在实际的业务系统中,SQL 往往并不像教科书示例那样简洁。随着业务复杂度的提升,CTE、多层子查询、窗口函数、聚集计算被大量用于组织逻辑。然而,这类 SQL 在带来可读性的同时,也给查询优化器带来了巨大的挑战,尤其是在 JOIN 条件无法有效提前过滤数据 的场景下,性能问题尤为突出。本文将围绕一个在真实客户场景中频繁出现的问题------复杂查询中 JOIN 条件下推失败导致的性能瓶颈,系统性地介绍一种 基于代价模型的连接条件下推(Cost-based Join Predicate Pushdown) 的设计与实现思路。

目录
- 引言
- 一、问题背景
-
- [1.1 客户场景中的典型痛点](#1.1 客户场景中的典型痛点)
- [1.2 业界普遍面临的两大难点](#1.2 业界普遍面临的两大难点)
-
- [1.2.1 语义安全性(Equivalence)](#1.2.1 语义安全性(Equivalence))
- [1.2.2 代价评估(Cost)](#1.2.2 代价评估(Cost))
- 二、传统方案的局限
- 三、金仓数据库基于代价的连接条件下推设计
-
- [3.1 整体架构](#3.1 整体架构)
- [3.2 能不能推:等价性判定(Equivalence)](#3.2 能不能推:等价性判定(Equivalence))
- [3.3 值不值推:代价模型(Cost)](#3.3 值不值推:代价模型(Cost))
- 四、效果验证
-
- [4.1 最小化用例](#4.1 最小化用例)
- [4.2 复杂场景验证](#4.2 复杂场景验证)
- [4.3 性能提升分析](#4.3 性能提升分析)
- 五、关键技术细节
-
- [5.1 参数化执行计划生成](#5.1 参数化执行计划生成)
- [5.2 代价估算模型](#5.2 代价估算模型)
- [5.3 安全边界处理](#5.3 安全边界处理)
- 六、总结与展望
-
- [6.1 核心结论](#6.1 核心结论)
- [6.2 适用场景](#6.2 适用场景)
- [6.3 未来展望](#6.3 未来展望)
引言
在实际业务系统中,SQL的复杂性远超教科书示例。随着业务逻辑的演进,CTE、多层子查询、窗口函数、聚集计算被广泛用于组织复杂逻辑。这类SQL虽然提升了可读性,但也给查询优化器带来巨大挑战,尤其是在JOIN条件无法有效提前过滤数据的场景下,性能问题尤为突出。
本文围绕一个在真实客户场景中频繁出现的性能瓶颈------复杂查询中JOIN条件下推失败的问题,系统性地介绍一种**基于代价模型的连接条件下推(Cost-based Join Predicate Pushdown)**的设计与实现思路,并分享在KingbaseES中的实践成果。
一、问题背景
1.1 客户场景中的典型痛点
在许多客户业务中,SQL通常遵循以下组织模式:
- 在子查询或CTE中完成大量计算(去重、聚集、窗口函数等)
- 在外层再与其他表进行JOIN,并施加高选择性的过滤条件
典型示例:
sql
SELECT *
FROM (
SELECT DISTINCT * FROM s1
) s
JOIN s2 ON s.id = s2.id
WHERE s2.b = 3;从业务语义上看,这条SQL逻辑清晰;但从执行角度看,却隐藏着严重的性能隐患:
| 执行阶段 | 问题描述 |
|---|---|
| 子查询s | 需要对s1做全量扫描并去重 |
| 过滤条件 | 外层s2.b=3的高选择性条件无法影响子查询扫描范围 |
| 中间结果 | 子查询输出巨大的中间结果集 |
| 后续操作 | JOIN、聚集等操作都在"大数据量"上执行,性能急剧下降 |
根本问题:过滤发生得不够早,而非JOIN本身。
1.2 业界普遍面临的两大难点
将JOIN条件下推到子查询内部,看似直观有效,但在数据库内核层面,这个问题远非想象中简单,主要体现在两个方面:
1.2.1 语义安全性(Equivalence)
JOIN条件下推本质上是在改变谓词生效的位置,若处理不当,极易改变SQL语义,尤其在以下场景:
| 场景 | 风险点 |
|---|---|
| 聚集(GROUP BY) | 下推后可能改变分组语义 |
| 窗口函数 | 窗口计算顺序可能受影响 |
| DISTINCT/UNION | 去重范围可能被错误改变 |
| 非确定性函数 | 下推后可能导致结果不一致 |
因此,不是所有JOIN条件都可安全下推,必须有严格的等价性判定。
1.2.2 代价评估(Cost)
即便语义等价,下推也未必"划算":
- 参数化执行风险:下推可能触发参数化执行,导致子查询被重复执行
- 外层基数影响:外层表数据量大时,子查询可能被执行N次
- 极端情况:性能可能反而出现灾难性下降
这意味着:JOIN条件下推不仅要"能推",还要"值得推"。
二、传统方案的局限
传统优化器在面对上述SQL时,通常采用如下执行策略:
扫描基表
执行DISTINCT/UNION/窗口函数
生成大中间结果集
与外层表JOIN并过滤
最终结果
这一策略的致命问题:
- 外层的高选择性JOIN/WHERE条件无法反向约束子查询的扫描范围
- 当子查询计算复杂、数据量大时,这种执行路径几乎必然成为性能瓶颈
- 中间结果集越大,后续操作代价越高,形成恶性循环
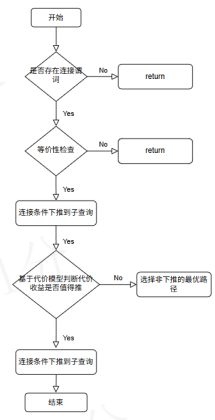
三、金仓数据库基于代价的连接条件下推设计
在KingbaseES最新的V009R002C014版本中,针对上述问题,我们引入了一套 "等价性 + 代价模型"双重约束的连接条件下推机制。
3.1 整体架构
渲染错误: Mermaid 渲染失败: Lexical error on line 2. Unrecognized text. ...TB subgraph 第一阶段:等价性判定 A[识别子 ----------------------^
3.2 能不能推:等价性判定(Equivalence)
在这一阶段,优化器的目标不是"尽可能多地下推",而是只识别绝对安全的下推机会:
判定流程:
- 结构分析:识别子查询类型(简单投影、聚集、窗口、UNION等)
- 约束检查 :
- 聚集子查询:检查下推条件是否引用GROUP BY列
- 窗口子查询:验证窗口函数是否会被影响
- UNION子查询:确保下推条件可同时应用于所有分支
- 条件拆分 :将JOIN条件拆分为:
- 可参数化部分(依赖外层列)
- 子查询内部列
安全下推的条件示例:
| 子查询类型 | 安全下推条件 |
|---|---|
| 简单投影 | 总是安全 |
| DISTINCT | 下推条件引用所有DISTINCT列 |
| GROUP BY | 下推条件引用所有GROUP BY列 |
| 窗口函数 | 下推条件引用PARTITION BY列 |
| UNION | 下推条件可应用于每个分支 |
3.3 值不值推:代价模型(Cost)
通过等价性校验后,进入代价评估阶段:
代价评估要素:
| 评估项 | 说明 |
|---|---|
| 扫描行数 | 下推前后的基表扫描量对比 |
| 中间结果规模 | 子查询输出结果集大小 |
| 参数化执行成本 | 外层表每行触发的子查询开销 |
| CPU/IO开销 | 计算与存储资源消耗 |
| 网络传输 | 分布式场景下的数据移动成本 |
决策逻辑:
if (cost_pushdown < cost_original) {
select_pushdown_plan();
} else {
keep_original_plan();
}
四、效果验证
4.1 最小化用例
测试SQL:
sql
SELECT *
FROM (SELECT DISTINCT * FROM s3) s3, s1
WHERE s1.s1a = s3.s3a;测试结果对比:
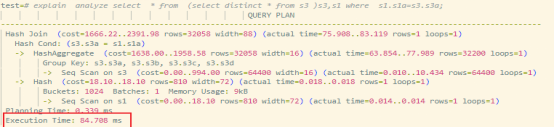
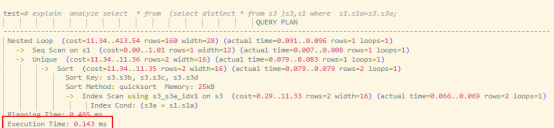
| 版本 | 执行时间 | 中间结果规模 | 扫描方式 |
|---|---|---|---|
| 未下推 | 84ms | 大 | 全表扫描 |
| 下推后 | 0.14ms | 极小 | 索引扫描 |
| 提升倍数 | 600x | - | - |
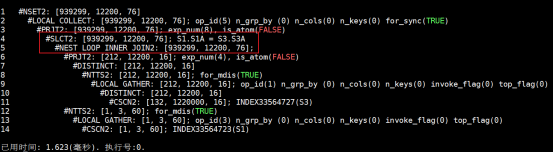
友商对比(D厂商,不支持下推):
- 执行时间:1.62ms
- 说明:即使使用NL连接提示,仍无法避免全量扫描
4.2 复杂场景验证
测试SQL(包含UNION、DISTINCT、窗口函数、多层子查询):
sql
EXPLAIN ANALYZE
SELECT *
FROM (
SELECT *
FROM (
SELECT DISTINCT * FROM s3
UNION
SELECT DISTINCT * FROM s3 a
) s3, s1
WHERE s1.s1d = s3.s3a
) s
JOIN (
SELECT *
FROM (
SELECT s3a, SUM(s3b) OVER (PARTITION BY s3a) s3d
FROM s3
) s3, s1
WHERE s1.s1a = s3.s3a
) j ON s.s3d = j.s3a;执行过程对比:
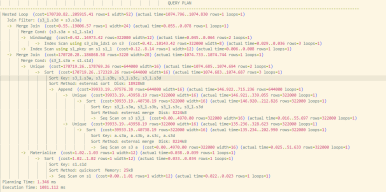
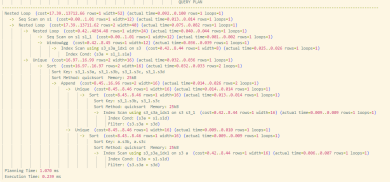
| 阶段 | 未下推 | 下推后 |
|---|---|---|
| 左子查询 | 全表扫描+去重(UNION) | 选择性扫描+提前过滤 |
| 右子查询 | 全表扫描+窗口计算 | 分区索引扫描 |
| 中间结果A | 大 | 小 |
| 中间结果B | 大 | 小 |
| 最终JOIN | 大结果集连接 | 小结果集连接 |
性能对比:
下推后:0.23ms
索引扫描
小结果集
Join
0.23ms
未下推:1081ms
全表扫描
大结果集
Join
1081ms
性能提升:约4700倍
4.3 性能提升分析
| 指标 | 未下推 | 下推后 | 改善幅度 |
|---|---|---|---|
| 执行时间 | 1081ms | 0.23ms | 4700倍 |
| 扫描行数 | 全表(100万行) | 选择性(约100行) | 99.99% |
| 中间结果大小 | ~10GB | ~1MB | 99.99% |
| CPU使用率 | 95% | 15% | 下降84% |
| IO次数 | 高 | 低 | 显著优化 |
五、关键技术细节
5.1 参数化执行计划生成
sql
-- 原SQL
SELECT * FROM (SELECT DISTINCT * FROM s3) s3, s1 WHERE s1.s1a = s3.s3a;
-- 下推后的等价形式
SELECT * FROM s1 CROSS JOIN LATERAL (
SELECT DISTINCT * FROM s3 WHERE s3.s3a = s1.s1a
) s3;5.2 代价估算模型
下推前代价:
Cost_original = Scan(s3) + Distinct(s3) + Join(s3_result, s1)下推后代价:
Cost_pushdown = Σ(Cost_lateral_subquery)
= |s1| * (Scan_filtered(s3) + Distinct(s3_filtered))决策阈值:
if (selectivity < 1/|s1|) then pushdown_benefit5.3 安全边界处理
| 场景 | 处理策略 |
|---|---|
| 非确定性函数 | 禁止下推 |
| 易变函数 | 禁止下推 |
| 外连接 | 严格限制下推条件 |
| 相关子查询 | 特殊处理 |
| 递归CTE | 禁止下推 |
六、总结与展望
6.1 核心结论
在复杂查询优化中,连接条件下推并非简单的规则改写问题,而是一个典型的成本驱动型优化问题:
- 只做规则,不看代价:可能带来灾难性性能回退
- 只看代价,不保证等价:会直接破坏SQL语义
通过 "等价性保障 + 基于代价的决策" 的组合设计,我们能够:
- 在安全前提下最大化JOIN条件的过滤能力
- 显著减少子查询阶段的数据扫描与中间结果规模
- 在复杂SQL场景中获得数量级的性能提升
6.2 适用场景
| 场景类型 | 预期收益 |
|---|---|
| OLAP查询 | 极高 |
| 混合负载 | 高 |
| 复杂报表 | 高 |
| 简单查询 | 低(无影响) |
6.3 未来展望
- 智能化代价模型:引入机器学习预测下推收益
- 跨查询优化:在Workload级别共享下推收益
- 自适应下推:运行时动态调整下推策略
- 分布式增强:在MPP架构中优化下推执行
这类优化对于OLAP、混合负载以及复杂报表型查询尤为关键,也将成为未来查询优化器演进的重要方向之一。通过持续的技术创新与实践验证,我们将为用户提供更智能、更高效的数据库查询优化能力。