分享一下AuraMate灵伴团队发的一篇论文。我们专门测 AI 到底能不能"算命",不是网上那种给 DeepSeek 发个 prompt 截图说"准到离谱"的玩法,我们做的是有标准答案的盲测。
怎么测的?
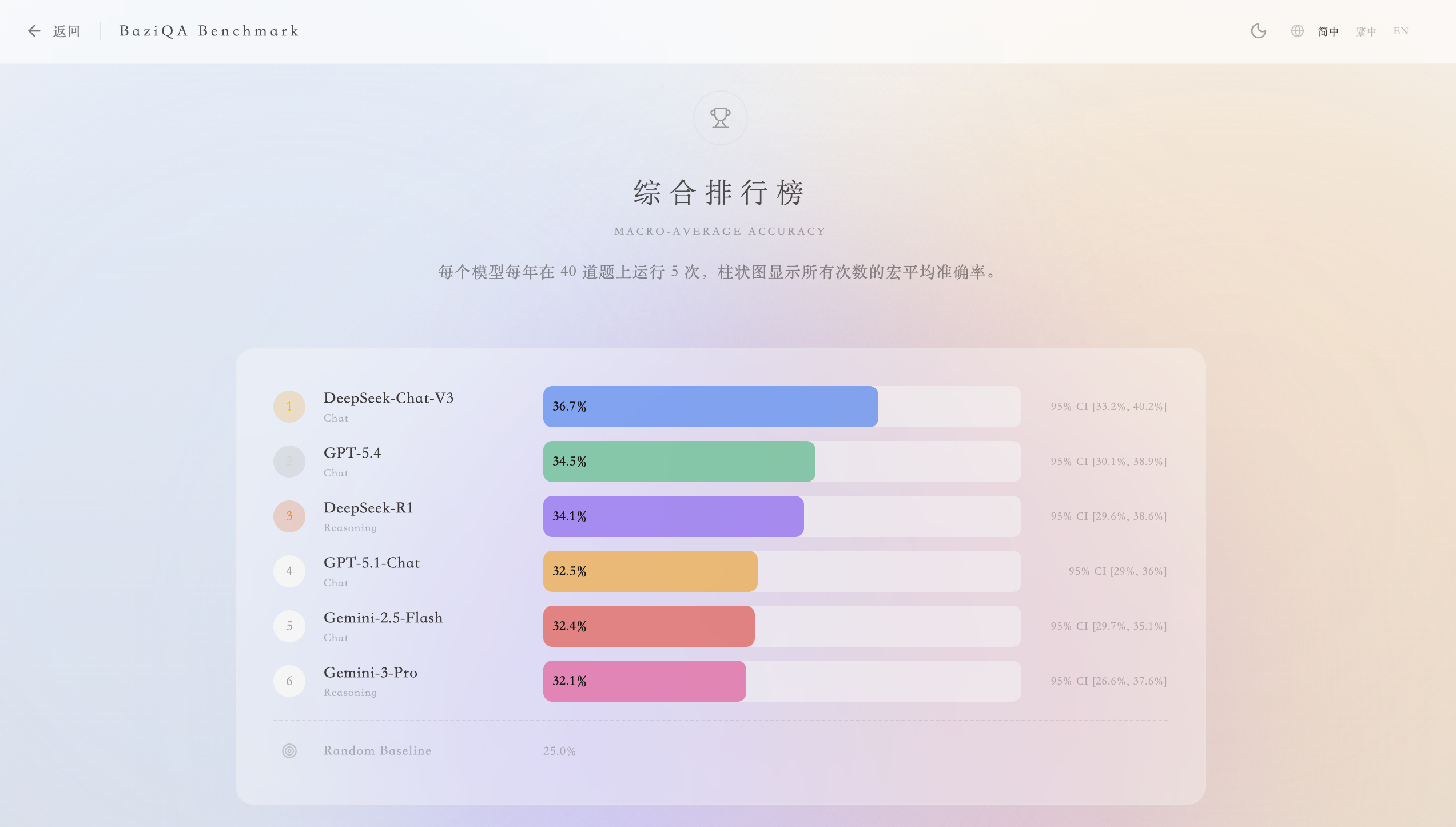
我们搞了一个 benchmark 叫 BaziQA,来源是全球算命师大赛 2021-2025 年的真题,200 道四选一选择题。每道题给出生辰八字,问具体的人生事件------"此人哪年结婚""出生家境如何""事业转折在何时"------有标准答案,不让 AI 打太极。
为了公平,所有模型拿到的干支数据完全一样------四柱、十神、大运流年都事先排好,只需要做推理。
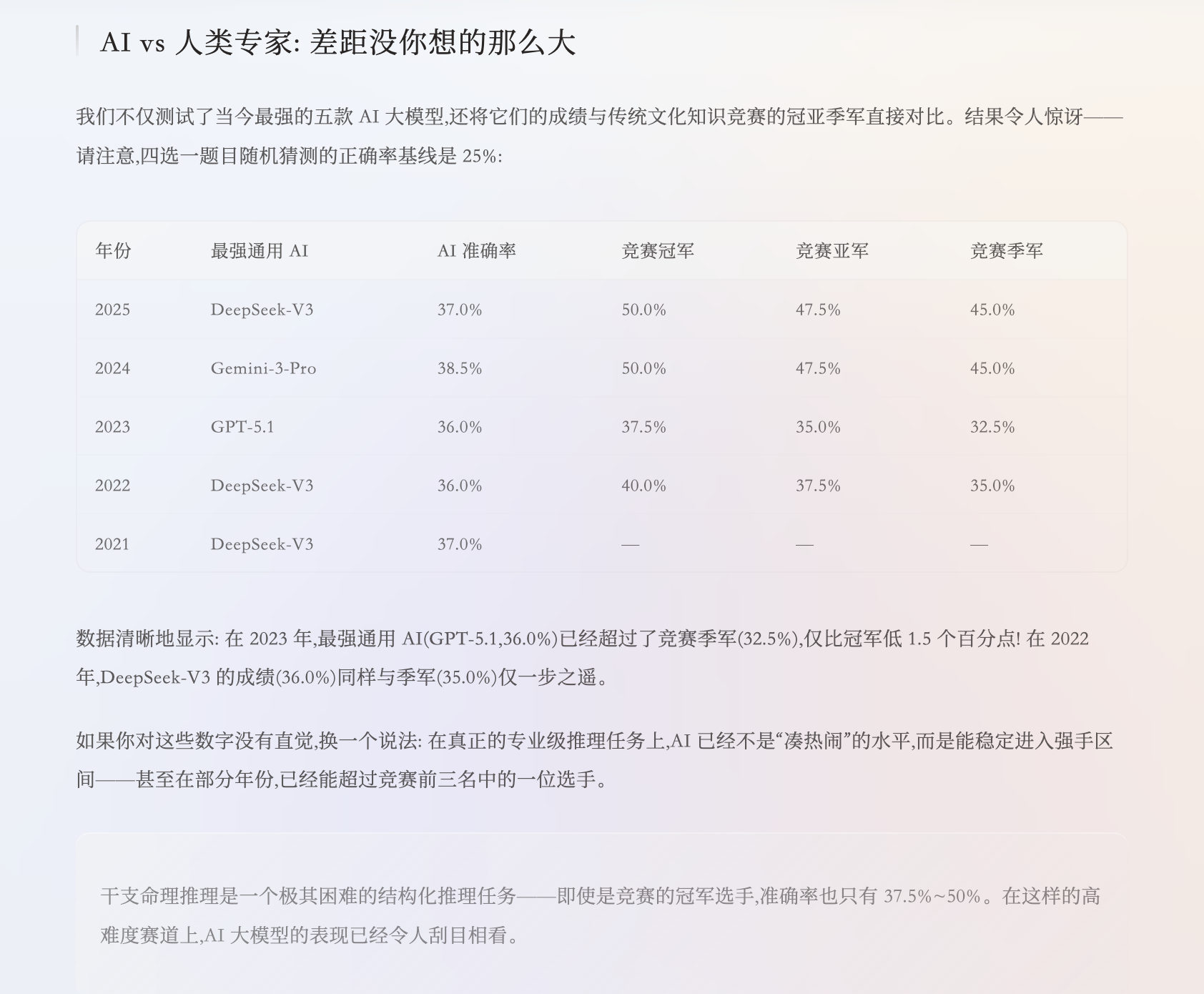
AI vs 人类专家,差距没想象中那么大:
| 年份 | 最强通用 AI | 竞赛冠军 | 竞赛季军 |
|---|---|---|---|
| 2025 | 37.0%(DeepSeek-V3) | 50.0% | 45.0% |
| 2023 | 36.0%(GPT-5.1) | 37.5% | 32.5% |
| 2022 | 36.0%(DeepSeek-V3) | 40.0% | 35.0% |
2023 年 GPT-5.1 已经超过了竞赛季军,离冠军只差 1.5%。在连人类冠军也只有 37.5%-50% 的高难度赛道上,AI 不是"凑热闹",已经能进入强手区间了。
但通用 AI 有个明显短板: 它们缺乏系统化的分析流程。八字推理需要"先看全局→排主次→再下结论",通用模型往往跳步骤,导致时间定位类问题拉胯。
所以我们提出了结构化推理协议(SRP):
引导 AI 按"全局扫描→力量排序→事件推断"的步骤来分析。效果很明显:
• 流年分析 +8~10 个百分点
• 事业推断最高 +15 个百分点
• 学业推断最高 +30 个百分点
SRP 引擎在 2022 年超越竞赛季军追平亚军,2025 年达到 42%,比最强通用 AI 高出 5 个百分点。
基于这套方法论,我们做了 AuraMate 灵伴 ------ 一个 AI 命理分析平台。**它不是简单地把八字丢给大模型,而是用论文验证过的结构化推理方法,配合自研的高精度排盘引擎,让每一步推理都有据可依、可追溯。
感兴趣的可以看看:
• 论文:arXiv:2602.12889
• 数据集开源:GitHub - BaziQA
• 实时评测榜单:auramate.net/benchmark
• 研究详情:AI 在传统四柱八字干支推理任务上的表现已接近人类专家
欢迎拿自己感兴趣的模型跑跑看 😃