摘要
在科普篇中,我们介绍了IP归属地运营商的核心字段(ASN/network_type)及基础接入。但在生产环境中,仅有正确字段远远不够。你是否遇到过:同一IP短期内外网归属突然漂移?IPv6流量大量返回unknown?新版本数据上线后风控策略命中率暴跌?这些问题往往不是数据源质量差,而是链路设计缺少缓存策略、降级回退、监控告警及灰度对账机制 。本文聚焦工程落地细节,提供可复用的方案与代码示例。
一、为什么需要缓存策略?------避免"看天吃饭"
IP归属地运营商查询通常依赖外部API或离线库。每次请求实时穿透,会导致延迟高、成本大、且容易因外部抖动拖垮主链路。
1. 两层缓存结构
- L1(进程内LRU) :热点IP段,例如高频访问的云厂商出口、CDN节点。TTL设为1-6小时。
- L2(Redis/KV) :共享缓存,统一管理TTL与失效推送。TTL按业务分级:风控业务短(15分钟-1小时),归因报表长(1天-1周)。
2. 负缓存(negative cache)------专门解决unknown
当API返回unknown(如新IPv6段未被覆盖),需对该IP/前缀做短TTL负缓存(例如5-15分钟)。否则,同一unknown IP每次请求都穿透查询,既浪费资源又放大延迟。
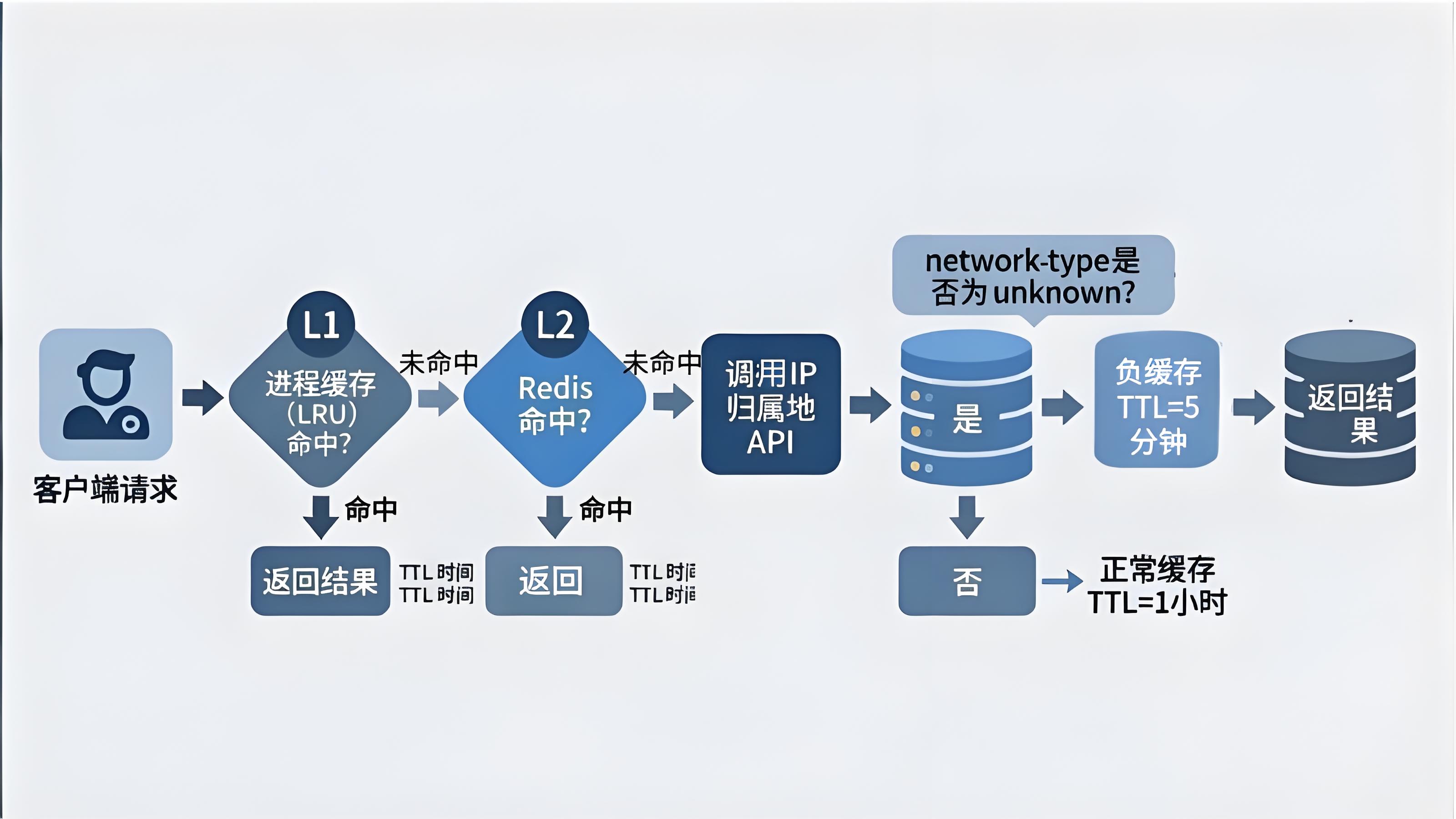
IP归属地运营商两层缓存加负缓存架构图
代码示例(Python + Redis)
python
import redis
import hashlib
import json
r = redis.Redis(host='localhost', port=6379, decode_responses=True)
def call_ip_api(ip, api_key):
# 实际实现见下文熔断器示例
pass
def get_ip_operator_with_cache(ip, api_key):
key = f"ip_op:{hashlib.md5(ip.encode()).hexdigest()}"
cached = r.get(key)
if cached:
return json.loads(cached)
result = call_ip_api(ip, api_key)
if result:
ttl = 3600
if result.get('network_type') == 'unknown':
ttl = 300
r.setex(key, ttl, json.dumps(result))
return result
return None二、降级与熔断:保护主链路
在线风控场景中,IP归属地运营商查询不能成为瓶颈。必须设计快速失败和降级策略。
1. 超时预算
从调用API到返回,总耗时不得超过50-150ms(按自身策略链路预算)。建议使用requests的超时参数拆分为连接超时+读取超时:timeout=(1.0, 2.0)。
2. 降级返回默认值
当超时/异常时,不抛出错误,而是返回安全的默认值:carrier_group=unknown、network_type=unknown,并记录降级标记。策略侧对unknown结果应采取更保守的处置(例如不直接拦截,而是转人工或增加其他因子)。
3. 熔断器(Circuit Breaker)
若连续错误率达到阈值(如50%),自动熔断10秒,期间直接返回降级结果,避免对外部服务反复无效请求。可使用pybreaker库实现。
代码示例(熔断器装饰器)
python
import pybreaker
import requests
breaker = pybreaker.CircuitBreaker(fail_max=5, reset_timeout=10)
@breaker
def call_ip_api(ip, api_key):
url = f"https://api.ipdatacloud.com/v2/query?ip={ip}&key={api_key}"
resp = requests.get(url, timeout=(1, 2))
resp.raise_for_status()
return resp.json()三、监控与漂移告警:不让"悄悄变"变成故障
没有监控的IP归属地运营商字段,就像没有告警的磁盘------满了你才知道。
核心监控指标(建议v4/v6分开)
|----------------------|-------------|------------------|
| 指标 | 含义 | 告警阈值 |
| unknown_rate_v4 / v6 | 未知返回占比 | v4>5% 或 v6>15% |
| Top ASN分布变化 | 前10 ASN占比偏差 | 日环比变化>30% |
| network_type突变 | 机房类型占比剧增 | 日环比变化>50% |
| API P95延迟 | 接口耗时 | >200ms |
| 错误率/熔断次数 | 降级比例 | 错误率>5% |
实施方式 :每次查询打印一行结构化日志(IP脱敏、返回字段、耗时、是否降级),离线聚合后推送到Prometheus/Grafana,或定时脚本计算分布偏移。
四、灰度对账:新版本上线不踩坑
当你切换IP数据源或升级离线库时,直接全量替换风险极高。必须做灰度对账。
步骤
- 影子流量双写 :线上继续使用旧版本,同时异步调用新版本API,比对结果(asn、carrier_group、network_type)差异。
- 分层抽样 :覆盖自然流量、高危IP、IPv6、已知机房段。
- 评估差异率 :若关键字段差异超过5%,则分析原因(如路由变更、数据源落后)。若差异来自新版本改进(如unknown率降低),且符合预期,则逐步放量。
- 保留版本字段 :所有落库结果必须附带data_version,支持按版本回放。
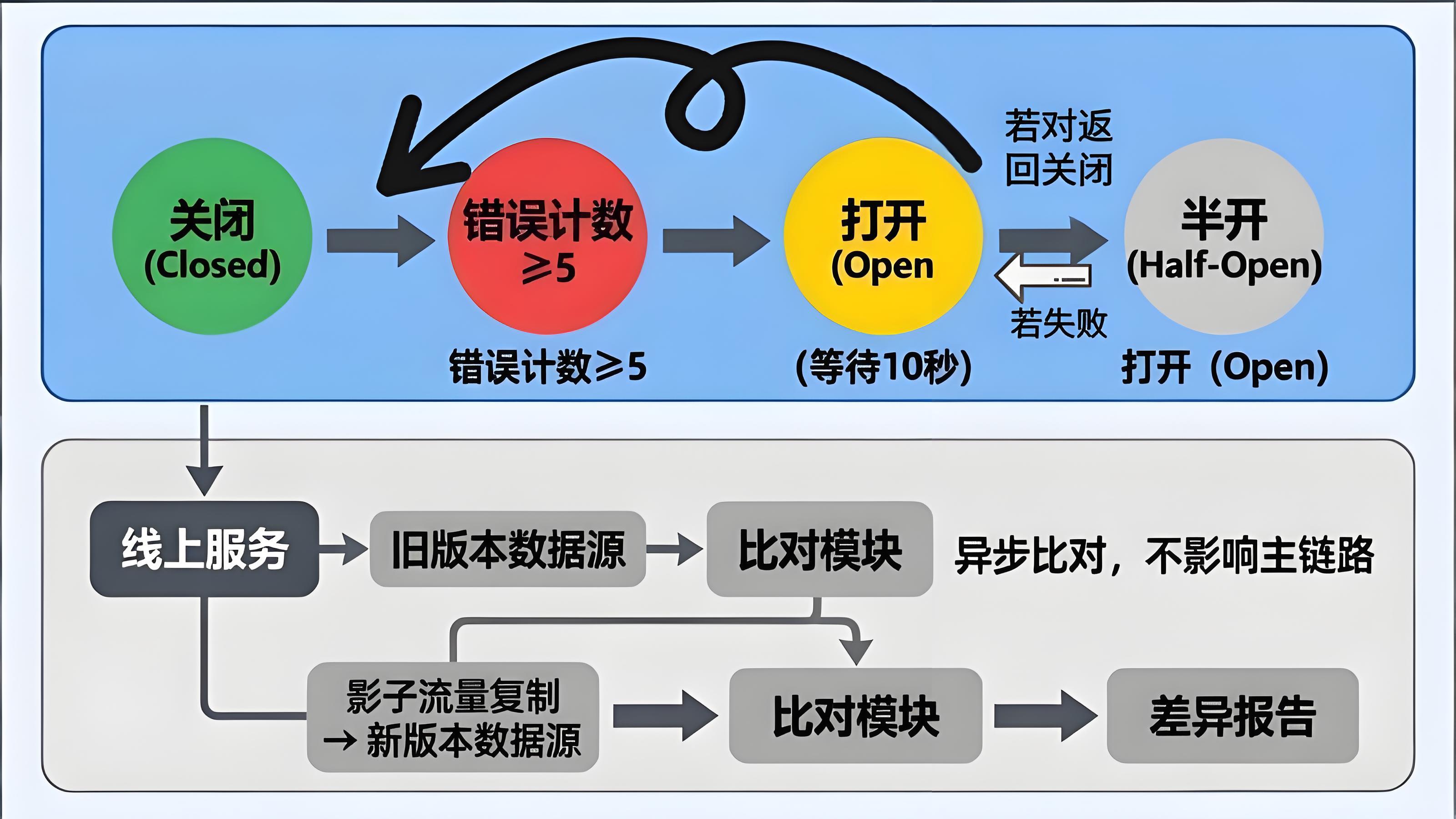
IP归属地运营商熔断器状态机与灰度对账影子流量双写流程
五、审计留存:让"为什么变了"可回答
生产事故中最怕"说不清什么时候变的"。建议至少保留:
- 请求时间(精确到毫秒)
- 脱敏后的IP(例如哈希或截断)
- 返回的asn、network_type、carrier_group
- data_version(数据源版本号)
- 耗时、是否命中缓存、是否降级
有了这些,当业务方质问"昨天还是电信,今天怎么变成了Chinanet"时,你可以直接拉出当时解析结果和版本号,快速定位是数据源更新还是上游BGP变更。
六、总结
将IP归属地运营商能力落地到生产环境,光有正确的字段(ASN+network_type)不够,必须配套:
- 两级缓存+负缓存 :控制延迟与成本
- 降级熔断 :保证主链路韧性
- 监控告警 :捕捉未知率与分布漂移
- 灰度对账 :安全迭代数据源
- 审计留存 :可回溯、可解释
以上每一点都是实践中踩过的坑。以IP数据云等供应商为基础数据源,同时自建上述工程链路,才能真正让IP归属地运营商成为稳定可靠的资产,而非不稳定因子。
数据来源
- 百谏方略(DIResearch) :《全球IP地理位置定位方案市场规模研究报告(2025-2032)》。
- Google Trends公开数据 :近两年"IP geolocation API"相关搜索热度上升约136%。