一、Jdk7
1、扩容死锁分析
死锁问题核心在于多线程扩容导致形成的链表环
ini
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
//第一行
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
//第二行
int i = indexFor(e.hash, newCapacity);
//第三行
e.next = newTable[i];
//第四行
newTable[i] = e;
//第五行
e = next;
}
}
}⚠️多线程扩容
✔️假设有两个线程 T1 和 T2 同时检测到需要扩容,它们都会创建新的数组并尝试迁移旧数组的元素 。
✔️由于没有同步控制,两个线程会同时执行transfer()操作,操作同一份链表数据,导致指针错乱,形成环形链表。
二、Jdk8
1、实现原理
Java8 HashMap扩容跳过了Jdk7扩容的坑,对源码进行了优化,采用高低位拆分转移方式,避免了链表环的产生
1.1、扩容前
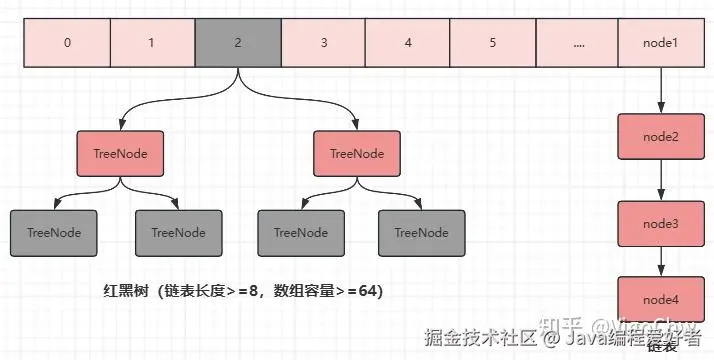
1.2、扩容后
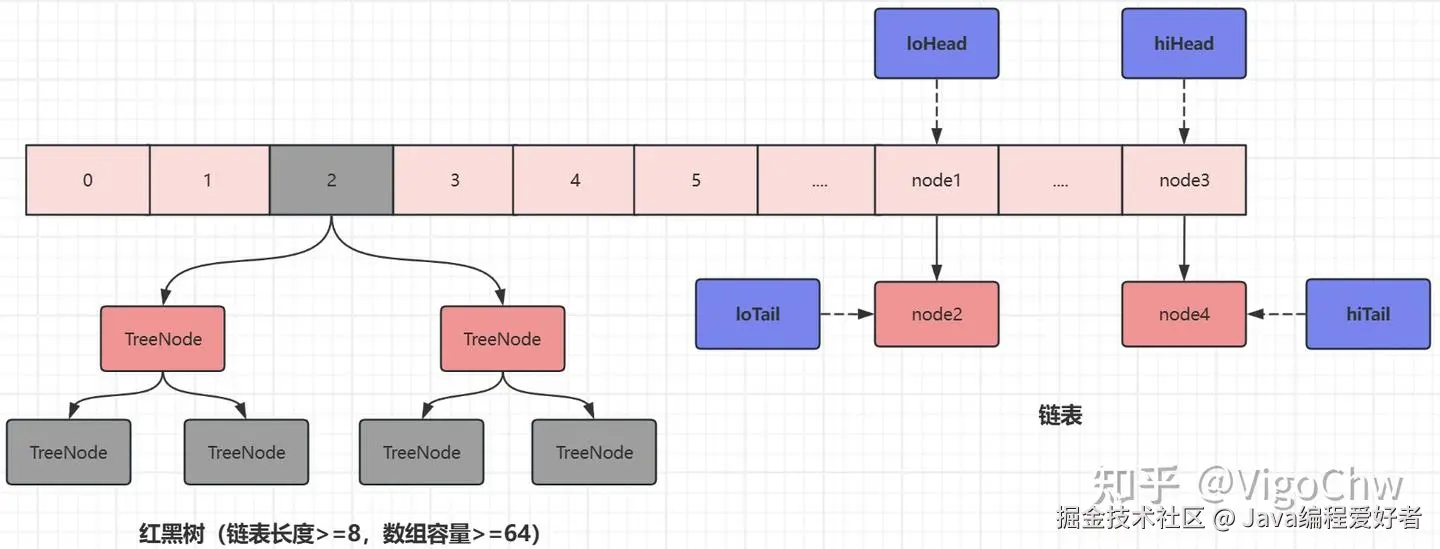
2、扩容方法:resize
数组的初始化和扩容都是通过调用resize方法完成的
ini
final Node<K,V>[] resize() {
// 扩容前的数组
Node<K,V>[] oldTab = table;
// 扩容前的数组的大小和阈值
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
// 预定义新数组的大小和阈值
int newCap, newThr = 0;
if (oldCap > 0) {
// 超过最大值就不再扩容了
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 扩大容量为当前容量的两倍,但不能超过 MAXIMUM_CAPACITY
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
// 当前数组没有数据,使用初始化的值
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
// 如果初始化的值为 0,则使用默认的初始化容量,默认值为16
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 如果新的容量等于 0
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
// 开始扩容,将新的容量赋值给 table
table = newTab;
// 原数据不为空,将原数据复制到新 table 中
if (oldTab != null) {
// 根据容量循环数组,复制非空元素到新 table
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// 如果链表只有一个,则进行直接赋值
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
// 红黑树相关的操作
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
// 链表复制,JDK 1.8 扩容优化部分
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// 原位置:原索引
if ((e.hash & oldCap) == 0) {
// hash 值的 oldCap 位为 0 → 保持在原位置 j
if (loTail == null)
// 记录低位链表的头
loHead = e;
else
// 链接到前一个节点
loTail.next = e;
// 更新尾节点
loTail = e;
}
// hash 值的 oldCap 位为 1 → 移动到 j + oldCap
else {
if (hiTail == null)
// 记录高位链表的头
hiHead = e;
else
// 链接到前一个节点
hiTail.next = e;
// 更新尾节点
hiTail = e;
}
} while ((e = next) != null);
// 断开低位链表的尾部
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 断开高位链表的尾部
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}3、高低位扩容
示例:从容量 16 扩容到 32(16<<1=32)
scss
// 假设条件
oldCap = 16 = 0b10000
newCap = 32 = 0b100000
// 旧数组索引 5 处有一条链表
oldTab[5] → A(hash=37) → B(hash=53) → C(hash=21) → D(hash=69) → null步骤 1:计算每个节点的 hash & oldCap
ini
节点 A: hash = 37 = 0b100101
37 & 16 = 0b100101 & 0b010000 = 0 → 低位
节点 B: hash = 53 = 0b110101
53 & 16 = 0b110101 & 0b010000 = 16 ≠ 0 → 高位
节点 C: hash = 21 = 0b010101
21 & 16 = 0b010101 & 0b010000 = 16 ≠ 0 → 高位
节点 D: hash = 69 = 0b1000101
69 & 16 = 0b1000101 & 0b010000 = 0 → 低位步骤 2:拆分链表
css
原始链表:
index 5: A(37) → B(53) → C(21) → D(69) → null
拆分后的两条链表:
低位链表(loHead): A(37) → C(69) → null
高位链表(hiHead): B(53) → D(21) → null步骤 3:安装到新数组
css
新数组(容量 32):
index 5: A(37) → C(69) → null ← 低位链表
index (5+16=21): B(53) → D(21) → null ← 高位链表⚠️高低位扩容的核心:
✔️判断条件:(e.hash & oldCap) == 0
✔️低位链表:保持在原位置 j
✔️高位链表:移动到新位置 j + oldCap
✔️不需要重新计算 hash
✔️链表被拆分成两条,减少冲突
✔️保持原有节点的相对顺序
4、索引计算方法
4.1、举个栗子🌰🌰
csharp
package com.nl;
public class HashMapDemo {
public static void main(String[] args) {
String test = "test1234678";
System.out.println("计算容量为16的索引:"+((16-1) & hash(test)));
// 为0,扩容后再原位置存放
System.out.println("容量为32的与运算值:"+(test.hashCode() & 32));
System.out.println("计算容量为32的索引:"+((32-1) & hash(test)));
// 不为0,扩容后重新计算索引
System.out.println("容量为64的与运算值:"+(test.hashCode() & 64));
System.out.println("计算容量为64的索引:"+((64-1) & hash(test)));
}
/**
* 源码生成hashCode的方法
* @param key
* @return
*/
static int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
}4.2、输出
makefile
计算容量为16的索引:8
容量为32的与运算值:0
计算容量为32的索引:8
容量为64的与运算值:64
计算容量为64的索引:40⚠️注意:
✔️容量为32的与运算值为0时,扩容后索引不变
✔️容量为64的与运算值为64时,扩容后索引改变