说是 SoA memory + Iteration 是抓住了物理层面的核心。ECS 所有的性能神话(海量渲染、物理模拟)其实都是为了顺应现代 CPU 的脾气 :喜欢连续数据,讨厌随机访问。
ECS 中的"块"管理 (Archetype Chunk)
Unity 的 ECS 并没有使用纯粹的全局大数组,而是采用了 Archetype Chunk 机制:
- 具有相同组件组合(原型)的实体被归类在一起。
- 每个 Chunk (16KB) 内部采用 SoA 布局。
- 本质:它是"分块的 SoA"。这既保持了线性迭代的优势,又解决了动态增删组件时的内存迁移压力。
Iteration (迭代) 的进化
在 ECS 中,迭代不再是 foreach(GameObject),而是:
- System 直接操作 Chunk:System 识别出感兴趣的组件列,直接通过指针在内存块上滑动。
- Burst 优化 :因为数据是连续且类型确定的,Burst Compiler 可以轻松地生成 SIMD (单指令多数据) 指令。例如,一次 CPU 时钟周期同时处理 4 个或 8 个实体的坐标运算。
为什么不直接叫 SoA? --因为 ECS =SoA + 对象识别逻辑框架:
- Entities (ID) :解决了 SoA 模式下如何**跨数组标识"同一个对象"**的问题。
- Systems (Queries) :解决了如何高效筛选出"同时拥有 A 和 B 组件的实体"的问题(通过组件掩码匹配)。
ECS 的存在本质上是为了抹平高级语言(C#) 与**现代 CPU 硬件(汇编/机器码)**之间的巨大鸿沟。
内存布局:从 "链表寻址"回归"偏移量寻址"
在传统 MonoBehaviour 中,C# 对象是堆上的引用类型。从汇编角度看,访问一个属性需要:
- 加载对象指针。
- 跳转到内存地址。
- 加上偏移量 读取数据。
这在汇编层面会产生大量的mov指令,且因为地址不连续,极易引发 Cache Miss(CPU 停顿等待内存)。
在 ECS (SoA) 中:
- System 拿到的直接是组件数组的首地址指针。
- 汇编指令变成了极其简单的:
base_ptr + index * size。 - 这种线性访问模式 让 CPU 的 L1/L2 缓存预取器能提前把下一组数据搬进缓存,汇编执行几乎是流水线式的,没有任何"漂移"。
指令集:开启 SIMD 的大门
这是 ECS 最硬核的地方。普通的 C# 代码很难被编译器自动优化为 SIMD(单指令多数据)。
- 传统代码 :汇编里可能是
addss(标量加法),一次只能加一个浮点数。 - ECS + Burst Compiler :因为数据是 SoA 连续排布的,编译器可以放心地生成
addps或vpaddd(矢量加法)。 - 结果 :一行机器码指令可以同时处理 4个、8个甚至16个 实体的坐标计算。这才是 ECS 性能比传统模式快出几十倍的真正"物理外挂"。
C# 角色转变为"汇编生成器"
在 ECS 体系中,C# 的角色变了:
- 你写的 C# 不再是 直接执行的逻辑,而是给 Burst Compiler 提供的"蓝图"。
- Burst 会绕过标准的 JIT(即时编译),直接将你的 C# 代码编译为针对特定 CPU 优化过的高度精简的汇编代码。
- 它剔除了 C# 的安全检查(如数组越界、GC 检查),生成的机器码在纯净度上几乎等同于手写 C++ 或 汇编。

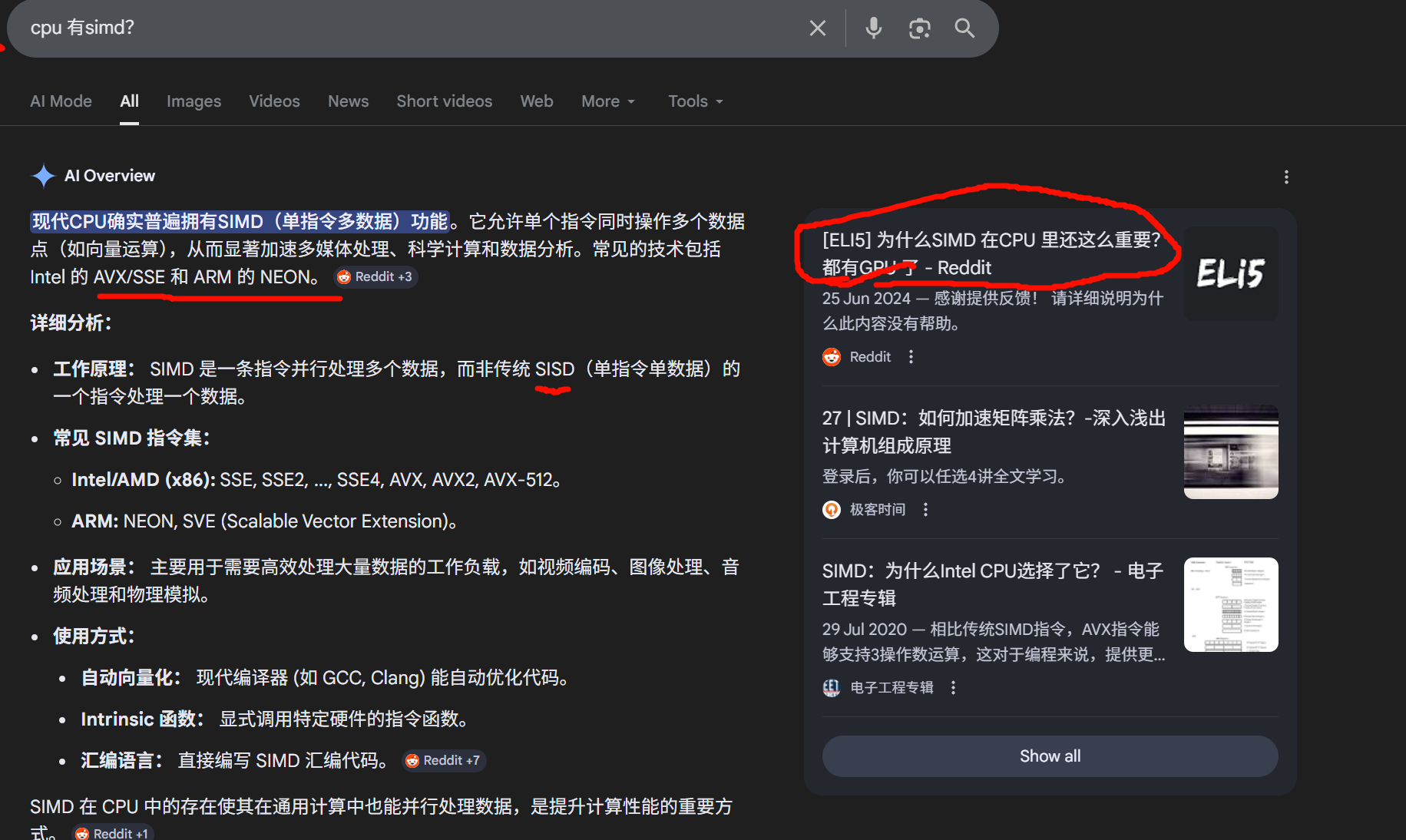
"GPU 是一种计算设备,它以更具多线程的方式实现了 SIMD(单指令多数据),实际上在 GPU 中 SIMD 被称为 SIMT(单指令,多线程)。所以基本上 GPU 是 SIMD 范式的扩展,具有大规模多线程、流式内存和动态调度。"
-Gary Cole, Quora
GPU SIMD(或称SIMT)以更细粒度、海量线程并行模式工作,适合高吞吐量的图形和通用计算。
unity创造了HPC# (High Performance C#)
Unity 并没有创造一门全新的编程语言,而是基于 C# 提取出了一个"高性能子集",官方称之为 HPC# (High Performance C#)。 1, 2
你可以把它理解为"带枷锁的 C#":为了极致的性能,它禁用了很多高级但低效的特性,从而让 Burst Compiler 能生成媲美汇编的机器码。 3, 4
1. HPC# 阉割了什么?(为什么它像新语言)
为了保证内存的绝对线性布局和零 GC(垃圾回收)开销,HPC# 严禁使用以下 C# 特性: 2, 5
- 禁止引用类型:不能使用
class,只能用struct。这意味着没有堆内存分配,也就没有了 GC 带来的掉帧风险。 - 禁止标准容器:不能用
List<T>或Dictionary<K,V>,必须使用 Unity 提供的NativeArray<T>等 Native 容器(手动管理内存)。 - 禁止托管操作:禁止垃圾回收、异常处理(Exception)以及虚函数(Virtual Methods)。 6
2. 为什么要这么做?(C# 到机器码的质变)
普通的 C# 代码在执行时需要经过 .NET 虚拟机的托管,就像是一个带翻译的职场:
- 普通 C#:灵活但臃肿,汇编指令里充斥着地址跳转和安全检查。
- HPC# + Burst:像是一个只说核心指令的军官。因为它只处理简单的结构体和连续内存,Burst 编译器 可以直接利用 LLVM 将其翻译成针对不同 CPU (如 Intel 的 AVX 或 ARM 的 Neon)优化的 SIMD (单指令多数据) 指令。 4, 7
3. 2026 年的现状
到 2026 年,Unity 的战略并不是用 HPC# 替换所有开发,而是分层开发: 8, 9
- 顶层逻辑:依然使用全功能 C# (MonoBehaviour),享受 .NET 10 (CoreCLR) 带来的开发便利。
- 底层核心:在需要处理海量单位、复杂物理或高性能计算时,开发者主动"切换"到 HPC# 模式编写 ECS 系统。 10
总结:
Unity 没有发明新语言,而是通过"裁剪 C# + 专用编译器 (Burst)"的方式,让 C# 在性能上达到了 C++/汇编 的级别。这让你能用熟悉的 C# 语法,写出硬件天花板性能的代码。 3, 7
如果你想尝试,我可以教你如何写出一段 符合 Burst 编译要求的 HPC# 结构体。
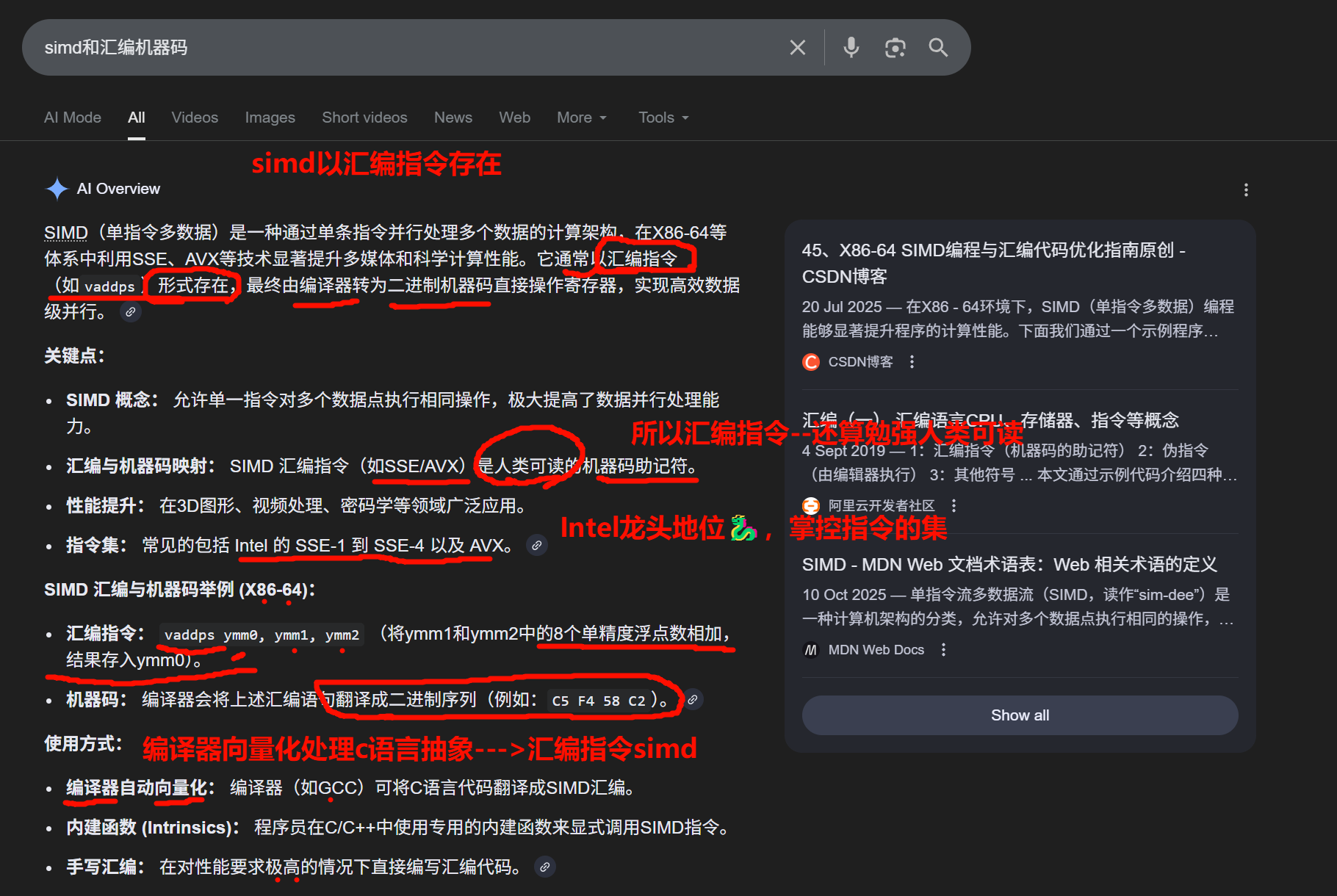
To "switch" to HPC# in Unity isn't a toggle in the settings; it's a coding discipline enforced by the Burst Compiler. You are essentially writing C# but stripping away everything that makes it "managed" (Garbage Collected).
编译器层:自动进行程序变换
如果只有抽象而没有编译器优化,性能会崩溃。
现代编程语言真正强大的地方在于:
编译器可以做程序级变换。
例如:
-
SSA 形式
-
Loop unrolling
-
Vectorization
-
Escape analysis
-
Dead code elimination
例如 Burst / LLVM:
overflow-visible!
for(i)
sum += ai
编译器可能变成:
overflow-visible!
SIMD 128/256 load
FMA
loop unroll
开发者写的是算法结构 ,编译器生成的是硬件最优路径。
这就是为什么:
overflow-visible!
C++ + LLVM
Rust + LLVM
Burst + LLVM
性能可以接近 hand-written assembly。
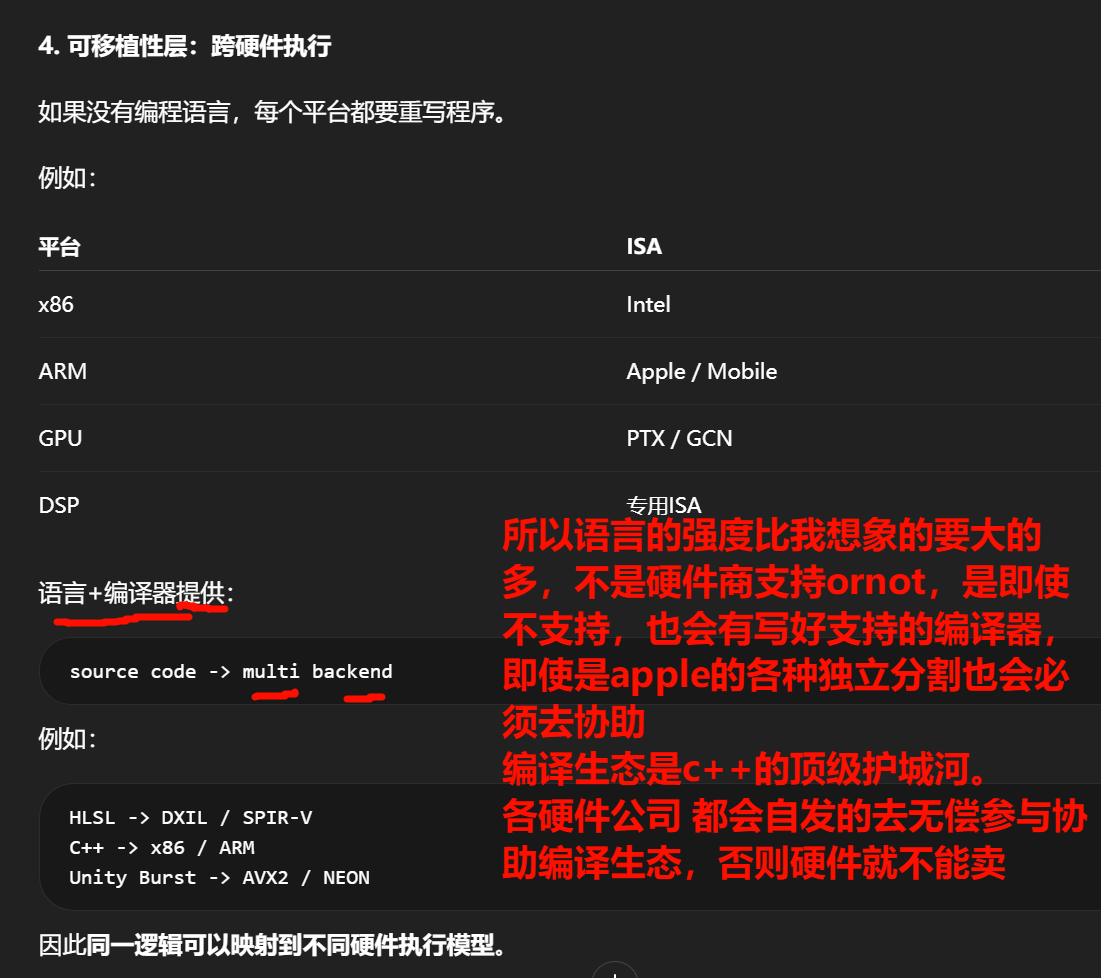
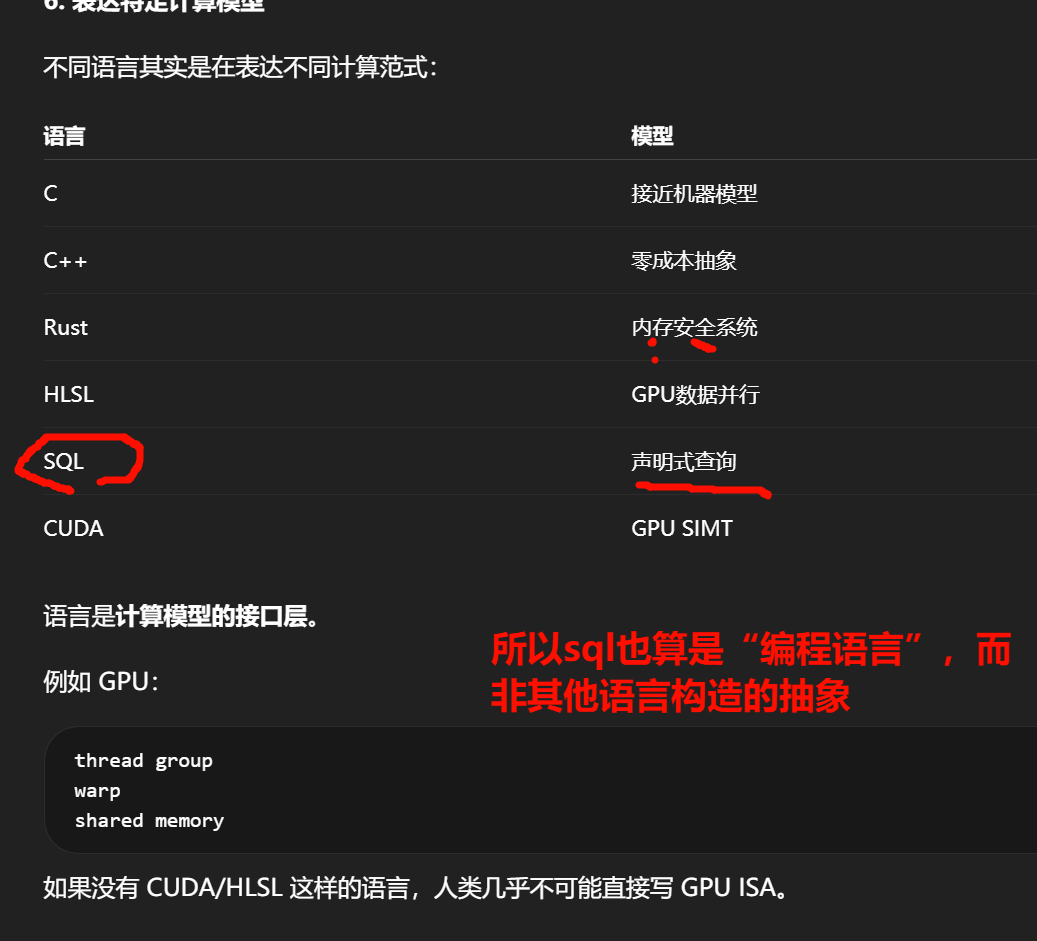
编程语言并不是"让机器运行程序"的工具。
它真正解决的是:
人类如何在有限认知能力下构建极其复杂的计算系统。
虚幻引擎(UE)源码本身免费提供,
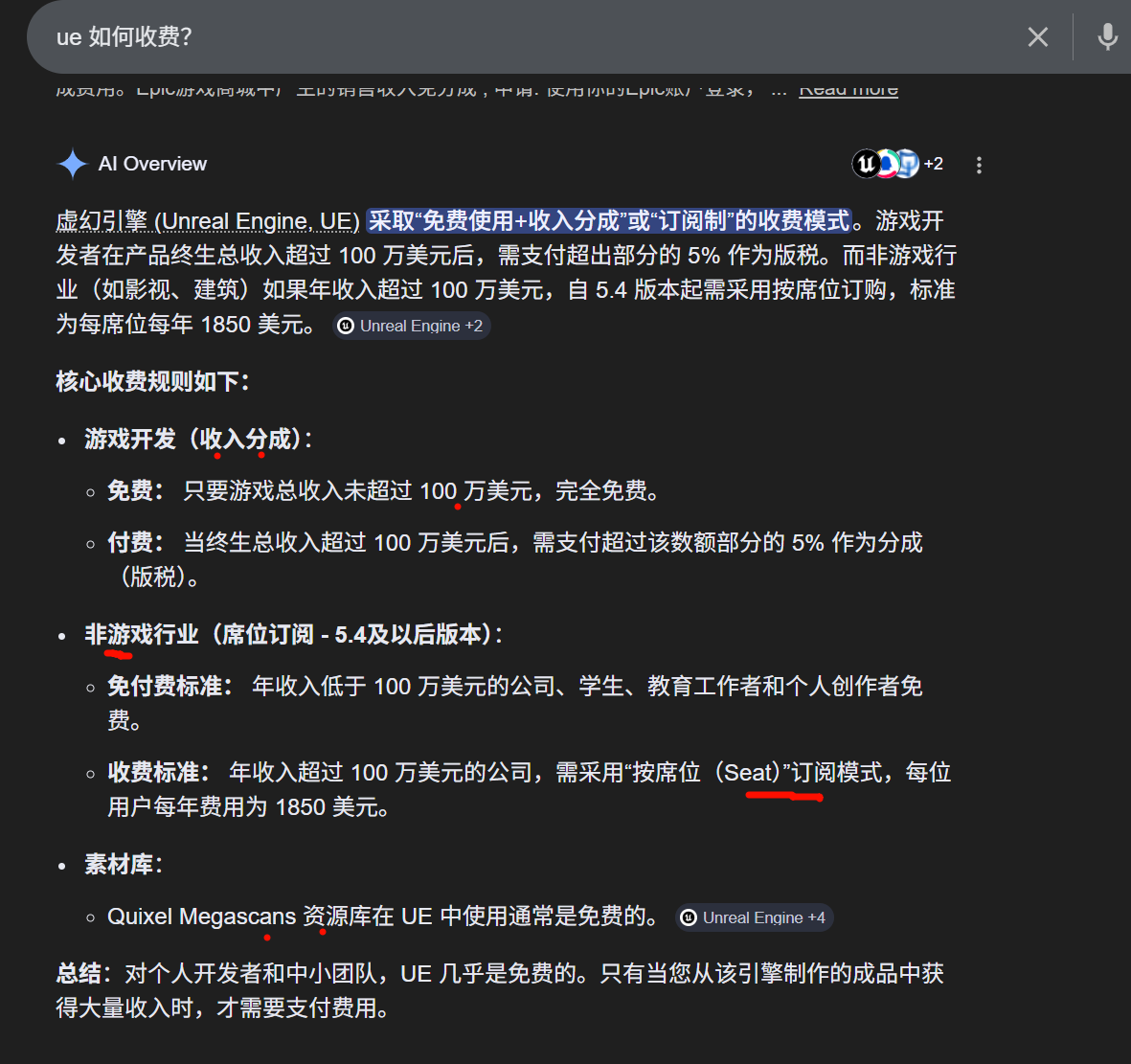
-
长期在 UE 官方中文直播 / 技术分享 中讲解引擎内部机制 Cnblogs
-
在知乎、B站等平台发布 UE 架构分析内容
-
真正的进阶不只是"看源码",而是 重写小型系统 。
从时间投入角度讲,图形工程师最值得花时间深挖的源码模块通常是这五个:
-
Render Graph
-
Scene / draw submission system
-
Renderer frame pipeline
-
Shader compile pipeline
-
RHI / DX12 backend
这五个基本覆盖:
overflow-visible!engine → GPU
frame → pass
scene → draw
shader → pipeline
resource → memory理解这五个系统,你基本就掌握了一个现代实时渲染引擎的核心结构。
RHI(Render Hardware Interface,渲染硬件接口)是虚幻引擎(UE)中连接上层渲染逻辑与底层图形API(如DirectX、Vulkan、Metal)的中间抽象层 。它封装了各平台图形API的差异,使UE开发者能通过统一接口实现跨平台渲染,同时负责资源管理(Shader、纹理、顶点数据)和命令执行。Unity 中也有完全类似的概念,虽然名字和架构稍有不同。在 Unity 的底层源码和性能分析器中,对应的术语通常是 GfxDevice。
Unity GfxDevice
Unity 中也有完全类似的概念,虽然名字和架构稍有不同。在 Unity 的底层源码和性能分析器中,对应的术语通常是 GfxDevice。
以下是 Unity 中与 UE RHI 对应的几个核心层面:
1. 底层接口:GfxDevice
GfxDevice 是 Unity 内部对不同图形 API(如 DirectX, Vulkan, Metal, OpenGL)的底层抽象层,功能与 UE 的 RHI 几乎一致。 1, 2
- 屏蔽差异:它负责将 Unity 通用的渲染命令翻译成具体显卡驱动能听懂的指令。
- 报错提示:如果你在 Unity 控制台看到
GfxDevice: device lost或相关的驱动报错,这通常就对应着 UE 里的 RHI 崩溃或重置。 3
2. 线程架构:RenderThread (渲染线程)
和 UE 类似,Unity 也采用多线程渲染架构: 4
- Main Thread (主线程):负责逻辑和准备渲染数据。
- Render Thread (渲染线程):持有真正的 GfxDevice 实例。它接收主线程发来的高层命令,调用 GfxDevice 接口生成最终的 GPU 指令。
3. 用户层面的"渲染控制":SRP (Scriptable Render Pipeline)
虽然 GfxDevice 是最底层的对应物,但 Unity 近几年推行的 SRP (脚本化渲染管线)(包括 URP 和 HDRP)在职责上涵盖了 UE 渲染架构中更靠上的部分: 5, 6
- URP (通用渲染管线):侧重于性能和跨平台(类似 UE 的移动端渲染路径)。
- HDRP (高清晰渲染管线):侧重于极高画质(类似 UE 的 Lumen/Nanite 级别追求)。
- Command Buffers:Unity 允许开发者通过 CommandBuffers 直接向底层发送渲染指令,这种操作逻辑非常接近于在 UE 中直接写 RHI 命令。 7, 8
总结对比
特性 Unreal Engine (UE) Unity 底层 API 抽象层 RHI (Render Hardware Interface) GfxDevice 渲染命令封装 FRHICommandList CommandBuffer / ScriptableRenderContext 多线程执行 RHI Thread Render Thread (Worker Thread) 如果你在 Unity 中进行 Profiler (性能分析),关注 "Gfx.PresentFrame" 或 "Gfx.ProcessCommands" 的耗时,其意义就等同于在 UE 里排查 RHI 线程 的瓶颈。 9
如果您想进一步了解如何手动控制底层渲染,我可以为您讲解 Unity 的 ScriptableRenderContext 或是底层 Native Graphics Plugin API 的用法。
3 https://discussions.unity.com
UE 的 RHI,本质上是一个更明确的 Rendering Hardware Interface。它长期就是作为 UE 渲染器和底层 API 之间的正式边界存在的。上层有 Render Graph / Renderer / Mesh Draw Command / PSO 管线组织,下层有 D3D12/Vulkan/Metal 等,RHI 负责资源、命令列表、管线状态、同步原语等的统一抽象。
Unity 的 GfxDevice 虽然也承担后端设备抽象职责,但它在历史上更像是 Unity 整体图形子系统中的"设备层实现核心",它不是一个和 UE-RHI 那样在架构概念上高度显式、强语义隔离的"渲染硬件接口层"品牌化边界。Unity 内部还有 GfxDeviceClient、GfxContext、CommandBuffer、SRP Native bridge、Graphics jobs、平台后端等多层协作,GfxDevice 常常更偏"后端设备执行核心",而不是唯一的抽象中枢。
所以两者都像"驱动适配层",但 UE 的 RHI 更像一个完整的硬件接口架构层 ,Unity 的 GfxDevice 更像图形设备后端核心对象,在整体引擎中的职责包边方式不完全对齐。
表面上二者都会做这些事:
-
创建/销毁纹理、buffer、RT
-
设置 pipeline / shader / descriptor
-
录制 draw / dispatch / copy / barrier
-
提交 command list / queue
-
处理 swapchain / backbuffer / present
这一层当然是"共性逻辑",因为任何现代引擎对 D3D12/Vulkan/Metal 都绕不开这些。
但关键差异在于:
这些动作是谁生成的、何时生成的、以什么粒度缓存和重排、在哪一层做状态归并与最小化提交。UE 更典型的是:
-
上层渲染器构建 pass 和 draw command
-
大量 PSO / shader binding / mesh draw command 的预组织发生在 RHI 之上
-
RHI 下面更强调平台无关命令接口和资源接口
-
FRHICommandList / DynamicRHI / 各平台 RHI 分层明确
-
新版 RDG 会把资源依赖、pass 调度、barrier 需求前推到更高层做统一分析
Unity 则更容易出现这种特征:
-
Camera / Renderer / SRP / CommandBuffer / RenderGraph(新管线)共同形成命令来源
-
GfxDevice 在实际后端落地时往往承担更多具体设备状态和资源执行细节
-
历史包袱更多,兼容 Built-in / SRP / 编辑器 / 多平台 runtime 的路径复杂度较高
-
某些状态整理、资源上传、主线程与渲染线程桥接逻辑,会更深地和引擎 runtime 生命周期耦合
所以"最终都发出 DrawIndexedInstanced/Dispatch/ResourceBarrier"不代表主要逻辑相同。很多真正复杂的价值,恰恰不在这些 API 调用本身,而在调用前的组织与约束系统。
SRP = 渲染流程与策略层
GfxDevice = 图形 API 设备执行层
两者关系更像"上层调度者"和"底层执行者",不是并列替代关系。
把它放进 Unity 的分层里看,会比较清楚:
C# SRP(URP/HDRP/自定义 RP)
→ CommandBuffer / RenderGraph / ScriptableRenderContext
→ Native graphics bridge
→ GfxDevice
→ D3D11 / D3D12 / Vulkan / Metal / GL
→ Driver / GPU
SRP 关心的是 frame graph、render policy、render scheduling。




Unity 的 GfxDevice 架构其实比 UE RHI 更"硬绑定引擎生命周期",这才是为什么 Unity 不愿意开源那一层。很多团队即使在 UE,也不会轻易动 RHI。
原因一样:
维护成本。
一旦改:
-
每个版本 merge
-
平台 SDK 更新
-
driver workaround
-
QA 成本
都会增加。
你圈的这些底层概念:
- GfxDevice 资源管理
- barrier 逻辑
- swapchain 逻辑
- render thread 调度
- descriptor heap / command list 分配策略 / PSO cache
这些属于 Unity 引擎核心,公开仓库里通常没有完整实现源码。
官方公开内容更多是:
- C# 层调用逻辑
- Native Plugin 接口
- SRP 包源码
- 少量参考源码
但 D3D11/D3D12/Vulkan/Metal backend 的 Unity 内部实现本体,不是公开的。
https://github.com/Unity-Technologies/Graphics
https://docs.unity3d.com/cn/2022.3/Manual/low-level-native-plugin-memory-manager-api.html
https://github.com/Unity-Technologies/NativeRenderingPlugin
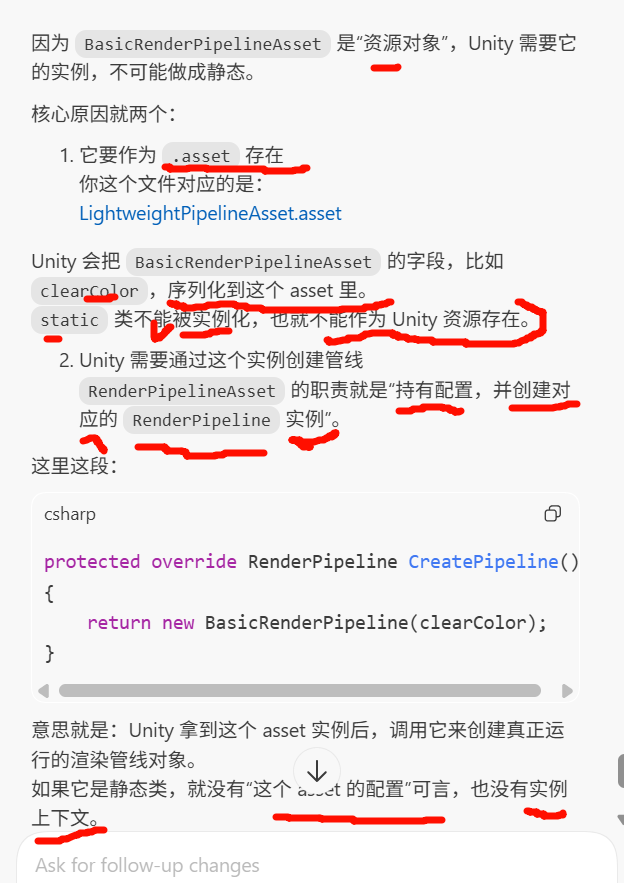
Unity 的 Scriptable Render Pipeline 最底层其实只有两类核心对象:
-
RenderPipelineAsset
-
RenderPipeline
这两个就是 SRP 的基础结构。
它们的关系是:
RenderPipelineAsset
→ 负责 配置 + 创建 RenderPipeline 实例
RenderPipeline
→ 负责 真正执行每一帧渲染
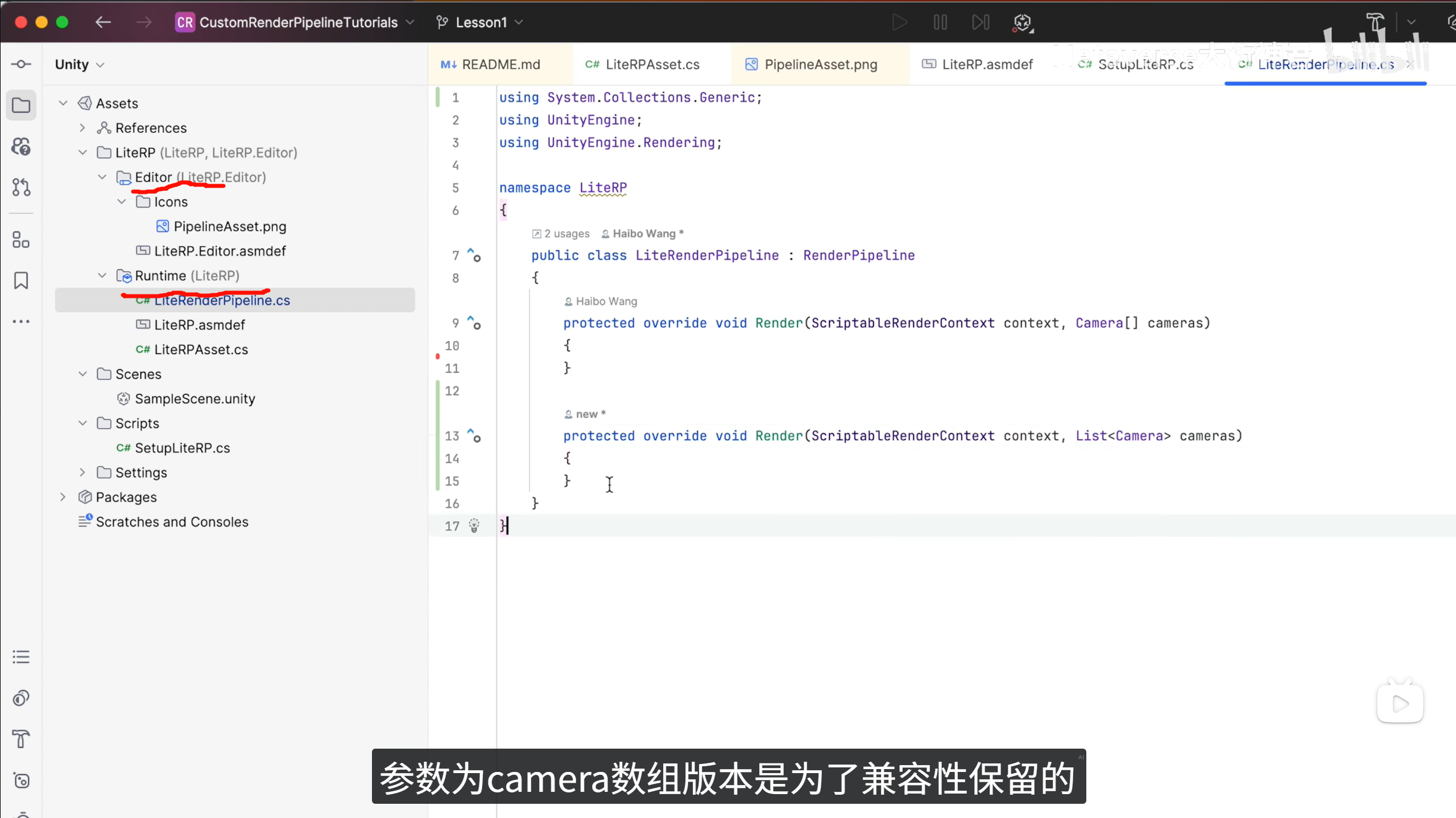
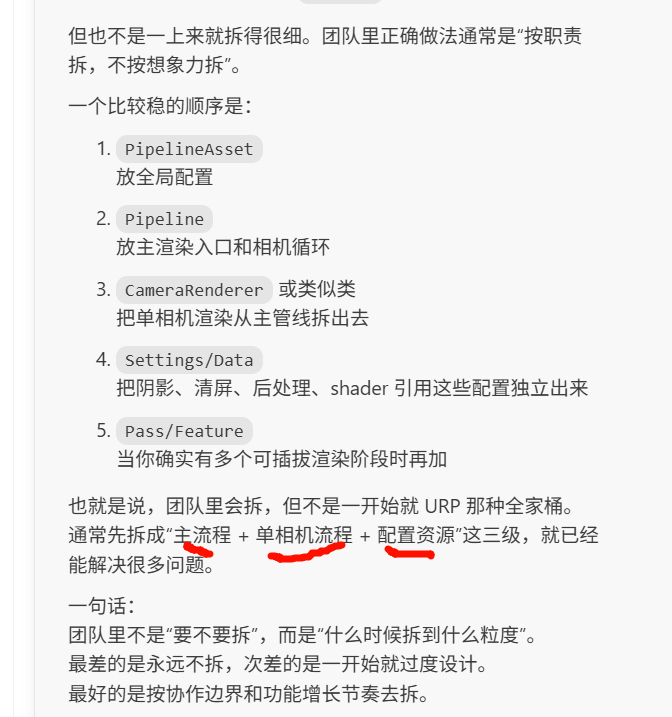
所以你的 LiteRP 结构本质就是:
overflow-visible!LiteRPAsset.cs // RenderPipelineAsset
LiteRenderPipeline.cs // RenderPipeline这两个是最小 SRP 必备。
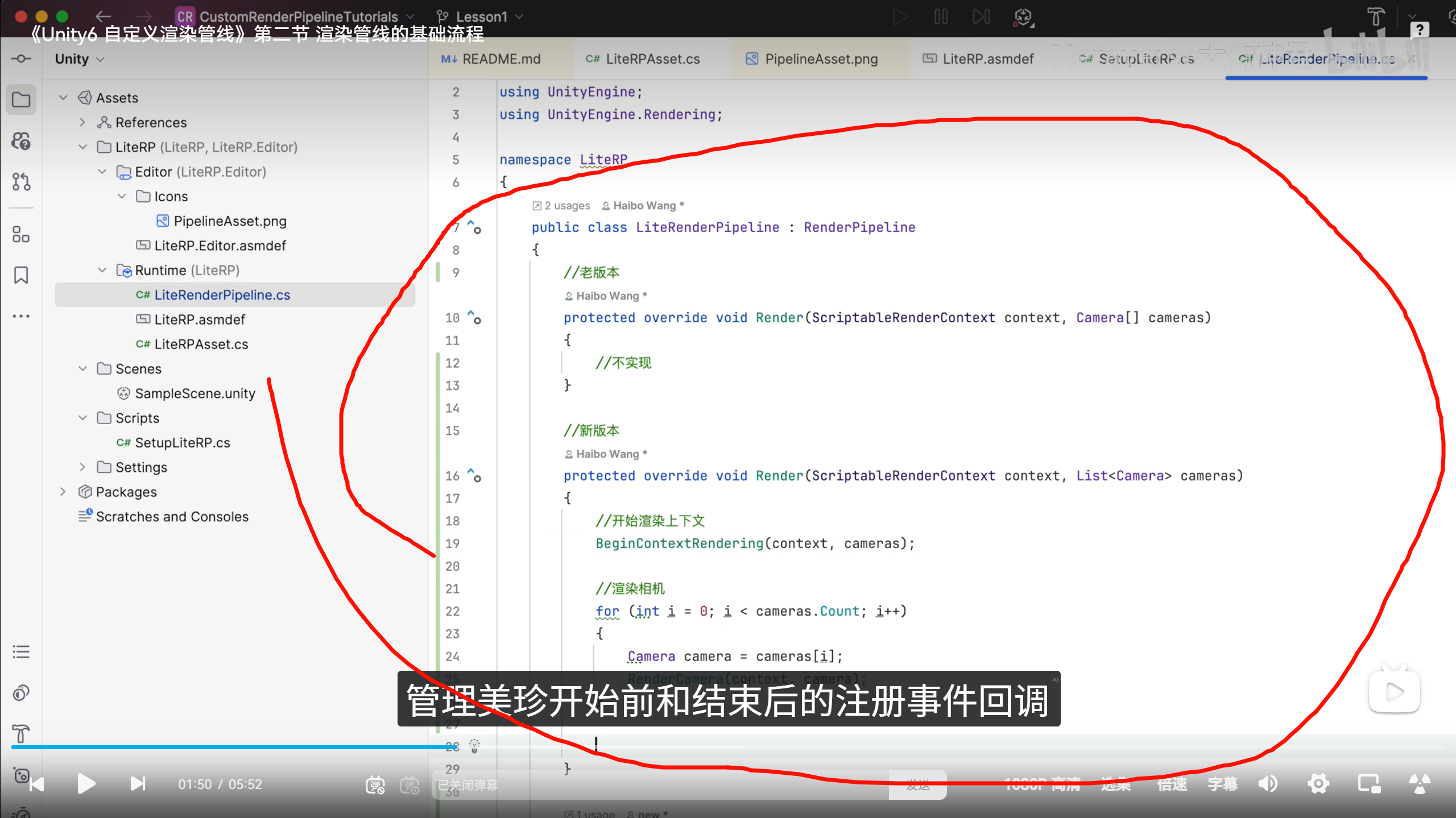
再看你截图里的
LiteRenderPipeline.cs。你继承的是:
overflow-visible!public class LiteRenderPipeline : RenderPipeline
然后实现:
overflow-visible!protected override void Render(ScriptableRenderContext context, List<Camera> cameras)
或者旧版本:
overflow-visible!protected override void Render(ScriptableRenderContext context, Camera\[\] cameras)
这两个函数的意义是:
Unity 每一帧会调用 Render(),把当前需要渲染的 camera 列表交给你的 pipeline。
然后你需要在里面做所有事情,例如:
-
camera sorting
-
culling
-
设置 render target
-
draw opaque
-
draw skybox
-
draw transparent
-
post process
-
submit context
所以 Render() 就是整个管线的入口。
LiteRP 项目结构其实也挺标准的:
overflow-visible!LiteRP
├─ Editor
│ └─ LiteRP_Editor.asmdef
│
├─ Runtime
│ ├─ LiteRenderPipeline.cs
│ ├─ LiteRPAsset.cs
│ └─ LiteRP.asmdef其中:
Runtime
→ 真正运行时渲染逻辑
Editor
→ inspector / pipeline asset GUI 等
把 SRP 最小结构画出来,其实就是:
overflow-visible!RenderPipelineAsset
│
▼
RenderPipeline (每帧执行)
│
▼
Render(context, cameras)
│
▼
for camera in cameras
├─ Culling
├─ Setup Camera
├─ Draw Opaque
├─ Draw Skybox
├─ Draw Transparent
└─ SubmitURP / HDRP 其实只是把这个流程扩展成了很多模块:
URP 内部结构大致是:
overflow-visible!UniversalRenderPipelineAsset
│
▼
UniversalRenderPipeline
│
▼
ScriptableRenderer
│
▼
ScriptableRenderPass所以你现在这个 LiteRP,其实是 SRP 最原始那一层。
帅啊,

很多人第一次写 SRP 会忽略的点。
RenderPipeline 本身是"全局的",不是 per camera。
也就是说:
overflow-visible!一个 RenderPipeline
渲染 多个 Camera所以你会看到函数签名是:
overflow-visible!Render(context, List<Camera> cameras)
而不是:
overflow-visible!Render(context, Camera camera)

自定义整个 SRP ,
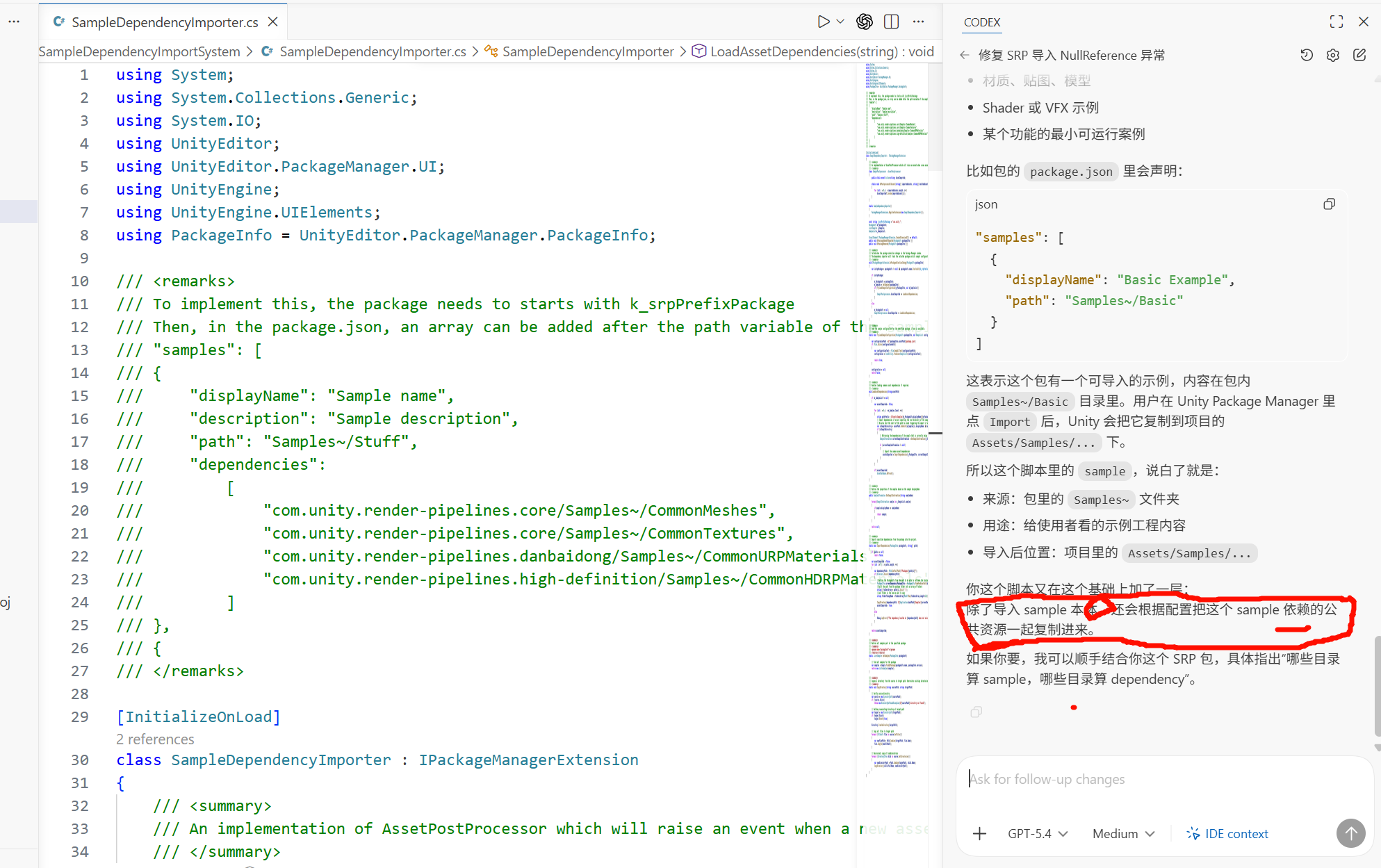
ScriptableRenderContext仍然是底层核心入口,Unity 6 也没有把它废掉。官方文档对ScriptableRenderContext的定义仍然是:你在自定义RenderPipeline时,用它来调度和提交状态更新与绘制命令;典型流程仍然包括DrawRenderers、ExecuteCommandBuffer,最后Submit。只是 URP Render Graph 模式下,你通常不再到处手搓传统
CommandBuffer+SetRenderTarget+Blit那套流程,而是优先在 render graph pass 里声明资源依赖、attachments 和执行函数。旧式 URP/Compatibility Mode 的思维是:
-
我拿一个
CommandBuffer -
我手工
SetRenderTarget -
我手工
Blit -
我自己保证这个 RT 什么时候创建、什么时候释放、前后依赖对不对
Unity 6 推荐的 URP Render Graph 思维是:
-
我声明这个 pass 读哪些 texture、写哪些 texture
-
我声明 color/depth attachment
-
我在 pass 回调里做绘制
-
图系统帮我推导资源生命周期、同步关系和部分优化
所以不是"不用写渲染命令",而是 从"命令式编排"往"声明式编排"迁移。
你如果是从工程实践角度问"我以后还要不要碰
context/command buffer",答案要分场景:如果你在做 完整自定义 SRP :
还是要。
context是主入口,CommandBuffer仍然是底层工具之一。在做 Unity 6 的 URP 新功能扩展 :
通常优先学 Render Graph;很多场景下你不会再直接围绕传统
Execute(CommandBuffer)去组织整个 feature,但并不代表命令缓冲概念消失。官方还专门提供了 Render Graph 内部的 command-buffer 接口。
static,竟是如此💃
SRP 提供的是底层抽象:
RenderPipelineAsset
RenderPipeline
ScriptableRenderContext
Cull、Draw、CommandBuffer、RendererList 这些 API
它没规定你必须有:
Renderer Data
Renderer Feature
Forward Renderer
Universal Renderer Data
这种资源组织方式
这些是 URP 在 SRP 之上自己搭出来的一层"产品化结构"。
所以你记得的 Render Data,本质上是:
不是 SRP 天生自带
而是 URP 为了可配置、可扩展、可在 Inspector 里管理渲染器行为,额外设计出来的资产层
- 如果只有一个 RenderPipelineAsset + RenderPipeline,你每改一次渲染行为都要改 C#。
但项目里很多需求其实更适合做成资源配置,比如:
阴影开关
后处理开关
Renderer feature 开关
深度纹理、Opaque Texture、排序策略
URP 的 Renderer Data 就是把这些东西变成可保存、可切换、可复用的 asset。
- 一个管线下支持多种 Renderer 方案
同一个 URP 管线里,可能既要:
普通 3D Forward Renderer
2D Renderer
特殊相机用的 Renderer
如果所有逻辑都塞进一个 RenderPipeline 类,代码会越来越肿。
所以 URP 把"管线级配置"和"具体怎么渲染某类相机/场景"拆开了。
Pipeline Asset 管总体配置
Renderer Data 管具体渲染器实现
配置和逻辑耦死
非程序人员无法参与
TA、美术、关卡没法安全地去改一个主管线脚本。
他们需要的是 asset、Inspector、可视化开关,不是进代码里改 if。
不容易做:
A 相机用一套流程
B 相机用另一套流程
空间浪费
没有配置层和拆分层,只能不停加 if/else
"全在一个文件里好找",通常会变成"全在一个文件里大家都在抢"。
-