一:大模型、SKILL、MCP 是什么关系 ?
1.1 先搞懂三个概念
| 概念 | 一句话解释 | 类比 |
|---|---|---|
| 大模型(LLM) | 能理解自然语言、生成文本的 AI 引擎 公司提供给大家使用的模型列表 | 一个超级聪明但"没有手"的大脑 |
| MCP Server | 给大模型提供"工具"的标准化服务 | 大脑的"手"和"脚" |
| Skill | 教大模型"何时用、怎么用"这些工具的说明书 | 大脑的"操作手册" |
1.2 三者关系图
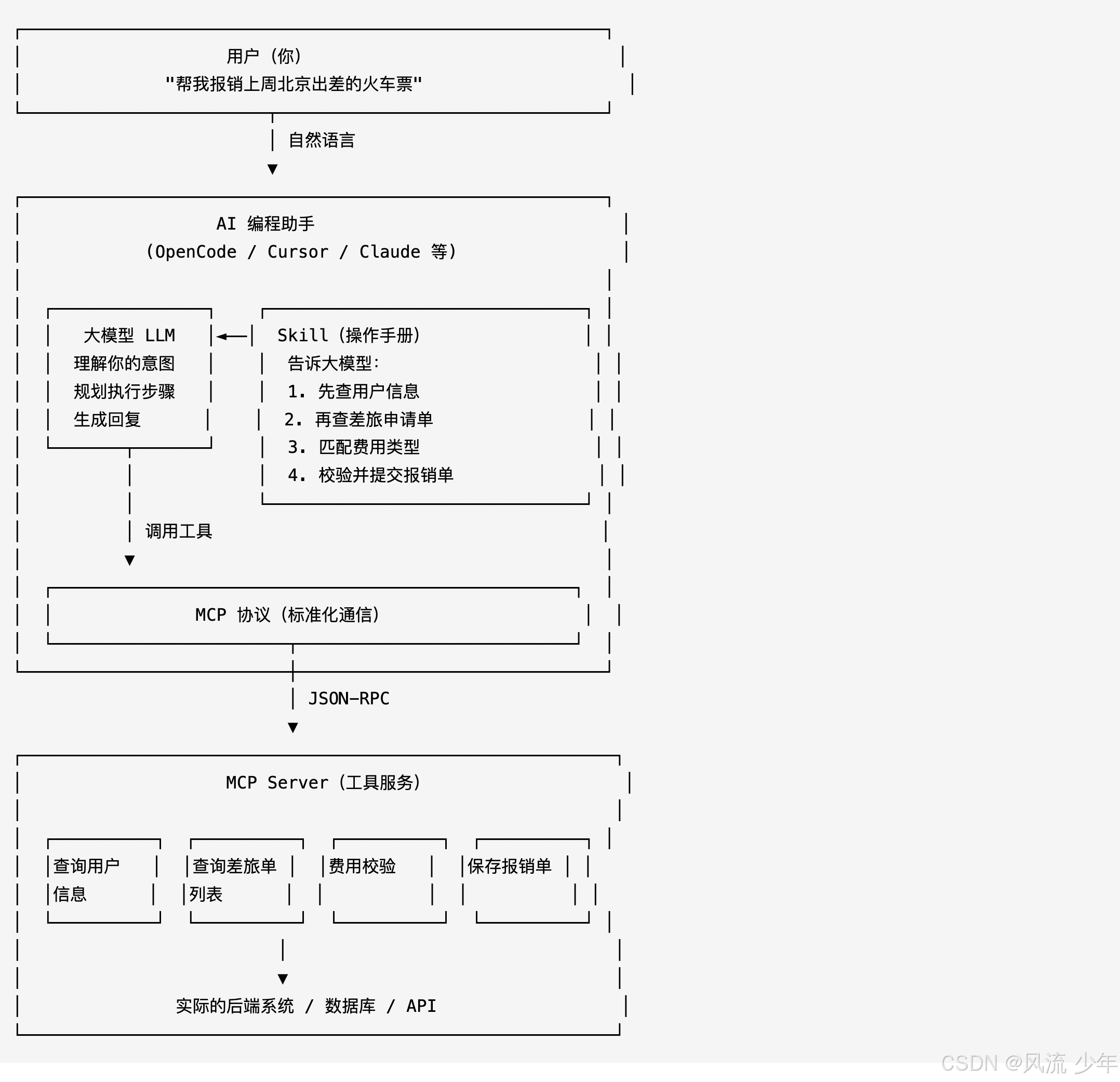
1.3 用一个生活例子理解
想象你去医院看病:
- 你(用户) 说:"我头疼"
- 医生(大模型) 听懂了你的症状,判断需要做哪些检查
- 检查项目清单(Skill) 告诉医护人员:先量体温、再测血压、然后验血
- 医疗设备(MCP Server) 是体温计、血压计、验血仪等具体工具
- MCP 协议 就是医生和设备之间标准化的操作接口
核心要点:大模型本身只会"思考",MCP Server 让它能"做事",Skill 教它"做对事"。
二:怎么把现有能力注册成一个 MCP Server?
2.1 什么是 MCP ?
MCP(Model Context Protocol) 是 Anthropic 在 2024 年底发布的开放协议,它定义了 AI 模型与外部工具/数据源之间的标准通信方式。
┌────────────────────────────────────────────────────┐
│ MCP 协议核心概念 │
├─────────────┬──────────────────────────────────────┤
│ 概念 │ 说明 │
├─────────────┼──────────────────────────────────────┤
│ Host │ 宿主应用(如 OpenCode、Cursor) │
│ Client │ MCP 客户端,嵌入在 Host 中 │
│ Server │ MCP 服务端,提供工具/资源/提示 │
│ Transport │ 通信方式(stdio / HTTP SSE) │
│ Tool │ 一个可被调用的函数(如 "查询用户") │
│ Resource │ 一份可被读取的数据(如 "配置文件") │
│ Prompt │ 一段预设的提示模板 │
└─────────────┴──────────────────────────────────────┘2.2 自己封装MCP Server(飞阅)
怎么将已有 API 封装成 MCP Server(以 Python 为例)
假设你已经有一个"查询员工信息"的 HTTP API,想让 AI 能调用它:
第一步:安装 MCP SDK
bash
pip install mcp第二步:编写 MCP Server
python
# my_mcp_server.pyfrom mcp.server.fastmcp import FastMCP
import httpx
# 创建 MCP Server 实例
mcp = FastMCP("employee-service")
@mcp.tool()
async def query_employee(username: str) -> dict:
"""查询员工基础信息,包括姓名、部门、职级等。
Args:
username: 员工用户名(邮箱前缀),如 zhangsan
"""# 调用已有的 HTTP APIasync with httpx.AsyncClient() as client:
resp = await client.get(f"https://api.internal.com/employee/{username}")
return resp.json()
@mcp.tool()
async def query_department(dept_id: str) -> dict:
"""查询部门信息。
Args:
dept_id: 部门 ID
"""
async with httpx.AsyncClient() as client:
resp = await client.get(f"https://api.internal.com/dept/{dept_id}")
return resp.json()# 启动服务if __name__ == "__main__":
mcp.run(transport="stdio") # 本地模式# mcp.run(transport="sse", port=8080) # 远程模式第三步:验证 Server 工具列表
bash
# 用 MCP Inspector 测试(官方调试工具)
npx @modelcontextprotocol/inspector python my_mcp_server.py关键点 :
@mcp.tool()装饰器下方的函数文档字符串(docstring)非常重要------大模型正是通过阅读这段描述来理解"这个工具能做什么、什么时候该用它"。写得越清楚,大模型调用得越准确。
注册 MCP Server 的核心步骤
┌──────────────────────────────────────────────────────────┐
│ 将已有能力注册为 MCP Server 的 4 个步骤 │
├──────┬───────────────────────────────────────────────────┤
│ 1 │ 安装 MCP SDK(Python: mcp / Node: @mcp/sdk) │
├──────┼───────────────────────────────────────────────────┤
│ 2 │ 用 @mcp.tool() 包装已有函数/API │
│ │ 重点:写清楚函数描述和参数说明 │
├──────┼───────────────────────────────────────────────────┤
│ 3 │ 选择传输方式:stdio(本地)或 HTTP(远程) │
├──────┼───────────────────────────────────────────────────┤
│ 4 │ 用 MCP Inspector 测试验证工具是否可正常调用 │
└──────┴───────────────────────────────────────────────────┘注意:聪明的你可能已经发现,这是一个极其不安全的接口,未来所有的MCP Server都会添加权限控制;
现阶段也会控制相关MCP Server的开放范围
三:什么是 Skill?有什么基础规范?
4.1 为什么有了 MCP 还需要 Skill ?
MCP Server 解决了"大模型能不能调用工具"的问题,但还有一个更重要的问题没解决:
┌─────────────────────────────────────────────────────────┐
│ 没有 Skill 时的问题 │
├─────────────────────────────────────────────────────────┤
│ │
│ 用户:"帮我报销上周的火车票" │
│ │
│ 大模型看到 10+ 个 MCP 工具,它会疑惑: │
│ │
│ ❓ 该先调哪个工具?后调哪个? │
│ ❓ 查到差旅申请单后怎么匹配? │
│ ❓ 费用类型怎么选?动态字段怎么填? │
│ ❓ 金额超标了怎么处理? │
│ ❓ 最终报文怎么组装? │
│ │
│ 结果:大模型可能胡乱调用工具,流程混乱,结果出错 │
└─────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────┐
│ 有 Skill 后 │
├─────────────────────────────────────────────────────────┤
│ │
│ Skill 像"操作手册"一样告诉大模型: │
│ │
│ ✅ 步骤 1:先上传发票并 OCR 识别 │
│ ✅ 步骤 2:查用户信息和差旅申请单 │
│ ✅ 步骤 3:用日期匹配差旅单 │
│ ✅ 步骤 4:确定费用类型、补全字段、校验超标 │
│ ✅ 步骤 5:组装报文提交草稿 │
│ │
│ 结果:大模型按步骤精确执行,流程正确,结果可靠 │
└─────────────────────────────────────────────────────────┘一句话总结:MCP 是"能力",Skill 是"智慧"。MCP 让大模型有工具可用,Skill 教大模型正确使用工具。
4.2 Skill 的本质
Skill 本质上就是一个 Markdown 文件( SKILL.md),里面用自然语言写清楚:
- 这个 Skill 做什么 (description)
- 什么时候触发 (适用场景)
- 需要哪些前置条件 (MCP Server、账号等)
- 具体执行步骤 (按什么顺序调用哪些工具)
- 异常怎么处理 (错误兜底策略)
4.3 Skill 的标准目录结构
推荐大家看一下:使用 skills 扩展 Claude - Claude Code Docs claude code的官方解释 ;
~/.config/opencode/skills/
└── my-skill-name/ # Skill 文件夹(名称即 Skill ID)
├── SKILL.md # 【必须】Skill 主文件
├── references/ # 【可选】参考资料
│ ├── api-reference.md # API 文档
│ └── field-mapping.md # 字段映射表
└── scripts/ # 【可选】辅助脚本
├── upload.py # 上传脚本
└── README.md # 脚本说明4.4 SKILL.md 的基础规范
markdown
---
name: my-skill-name # Skill 唯一标识
description: 一句话描述 Skill 的功能。 # 大模型通过这段话判断是否触发
当用户说「xxx」时使用。 # 触发关键词
依赖 MCP server xxx。 # 声明依赖---**# Skill 标题## 目的**
用 1-2 句话说明 Skill 要实现什么目标。
---
**## 适用场景** - 用户说「帮我做 xxx」时触发
- 用户上传了 xxx 文件时触发
**## 前置条件** 1. ****MCP Server 可用****:xxx-server
2. ****用户账号****:需要 xxx 权限
**## 执行流程### 步骤 1:xxx**
具体说明调用哪个 MCP 工具,传什么参数...
**### 步骤 2:xxx**
...
**## 异常处理** - 如果 xxx 失败,则 ...4.5 Skill 触发机制
┌──────────────────────────────────────────────────────┐
│ Skill 触发流程 │
│ │
│ 用户输入 ──► AI 助手读取所有 Skill 的 description │
│ │ │
│ ▼ │
│ description 与用户意图匹配? │
│ / \ │
│ 是 否 │
│ / \ │
│ ▼ ▼ │
│ 加载 SKILL.md 不加载,正常对话 │
│ 按流程执行 │
└──────────────────────────────────────────────────────┘重要 :
description字段是 Skill 的"触发器"。AI 助手会在对话开始时扫描所有 Skill 的 description,与用户意图匹配后才加载完整的 SKILL.md。所以 description 要写得精准,包含用户可能用到的关键词。
四:怎么写 Skill?Skill 怎么调用 MCP 工具?
4.1 完整示例:飞书文档导出 Skill
下面以一个真实的 Skill 为例,展示完整的写法:
markdown
---name: larkkit-feishu-doc
description: 使用 larkkit 实现飞书文档与 Markdown 双向无损转换。
当用户需要「下载飞书文档」「把飞书文档导出为 Markdown」
「上传 Markdown 到飞书」「批量下载/上传飞书文档」
「查看文档/知识库信息」或类似表述时使用。
依赖本机已安装 larkkit 且已配置 ~/.larkkit/config。---**# 飞书文档 ↔ Markdown 转换 Skill## 目的**
让用户通过自然语言完成飞书文档与 Markdown 的互转。
**## 适用场景** - 用户说「下载这个飞书文档」或给出飞书文档 URL
- 用户说「把这个 md 文件上传到飞书」
**## 前置条件** 1. ****larkkit 已安装****:`uv tool install larkkit`2. ****配置文件就绪****:`~/.larkkit/config` 中包含 app_id 和 app_secret
**## 执行流程### 下载文档**
用户提供飞书文档 URL 时,执行:
larkkit download <URL> -o <输出目录>**### 上传文档**
用户要上传 Markdown 时,执行:
larkkit upload <文件路径> --to <目标飞书URL>**## 异常处理** - 如果提示权限不足,引导用户执行 `larkkit auth`- 如果 URL 格式无法识别,提示用户确认链接4.2 Skill 中引用 MCP 工具的方式
Skill 不需要写代码来调用 MCP 工具。只需在 SKILL.md 中用自然语言描述 应该调用哪个工具、传什么参数,大模型会自动完成调用。
markdown
**### 步骤 2:拉取用户基础信息**
调用 MCP 工具 `queryExpenseApplier`,参数如下:
- `docApplierUsername`:用户提供的账号(邮箱前缀)
从返回结果中保存以下关键字段:
- `companyId` → 后续步骤需要
- `costCenterId` → 后续步骤需要
- `deptId` → 后续步骤需要
- `fdPersonDeptId` → 部门 ID
向用户展示姓名、部门、公司等基本信息。大模型读到这段描述后,会自动:
- 调用
queryExpenseApplier这个 MCP 工具 - 传入正确的参数
- 解析返回结果
- 保存需要的字段
Skill 的威力在于:你不需要写一行代码,只需要用清楚的自然语言描述流程,大模型就能自动编排 MCP 工具调用。
4.3 Skill 开发完整流程图
┌────────────────────────────────────────────────────────────────┐
│ Skill 开发全流程 │
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌────────────┐ │
│ │ 1. 需求 │──►│ 2. 确认 │──►│ 3. 编写 │──►│ 4. 本地 │ │
│ │ 分析 │ │ MCP 工具 │ │ SKILL.md │ │ 测试 │ │
│ │ │ │ 是否就绪 │ │ │ │ │ │
│ └──────────┘ └──────────┘ └──────────┘ └─────┬──────┘ │
│ │ │
│ ▼ │
│ ┌────────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 7. 版本 │◄──│ 6. 团队 │◄──│ 5. 迭代 │ │
│ │ 发布 │ │ 评审 │ │ 优化 │ │
│ └────────────┘ └──────────┘ └──────────┘ │
└────────────────────────────────────────────────────────────────需求分析写好一个Skill最关键的部分,当你给到足够的知识输入,你只需要告诉大模型帮你创建一个Skill就可以了;
推荐一个好用的skill: https://skills.sh/francyjglisboa/agent-skill-creator/agent-skill-creator
4.4 在哪获取和使用 Skill?
五:开源社区
目前各开源社区上面可以找到很多好用skill , 养龙虾的同学可以多关注
-
Skill Hub:https://skills.sh/
-
Openclaw Skill Hub:https://clawhub.ai/skills?sort=downloads&nonSuspicious=true
-
Github :https://github.com/VoltAgent/awesome-openclaw-skills