Excel Python:飞速搞定数据分析与处理

第三部分 在 Excel 之外读写 Excel 文件
第八章 使用读写包操作 Excel 文件
本章介绍 OpenPyXL、XlsxWriter、pyxlsb、xlrd 和 xlwt:它们都是可以用来读写 Excel 文件的包,在调用pandas 的 read_excel 函数和 to_excel 函数时,这些包就在背后完成相应的工作。我们可以利用这些读写包来创建更加复杂的 Excel 报表,也可以对文件读取过程进行优化。另外,如果你参与的项目中只需要读写 Excel 文件而不需要 pandas 的其他功能,那么安装整个 NumPy/pandas 技术栈完全就是"杀鸡用牛刀"。本章首先会介绍应当如何从诸多读写包中做出选择,其语法又是怎样的。然后再对一些高级主题进行研究,其中包括如何处理大型Excel 文件,以及如何将 pandas 和各种读写包相结合以改进 DataFrame 的样式。最后会回到第 7 章开头的案例研究,通过调整表格的格式并添加图表来改进这份报表。
8.1 读写包
本节会介绍至少 6 个包,因为几乎每种 Excel 文件都需要不同的包。事实上每个包都使用了各自的语法,并且都和原本的 Excel 对象模型 (第9章会详细介绍 Excel 对象模型的相关内容)大相径庭,因而进一步增加了学习难度。 这就意味着即便你是 VBA 熟手,也可能需要查询大量的命令的用法。本节首先会解释你在何时需要用到哪一种读写包,然后会介绍一个辅助模块,该模块可以让这些包用起来更加方便。之后我会将各个包以菜谱的形式展示出来,这样你就可以查询到大部分常用命令是如何工作的。
8.1.1 何时使用何种包
本节会介绍下列用于读、写和编辑 Excel 文件的 6 个包。
- OpenPyXL
- XlsxWriter
- pyxlsx
- xlrd
- xlwt
- xlutils
为了理解各个包的功能,请参见表 8-1。例如,要想读取 xlsx 格式的文件,就必须使用 OpenPyXL 包。

如果想写入 xlsx 或者 xlsm 文件,就需要在 OpenPyXL 和 XlsxWriter 中做出选择。这两个包有相似的功能,但是各自又有一些对方所没有的特性。由于这两个包都在积极开发中, 因此功能会随时间不断变化。下面是对两者区别的一个概述。
- OpenPyXL 可以读、写和编辑 Excel 文件,而 XlsxWriter 只能读。
- OpenPyXL 处理包含 VBA 宏的 Excel 文件时更加方便。
- XlsxWriter 的文档更优秀。
- XlsxWriter 通常 比 OpenPyXL 更快,不过具体速度取决于你要写入的工作簿的大小,有时候差异并不明显。
pandas 会使用它可以找到的读取包,如果同时安装了 OpenPyXL 和 XlsxWriter,那么 pandas 默认使用XlsxWriter。如果你想亲自选择 pandas 所使用的包,则可以在 read_excel 或 to_excel,以及 ExcelFile 或 ExcelWriter 的 engine 参数中指定所选包。engine(引擎) 是小写的包名,因此如果要用 OpenPyXL 而不是XlsxWriter 来写文件,则需要执行如下代码:
df.to_excel("filename.xlsx", engine="openpyxl")在知道了需要使用的包之后,还面临着第二道挑战:大部分的包需要用一些代码来读写单元格区域,而每个包所使用的又是不同的语法。为了让工作更轻松,接下来会介绍一个辅助模块。
8.1.2 excel.py 模块
该模块会让你在使用读写包时更加方便,该模块负责处理以下问题。
包切换 :切换读写包是一种很常见的场景。例如,Excel 文件会随着时间不断增大,很多用户会尽可能地将文件格式从 xlsx 切换到 xlsb,因为 xlsb 格式可以大幅削减文件大小。在这种情况下,你不得不从 OpenPyXL 切换到pyxlsb。因此也就必须将使用 OpenPyXL 的代码改写成 pyxlsb 的语法。
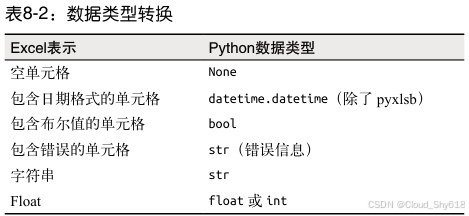
数据类型转换 :这一点和前一点密切相关:在切换包时,你不仅需要对代码的语法 进行调整 ,还需要注意不同包返回同一单元格内容时所用的不同数据类型。例如,OpenPyXL 会为空单元格返回 None,而 xlrd 返回的是空字符串。
单元格循环 :读写包是低级包:这就意味着它们并未提供一些方便的函数来处理常见任务。例如,大部分包会要求你通过循环来操作每一个需要读或写的单元格。
可以在配套代码库中找到 excel.py 模块,接下来的内容中会用到它。不过作为预览,这里给出了读写值的语法:
import excel
values = excel.read(sheet_object, first_cell="A1", last_cell=None)
excel.write(sheet_object, values, first_cell="A1")read 函数接受以下任一种包的 sheet 对象:xlrd、OpenPyXL 或 pyxlsb。它也接受可选参数 first_cell 和 last_cell。这两个参数可以以 A1 这样的字符串形式提供,也可以通过行列元组的形式提供(遵循 Excel 从 1 开始的索引规则):(1, 1)。first_cell 的默认值是 A1,而 last_cell 的默认值是所用区域的右下角。因此如果你只提供了sheet 对象作为参数,那么它就会读取整张工作表。与 read 函数的工作方式类似,write 函数接受 xlwt、 OpenPyXL 或 XlsxWriter 的 sheet 对象,以及以嵌套列表和可选的 first_cell 表示的值。 可选参数 first_cell 代表待写入区域左上角的单元格,嵌套列表将从这里开始写入。如表 8-2 所示,excel.py 模块还可以让数据类型转换更加顺畅。
有了 excel.py 模块,现在可以深入了解这些包了:接下来的内容中会讲到 OpenPyXL、 XlsxWriter、pyxlsb 和 xlrd/xlwt/xlutils。这些内容可以让你快速上手这些包。比起依次阅读这些内容,我更推荐根据表 8-1 选择你所需要的包,然后直接跳到对应的位置。
8.1.3 OpenPyXL
OpenPyXL 是本节中唯一既可以读也可以写 Excel 文件的包。你甚至可以用它来编辑 Excel 文件------不过只能编辑一些简单的文件。
1、使用 OpenPyXL 读取文件
下面的示例代码展示了在使用 OpenPyXL 时如何执行一些读取 Excel 文件时的常见任务。 要获得单元格的值,需要使用 data_only=True 参数来打开工作簿,其默认值是 False,此时会返回单元格的公式而不是值:
In [1]: import pandas as pd
import openpyxl
import excel
import datetime as dt
In [2]: # 打开工作簿来读取单元格的值
# 在加载数据之后文件会自动关闭
book = openpyxl.load_workbook("xl/stores.xlsx", data_only=True)
In [3]: # 通过名称或索引(从0开始)获取工作表对象
sheet = book["2019"]
sheet = book.worksheets[0]
In [4]: # 获取所有工作表名称的列表
book.sheetnames
Out[4]: ['2019', '2020', '2019-2020']
In [5]: # 遍历所有工作表对象
# openpyxl使用的是title而不是name
for i in book.worksheets:
print(i.title)
2019
2020
2019-2020
In [6]: # 获取维度,以工作表所选区域为例
sheet.max_row, sheet.max_column
Out[6]: (8, 6)
In [7]: # 读取单个单元格的值,分别使用的是 A1 这种表示法,以及单元格索引(从1开始)
sheet["B6"].value
sheet.cell(row=6, column=2).value
Out[7]: 'Boston'
In [8]: # 使用 excel 模块来读取一个单元格区域的值
data = excel.read(book["2019"], (2, 2), (8, 6))
data[:2] # 打印前两行
Out[8]: [['Store', 'Employees', 'Manager', 'Since', 'Flagship'],
['New York', 10, 'Sarah', datetime.datetime(2018, 7, 20, 0, 0), False]]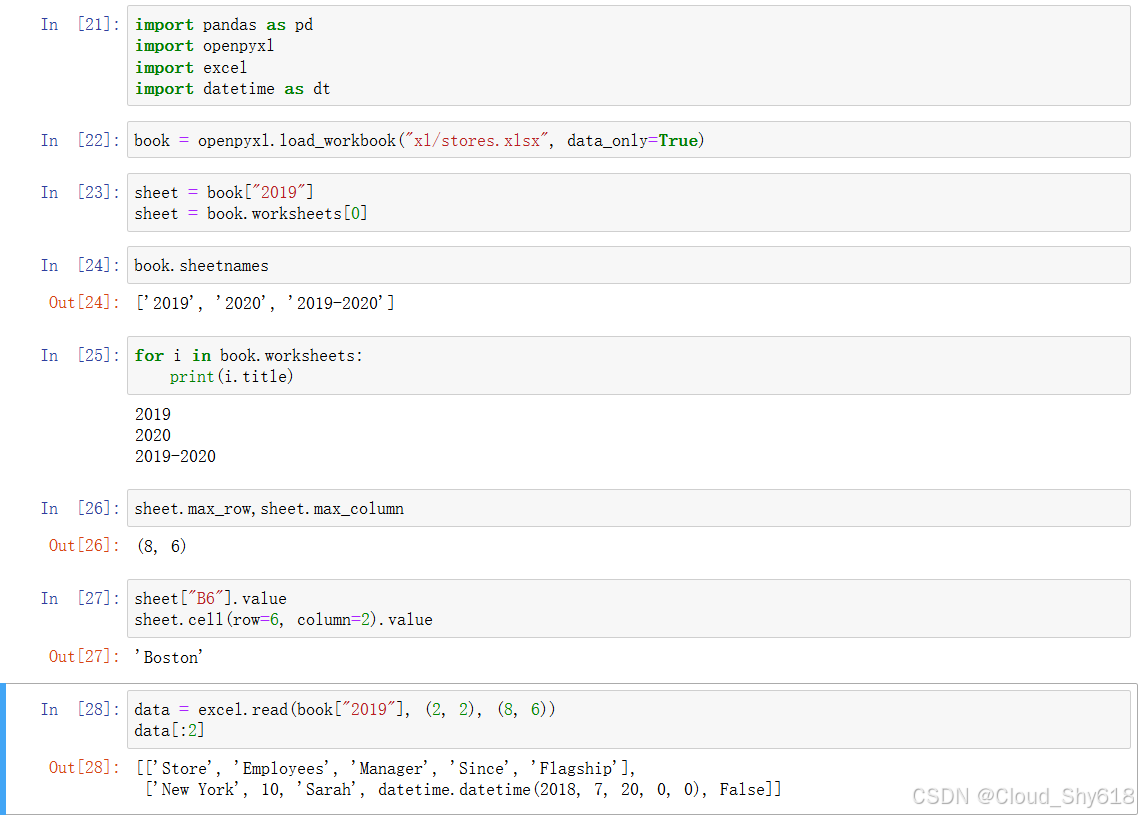
2、使用 OpenPyXL 写入文件
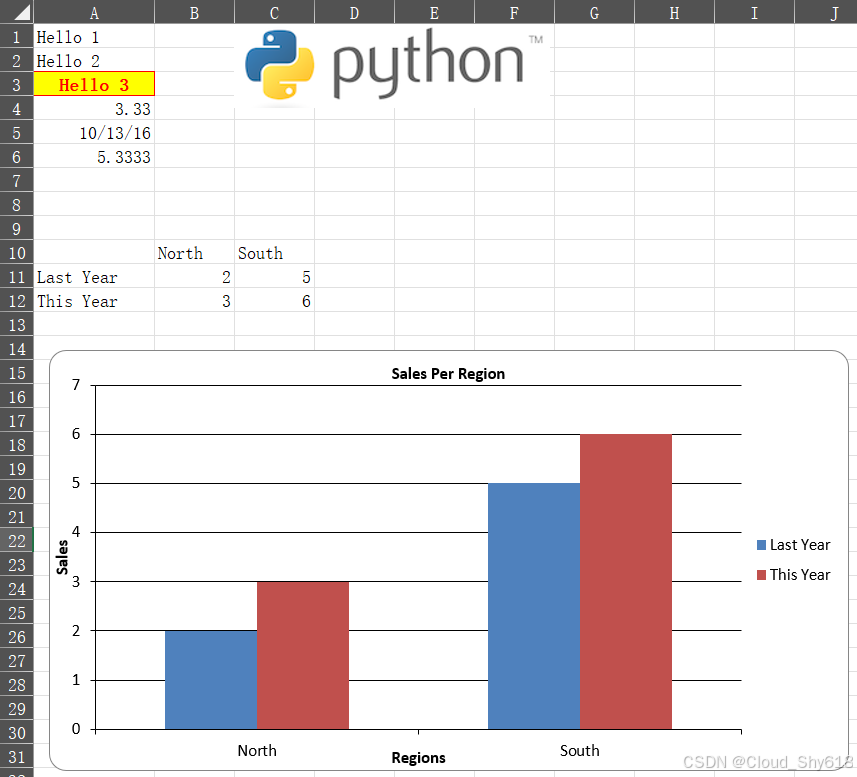
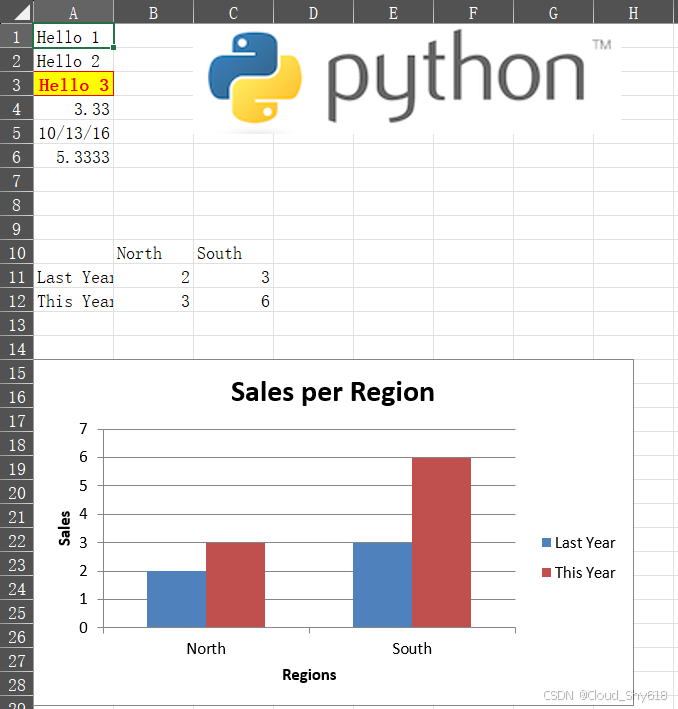
OpenPyXL 会在内存中构建 Excel 文件,当你调用 save 方法时会将其写入文件。下面的代码生成了图 8-1中的文件。
In [9]: import openpyxl
from openpyxl.drawing.image import Image
from openpyxl.chart import BarChart, Reference
from openpyxl.styles import Font, colors
from openpyxl.styles.borders import Border, Side
from openpyxl.styles.alignment import Alignment
from openpyxl.styles.fills import PatternFill
import excel
In [10]: # 实例化工作簿
book = openpyxl.Workbook()
# 获取第一张工作表并赋予它一个名称
sheet = book.active
sheet.title = "Sheet1"
# 使用A1表示法和单元格索引 (从1开始)写入各个单元格
sheet["A1"].value = "Hello 1"
sheet.cell(row=2, column=1, value="Hello 2")
# 格式化:填充颜色、对齐、边框和字体
font_format = Font(color="FF0000", bold=True)
thin = Side(border_style="thin", color="FF0000")
sheet["A3"].value = "Hello 3"
sheet["A3"].font = font_format
sheet["A3"].border = Border(top=thin, left=thin,
right=thin, bottom=thin)
sheet["A3"].alignment = Alignment(horizontal="center")
sheet["A3"].fill = PatternFill(fgColor="FFFF00", fill_type="solid")
# 数字格式化(使用Excel的格式化字符串)
sheet["A4"].value = 3.3333
sheet["A4"].number_format = "0.00"
# 日期格式化(使用Excel的格式化字符串)
sheet["A5"].value = dt.date(2016, 10, 13)
sheet["A5"].number_format = "mm/dd/yy"
# 公式:必须使用以逗号分隔的英文公式名称
sheet["A6"].value = "=SUM(A4, 2)"
# 图片
sheet.add_image(Image("images/python.png"), "C1")
# 二维列表(使用excel模块)
data = [[None, "North", "South"],
["Last Year", 2, 5],
["This Year", 3, 6]]
excel.write(sheet, data, "A10")
# 图表
chart = BarChart()
chart.type = "col"
chart.title = "Sales Per Region"
chart.x_axis.title = "Regions"
chart.y_axis.title = "Sales"
chart_data = Reference(sheet, min_row=11, min_col=1,
max_row=12, max_col=3)
chart_categories = Reference(sheet, min_row=10, min_col=2,
max_row=10, max_col=3)
# from_rows就像你手动在Excel中
# 添加图表那样解释数据
chart.add_data(chart_data, titles_from_data=True, from_rows=True)
chart.set_categories(chart_categories)
sheet.add_chart(chart, "A15")
# 保存工作簿会在磁盘上创建文件
book.save("openpyxl.xlsx")

如果想写入为 Excel 模板文件,那么需要在保存前设置 template 属性为 True:
In [11]: book = openpyxl.Workbook()
sheet = book.active
sheet["A1"].value = "This is a template"
book.template = True
book.save("template.xltx")

OpenPyXL 通过类似于 FF0000 这样的字符串来设置颜色。这样的值由 3 个 hex 值(FF、00 和 00)组成,分别对应所需颜色的红、绿、蓝分量。hex 代表 hexadecimal(十六进制),十六进制以 16 为基数来表示数字,而不像标准十进制那样以 10 为基数。
3、使用 OpenPyXL 编辑文件
并不存在真正可以编辑 Excel 文件的读写包:实际上 OpenPyXL 首先会读取所有它可以理解的数据,然后再将文件数据从头到尾写回去,其间你做出的所有更改也会包含其中。对 于一些主要包含已格式化的单元格以及数据和公式的简单 Excel 文件来说,它的功能已经非常强大了。但如果你的工作表中包含图表或者其他高级内容,那么OpenPyXL 的功能就显得非常有限了,这些内容要么会被修改,要么会被直接丢弃。例如,在 OpenPyXL v3.0.5 版本中,图表会被重命名且标题会被丢弃。下面是编辑 Excel 文件的示例:
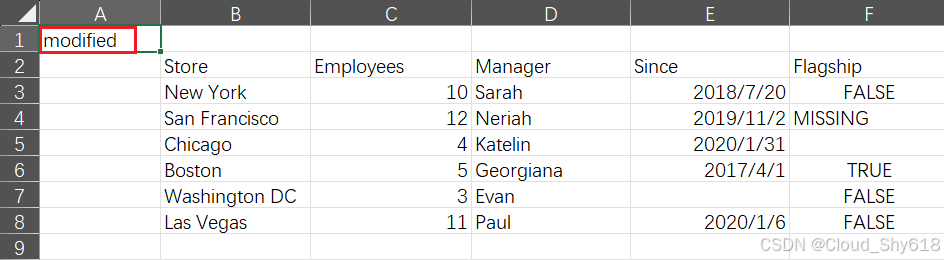
In [12]: # 读取stores.xlsx文件,修改一个单元格,并将其以新的名称保存到新的位置
book = openpyxl.load_workbook("xl/stores.xlsx")
book["2019"]["A1"].value = "modified"
book.save("stores_edited.xlsx")
如果想写入为 xlsm 文件,那么 OpenPyXL 就必须处理一个已经存在的文件,并且在加载时需要将 keep_vba 参数设置为 True:
In [13]: book = openpyxl.load_workbook("xl/macro.xlsm", keep_vba=True)
book["Sheet1"]["A1"].value = "Click the button!"
book.save("macro_openpyxl.xlsm")
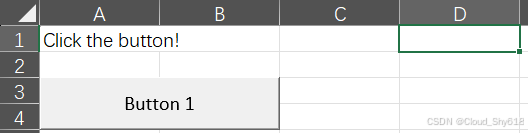
示例文件中的按键会调用一个显示对话框的宏。
8.1.4 XlsxWriter
顾名思义,XlsxWriter 只能写入 Excel 文件。下面的代码会和前面使用 OpenPyXL 时生成同样的工作簿,也就是图 8-1 中的文件。注意,XlsxWriter 使用的是从 0 开始的单元格索引, 而 OpenPyXL 使用的是从 1 开始的单元格索引,一定要在切换两个包时考虑到这一点:
In [14]: import datetime as dt
import xlsxwriter
import excel
In [15]: # 实例化工作簿
book = xlsxwriter.Workbook("xlxswriter.xlsx")
# 添加工作表并为其命名
sheet = book.add_worksheet("Sheet1")
# 使用A1表示法和单元格索引
#(从0开始)写入各个单元格
sheet.write("A1", "Hello 1")
sheet.write(1, 0, "Hello 2")
# 格式化:填充颜色、对齐、边框和字体
formatting = book.add_format({"font_color": "#FF0000",
"bg_color": "#FFFF00",
"bold": True, "align": "center",
"border": 1, "border_color": "#FF0000"})
sheet.write("A3", "Hello 3", formatting)
# 数字格式化(使用Excel的格式化字符串)
number_format = book.add_format({"num_format": "0.00"})
sheet.write("A4", 3.3333, number_format)
# 日期格式化(使用Excel的格式化字符串)
date_format = book.add_format({"num_format": "mm/dd/yy"})
sheet.write("A5", dt.date(2016, 10, 13), date_format)
# 公式:必须使用以逗号分隔的公式的英文名称
sheet.write("A6", "=SUM(A4, 2)")
# 图片
sheet.insert_image(0, 2, "images/python.png")
# 二维列表(使用excel模块)
data = [[None, "North", "South"],
["Last Year", 2, 5],
["This Year", 3, 6]]
excel.write(sheet, data, "A10")
# 图表:参见配套代码库中的文件sales_report_xlsxwriter.py,
# 以了解如何使用索引而不是单元格地址
chart = book.add_chart({"type": "column"}) # 创建图表对象的类型为柱状图
chart.set_title({"name": "Sales per Region"}) # 设置图表标题
# 添加第一条数据序列(第一组柱子)
# name: "=Sheet1!A11" 表示:该序列在图例(legend)中显示的名称,
# 来自 Sheet1 工作表的 A11 单元格内容。
# 注意前面的 =:这是 Excel 的"引用写法",表示引用单元格而不是直接写死字符串。
# categories: "=Sheet1!B10:C10" 横轴分类标签(X 轴分类)来自 B10 到 C10(两个分类)。
# values: "=Sheet1!B11:C11" 该序列对应的数值(柱子的高度)来自 B11 到 C11(两个数值), # 分别对应上面两个 categories。
chart.add_series({"name": "=Sheet1!A11",
"categories": "=Sheet1!B10:C10",
"values": "=Sheet1!B11:C11"})
chart.add_series({"name": "=Sheet1!A12",
"categories": "=Sheet1!B10:C10",
"values": "=Sheet1!B12:C12"})
chart.set_x_axis({"name": "Regions"})
chart.set_y_axis({"name": "Sales"})
sheet.insert_chart("A15", chart)
# 关闭工作簿并在磁盘上创建文件
book.close()
和 OpenPyXL 相比,XlsxWriter 在写入 xlsm 文件时必须采用一种更复杂的方法。首先,你需要在 Anaconda Prompt 中从既存的 Excel 文件中提取宏代码。(示例中使用的是 macro. xlsm 文件,你可以在配套代码库的 xl 文件夹中找到。)
Windows :
首先切换至 xl 目录,找到 vba_extract.py 的路径(以博主主机为例),这是一个和 XlsxWriter 一起使用的脚本:
(base) C:\Users\SHY>d: # 博主的文件放在了D盘,因此先切换到D盘
(base) D:\>cd D:\DevTools\Jupyter\python-for-excel-1st-edition\xl
注意:base 环境下可能并没有安装 xlsxwriter,因此需要先安装。
(base) D:\DevTools\Jupyter\python-for-excel-1st-edition\xl>pip install xlsxwriter接着,查找 vba_extract.py 的路径。
(base) D:\DevTools\Jupyter\python-for-excel-1st-edition\xl>where vba_extract.py
然后,在下面的命令中使用该路径。
(base) D:\DevTools\Jupyter\python-for-excel-1st-edition\xl>python D:\DevTools\anaconda3\Scripts\vba_extract.py macro.xlsm
该命令会将 vbaProject.bin 保存在执行命令时所在的目录。将提取出来的文件放在配套代码库的xl文件夹中。以下示例会用这个文件来写入一个带有宏按钮的工作簿。
In [16]: book = xlsxwriter.Workbook("macro_xlsxwriter.xlsm")
sheet = book.add_worksheet("Sheet1")
sheet.write("A1", "Click the button!")
book.add_vba_project("xl/vbaProject.bin")
sheet.insert_button("A3", {"macro": "Hello", "caption": "Button 1",
"width": 130, "height": 35})
book.close()
8.1.5 pyxlsb
和其他读取库相比,pyxlsb 提供的功能不多,但是如果你要读取二进制的 xlsb 格式的 Excel 文件,那么 pyxlsb 就成了唯一选择。pylsb 不是 Anaconda 的一部分,如果你还没有安装过它,则需要先安装。目前无法通过 Conda 来安装 pyxlsb,需要使用 pip:
(base) C:\Users\SHY>pip install pyxlsb
读取工作簿和单元格的值:
In [17]: import pyxlsb
import excel
In [18]: # 遍历工作表。在pyxlsb中,工作簿和sheet对象
# 都可以被用作上下文管理器。book.sheets 返回的是工作表名称列表,而不是对象!
# 要获取工作表对象,需要使用 get_sheet()
with pyxlsb.open_workbook("xl/stores.xlsb") as book:
for sheet_name in book.sheets:
with book.get_sheet(sheet_name) as sheet:
dim = sheet.dimension
print(f"Sheet '{sheet_name}' has "
f"{dim.h} rows and {dim.w} cols")
Sheet '2019' has 7 rows and 5 cols
Sheet '2020' has 7 rows and 5 cols
Sheet '2019-2020' has 20 rows and 5 cols
In [19]: # 利用excel模块读取一个区间中单元格的值
# 除了"2019",也可以使用它的索引(从1开始)
with pyxlsb.open_workbook("xl/stores.xlsb") as book:
with book.get_sheet("2019") as sheet:
data = excel.read(sheet, "B2")
data[:2] # 打印前两行
Out[19]: [['Store', 'Employees', 'Manager', 'Since', 'Flagship'],
['New York', 10.0, 'Sarah', 43301.0, False] 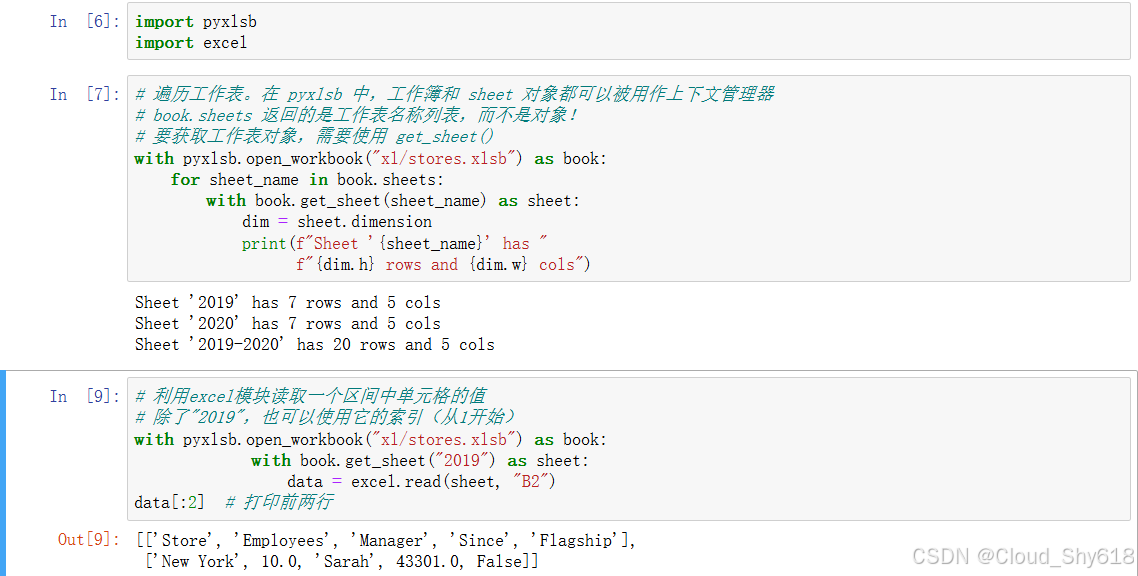
pyxlsb 目前无法识别包含日期的单元格,所以必须手动将以日期为格式的单元格中的值转换为 datetime 对象,就像下面这样:
In [20]: from pyxlsb import convert_date
convert_date(data[1][3])
Out[20]: datetime.datetime(2018, 7, 20, 0, 0)
记住, 在使用版本低于 1.3 的 pandas 读取 xlsb 格式的文件时,需要显式地指定引擎。
In [21]: df = pd.read_excel("xl/stores.xlsb", engine="pyxlsb")8.1.6 xlrd、xlwt 和 xlutils
OpenPyXL 可以为 xlsx 格式提供读、写和编辑的功能。如果将 xlrd、xlwt 和 xlutils 结合起来,它们也可以为旧式xls 格式的文件提供类似的功能:xlrd 读、xlwt 写和 xluils 编辑 xls 文件。虽然这些包不再积极开发,但只要 xls 文件还存在,它们就依然有用武之地。xlutils 不是 Anaconda 的一部分,如果你还没有安装,则需要先安装:
(base)> conda install xlutils1、使用 xlrd 读取文件
下面的示例代码展示了如何使用 xlrd 从 Excel 工作簿中读取单元格的值。
In [22]: import xlrd
import xlwt
from xlwt.Utils import cell_to_rowcol2
import xlutils
import excel
In [23]: # 打开工作簿来读取单元格的值
# 在加载数据后文件会自动关闭
book = xlrd.open_workbook("xl/stores.xls")
In [24]: # 获取所有工作表的名称
book.sheet_names()
Out[24]: ['2019', '2020', '2019-2020']
In [25]: # 遍历所有工作表对象
for sheet in book.sheets():
print(sheet.name)
2019
2020
2019-2020
In [26]: # 通过名称或者索引(从0开始)获取工作表对象
sheet = book.sheet_by_index(0)
sheet = book.sheet_by_name("2019")
In [27]: # 维度
sheet.nrows, sheet.ncols
Out[27]: (8, 6)
In [28]: # 使用A1表示法或者单元格索引
#(从0开始)读取各个单元格的值。
# *会解包cell_to_rowcol2返回的
# 元组以生成各个参数
sheet.cell(*cell_to_rowcol2("B3")).value
sheet.cell(2, 1).value
Out[28]: 'New York'
In [29]: # 使用excel模块读取一个区间中单元格的值
data = excel.read(sheet, "B2")
data[:2] # 打印前两行
Out[29]: [['Store', 'Employees', 'Manager', 'Since', 'Flagship'],
['New York', 10.0, 'Sarah', datetime.datetime(2018, 7, 20, 0, 0),
False]]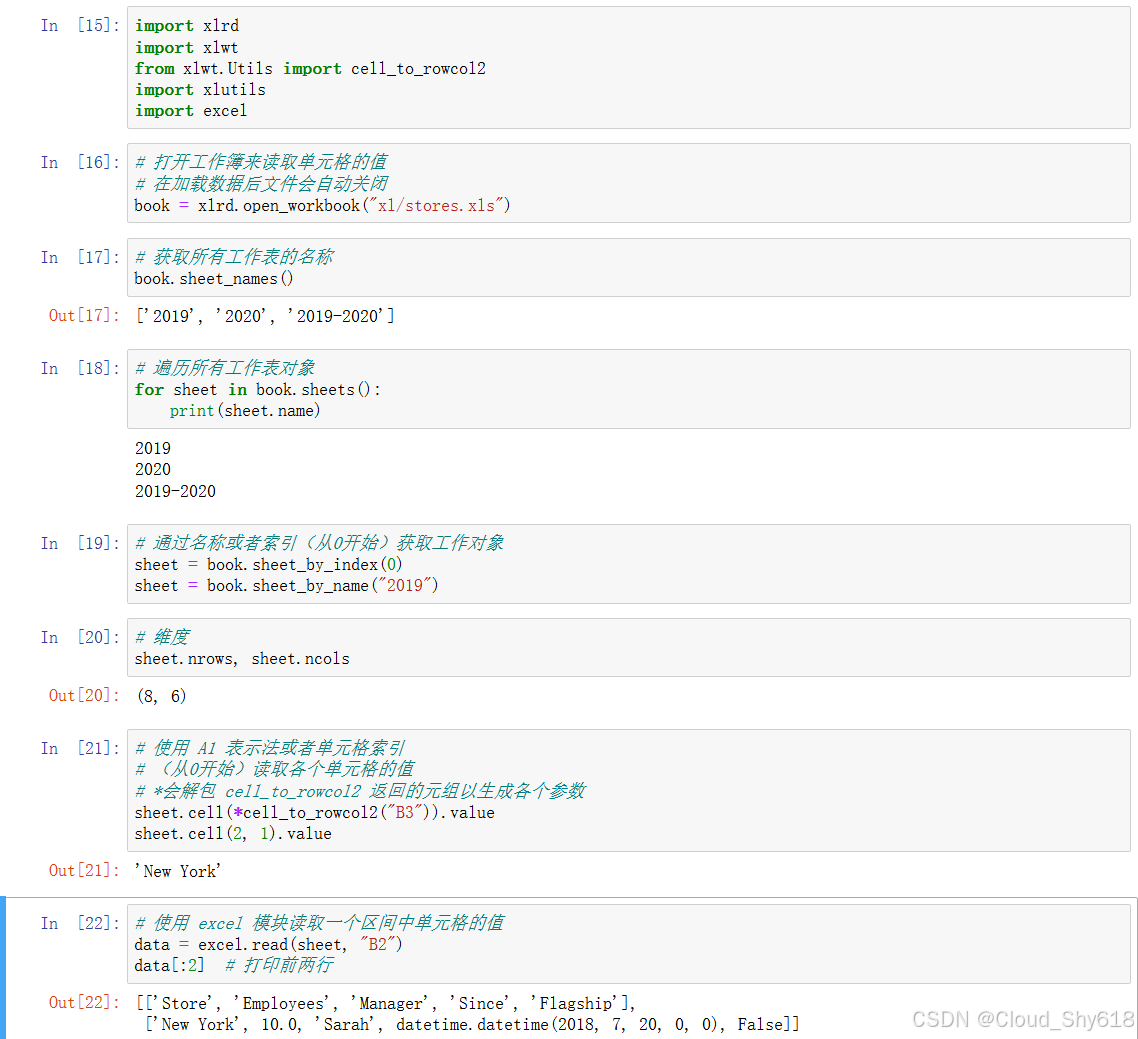
使用区域 :与OpenPyXL 和 pyxlsb 不同,在使用 sheet.nrows 和 sheet.ncols 时,xlrd 会以值的形式而不是工作表的使用区域(used range)返回单元格的维度。 Excel 以使用区域的形式返回的值通常包含区域底部和右侧的空行和空列。 例如,当你(通过 Delete 键)删除行的内容,而不是(单击右键,选择删除)删除行本身时,就可能发生这种情况。
2、使用 xlwt 写入文件
下面的代码重现了之前用 OpenPyXL 和 XlsxWriter 生成的图 8--1 中的文件。不过 xlwt 并不能生成图表,并且只支持 bmp 格式的图片。
In [30]: import xlwt
from xlwt.Utils import cell_to_rowcol2
import datetime as dt
import excel
In [31]: # 实例化工作簿
book = xlwt.Workbook()
# 添加工作表并为其命名
sheet = book.add_sheet("Sheet1")
# 使用A1表示法和单元格索引
#(从0开始)写入各个单元格
sheet.write(*cell_to_rowcol2("A1"), "Hello 1")
sheet.write(r=1, c=0, label="Hello 2")
# 格式化:填充颜色、对齐、边框和字体
formatting = xlwt.easyxf("font: bold on, color red;"
"align: horiz center;"
"borders: top_color red, bottom_color red,"
"right_color red, left_color red,"
"left thin, right thin,"
"top thin, bottom thin;"
"pattern: pattern solid, fore_color yellow;")
sheet.write(r=2, c=0, label="Hello 3", style=formatting)
# 数字格式化(使用Excel的格式化字符串)
number_format = xlwt.easyxf(num_format_str="0.00")
sheet.write(3, 0, 3.3333, number_format)
# 日期格式化(使用Excel的格式化字符串)
date_format = xlwt.easyxf(num_format_str="mm/dd/yyyy")
sheet.write(4, 0, dt.datetime(2012, 2, 3), date_format)
# 公式:必须使用以逗号分隔的公式的英文名称
sheet.write(5, 0, xlwt.Formula("SUM(A4, 2)"))
# 二维列表(使用excel模块)
data = [[None, "North", "South"],
["Last Year", 2, 5],
["This Year", 3, 6]]
excel.write(sheet, data, "A10")
# 图片(只支持添加 bmp 格式的图片)
sheet.insert_bitmap("images/python.bmp", 0, 2)
# 将文件写入磁盘
book.save("xlwt.xls") 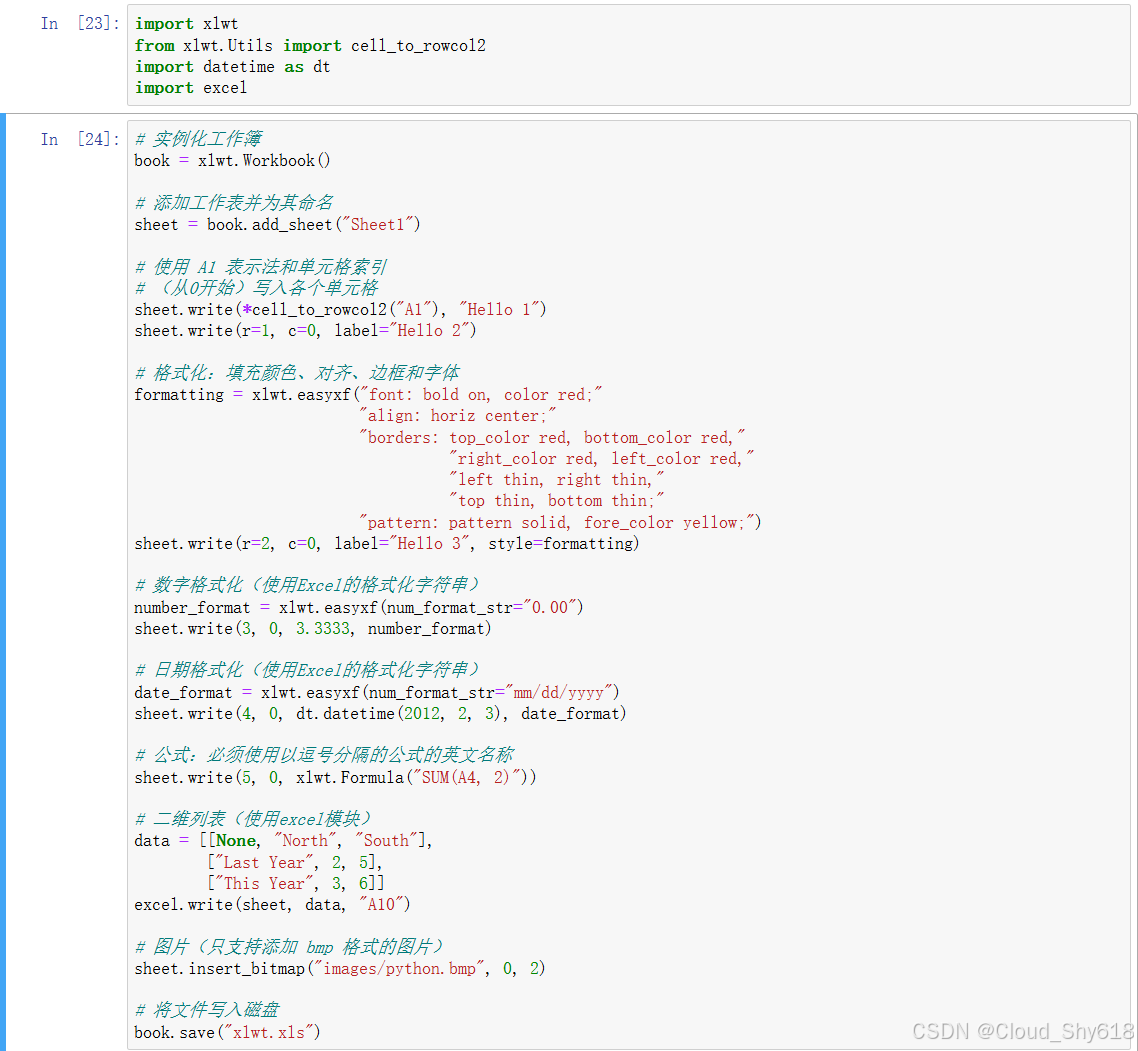
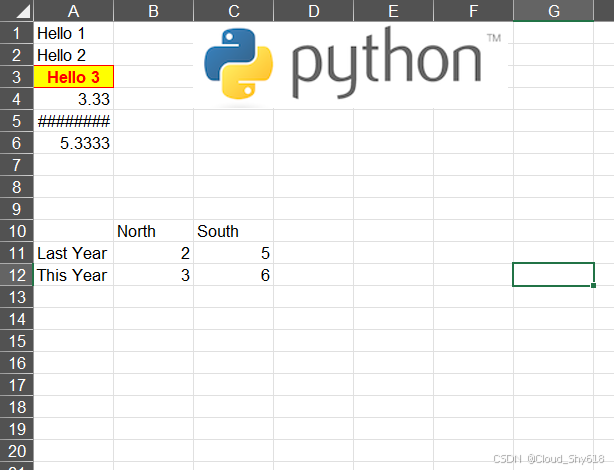
如上图所示,生成的表格中确实没有图表。
3、使用 xlutils 编辑文件
xlutils 可以作为 xlrd 和 xlwt 之间的桥梁。这也表明了实际上这不是真正的编辑操作:工作表通过 xlrd 读取包含格式在内的文件内容(将 formatting_info 的参数设置为 True),然后再通过 xlwt 将其间做出的更改写入文件:
In [32]: import xlutils.copy
In [33]: book = xlrd.open_workbook("xl/stores.xls", formatting_info=True)
book = xlutils.copy.copy(book)
book.get_sheet(0).write(0, 0, "changed!")
book.save("stores_edited.xls")
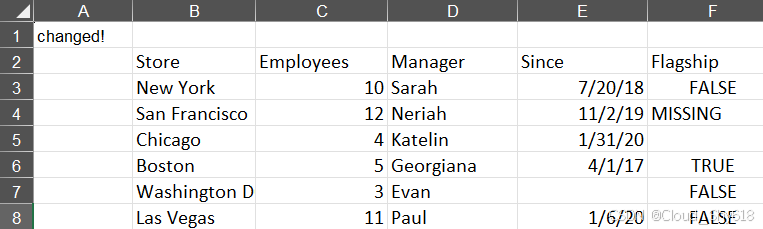
好啦,现在你已经知道如何读写特定格式的 Excel 工作簿。下一节将开始学习一些高级主题,其 中包括大型 Excel文件的处理,以及将 pandas 和各种读写包结合使用。