核心代码
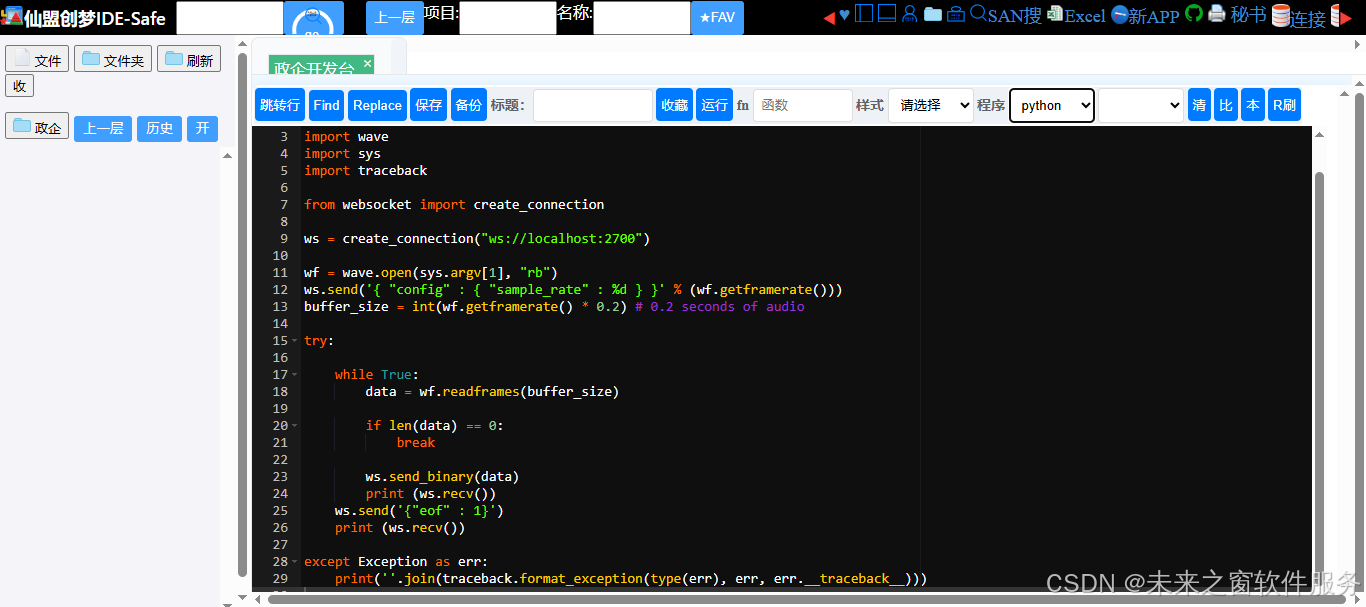
客户端完整代码
#!/usr/bin/env python3
import wave
import sys
import traceback
from websocket import create_connection
ws = create_connection("ws://localhost:2700")
wf = wave.open(sys.argv[1], "rb")
ws.send('{ "config" : { "sample_rate" : %d } }' % (wf.getframerate()))
buffer_size = int(wf.getframerate() * 0.2) # 0.2 seconds of audio
try:
while True:
data = wf.readframes(buffer_size)
if len(data) == 0:
break
ws.send_binary(data)
print (ws.recv())
ws.send('{"eof" : 1}')
print (ws.recv())
except Exception as err:
print(''.join(traceback.format_exception(type(err), err, err.__traceback__)))基于 Vosk 语音识别引擎、通过 WebSocket 协议实现音频文件实时转写的 Python 代码。Vosk 是一款开源离线语音识别工具,代码核心逻辑是把音频文件切成小块,通过 WebSocket 传给本地 Vosk 服务,逐段获取识别结果,最后完成完整转写。下面用初学者能懂的语言(少量东方仙盟比喻)拆解代码的每一部分。
一、代码整体作用
这段代码的核心功能:读取本地 WAV 格式音频文件 → 建立与本地 Vosk WebSocket 服务的连接 → 按固定时长切割音频数据 → 逐段发送音频数据给 Vosk 服务 → 实时接收并打印语音识别结果 → 发送结束信号并获取最终识别结果。可以类比成:你(代码)是 "东方仙盟" 的传讯弟子,要把一卷长音频 "天书" 拆成小份,通过 "WebSocket 仙桥" 传给盟里的 "Vosk 语音仙师",仙师看完一小份就告诉你内容,直到整卷天书解读完毕。
二、逐行代码解释
python
运行
#!/usr/bin/env python3- 作用:指定代码用 Python3 解释器运行,是 Linux/macOS 系统的 "约定",Windows 下可忽略。
- 比喻:相当于给 "传讯弟子" 指定了专属的 "修行法门(Python3)",确保执行规则统一。
python
运行
import wave
import sys
import traceback
from websocket import create_connection- 导入核心库:
wave:Python 内置库,专门读取 WAV 格式音频文件(处理音频的 "天书解码器");sys:获取命令行参数(接收外界传入的 "天书路径");traceback:捕获并打印详细的错误信息(记录 "传讯过程中的差错");websocket.create_connection:创建 WebSocket 连接(搭建和 "Vosk 仙师" 沟通的 "仙桥")。
python
运行
ws = create_connection("ws://localhost:2700")- 核心操作:连接本地 2700 端口的 Vosk WebSocket 服务。
- 前提:你需要先启动 Vosk 的 WebSocket 服务(比如通过
vosk-server-websocket命令),否则会报错 "连接失败"。 - 比喻:弟子通过 "仙桥"(WebSocket)连接到仙师的洞府(localhost:2700),准备传讯。
python
运行
wf = wave.open(sys.argv[1], "rb")- 作用:读取命令行传入的第一个参数(即 WAV 音频文件路径),以二进制只读模式打开。
- 示例:运行代码时需输入
python3 代码名.py 音频文件.wav,sys.argv[1]就是 "音频文件.wav"。 - 比喻:弟子拿到外界送来的 "天书"(音频文件),用 "解码器"(wave.open)打开准备拆解。
python
运行
ws.send('{ "config" : { "sample_rate" : %d } }' % (wf.getframerate()))- 作用:向 Vosk 服务发送配置信息,核心是告知音频的采样率(
wf.getframerate()获取 WAV 文件的采样率,比如 16000Hz)。 - 比喻:弟子先告诉仙师 "天书的文字编码规则(采样率)",确保仙师能看懂后续的内容。
python
运行
buffer_size = int(wf.getframerate() * 0.2) # 0.2 seconds of audio- 作用:计算每次发送的音频数据长度,即 "0.2 秒的音频帧数量"(采样率 × 时长)。比如采样率 16000 时,buffer_size=3200,每次读 3200 帧(0.2 秒)。
- 比喻:弟子把 "天书" 按 "每 0.2 页" 切成小份,避免一次传太多导致仙桥拥堵。
python
运行
try:
while True:
data = wf.readframes(buffer_size)
if len(data) == 0:
break
ws.send_binary(data)
print (ws.recv())
ws.send('{"eof" : 1}')
print (ws.recv())- 核心逻辑(逐行拆解):
while True:循环读取音频数据,直到读完;data = wf.readframes(buffer_size):读取 buffer_size 帧的音频数据(0.2 秒);if len(data) == 0: break:如果没有数据了(音频读完),退出循环;ws.send_binary(data):以二进制形式发送音频数据给 Vosk 服务;print (ws.recv()):接收 Vosk 返回的实时识别结果并打印;ws.send('{"eof" : 1}'):发送 "EOF(文件结束)" 信号,告知 Vosk 音频已传完;print (ws.recv()):接收最终的完整识别结果。
- 比喻:弟子循环切分 "天书",每次送一小份给仙师,仙师看完立刻告诉弟子解读结果;等天书全送完,弟子说 "解读完毕",仙师给出最终的完整解读。
python
运行
except Exception as err:
print(''.join(traceback.format_exception(type(err), err, err.__traceback__)))- 作用:捕获代码运行中的所有异常(比如连接断开、音频文件不存在、采样率不匹配等),并打印详细的错误堆栈,方便排查问题。
- 比喻:如果传讯过程中仙桥断了、天书损坏,弟子会记录详细的 "差错日志",方便后续排查。
三、初学者使用前的准备
-
环境安装:
-
安装依赖库:
pip install wave websocket-client vosk(注意:wave 是 Python 内置库,无需额外装;websocket-client 是 WebSocket 连接的核心库); -
下载 Vosk 模型:从 Vosk 官网(https://alphacephei.com/vosk/models)下载对应语言的模型(比如中文模型
vosk-model-small-cn-0.22); -
启动 Vosk WebSocket 服务: bash
运行
vosk-server-websocket -m 模型路径 -p 2700(-m 指定模型路径,-p 指定端口 2700,和代码中的
ws://localhost:2700对应)。
-
-
音频文件要求:
- 必须是 WAV 格式;
- 采样率需和 Vosk 模型匹配(比如中文小模型是 16000Hz);
- 单声道、16 位深度(Vosk 的默认要求)。
四、运行示例
假设你有一个 16000Hz 采样率的中文 WAV 音频文件test.wav,步骤:
- 启动 Vosk WebSocket 服务:
vosk-server-websocket -m vosk-model-small-cn-0.22 -p 2700; - 运行代码:
python3 asr_code.py test.wav; - 输出:逐段打印实时识别结果,最后打印完整结果(JSON 格式,包含识别的文字)。
总结
- 核心逻辑:通过 WebSocket 将 WAV 音频按固定时长分片发送给本地 Vosk 服务,实时获取语音识别结果,最后发送结束信号获取完整结果;
- 关键前提:需先启动 Vosk WebSocket 服务、确保音频格式(WAV、采样率匹配、单声道)符合要求;
- 核心库作用:
wave读音频、websocket建立连接、sys获取命令行参数,异常捕获确保代码鲁棒性。
(东方仙盟比喻总结:代码像 "传讯弟子",WebSocket 是 "仙桥",Vosk 是 "语音仙师",音频文件是 "天书",拆解发送是为了 "高效解读",最终得到 "天书的文字内容(识别结果)"。)
东方仙盟:拥抱知识开源,共筑数字新生态
在全球化与数字化浪潮中,东方仙盟始终秉持开放协作、知识共享的理念,积极拥抱开源技术与开放标准。我们相信,唯有打破技术壁垒、汇聚全球智慧,才能真正推动行业的可持续发展。
开源赋能中小商户:通过将前端异常检测、跨系统数据互联等核心能力开源化,东方仙盟为全球中小商户提供了低成本、高可靠的技术解决方案,让更多商家能够平等享受数字转型的红利。
共建行业标准:我们积极参与国际技术社区,与全球开发者、合作伙伴共同制定开放协议 与技术规范,推动跨境零售、文旅、餐饮等多业态的系统互联互通,构建更加公平、高效的数字生态。
知识普惠,共促发展:通过开源社区 、技术文档与培训体系,东方仙盟致力于将前沿技术转化为可落地的行业实践,赋能全球合作伙伴,共同培育创新人才,推动数字经济 的普惠式增长
阿雪技术观
在科技发展浪潮中,我们不妨积极投身技术共享。不满足于做受益者,更要主动担当贡献者。无论是分享代码、撰写技术博客,还是参与开源项目 维护改进,每一个微小举动都可能蕴含推动技术进步的巨大能量。东方仙盟是汇聚力量的天地,我们携手在此探索硅基 生命,为科技进步添砖加瓦。
Hey folks, in this wild tech - driven world, why not dive headfirst into the whole tech - sharing scene? Don't just be the one reaping all the benefits; step up and be a contributor too. Whether you're tossing out your code snippets , hammering out some tech blogs, or getting your hands dirty with maintaining and sprucing up open - source projects, every little thing you do might just end up being a massive force that pushes tech forward. And guess what? The Eastern FairyAlliance is this awesome place where we all come together. We're gonna team up and explore the whole silicon - based life thing, and in the process, we'll be fueling the growth of technology