微调Qwen3.5-0.8B实现新闻分类
🐬 目录:
一、任务描述

AG News Dataset 拥有超过 100 万篇新闻文章,其中包含 496,835 条 AG 新闻语料库中超过 2000 个新闻源的文章,每种类别均拥有 30,000 个训练样本和 1900 个测试样本。本任务旨在利用 AG News 数据集,对 Qwen3.5-0.8B 模型进行监督微调(Supervised Fine-Tuning, SFT),使其成为一个高效的新闻主题分类器。模型需具备接收新闻标题和正文描述后,准确将其归类到四个预定义类别之一的能力。
分类体系(4类):
🌐World (世界新闻)
🎾Sports (体育新闻)
💴Business (商业财经)
✈️Sci/Tech (科技科学)
二、模型介绍
Qwen3.5-0.8B 是阿里巴巴通义千问团队于2026年3月最新发布的轻量级大语言模型,属于Qwen3.5小模型全家桶(包括0.8B, 2B, 4B, 9B四个版本)中的极致轻量版。
🔖核心规格与架构
👻参数量 :约0.8 Billion (8亿)参数。
👻模型体积 :全精度权重文件约为 1.7 GB,量化后(如 INT4/GGUF)可压缩至 500MB - 600MB 左右,极易部署。
👻上下文窗口 :支持 256K 超长上下文,这在同体量小模型中极为罕见,使其能够处理长文档或长对话历史而不丢失信息。
👻架构升级 :继承了 Qwen3.5 系列的先进架构,相比前代 Qwen3-0.6B,其配置文件扩展了约4倍,引入了更高效的注意力机制和混合专家(MoE)思想的轻量化变体(具体架构细节视官方技术报告而定,但已知其推理效率显著提升)。
👻原生多模态潜力 :虽然 0.8B 版本主要聚焦文本,但其架构设计预留了多模态接口(配置文件包含视觉/视频预处理配置),为未来端侧多模态应用打下基础。
👻分词器:采用扩展版分词器(vocab 约 13M+),支持全球 100+ 种语言的高精度 Tokenization,对中文、英文及代码片段有极好的兼容性。
三、代码实现
1️⃣ 模型配置
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
model_id = 'Qwen/Qwen3.5-0.8B'
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type='nf4',
bnb_4bit_compute_dtype=torch.bfloat16
)
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config,
device_map='auto',
dtype=torch.bfloat16
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token = tokenizer.eos_token
model.config.pad_token_id = tokenizer.eos_token_id
model.generation_config.pad_token_id = tokenizer.eos_token_id🍄配置轻量化的模型,其中BitAndBytesConfig中的参数:
load_in_4bit--启用 4-bit 量化加载。模型权重将从默认的 16-bit (float16/bfloat16) 或 32-bit 压缩到 4-bit,显存占用减少约 75%。
bnb_4bit_quant_type='nf4'--使用 Normal Float 4 (NF4) 数据类型。这是一种专门为神经网络权重分布设计的量化格式,相比标准的 int4,它能更好地保留权重的统计特性,从而在极低精度下保持更高的模型性能。
bnb_4bit_compute_dtype=torch.bfloat16--指定在进行矩阵乘法等计算时,将量化后的权重临时解量化为 bfloat16 精度。这能在保持低显存占用的同时,利用现代 GPU(如 Ampere 架构及以后)对 bfloat16 的加速支持,保证计算稳定性。
🍄设置Padding Token
tokenizer.pad_token = tokenizer.eos_token
许多大模型(包括早期的 Qwen 版本或 Llama 系列)在配置文件中可能没有明确定义 pad_token(填充令牌),或者将其设为 None。但在进行批量训练(Batch Training)或推理时,必须将不同长度的句子填充到同一长度,这就需要 pad_token。此处将pad_token设置为 eos_token(End of Sequence,结束符)。这是一个常见的做法,意味着用"句子结束符"来填充空白位置。
🍄同步模型配置中的Padding Token ID
model.config.pad_token_id = tokenizer.eos_token_id
model.generation_config.pad_token_id = tokenizer.eos_token_id
model.config.pad_token_id: 更新模型基础配置对象 中的 pad_token_id。
model.generation_config.pad_token_id: 更新模型生成配置对象中的 pad_token_id
2️⃣加载数据
from datasets import load_dataset
dataset = load_dataset('ag_news')
train_dataset = dataset['train'].select(range(2500))
test_dataset = dataset['test'].select(range(200)从Hugging Face Hub下载并加载名为ag_news数据集,截取训练集前3000条作为训练数据,测试集前200条新闻用于评估模型效果
3️⃣新闻分类(微调前)
🕜 对单个样本进行分类预测
import torch
import re
#1. 构造输入Qwen2.5-0.8B的提示词
labels = ['World','Sports','Business','Sci/Tech']
def build_prompt(text):
return f"""
Classify the news article.
Article:
{text}
Return ONLY the number of the correct label.
0 = World
1 = Sports
2 = Business
3 = Sci/Tech
Answer:
"""
#2. 取一个样本进行分类预测
sample = train_dataset[10]
sample_text = sample["text"]
sample_label = sample["label"]
#3. 从输出中提取预测结果
def extract_label(text):
# Remove reasoning blocks if present
text = re.sub(r"<think>.*?</think>", "", text, flags=re.DOTALL) # 把 <think> 到 </think> 之间的所有内容(包括换行符)全部删掉。
# Find the last digit 0--3
matches = re.findall(r"[0-3]", text)
if matches:
return int(matches[-1])
return -1
#4. 使用大模型进行预测
prompt = build_prompt(sample_text)
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
with torch.inference_mode():
outputs = model.generate(
**inputs,
max_new_tokens=5,
do_sample=False,
pad_token_id=tokenizer.eos_token_id
)
prediction = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("Model prediction (before training):")
print(sample_text)
print(extract_label(prediction))得到单个样本的预测结果:
Model prediction (before training):
Oil and Economy Cloud Stocks' Outlook NEW YORK (Reuters) - Soaring crude prices plus worries about the economy and the outlook for earnings are expected to hang over the stock market next week during the depth of the summer doldrums.
2
🕜 对测试样本进行分类预测
from sklearn.metrics import accuracy_score, f1_score
from tqdm.notebook import tqdm
def evaluate_model(dataset):
preds = []
refs = []
model.eval()
for example in tqdm(dataset):
text = example["text"]
label = example["label"]
prompt = build_prompt(text)
inputs = tokenizer(prompt, return_tensors="pt", truncation=True)
inputs = {k: v.to("cuda") for k, v in inputs.items()}
with torch.inference_mode():
outputs = model.generate(
**inputs,
max_new_tokens=5,
do_sample=False,
pad_token_id=tokenizer.eos_token_id
)
prediction = tokenizer.decode(outputs[0], skip_special_tokens=True)
pred_label = extract_label(prediction)
preds.append(pred_label)
refs.append(label)
acc = accuracy_score(refs, preds)
f1 = f1_score(refs, preds, average="weighted")
print("Accuracy:", acc)
print("F1:", f1)
print('Pre‑fine‑tuning evaluation')
evaluate_model(test_dataset)得到微调前的预测结果:
Accuracy: 0.52
F1: 0.45889163289429247
4️⃣使用Lora微调
# 1. 训练数据准备
from peft import LoraConfig, get_peft_model
from trl import SFTTrainer, SFTConfig
from transformers import TrainingArguments
def format_train(example):
prompt = build_prompt(example['text'])
answer = str(example['label'])
return {'text': prompt + ' ' + answer}
train_dataset = train_dataset.map(format_train)
#2. 配置Lora
lora_config = LoraConfig(
r=16, #Lora矩阵的秩,决定新增可训练参数数量。r越大,参数量越多,模型能学到的特征越复杂
lora_alpha=16, #缩放系数
lora_dropout=0,
bias='none',
task_type='CAUSAL_LM',
target_modules=[ #目标层
'q_proj','k_proj','v_proj','o_proj',
'gate_proj','up_proj','down_proj'
]
)
#3. 训练参数设置
training_args = SFTConfig(
output_dir="./qwen35-lora",
per_device_train_batch_size=8,
gradient_accumulation_steps=2,
learning_rate=2e-4,
num_train_epochs=1,
logging_steps=10,
bf16=True,
dataset_text_field="text", #告诉训练器,你的数据集中哪一列包含实际的文本内容。
packing=False, #是否开启 样本打包
)
#4. 模型微调
trainer = SFTTrainer(
model=model,
train_dataset=train_dataset,
peft_config=lora_config,
args=training_args,
processing_class=tokenizer
)
trainer.train()
#5. 保存权重
trainer.model.save_pretrained("qwen35-small-news-class")
tokenizer.save_pretrained("qwen35-small-news-class")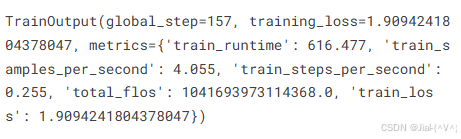
5️⃣新闻分类(微调后)
from transformers import AutoModelForCausalLM
from peft import PeftModel
#1. 加载基础模型
base_model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
dtype=torch.bfloat16
)
#2. 加载权重
model = PeftModel.from_pretrained(
base_model,
"./qwen35-small-news-class"
)
model.eval()
#3. 测试分类效果
evaluate_model(test_dataset)微调后的测试结果:
Accuracy: 0.865
F1: 0.8660926258753361