前言
集群这个词,有着广义与狭义的概念
广义的集群 ,指的是只要有多个机器构成了分布式系统,都可以称为集群,如前文中提到的主从模式,哨兵机制 Redis主从复制-CSDN博客 Redis哨兵(Sentinel)机制-CSDN博客
狭义的集群,指的是redis提供的集群模式,这个模式主要解决的是存储空间不足的问题(拓展存储空间)
一.数据分配算法
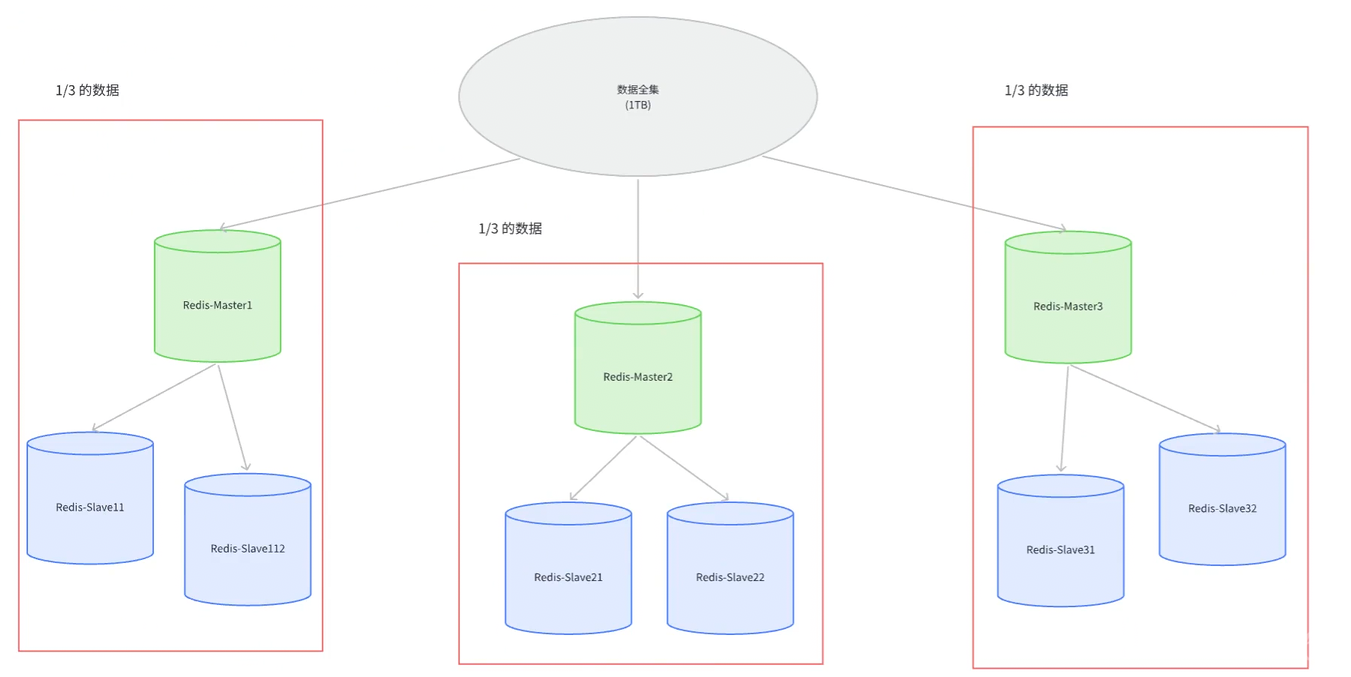
redis中的集群,即引入多台机器,每个机器存储一部分数据
需要选用一种合理的算法思想,将数据合理分配给不同的机器
常见的分配算法有以下几种:
1.哈希求余
借鉴哈希表思想,借助哈希函数,把一个key映射到整数,再针对数组的长度进行求余,就可以得到一个数组的下标.
通过该算法,我们可以将数据平均的分配给各个存储片区.
但服务器集群一旦需要扩展,则有大部分的数据需要迁移到其他片区,需要更高的成本
2.一致性哈希算法
针对服务器集群扩展成本高,一致性哈希算法通过划分出区域大小,根据hash值的大小划分到对应的区间,如此,可大大减小服务器集群扩展时,需要搬迁的数据量
但是,这样虽然搬运数据的成本低了,但每个片区的数据量,就可能不均匀了(数据倾斜)
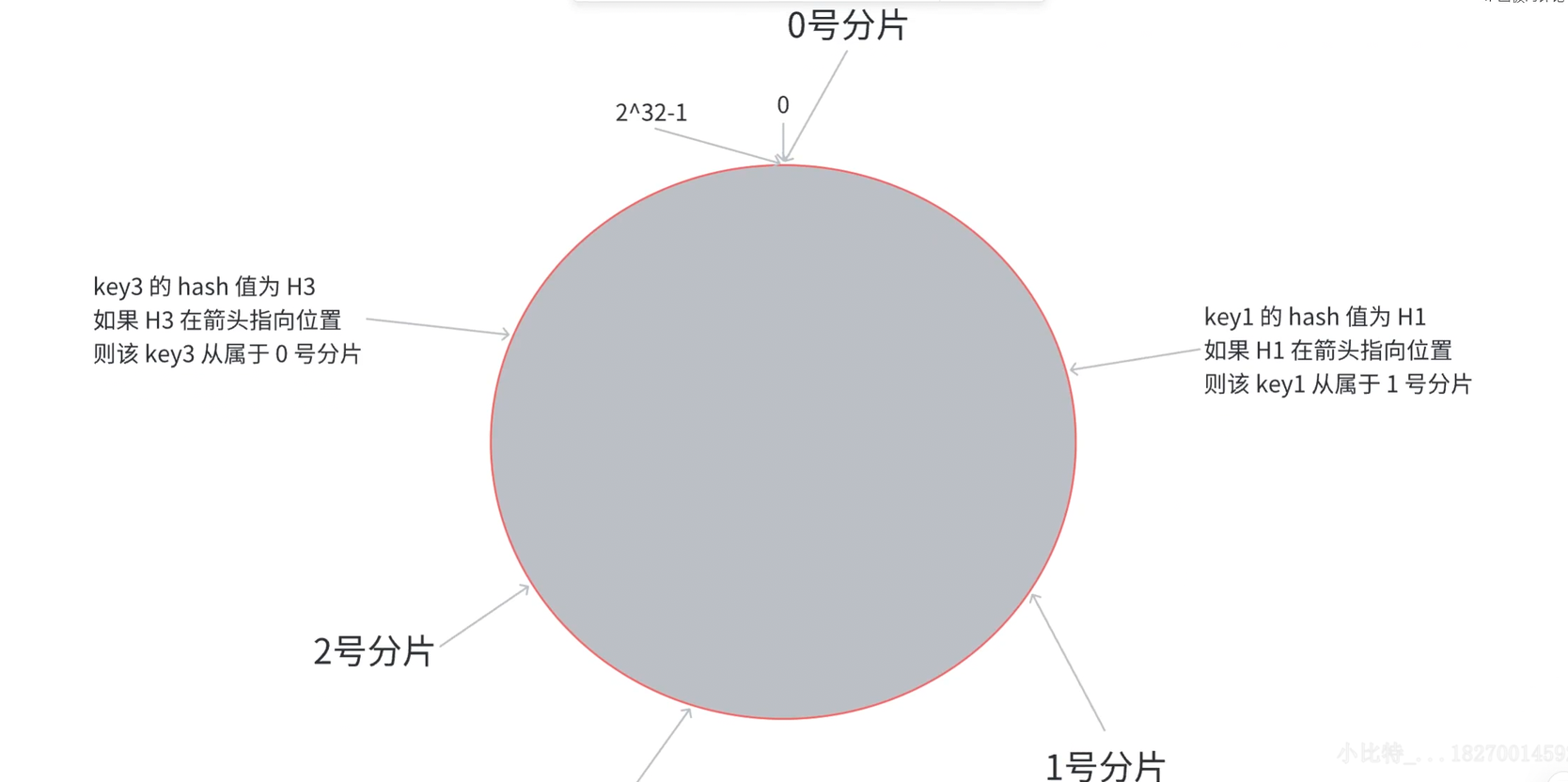
3.哈希槽分区算法(redis采用)
哈希槽分区算法,首先会根据key的值求出哈希槽,公式为:hash_slot=crc16(key)%16384
16384刚好为16*1024(16k)
根据hash_slot(哈希槽)进一步将数据分配到片区中
每个分区负责接收的哈希槽数量相当,虽然不能保证各个分区的数据严格意义上的均匀,但差距也是非常小了
哈希槽分区算法的本质,是将哈希求余 与一致性哈希算法相结合,既能一定程度上减少数据倾斜,也大大减少了集群扩容时的成本
但是,集群的扩容操作是一件风险较高,成本较大的操作,操作时一定需要谨慎再谨慎.(也可以通过构建新的集群来替代原有的集群,这样更为安全)
二.故障处理
在redis集群中,有着故障转移的机制
当某一片区的主节点挂了,会在可用从节点中选出新的主节点来处理工作
此处的故障转移与redis哨兵机制流程有着差别
分为以下流程:
1.故障判定
集群中的每个节点,每秒钟都会给随机的节点发送ping包(不全发是避免节点过多,心跳包过多)
当A节点给B节点发送ping包,B节点不能如期回应时,此时A节点会尝试重置与B节点的TCP连接,看是否能连接成功,若失败,则A节点会把B节点标记为PFAIL
随后,A节点通过redis内置的Gossip协议,和其他节点沟通,确认B的状态
若超过半数节点认为B节点挂了,则A节点将B节点标记为FAIL,并将消息同步给其他节点
2.故障迁移
当片区中主节点挂掉后,从节点会先判断自身是否有选举资格成为新的主节点(offset数值大小,与主节点数据差距大,则失去资格) 具有选举资格的节点会进行休眠一段时间,哪个节点offset越大,则休眠时间越短,休眠结束则会进行拉票
其他主节点进行投票,超过半数票数则晋升主节点
同时,新节点会通知其他集群节点.