1 什么是 Cache ?
Cache 是一块高速内存,由于 CPU 和 主存(通常是DDR等) 速度之间存在数量级的差异,于是在 CPU 和 主存 之间,加入速度更快、造价更高、容量更小 的内存,也即 Cache,以缓解 CPU 和 主存 之间速度差异造成的性能损失:CPU 可以先将数据从主存加载到高速内存(即Cache),然后 CPU 大多数时候和高速Cache交互,在必要的时候从主存加载数据到Cache,或者将Cache中的数据刷入到主存。
2 Cache 工作原理
Cache 之所以能提高程序的速度,首先自然是因为它相对于主存更高的读写速度。但同时由于 Cache 的容量有限,不可能缓存所有程序和数据,此时 Cache 利用了程序执行的 空间局部性(Spatial locality) 和 时间局部性(Temporal locality) 原理,来提高程序的性能。
空间局部性(Spatial locality) 是指紧邻当前位置访问的指令和数据,接下来本访问的可能性很大。
时间局部性(Temporal locality) 是指最近访问的指令和数据,在接下来短时间内被访问的可能性很大。
3 Cache 层级
CPU Cache一般分为L1(一级缓存)、L2(二级缓存)和L3(三级缓存),它们离CPU核心的距离依次增加,容量依次增大,速度依次降低。
L1 Cache:最快(周期级访问),容量最小(几十KB),分指令缓存(I-Cache)和数据缓存(D-Cache),避免指令与数据竞争带宽。
L2/L3 Cache:容量递增,速度递减,L3通常为多核共享。
4 内存架构中各级访问速度概览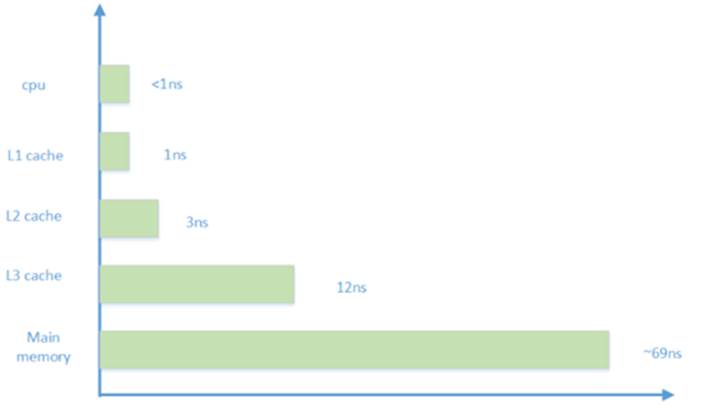
5 Cache 分类
按照 处理器 取指操作 和 数据读写操作,是否使用独立的 指令 Cache 和 数据 Cache ,可以将 Cache 分为 统一型 Cache(Unified Cache) 和 分离型 Cache(Separate cache) 。统一型 Cache(Unified Cache) 指令 和 数据 使用相同的 Cache; 分离型 Cache(Separate cache) 指令 和 数据 使用各自独立的 Cache 。统一型 Cache(Unified Cache) 是 冯.诺伊曼架构(Neumann architecture) 使用的模型; 分离型 Cache(Separate cache) 是 哈佛架构(Harvard architecture) 使用的模型。
ARM 架构下 Cache,使用 哈佛架构(Harvard architecture) 的 分离型 Cache(Separate cache) 。
6 Cache 的 查找 和 组织方式
下图给出了 ARMv7 架构下的 Cache 组织形式:
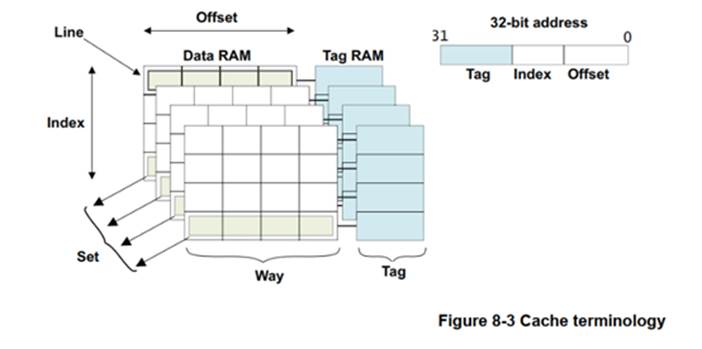
6.1 Cache 组织相关术语
先介绍下 Cache 相关术语 Way 和 Line :
Way:
中文通常翻译为 路,将 Cache 按容量平均分成 N 份,每一份称为一路(Way),N 份就是 N 路(Way)。如一个 32KB 的 Cache ,分为4份,每份 32KB / 4 = 8KB ,每 8KB 为一路,总共有 4 路。
Line:
Cache 行(Line),Cache的每一路(Way),包含多个 Cache 行(Line),每个 Cache 行(Line)包含 多个Word 或 多个字节,所有的 Cache 行(Line)的长度都是一样的,常见的有 32 或 64 字节等。如一个 32KB Cache 分为 4 路,则每路为 8KB,如果 Cache 行的长度为 64 字节,则每 8KB 大小的一路 Cache,将包含 8KB / 64 = 128 个 Cache 行。由于所有 Cache 路 具有相同的容量,那自然所有的 Cache 路 都包含相同的 Cache 行 数目。Cache 行也是 和 主存 进行交互的最小单位,即 每次从 主存 加载 到 Cache ,或者 将 Cache 数据刷回到主存都是以 Cache 行 为单位进行的。
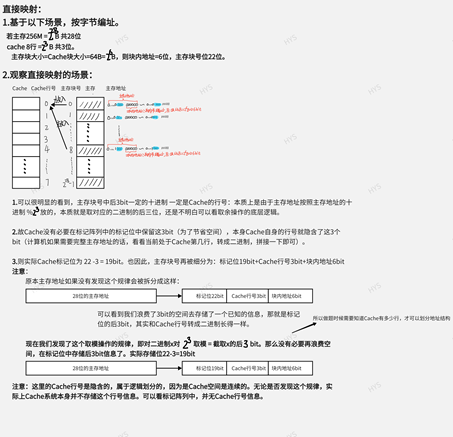
需要有一种方法,建立 主存地址块 和 Cache 行 之间的映射关系,硬件通过 主存地址块首地址,来建立 主存地址块 和 Cache 行 之间的映射,如下图(ARM32 架构示例):
上图将 主存地址块首地址,划分为 Tag,Index,Offset 三部分。其中:
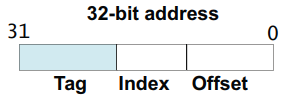
Tag: 用来 匹配 或者说 标记 一个 Cache 行。
每个 Cache 行有额外的空间(图中 Tag RAM),用来存储映射的主存内存块的首地址的 Tag ,这个额外 Tag 空间,
不包含在 Cache 行的存储空间(图中 Data RAM)之内。
Index: 每路 Cache 包含多个 Cache 行,这些 Cache 行通过 主存地址的 Index 部分进行索引。
Offset: 每个 Cache 行包含 多个Word 或 多个字节。这些 Cache 行中的 Word 或 字节,通过 Offset 进行定位。
Set: 所有 Cache 路中,(对应主存地址的) Index 相同的所有 Cache 行,称为 一组(Set)。组(Set)的数目对应每路中 Cache 行的数目。
如一个 32KB 的 Cache,分为 4 路,Cache 行大小为 64 字节,则每路 Cache 有 128 个 Cache 行,也即有 128 组(Set)。
6.2 Cache 查找
6.2.1 Cache 查找过程概述
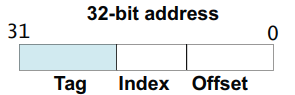
Cache 查找,是指根据数据的虚拟地址(VA:Virtual Address)和物理地址(PA:Physical Address),定位到 数据对应 Cache 行(Line)内的Word或字节偏移位置的过程。如果查找成功,则表示 Cache 命中(Cache Hit),否则为 Cache 未命中(Cache Miss) 。
Cache 查找过程将数据地址分为如下图的3部分进行:
6.3 Cache 的各种组织形式
本小节描述 Cache 的各种组织形式,以及它们各自的优缺点。
6.3.1 直接映射(Direct Mapped)
直接映射 Cache(Direct Mapped Cache),是指主存的每个位置,唯一映射到一个 Cache 行。由于 Cache 的容量远小于主存的容量,所以会存在多个主存位置映射到同一 Cache 行的情形。 映射示例如下图:
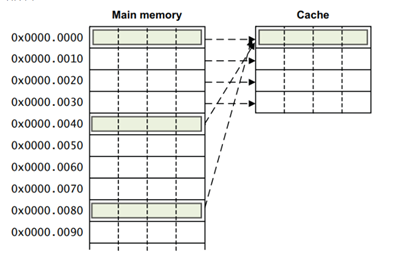
上图中,Cache 只有1路(Way),同时没有分组(Set),或者也可以认为是只有1路1组的情形;Cache 行大小为 16 字节,Cache 总大小为 16x4 = 64 字节,总共 64/16 = 4 个 Cache 行。
直接映射 Cache(Direct Mapped Cache) 的优点点在于硬件实现简单、成本低;缺点在于容易造成 Cache 颠簸(thrashing):前一数据刚被加载到某一 Cache 行,紧接着使用的数据又要使用相同的 Cache 行,这就使得前一数据刚加载到 Cache 行、立马又被换出这个 Cache 行,这样就无法利用 Cache 带来的速度优势。
6.3.2 多路组相联(N-Way Set-Associative)
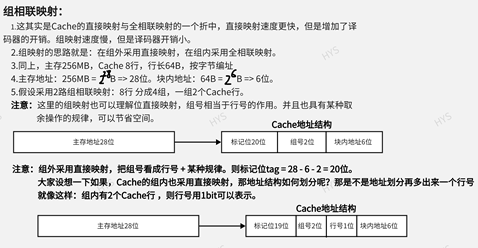
多路组相联 Cache(N-Way Set-Associative Cache),是指 将 Cache 按容量平均分成 N 份,称为 N 路(N-Way);同时每路(Way) Cache 中,Index 相同的 Cache 行(Line) 形成一组(Set),组(Set)的数目为一路(Way) Cache 包含的 Cache 行(Line)数。来看一个例子,有一 Cache,其容量为 128 字节,分为两路,每路容量则为 128/2 = 64 字节,Cache 行的大小为 16 字节,所以每路 Cache 包含 64/16 = 4 个 Cache 行,也即 Cache 组数为 4 组。这是一个 两路组相联的 Cache 。看一下图示:
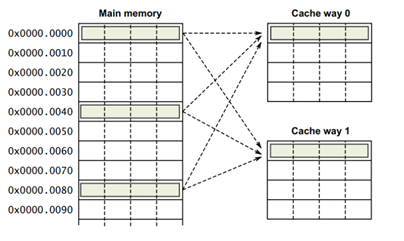
多路组相联 Cache(N-Way Set-Associative Cache),是现代 Cache 实现的主流方式。
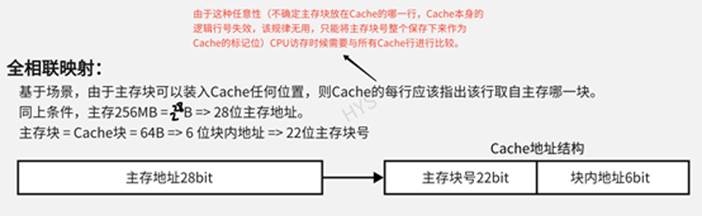
6.3.3 全相联(Fully Associative)
全相联 Cache(Fully Associative Cache),可以认为是 多路组相联(N-Way Set-Associative) 的一种特殊情形:任意的主存数据在 Cache 所有行都可进行映射。这和 直接映射 Cache(Direct Mapped Cache) 的情形刚好相反,是 Cache 映射的另一种极端情况。
在实际应用当中,大于4路的组相联 L1 Cache,对性能提升很小;8路 或 16路 的组相联,对于容量更大的 L2 Cache 会更有用。
7 Cache 策略
写策略:
▪ 写通(Write-Through):数据同时写入Cache和内存,一致性高但性能低。
▪ 写回(Write-Back):数据先写入Cache,标记为「脏」,淘汰时写入内存,性能高但存在掉电丢失风险。
淘汰策略:
FIFO 先进先出、LRU 最近最少使用, LFU 最不经常使用。
Cache一致性协议:多核场景下通过MESI协议确保各核心Cache数据一致(Modified, Exclusive, Shared, Invalid状态)。
8 Cache 和 主存之间写缓冲: Write buffer
为了加快 Cache 回写数据到主存的速度,在 Cache 和 主存之间,加入了 Write buffer,其大小通常是几个 Cache 行。这样在将 Cache 数据回写到主存时,CPU 只需要给 Write buffer 提供一些信息(如数据地址,大小等),发起回写请求后,就不需要等待回写操作完成,可以继续执行后续工作;而后 Write buffer 会在某个时间点完成回写操作。
有的 Write buffer 实现,还支持多个回写请求的合并,即 write merging,又叫做 write combining。write merging 将多个回写操作合并成单个操作,这样可以减少和主存间交互,提高性能。但 write merging 并不总是可行的,譬如与外设的数据交互,可能需要即时完成。
有回写的 Write buffer,自然也有为提高效率的预取缓冲,如用来 指令 prefetch buffer 等。
9 Cache 维护操作
9.1 Cache invalidate
Cache invalidate 是指清除一个或多个 Cache 行的 Valid 位,Cache 行的数据将丢失。如果被清除的 Cache 行包含合法数据,通常应该先将数据刷回主存,然后再执行清除操作。当然如果不关心这些数据自然就没所谓了。
在复位后,所有的 Cache 行都处于被 Invalidate 了的状态。
9.2 Cache clean
Cache clean 是指将包含脏(Dirty)数据的Cache行回写到主存,并清除 Cache 行的 Valid 位。
9.3 Cache flush
通常没有对 Cache flush 给出正式定义,通常所说的 Cache flush 是指 Cache invalidate + Cache clean。
9.4 Cache lockdown
Cache 随着代码和数据的运行,会被分配到不同位置的代码和数据,这导致 Cache 对性能的提升呈现抖动(不稳定)。可以通过锁定(lockdown)一些关键代码和数据的 Cache 行,这些被锁定的 Cache 行,后续不再参加重新分配,这使得这些映射到被锁定 Cache 行的代码和数据稳定,呈现出稳定的性能提升。
ARM架构支持 Format A,Format B,Format C,Format D 4种格式的 Cache 锁定机制,更多相关细节,可参考 ARM 官方手册,本文不做更多展开。
9.5 Cache 操作的目标或范围
Cache 操作可按 Cache 组(Set)、Cache 路(Way)、虚拟地址 实施。
10 Cache 性能 和 命中率
要利用 Cache 提高性能,说到底是利用程序执行的时空局限性,尽力的提高 Cache 命中率。一直在说 Cache 命中率,到底什么是 Cache 命中率?Cache 命中率 是指在一定时间内,Cache 命中的次数,通常表示为一个百分比。
对于提高 Cache 命中率(也即提高 Cache 性能),有一些通用性的规则和建议:
. 将近期访问的数据和代码,尽量让它们在地址空间上相邻
. 更小的数据和更小的代码
. 尽量将热点代码和数据组织到相邻位置
. 避免cache行的伪共享:把没有依赖关系的数据,放到不同的 Cache 行,避免写数据时无谓的Cache同步操作
. 保持数据对齐到 cache 行
11 Cache 一致性
即使跳过 Cache 歧义 和 别名 的坑,Cache 带来的也不只是性能的提升,同样也带来了其它麻烦。当多个不同的 CPU 核访问相同的主存位置,会将数据加载到 CPU 核各自的缓存中,如果其中一个 CPU 核更新了缓存(假设写策略使用 write-back),那另一个 CPU 核可能看不到最新的数据版本,这就是 Cache 一致性问题。当然,不仅不同 CPU 核之间对数据的访问存在一致性问题,CPU 和 外设之间的协同数据访问,也存在一致性问题。
11.1 写无效(Write Invalidate)协议
工作原理:
当核心A要修改某个缓存行时:
先让其他核心中该缓存行的副本失效
然后核心A才能修改自己的副本
其他核心后续读取时需要重新从内存或核心A获取最新数据
优点:实现简单,适合读多写少的场景
缺点:频繁写入会导致大量无效化操作
11.2 写更新(Write Update)协议
工作原理
当核心A修改某个缓存行时:
把新值广播给所有缓存了该行的其他核心
所有核心同时更新自己的副本
优点:其他核心总能拿到最新数据
缺点:写入开销大,产生大量总线流量
11.3 MESI协议
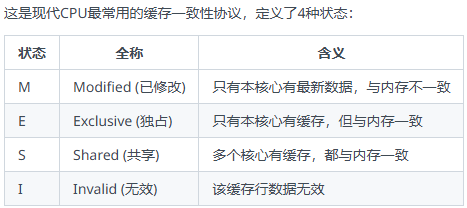
工作流程:
核心A第一次读取数据:从内存加载,状态变为E(独占)
核心B也读取相同数据:两核心状态都变为S(共享)
核心A要修改数据:
先让核心B的副本无效(状态变I)
核心A的状态变为M(已修改)
核心B再次读取:
发现自己的缓存无效
从核心A获取最新数据
两核心状态都变为S(共享)
12. Cache 调试方法
12.1 使用 Cache 调试工具
Linux 的 perf 工具可以用来查看 Cache Miss 的信息,进而用来调试 Cache 相关问题:
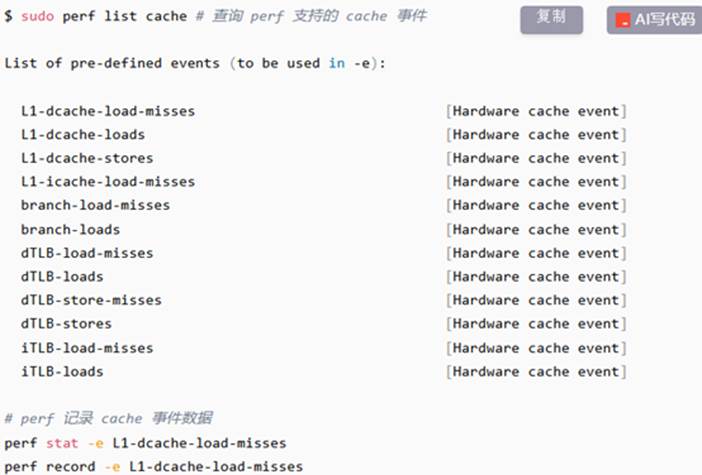
注意,这些 Cache 事件查询都需要硬件底层架构提供支持。
12.2 查询 Cache 信息
$ lscpu
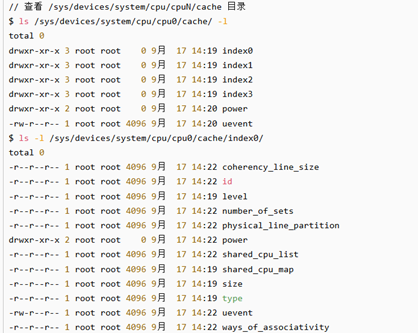
// 查看 /sys/devices/system/cpu/cpuN/cache 目录
还可以通过函数 sysconf(_SC_LEVEL1_DCACHE_LINESIZE) 查询 dCache 行大小,不过这个方法似乎有些场合下不奏效。