2.1 关于爬虫的合法性
几乎每个网站都有一个名为robots.txt的文档,当然也有部分网站没有设定robots.txt。对于没有设定robots.txt的网站,可以通过网络爬虫获取没有口令加密的数据,也就是该网站所有页面数据都可以被爬取。如果网站有robots.txt文档,就要判断是否有禁止访客获取的数据。
以某电商网站为例,该电商网站允许部分爬虫访问它的部分路径,而没有得到允许的用户,则全部禁止爬取,代码如下。
python
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36'
}
Disallow:/除了前面指定的爬虫外,不允许其他爬虫爬取任何数据。
2.2 认识网页结构
网页一般由三个部分组成,分别是HTML(超文本标记语言),CSS(层叠样式表)和JScript(活动脚本语言)。
1. HTML
HTML 是整个网页的结构,相当于真个网站的框架。带"<"">"符号的都属于HTML的标签,并且标签都是成对出现的。
常见的标签如下。
html
<html>..</html> 表示标记中间的元素是网页
<body>..</body> 表示用户可见的内容
<div>..</div> 表示框架
<p>..</p> 表示段落
<li>..</li> 表示列表
<img>..</img> 表示图片
<h1>..</h1> 表示标题
<a href="">..</a> 表示超链接2. CSS
CSS表示样式,<style type="text/css">表示将在下面引用一个CSS,并在CSS中定义了对应的样式。
3. JScript
JScript表示功能。交互的内容和各种特效都在JScript中,JScript描述了网站中的各种功能。
如果把网页比喻为人体,那么HTML是人的骨架,并且定义了人的嘴巴,眼睛,耳朵等要长在哪里;CSS表示人的外观细节,如嘴巴长什么样子,眼睛是双眼皮还是单眼皮,是大眼睛还是小眼睛,皮肤是黑色的还是白色的等;JScript表示人的技能,如跳舞,唱歌或演奏乐器等。
2.3 使用 requests 库请求网站
2.3.1 安装requests库
首先在PyCharm中安装requests库,安装命令如下:
python
pip3 install requests2.3.2 爬虫的基本原理
1. 网页请求的过程
(1) Request (请求)。
每个展示在用户面前的网页都必须经过这一步,也就是向服务器发送访问请求。
(2) Response(响应)。
服务器在接收到用户的请求后,会验证请求的有效性,然后向用户(客户端)发送响应的内容;客户端接收服务器响应的内容,将内容展示出来,这就是我们所熟悉的网页请求。
2. 网页请求的方式
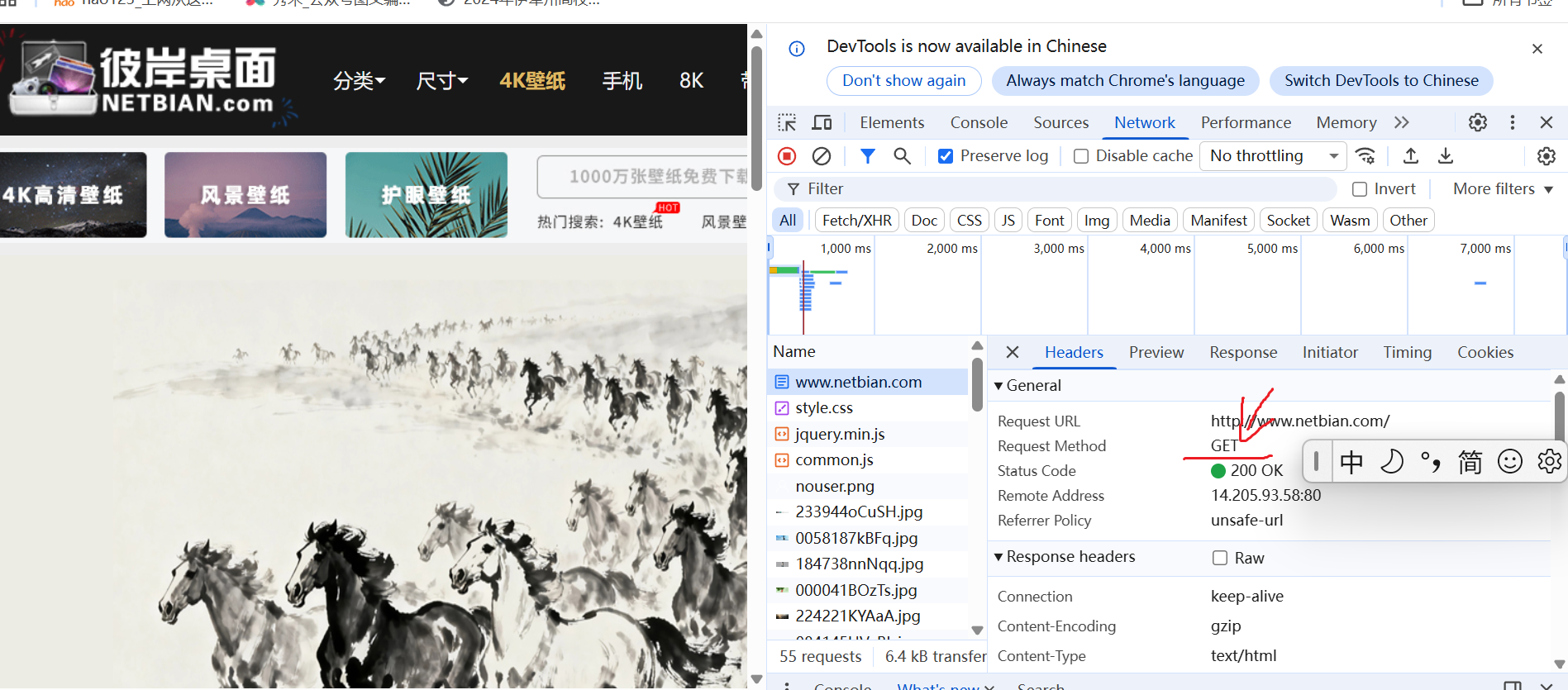
(1) GET:最常见的方式,一般用于获取或查询资源信息,参数设置在URL中,其也是大多数网站使用的方式,只需一次发送和返回,响应速度快。
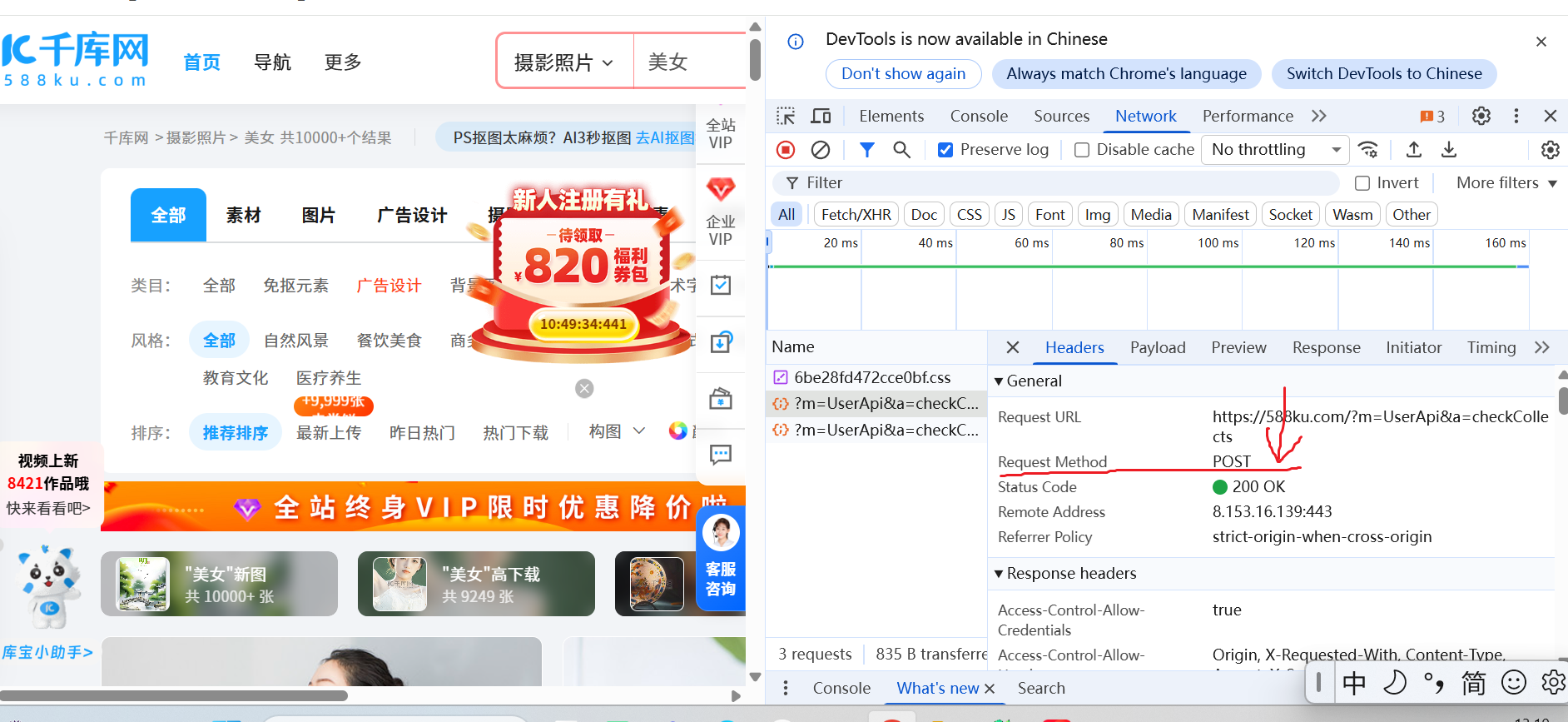
(2) POST:相比GET方式,POST方式通过request body 传递参数,可发送请求的信息远大于GET方式。
2.3.3 使用GET方式抓取数据
1. GET常见的参数
|---------|---------------------|------------------------------------------------------------------------------------------------------------------------------------|
| 参数 | 说明 | 实例 |
| url | 请求地址(必填) | ' http://www.netbian.com/ ' |
| params | URL 查询参数,字典或元组列表 | {'key':'value'} |
| headers | 请求头字典 | {' User-Agent:'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36' '} |
| cookies | Cookies字典或CookieJar | {'session':'abc123'} |
| timeout | 超时时间(秒) | 5或(3,27) |
| proxies | 代理设置 | {'http': 'http://proxy.com:8080'} |
| verify | SSL证书验证 | False |
| auth | 认证元组 | ('username', 'password') |
2. 小案例
python
import requests
url = 'http://www.netbian.com/'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36'
}
response = requests.get(url,headers=headers)
response.encoding ='gbk'
soundCode = response.text
print(soundCode)加载库使用的语句是 import +库的名称,在上述过程中,加载requests库的语句是 import requests。
用GET方式获取数据需要调用requests库中的get方法,使用方法是在requests后输入英文点号(.),如下所示。
python
requests.get将获取到的数据保存到response变量中,代码如下。
python
response = requests.get(url,headers=headers)这是response 是一个URL对象,它代表整个网页,但此时只需要网页中的源码,下面的语句表示网页源码。
python
soundCode = response.text**注意:**我选择哪个网页请求方式,不是我们自己决定的,而是我们根据网站的 Request Method的参数决定的 如上述网页图片所示。
2.3.4 使用POST方式抓取数据
1. POST常见的参数
|-------------------------------------|------------------------------------------------|---------------------|
| 参数 | 说明 | 使用场景 |
| url | 请求地址(必填) | - |
| data | 表单数据,字典/元组列表/字节 | 传统表单提交 |
| json | JSON数据,自动序列化并设置 Content-Type: application/json | REST API |
| files | 上传文件,字典 | 文件上传 |
| headers | 自定义请求头 | 设置Authorization 等 |
| cookies/timeout/proxies/verify/auth | 同GET | - |
2. 小案例
python
import requests
url = 'https://588ku.com/photogram/meinv.html'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36'
}
response = requests.post(url,headers=headers)
response.encoding ='utf-8'
soundCode = response.text
print(soundCode)2.4 使用Beautiful Soup 解析网页
通过requests库已经抓取到网页源码,接下来从源码中找到并提取数据。BeautifulSoup是Python的一个库。其主要功能是从网页中抓取数据。Beautiful Soup目前已经被移植到bs4库中,也就是说在导入Beautiful Soup时需要先安装bs4库。
1. 安装bs4库
python
pip install beautifulsoup4
pip install lxml2. 创建BeautifulSoup对象
python
import requests
from bs4 import BeautifulSoup
html_doc = """
<html>
<head><title>示例页面</title></head>
<body>
<div class="content">
<p id="intro">这是一个介绍</p>
<a href="https://example.com">链接</a>
</div>
</body>
</html>
"""
soup = BeautifulSoup(html_doc, 'lxml')
with open('index.html', 'r', encoding='utf-8') as f:
soup = BeautifulSoup(f, 'lxml')
response = requests.get('https://example.com')
soup = BeautifulSoup(response.text, 'lxml')2.5 爬虫攻防
爬虫是模拟人的浏览访问行为,进行数据的批量爬取。当爬取的数据量逐渐增大时,会给被访问的服务器造成很大的压力,甚至有可能崩溃。换句话说就是,服务器是不喜欢有人抓取自己的数据的,那么,网站方面就会针对这些爬虫采取一些反爬策略。
服务器识别爬虫的一种方式是通过检查连接的User-Agent来识别到底是浏览器访问的还是代码访问的。如果是代码访问的,当访问量增大时,服务器就会直接封掉来访IP。在一个IP下批量访问,下载图片,这种行为不符合正常人类的行为,肯定要被封掉IP。不管如何访问,服务器的目的就是查出那些行为代码访问,然后封掉IP。解决方法:为避免被封掉IP,在数据采集时经常使用代理。当然,requests也是有相应的proxies属性。
首先构建自己的代码IP池,将其以字典的形式赋值给proxies,然后传输给requests。
python
proxies = {
"http":"http://10.10.1.10:3128",
"https":"http://10.10.1.10:1080",
}
response = requests.get(url,proxies=proxies)2.6 关于什么时候存储数据
数据存储一般发生在获取到网页的HTML或数据之后,未经过清洗和组织的数据是必须要保存的资料。保存好这些资料后,再写清洗和组织数据的脚本,将数据提取出来重新存入数据库或数据表中。