关联:把上一个接口返回的数据提取出来,传给下一个接口使用
JSON 优先用 JSON 提取器,XML/HTML 优先用 XPath提取器,仅当格式混乱时用正则提取器
Xpath提取器
常用于接口返回是 XML / HTML 格式,json一般不用
添加路径:右键http请求添加-后置处理器-XPath处理器
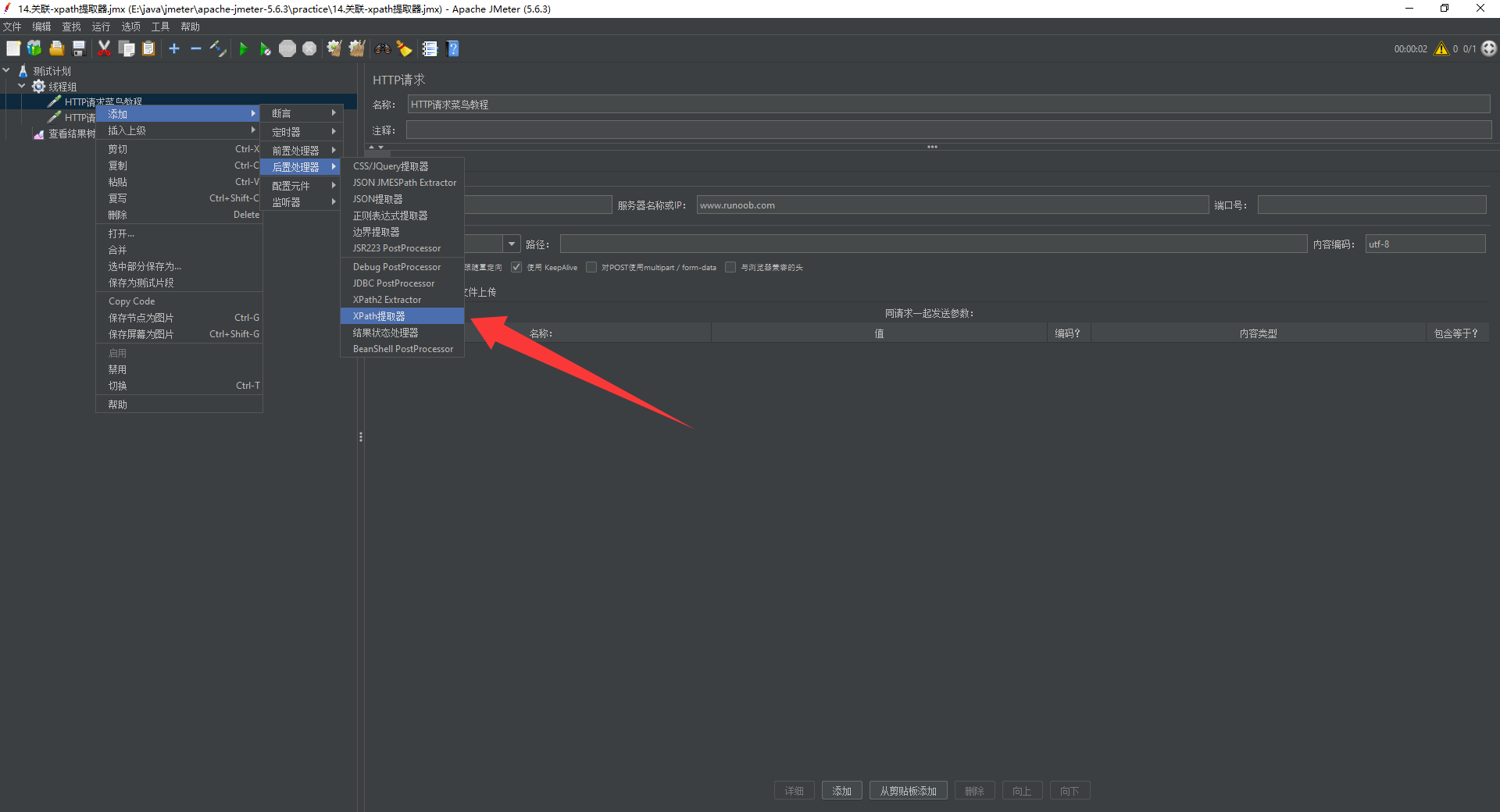
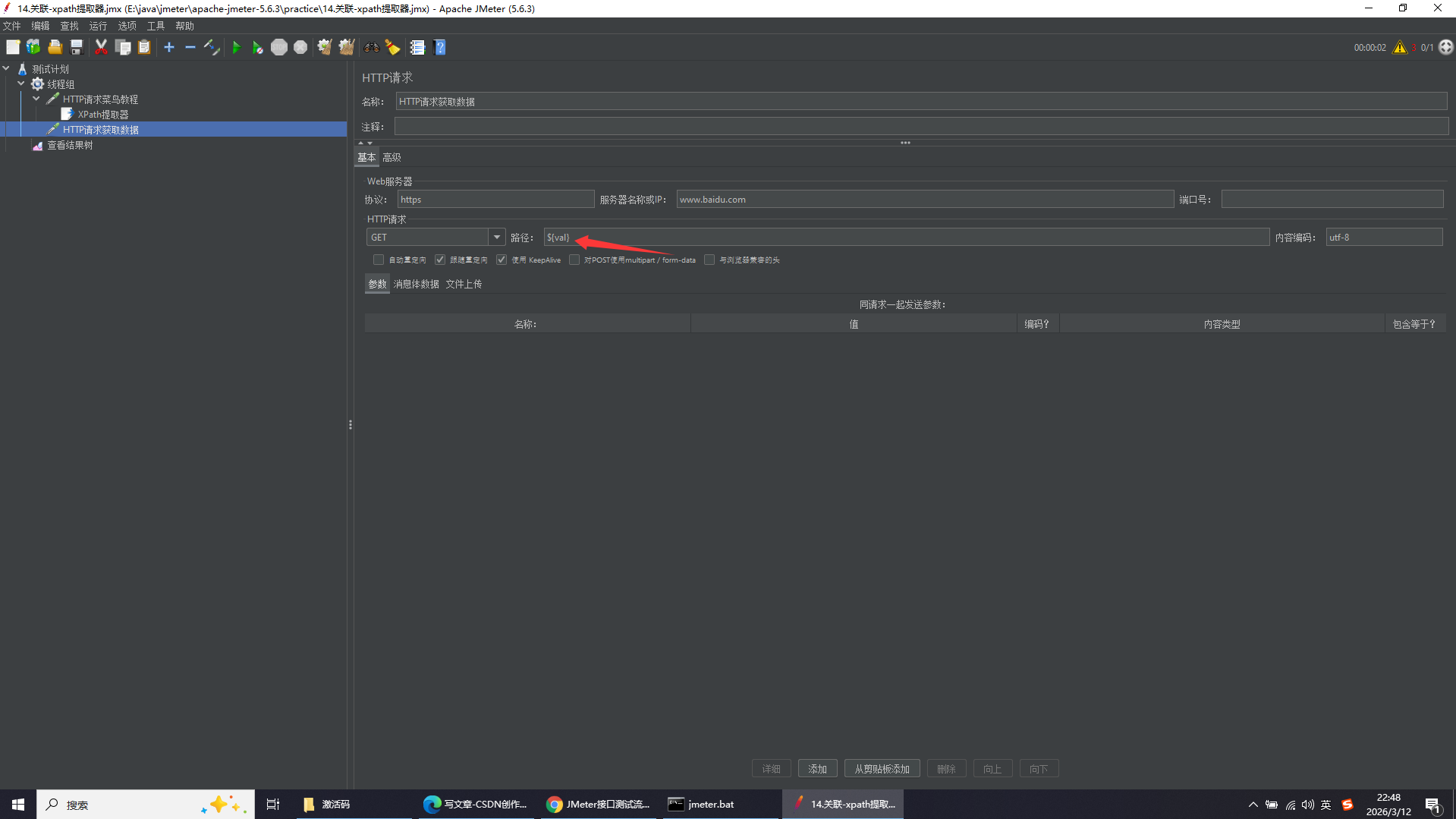
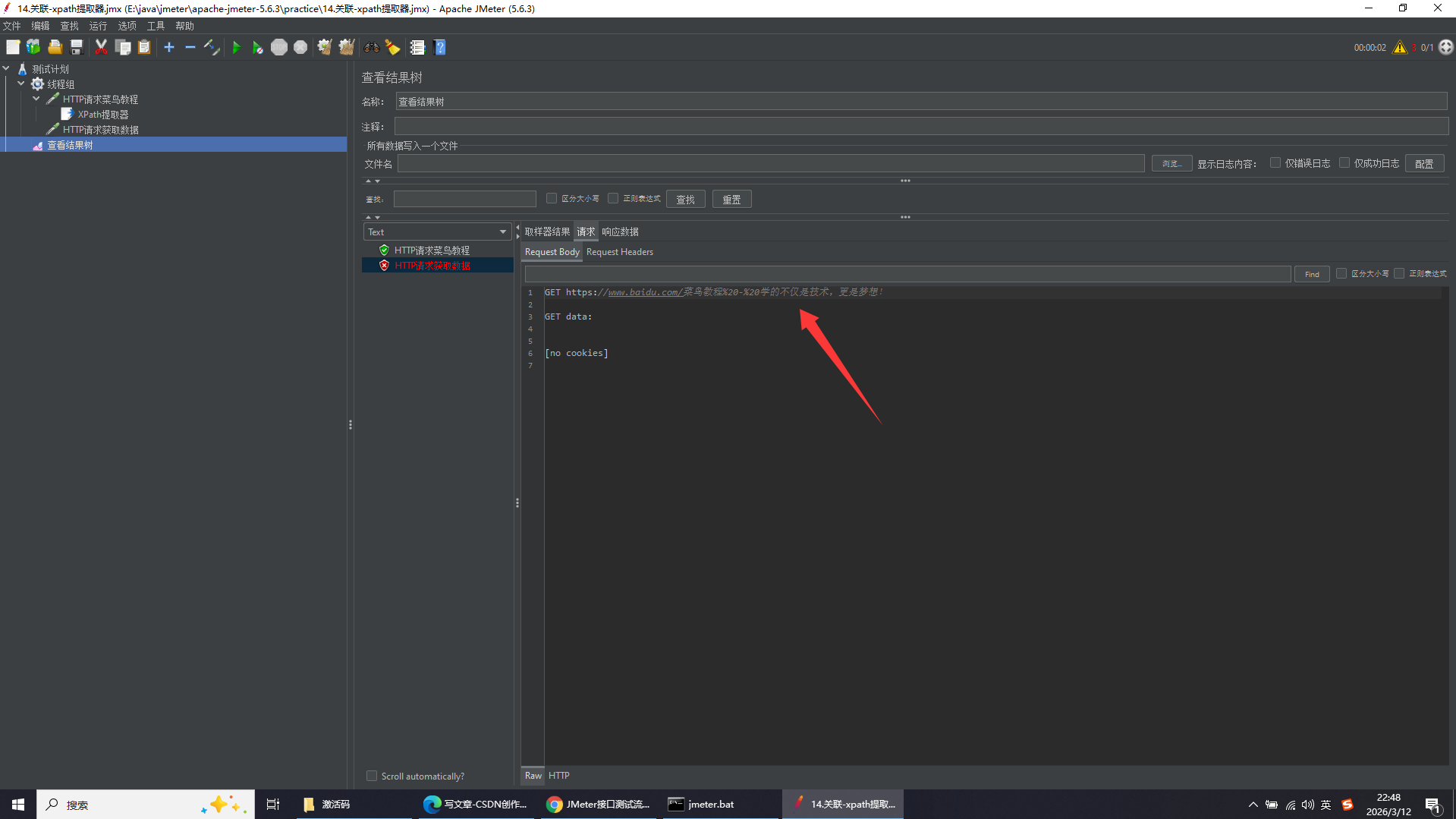
实操:访问菜鸟教程首页,并提取title内容
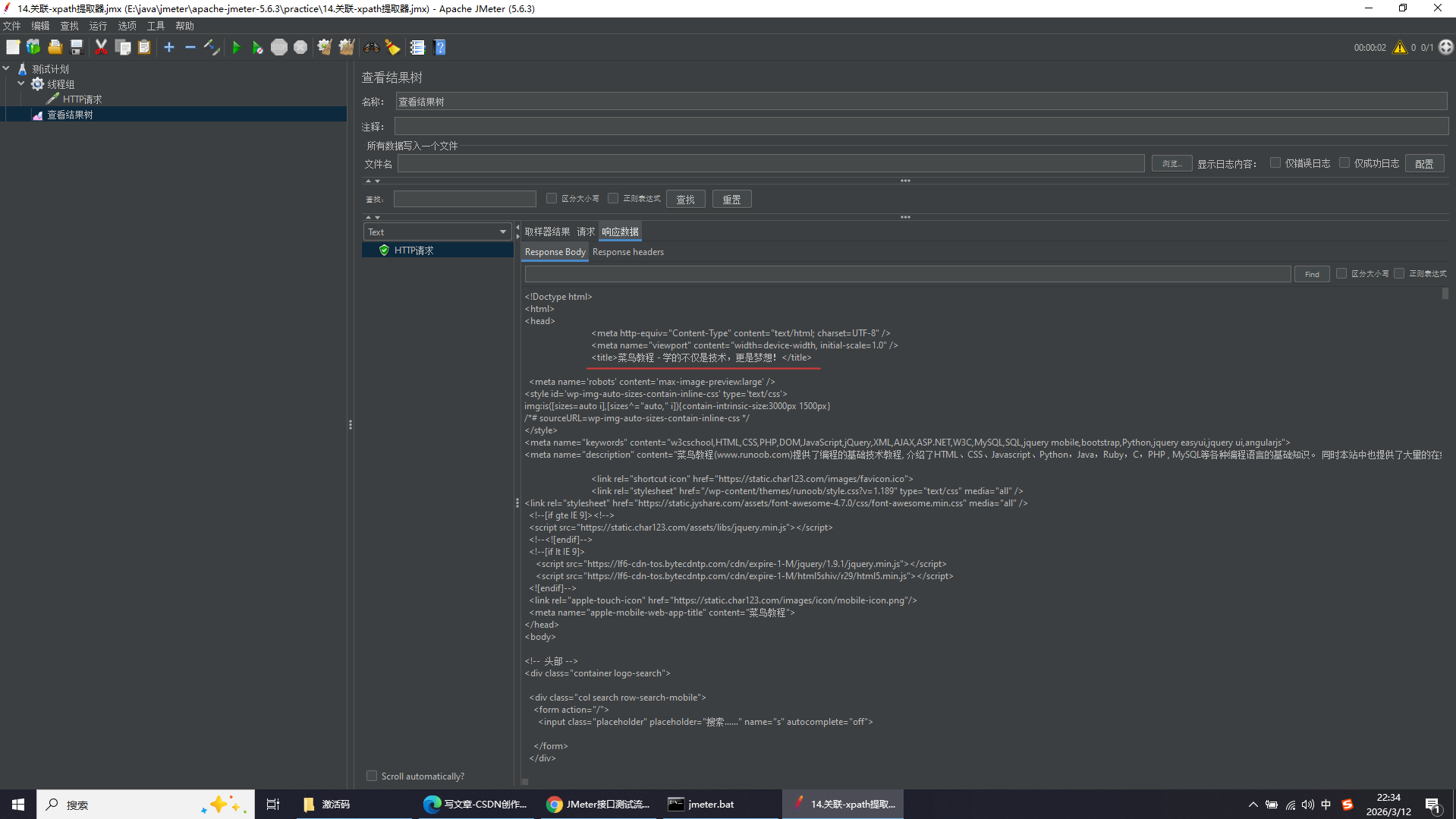
注意:HTML 不是标准 XML,JMeter 原生 XPath 不能直接解析,必须用 Tidy 把 HTML 转成标准 XML 才能正常提取。即返回是HTML网页,则必须勾选Use Tidy,返回是标准XML,则无须勾选。
因为返回的是HTML网页数据,所以勾选Use Tidy,下方填写内容为获取第一个title标签的文本内容,并将其赋予变量val,若不存在则将val变量的值设为无数据
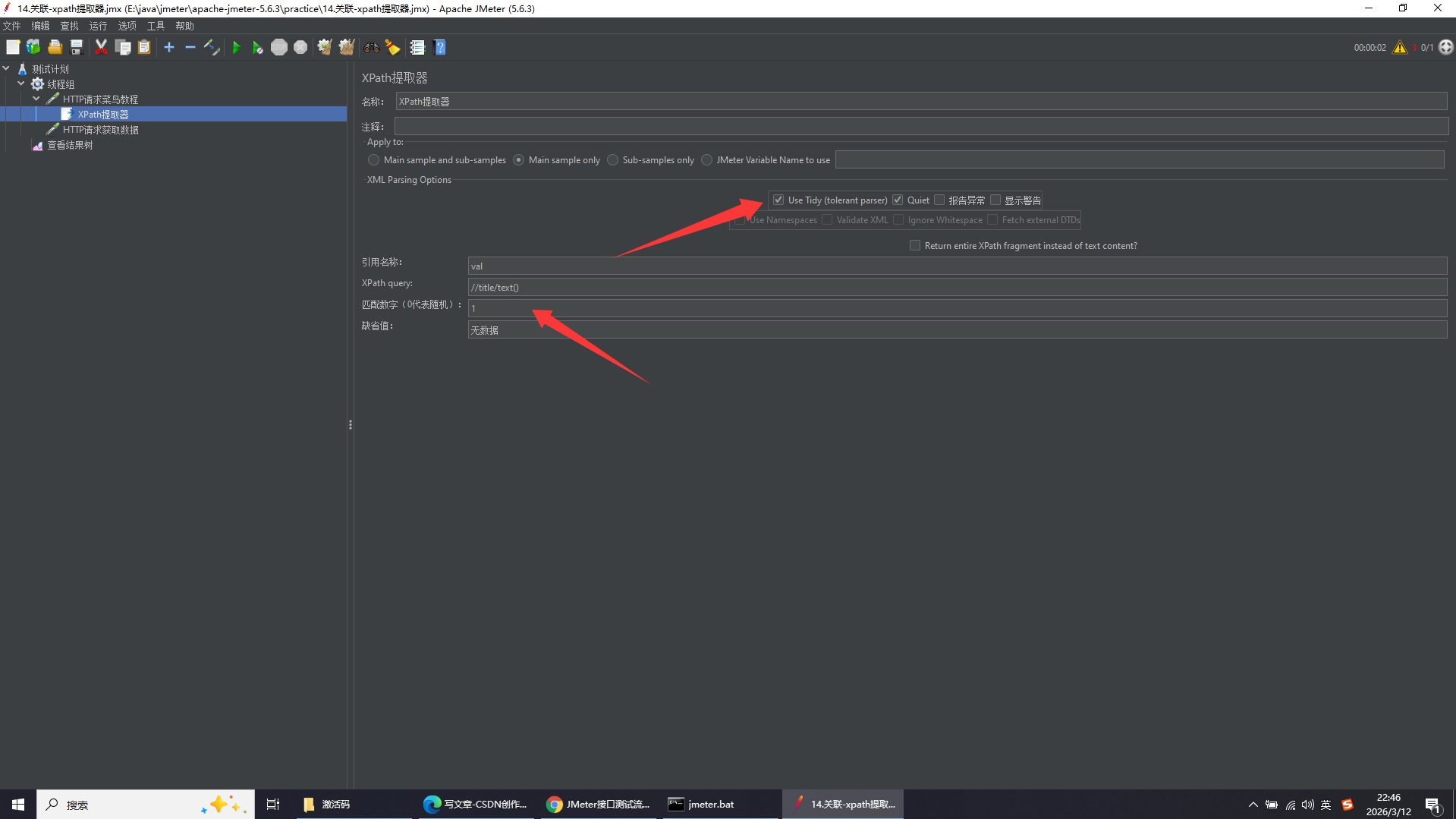
xpath常用提取语句
示例xml代码
<response>
<code>200</code>
<msg>操作成功</msg>
<data sessionId="sess_123456">
<user id="1001" name="张三">
<order id="order_001" status="paid">
<price>99.9</price>
</order>
<order id="order_002" status="unpaid">
<price>199.9</price>
</order>
</user>
</data>
</response>|-------------------|----------------------------------|------------------------------------------|----------------------|
| 获取某一标签的内容 | 提取指定code的内容 | //response/code/text() | 精准定位标签层级使用 / 拼接访问路径 |
| 获取所有此标签内容 | 提取任意code的内容 | //code/text() | 直接//标签名提取 |
| 获取标签的属性值 | 提取data标签的sessionId属性 | //response/data/@sessionId | 定位标签后使用@获取属性值 |
| 获取指定标签的属性值 | 提取第一个order标签的id属性 | //order1/@id | \[\]索引从1开始 |
| 属性满足某一条件的标签值 | 提取 status=paid 的 order 下的price内容 | //order@status = 'paid'/price/text() | 属性筛选后提取 |
| 获取某一标签下值满足某条件的属性值 | 提取price大于100的order的id属性 | //orderprice\>100/@id | 按子节点的值筛选 |
| 模糊匹配属性值 | 包含姓张的user标签id属性值 | //usercountains(@name,'张')/@id | \[\]录入条件,countains包含 |
示例HTML代码
<html>
<body>
<div class="login-box">
<input type="text" id="username" value="test001">
<button id="submit-btn">登录</button>
<a href="/user/1001">我的主页</a>
</div>
</body>
</html>|-------------------------|---------------------------------|-------------------------------------|------------------------------|
| 获取某一标签下某一属性等于一个值的的另一属性值 | 提取id=username1的input标签的value属性值 | //input@id = 'username/@value | 通过id属性值精准匹配input标签获取value属性值 |
| 精准匹配某一标签的文本内容 | 获取id=submit-btn的button文本内容 | //buttonid="submit-btn"/text() | 通过id属性值精准匹配button标签来获取文本内容 |
| 模糊匹配某一标签的属性值 | 获取内容包含"我的"的a标签的href属性值 | //acountains(text(),'我的')/@href | 通过文本内容模糊匹配a标签来获取href属性值 |
- 层级控制 :
//:全局查找(忽略层级,最常用);/:精准层级(如/response/data/user,只找 response 下的 data 下的 user)。
- 筛选逻辑 :
[@属性名='值']:精准匹配属性;contains(@属性名,'关键词'):模糊匹配;[索引]:取第 N 个元素(索引从 1 开始,不是 0)。
- 文本 / 属性区分 :
text():提取标签内的文本;@属性名:提取标签的属性值。
正则表达式提取器
正则表达式提取器是 JMeter 中通用的文本提取工具,可从任意格式响应文本(HTML/JSON/ 纯文本 / XML)中提取目标数据,核心解决「非结构化 / 混合格式文本」的关联问题(JSON 优先用 JSON 提取器,XML/HTML 优先用 XPath,仅格式混乱时用正则)。
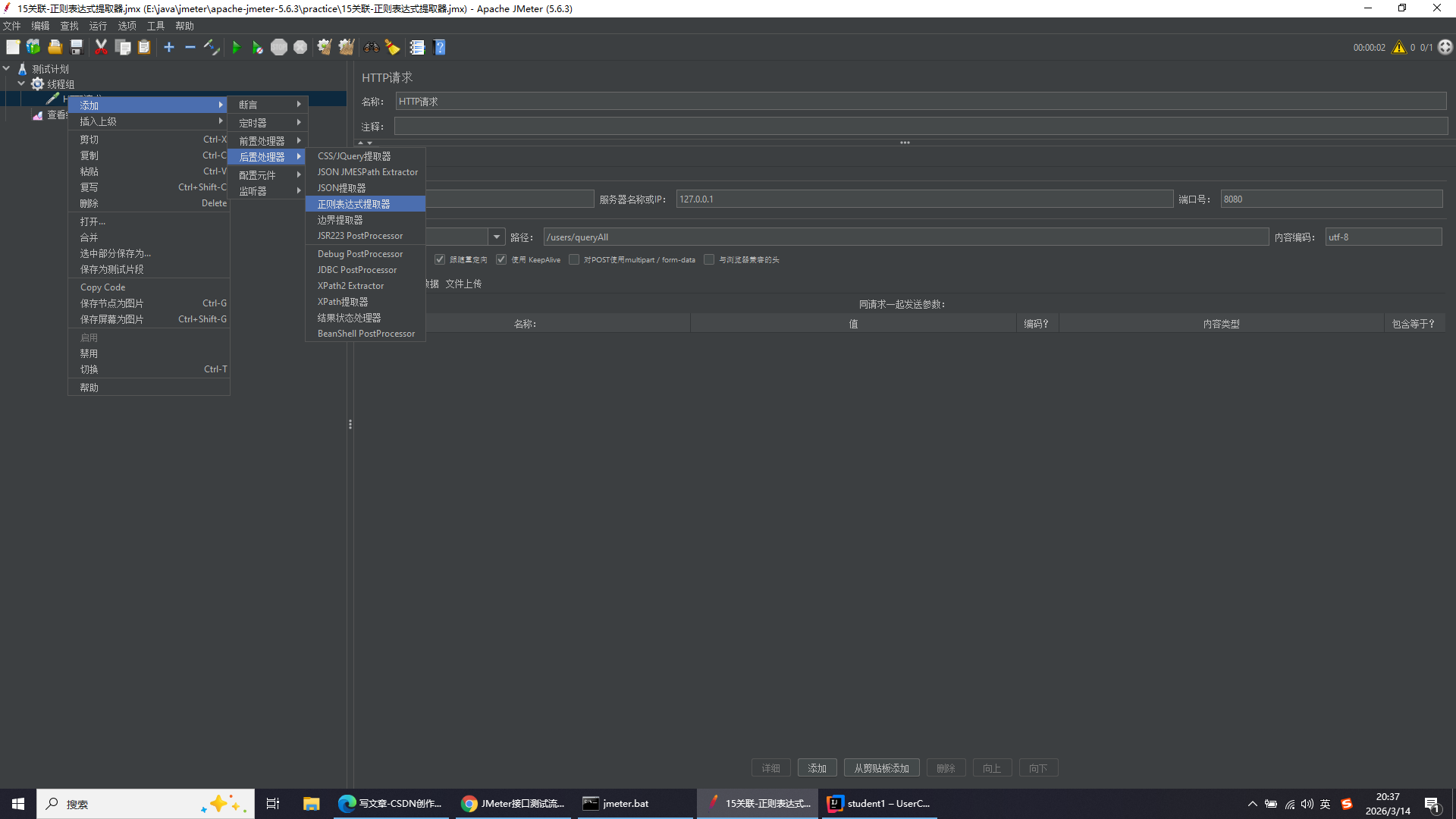
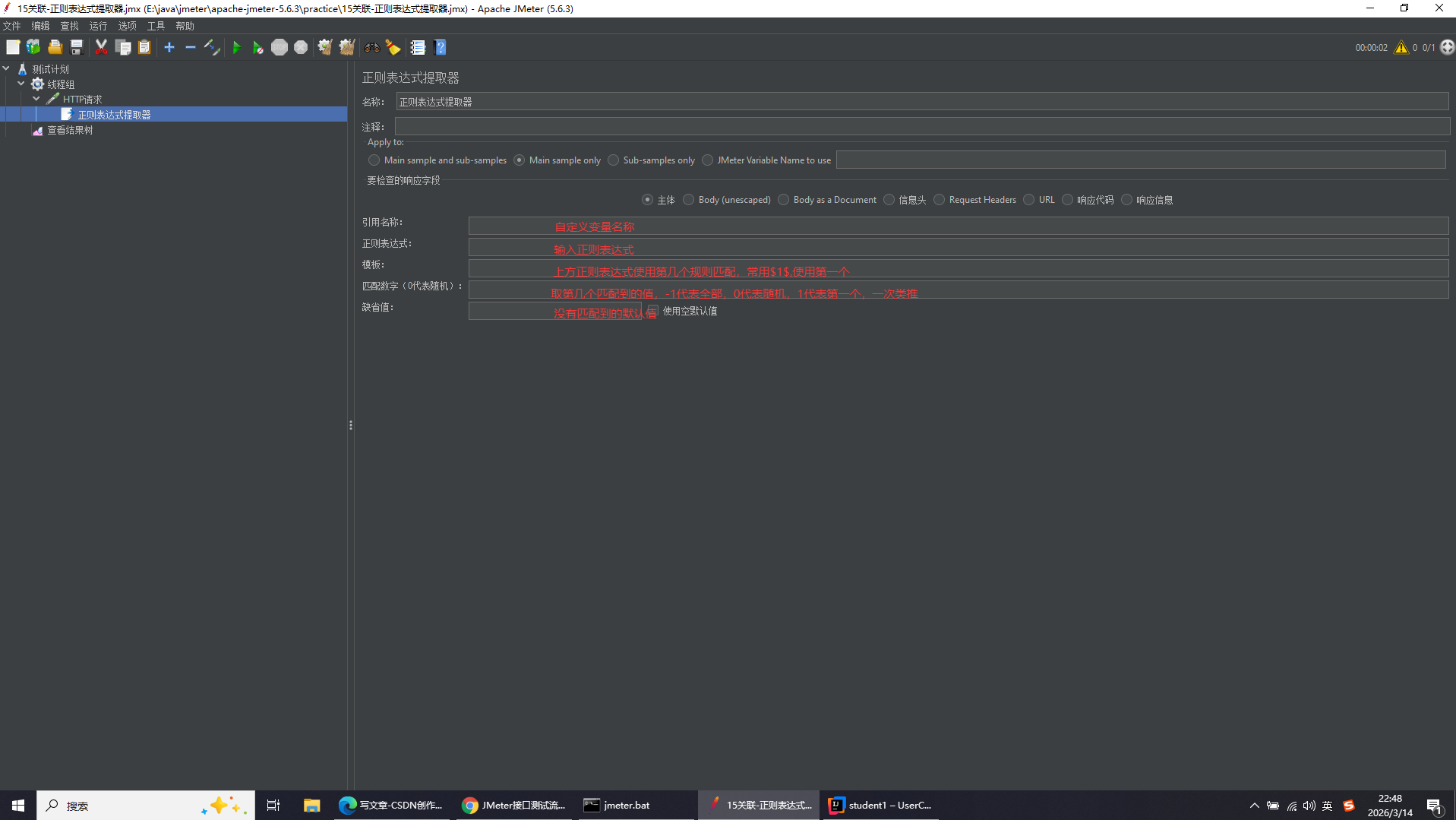
添加路径:http请求右键添加-后置处理器-正则表达式提取器
取这个json字符串中的"张三"
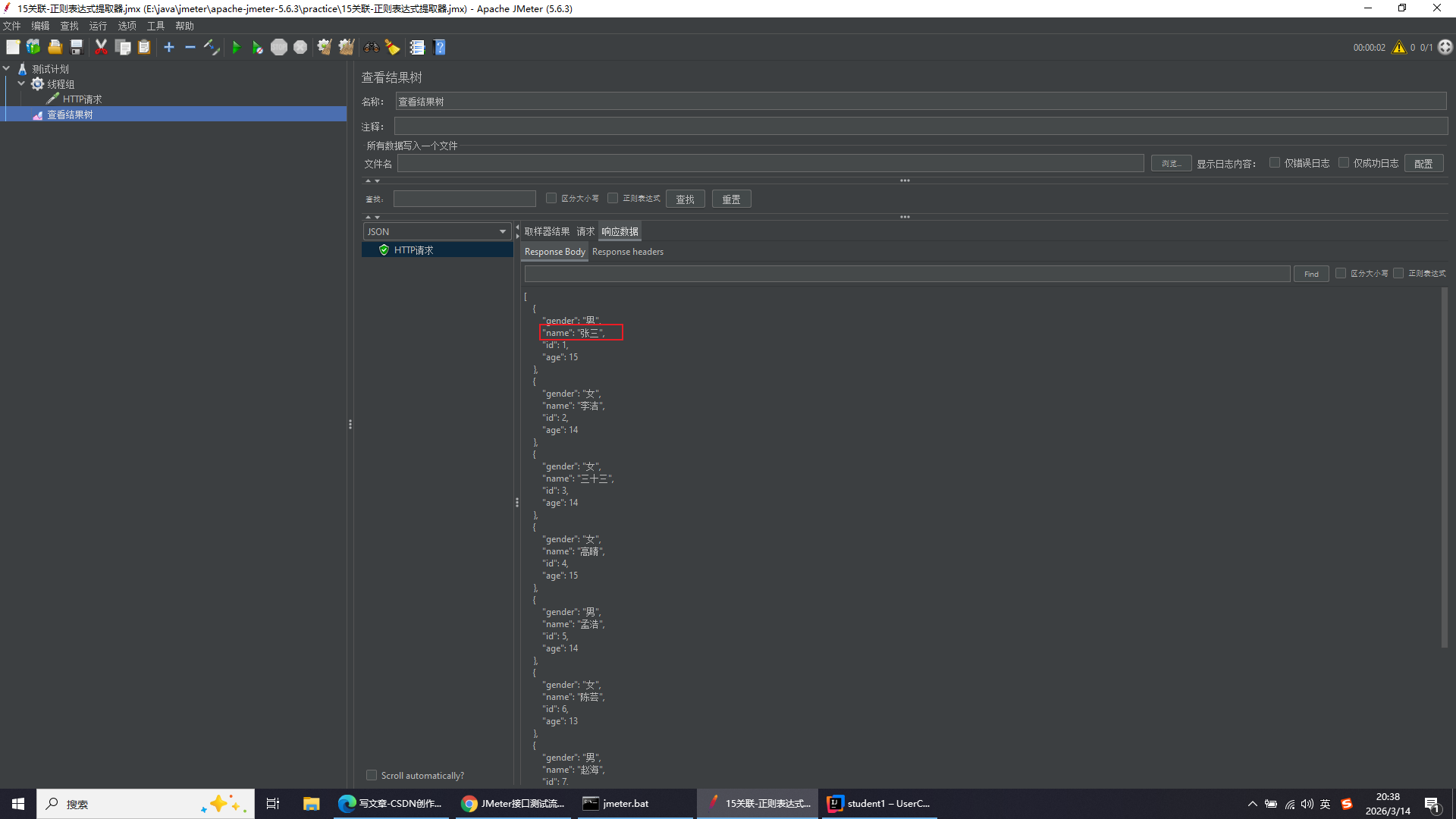
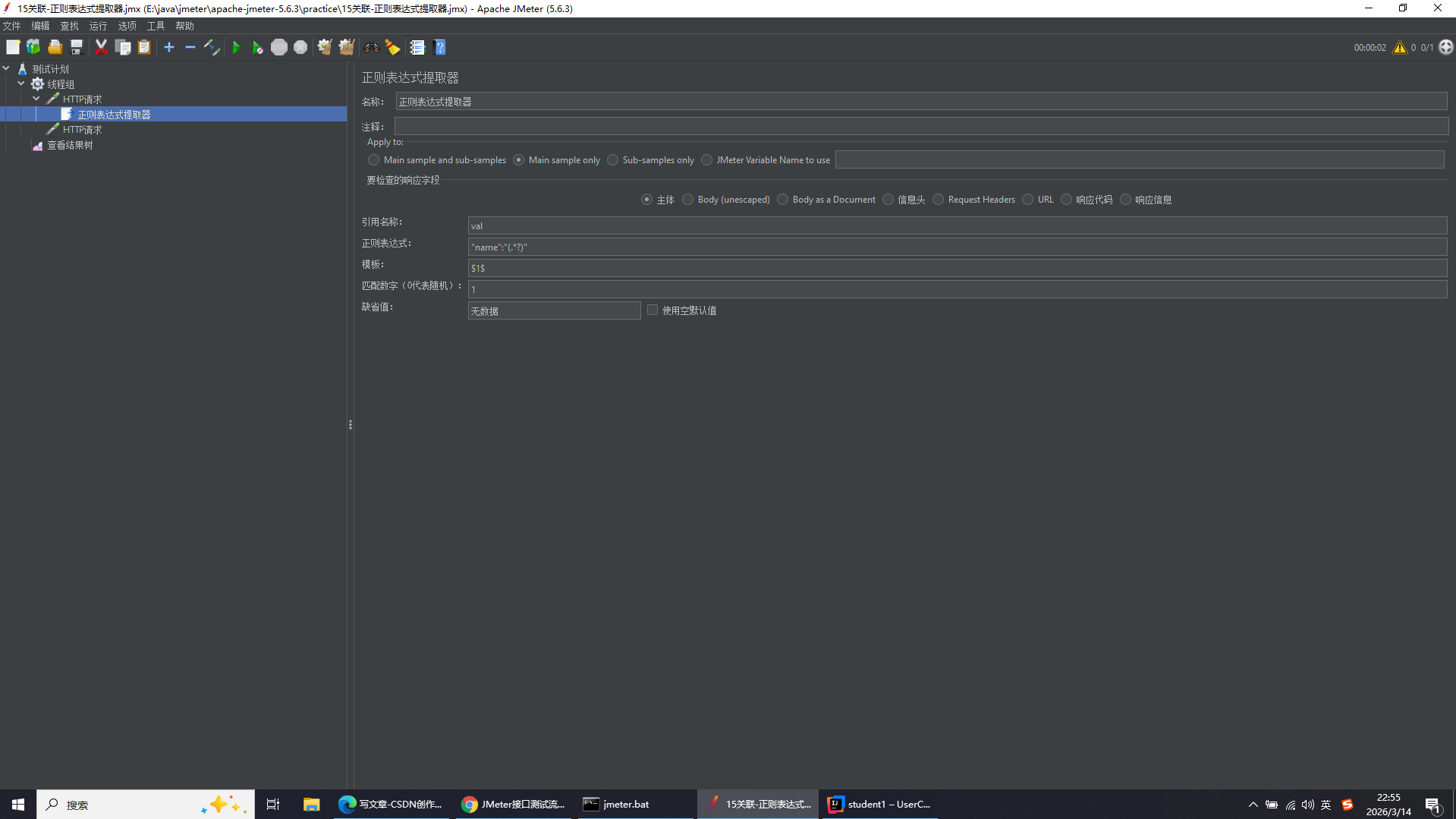
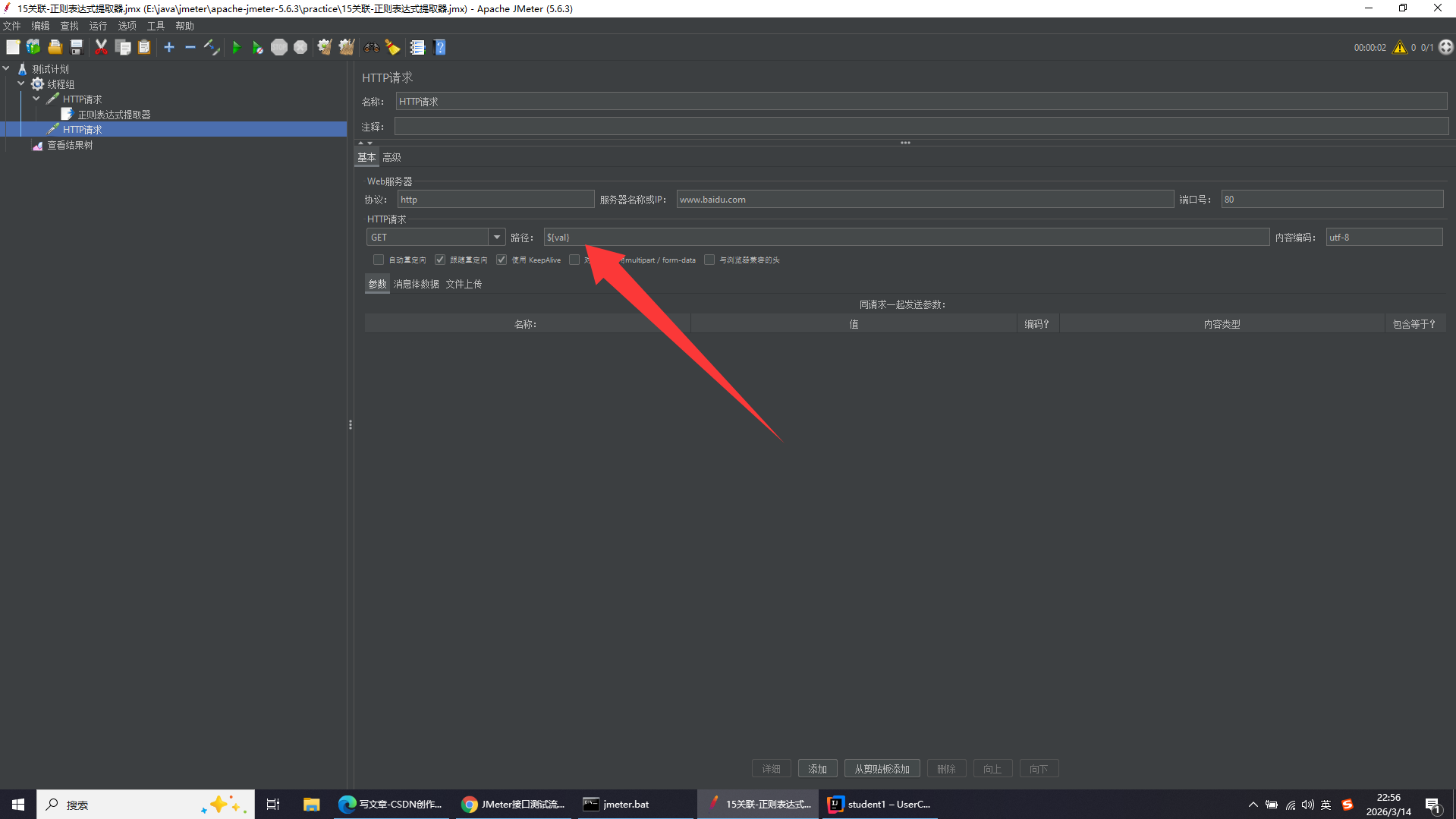
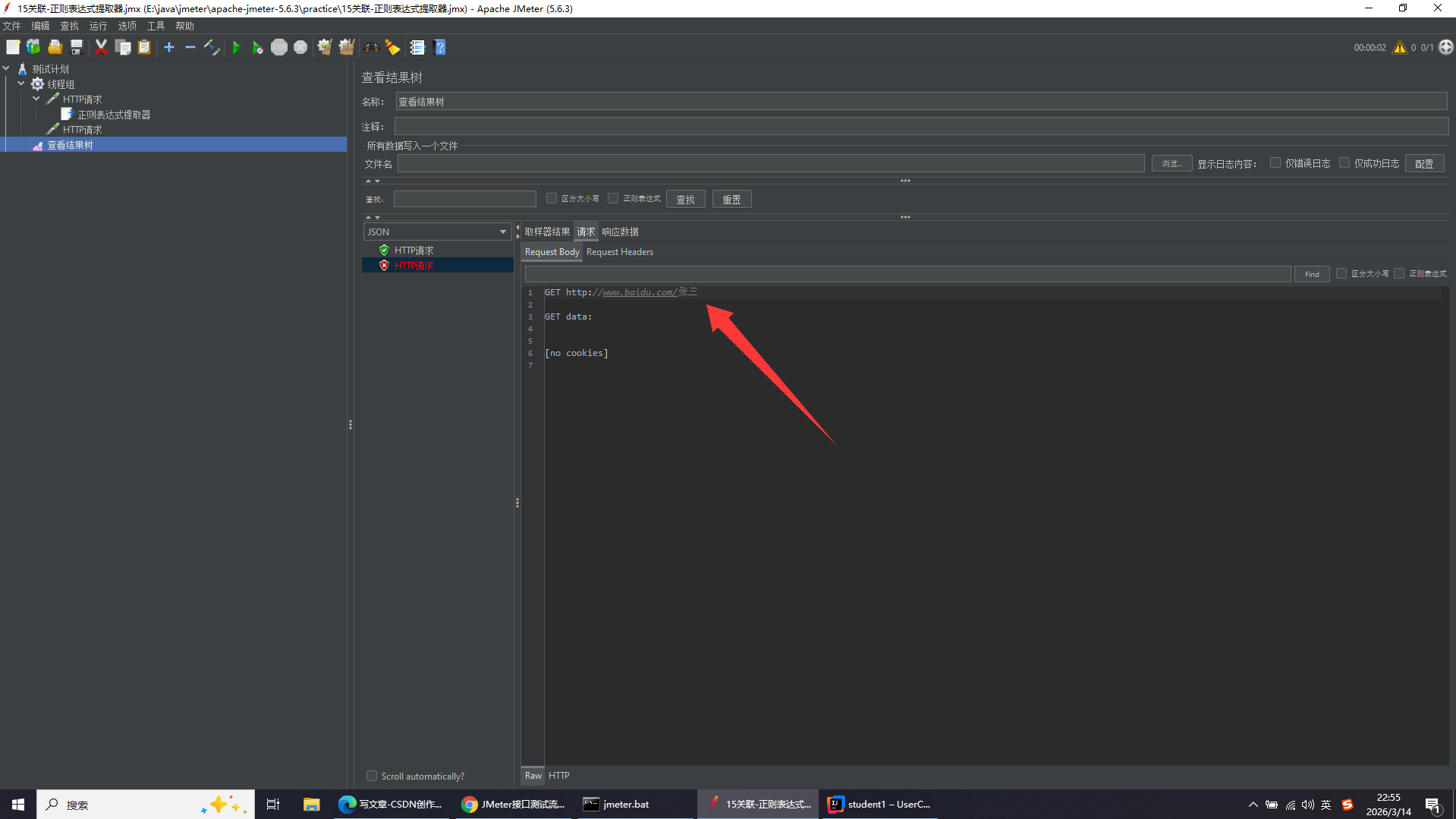
正则表达式常用基础语法
正则表达式匹配符需要用()包裹
正则表达式练习网址
import re
# 模拟JMeter中常见的接口响应文本(包含JSON、HTML、纯文本)
test_response = """
{
"code": 200,
"msg": "操作成功",
"data": {
"token": "abc123_def456",
"userInfo": {
"id": 1001,
"name": "张三",
"phone": "13888889999"
}
}
}
<div class="order">
<p>订单号:OD20260314001</p>
<p>金额:99.9元</p>
</div>
"""|------|----------|------------------|-------------------|-------------|
| . | 任意匹配一个字符 | 获取"张三" | "name": "(..)", | 张三 |
| \d+ | 匹配数字 | 获取手机号13888889999 | "phone": "(\d+)" | 13888889999 |
| .*? | 匹配任意字符串 | 获取操作成功 | "msg": "(.*?)", | 操作成功 |
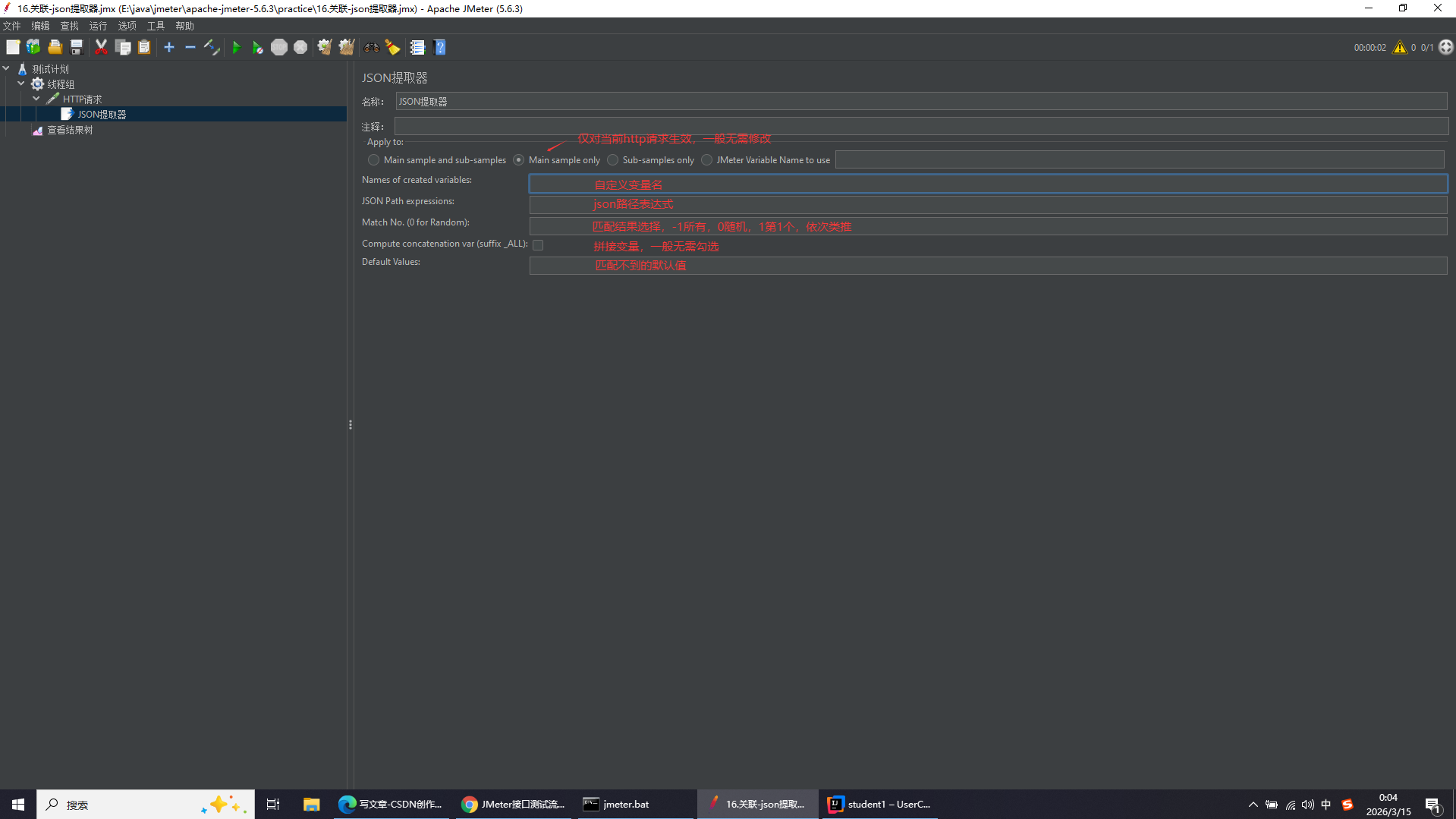
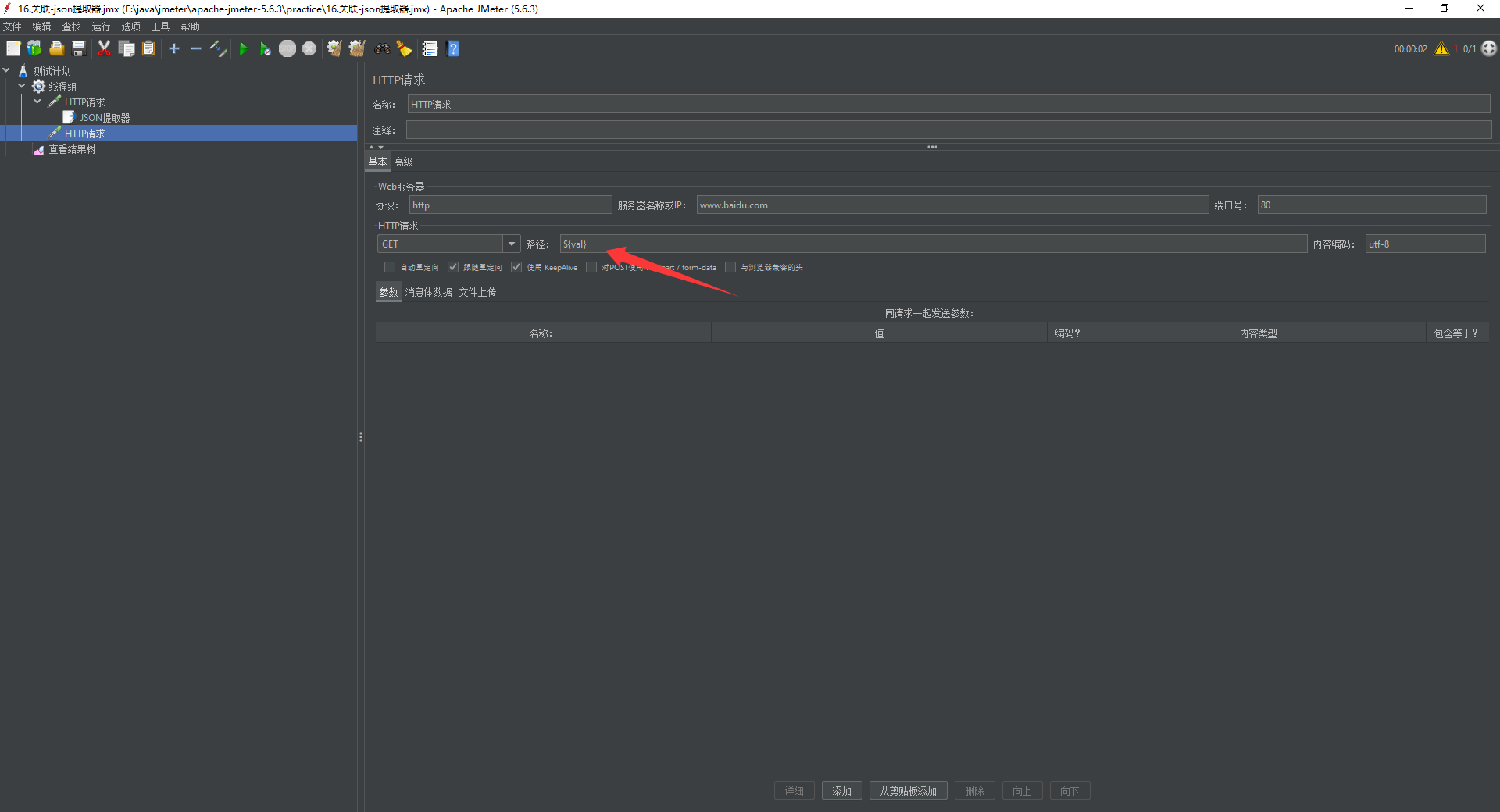
json提取器
对json格式的响应文本进行提取匹配
添加路径:http请求右键添加-后置处理器-json提取器
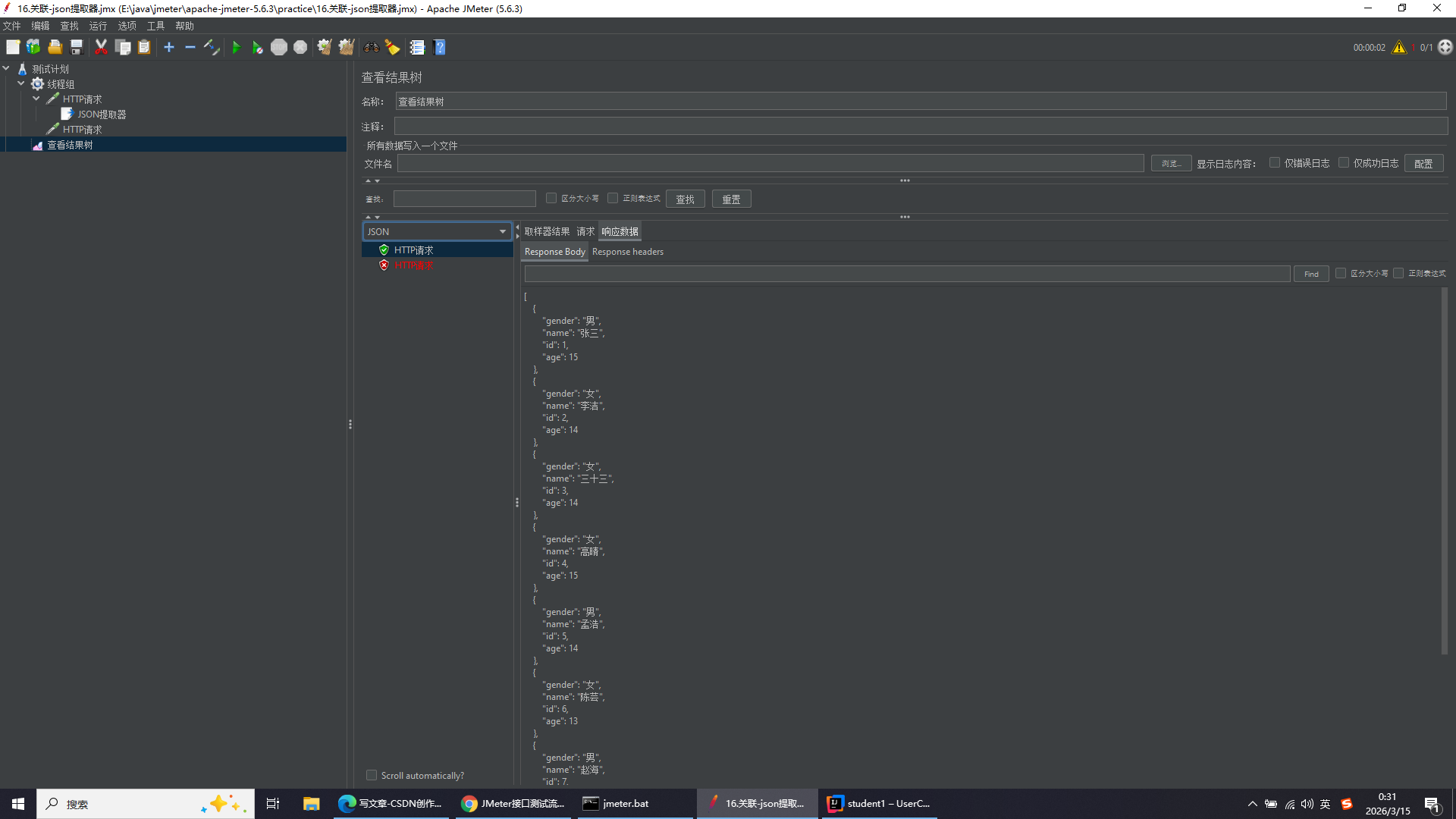
提取第一个性别男
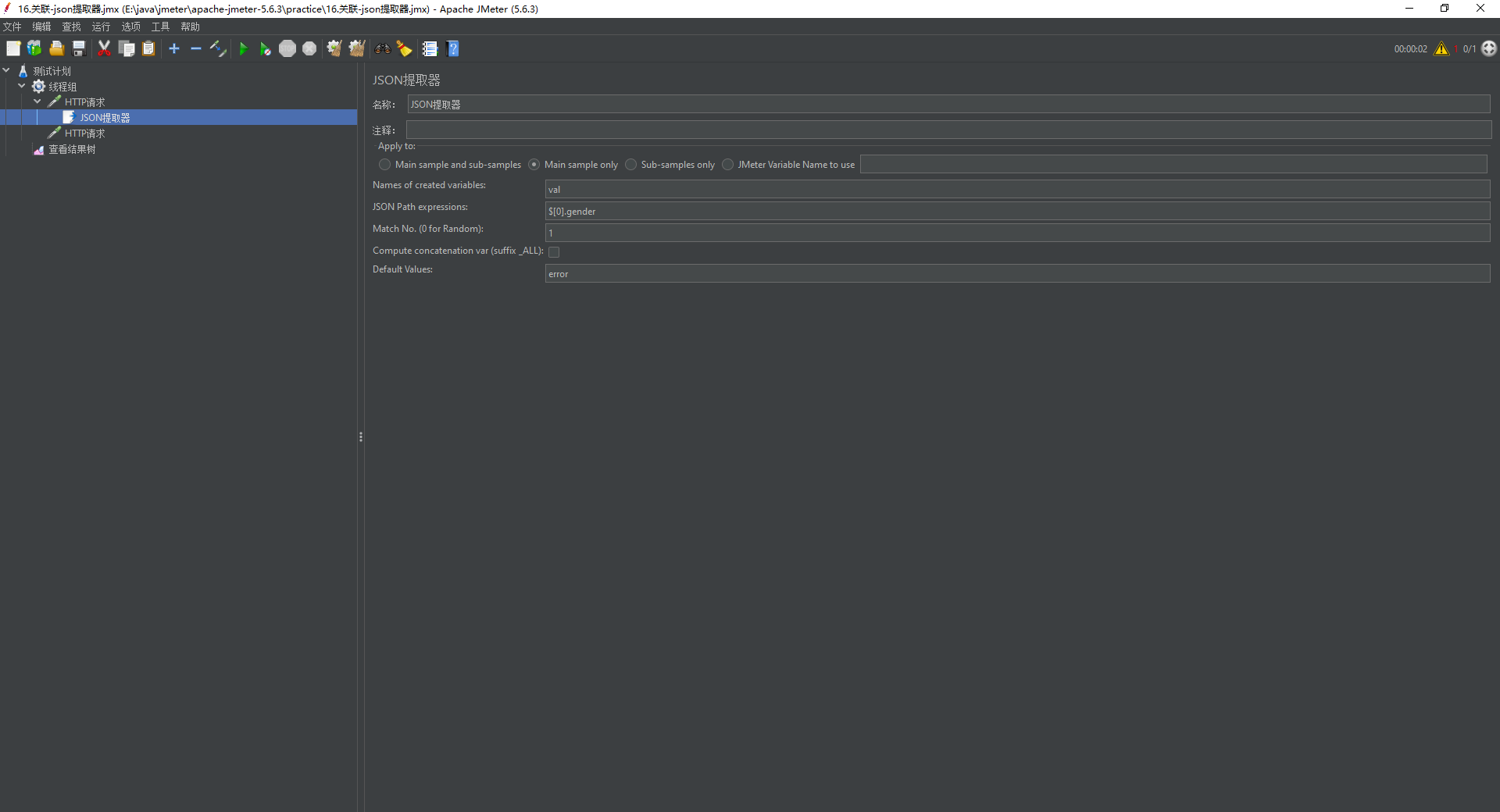
json提取器基础语法
$:根节点
.:取子节点
[]:取数组元素(比如data.list[0]取第一个元素)