【性能优化】案例分享-一个因为卡GPU丢帧的案例
-
-
- 一、案例中的现象
- 二、分析思路
-
- [2.1 app-sf的生产者-消费者模型中,buffer的流向](#2.1 app-sf的生产者-消费者模型中,buffer的流向)
- [2.2 按照这个模型,什么情况下会导致dequeueBuffer卡住?](#2.2 按照这个模型,什么情况下会导致dequeueBuffer卡住?)
- [2.3 再看sf的合成过程是否卡顿?](#2.3 再看sf的合成过程是否卡顿?)
- [2.4 sf合成没卡,那为什么sf会延后消费buffer?](#2.4 sf合成没卡,那为什么sf会延后消费buffer?)
- [2.5 如何关联上GPU xxx的waiting for completion xxx轨道信息](#2.5 如何关联上GPU xxx的waiting for completion xxx轨道信息)
- [2.6 总结分析结论,此题是卡GPU了](#2.6 总结分析结论,此题是卡GPU了)
-
一、案例中的现象
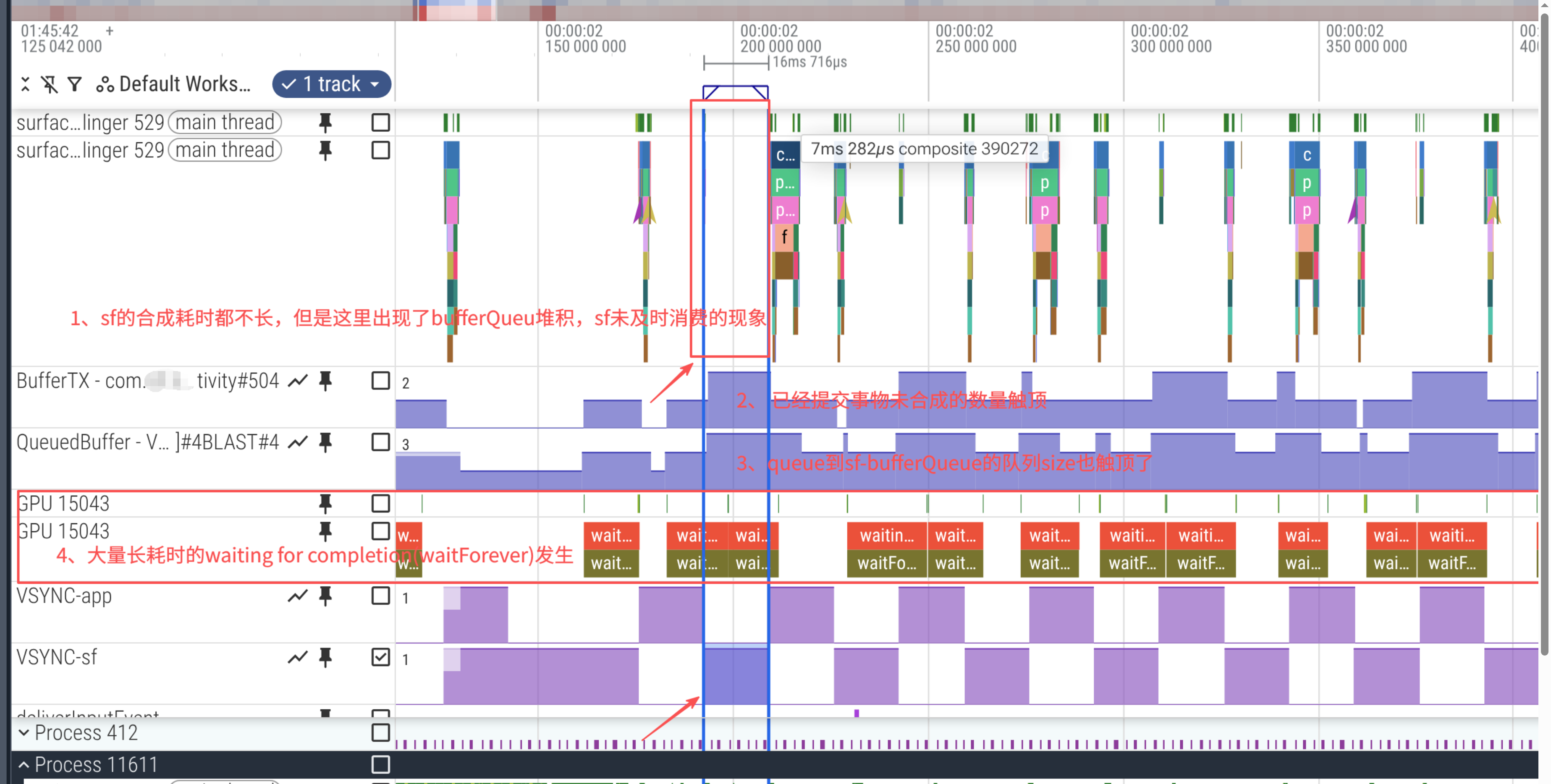
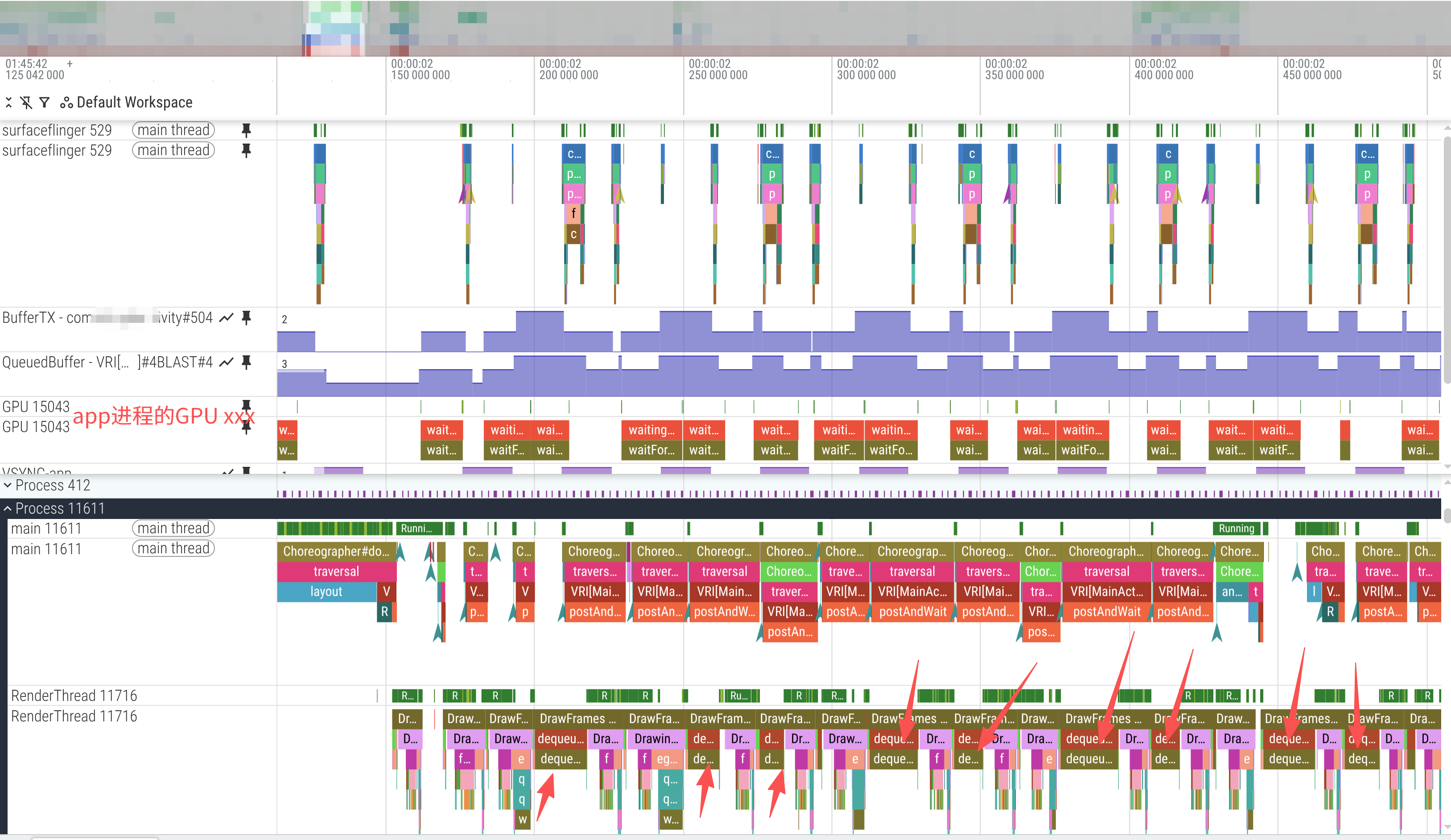
某个新机型性能摸底时,发现安装相同app版本情况下,新机型从trace查看帧率低很多。通过抓取trace分析发现,主要卡在app进程的RenderThread线程的dequeueBuffer阶段,trace如下如所示:
 计算帧率:45.94fps,这里计算时抛掉前面明显的在案件按键之后layout耗时,因为该问题原因已知。
计算帧率:45.94fps,这里计算时抛掉前面明显的在案件按键之后layout耗时,因为该问题原因已知。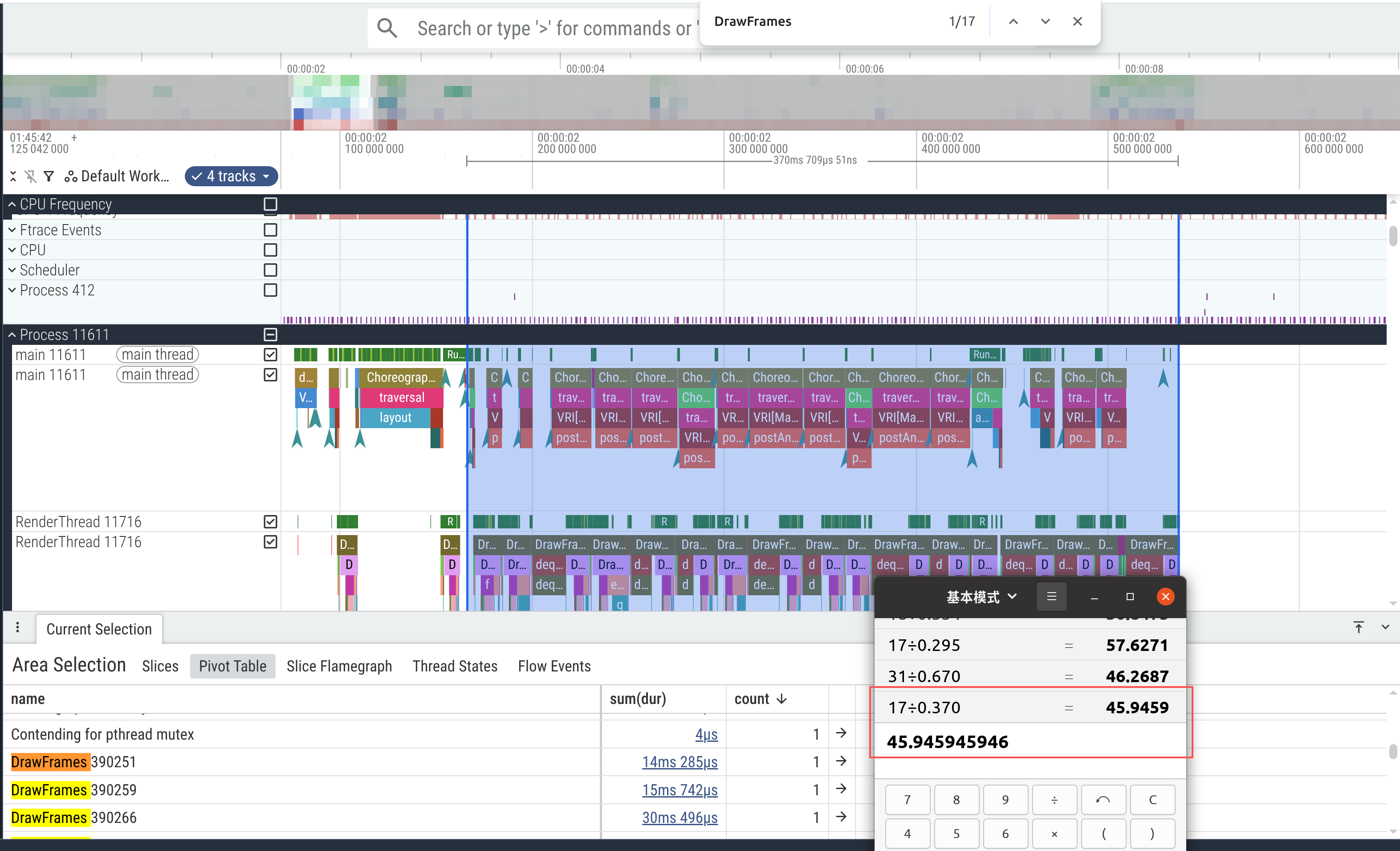
二、分析思路
首先dequeueBuffer是从sf的BufferQueue中获取一个可用的buffer,该函数耗时了说明是获取buffer过程卡住了。
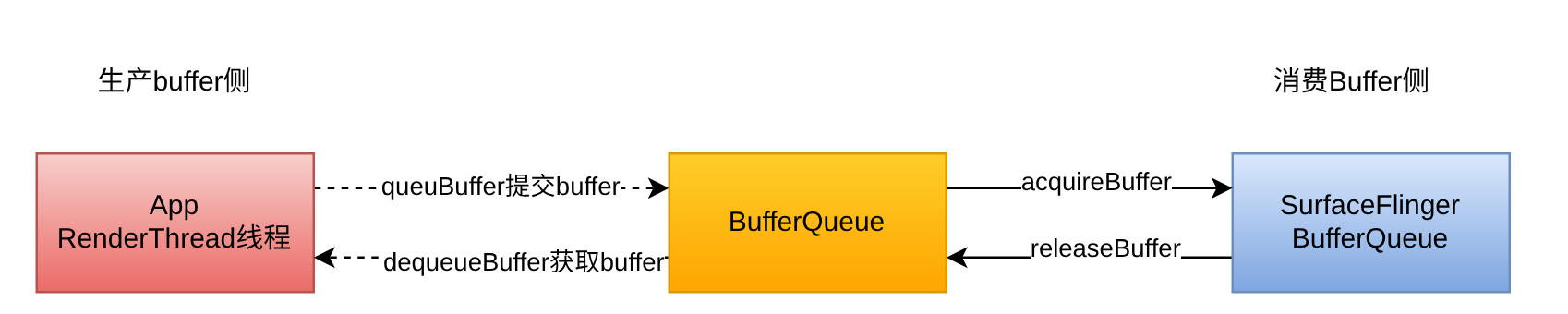
2.1 app-sf的生产者-消费者模型中,buffer的流向
注:曲线代表跨进程,实现代表进程内访问
2.2 按照这个模型,什么情况下会导致dequeueBuffer卡住?
有了上述的buffer流向,其实不难看出:
当三个buffer都queuBuffer到了BufferQueue中,但是sf侧没有及时合成完毕重新放入到BufferQueue中,那么自然就无法及时拿到buffer了。
2.3 再看sf的合成过程是否卡顿?
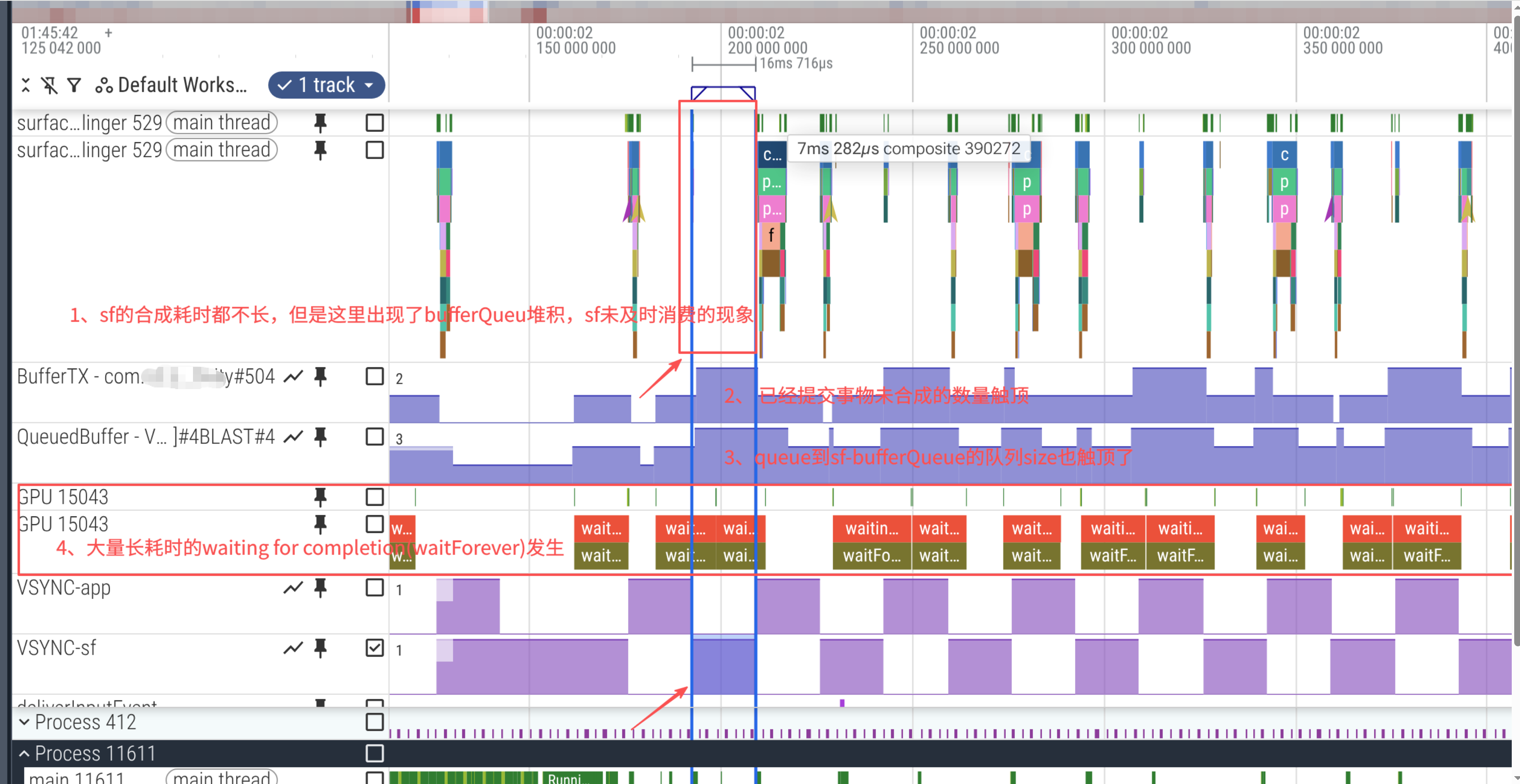
从上述trace截图分析,sf合成逻辑并没有卡顿,所以不难看出丢帧的原因是sf消费buffer时机延后导致的丢帧。
2.4 sf合成没卡,那为什么sf会延后消费buffer?
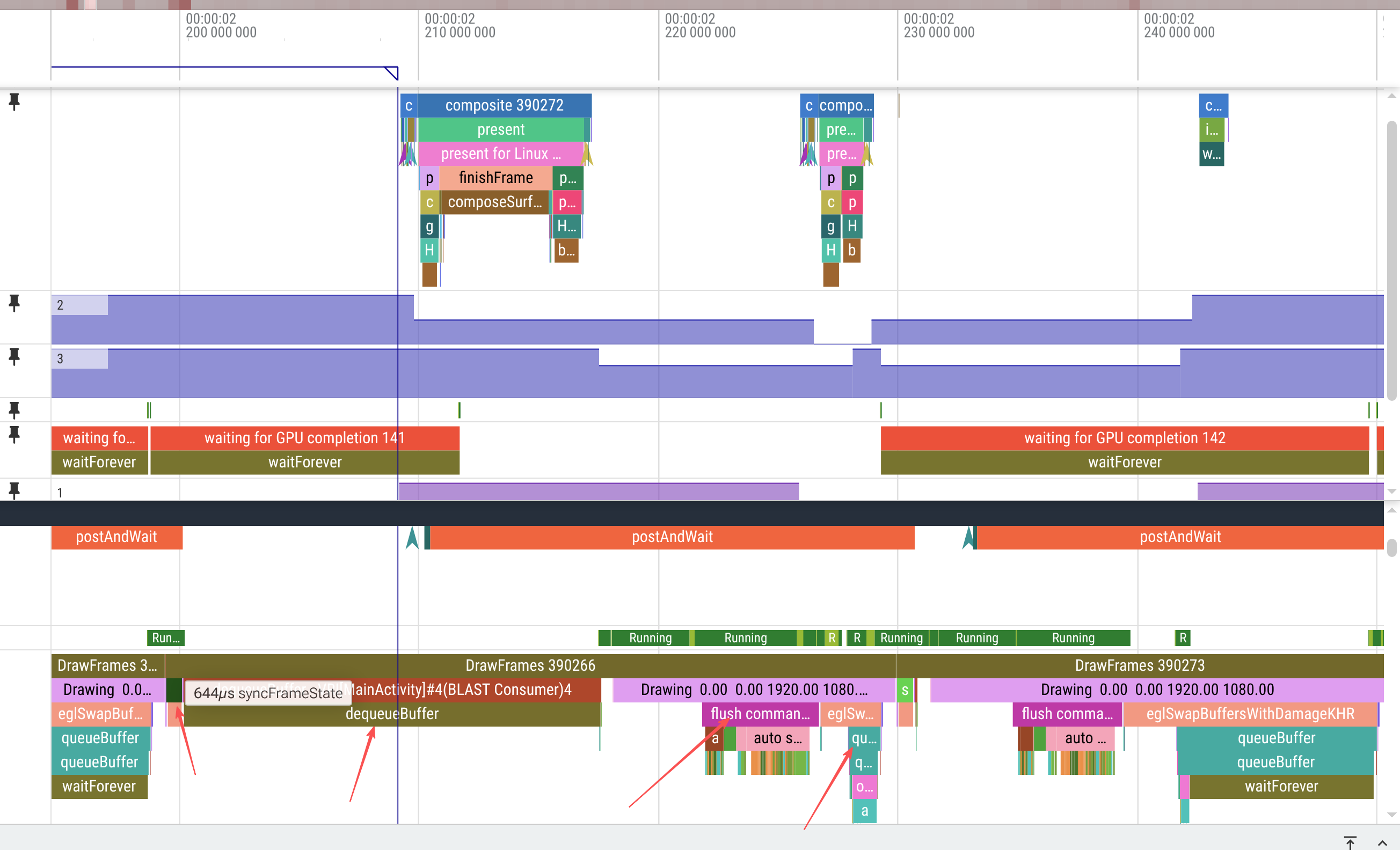
这个问题涉及到一个RenderThread提交绘制指令给GPU的时机问题。
RenderThread工作的几个阶段:
1、syncFrameState
2、dequeueBuffer
3、flush commands
4、queueBuffer
2.5 如何关联上GPU xxx的waiting for completion xxx轨道信息
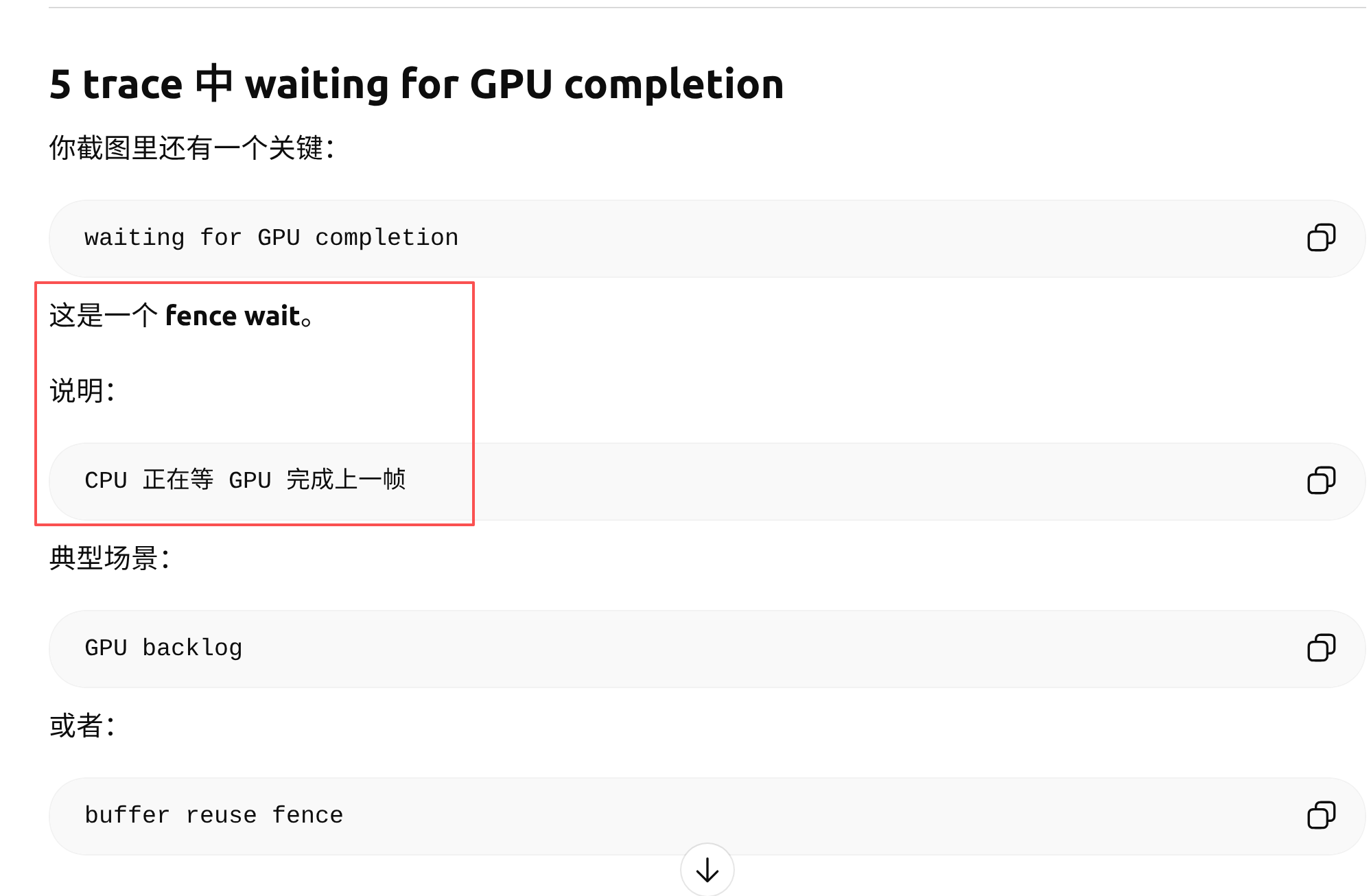
这个问题,做为一个UI崽来说,属实只是盲区了,确实不懂,求问ChatGpt,把截图和问题描述给他,回答如下:
eglSwapBuffersWithDamageKHR是是GPU执行pipeline被真正提交(submit)的时机,那么其内部操作逻辑时序如下:
1 提交 GPU command buffer,这个只是把命令提交给了GPU队列,是异步的并非同步的立即执行
2 触发 buffer swap
3 queuBuffer
那么按照如上的架构设计,就有一个问题,通过queueBuffer提交给BufferQueue的buffer可能还未绘制完成,这时候即使vsync-sf到来,sf也是无法立即acqureBuffer进行合成的。
那么,sf就需要等GPU绘制完成,才能进行合成逻辑,由此产生了App进程的GPU xxx的轨道上的waiting for completion xx(waitforever)的trace。