文章目录
-
- 引言:时序数据的爆发时代
- 一、时序数据模型:理解数据本质是选型的第一步
-
- [1.1 什么是时序数据?](#1.1 什么是时序数据?)
- [1.2 时序数据的三层模型结构](#1.2 时序数据的三层模型结构)
- 二、为什么需要专门的时序数据库?
- 三、前沿能力:时序大模型开启智能分析时代
-
- [3.1 IoTDB 支持的时序大模型](#3.1 IoTDB 支持的时序大模型)
- [3.2 三大智能应用场景](#3.2 三大智能应用场景)
- [3.3 快速部署体验](#3.3 快速部署体验)
- 四、选型建议:什么时候选择IoTDB?
- 五、总结
引言:时序数据的爆发时代
万物互联的今天,工业物联网、智慧能源、智能制造等场景正在进行深度数字化转型。一台风力发电机每天产生数百万个数据点,一辆智能网联汽车每秒上传数百个信号量,一座智能工厂每分钟记录数万条设备状态------这些数据共同构成了我们时代的"数字脉搏"。
但如何高效存储、查询和分析这些海量时序数据?如何选择适合业务场景的时序数据库?本文将从数据模型、分析能力、智能运维等角度,为您提供一份实用的时序数据库选型指南,并重点介绍 Apache IoTDB 在这一领域的创新实践。
一、时序数据模型:理解数据本质是选型的第一步
1.1 什么是时序数据?
时序数据是由一系列按时间递增排列的数据点组成的序列。每个数据点包含一个时间戳和一个数值。比如电机采集的电压、风机叶片的转速、车辆的GPS位置、桥梁的振动频率等。
用表格的形式看,一条时间序列就是时间戳和数值两列;用图形化看,它就是一条随时间变化的曲线------我们称之为设备的"心电图"。
1.2 时序数据的三层模型结构
理解时序数据的关键在于掌握三个核心概念:数据点 、测点 、设备。
数据点:由一个时间戳(long类型)和一个具体数值(boolean/int32/float等)组成,是时序数据的最小单元。
测点:同一采集点位按时间递增形成的时间序列。电力场景的电流、车联网的车速、工厂的温度都属于测点。
设备 :一组测点的集合,对应现实物理设备。车辆由VIN码标识,风机由区域+场站+线路标识,CPU由机房+机架+hostname标识。
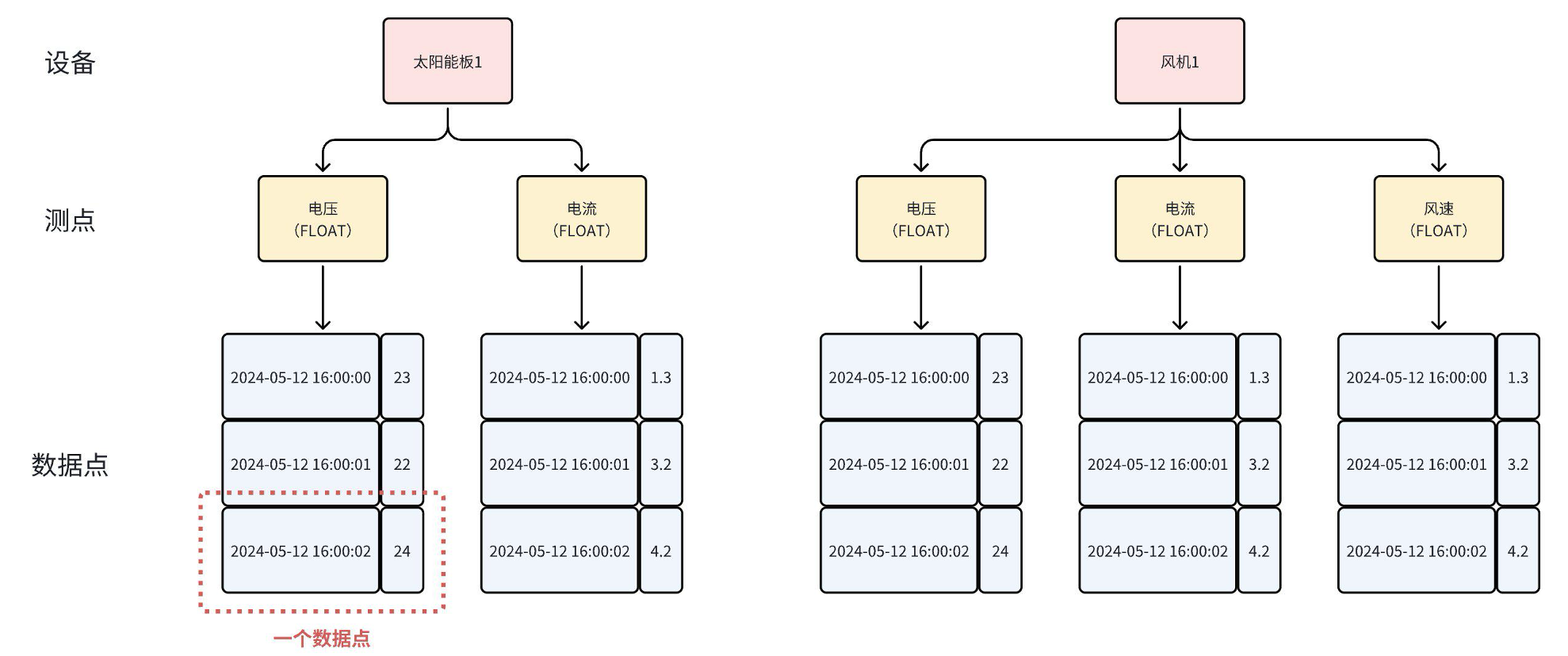
下图清晰展示了这三层结构的关系:
设备 (Device)
├── 测点1: 电压 (Voltage)
│ ├── 数据点: (2025-01-01 00:00:00, 220.5)
│ ├── 数据点: (2025-01-01 00:00:01, 220.8)
│ └── ...
├── 测点2: 电流 (Current)
└── 测点3: 温度 (Temperature)这一模型使得IoTDB能够天然对齐工业物联网的层级组织结构,在数据写入和查询时保持极高的语义保真度。
二、为什么需要专门的时序数据库?
传统关系型数据库在处理时序数据时面临三大痛点:
| 痛点 | 表现 | 后果 |
|---|---|---|
| 写入瓶颈 | 每秒百万级点写入压力 | 数据丢失,系统崩溃 |
| 查询缓慢 | 时间范围查询扫描大量无关数据 | 分析延迟,用户体验差 |
| 存储爆炸 | 无差别存储压缩 | 成本指数级增长 |
Apache IoTDB 针对这些问题设计了专门的存储引擎:采用列式存储、双索引LSM树、高效压缩算法(支持有损/无损混合压缩),在工业场景实测中写入吞吐可达每秒千万点,存储空间仅为原始数据的1/10到1/50。
三、前沿能力:时序大模型开启智能分析时代
传统时序数据库擅长"存"和"查",但面对预测、异常检测、填补等分析任务,往往需要用户自己训练模型。Apache IoTDB 创新性地引入了 AINode 架构,内置了多个前沿时序大模型,将数据库从"存储基础设施"升级为"智能分析平台"。
3.1 IoTDB 支持的时序大模型
IoTDB 团队长期自研 Timer 系列模型,同时集成业界前沿成果:
| 模型 | 参数规模 | 核心能力 | 适用场景 |
|---|---|---|---|
| Timer-XL | 十亿级 | 超长上下文、多变量预测 | 工业时序、多传感器融合 |
| Timer-Sundial | 1.28亿 | 零样本预测、概率预测 | 快速部署、不确定性分析 |
| Chronos-2 | - | 通用预测、协变量支持 | AWS生态、多变量场景 |
这些模型均基于 Transformer 架构,经过海量跨领域时序数据预训练,具备零样本 和少样本泛化能力。
3.2 三大智能应用场景
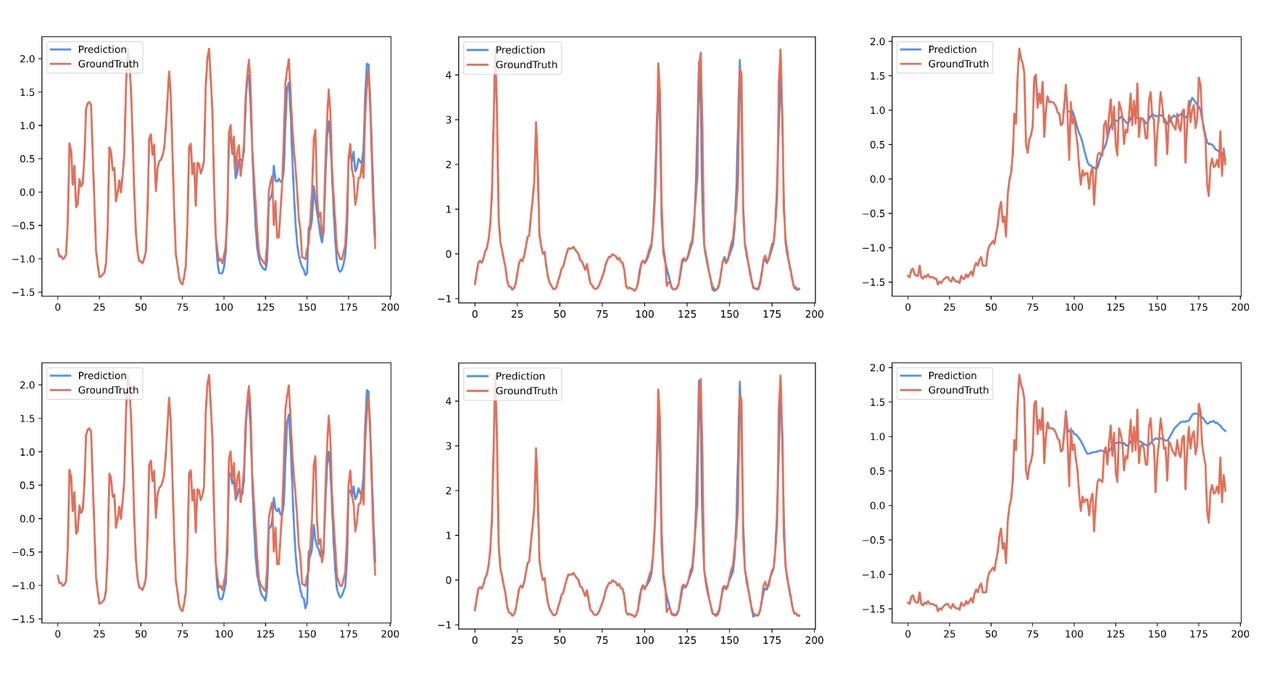
场景一:时序预测
下图展示了 Timer 模型对风机功率的预测效果(蓝色为预测,红色为实际值),两条曲线高度吻合:
代码示例 - 使用IoTDB进行预测:
sql
-- 查看已部署的模型
IoTDB> show models
-- 使用Timer-XL预测未来24小时的风机功率
IoTDB> SELECT forecast(s1, model='timer_xl', horizon=24)
FROM root.windfarm.wt01.speed
WHERE time >= 2025-01-01 00:00:00
-- 使用Sundial进行概率预测(输出分位数)
IoTDB> SELECT forecast_prob(s1, model='sundial', quantiles=[0.1,0.5,0.9])
FROM root.windfarm.wt01.power场景二:异常检测
利用自回归技术实时监测数据流,精准识别偏离正常模式的异常点。支持在写入过程中自动标注异常,无需后处理。
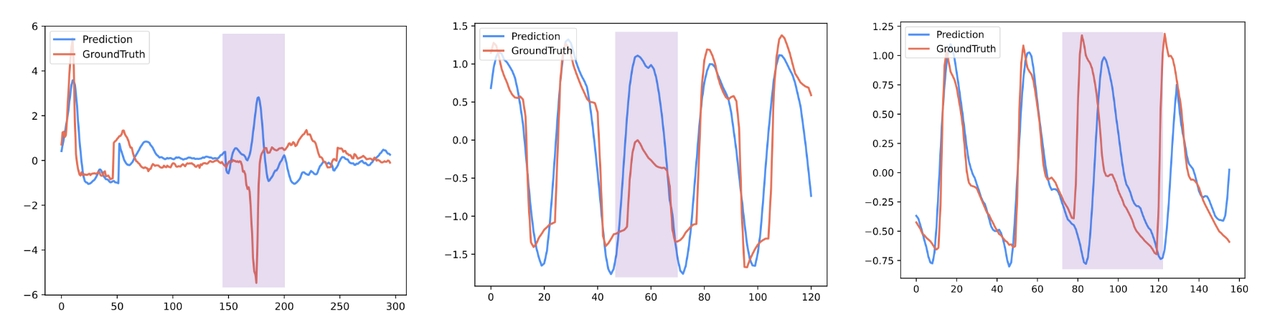
sql
-- 实时异常检测
IoTDB> SELECT s1, anomaly(s1, model='timer_xl') as is_anomaly
FROM root.factory.robot1.vibration
WHERE time >= now() - 1h场景三:数据填补
工业场景中传感器故障、网络中断常导致数据缺失。时序大模型能根据上下文自动填补缺失段,增强数据完整性。
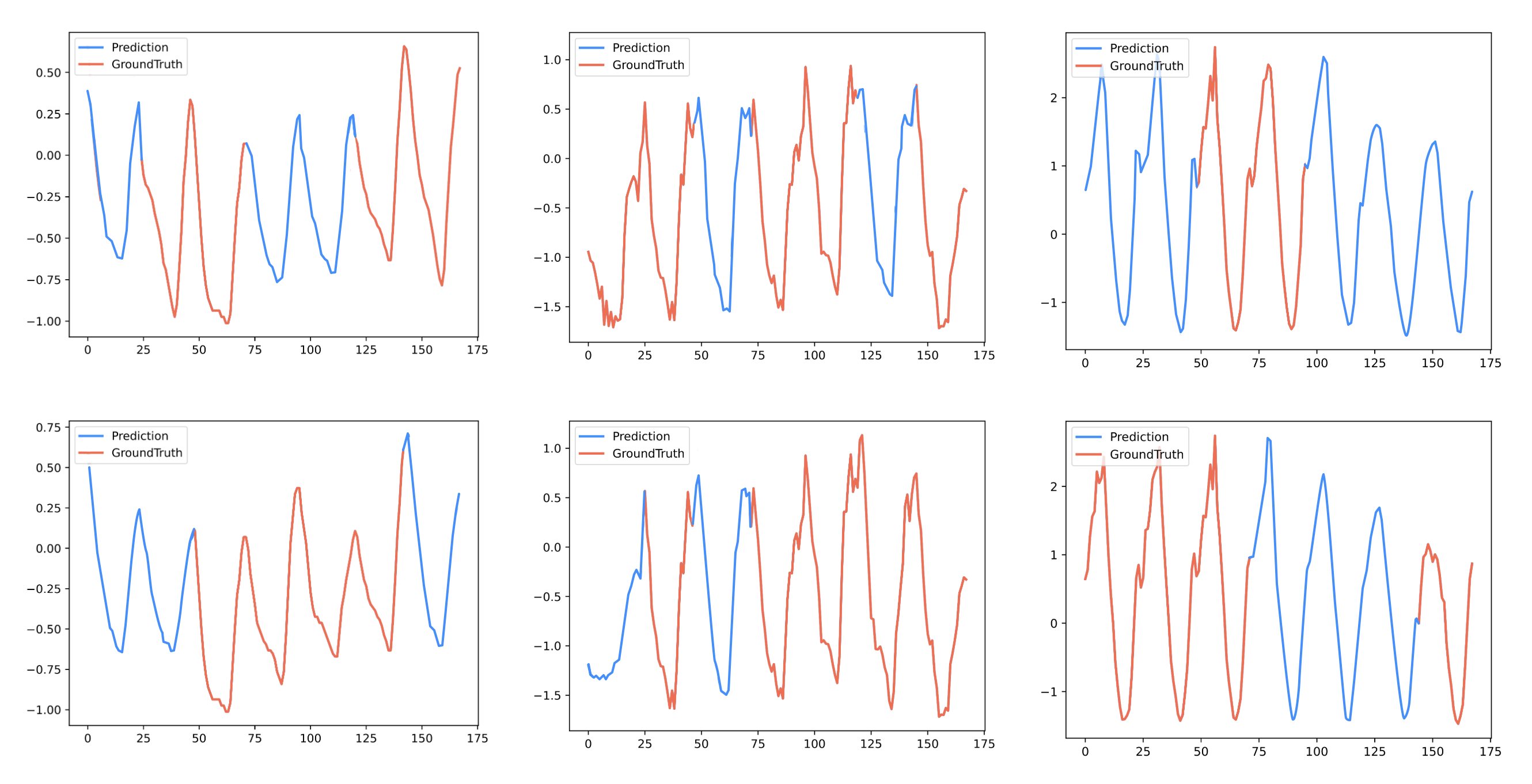
sql
-- 填补缺失数据
IoTDB> SELECT impute(temperature, method='timer_xl')
FROM root.plant.boiler
WHERE time BETWEEN 2025-01-01 00:00:00 AND 2025-01-02 00:00:003.3 快速部署体验
IoTDB 集群架构支持专门的 AINode 节点,部署后自动拉取模型权重:
bash
# 检查集群状态
IoTDB> show cluster
+------+----------+-------+---------------+------------+
|NodeID| NodeType |Status |InternalAddress|InternalPort|
+------+----------+-------+---------------+------------+
| 0|ConfigNode|Running| 127.0.0.1 | 10710|
| 1| DataNode|Running| 127.0.0.1 | 10730|
| 2| AINode|Running| 127.0.0.1 | 10810|
+------+----------+-------+---------------+------------+
# 验证模型可用
IoTDB> show models
+---------------------+---------+--------+--------+
| ModelId|ModelType|Category| State|
+---------------------+---------+--------+--------+
| timer_xl| timer| builtin| active|
| sundial| sundial| builtin| active|
| chronos2| t5| builtin| active|
+---------------------+---------+--------+--------+四、选型建议:什么时候选择IoTDB?
| 场景特征 | 推荐程度 | 理由 |
|---|---|---|
| 工业物联网/智能制造 | ⭐⭐⭐⭐⭐ | 原生支持设备-测点层级模型 |
| 需要内置AI分析能力 | ⭐⭐⭐⭐⭐ | AINode + 时序大模型开箱即用 |
| 边缘-云端协同部署 | ⭐⭐⭐⭐⭐ | 支持边缘侧的轻量化版本 |
| 纯云原生时序分析 | ⭐⭐⭐⭐ | 可对接K8s等容器平台 |
| 简单监控指标存储 | ⭐⭐⭐ | 功能过剩,可考虑更轻量方案 |
五、总结
时序数据库的选型需要从数据模型匹配度、写入查询性能、存储成本、智能分析能力四个维度综合评估。Apache IoTDB 凭借其:
- ✅ 工业原生的树形数据模型
- ✅ 千万级写入吞吐能力
- ✅ 内置时序大模型的创新架构
- ✅ 边缘-云协同的完整生态
正在成为工业物联网、智能制造、智慧能源等领域的首选时序数据基础设施。随着时序大模型能力的持续进化,未来的时序数据库将不仅是数据的"仓库",更是企业智能决策的"大脑"。