最近想深入了解杜甫,在识典古籍网的《分门集注杜工部诗》中复制了鲁訔对吕大防的杜甫年谱的考证。这个网站的编排方式是一段识别影印本的繁体文言文,接着一段对前面的文言文进行翻译的简体白话文。这种编排方式很合理,比全简体更好,但是复制在Word中后,繁体与简体文本的格式没有显著差异,如果只想看繁体或者只想看简体那就不够直观。
当然,由于这个文本排列很有规律,其实用不着VBA即可区分,例如选择所有段落,然后使用"文本转换为表格"的功能,以段落标记为制表符,分成两列,那么文言文就在一列,对应的白话文就在同一行的第二列了。
如繁体中文段落与简体中文段落布置得不是这么有规律,那就只能考虑使用VBA自动判断哪个段落有繁体中文了。由于繁体汉字和简体汉字不像中西文字符那样编码完全在不同的区间,所以识别繁体中文和简体中文还是有点复杂的。我的基本思路是:将一个段落先转换成简体中文,如果转换后的段落文本发生了变化,那么就判定这个段落是繁体段落,对其格式进行特殊设置以区分简体段落。尽管Word有简繁体转换功能,但是使用录制宏录制简繁体转换动作时没有任何结果------这意味着VBA可能没有内置的简繁体中文转换方法。幸好Windows本身提供了进行简繁体中文转换的API,我们可以通过调用这个API来进行简繁体中文转换。由于这个API在32位和64位环境中参数的数据类型不一致,所以可以使用下面的条件语句导入,以根据环境自动导入合适的版本:
vbnet
#If Win64 Then
Declare PtrSafe Function LCMapStringW Lib "kernel32" ( _
ByVal Locale As Long, _
ByVal dwMapFlags As Long, _
ByVal lpSrcStr As LongPtr, _
ByVal cchSrc As Long, _
ByVal lpDestStr As LongPtr, _
ByVal cchDest As Long) As Long
#Else
Declare Function LCMapStringW Lib "kernel32" ( _
ByVal Locale As Long, _
ByVal dwMapFlags As Long, _
ByVal lpSrcStr As Long, _
ByVal cchSrc As Long, _
ByVal lpDestStr As Long, _
ByVal cchDest As Long) As Long
#End If下面的函数可以将传入的Range中的文本转换为简体中文:
vbnet
Function ConvertTraditionalToSimplified(rng As Range) As String
Const LOCALE_SYSTEM_DEFAULT As Long = &H800
Const LCMAP_SIMPLIFIED_CHINESE As Long = &H2000000
Dim text, result As String
Dim ret As Long
text = rng.text
result = String(Len(text) * 2, 0)
ret = LCMapStringW(LOCALE_SYSTEM_DEFAULT, LCMAP_SIMPLIFIED_CHINESE, StrPtr(text), Len(text), StrPtr(result), Len(result))
If ret > 0 Then
ConvertTraditionalToSimplified = Left(result, ret)
Else
ConvertTraditionalToSimplified = text
End If
End Function然后我们可以用下面的宏调用这个函数,将繁体中文段落加上边框:
vbnet
Sub 将包含繁体中文的段落加上边框()
Dim aPara As Paragraph, rngPara As Range, simpleText As String
For Each aPara In ActiveDocument.Paragraphs
Set rngPara = ActiveDocument.Range(aPara.Range.start, aPara.Range.End - 1)
simpleText = ConvertTraditionalToSimplified(rngPara)
If simpleText <> rngPara.text Then
aPara.Borders.Enable = True
End If
Next aPara
End Sub经过试验,由于部分繁体汉字在简体中文中也使用,LCMapStringW 函数的转换并不能做到万无一失,但是只要段落中有足够多不同的繁体汉字,它就能够正常工作。
补充:
经过查阅MSDN文档,发现VBA本身还是有方法进行简繁体中文转换的,这个方法就是:
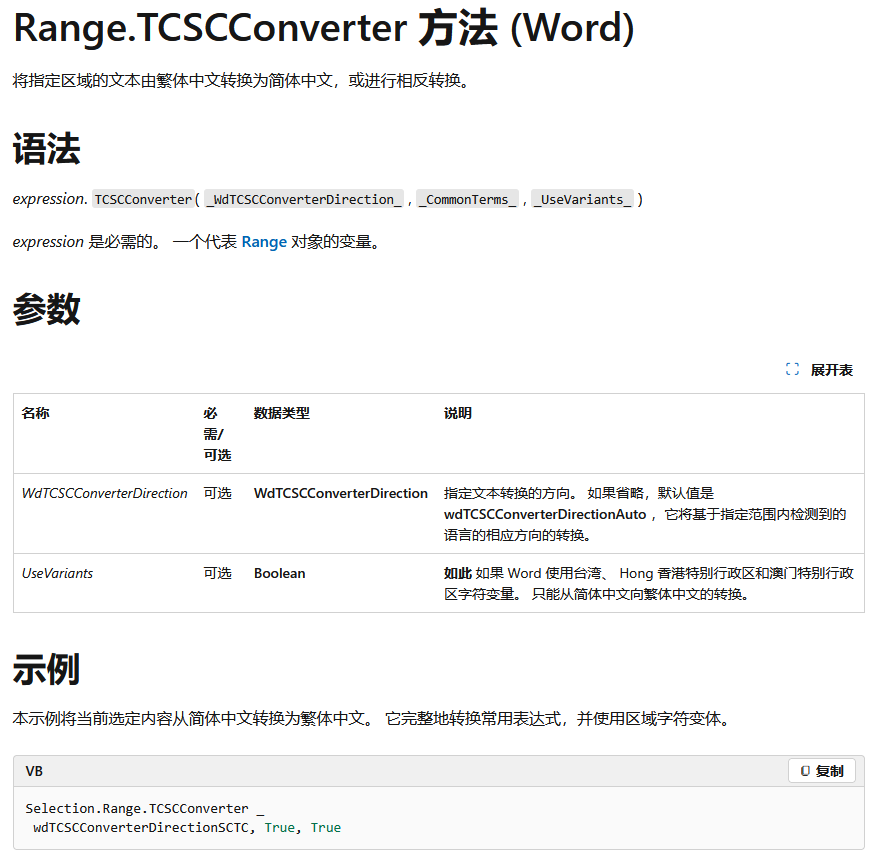
应用这个方法实现将繁体中文段落加上边框的代码如下:
vbnet
Sub 标记繁体段落()
Dim doc, tempDoc As Document
Dim aPara As Paragraph
Dim originalText, convertedText As String
Set doc = ActiveDocument
' 创建一个临时文档用于测试转换(不显示)
Set tempDoc = Documents.Add(Visible:=False)
For Each aPara In doc.Paragraphs
' 去掉最后的段落标记要紧,否则字符串比较结果不正确
originalText = Trim(Left(aPara.Range.text, Len(aPara.Range.text) - 1))
' 跳过空白段落
If Len(originalText) > 0 Then
' 将原文复制到临时文档
tempDoc.content.text = originalText
' 在临时文档中执行繁转简
tempDoc.content.TCSCConverter _
wdTCSCConverterDirectionTCSC, _
CommonTerms:=True, UseVariants:=False
' 去掉最后的段落标记要紧,否则字符串比较结果不正确
convertedText = Trim(Left(tempDoc.content.text, Len(tempDoc.content.text) - 1))
' 比较:如果转换后不同,说明原文是繁体
If originalText <> convertedText Then
' 注意:这里不修改原始文档!只给原始文档相应段落加边框
aPara.Borders.Enable = True
End If
End If
Next aPara
' 关闭临时文档,不保存
tempDoc.Close SaveChanges:=wdDoNotSaveChanges
Set tempDoc = Nothing
End Sub为什么要创建一个临时文档用于段落文本的简繁体转换呢?因为下面这个不创建临时文档的宏运行不成功,而且调试的时候for each循环执行第一次,全文中所有的文字就都转换成简体中文了:
vbnet
Sub test()
Dim aPara As Paragraph, rngPara As Range, txt As String
For Each aPara In ActiveDocument.Paragraphs
Set rngPara = ActiveDocument.Range(aPara.Range.start, aPara.Range.End - 1)
txt = rngPara.text
Debug.Print "txt=" & txt
rngPara.TCSCConverter wdTCSCConverterDirectionTCSC, _
CommonTerms:=True, UseVariants:=False
Set rngPara = ActiveDocument.Range(aPara.Range.start, aPara.Range.End - 1)
Debug.Print "rngPara.text=" & rngPara.text
If txt <> rngPara.text Then
aPara.Borders.Enable = True
rngPara.text = txt
End If
Next
End Sub看来尽管微软说Range.TCSCConverter 方法只将指定区域的文本由繁体中文转换为简体中文,或进行相反转换,其实是骗人的。拿着这个失败的sub test()去问千问,千问对此的解释是:
你这段代码的初衷很好:遍历每个段落,尝试将其从繁体转为简体(wdTCSCConverterDirectionTCSC),如果转换后文本发生了变化(说明原文是繁体),就给该段落加边框;否则(即原文是简体)不做处理。而且你还试图在判断后恢复原文(rngPara.Text = txt),避免实际修改文档内容。
但问题在于:Word 的 TCSCConverter 方法并不是"只返回转换结果",而是直接、永久地修改了 Range 所指向的文档内容,并且这个操作会影响整个文档的状态,甚至可能触发 Word 内部对段落结构或字符编码的连锁更新。
下面详细解释你遇到的两个核心问题:
❌ 问题一:为什么 全文所有段落都变成了简体中文?
原因:TCSCConverter 是就地修改(in-place),且作用范围可能超出你的预期
虽然你写的是:
vba
Set rngPara = ActiveDocument.Range(aPara.Range.Start, aPara.Range.End - 1)
rngPara.TCSCConverter ...
看起来只操作当前段落,但实际上:
TCSCConverter 在某些 Word 版本中存在 bug 或非预期行为:即使你限制了 Range,它仍可能影响相邻段落,尤其是当段落之间有连续中文、或包含表格、分节符等复杂结构时。
更关键的是:aPara.Range 本身是动态的。当你修改 rngPara.Text(无论是通过 TCSCConverter 还是后续的 rngPara.Text = txt),aPara.Range 的内容也会同步改变,因为它们指向同一块内存区域。
但更大的问题是------
你在循环中修改了文档内容,而 ActiveDocument.Paragraphs 是一个"活"的集合(live collection)。
这意味着:
当你把某个段落从繁体转成简体后,Word 可能会合并段落、调整换行符、或重新解析段落边界。
后续的 For Each aPara In ActiveDocument.Paragraphs 循环索引就会错乱,导致跳过段落、重复处理,甚至把已经处理过的段落再次转换。
最终结果就是:多次转换叠加,所有文字都被强制转为简体。
❌ 问题二:为什么 没有恢复成繁体中文?(即 rngPara.Text = txt 失效)
你保存了原始文本 txt = rngPara.Text,并在判断后执行:
vba
rngPara.Text = txt
理论上应该恢复原文。但这里有两个陷阱:
- TCSCConverter 可能改变了段落的内部格式或 Unicode 表示
繁简转换不仅仅是字符替换,还可能涉及:
全角/半角标点转换
异体字映射(如「裡」→「里」)
地区用词差异(如「软体」→「软件」)
即使你把 .Text 设回原字符串,Word 可能已将该段落标记为"简体中文语言",后续显示或排版仍按简体处理。
- 更严重的是:你恢复文本的操作本身会破坏段落结构
rngPara.Text = txt 会完全替换该 Range 的内容,包括删除原有的格式、字段、书签等。
而且,由于 rngPara 是基于 aPara.Range 创建的,修改它会直接影响 aPara,进而干扰后续循环。
✅ 正确做法:不要修改原文,只做"模拟转换"判断
由于 TCSCConverter 无法"只读"地预览转换结果,我们需要换一种思路:
方案:复制段落到临时位置(如隐藏文档或剪贴板),在那里做转换测试
实际上,在我的office2021上TCSCConverter 方法并不是只直接、永久地修改了 Range 所指向的文档内容,而是修改了整个文档的内容,连千问都没想到会这样。当然,前面运行结果符合预期的宏代码是在千问给出的代码的基础上修正的(千问给出的代码存在命名参数错误并且在获取段落文本时没有去掉段落标记,导致originalText <> convertedText 总是返回True)。
进一步的改进:
考虑到判断段落是否是繁体中文段落只需要对中文进行检测,而非中文字符的干扰反而可能导致繁简转换的结果出现差错,所以我考虑将上面的代码进一步改进,将段落中的非中文字符全部删除后再进行转换并检查转换前后的文本是否一致。打开Edge浏览器的插件askgo,将上面的Sub 标记繁体段落()发给它让它派个AI改进一下,结果AI生成的代码给了我更多惊喜:它考虑到了更多的段落控制符类型,并且考虑到了确保临时文档成功关闭的问题。通过比较改进代码与原始代码,无疑可以提高VBA的基本功:
vbnet
Sub 标记繁体段落改进版()
Dim doc, tempDoc As Document
Dim aPara As Paragraph
Dim originalText, chineseText, convertedText As String
On Error GoTo CleanFail
Set doc = ActiveDocument
' 创建隐藏的临时文档,用于将段落文本进行繁简转换,避免
' TCSCConverter在原文档中产生意料之外的影响
Set tempDoc = Documents.Add(Visible:=False)
For Each aPara In doc.Paragraphs
' 取得段落文本,并去掉段末控制字符
originalText = GetParagraphText(aPara.Range.text)
' 提取纯中文字符,排除英文、数字、标点、空白等干扰
chineseText = KeepChineseOnly(originalText)
' 没有中文则跳过
If Len(chineseText) > 0 Then
' 放入临时文档
tempDoc.content.text = chineseText
' 执行繁转简
tempDoc.content.TCSCConverter _
WdTCSCConverterDirection:=wdTCSCConverterDirectionTCSC, _
CommonTerms:=True, UseVariants:=False
' 读取转换结果
convertedText = GetParagraphText(tempDoc.content.text)
' 如果转换前后不同,说明原段落中包含可转换的繁体中文
If chineseText <> convertedText Then
aPara.Borders.Enable = True
Else
aPara.Borders.Enable = False
End If
Else
' 没有中文字符,不加边框
aPara.Borders.Enable = False
End If
Next aPara
CleanExit:
On Error Resume Next
If Not tempDoc Is Nothing Then
tempDoc.Close SaveChanges:=wdDoNotSaveChanges
Set tempDoc = Nothing
End If
Exit Sub
CleanFail:
MsgBox "运行出错:" & Err.Description, vbExclamation
Resume CleanExit
End Sub
' 去掉段落末尾的段落标记、单元格结束符等
Private Function GetParagraphText(ByVal s As String) As String
Do While Len(s) > 0
Select Case AscW(Right$(s, 1))
Case 13, 7, 11 ' 段落标记、单元格结束符、手动换行等常见控制字符
s = Left$(s, Len(s) - 1)
Case Else
Exit Do
End Select
Loop
GetParagraphText = Trim$(s)
End Function
' 仅保留中文字符
Private Function KeepChineseOnly(ByVal s As String) As String
Dim regEx As Object
Set regEx = CreateObject("VBScript.RegExp")
With regEx
.Global = True
.IgnoreCase = True
' 保留常见中文统一表意文字范围:
' \u3400-\u4DBF CJK扩展A
' \u4E00-\u9FFF CJK基本区
' \uF900-\uFAFF CJK兼容汉字
'
' 把"不在这些范围内"的字符全部替换为空
.Pattern = "[^\u3400-\u4DBF\u4E00-\u9FFF\uF900-\uFAFF]"
End With
KeepChineseOnly = regEx.Replace(s, "")
End Function外一段:
用Excel求公元纪年的干支的公式:
=IF(J28<0,LOOKUP(MOD((J28+1),10),{0,1,2,3,4,5,6,7,8,9},{"庚","辛","壬","癸","甲","乙","丙","丁","戊","己"}) & LOOKUP(MOD((J28+1),12),{0,1,2,3,4,5,6,7,8,9,10,11},{"申","酉","戌","亥","子","丑","寅","卯","辰","巳","午","未"}),LOOKUP(MOD((J28-1),10),{0,1,2,3,4,5,6,7,8,9},{"辛","壬","癸","甲","乙","丙","丁","戊","己","庚"}) & LOOKUP(MOD((J28-1),12),{0,1,2,3,4,5,6,7,8,9,10,11},{"酉","戌","亥","子","丑","寅","卯","辰","巳","午","未","申"}))
注释:J28即公元纪年所在单元格的名称,其中公元前以负整数表示,公元后以正整数表示。已知公元1年干支为辛酉,因为没有公元0年,所以公元前1年干支为辛酉前一位的庚申。通过对公元纪年与公元前后1年之间相差的年数分别对10和12求余,可以得到该年在天干表和地支表中的索引,依据索引即可查到天干和地支,组合起来即得到了干支。当然,可以将天干表和地支表及其对应的索引保存在工作表中,可以减少公式的长度,看起来会简单一点。