非僵化 (fluid not rigid)",并试图通过一套 Slash 命令来简化流程,但当你真正使用它时会发现:为了添加一个功能,你依然需要生成并维护一个包含 proposal.md、specs/、design.md 和 tasks.md 四个 Markdown 文件的专属文件夹。
这种"文档驱动"的刻板印象,导致绝大多数开发者依然停留在最原始的阶段------直接把成百上千行的源码扔给 AI,然后祈祷它能像资深同事一样瞬间领悟系统的精髓。
结果显而易见:AI 经常产生幻觉,写出无法运行的代码,或者在复杂的逻辑迷宫中迷失方向。
我们需要打破"Spec Coding = 重型工程"的诅咒。本文将探讨一种极简主义且与众不同的落地方案------我们称之为 Zero-Doc Spec Coding(零文档契约)。它不要求你引入任何额外的工具链,也不强迫你学习一套生硬的"提示词语言"去讨好 AI。它只要求你回归开发者的本能:写好结构化的测试断言。
一、 困境与破局:从"文档驱动"到"极简意图"
1.1 上下文窗口的"信噪比"危机
要理解为什么我们需要 Spec Coding,首先得理解大语言模型 (LLM) 的局限性。LLM 本质上是一个"无状态"的函数,它的输出质量完全取决于输入的质量。
当你把整个项目的源代码一股脑地塞进 AI 的上下文窗口时,你实际上是在制造一场"信息灾难"。生产级的代码库中充满了实现细节 (Implementation Details) :繁琐的数据库连接配置、冗长的错误处理逻辑、各种 Helper 函数的定义......这些对于 AI 理解"你要做什么"来说,绝大部分都是噪声 (Noise)。
当噪声淹没了真正的业务逻辑(信号 Signal),AI 的注意力就会被分散。简单地说,把原始代码直接丢给 AI,就像是在嘈杂的菜市场里试图通过喊叫来沟通复杂的数学问题------沟通效率极其低下,且极易出错。
1.2 极简解法:Zero-Doc(零文档)
传统的 Spec Coding 之所以难以落地,正是因为它走入了一个误区:要求开发者在代码之外,再维护一套复杂的文档或模型。像 OpenSpec 这样的方案虽然解决了"从无到有"的对齐问题,但却无法逃避"文档腐化"的宿命。 写文档存在沉重的维护负担,且极易过时。
这正是 Zero-Doc Spec Coding 与众不同的地方:我们不维护任何静态的 Markdown 注释或文档,我们只维护活的断言。 文档是死的,单测可以跟着系统一起迭代,是活的。
将 PRD 直接转化为结构化的测试断言,这就是我们的极简着陆点:
- 输入:PRD(业务意图)
- 锚点:结构化测试代码(Human in the loop 的绝对审查领域)
- 产物:实现代码(可抛弃的衍生品)
二、 核心方法论:构建"海平面"的高保真契约
传统的 Spec Coding 常常要求"频繁且有意的压缩 (Frequent Intentional Compression)"来为 AI 提供一份提炼过的说明书。而在 Zero-Doc 的理念下,我们将这种"压缩"直接具象化为测试用例的编写。
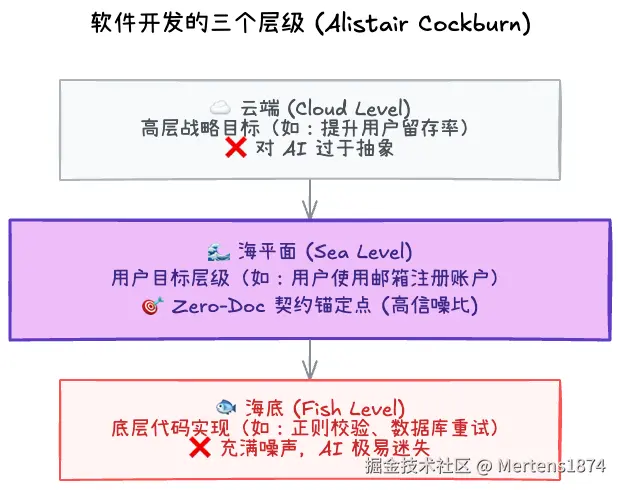
为了实现这一点,我们借鉴了软件工程先驱 Alistair Cockburn 提出的"海平面用例 (Sea-Level Use Case)"概念。
2.1 锚定海平面
想象一下,软件开发就像一片海洋:
- 云端 (Cloud Level):是高层的战略目标(如"提升用户留存率"),这对 AI 写代码来说太抽象。
- 海底 (Fish Level):是底层的具体函数实现(如"数据库连接重试逻辑"),这对 AI 理解意图来说太琐碎且充满了噪音。
- 海平面 (Sea Level) :恰好是用户目标层级(如"用户想要重置密码")。
Spec Coding 强调将我们的意图锚定在"海平面"上。在这个层级,我们既不谈论虚无缥缈的愿景,也不纠缠于具体的代码实现,而是清晰地描述用户试图通过系统达成什么具体的、可观测的目标。
2.2 结构化降噪:目录即地图,用例即契约
自然语言是模糊的,常常充满歧义。为了让 AI 精准理解海平面用例,我们需要一种多层级的结构化降噪方案:
- 宏观结构化(目录层):用测试文件的物理目录和动名词命名,构建出系统的能力地图。
- 微观结构化(代码层) :在具体的测试文件中,将断言分为
@MSS(主成功场景)和@Extensions(扩展流程),将非结构化的需求转化为一份格式严整的测试模板。
2.2.1 宏观降噪:构建系统能力地图
在真实的生产级项目(例如一个典型的电商或内容平台)中,整个 specs 测试目录不再按底层技术组件(如 Controller、Service)划分,而是严格按照"用户目标(用例)"组织。
打开项目的 specs 目录,你看到的不是冷冰冰的代码文件,而是清晰的业务动作:
💡 命名注记 :在标准的用例(Use Case)命名规范中,强烈建议使用动名词或动宾结构 (如
RegisteringUser或CreateOrder)来命名。因为用例描述的是"用户试图达成的具体目标和动作过程",而不是一个静态的系统功能模块或状态。这能更好地向 AI 和开发者传递动态的业务行为意图。
text
apps/system/specs/
├── ClaimTask.spec.ts # 认领任务
├── ConfigurePaymentTable.spec.tsx # 配置支付表格
├── CreateOrder.spec.tsx # 创建订单
├── DeleteUserAccount.spec.tsx # 注销账户
├── ManageUserData.spec.ts # 管理用户数据
├── ManageSettlements.spec.tsx # 管理结算列表
├── PerformPaymentAction.spec.tsx # 执行支付操作
├── ReviewContentMachine.spec.ts # 内容机器审核
├── SearchTasks.spec.ts # 搜索任务
└── ViewIncomeSummary.spec.tsx # 查看收益概览
... (共数十个独立业务用例)基于这种平铺的用例文件,我们可以用 AI 生成 一份高信噪比的系统能力地图(索引文件 README_SPECS.md)。
为什么一定要生成这份索引?因为真实的业务是有层级的,而文件系统如果是平铺的,随着用例增多会变得难以维护。用一份独立的 Markdown 索引来管理业务的模块与层级,可以极大地降低用例的管理成本。 不管上层的业务模块如何调整、重组,底层平铺的用例文件结构都不需要大改,只需更新索引即可。
当团队的新人或者 AI 想要了解"系统到底能做什么"时,不需要去翻阅语焉不详且早已过时的文档,只需看一眼这份地图:
markdown
## 核心业务用例 (System Capabilities)
### 用户入驻与认证 (User Onboarding)
* **[管理用户资料数据 (ManageUserData)](./specs/ManageUserData.spec.ts)**:管理用户资料拉取、回填及多步表单验证。
* **[内容机器审核 (ReviewContentMachine)](./specs/ReviewContentMachine.spec.ts)**:用户提交材料的机器审核流程,支持自动识别与信息比对。
### 财务与结算系统 (Settlement System)
* **[管理结算单列表 (ManageSettlements)](./specs/ManageSettlements.spec.tsx)**:结算列表主页面,整合搜索、批量操作和创建入口。
* **[执行支付操作 (PerformPaymentAction)](./specs/PerformPaymentAction.spec.tsx)**:处理结算单的审批、绑定、付款、删除等业务动作。你可以清晰地看到,这份地图和底层目录共同构成了一份永远不会过时的、活的 PRD。所有的命名都遵循动名词组,业务意图昭然若揭。
2.2.2 微观降噪:结构化测试契约
当我们从宏观地图点击进入任意一个具体的用例文件(例如"用户注册"),就会进入微观的契约层。
在传统方式下,这通常是一个充满高噪声的过程:开发者直接把一个几百行的 React 组件丢给 AI,里面混杂着 UI 样式、副作用管理和 DOM 事件,AI 极易迷失在这些技术细节中。
而在 Zero-Doc 方式下,我们将获得极高的信噪比。我们将业务契约直接写入测试文件的断言中。你可以看到更底层的结构化契约:
typescript
// specs/RegisteringUser.spec.ts
describe('@UseCase RegisteringUser: 用户使用邮箱和密码注册新账户', () => {
// @MSS: Main Success Scenario (主成功流程)
it('@MSS-1: 提交有效信息应成功创建账户并返回成功消息', async () => {
const result = await register('test@example.com', 'StrongPass123!');
expect(result.status).toBe('success');
});
// @Extensions: 异常与分支流程
it('@Ext-2a: 邮箱格式无效应拒绝并报错', async () => {
const result = await register('invalid-email', 'StrongPass123!');
expect(result.error).toBe('InvalidEmail');
});
});三、 辨析:Zero-Doc 契约 vs 普通单元测试
这种结构化的做法常常会引来一种质疑:"这不就是要求我多写点单元测试,然后把它们集中存放在一个测试文件夹里吗?这和普通的单测有什么区别?"
这是一个非常关键的问题。表面上看它们都使用了测试框架,但本质上,Zero-Doc 契约是披着测试外衣的"可执行文档(Executable Specification)"。
两者的核心差异主要体现在三个方面。
首先是视角的本质不同。 普通单测是自下而上的"海底视角",关注实现细节(如 test_validate_email_regex),用来验证"代码写得对不对"。而 Zero-Doc 契约是自上而下的"海平面视角",它屏蔽底层技术,只关注业务意图(如 RegisteringUser),用来验证"系统做的事情对不对"。
其次是信息架构的不同。 普通单测往往平铺直叙,像一堆缺乏业务关联的零散零件。而 Zero-Doc 契约通过宏观的目录索引和微观的 @MSS 标签,将非结构化的需求翻译成了一张高信噪比的蓝图,它是用测试框架的壳,装了领域驱动设计(DDD)的魂。
最后是生命周期的不同。 普通单测是代码的附庸,底层重构时往往跟着报废。但在 Zero-Doc 的理念下,契约是 AI 生成代码的输入源(Prompt 的具象化)。只要业务需求没变,无论底层代码被 AI 如何重写,这份契约都坚如磐石。在 Zero-Doc 的世界里,业务代码才是可以随时被 AI 抛弃和重写的衍生品,而这份测试契约,是系统唯一的、永不过时的资产。一旦契约确立,AI 便能顺藤摸瓜,生成具体的实现代码。
四、 全场景落地:统一的工作流闭环
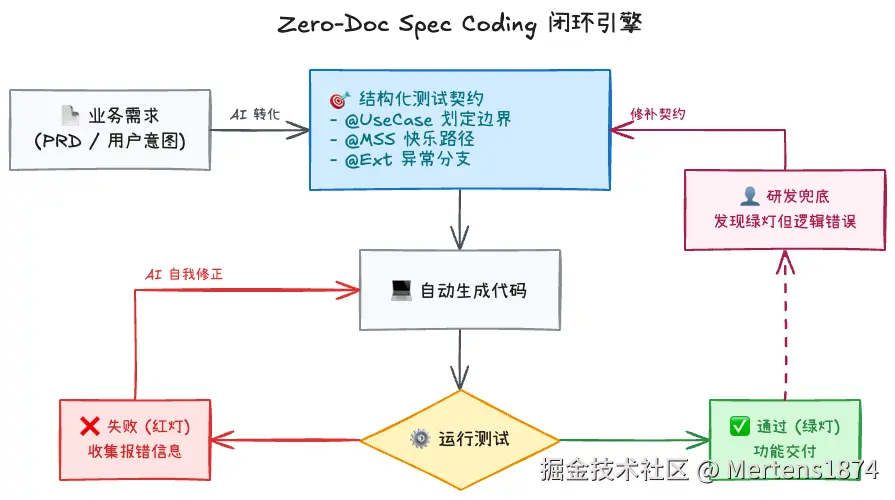
这种方式最强大的地方在于,它不仅仅是文档,更是可执行的测试。这形成了一个自动化的反馈循环。
4.1 闭环引擎:AI 的自我修正
- Spec -> 测试 :AI 读取 PRD,自动生成包含
@UseCase、@MSS和@Extensions标签的测试用例。 - 测试 -> 实现:AI 编写实现代码以通过上述测试。
- 自我修正:如果实现代码有误,测试会失败(红灯)。AI 收到报错信息后,会在"测试围栏"内自动调整逻辑,直至测试通过(绿灯)。
4.2 遗留系统治理 (Reverse Engineering)
面对没有文档的"屎山"代码,我们采用增量逆向策略:
- 逆向:让 AI 扫描老模块源码,反向生成测试断言。
- 固化:将断言保存为测试文件,形成"行为快照"。
- 重构:有了测试作为安全网,你可以大胆地进行重构。
4.3 新需求开发 (New Feature)
面对冗长的 PRD 文档:
- 转化:把 PRD 喂给 AI,让它自动提取并生成结构化的单测断言。
- 审查:开发者作为 human in the loop,审查测试用例是否覆盖了所有的 @MSS 和 @Extensions。
- 生成:AI 自动生成实现代码。
4.4 需求变更 (Legacy Change)
当业务规则发生变化(例如密码长度从 8 位改为 12 位):
- 定位:找到对应的测试文件。
- 修改:仅修改测试断言中的期望值。
- 修复:运行测试,AI 发现不匹配,自动定位并修复实现代码。这是一次精准的外科手术。
这本质上是一种用例驱动 (Use Case Driven) 的 Zero-Doc Spec Coding 模式。我们用宏观目录划定系统边界,用 @UseCase 圈定业务场景,用 @MSS 和 @Extensions 穷尽业务分支。这个闭环彻底取代了传统的文档维护。
回望过去,为了对抗软件的熵增,开发者们常常需要小心翼翼、如履薄冰地设计各种复杂的系统架构(比如洋葱架构、六边形架构),试图用层层抽象来保护核心业务逻辑。但在 AI 编程时代,这种沉重的"防御性设计"可能不再是首选项。当 AI 拥有了强大的实现能力,我们不再需要过度设计复杂的代码架构,我们只需要设计好这套清晰的目录结构和契约蓝图就可以了。 只要契约在,系统随时可以推倒重来。
五、 终极图景:迎接"代码虚无主义"
如果明天 AI 模型进化了,上下文窗口无限大,推理能力强到能秒懂 10 万行代码,我们还需要写 Spec 吗?
如果真到了那一天,连程序员都不需要了。但在那一天到来之前,我们必须为系统建立坚固的"护栏"。
这并不是一场伪装成"AI 最佳实践"的 TDD 复兴运动,而是确立一种全新的人机协作范式。当你准备好让断言完全接管业务逻辑的描述,你也就准备好接受这种"代码虚无主义"------实现代码变得不再重要,重要的是你定义的测试契约。
结语
告别僵死的文档,拥抱鲜活的断言。Zero-Doc Spec Coding 以 @MSS 与 @Extensions 为契约,确立了 AI 协作的唯一事实来源 。这不仅是开发门槛的降低,更是生产关系的重塑:人类定义意图,AI 交付实现。
附录:开箱即用的 Zero-Doc Skill
为了让你立刻体验 Zero-Doc 的威力,你可以直接在 Trae/Cursor 中安装我开源的 Skill,一键让你的 AI 编程助手掌握这套方法论:
bash
npx skills add MertensMing/zero-doc-spec-coding-assistant