1.给字段加上雪花算法

雪花算法:时间戳+机器码+序列号。
2.万能条件模版:
App为实体类,想用替换App和字段即可。
java
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.core.toolkit.StringUtils;
import org.springframework.stereotype.Component;
/**
* 构建App查询条件的工具方法(也可直接写在ServiceImpl中)
*/
@Component
public class AppQueryWrapperBuilder {
/**
* 构建App查询条件的QueryWrapper(带全量空值判断)
* @param appQueryRequest 查询参数DTO
* @return 组装好条件的QueryWrapper
*/
public QueryWrapper<App> getQueryWrapper(AppQueryRequest appQueryRequest) {
// 1. 参数非空校验
if (appQueryRequest == null) {
throw new BusinessException(ErrorCode.PARAMS_ERROR, "请求参数为空");
}
// 2. 提取查询参数
Long id = appQueryRequest.getId();
String appName = appQueryRequest.getAppName();
String cover = appQueryRequest.getCover();
String initPrompt = appQueryRequest.getInitPrompt();
String codeGenType = appQueryRequest.getCodeGenType();
String deployKey = appQueryRequest.getDeployKey();
Integer priority = appQueryRequest.getPriority();
Long userId = appQueryRequest.getUserId();
String sortField = appQueryRequest.getSortField();
String sortOrder = appQueryRequest.getSortOrder();
// 3. 构建QueryWrapper(每个条件加空值判断)
QueryWrapper<App> wrapper = QueryWrapper.create();
// 精准匹配:id/优先级/用户ID(数字类型仅判断null)
wrapper.eq(id != null, "id", id)
.eq(priority != null, "priority", priority)
.eq(userId != null, "user_id", userId)
// 精准匹配:字符串类型(非空且非空串才拼接)
.eq(StringUtils.hasText(codeGenType), "code_gen_type", codeGenType)
.eq(StringUtils.hasText(deployKey), "deploy_key", deployKey)
// 模糊匹配:字符串类型(非空且非空串才拼接)
.like(StringUtils.hasText(appName), "app_name", appName)
.like(StringUtils.hasText(cover), "cover", cover)
.like(StringUtils.hasText(initPrompt), "init_prompt", initPrompt);
// 4. 完善排序逻辑(支持升序/降序,默认升序)
if (StringUtils.hasText(sortField)) {
boolean isAsc = "asc".equalsIgnoreCase(sortOrder);
wrapper.orderBy(true, isAsc, sortField);
}
return wrapper;
}
}来看业务中的调用:
java
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
/**
* App服务实现类
*/
@Service
public class AppServiceImpl extends ServiceImpl<AppMapper, App> implements AppService {
// 注入QueryWrapper构建工具类(如果工具方法写在本类,可省略注入)
@Autowired
private AppQueryWrapperBuilder queryWrapperBuilder;
/**
* 按条件分页/列表查询App(简洁调用封装好的Wrapper构建方法)
* @param appQueryRequest 查询参数
* @return 符合条件的App列表
*/
@Override
public List<App> listAppByCondition(AppQueryRequest appQueryRequest) {
// 1. 调用工具方法获取组装好的QueryWrapper
QueryWrapper<App> wrapper = queryWrapperBuilder.getQueryWrapper(appQueryRequest);
// 2. 直接调用MyBatis-Plus内置方法查询(一行搞定)
return this.list(wrapper);
}
/**
* (可选)分页查询(更贴合企业实际场景)
* @param page 分页参数(current-页码,size-每页条数)
* @param appQueryRequest 查询参数
* @return 分页结果
*/
@Override
public Page<App> pageAppByCondition(Page<App> page, AppQueryRequest appQueryRequest) {
QueryWrapper<App> wrapper = queryWrapperBuilder.getQueryWrapper(appQueryRequest);
return this.page(page, wrapper);
}
}万能条件模版。
3.@Target 和 @Retention注解:
@Target 和 @Retention 是 Java 自带的元注解 (Meta Annotation),它们的作用不是给业务代码用,而是专门用来修饰「你自己写的注解」 ,帮你定义这个注解的使用范围 和存活时间。
@Target(ElementType.METHOD):管「注解能贴在哪」
核心作用
限定你自定义的 @AuthCheck 注解,只能标注在哪些 Java 元素上,如果贴到不允许的位置,编译器会直接报错。
语法解析:
@Target(ElementType.METHOD)
ElementType是一个枚举,代表 Java 中不同的元素类型- 你这里写的
METHOD→ 表示@AuthCheck只能贴在「方法」上
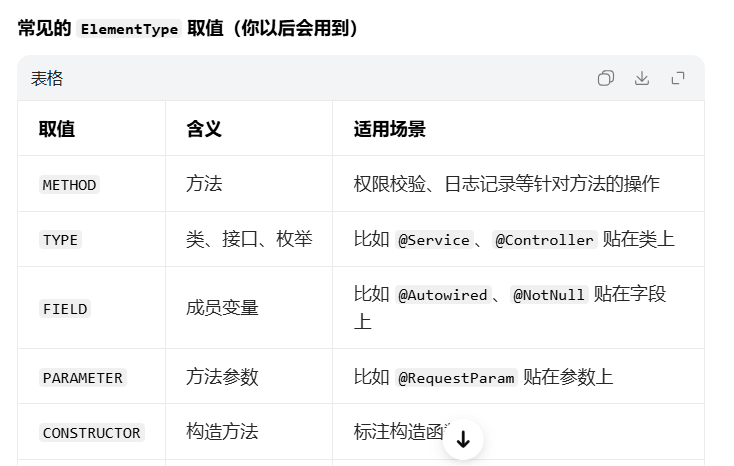
@Retention(RetentionPolicy.RUNTIME):管「注解能活多久」
核心作用
规定 @AuthCheck 注解的生命周期,也就是它会保留到代码运行的哪个阶段,这直接决定了你的 AOP 能不能读到它。
语法解析
@Retention(RetentionPolicy.RUNTIME)
-
RetentionPolicy是枚举,代表注解的 3 种存活阶段 -
你这里写的
RUNTIME→ 表示注解会一直存活到程序运行时,JVM 可以通过反射读取它
三种 RetentionPolicy 对比(关键!)

4.ServerSentEvent和redis令牌桶限流
@RateLimit(limitType = RateLimitType.USER, rate = 5, rateInterval = 60, message = "AI 对话请求过于频繁,请稍后再试")
public Flux<ServerSentEvent<String>> chatToGenCode(@RequestParam Long appId,
@RequestParam String message,
HttpServletRequest request) 这个ServerSentEvent的作用就是缺一不可的意思就是没有它无法完成流式输出。对这种输出的内容多的必须得用这样的方法也就是reactor就是示例代码这种输出,传统的SseEmitter支撑不起来这么多的输出内容容易崩。
下面看redis令牌桶限流:
java
package com.yupi.yuaicodemother.ratelimter.aspect;
import com.yupi.yuaicodemother.exception.BusinessException;
import com.yupi.yuaicodemother.exception.ErrorCode;
import com.yupi.yuaicodemother.model.entity.User;
import com.yupi.yuaicodemother.ratelimter.annotation.RateLimit;
import com.yupi.yuaicodemother.service.UserService;
import jakarta.annotation.Resource;
import jakarta.servlet.http.HttpServletRequest;
import lombok.extern.slf4j.Slf4j;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.reflect.MethodSignature;
import org.redisson.api.RRateLimiter;
import org.redisson.api.RateIntervalUnit;
import org.redisson.api.RateType;
import org.redisson.api.RedissonClient;
import org.springframework.stereotype.Component;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.context.request.ServletRequestAttributes;
import java.lang.reflect.Method;
import java.time.Duration;
/**
* 限流切面核心逻辑
*/
@Aspect
@Component
@Slf4j
public class RateLimitAspect {
@Resource
private RedissonClient redissonClient;
@Resource
private UserService userService;
@Before("@annotation(rateLimit)")
public void doBefore(JoinPoint point, RateLimit rateLimit) {
String key = generateRateLimitKey(point, rateLimit);
// 使用 Redisson 的分布式限流器
RRateLimiter rateLimiter = redissonClient.getRateLimiter(key);
rateLimiter.expire(Duration.ofHours(1)); // 1 小时后过期
// 设置限流器参数:每个时间窗口允许的请求数和时间窗口
rateLimiter.trySetRate(RateType.OVERALL, rateLimit.rate(), rateLimit.rateInterval(), RateIntervalUnit.SECONDS);
// 尝试获取一个令牌,如果获取失败则限流
if (!rateLimiter.tryAcquire(1)) {
throw new BusinessException(ErrorCode.TOO_MANY_REQUEST, rateLimit.message());
}
}
/**
* 生成限流key
*
* @param point
* @param rateLimit
* @return
*/
private String generateRateLimitKey(JoinPoint point, RateLimit rateLimit) {
StringBuilder keyBuilder = new StringBuilder();
keyBuilder.append("rate_limit:");
// 添加自定义前缀
if (!rateLimit.key().isEmpty()) {
keyBuilder.append(rateLimit.key()).append(":");
}
// 根据限流类型生成不同的key
switch (rateLimit.limitType()) {
case API:
// 接口级别:方法名
MethodSignature signature = (MethodSignature) point.getSignature();
Method method = signature.getMethod();
keyBuilder.append("api:").append(method.getDeclaringClass().getSimpleName())
.append(".").append(method.getName());
break;
case USER:
// 用户级别:用户ID
try {
ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
if (attributes != null) {
HttpServletRequest request = attributes.getRequest();
User loginUser = userService.getLoginUser(request);
keyBuilder.append("user:").append(loginUser.getId());
} else {
// 无法获取请求上下文,使用IP限流
keyBuilder.append("ip:").append(getClientIP());
}
} catch (BusinessException e) {
// 未登录用户使用IP限流
keyBuilder.append("ip:").append(getClientIP());
}
break;
case IP:
// IP级别:客户端IP
keyBuilder.append("ip:").append(getClientIP());
break;
default:
throw new BusinessException(ErrorCode.SYSTEM_ERROR, "不支持的限流类型");
}
return keyBuilder.toString();
}
/**
* 获取客户端IP
*
* @return
*/
private String getClientIP() {
ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
if (attributes == null) {
return "unknown";
}
HttpServletRequest request = attributes.getRequest();
String ip = request.getHeader("X-Forwarded-For");
if (ip == null || ip.isEmpty() || "unknown".equalsIgnoreCase(ip)) {
ip = request.getHeader("X-Real-IP");
}
if (ip == null || ip.isEmpty() || "unknown".equalsIgnoreCase(ip)) {
ip = request.getRemoteAddr();
}
// 处理多级代理的情况
if (ip != null && ip.contains(",")) {
ip = ip.split(",")[0].trim();
}
return ip != null ? ip : "unknown";
}
}String key = generateRateLimitKey(point, rateLimit);这个是生成key。下面直接看 generateRateLimitKey(point, rateLimit);这个方法。里面就是根据不同的类型生成不同的key,具体注释里面写的已经很清楚了。下面看最最重要的。
// 使用 Redisson 的分布式限流器
RRateLimiter rateLimiter = redissonClient.getRateLimiter(key);
先获取限流器也就是获取令牌桶
设置令牌桶过期时间一个小时后令牌桶过期,用户一个小时后再次访问会再次进行创建。
rateLimiter.expire(Duration.ofHours(1)); // 1 小时后过期
// 设置限流器参数:每个时间窗口允许的请求数和时间窗口
rateLimiter.trySetRate(RateType.OVERALL, rateLimit.rate(), rateLimit.rateInterval(), RateIntervalUnit.SECONDS);rate表示生成令牌桶数量,rateInterval代表时间的数量,后面那个是单位。
假如说此时rate=5,rateInterval=60,就是60秒生成五个令牌
if (!rateLimiter.tryAcquire(1)) {
throw new BusinessException(ErrorCode.TOO_MANY_REQUEST, rateLimit.message());
}
这个就是从令牌桶拿令牌拿不到就抛出异常。
5.洗牌即打乱顺序
java
List<OptionVO> shuffledOptions = new ArrayList<>(questionVO.getOptions());
Collections.shuffle(shuffledOptions);
questionVO.setOptions(shuffledOptions);.shuffle就是洗牌可以打乱集合的顺序。
6.管理员校验 @AuthCheck
java
@PostMapping("/admin/delete")
@AuthCheck(mustRole = UserConstant.ADMIN_ROLE)
public BaseResponse<Boolean> deleteAppByAdmin(@RequestBody DeleteRequest deleteRequest) {
if (deleteRequest == null || deleteRequest.getId() <= 0) {
throw new BusinessException(ErrorCode.PARAMS_ERROR);
}
long id = deleteRequest.getId();
// 判断是否存在
App oldApp = appService.getById(id);
ThrowUtils.throwIf(oldApp == null, ErrorCode.NOT_FOUND_ERROR);
boolean result = appService.removeById(id);
return ResultUtils.success(result);
}也是一个切面类一开始就设置好user的身份。
然后这个aop张这个样子:
java
package com.yupi.yuaicodemother.aop;
import com.yupi.yuaicodemother.annotation.AuthCheck;
import com.yupi.yuaicodemother.exception.BusinessException;
import com.yupi.yuaicodemother.exception.ErrorCode;
import com.yupi.yuaicodemother.model.entity.User;
import com.yupi.yuaicodemother.model.enums.UserRoleEnum;
import com.yupi.yuaicodemother.service.UserService;
import jakarta.annotation.Resource;
import jakarta.servlet.http.HttpServletRequest;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.springframework.stereotype.Component;
import org.springframework.web.context.request.RequestAttributes;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.context.request.ServletRequestAttributes;
@Aspect
@Component
public class AuthInterceptor {
@Resource
private UserService userService;
/**
* 执行拦截
*
* @param joinPoint 切入点
* @param authCheck 权限校验注解
* @return
* @throws Throwable
*/
@Around("@annotation(authCheck)")
public Object doInterceptor(ProceedingJoinPoint joinPoint, AuthCheck authCheck) throws Throwable {
String mustRole = authCheck.mustRole();
RequestAttributes requestAttributes = RequestContextHolder.currentRequestAttributes();
HttpServletRequest request = ((ServletRequestAttributes) requestAttributes).getRequest();
// 获取当前登录用户
User loginUser = userService.getLoginUser(request);
UserRoleEnum mustRoleEnum = UserRoleEnum.getEnumByValue(mustRole);
// 不需要权限,直接放行
if (mustRoleEnum == null) {
return joinPoint.proceed();
}
// 以下的代码:必须有这个权限才能通过
UserRoleEnum userRoleEnum = UserRoleEnum.getEnumByValue(loginUser.getUserRole());
// 没有权限,直接拒绝
if (userRoleEnum == null) {
throw new BusinessException(ErrorCode.NO_AUTH_ERROR);
}
// 要求必须有管理员权限,但当前登录用户没有
if (UserRoleEnum.ADMIN.equals(mustRoleEnum) && !UserRoleEnum.ADMIN.equals(userRoleEnum)) {
throw new BusinessException(ErrorCode.NO_AUTH_ERROR);
}
// 通过普通用户的权限校验,放行
return joinPoint.proceed();
}
}即查询数据库看用户类型是不是admin必须是admin才可以进行操作,如果不是的话直接返回无该权限。
7.应用部署:
先搞懂:serve 是什么?
它是 Node.js 生态里的一个轻量命令行工具,作用就是:
把你电脑上的某个文件夹 ,瞬间变成一个可通过浏览器访问的静态网站服务器。里面的 HTML/CSS/JS/ 图片等文件,都能通过
http://xxx地址直接打开。
完整操作步骤:
先安装 Node.js(前提)
serve 是 Node.js 的包,所以必须先装 Node.js:
- 去 Node.js 官网 下载对应你系统(Windows/Mac/Linux)的安装包,一路下一步安装即可。
- 安装完打开终端 / 命令提示符,输入下面命令验证:
java
node -v # 看 Node 版本
npm -v # 看 npm 版本(Node 自带的包管理器)全局安装 serve 工具
在终端里直接运行图里的命令:
*
java
npm i -g servenpm i:是npm install的简写,意思是「安装包」-g:代表 全局安装 ,这样你在电脑任何文件夹里都能调用serve命令- 安装完成后,输入
serve -v能输出版本号,就说明装好了。
进入你要部署的文件夹
比如你要把 code_output 这个文件夹变成网站:
- Windows:在
code_output文件夹里右键 →「在此处打开终端」 - Mac/Linux:用
cd命令进入,比如:
java
cd /Users/你的名字/Desktop/code_output启动 Web 服务
在目标目录里直接输入:
*
java
serve回车后,终端会输出类似这样的信息:
*
java
Serving!
- Local: http://localhost:3000
- Network: http://192.168.1.100:3000访问你的静态网站
- 本地访问:打开浏览器,输入
http://localhost:3000,就能看到code_output里的文件了(如果有index.html会自动打开)。 - 局域网访问:同一 WiFi 下的手机 / 其他电脑,输入
Network那行的地址(比如http://192.168.1.100:3000),也能访问。
8.Canel监听mysql的行为
Canal = 监听 MySQL binlog 的实时同步工具你只要:
- MySQL 开 binlog
- 配 Canal
- Java 连上去就能实时拿到所有增删改,做同步、做日志、做通知。
Canal 到底干嘛?
-
伪装成 MySQL 的 从库(slave)
-
监听 MySQL 的 binlog 日志
-
拿到 insert / update / delete 实时数据
-
常用于:缓存同步(MySQL 变→Redis 更)、数据同步、审计日志
下面来看步骤:
第一步:MySQL 开启 binlog(必须做)
- 修改 MySQL 配置
my.cnf/my.ini
java
[mysqld]
# 开启binlog
log-bin=mysql-bin
# 选择行模式(Canal 必须用 ROW)
binlog-format=ROW
# 唯一id
server-id=1重启 MySQL
给 Canal 创建账号并授权
java
CREATE USER 'canal'@'%' IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;第二步:安装并配置 Canal
-
下载 Canal(解压即用)
-
修改配置:
conf/example/instance.properties
java
# mysql 地址
canal.instance.master.address=127.0.0.1:3306
# 账号密码
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
# 要监听的库(正则)
canal.instance.defaultDatabaseName=test_db
# 监听哪张表(可不配,默认全库)
# canal.instance.filter.regex=test_db\.order- 启动 Canal
Linux:
java
sh bin/startup.shwindows:
java
bin\startup.bat第三步:Java 客户端代码(直接复制用)
- 引入依赖
java
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.5</version>
</dependency>- 监听代码(核心!)
java
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry.*;
import com.alibaba.otter.canal.protocol.Message;
import java.net.InetSocketAddress;
import java.util.List;
public class CanalClient {
public static void main(String[] args) {
// 1. 创建连接(Canal 地址+端口+实例名)
CanalConnector connector = CanalConnectors.newSingleConnector(
new InetSocketAddress("127.0.0.1", 11111),
"example", "", ""
);
// 每次获取100条消息
int batchSize = 100;
try {
connector.connect();
// 订阅所有表(可写库.表)
connector.subscribe(".*\\..*");
connector.rollback();
while (true) {
// 2. 获取消息
Message message = connector.getWithoutAck(batchSize);
long batchId = message.getId();
List<Entry> entries = message.getEntries();
if (batchId == -1 || entries.isEmpty()) {
Thread.sleep(1000);
continue;
}
// 3. 处理数据
for (Entry entry : entries) {
// 只处理行数据(binlog的ROW模式,Canal必须用这个)
if (entry.getEntryType() == EntryType.ROWDATA) {
// 把二进制的storeValue解析成RowChange(能看懂的操作)
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
// 解析出:哪个库、哪个表、什么操作(insert/update/delete)
String database = entry.getHeader().getSchemaName(); // 库名,比如test_db
String table = entry.getHeader().getTableName(); // 表名,比如order
EventType eventType = rowChange.getEventType(); // 操作类型,比如INSERT
// 解析具体的字段数据(新增/修改/删除的字段值)
for (RowData rowData : rowChange.getRowDatasList()) {
if (eventType == EventType.INSERT) {
// 新增:只拿新增后的数据
List<Column> columns = rowData.getAfterColumnsList();
for (Column col : columns) {
System.out.println(col.getName() + " = " + col.getValue()); // 比如id=1001, name=订单1
}
} else if (eventType == EventType.UPDATE) {
// 修改:拿修改前+修改后的数据
List<Column> before = rowData.getBeforeColumnsList(); // 修改前
List<Column> after = rowData.getAfterColumnsList(); // 修改后
} else if (eventType == EventType.DELETE) {
// 删除:只拿删除前的数据
List<Column> before = rowData.getBeforeColumnsList();
}
}
}
}
// 确认消息
connector.ack(batchId);
}
} catch (Exception e) {
e.printStackTrace(); // 出异常打印日志,不直接崩
} finally {
connector.disconnect(); // 程序停掉/出异常时,断开连接
}
}9.部署接口以及展示接口(用户点击一键部署加url后端做的事)
这一部分不讲llm生成代码并写入文件的流程下一步在讲。这里就默认ai回答完问题后代码文件已经生成。
首先流程是这样的:
第一阶段:用户点击「一键部署」(后端只做 "开入口、给钥匙",不碰代码)
第 1 步:用户点击部署按钮,前端发起请求
用户在前端页面,点击生成好的应用的「一键部署」按钮。前端调用后端部署接口:POST /app/{appId}/deploy,把当前应用的appId传给后端。
第 2 步:后端部署接口做基础校验
后端接口接住请求,依次做这几件事:
- 查数据库,确认这个
appId对应的应用是否存在; - 校验权限,确认当前登录用户是这个应用的创建者;
- 校验
codeGenType,确认这是一个生成了代码的应用(普通问题直接抛异常); - 拼接代码文件路径,校验服务器磁盘里的代码文件是否真实存在(文件是 AI 对话时早就写好的)。
第 3 步:处理deployKey(核心!保证访问地址稳定)
从数据库里查这个应用的deployKey字段:
-
如果是空的(第一次部署):生成一个 6 位的随机字符串(字母 + 数字);
-
如果已经有值了(之前部署过):直接复用旧的,不生成新的。
第 4 步:拼接访问 URL,更新数据库
后端用「项目基础域名 + /deploy/ + deployKey + /」的规则,拼接出最终的访问 URL,比如:https://你的域名.com/deploy/abc123/
然后把这些信息更新到数据库的app表:
deployKey:刚才生成 / 复用的 6 位字符串deployStatus:更新为 "已部署"deployedTime:更新为当前时间deployUrl:刚才拼接好的完整 URL
第 5 步:部署接口返回 URL,前端展示
部署接口把生成好的deployUrl返回给前端,前端在页面上显示「部署成功,点击访问」的按钮,按钮的链接就是这个 URL。👉 到这里,部署接口的工作就 100% 结束了,它全程没有碰代码文件,没有启动任何新服务,只是给代码开了一个访问入口。
第二阶段:用户点击 URL,看到网页(核心是你的静态资源接口)
第 6 步:用户点击 URL,浏览器发起请求
用户点击前端展示的https://你的域名.com/deploy/abc123/链接。浏览器在新标签页,给你的 Spring Boot 服务器发起一个标准的 HTTP GET 请求,请求路径就是/deploy/abc123/。
第 7 步:后端静态资源接口处理请求,返回文件内容
这个请求正好匹配到你写的那个接口:
java
运行
@GetMapping("/deploy/{deployKey}/**")
public ResponseEntity<Resource> serveStaticResource(...)接口执行以下逻辑:
-
从 URL 里拿到
deployKey=abc123; -
去数据库查:哪个应用的
deployKey是abc123?查到对应的userId和appId; -
用
userId+appId,拼接出和 AI 写文件时100% 一致的磁盘路径; -
解析出用户要访问的具体文件(如果是根路径,默认是
index.html); -
校验文件是否真实存在,不存在直接返回 404;
-
读取文件的完整内容,封装成 Spring 的
Resource对象,设置好正确的Content-Type(比如 HTML 是text/html,CSS 是text/css); -
把文件内容原封不动地返回给浏览器。
第 8 步:浏览器拿到文件,渲染出完整网页
浏览器收到接口返回的index.html内容,开始解析渲染:
-
先解析 HTML 结构;
-
发现 HTML 里引用了
style.css、script.js、图片等资源,自动发起新的 HTTP 请求 ,请求路径还是/deploy/abc123/style.css这种,还是走上面那个静态资源接口; -
接口再次执行逻辑,返回对应的 CSS、JS 文件内容;
-
浏览器拿到所有资源后,完整渲染出你生成的网页
这就是大概所有流程下面咱们直接来看代码分析:
先把表结构给放一下这个deploy表

先看第一个接口:
java
@PostMapping("/deploy")
public BaseResponse<String> deployApp(@RequestBody AppDeployRequest appDeployRequest, HttpServletRequest request) {
// 检查部署请求是否为空
ThrowUtils.throwIf(appDeployRequest == null, ErrorCode.PARAMS_ERROR);
// 获取应用 ID
Long appId = appDeployRequest.getAppId();
// 检查应用 ID 是否为空
ThrowUtils.throwIf(appId == null || appId <= 0, ErrorCode.PARAMS_ERROR, "应用 ID 不能为空");
// 获取当前登录用户
User loginUser = userService.getLoginUser(request);
// 调用服务部署应用
String deployUrl = appService.deployApp(appId, loginUser);
// 返回部署 URL
return ResultUtils.success(deployUrl);
}下面从每一行开始分析:
// 检查部署请求是否为空
ThrowUtils.throwIf(appDeployRequest == null, ErrorCode.PARAMS_ERROR);
java
public static void throwIf(boolean condition, ErrorCode errorCode) {
throwIf(condition, new BusinessException(errorCode));
}
public static void throwIf(boolean condition, RuntimeException runtimeException) {
if (condition) {
throw runtimeException;
}
}统一了一下一行代码就可以防止代码冗余。
接着向下看:
String deployUrl = appService.deployApp(appId, loginUser);获取用户信息并且执行deployApp方法。
deployApp方法:
java
@Override
public String deployApp(Long appId, User loginUser) {
// 1. 参数校验
ThrowUtils.throwIf(appId == null || appId <= 0, ErrorCode.PARAMS_ERROR, "应用 ID 错误");
ThrowUtils.throwIf(loginUser == null, ErrorCode.NOT_LOGIN_ERROR, "用户未登录");
// 2. 查询应用信息
App app = this.getById(appId);
ThrowUtils.throwIf(app == null, ErrorCode.NOT_FOUND_ERROR, "应用不存在");
// 3. 权限校验,仅本人可以部署自己的应用
if (!app.getUserId().equals(loginUser.getId())) {
throw new BusinessException(ErrorCode.NO_AUTH_ERROR, "无权限部署该应用");
}
// 4. 检查是否已有 deployKey
String deployKey = app.getDeployKey();
// 如果没有,则生成 6 位 deployKey(字母 + 数字)
if (StrUtil.isBlank(deployKey)) {
deployKey = RandomUtil.randomString(6);
}
// 5. 获取代码生成类型,获取原始代码生成路径(应用访问目录)
String codeGenType = app.getCodeGenType();
String sourceDirName = codeGenType + "_" + appId;
String sourceDirPath = AppConstant.CODE_OUTPUT_ROOT_DIR + File.separator + sourceDirName;
// 6. 检查路径是否存在
File sourceDir = new File(sourceDirPath);
if (!sourceDir.exists() || !sourceDir.isDirectory()) {
throw new BusinessException(ErrorCode.SYSTEM_ERROR, "应用代码路径不存在,请先生成应用");
}
// 7. Vue 项目特殊处理:执行构建
CodeGenTypeEnum codeGenTypeEnum = CodeGenTypeEnum.getEnumByValue(codeGenType);
if (codeGenTypeEnum == CodeGenTypeEnum.VUE_PROJECT) {
// Vue 项目需要构建
boolean buildSuccess = vueProjectBuilder.buildProject(sourceDirPath);
ThrowUtils.throwIf(!buildSuccess, ErrorCode.SYSTEM_ERROR, "Vue 项目构建失败,请重试");
// 检查 dist 目录是否存在
File distDir = new File(sourceDirPath, "dist");
ThrowUtils.throwIf(!distDir.exists(), ErrorCode.SYSTEM_ERROR, "Vue 项目构建完成但未生成 dist 目录");
// 构建完成后,需要将构建后的文件复制到部署目录
sourceDir = distDir;
}
// 8. 复制文件到部署目录
String deployDirPath = AppConstant.CODE_DEPLOY_ROOT_DIR + File.separator + deployKey;
try {
FileUtil.copyContent(sourceDir, new File(deployDirPath), true);
} catch (Exception e) {
throw new BusinessException(ErrorCode.SYSTEM_ERROR, "应用部署失败:" + e.getMessage());
}
// 9. 更新数据库
App updateApp = new App();
updateApp.setId(appId);
updateApp.setDeployKey(deployKey);
updateApp.setDeployedTime(LocalDateTime.now());
boolean updateResult = this.updateById(updateApp);
ThrowUtils.throwIf(!updateResult, ErrorCode.OPERATION_ERROR, "更新应用部署信息失败");
// 10. 构建应用访问 URL
String appDeployUrl = String.format("%s/%s/", deployHost, deployKey); // 11. 异步生成截图并且更新应用封面
generateAppScreenshotAsync(appId, appDeployUrl);
return appDeployUrl;
}下面来逐行分析:
App app = this.getById(appId);先获取这个用户的App信息
表长这样:
java
-- 创建库
create database if not exists yu_ai_code_mother;
-- 切换库
use yu_ai_code_mother;
-- 用户表
-- 以下是建表语句
-- 用户表
create table if not exists user
(
id bigint auto_increment comment 'id' primary key,
userAccount varchar(256) not null comment '账号',
userPassword varchar(512) not null comment '密码',
userName varchar(256) null comment '用户昵称',
userAvatar varchar(1024) null comment '用户头像',
userProfile varchar(512) null comment '用户简介',
userRole varchar(256) default 'user' not null comment '用户角色:user/admin',
editTime datetime default CURRENT_TIMESTAMP not null comment '编辑时间',
createTime datetime default CURRENT_TIMESTAMP not null comment '创建时间',
updateTime datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间',
isDelete tinyint default 0 not null comment '是否删除',
UNIQUE KEY uk_userAccount (userAccount),
INDEX idx_userName (userName)
) comment '用户' collate = utf8mb4_unicode_ci;
-- 应用表
create table app
(
id bigint auto_increment comment 'id' primary key,
appName varchar(256) null comment '应用名称',
cover varchar(512) null comment '应用封面',
initPrompt text null comment '应用初始化的 prompt',
codeGenType varchar(64) null comment '代码生成类型(枚举)',
deployKey varchar(64) null comment '部署标识',
deployedTime datetime null comment '部署时间',
priority int default 0 not null comment '优先级',
userId bigint not null comment '创建用户id',
editTime datetime default CURRENT_TIMESTAMP not null comment '编辑时间',
createTime datetime default CURRENT_TIMESTAMP not null comment '创建时间',
updateTime datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间',
isDelete tinyint default 0 not null comment '是否删除',
UNIQUE KEY uk_deployKey (deployKey), -- 确保部署标识唯一
INDEX idx_appName (appName), -- 提升基于应用名称的查询性能
INDEX idx_userId (userId) -- 提升基于用户 ID 的查询性能
) comment '应用' collate = utf8mb4_unicode_ci;
-- 对话历史表
create table chat_history
(
id bigint auto_increment comment 'id' primary key,
message text not null comment '消息',
messageType varchar(32) not null comment 'user/ai',
appId bigint not null comment '应用id',
userId bigint not null comment '创建用户id',
createTime datetime default CURRENT_TIMESTAMP not null comment '创建时间',
updateTime datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间',
isDelete tinyint default 0 not null comment '是否删除',
INDEX idx_appId (appId), -- 提升基于应用的查询性能
INDEX idx_createTime (createTime), -- 提升基于时间的查询性能
INDEX idx_appId_createTime (appId, createTime) -- 游标查询核心索引
) comment '对话历史' collate = utf8mb4_unicode_ci;然后接着往下看代码:
if (!app.getUserId().equals(loginUser.getId())) {
throw new BusinessException(ErrorCode.NO_AUTH_ERROR, "无权限部署该应用");
}这一步颇为关键防止其他人通过url访问你的应用,因为他会跟浏览器上那个登录用户进行校验,如果是别人根据appid去访问你的应用是不可能实现的,每个appid对应一个userid,然后拿登录id和appid对应的userid进行校验就可以劝退。
// 4. 检查是否已有 deployKey
String deployKey = app.getDeployKey();
// 如果没有,则生成 6 位 deployKey(字母 + 数字)
if (StrUtil.isBlank(deployKey)) {
deployKey = RandomUtil.randomString(6);
}先检查有没有deploykey如果没有则创建如果有的话则直接拿,就算是多次点击也不会使一个文件的,有没有人疑问为什么要用deploykey,其实流程就是返回给前端的是一个含有deploykey的url而不是含有appid的url,你总不能暴漏你的appid吧,然后在访问那个展示接口的时候也是给后端传deploykey,然后在通过deploykey去查库拿到appid在找到相应的文件的位置,然后再把文件返回给前端然后渲染。
deployKey 的设计初衷:
-
不暴露内部 ID :
appId、userId是数据库的自增主键,非常敏感,容易被人猜测、遍历,用随机生成的deployKey对外暴露,完全隐藏了内部信息; -
访问隔离 :每个应用的
deployKey都是唯一的,用户只能通过自己的deployKey访问自己的文件,无法访问别人的; -
路径解耦 :外部 URL 只认
deployKey,不认文件路径,文件路径可以随时换,只要deployKey不变,访问 URL 就不变。
下面接着看代码:
// 5. 获取代码生成类型,获取原始代码生成路径(应用访问目录)
String codeGenType = app.getCodeGenType();
String sourceDirName = codeGenType + "_" + appId;
String sourceDirPath = AppConstant.CODE_OUTPUT_ROOT_DIR + File.separator + sourceDirName;拼装文件地址,这个和ai生成的那个地址是一模一样的。
假设·appid为2,类型为html类型
那么路径就是String sourceDirPath = "/data/yu-ai-code" + "/" + "html_2";
D:\Project\yu-ai-code 目录下启动的项目,最终路径就是
D:\Project\yu-ai-code \data\yu-ai-code\html_2
下面接着来看:
// 6. 检查路径是否存在
File sourceDir = new File(sourceDirPath);
if (!sourceDir.exists() || !sourceDir.isDirectory()) {
throw new BusinessException(ErrorCode.SYSTEM_ERROR, "应用代码路径不存在,请先生成应用");
}检查这个路径下有没有文件如果没有的话说明ai没有生成文件代码,这样就没有必要进行后面的内容了直接给用户返回没有应用即可,让用户重新问。
下面接着看:
if (codeGenTypeEnum == CodeGenTypeEnum.VUE_PROJECT) {
// Vue 项目需要构建
boolean buildSuccess = vueProjectBuilder.buildProject(sourceDirPath);
ThrowUtils.throwIf(!buildSuccess, ErrorCode.SYSTEM_ERROR, "Vue 项目构建失败,请重试");
// 检查 dist 目录是否存在
File distDir = new File(sourceDirPath, "dist");
ThrowUtils.throwIf(!distDir.exists(), ErrorCode.SYSTEM_ERROR, "Vue 项目构建完成但未生成 dist 目录");
// 构建完成后,需要将构建后的文件复制到部署目录
sourceDir = distDir;
}HTML 项目是「原生静态文件,浏览器开箱即用」,而 Vue 项目是「现代前端框架项目,必须经过构建打包,浏览器才能识别」
所以才要这样分类。
- HTML 项目(你之前的场景)
-
文件类型 :纯
.html、.css、.js,没有任何框架语法; -
浏览器支持:浏览器天生就能直接识别、解析、渲染;
-
部署方式 :直接把文件丢给服务器,静态资源接口一读,返回给浏览器就行,不需要任何额外处理。
- Vue 项目(现代前端框架)
-
文件类型 :有
.vue单文件组件、package.json依赖配置、可能还有 TypeScript(.ts)、SCSS(.scss)等浏览器不认识的文件; -
浏览器支持 :浏览器完全不认识
.vue文件 ,也不认识import Vue from 'vue'这种模块化语法; -
部署方式 :必须先经过「构建打包」 ,用 Vite/Webpack 把所有
.vue、.ts、.scss编译、压缩、打包成浏览器能识别的纯.html、.css、.js,生成一个dist目录,只有dist目录里的文件才能部署。
第 1 步:触发 Vue 项目构建
boolean buildSuccess = vueProjectBuilder.buildProject(sourceDirPath);
ThrowUtils.throwIf(!buildSuccess, ErrorCode.SYSTEM_ERROR, "Vue 项目构建失败,请重试");这一步的作用是:在服务器上执行 npm install && npm run build 命令(或者 Vite 的构建命令)。
- 先安装 Vue 项目的依赖(
node_modules); - 然后执行构建,把
.vue文件编译成浏览器能识别的代码。
来看
vueProjectBuilder.buildProject(sourceDirPath)这个方法的代码。
java
public boolean buildProject(String projectPath) {
File projectDir = new File(projectPath);
if (!projectDir.exists() || !projectDir.isDirectory()) {
log.error("项目目录不存在:{}", projectPath);
return false;
}
// 检查是否有 package.json 文件
File packageJsonFile = new File(projectDir, "package.json");
if (!packageJsonFile.exists()) {
log.error("项目目录中没有 package.json 文件:{}", projectPath);
return false;
}
log.info("开始构建 Vue 项目:{}", projectPath);
// 执行 npm install
if (!executeNpmInstall(projectDir)) {
log.error("npm install 执行失败:{}", projectPath);
return false;
}
// 执行 npm run build
if (!executeNpmBuild(projectDir)) {
log.error("npm run build 执行失败:{}", projectPath);
return false;
}
// 验证 dist 目录是否生成
File distDir = new File(projectDir, "dist");
if (!distDir.exists() || !distDir.isDirectory()) {
log.error("构建完成但 dist 目录未生成:{}", projectPath);
return false;
}
log.info("Vue 项目构建成功,dist 目录:{}", projectPath);
return true;
}if (!projectDir.exists() || !projectDir.isDirectory()) {
log.error("项目目录不存在:{}", projectPath);
return false;
}依旧判断ai有没有生成没有生成则返回然后:
// 检查是否有 package.json 文件
File packageJsonFile = new File(projectDir, "package.json");
if (!packageJsonFile.exists()) {
log.error("项目目录中没有 package.json 文件:{}", projectPath);
return false;
}- 检查项目目录下,有没有
package.json这个文件。
为什么这么做:
-
package.json是 Node.js/Vue 项目的核心标志:-
它定义了项目的依赖(比如
vue、vite); -
它定义了构建命令(比如
npm run build对应的脚本);
-
-
没有这个文件,就没法用
npm安装依赖,也没法执行构建。
AI 生成 Vue 项目时,一定会生成 package.json,如果没有,说明 AI 生成失败了。
下面看最重要的:
// 执行 npm install
if (!executeNpmInstall(projectDir)) {
log.error("npm install 执行失败:{}", projectPath);
return false;
}
// 执行 npm run build
if (!executeNpmBuild(projectDir)) {
log.error("npm run build 执行失败:{}", projectPath);
return false;
}- 调用
executeNpmInstall方法(这个方法里应该是用ProcessBuilder或Runtime执行系统命令); - 在项目目录下,执行
npm install命令。
为什么这么做:
- Vue 项目需要依赖第三方库(比如
vue框架本身、vite构建工具); - 这些依赖不会被 AI 生成到代码里(文件太大了),AI 只会在
package.json里写清楚需要哪些依赖; npm install会根据package.json,从 npm 官方仓库下载所有依赖,放到node_modules目录里。
失败场景:
- 服务器没装 Node.js/npm;
- 服务器网络不好,连不上 npm 仓库;
package.json里的依赖名称 / 版本写错了。
先看executeNpmInstall方法:
java
private boolean executeNpmInstall(File projectDir) {
log.info("执行 npm install...");
String command = String.format("%s install", buildCommand("npm"));
return executeCommand(projectDir, command, 300); // 5分钟超时
}就是执行这个命令行。
前提是要提前在服务器上面安装node.js。
然后
- 调用
executeNpmBuild方法; - 在项目目录下,执行
npm run build命令。
为什么这么做:
- 这是最核心的一步 ,把 Vue 源码变成浏览器能识别的代码:
- 把
.vue单文件组件编译成纯 JS/CSS; - 把 TypeScript(
.ts)编译成纯 JS; - 把 SCSS/Less 编译成纯 CSS;
- 压缩、优化代码,减小文件体积;
- 生成最终的
index.html和assets目录。
- 把
- 这个命令是在
package.json里定义的,通常对应vite build或vue-cli-service build。
再看executeNpmBuild方法:
java
/**
* 执行 npm run build 命令
*/
private boolean executeNpmBuild(File projectDir) {
log.info("执行 npm run build...");
String command = String.format("%s run build", buildCommand("npm"));
return executeCommand(projectDir, command, 180); // 3分钟超时
}执行 npm run build 命令。
第 5 步:验证 dist 目录是否生成(确认构建成功)
// 验证 dist 目录是否生成
File distDir = new File(projectDir, "dist");
if (!distDir.exists() || !distDir.isDirectory()) {
log.error("构建完成但 dist 目录未生成:{}", projectPath);
return false;
}在做什么:
-
检查项目目录下,有没有生成
dist目录; -
确认
dist是一个目录(不是文件)。
为什么这么做:
-
dist是 Vue 构建成功的唯一标志:-
构建成功,一定会生成
dist目录; -
没有
dist目录,说明构建肯定失败了(哪怕第 4 步没报错)。
-
-
后面的部署逻辑,用的就是这个
dist目录。
第 6 步:构建成功,返回 true
log.info("Vue 项目构建成功,dist 目录:{}", projectPath);
return true;接着往下看:
String deployDirPath = AppConstant.CODE_DEPLOY_ROOT_DIR + File.separator + deployKey;
-
- 用
deployKey当部署目录的名字(比如/data/yu-ai-deploy/abc123); - 设计初衷 :
- ✅ 隔离性:每个应用的部署文件完全独立,互不干扰;
- ✅ 安全性:用随机的
deployKey当目录名,不暴露appId、userId,别人猜不到; - ✅ 对应性:后面静态资源接口通过
deployKey找目录,100% 匹配。
- 用
FileUtil.copyContent(sourceDir, new File(deployDirPath), true);
-
sourceDir:如果是 HTML 项目,就是源码目录;如果是 Vue 项目,就是构建后的dist目录; -
new File(deployDirPath):目标部署目录(刚才拼的那个); -
true:覆盖模式,如果目录已经存在(比如重新部署),直接覆盖旧文件,保证是最新的。 -
**为什么要复制?直接用源码目录不行吗?**宝贝,这是个好问题!直接用源码目录也能跑,但复制有 3 个不可替代的好处:
-
🛡️ 安全性:部署目录和源码目录分离,防止用户 / AI 修改源码时,直接影响线上正在运行的应用;
-
🔄 回滚方便:如果重新部署失败,旧的部署目录还在,随时能回滚;
-
📁 统一管理 :所有部署的文件都在
CODE_DEPLOY_ROOT_DIR下,备份、清理、迁移都方便。 -
第 9 步:更新数据库(告诉大家 "我部署好了")
// 9. 更新数据库 App updateApp = new App(); updateApp.setId(appId); updateApp.setDeployKey(deployKey); updateApp.setDeployedTime(LocalDateTime.now()); boolean updateResult = this.updateById(updateApp); ThrowUtils.throwIf(!updateResult, ErrorCode.OPERATION_ERROR, "更新应用部署信息失败");
第 10 步:构建应用访问 URL(给用户一个能点的链接)
// 10. 构建应用访问 URL
String appDeployUrl = String.format("%s/%s/", deployHost, deployKey);宝贝,这一步就是 "临门一脚":
-
deployHost:你在配置文件里配的项目域名(比如https://yu-ai-code.com); -
deployKey:刚才生成的随机字符串; -
拼接后就是:
https://yu-ai-code.com/abc123/; -
这个 URL 正好对应你之前写的静态资源接口:
-
用户点击这个 URL → 浏览器请求
https://yu-ai-code.com/abc123/→ 接口通过deployKey=abc123找到部署目录 → 返回index.html→ 用户看到网页。 -
第 11 步:异步生成截图并且更新应用封面(悄悄提升体验)
// 11. 异步生成截图并且更新应用封面 generateAppScreenshotAsync(appId, appDeployUrl); return appDeployUrl;宝贝,这一步是 "点睛之笔",我给你讲两个关键点:
-
什么是 "异步"?为什么要异步?
-
异步:就是 "不在这里等它做完,先把 URL 返回给用户,后台慢慢做";
-
为什么要异步?
-
生成截图很慢(要启动浏览器、加载网页、截图、保存),可能要好几秒甚至十几秒;
-
如果是同步(在这里等截图生成完再返回),用户点击部署后,页面会转十几秒的圈,体验极差;
-
异步的话:用户点击部署 → 1 秒内拿到 URL → 直接去看网页 → 后台默默生成截图 → 生成完自动更新到数据库。
-
-
-
生成截图干嘛用?
-
生成的截图会当成应用的封面图;
-
用户在 "我的应用" 列表里,能直接看到每个应用长什么样,不用点进去,体验更好。
-
最后,宝贝,我给你串成完整的闭环
-
复制文件 :把构建好的文件,复制到用
deployKey命名的独立部署目录; -
更新数据库 :把
deployKey和部署时间存到数据库,留好 "访问凭证"; -
返回 URL:给用户一个能直接访问的链接;
-
异步截图:后台悄悄生成封面图,不耽误用户时间。
-
下面看这个方法的代码:
java@Override public void generateAppScreenshotAsync(Long appId, String appUrl) { // 使用虚拟线程并执行 Thread.startVirtualThread(() -> { // 调用截图服务生成截图并上传 String screenshotUrl = screenshotService.generateAndUploadScreenshot(appUrl); // 更新数据库的封面 App updateApp = new App(); updateApp.setId(appId); updateApp.setCover(screenshotUrl); boolean updated = this.updateById(updateApp); ThrowUtils.throwIf(!updated, ErrorCode.OPERATION_ERROR, "更新应用封面字段失败"); }); }异步入口层 ------
generateAppScreenshotAsync核心职责 :在后台开一个线程悄悄干活,绝对不阻塞部署接口的主流程,让用户立刻拿到部署 URL,不用等截图生成。
-
关键细节:
-
**为什么用虚拟线程
Thread.startVirtualThread?**虚拟线程是 Java 21 + 的特性,非常轻量,开几千几万个都不占资源,专门用来处理这种 "耗时但不重要" 的后台任务,比传统的线程池更简单高效。 -
为什么只 set
cover字段? 又是利用了 MyBatis Plus 的updateById特性:只更新非 null 字段,绝对不会不小心覆盖掉appName、deployKey这些其他字段,安全。 -
下面来看这段代码:
// 本地截图 String localScreenshotPath = WebScreenshotUtils.saveWebPageScreenshot(webUrl);- 来看这个方法:
-
java
public static String saveWebPageScreenshot(String webUrl) {
// 非空校验
if (StrUtil.isBlank(webUrl)) {
log.error("网页截图失败,url为空");
return null;
}
// 创建临时目录
try {
String rootPath = System.getProperty("user.dir") + "/tmp/screenshots/" + UUID.randomUUID().toString().substring(0, 8);
FileUtil.mkdir(rootPath);
// 图片后缀
final String IMAGE_SUFFIX = ".png";
// 原始图片保存路径
String imageSavePath = rootPath + File.separator + RandomUtil.randomNumbers(5) + IMAGE_SUFFIX;
// 访问网页
webDriver.get(webUrl);
// 等待网页加载
waitForPageLoad(webDriver);
// 截图
byte[] screenshotBytes = ((TakesScreenshot) webDriver).getScreenshotAs(OutputType.BYTES);
// 保存原始图片
saveImage(screenshotBytes, imageSavePath);
log.info("原始截图保存成功:{}", imageSavePath);
// 压缩图片
final String COMPRESS_SUFFIX = "_compressed.jpg";
String compressedImagePath = rootPath + File.separator + RandomUtil.randomNumbers(5) + COMPRESS_SUFFIX;
compressImage(imageSavePath, compressedImagePath);
log.info("压缩图片保存成功:{}", compressedImagePath);
// 删除原始图片
FileUtil.del(imageSavePath);
return compressedImagePath;
} catch (Exception e) {
log.error("网页截图失败:{}", webUrl, e);
return null;
}
}这个方法里面就是讲为什么要截图。下面来一步步分析这段代码。
这段代码的核心目标是:在服务器后台,用一个 "看不见的浏览器" 打开你刚部署好的网页,截一张和用户看到的一模一样的图,再压缩成小文件,返回本地路径。
我把它拆成 10 个小步骤,每一步都讲得明明白白:
步骤 1:先做最基础的非空校验
java
if (StrUtil.isBlank(webUrl)) {
log.error("网页截图失败,url为空");
return null;
}在做什么 :先检查传进来的访问 URL 是不是空的,如果是空的,直接打日志报错,不往下走了。为什么这么做:防止空指针异常,这是代码里最基础的安全校验。
步骤 2:创建一个专属的临时目录
java
String rootPath = System.getProperty("user.dir") + "/tmp/screenshots/" + UUID.randomUUID().toString().substring(0, 8);
FileUtil.mkdir(rootPath);在做什么:
System.getProperty("user.dir"):拿到你项目在服务器上的根目录;UUID.randomUUID().toString().substring(0, 8):生成一个随机的 8 位字符串,避免和其他截图任务的目录冲突;- 最后拼接成一个临时目录路径(比如
/你的项目根目录/tmp/screenshots/abc12345/),然后创建这个目录。为什么这么做:因为可能同时有好几个用户在部署应用、生成截图,用随机 UUID 命名目录,能彻底避免多线程文件冲突,你截你的图,我存我的文件,互不干扰。
步骤 3:准备原始截图的保存路径
final String IMAGE_SUFFIX = ".png";
String imageSavePath = rootPath + File.separator + RandomUtil.randomNumbers(5) + IMAGE_SUFFIX;步骤 4:【核心】用 "看不见的浏览器" 打开网页
webDriver.get(webUrl);在做什么 :这里的webDriver就是无头浏览器 (比如 Chrome Headless)------ 一个在服务器后台运行的、没有界面的真实浏览器。这行代码就是让这个无头浏览器去访问你刚部署好的网页 URL。为什么要用无头浏览器:这是最关键的!因为你的网页可能有 JS 动态渲染(比如 Vue 项目),普通的 HTTP 请求只能拿到 HTML 源码,拿不到 JS 渲染后的最终页面,只有用真实的浏览器打开,才能截到和用户看到的一模一样的图。
但是为什么这一行就可以访问静态接口呢下面来看我解释:
-
webDriver.get(url)= 浏览器 发 GET 请求 给后端 -
你传的这个
url是:https://你的域名.com/abc123/ -
你后端写的静态接口是:
@GetMapping("/{deployKey}/**") -
所以:URL 路径一匹配 → 直接进你这个静态接口
-
假如说端口是本地localhost那么那个url路径就是
https:/localhost/stast/abc123/而且还是get请求 -
这不就相当于前端去调用后端的get请求的接口吗,就是调用这个接口的意思。
-
webDriver.get(url)= 新开一个无头浏览器 ,用你那个deployKey的 URL,去访问你的静态接口。 -
它自己在后台:请求接口 → 拿到 HTML → 渲染页面。
-
getScreenshotAs(...)= 直接在这个已经加载好页面的浏览器上截图。
步骤 5:等待网页完全加载
waitForPageLoad(webDriver);在做什么 :无头浏览器打开网页后,不会立刻截图,而是会等待网页完全加载 ------ 包括 HTML、CSS、JS 都执行完,页面上的所有元素都渲染出来。为什么要等:如果不等,可能会截到一个白屏、或者只有一半内容的图,就白截了。
在做什么:
- 定义原始截图的格式是
.png(PNG 是无损格式,截图最清晰); - 生成一个随机的 5 位数字当文件名,拼接成完整的原始图片保存路径(比如
/你的项目根目录/tmp/screenshots/abc12345/12345.png)。为什么用随机文件名:还是为了避免冲突,保证每个截图文件的名字都是唯一的。
步骤 6:【核心】给渲染好的网页截图
byte[] screenshotBytes = ((TakesScreenshot) webDriver).getScreenshotAs(OutputType.BYTES);在做什么 :让无头浏览器给当前渲染好的网页截一张全屏图,把截图转成字节数组(byte[]),暂时存在内存里。为什么转成字节数组:方便后续保存到本地文件里。
步骤 7:把原始截图保存到本地
saveImage(screenshotBytes, imageSavePath);
log.info("原始截图保存成功:{}", imageSavePath);在做什么:把内存里的截图字节数组,写入到步骤 3 准备好的本地 PNG 文件里,然后打日志说 "原始截图保存成功了"。
然后看这个方法:
java
private static void saveImage(byte[] imageBytes, String imagePath) {
try {
FileUtil.writeBytes(imageBytes, imagePath);
} catch (Exception e) {
log.error("保存图片失败:{}", imagePath, e);
throw new BusinessException(ErrorCode.SYSTEM_ERROR, "保存图片失败");
}
}即把这个字节转换成照片存入相应的地址也就是imagepath。
步骤 8:【核心】把大的 PNG 压缩成小的 JPG
java
运行
final String COMPRESS_SUFFIX = "_compressed.jpg";
String compressedImagePath = rootPath + File.separator + RandomUtil.randomNumbers(5) + COMPRESS_SUFFIX;
compressImage(imageSavePath, compressedImagePath);
log.info("压缩图片保存成功:{}", compressedImagePath);在做什么:
-
定义压缩后的格式是
.jpg(JPG 是有损格式,但体积小很多); -
生成一个新的随机文件名,拼接成压缩后的图片路径;
-
调用
compressImage方法,把刚才的 PNG 原图压缩成 JPG,保存到新路径里; -
打日志说 "压缩成功了"。为什么要压缩:原始 PNG 截图通常很大(可能几 MB),压缩成 JPG 后,体积能缩小到原来的 1/10 甚至更小,能:
-
💰 节省对象存储(COS)的存储空间和流量费用;
-
⚡ 用户在应用列表里看封面图,加载速度更快。
-
步骤 9:删除原始 PNG,只保留压缩后的 JPG
java
运行
FileUtil.del(imageSavePath);在做什么 :把步骤 7 保存的 PNG 原图删掉,只留步骤 8 压缩后的 JPG。为什么要删:原图已经没用了,留着只会占服务器磁盘空间,浪费资源。
步骤 10:返回压缩后的图片路径,给上一层用
java
运行
return compressedImagePath;在做什么 :把压缩后的 JPG 图片的本地路径,返回给上一层的业务逻辑(ScreenshotServiceImpl),让它去上传到 COS。
下面就是上传到cos:
// 上传图片到 COS
try {
String cosUrl = uploadScreenshotToCos(localScreenshotPath);
ThrowUtils.throwIf(StrUtil.isBlank(cosUrl), ErrorCode.OPERATION_ERROR, "上传截图到对象存储失败");
log.info("截图上传成功,URL:{}", cosUrl);
return cosUrl;
} finally {
// 清理本地文件
cleanupLocalFile(localScreenshotPath);
}这个流程就是:
- 就是上传到 COS:把本地压缩好的 JPG 截图,上传到腾讯云对象存储(COS)里。
- 拿到图片的 URL :上传成功后,COS 会返回一个公网可访问的图片链接 (比如
https://你的cos桶名.cos.ap-guangzhou.myqcloud.com/screenshots/abc123.jpg)。 - 存入 app 表为封面 :把这个 COS URL 存到
app表的cover字段里,用户下次刷新「我的应用」列表,就能直接从 COS 加载封面图了。 - 本地文件就没有用了:因为 COS 里已经有了公网可访问的图片,本地的临时文件(包括压缩后的 JPG、临时目录)完全没用了,必须删掉,防止占满服务器磁盘。
下面来看这个方法内部
String cosUrl = uploadScreenshotToCos(localScreenshotPath);
java
/**
* 上传截图到对象存储
*
* @param localScreenshotPath 本地截图路径
* @return 对象存储访问URL,失败返回null
*/
private String uploadScreenshotToCos(String localScreenshotPath) {
if (StrUtil.isBlank(localScreenshotPath)) {
return null;
}
File screenshotFile = new File(localScreenshotPath);
if (!screenshotFile.exists()) {
log.error("截图文件不存在: {}", localScreenshotPath);
return null;
}
// 生成 COS 对象键
String fileName = UUID.randomUUID().toString().substring(0, 8) + "_compressed.jpg";
String cosKey = generateScreenshotKey(fileName);
return cosManager.uploadFile(cosKey, screenshotFile);
}if (StrUtil.isBlank(localScreenshotPath)) {
return null;
}
File screenshotFile = new File(localScreenshotPath);
if (!screenshotFile.exists()) {
log.error("截图文件不存在: {}", localScreenshotPath);
return null;
}这些都不需要说了很简单的判空但也是非常重要的。
关键设计亮点:
-
为什么要重新生成文件名?不用本地的? 本地文件名是
RandomUtil.randomNumbers(5) + "_compressed.jpg",虽然也是随机的,但上传到 COS 后,为了100% 避免文件名冲突(比如两个用户同时生成了一样的 5 位随机数),用 UUID 重新生成一个 8 位的唯一文件名,更稳妥。 -
**为什么要做两次校验?**先校验路径不为空,再校验文件真的存在,这是代码里最基础的 "防御性编程",防止后面调用 COS SDK 时报错,提前拦截问题。
来看
String cosKey = generateScreenshotKey(fileName);这个方法。
java
private String generateScreenshotKey(String fileName) {
String datePath = LocalDate.now().format(DateTimeFormatter.ofPattern("yyyy/MM/dd"));
return String.format("/screenshots/%s/%s", datePath, fileName);
}为什么要按日期分目录? 这是对象存储(COS/OSS)里的最佳实践,有三个不可替代的好处:
- 📦 方便管理:以后要清理旧的截图(比如删除半年前的),直接按日期删目录就行,不用一个个找文件;
- ⚡ 提升性能:COS 里如果有几百万个文件,都放在同一个目录下,访问性能会下降,按日期分目录能分散压力;
- 📊 方便统计:想知道今天生成了多少张截图,直接看今天的目录下有多少个文件就行。
下面来看最重要的上传:
return cosManager.uploadFile(cosKey, screenshotFile);coskey为新生成的String类型路径,screenshotFile为照片所在的文件注意这里是文件不是文件地址。
下面来看这个方法:
java
public String uploadFile(String key, File file) {
PutObjectResult result = putObject(key, file);
if (result != null) {
String url = String.format("%s%s", cosClientConfig.getHost(), key);
log.info("文件上传到 COS 成功:{} -> {}", file.getName(), url);
return url;
} else {
log.error("文件上传到 COS 失败:{},返回结果为空", file.getName());
return null;
}
}
}来直接看第一行的这个方法代码就是最关键的上传代码:
java
public PutObjectResult putObject(String key, File file) {
PutObjectRequest putObjectRequest = new PutObjectRequest(cosClientConfig.getBucket(), key, file);
return cosClient.putObject(putObjectRequest);
}PutObjectRequest putObjectRequest = new PutObjectRequest(
cosClientConfig.getBucket(), // 告诉COS:我要传到「哪个桶」里
key, // 告诉COS:文件在桶里「叫什么名字、存哪个路径」
file // 告诉COS:我要传的「本地文件」是哪个 );
拿到反馈后如果成功就拼接url
String url = String.format("%s%s", cosClientConfig.getHost(), key);然后返回这个url就是得这样拼接。
那么
uploadScreenshotToCos方法的返回值就拿到啦。来回到
generateAndUploadScreenshot这个方法。String cosUrl = uploadScreenshotToCos(localScreenshotPath);现在已经到这一步啦,来看剩下的代码:
ThrowUtils.throwIf(StrUtil.isBlank(cosUrl), ErrorCode.OPERATION_ERROR, "上传截图到对象存储失败");
log.info("截图上传成功,URL:{}", cosUrl);
return cosUrl;
} finally {
// 清理本地文件
cleanupLocalFile(localScreenshotPath);就是一些校验和删除不要的文件。
然后再回到上一层
generateAppScreenshotAsync这个方法看剩下的代码:
// 更新数据库的封面
App updateApp = new App();
updateApp.setId(appId);
updateApp.setCover(screenshotUrl);
boolean updated = this.updateById(updateApp);
ThrowUtils.throwIf(!updated, ErrorCode.OPERATION_ERROR, "更新应用封面字段失败");就是给数据库里面的字段赋值,咱们不是生成了封面的url吗对吧,然后直接存入数据库,然后前端刷新页面查数据库拿到url然后渲染就可以看到那个图片了。
再往上回到
deployApp这个方法。最后是
return appDeployUrl; 返回那个生成的url(不是照片的),然后用户点击去访问静态接口,记住这个url是由deploykey组成的。下面来看静态接口:
- 用户 / 无头浏览器访问 :
/api/static/abc123/ - 进入这个接口 :
StaticResourceController.serveStaticResource - 处理路径 :去掉前缀,拿到
/ - 默认返回 index.html :把
/变成/index.html - 拼接本地路径 :
/data/yu-ai-code/output/abc123/index.html - 检查文件存在:存在
- 设置 Content-Type :
text/html; charset=UTF-8 - 返回文件:浏览器收到 HTML,渲染页面
- 截图成功:无头浏览器拿到页面,截出正常的封面图
作用:
根据传入的 deployKey,找到对应部署好的前端静态文件,返回给浏览器,让页面能正常打开、渲染显示。
简单说:负责让用户 / 截图工具,能通过链接访问到你部署的前端页面。
代码如下:
java
package com.yupi.yuaicodemother.controller;
import com.yupi.yuaicodemother.constant.AppConstant;
import jakarta.servlet.http.HttpServletRequest;
import org.springframework.core.io.FileSystemResource;
import org.springframework.core.io.Resource;
import org.springframework.http.HttpHeaders;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.servlet.HandlerMapping;
import java.io.File;
/**
* 静态资源访问
*/
@RestController
@RequestMapping("/static")
public class StaticResourceController {
// 应用生成根目录(用于浏览)
private static final String PREVIEW_ROOT_DIR = AppConstant.CODE_OUTPUT_ROOT_DIR;
/**
* 提供静态资源访问,支持目录重定向
* 访问格式:http://localhost:8123/api/static/{deployKey}[/{fileName}]
*/
@GetMapping("/{deployKey}/**")
public ResponseEntity<Resource> serveStaticResource(
@PathVariable String deployKey,
HttpServletRequest request) {
try {
// 获取资源路径
String resourcePath = (String) request.getAttribute(HandlerMapping.PATH_WITHIN_HANDLER_MAPPING_ATTRIBUTE);
resourcePath = resourcePath.substring(("/static/" + deployKey).length());
// 如果是目录访问(不带斜杠),重定向到带斜杠的URL
if (resourcePath.isEmpty()) {
HttpHeaders headers = new HttpHeaders();
headers.add("Location", request.getRequestURI() + "/");
return new ResponseEntity<>(headers, HttpStatus.MOVED_PERMANENTLY);
}
// 默认返回 index.html
if (resourcePath.equals("/")) {
resourcePath = "/index.html";
}
// 构建文件路径
String filePath = PREVIEW_ROOT_DIR + "/" + deployKey + resourcePath;
File file = new File(filePath);
// 检查文件是否存在
if (!file.exists()) {
return ResponseEntity.notFound().build();
}
// 返回文件资源
Resource resource = new FileSystemResource(file);
return ResponseEntity.ok()
.header("Content-Type", getContentTypeWithCharset(filePath))
.body(resource);
} catch (Exception e) {
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).build();
}
}
/**
* 根据文件扩展名返回带字符编码的 Content-Type
*/
private String getContentTypeWithCharset(String filePath) {
if (filePath.endsWith(".html")) return "text/html; charset=UTF-8";
if (filePath.endsWith(".css")) return "text/css; charset=UTF-8";
if (filePath.endsWith(".js")) return "application/javascript; charset=UTF-8";
if (filePath.endsWith(".png")) return "image/png";
if (filePath.endsWith(".jpg")) return "image/jpeg";
return "application/octet-stream";
}
}先看整体:这个类是干什么的?
@RestController
@RequestMapping("/static")
public class StaticResourceController {
// ...
}核心作用:
- 这是一个专门提供静态资源访问的控制器
- 访问路径前缀是:
/api/static/(因为你项目里应该配置了context-path: /api) - 它就是你之前一直在找的、让浏览器 / 无头浏览器能访问到前端页面的接口!
-
先看常量:根目录在哪?
// 应用生成根目录(用于浏览)
private static final String PREVIEW_ROOT_DIR = AppConstant.CODE_OUTPUT_ROOT_DIR;
意思:
- 它指向你项目里
AppConstant类里定义的CODE_OUTPUT_ROOT_DIR - 这就是你存放AI 生成的前端代码的根目录
- 对应你之前聊的
/data/yu-ai-deploy/这类路径
核心方法:serveStaticResource(最关键)
这是整个类的灵魂,我拆成6 个步骤给你讲:
步骤 1:获取请求的资源路径
// 获取资源路径
String resourcePath = (String) request.getAttribute(HandlerMapping.PATH_WITHIN_HANDLER_MAPPING_ATTRIBUTE);
resourcePath = resourcePath.substring(("/static/" + deployKey).length());大白话:
- 比如你访问:
/api/static/abc123/index.html - 它会把
/static/abc123去掉,拿到剩下的/index.html - 这样就能知道:你要访问
abc123这个部署包里的index.html文件
步骤 2:处理目录重定向(超级贴心的细节)
// 如果是目录访问(不带斜杠),重定向到带斜杠的URL
if (resourcePath.isEmpty()) {
HttpHeaders headers = new HttpHeaders();
headers.add("Location", request.getRequestURI() + "/");
return new ResponseEntity<>(headers, HttpStatus.MOVED_PERMANENTLY);
}为什么要这么做?
- 比如你访问:
/api/static/abc123(不带斜杠) - 它会自动重定向到:
/api/static/abc123/(带斜杠) - 好处 :避免页面里的相对路径(比如
./css/style.css)找不到文件,这是 Web 开发的最佳实践!
步骤 3:默认返回 index.html
java
运行
// 默认返回 index.html
if (resourcePath.equals("/")) {
resourcePath = "/index.html";
}意思:
- 只要你访问的是目录(比如
/api/static/abc123/) - 它就自动给你返回这个目录下的
index.html - 不管是原生 HTML 项目,还是 Vue/React 打包后的项目,入口都是
index.html,完美适配!
步骤 4:拼接完整的本地文件路径
java
运行
// 构建文件路径
String filePath = PREVIEW_ROOT_DIR + "/" + deployKey + resourcePath;
File file = new File(filePath);举个例子:
PREVIEW_ROOT_DIR=/data/yu-ai-code/outputdeployKey=abc123resourcePath=/index.html- 拼出来:
/data/yu-ai-code/output/abc123/index.html - 这就是你本地磁盘上的真实文件路径!
步骤 5:检查文件是否存在
java
运行
// 检查文件是否存在
if (!file.exists()) {
return ResponseEntity.notFound().build();
}意思:
- 如果文件找不到(比如 deployKey 错了,或者文件被删了)
- 直接返回 404 Not Found
- 防御性编程,避免报错
步骤 6:返回文件,设置正确的 Content-Type
java
运行
// 返回文件资源
Resource resource = new FileSystemResource(file);
return ResponseEntity.ok()
.header("Content-Type", getContentTypeWithCharset(filePath))
.body(resource);意思:
- 把本地文件包装成
Resource返回给浏览器 - 关键 :调用下面的
getContentTypeWithCharset方法,设置正确的文件类型和编码
- 辅助方法:
getContentTypeWithCharset(细节决定成败)
java
运行
private String getContentTypeWithCharset(String filePath) {
if (filePath.endsWith(".html")) return "text/html; charset=UTF-8";
if (filePath.endsWith(".css")) return "text/css; charset=UTF-8";
if (filePath.endsWith(".js")) return "application/javascript; charset=UTF-8";
if (filePath.endsWith(".png")) return "image/png";
if (filePath.endsWith(".jpg")) return "image/jpeg";
return "application/octet-stream";
}为什么这个方法超级重要?
- 正确的 Content-Type:告诉浏览器这是什么文件(HTML/CSS/JS/ 图片),浏览器才能正确渲染
- 强制 UTF-8 编码 :HTML/CSS/JS 都加了
charset=UTF-8,彻底避免中文乱码! - 兜底处理 :其他文件类型返回
application/octet-stream(二进制流),保证不会报错
下面其实这么多文件名大家一定会绕来绕去的所以下面我总结了一下所有的文件名,以及不同接口生成的文件名:
统一固定参数(全程不变):
- 端口:
8080 - 接口统一前缀:
/api - 项目唯一标识:
deployKey = test-app-123 - 本地基础目录:
D:/yu-ai-code- 源码生成目录:
D:/yu-ai-code/generate - 构建打包目录:
D:/yu-ai-code/build - 最终部署目录:
D:/yu-ai-code/deploy - 临时文件目录:
D:/yu-ai-code/temp
- 源码生成目录:
全程按「接口执行顺序」超级详细版
第 1 步:接口 1 → AI 大模型生成【Vue3 原始源码】
接口地址 POST http://localhost:8080/api/generate
接口作用 AI 根据需求生成一套完整可运行的 Vue3 项目源码
此接口生成的所有路径 & 用途 & 是否删除
-
Vue3 项目根目录
- 路径:
D:/yu-ai-code/generate/test-app-123 - 用途:存放完整 Vue3 源码
- 是否删除:不删(项目母版源码)
- 路径:
-
Vue3 核心源码文件
- 路径:
D:/yu-ai-code/generate/test-app-123/src/App.vue - 路径:
D:/yu-ai-code/generate/test-app-123/src/main.js - 路径:
D:/yu-ai-code/generate/test-app-123/index.html - 用途:Vue3 开发时的源代码
- 是否删除:不删
- 路径:
-
项目配置文件(必须有)
- 路径:
D:/yu-ai-code/generate/test-app-123/package.json - 用途:记录依赖、
npm install/npm build命令 - 是否删除:不删
- 路径:
-
vite 或 webpack 配置
- 路径:
D:/yu-ai-code/generate/test-app-123/vite.config.js - 用途:Vue3 打包构建工具配置
- 是否删除:不删
- 路径:
第 2 步:接口 2 → 安装依赖(执行 npm install)
接口地址 POST http://localhost:8080/api/npm/install?deployKey=test-app-123
接口作用 进入源码目录,执行 npm install,下载 Vue3 等所有依赖包
此接口生成的所有路径 & 用途 & 是否删除
-
依赖安装执行目录
- 路径:
D:/yu-ai-code/generate/test-app-123 - 命令:
npm install - 用途:安装 Vue3、vite 等依赖
- 路径:
-
自动生成的依赖文件夹(巨量文件)
- 路径:
D:/yu-ai-code/generate/test-app-123/node_modules - 用途:存放所有下载的第三方包(Vue3、axios、css 库等)
- 是否删除:可删,但一般不删(下次构建快)
- 路径:
-
依赖版本锁定文件
- 路径:
D:/yu-ai-code/generate/test-app-123/package-lock.json - 用途:保证依赖版本一致,防止构建出错
- 是否删除:不删
- 路径:
第 3 步:接口 3 → 打包构建(执行 npm run build)
接口地址 POST http://localhost:8080/api/npm/build?deployKey=test-app-123
接口作用 执行 npm run build,把 Vue3 源码 编译、压缩、打包成静态文件 ,生成 dist 目录
此接口生成的所有路径 & 用途 & 是否删除
-
构建执行目录
- 路径:
D:/yu-ai-code/generate/test-app-123 - 命令:
npm run build
- 路径:
-
打包输出根目录(dist)
- 路径:
D:/yu-ai-code/generate/test-app-123/dist - 用途:Vue3 打包后真正能上线运行的静态文件
- 是否删除:构建完成后可移走,本身临时过渡目录
- 路径:
-
dist 里的核心文件(你最关心的)
- 入口 HTML
- 路径:
dist/index.html - 用途:整个 Vue3 项目的唯一入口
- 路径:
- 打包后的 JS(带哈希)
- 路径:
dist/assets/index-abc123def.js - 用途:Vue3 源码 + 业务代码打包压缩后的脚本
- 路径:
- 打包后的 CSS(带哈希)
- 路径:
dist/assets/index-456xyz78.css - 用途:所有样式合并压缩
- 路径:
- 图片 / 字体
- 路径:
dist/assets/logo.png
- 路径:
- 是否删除:dist 内文件不删,要用于部署
- 入口 HTML
第 4 步:接口 4 → 一键部署
接口地址 POST http://localhost:8080/api/deploy?deployKey=test-app-123
接口作用 把上面 dist 里的所有静态文件,复制到「正式部署目录」,供外部访问
此接口涉及的路径 & 用途 & 是否删除
-
源文件(从哪复制)
- 路径:
D:/yu-ai-code/generate/test-app-123/dist/*
- 路径:
-
目标部署目录(最终存放地)
- 路径:
D:/yu-ai-code/deploy/test-app-123 - 用途:静态接口真正读取的目录
- 是否删除:绝对不删(用户访问全靠它)
- 路径:
-
部署后的文件(和 dist 完全一样)
D:/yu-ai-code/deploy/test-app-123/index.htmlD:/yu-ai-code/deploy/test-app-123/assets/index-abc123def.jsD:/yu-ai-code/deploy/test-app-123/assets/index-456xyz78.css- 用途:提供给浏览器 / 无头浏览器访问
- 是否删除:不删
第 5 步:接口 5 → 静态资源访问(你项目里的 StaticResourceController)
接口地址规则 GET http://localhost:8080/api/static/{deployKey}/**
接口作用 根据 URL,去「部署目录」读取对应的静态文件(html/js/css/png) 返回给浏览器
此接口读取的路径(只读取,不生成)
-
访问 Vue3 首页
- URL:
http://localhost:8080/api/static/test-app-123/ - 对应本地文件:
D:/yu-ai-code/deploy/test-app-123/index.html - 用途:返回入口,浏览器加载 Vue3
- URL:
-
访问 Vue3 打包后的 JS
- URL:
http://localhost:8080/api/static/test-app-123/assets/index-abc123def.js - 对应文件:
D:/yu-ai-code/deploy/test-app-123/assets/index-abc123def.js
- URL:
-
访问 CSS / 图片
- URL:
.../assets/index-456xyz78.css - 对应文件:部署目录下的 css/png
- URL:
第 6 步:接口 6 → 截图 + 上传 COS + 存封面
接口地址 POST http://localhost:8080/api/screenshot/upload?deployKey=test-app-123
接口作用无头浏览器访问静态接口 → 截图 → 压缩 → 上传 COS → 清理本地临时文件 → 存数据库
此接口所有路径(生成 → 使用 → 删除 全链路)
-
无头浏览器访问的页面
- URL:
http://localhost:8080/api/static/test-app-123/ - 用途:加载 Vue3 页面,准备截图
- URL:
-
本地临时截图(未压缩)
- 路径:
D:/yu-ai-code/temp/test-app-123-origin.png - 用途:刚截下来的原图
- 是否删除:压缩后立即删除
- 路径:
-
本地压缩后截图(待上传)
- 路径:
D:/yu-ai-code/temp/test-app-123-compress.jpg - 用途:缩小体积,用于上传 COS
- 是否删除:上传完必删(finally 代码块)
- 路径:
-
COS 内部存储路径(key)
- 路径:
/screenshots/2026/03/13/888abc-compress.jpg - 用途:COS 里文件的存放位置
- 路径:
-
COS 公网访问 URL(存入数据库 app.cover)
- 路径:
https://yu-code.cos.ap-beijing.myqcloud.com/screenshots/2026/03/13/888abc-compress.jpg - 用途:前端列表页显示应用封面图
- 是否删除:云端不删,永久保存
- 路径:
-
generate 接口 → 生成 Vue3 源码→
D:/yu-ai-code/generate/xxx -
npm install 接口 → 下载依赖→ 生成
node_modules -
npm build 接口 → 打包→ 生成
dist目录(html+js+css) -
deploy 接口 → 复制 dist 到部署目录→
D:/yu-ai-code/deploy/xxx -
static 接口 → 读取部署目录文件→ 浏览器能打开 Vue3 页面
-
screenshot 接口 → 访问页面 → 截图 → 上传 COS → 本地临时文件删除 → 封面 URL 存库
10:AI交互流程
第 1 步:用户在前端输入需求,发起对话
用户在前端输入:"生成一个带增删改查的待办清单网页",点击发送。前端调用后端的流式对话接口 (比如 POST /chat/stream),把用户的需求、当前的 appId 传给后端。
第 2 步:后端组装 "全套信息",一次性发给大模型
后端拿到请求后,会组装好这 5 样东西,通过 API 一次性发给大模型(比如 Claude/OpenAI):
-
系统提示词(System Prompt):定死铁律 ------"必须通过文件工具把代码写入服务器,禁止直接返回完整代码,仅反馈工具执行结果";
-
工具定义(Tool Definitions) :把你写的带
@Tool注解的工具类(CreateFileTool/WriteFileTool),转换成大模型能看懂的 "工具说明书"; -
历史对话消息:这个用户和这个应用之前的所有对话记录,让大模型有上下文记忆;
-
用户当前输入:用户刚发的那句需求;
-
固定上下文 :当前登录用户的
userId、当前应用的appId(通过 ThreadLocal 存着,工具执行时要用)。
把这些都放入prompt。下面开始交互,记住一次请求只跟大模型交互一次。
第 3 步:大模型自主决策,生成 "工具调用指令"
大模型收到全套信息后,会做 3 件事:
-
分析需求,生成对应的 HTML、CSS、JS 完整代码;
-
对照系统提示词的规则,决定必须调用
WriteFileTool,不能直接返回代码; -
生成结构化的工具调用指令(JSON 格式),告诉后端要调用哪个工具、传什么参数。
大模型返回的指令大概长这样:
json
{
"tool_calls": [
{
"name": "WriteFileTool",
"arguments": {
"fileName": "index.html",
"content": "<!DOCTYPE html>\n<html lang=\"zh-CN\">\n<head>...这里是完整的HTML代码...</head>\n<body>...</body>\n</html>"
}
},
{
"name": "WriteFileTool",
"arguments": {
"fileName": "style.css",
"content": "* { margin: 0; padding: 0; box-sizing: border-box; }...这里是完整的CSS代码..."
}
},
{
"name": "WriteFileTool",
"arguments": {
"fileName": "script.js",
"content": "const todoList = [];...这里是完整的JS代码..."
}
}
]
}第 4 步:后端 AI 框架拦截指令,自动执行工具
后端的 AI 框架(LangChain4j)接住大模型返回的指令,自动做这几件事:
-
解析指令,找到要调用的工具(
WriteFileTool); -
找到项目里对应的、带
@Tool注解的WriteFileTool方法; -
把大模型传过来的
fileName和content,当成入参传给这个方法。
第 5 步:工具执行,把代码写入服务器磁盘
WriteFileTool 方法开始执行,核心逻辑如下:
-
从 ThreadLocal 里拿到当前的
userId、appId; -
拼接文件路径:
代码根目录 + userId + File.separator + appId + File.separator(比如/data/yu-ai-code/456/123/); -
创建目录(如果不存在);
-
把大模型传过来的完整代码,写入对应的文件(
index.html、style.css、script.js); -
(可选)通过 SSE 把 "已成功写入文件" 的反馈推给前端。
执行完这一步,代码就已经完整躺在服务器磁盘的对应目录里了,这是后续部署的基础。
第 6 步:工具执行结果回传给大模型
LangChain4j 把工具的执行结果(比如 "成功写入 index.html""成功写入 style.css"),再一次发给大模型,告诉它:你让我做的事,我已经做完了。
第 7 步:大模型生成最终回复,返回给前端
大模型拿到工具执行结果后,生成给用户看的自然语言回复,比如:
"我已经帮你完成了待办清单网页的开发,所有代码已写入文件,你可以点击部署按钮上线查看效果了。"
后端把这句回复,通过 SSE 流式推给前端,用户在页面上看到这句话,AI 生成文件的流程就 100% 结束了。
三、最后给你串成完整的大闭环
-
AI 生成文件:用户提需求 → 大模型生成代码 → 调用工具 → 代码写入服务器磁盘;
-
一键部署 :用户点击部署 → 校验文件存在 → 生成 / 复用
deployKey→ 存入数据库 → 返回含deployKey的 URL; -
访问网页 :用户点击 URL → 接口通过
deployKey查appId/userId→ 找到文件路径 → 读取文件返回给浏览器 → 渲染出网页。
下面工具粘在下面了:
java
package com.yupi.yuaicodemother.ai.tools;
import cn.hutool.json.JSONObject;
/**
* 工具基类
* 定义所有工具的通用接口
*/
public abstract class BaseTool {
/**
* 获取工具的英文名称(对应方法名)
*
* @return 工具英文名称
*/
public abstract String getToolName();
/**
* 获取工具的中文显示名称
*
* @return 工具中文名称
*/
public abstract String getDisplayName();
/**
* 生成工具请求时的返回值(显示给用户)
*
* @return 工具请求显示内容
*/
public String generateToolRequestResponse() {
return String.format("\n\n[选择工具] %s\n\n", getDisplayName());
}
/**
* 生成工具执行结果格式(保存到数据库)
*
* @param arguments 工具执行参数
* @return 格式化的工具执行结果
*/
public abstract String generateToolExecutedResult(JSONObject arguments);
}
java
package com.yupi.yuaicodemother.ai.tools;
import cn.hutool.json.JSONObject;
import dev.langchain4j.agent.tool.Tool;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
/**
* 告诉 AI 要退出的工具
*/
@Slf4j
@Component
public class ExitTool extends BaseTool {
@Override
public String getToolName() {
return "exit";
}
@Override
public String getDisplayName() {
return "退出工具调用";
}
/**
* 退出工具调用
* 当任务完成或无需继续使用工具时调用此方法
*
* @return 退出确认信息
*/
@Tool("当任务已完成或无需继续调用工具时,使用此工具退出操作,防止循环")
public String exit() {
log.info("AI 请求退出工具调用");
return "不要继续调用工具,可以输出最终结果了";
}
@Override
public String generateToolExecutedResult(JSONObject arguments) {
return "\n\n[执行结束]\n\n";
}
}
java
package com.yupi.yuaicodemother.ai.tools;
import cn.hutool.json.JSONObject;
import com.yupi.yuaicodemother.constant.AppConstant;
import dev.langchain4j.agent.tool.P;
import dev.langchain4j.agent.tool.Tool;
import dev.langchain4j.agent.tool.ToolMemoryId;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
/**
* 文件删除工具
* 支持 AI 通过工具调用的方式删除文件
*/
@Slf4j
@Component
public class FileDeleteTool extends BaseTool {
@Tool("删除指定路径的文件")
public String deleteFile(
@P("文件的相对路径")
String relativeFilePath,
@ToolMemoryId Long appId
) {
try {
Path path = Paths.get(relativeFilePath);
if (!path.isAbsolute()) {
String projectDirName = "vue_project_" + appId;
Path projectRoot = Paths.get(AppConstant.CODE_OUTPUT_ROOT_DIR, projectDirName);
path = projectRoot.resolve(relativeFilePath);
}
if (!Files.exists(path)) {
return "警告:文件不存在,无需删除 - " + relativeFilePath;
}
if (!Files.isRegularFile(path)) {
return "错误:指定路径不是文件,无法删除 - " + relativeFilePath;
}
// 安全检查:避免删除重要文件
String fileName = path.getFileName().toString();
if (isImportantFile(fileName)) {
return "错误:不允许删除重要文件 - " + fileName;
}
Files.delete(path);
log.info("成功删除文件: {}", path.toAbsolutePath());
return "文件删除成功: " + relativeFilePath;
} catch (IOException e) {
String errorMessage = "删除文件失败: " + relativeFilePath + ", 错误: " + e.getMessage();
log.error(errorMessage, e);
return errorMessage;
}
}
/**
* 判断是否是重要文件,不允许删除
*/
private boolean isImportantFile(String fileName) {
String[] importantFiles = {
"package.json", "package-lock.json", "yarn.lock", "pnpm-lock.yaml",
"vite.config.js", "vite.config.ts", "vue.config.js",
"tsconfig.json", "tsconfig.app.json", "tsconfig.node.json",
"index.html", "main.js", "main.ts", "App.vue", ".gitignore", "README.md"
};
for (String important : importantFiles) {
if (important.equalsIgnoreCase(fileName)) {
return true;
}
}
return false;
}
@Override
public String getToolName() {
return "deleteFile";
}
@Override
public String getDisplayName() {
return "删除文件";
}
@Override
public String generateToolExecutedResult(JSONObject arguments) {
String relativeFilePath = arguments.getStr("relativeFilePath");
return String.format(" [工具调用] %s %s", getDisplayName(), relativeFilePath);
}
}
java
package com.yupi.yuaicodemother.ai.tools;
import cn.hutool.core.io.FileUtil;
import cn.hutool.core.util.StrUtil;
import cn.hutool.json.JSONObject;
import com.yupi.yuaicodemother.constant.AppConstant;
import dev.langchain4j.agent.tool.P;
import dev.langchain4j.agent.tool.Tool;
import dev.langchain4j.agent.tool.ToolMemoryId;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import java.io.File;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.List;
import java.util.Set;
/**
* 文件目录读取工具
* 使用 Hutool 简化文件操作
*/
@Slf4j
@Component
public class FileDirReadTool extends BaseTool {
/**
* 需要忽略的文件和目录
*/
private static final Set<String> IGNORED_NAMES = Set.of(
"node_modules", ".git", "dist", "build", ".DS_Store",
".env", "target", ".mvn", ".idea", ".vscode", "coverage"
);
/**
* 需要忽略的文件扩展名
*/
private static final Set<String> IGNORED_EXTENSIONS = Set.of(
".log", ".tmp", ".cache", ".lock"
);
@Tool("读取目录结构,获取指定目录下的所有文件和子目录信息")
public String readDir(
@P("目录的相对路径,为空则读取整个项目结构")
String relativeDirPath,
@ToolMemoryId Long appId
) {
try {
Path path = Paths.get(relativeDirPath == null ? "" : relativeDirPath);
if (!path.isAbsolute()) {
String projectDirName = "vue_project_" + appId;
Path projectRoot = Paths.get(AppConstant.CODE_OUTPUT_ROOT_DIR, projectDirName);
path = projectRoot.resolve(relativeDirPath == null ? "" : relativeDirPath);
}
File targetDir = path.toFile();
if (!targetDir.exists() || !targetDir.isDirectory()) {
return "错误:目录不存在或不是目录 - " + relativeDirPath;
}
StringBuilder structure = new StringBuilder();
structure.append("项目目录结构:\n");
// 使用 Hutool 递归获取所有文件
List<File> allFiles = FileUtil.loopFiles(targetDir, file -> !shouldIgnore(file.getName()));
// 按路径深度和名称排序显示
allFiles.stream()
.sorted((f1, f2) -> {
int depth1 = getRelativeDepth(targetDir, f1);
int depth2 = getRelativeDepth(targetDir, f2);
if (depth1 != depth2) {
return Integer.compare(depth1, depth2);
}
return f1.getPath().compareTo(f2.getPath());
})
.forEach(file -> {
int depth = getRelativeDepth(targetDir, file);
String indent = " ".repeat(depth);
structure.append(indent).append(file.getName());
});
return structure.toString();
} catch (Exception e) {
String errorMessage = "读取目录结构失败: " + relativeDirPath + ", 错误: " + e.getMessage();
log.error(errorMessage, e);
return errorMessage;
}
}
/**
* 计算文件相对于根目录的深度
*/
private int getRelativeDepth(File root, File file) {
Path rootPath = root.toPath();
Path filePath = file.toPath();
return rootPath.relativize(filePath).getNameCount() - 1;
}
/**
* 判断是否应该忽略该文件或目录
*/
private boolean shouldIgnore(String fileName) {
// 检查是否在忽略名称列表中
if (IGNORED_NAMES.contains(fileName)) {
return true;
}
// 检查文件扩展名
return IGNORED_EXTENSIONS.stream().anyMatch(fileName::endsWith);
}
@Override
public String getToolName() {
return "readDir";
}
@Override
public String getDisplayName() {
return "读取目录";
}
@Override
public String generateToolExecutedResult(JSONObject arguments) {
String relativeDirPath = arguments.getStr("relativeDirPath");
if (StrUtil.isEmpty(relativeDirPath)) {
relativeDirPath = "根目录";
}
return String.format("[工具调用] %s %s", getDisplayName(), relativeDirPath);
}
}
java
package com.yupi.yuaicodemother.ai.tools;
import cn.hutool.json.JSONObject;
import com.yupi.yuaicodemother.constant.AppConstant;
import dev.langchain4j.agent.tool.P;
import dev.langchain4j.agent.tool.Tool;
import dev.langchain4j.agent.tool.ToolMemoryId;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.StandardOpenOption;
/**
* 文件修改工具
* 支持 AI 通过工具调用的方式修改文件内容
*/
@Slf4j
@Component
public class FileModifyTool extends BaseTool {
@Tool("修改文件内容,用新内容替换指定的旧内容")
public String modifyFile(
@P("文件的相对路径")
String relativeFilePath,
@P("要替换的旧内容")
String oldContent,
@P("替换后的新内容")
String newContent,
@ToolMemoryId Long appId
) {
try {
Path path = Paths.get(relativeFilePath);
if (!path.isAbsolute()) {
String projectDirName = "vue_project_" + appId;
Path projectRoot = Paths.get(AppConstant.CODE_OUTPUT_ROOT_DIR, projectDirName);
path = projectRoot.resolve(relativeFilePath);
}
if (!Files.exists(path) || !Files.isRegularFile(path)) {
return "错误:文件不存在或不是文件 - " + relativeFilePath;
}
String originalContent = Files.readString(path);
if (!originalContent.contains(oldContent)) {
return "警告:文件中未找到要替换的内容,文件未修改 - " + relativeFilePath;
}
String modifiedContent = originalContent.replace(oldContent, newContent);
if (originalContent.equals(modifiedContent)) {
return "信息:替换后文件内容未发生变化 - " + relativeFilePath;
}
Files.writeString(path, modifiedContent, StandardOpenOption.CREATE, StandardOpenOption.TRUNCATE_EXISTING);
log.info("成功修改文件: {}", path.toAbsolutePath());
return "文件修改成功: " + relativeFilePath;
} catch (IOException e) {
String errorMessage = "修改文件失败: " + relativeFilePath + ", 错误: " + e.getMessage();
log.error(errorMessage, e);
return errorMessage;
}
}
@Override
public String getToolName() {
return "modifyFile";
}
@Override
public String getDisplayName() {
return "修改文件";
}
@Override
public String generateToolExecutedResult(JSONObject arguments) {
String relativeFilePath = arguments.getStr("relativeFilePath");
String oldContent = arguments.getStr("oldContent");
String newContent = arguments.getStr("newContent");
// 显示对比内容
return String.format("""
[工具调用] %s %s
替换前:
```
%s
```
替换后:
```
%s
```
""", getDisplayName(), relativeFilePath, oldContent, newContent);
}
}
java
package com.yupi.yuaicodemother.ai.tools;
import cn.hutool.json.JSONObject;
import com.yupi.yuaicodemother.constant.AppConstant;
import dev.langchain4j.agent.tool.P;
import dev.langchain4j.agent.tool.Tool;
import dev.langchain4j.agent.tool.ToolMemoryId;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
/**
* 文件读取工具
* 支持 AI 通过工具调用的方式读取文件内容
*/
@Slf4j
@Component
public class FileReadTool extends BaseTool {
@Tool("读取指定路径的文件内容")
public String readFile(
@P("文件的相对路径")
String relativeFilePath,
@ToolMemoryId Long appId
) {
try {
Path path = Paths.get(relativeFilePath);
if (!path.isAbsolute()) {
String projectDirName = "vue_project_" + appId;
Path projectRoot = Paths.get(AppConstant.CODE_OUTPUT_ROOT_DIR, projectDirName);
path = projectRoot.resolve(relativeFilePath);
}
if (!Files.exists(path) || !Files.isRegularFile(path)) {
return "错误:文件不存在或不是文件 - " + relativeFilePath;
}
return Files.readString(path);
} catch (IOException e) {
String errorMessage = "读取文件失败: " + relativeFilePath + ", 错误: " + e.getMessage();
log.error(errorMessage, e);
return errorMessage;
}
}
@Override
public String getToolName() {
return "readFile";
}
@Override
public String getDisplayName() {
return "读取文件";
}
@Override
public String generateToolExecutedResult(JSONObject arguments) {
String relativeFilePath = arguments.getStr("relativeFilePath");
return String.format("[工具调用] %s %s", getDisplayName(), relativeFilePath);
}
}
java
package com.yupi.yuaicodemother.ai.tools;
import cn.hutool.core.io.FileUtil;
import cn.hutool.json.JSONObject;
import com.yupi.yuaicodemother.constant.AppConstant;
import dev.langchain4j.agent.tool.P;
import dev.langchain4j.agent.tool.Tool;
import dev.langchain4j.agent.tool.ToolMemoryId;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.StandardOpenOption;
/**
* 文件写入工具
* 支持 AI 通过工具调用的方式写入文件
*/
@Slf4j
@Component
public class FileWriteTool extends BaseTool {
@Tool("写入文件到指定路径")
public String writeFile(
@P("文件的相对路径")
String relativeFilePath,
@P("要写入文件的内容")
String content,
@ToolMemoryId Long appId
) {
try {
Path path = Paths.get(relativeFilePath);
if (!path.isAbsolute()) {
// 相对路径处理,创建基于 appId 的项目目录
String projectDirName = "vue_project_" + appId;
Path projectRoot = Paths.get(AppConstant.CODE_OUTPUT_ROOT_DIR, projectDirName);
path = projectRoot.resolve(relativeFilePath);
}
// 创建父目录(如果不存在)
Path parentDir = path.getParent();
if (parentDir != null) {
Files.createDirectories(parentDir);
}
// 写入文件内容
Files.write(path, content.getBytes(),
StandardOpenOption.CREATE,
StandardOpenOption.TRUNCATE_EXISTING);
log.info("成功写入文件: {}", path.toAbsolutePath());
// 注意要返回相对路径,不能让 AI 把文件绝对路径返回给用户
return "文件写入成功: " + relativeFilePath;
} catch (IOException e) {
String errorMessage = "文件写入失败: " + relativeFilePath + ", 错误: " + e.getMessage();
log.error(errorMessage, e);
return errorMessage;
}
}
@Override
public String getToolName() {
return "writeFile";
}
@Override
public String getDisplayName() {
return "写入文件";
}
@Override
public String generateToolExecutedResult(JSONObject arguments) {
String relativeFilePath = arguments.getStr("relativeFilePath");
String suffix = FileUtil.getSuffix(relativeFilePath);
String content = arguments.getStr("content");
return String.format("""
[工具调用] %s %s
```%s
%s
```
""", getDisplayName(), relativeFilePath, suffix, content);
}
}
java
package com.yupi.yuaicodemother.ai.tools;
import jakarta.annotation.PostConstruct;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import java.util.HashMap;
import java.util.Map;
/**
* 工具管理器
* 统一管理所有工具,提供根据名称获取工具的功能
*/
@Slf4j
@Component
public class ToolManager {
/**
* 工具名称到工具实例的映射
*/
private final Map<String, BaseTool> toolMap = new HashMap<>();
/**
* 自动注入所有工具
*/
@Resource
private BaseTool[] tools;
/**
* 初始化工具映射
*/
@PostConstruct
public void initTools() {
for (BaseTool tool : tools) {
toolMap.put(tool.getToolName(), tool);
log.info("注册工具: {} -> {}", tool.getToolName(), tool.getDisplayName());
}
log.info("工具管理器初始化完成,共注册 {} 个工具", toolMap.size());
}
/**
* 根据工具名称获取工具实例
*
* @param toolName 工具英文名称
* @return 工具实例
*/
public BaseTool getTool(String toolName) {
return toolMap.get(toolName);
}
/**
* 获取已注册的工具集合
*
* @return 工具实例集合
*/
public BaseTool[] getAllTools() {
return tools;
}
}这些工具如果给ai写那提示词该怎么写:
- Vue 项目结构生成工具(VueProjectStructureTool)
java
## 工具名称:VueProjectStructureTool
### 工具描述
初始化Vue3项目的标准目录结构,生成项目所需的所有文件夹,是Vue项目生成的第一步必须调用的工具。
### 调用条件
当用户需求是生成完整的Vue3/Vue3+TypeScript项目时,必须优先调用本工具,再调用其他工具生成具体文件。
### 参数规范
{
"projectRoot": "必填,字符串,项目根目录名称,固定为用户的deployKey,例如 test-vue-shop-123",
"dirs": "必填,字符串数组,要生成的目录路径,相对于项目根目录,例如 ["src", "src/pages", "src/components", "src/router", "src/assets", "src/stores"]
}
### 返回格式
调用成功返回:"已成功创建Vue项目目录结构:\n- test-vue-shop-123/src\n- test-vue-shop-123/src/pages\n..."
### 错误处理
- projectRoot为空:返回「错误:VueProjectStructureTool调用失败,projectRoot不能为空」
- dirs为空:返回「错误:VueProjectStructureTool调用失败,dirs不能为空」
- 目录创建失败:返回「错误:目录创建失败,失败原因:xxx」- 项目配置文件生成工具(ProjectConfigFileTool)
java
## 工具名称:ProjectConfigFileTool
### 工具描述
生成Vue项目的核心配置文件,包括package.json、vite.config.ts、tsconfig.json、index.html等项目启动/打包必须的配置文件。
### 调用条件
Vue项目目录结构创建完成后,调用本工具生成项目配置文件,之后再生成页面/组件文件。
### 参数规范
{
"projectRoot": "必填,字符串,项目根目录名称,和VueProjectStructureTool的projectRoot保持一致",
"fileName": "必填,字符串,要生成的配置文件名,例如 package.json、vite.config.ts、index.html",
"fileContent": "必填,字符串,配置文件的完整内容,必须是可直接使用的标准配置,不能有语法错误"
}
### 返回格式
调用成功返回:"已成功生成配置文件:[projectRoot]/[fileName]"
### 错误处理
- 任一必填参数为空:返回「错误:ProjectConfigFileTool调用失败,projectRoot、fileName、fileContent均不能为空」
- 文件写入失败:返回「错误:配置文件写入失败,失败原因:xxx」- Vue 单文件组件生成工具(VueSingleFileCreateTool)
java
## 工具名称:VueSingleFileCreateTool
### 工具描述
生成Vue3单文件组件(.vue),包括页面组件、公共组件,支持 <script setup lang="ts"> 语法。
### 调用条件
需要生成Vue项目的页面、组件时调用,例如首页、导航栏组件、商品列表组件等。
### 参数规范
{
"projectRoot": "必填,字符串,项目根目录名称",
"filePath": "必填,字符串,文件的相对路径,例如 src/pages/HomePage.vue、src/components/NavBar.vue",
"template": "必填,字符串,Vue组件的<template>模板内容,必须是符合Vue3规范的HTML结构",
"script": "必填,字符串,Vue组件的<script setup>脚本内容,支持TypeScript",
"style": "可选,字符串,Vue组件的<style>样式内容,默认添加 scoped 属性"
}
### 返回格式
调用成功返回:"已成功生成Vue组件文件:[projectRoot]/[filePath]"
### 错误处理
- 任一必填参数为空:返回「错误:VueSingleFileCreateTool调用失败,projectRoot、filePath、template、script均不能为空」
- 文件写入失败:返回「错误:Vue组件文件写入失败,失败原因:xxx」- Vue 路由配置生成工具(VueRouterConfigTool)
java
## 工具名称:VueRouterConfigTool
### 工具描述
生成Vue Router的路由配置文件,定义页面路径和组件的映射关系,支持History模式。
### 调用条件
Vue项目的页面组件生成完成后,需要配置页面路由时调用。
### 参数规范
{
"projectRoot": "必填,字符串,项目根目录名称",
"filePath": "必填,字符串,路由文件的相对路径,固定为 src/router/index.ts",
"routes": "必填,数组,路由配置列表,每个项包含:path(路由路径)、name(路由名称)、componentPath(组件的相对路径,例如 @/pages/HomePage.vue)、title(页面标题,可选)"
}
### 返回格式
调用成功返回:"已成功生成Vue路由配置文件:[projectRoot]/[filePath],配置的路由:\n- / -> HomePage.vue\n..."
### 错误处理
- 任一必填参数为空:返回「错误:VueRouterConfigTool调用失败,projectRoot、filePath、routes均不能为空」
- 文件写入失败:返回「错误:路由配置文件写入失败,失败原因:xxx」- 通用文件写入工具(CommonFileWriteTool)
java
## 工具名称:CommonFileWriteTool
### 工具描述
通用的文件写入工具,用于生成上述工具未覆盖的其他类型文件,例如工具类、全局样式文件、状态管理文件、静态资源声明文件等。
### 调用条件
需要生成的文件不属于配置文件、Vue组件、路由配置时,调用本工具。
### 参数规范
{
"projectRoot": "必填,字符串,项目根目录名称",
"filePath": "必填,字符串,文件的相对路径,例如 src/utils/request.ts、src/assets/global.css",
"fileContent": "必填,字符串,文件的完整内容,必须符合对应文件类型的语法规范"
}
### 返回格式
调用成功返回:"已成功生成文件:[projectRoot]/[filePath]"
### 错误处理
- 任一必填参数为空:返回「错误:CommonFileWriteTool调用失败,projectRoot、filePath、fileContent均不能为空」
- 文件写入失败:返回「错误:文件写入失败,失败原因:xxx」- 文件读取工具(FileReadTool)
java
## 工具名称:FileReadTool
### 工具描述
读取项目中已存在的文件内容,用于用户修改、编辑已有代码的场景。
### 调用条件
用户需要修改已生成的代码,需要先读取原有文件内容时调用。
### 参数规范
{
"projectRoot": "必填,字符串,项目根目录名称",
"filePath": "必填,字符串,要读取的文件相对路径,例如 src/pages/HomePage.vue"
}
### 返回格式
调用成功返回:"文件 [filePath] 的内容如下:\n[文件完整内容]"
### 错误处理
- 参数为空:返回「错误:FileReadTool调用失败,projectRoot、filePath均不能为空」
- 文件不存在:返回「错误:文件 [projectRoot]/[filePath] 不存在,无法读取」- HTML 单页面生成工具(HtmlPageGenerateTool)
java
## 工具名称:HtmlPageGenerateTool
### 工具描述
生成单个完整的HTML页面文件,包含HTML结构、内联CSS、内联JavaScript,无需依赖构建工具,可直接在浏览器打开。
### 调用条件
用户需求是生成单HTML页面、静态页面,无需Vue/React框架时调用,无需配合其他工具,直接生成完整文件。
### 参数规范
{
"projectRoot": "必填,字符串,项目根目录名称",
"fileName": "必填,字符串,生成的文件名,固定为 index.html",
"htmlContent": "必填,字符串,完整的HTML5文件内容,包含DOCTYPE、html、head、body标签,内嵌CSS和JS,保证可直接运行"
}
### 返回格式
调用成功返回:"已成功生成HTML单页面文件:[projectRoot]/[fileName]"
### 错误处理
- 任一必填参数为空:返回「错误:HtmlPageGenerateTool调用失败,projectRoot、fileName、htmlContent均不能为空」
- 文件写入失败:返回「错误:HTML文件写入失败,失败原因:xxx」11.此项目架构最最最重要
统一示例约定:
- 项目:
yu-ai-code-motherSpringBoot 单体项目 - 端口:
8123,接口统一前缀/api - 测试用户:userId=1,创建应用 appId=1001,唯一部署标识
deployKey=test-vue-shop-123 - 固定根目录:
CODE_OUTPUT_ROOT_DIR = D:/yu-ai-code/output(源码生成目录)、DEPLOY_ROOT_DIR = D:/yu-ai-code/deploy(静态部署目录)、TEMP_DIR = D:/yu-ai-code/temp(临时文件目录)
步骤 1:前置操作 - 用户注册登录
- 用户操作:打开平台前端,完成注册→账号登录
- 对应接口 :
POST /api/user/register(注册)POST /api/user/login(登录)
- 核心类 :
UserController、UserService - 执行逻辑 :
- 校验用户提交的账号密码,完成注册 / 登录校验
- 生成用户登录态(Redis Session),返回用户信息
- 后续所有接口都会校验登录态,保证多租户隔离(用户只能操作自己的应用)
步骤 2:创建应用(生成核心标识,所有流程的基础)
- 用户操作:登录后点击「新建应用」,填写应用名称「Vue3 电商首页项目」,点击确认创建
- 对应接口 :
POST /api/app/add - 核心类 :
AppController、AppService - 执行逻辑 & 生成内容 :
- 校验用户登录态,获取当前用户 userId=1
- 生成全局唯一的
appId=1001、deployKey=test-vue-shop-123(后续部署、静态访问的唯一标识) - 初始化应用数据:应用名称、所属用户 ID、deployKey、生成状态(未生成)、部署状态(未部署)、封面 URL(空)、创建时间
- 将应用信息持久化到 MySQL 的
app表 - 向前端返回 appId、,前端跳转到应用的代码生成 / 编辑页面
步骤 3:核心环节 - AI 生成代码(含流式输出、工具调用、代码持久化)
- 用户操作:在应用编辑页,输入需求「生成一个 Vue3 电商首页项目,包含导航栏、轮播图、商品列表、购物车入口,用 TypeScript+Ant Design Vue」,点击「生成代码」
- 对应接口 :
POST /api/ai/code/generate/stream(SSE 流式接口,实时返回生成过程) - 核心类 :
AiCodeController、AiCodeGeneratorFacade、AiCodeGeneratorService、ToolManager、CodeFileSaverExecutor - 完整执行流程 :
- 权限 & 参数校验:接口接收 appId、用户 prompt,校验该应用是否属于当前登录用户,防止越权操作
- 路由生成类型 :
AiCodeGenTypeRoutingService分析用户需求,判定为「Vue 完整项目生成」,启用工具调用能力(单 HTML 生成无需工具,直接流式输出) - 构建 AI 服务实例 :
AiCodeGeneratorServiceFactory通过appId+生成类型,创建 / 从 Caffeine 本地缓存获取 AI 服务实例- 加载该 appId 对应的对话历史记忆(Redis 存储,首次生成则为空)
- 加载「Vue 项目生成专用系统提示词」(定义了可用工具、调用规则、代码规范)
- 绑定流式大模型实例、
ToolManager(统一管理所有可调用工具)
- 流式生成 + 工具调用循环(核心) :
- 第一轮:AI 接收需求 + 系统提示词,判定需先初始化项目结构,返回工具调用指令,调用【Vue 项目结构生成工具】
- 后端
ToolManager解析工具调用请求,执行对应工具,生成项目目录结构,写入本地磁盘,将执行结果返回给 AI - 第二轮:AI 收到工具执行成功的结果,判定需生成项目依赖配置,调用【项目配置文件生成工具】,生成
package.json、vite.config.ts等配置文件 - 后端执行工具,写入文件,返回执行结果给 AI
- 第三轮:AI 判定需生成首页核心组件,调用【Vue 单文件组件生成工具】,生成
HomePage.vue、NavBar.vue、Banner.vue等页面 / 组件文件 - 后端执行工具,写入文件,返回结果
- 第四轮:AI 判定需配置页面路由,调用【Vue 路由配置生成工具】,生成
router/index.ts路由文件 - 后端执行工具,写入文件,返回结果
- 循环执行:直到所有需要的文件生成完成,AI 判定生成结束,退出工具调用循环(最多允许 20 次连续调用,防止死循环)
- 实时流式输出:整个过程中,AI 的思考过程、工具调用动作、生成的代码片段,都会通过 SSE 流式推送给前端,前端实时展示给用户,用户可直观看到 AI 的执行进度
- 代码持久化保存 :生成完成后,
CodeFileSaverExecutor将所有生成的文件,按目录结构完整写入本地源码目录- 源码根路径:
D:/yu-ai-code/output/test-vue-shop-123/ - 生成的完整目录结构:
- 源码根路径:
java
test-vue-shop-123/
├─ package.json
├─ index.html
├─ vite.config.ts
├─ tsconfig.json
└─ src/
├─ main.ts
├─ App.vue
├─ pages/
│ └─ HomePage.vue
├─ router/
│ └─ index.ts
├─ components/
│ ├─ NavBar.vue
│ ├─ Banner.vue
│ └─ GoodsList.vue
└─ assets/
└─ logo.png- 7.更新应用状态 :
AppService更新app表中 appId=1001 的记录,将生成状态改为「已生成」,更新代码生成时间 - 8.持久化对话记忆:将本次生成的对话历史、AI 思考过程、工具调用记录存入 Redis,方便后续用户编辑修改时,AI 能保留上下文
步骤 4:核心环节 - 一键部署(含 npm install、build、文件部署)
- 用户操作:代码生成完成后,点击页面上的「一键部署」按钮
- 对应接口 :
POST /api/app/deploy?appId=1001 - 核心类 :
AppController、DeployService、CommandExecutorUtil、FileUtil - 完整执行流程 :
- 权限 & 状态校验:接口接收 appId,校验用户权限,确认应用属于当前用户,且代码已生成
- 状态锁定:更新应用的部署状态为「部署中」,防止用户重复点击触发并发部署问题
- 定位源码目录 :获取应用的 deployKey,定位到源码根路径
D:/yu-ai-code/output/test-vue-shop-123/ - 第一步:执行 npm install 安装依赖
- 调用
CommandExecutorUtil(系统命令执行工具),进入源码目录,执行npm install命令 - 自动下载
package.json中定义的所有依赖(Vue3、TypeScript、Ant Design Vue、vite 等) - 生成
node_modules依赖文件夹(路径:D:/yu-ai-code/output/test-vue-shop-123/node_modules/)、package-lock.json依赖版本锁定文件 - 实时捕获命令执行日志,若安装报错(如依赖冲突、网络问题),立即终止部署,返回部署失败,将错误信息返回给前端
- 调用
- 第二步:执行 npm run build 打包构建
-
依赖安装成功后,继续在源码目录执行
npm run build命令 -
调用 vite 打包工具,将 Vue 源码编译、压缩、Tree-Shaking,生成浏览器可直接运行的静态产物
-
打包完成后,自动生成
dist产物目录(路径:D:/yu-ai-code/output/test-vue-shop-123/dist/) -
dist 目录的最终产物结构: plaintext
dist/ ├─ index.html(项目唯一入口文件) └─ assets/ ├─ index-abc123def.js(打包后的JS脚本,带哈希防缓存) ├─ index-456xyz78.css(打包后的样式文件) └─ logo-hash.png(静态图片资源) -
若打包报错(如语法错误、路径错误),立即捕获异常,返回部署失败,更新部署状态为「部署失败」
-
- 第三步:部署产物到正式访问目录
- 打包成功后,调用
FileUtil,将dist目录内的所有文件,完整复制到「静态资源部署根目录」 - 目标部署路径:
D:/yu-ai-code/deploy/test-vue-shop-123/ - 复制完成后,该目录内的文件和 dist 目录完全一致,是后续静态接口读取的唯一目录
- 打包成功后,调用
- 更新部署状态 :
AppService更新app表记录,将部署状态改为「已部署」,更新部署时间、预览地址(/api/static/test-vue-shop-123/) - 返回结果:向前端返回部署成功结果,前端展示「部署成功」,显示预览按钮、生成封面按钮
步骤 5:生成封面截图(含页面访问、截图、压缩、COS 上传)
- 用户操作:部署成功后,点击「生成封面」按钮,或系统自动触发截图
- 对应接口 :
POST /api/app/screenshot?appId=1001 - 核心类 :
AppController、ScreenshotService、BrowserUtil、ImageCompressUtil、CosService - 完整执行流程 :
- 权限 & 状态校验:接收 appId,校验用户权限,确认应用已完成部署
- 拼接预览地址 :从数据库获取 deployKey,拼接出静态页面的完整访问地址:
http://localhost:8123/api/static/test-vue-shop-123/ - 启动无头浏览器 :调用
BrowserUtil(封装 Playwright/Puppeteer),启动无头浏览器,访问上面的预览地址 - 等待页面渲染:等待页面完全加载(等待 Vue 代码执行完成、DOM 渲染完毕,默认等待 300ms 或等待 #app 元素加载完成),保证截图完整
- 生成临时截图文件 :对页面进行全屏截图,生成原始 PNG 截图,保存到本地临时目录:
D:/yu-ai-code/temp/test-vue-shop-123-origin.png - 释放资源:截图完成后,立即关闭无头浏览器,释放服务器资源
- 图片压缩 :调用
ImageCompressUtil,将原始 PNG 截图压缩为 JPG 格式,大幅缩小文件体积,压缩后的文件路径:D:/yu-ai-code/temp/test-vue-shop-123-compressed.jpg - 上传到腾讯云 COS :调用
CosService,将压缩后的截图上传到 COS,COS 内的存储路径为/screenshots/2026/03/14/test-vue-shop-123-abc123.jpg - 获取公网 URL :COS 上传成功后,返回图片的公网永久访问地址,例如:
https://yu-ai-code.cos.ap-beijing.myqcloud.com/screenshots/2026/03/14/test-vue-shop-123-abc123.jpg - 清理临时文件 :在
finally代码块中,强制删除临时目录内的原始截图、压缩后截图,无论上传成功 / 失败,都不会残留垃圾文件占用服务器磁盘 - 更新数据库 :
AppService将 COS 公网 URL,更新到app表对应记录的cover封面字段 - 返回结果:向前端返回截图成功结果,前端刷新页面,展示生成的应用封面图
步骤 6:应用预览(静态资源接口完整执行流程)
- 用户操作:部署成功后,点击「预览应用」,前端打开新标签页,访问应用预览地址
- 访问地址 :
http://localhost:8123/api/static/test-vue-shop-123/ - 对应接口 :
GET /api/static/{deployKey}/**(就是你之前贴的StaticResourceController) - 核心类 :
StaticResourceController - 完整执行流程 :
- 浏览器发起请求,请求打到 SpringBoot 的
StaticResourceController - 接口解析路径参数,获取
deployKey=test-vue-shop-123,以及通配符匹配的资源路径(本次为/,即根路径) - 目录重定向处理 :若访问路径不带末尾的
/,自动返回 301 重定向到带/的地址,保证页面内的相对路径资源能正常加载 - 默认入口文件匹配 :若访问的是根路径
/,自动映射到index.html入口文件 - 拼接本地文件路径 :用「部署根目录 + deployKey + 资源路径」,拼接出完整的本地文件路径:
D:/yu-ai-code/deploy/test-vue-shop-123/index.html - 文件存在性校验 :若文件 / 目录不存在,直接返回
404 Not Found - 设置正确的 Content-Type :调用
getContentTypeWithCharset方法,根据文件后缀设置正确的 MIME 类型,例如:.html文件:text/html; charset=UTF-8.js文件:application/javascript; charset=UTF-8.css文件:text/css; charset=UTF-8- 图片文件:对应图片 MIME 类型彻底避免中文乱码、浏览器解析错误的问题
- 返回文件资源 :将本地文件包装为
FileSystemResource,返回给浏览器 - 浏览器加载后续资源 :浏览器解析
index.html后,发现需要加载assets/内的 JS、CSS、图片资源,自动发起新的请求 - 静态接口处理资源请求 :浏览器请求
http://localhost:8123/api/static/test-vue-shop-123/assets/index-abc123def.js,接口重复上述流程,找到本地对应的 JS 文件,返回给浏览器 - 页面渲染完成:浏览器加载完所有资源后,执行 Vue 代码,渲染出完整的电商首页,用户可正常查看、交互
- 浏览器发起请求,请求打到 SpringBoot 的
补充:配套的其他核心操作
- 代码编辑:用户可在前端编辑生成的代码,点击保存后,调用接口更新本地源码文件,之后可重新部署
- 源码下载:用户点击「下载源码」,接口将源码目录打包为 ZIP 文件,返回给浏览器下载
- 应用管理:用户可在个人中心查看自己的所有应用,修改应用名称、删除应用、重新生成 / 部署