这是我的专栏《春哥的Agent通关秘籍》系列文章的第20篇。
希望系统性跟着我一起学AI-Agent编码的同学可以关注一下我的这个专栏。

在前面的第14课里,我们从概念上聊过,记忆是Agent开发的核心。
这节课我们将从头开始理解并手撕两个Agent记忆处理最高频最核心的场景:
- 信息提取
- 记忆压缩
市面上主流的Agent基本都涉及到以上两个场景,整明白之后你也可以在自己的Agent开发中对记忆处理游刃有余。
一、信息提取
信息并不直接体现在文字表面,它极度依赖上下文,以及解读者的理解水平。
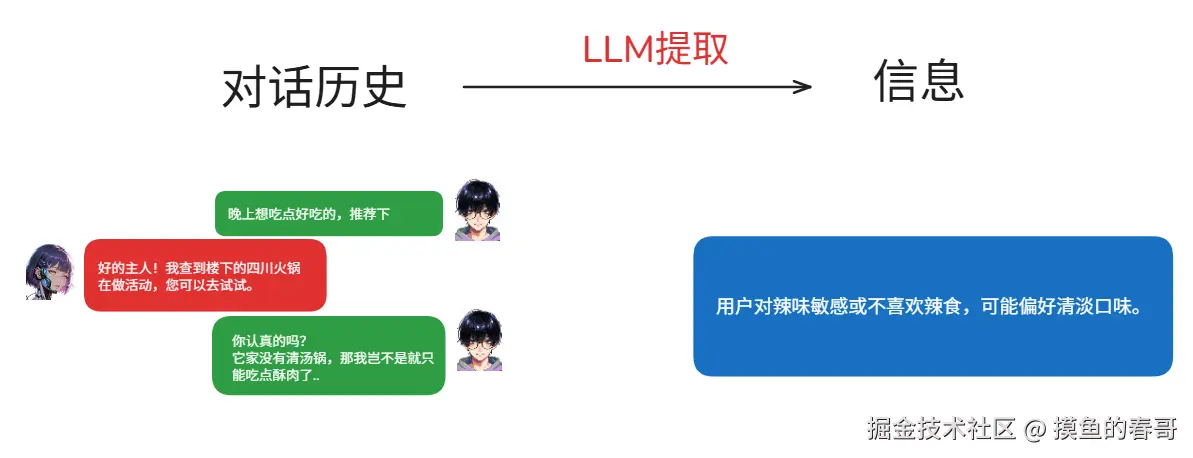
假设,小李和他的AI助理"梦姬"发生如下对话:

你能从上面的对话里找到关于小李的什么信息?
如果只关注小李本身的输入,以及其文本内容,我们很容易只提取到:"小李喜欢吃酥肉"这种错误的结论。
但以上对话的真正隐含的重要喜好信息其实是:小李怕辣。
因此,在用户和Agent产生实际对话时,我们需要把 Agent 和 用户 的对话历史放在一起,配合合理的系统提示词,才能提取到足够有效的信息,
假设,我们现在组装了如下提示词,并通过API调用LLM,
markdown
【系统提示词】: 你是一个专业的信息提取专家,擅长从多轮对话的"言外之意"中,精准捕捉目标人物的隐性特征。
【用户提示词】: 以下为对话内容:
- User:晚上想吃点好吃的,推荐下
- Assistant: 好的主人!我查到楼下的四川火锅在做活动,您可以去试试。
- User: 你认真的吗?它家没有清汤锅,那我岂不是就只能吃点酥肉了..我使用 langchain + deepseek 撰写了 demo,当然用其他任何框架和工具都行。
这个demo的代码我放在了这里:github.com/zhangshichu...
运行该脚本,LLM会输出如下一句话:
md
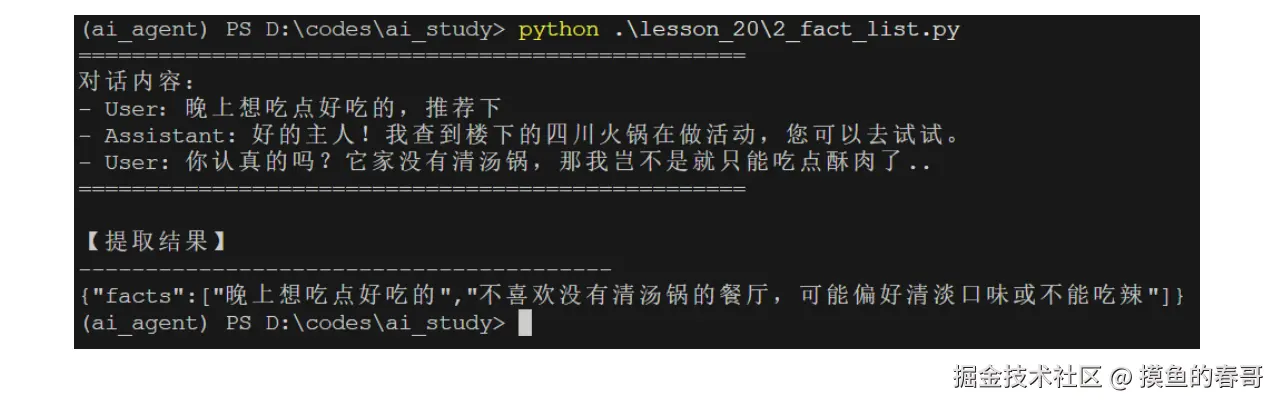
用户对辣味敏感或不喜欢辣食,可能偏好清淡口味。这样,我们就完成了最基础的信息提取。
但一组聊天记录里往往可能并不只有一个信息,可能包含用户的喜好,当前的心情,此刻的目标等等。
实际的Agent工程落地中,一段纯文本的结论对代码来说并不好处理。我们通常会双管齐下,要求LLM稳定输出JSON格式的内容:
- 直接在传参里输入:{"response_format": {"type": "json_object"}}
- 在提示词里明确规范JSON格式
前端在模型底层限制了JSON输出,后者让LLM知道输出什么样的JSON。
那么问题来了,应该用什么样的格式来提取信息?
目前主流的做法有四种:
- 事实清单 【本章会介绍】
- 标签化的事实清单 【本章会介绍】
- 事件流与情景摘要 【下一章再介绍】
- 关系三元组 【下一章再介绍】
这四种主流做法,各有其擅长的场景,本章我们主要介绍前两种:【事实清单】及【标签化的事实清单】。
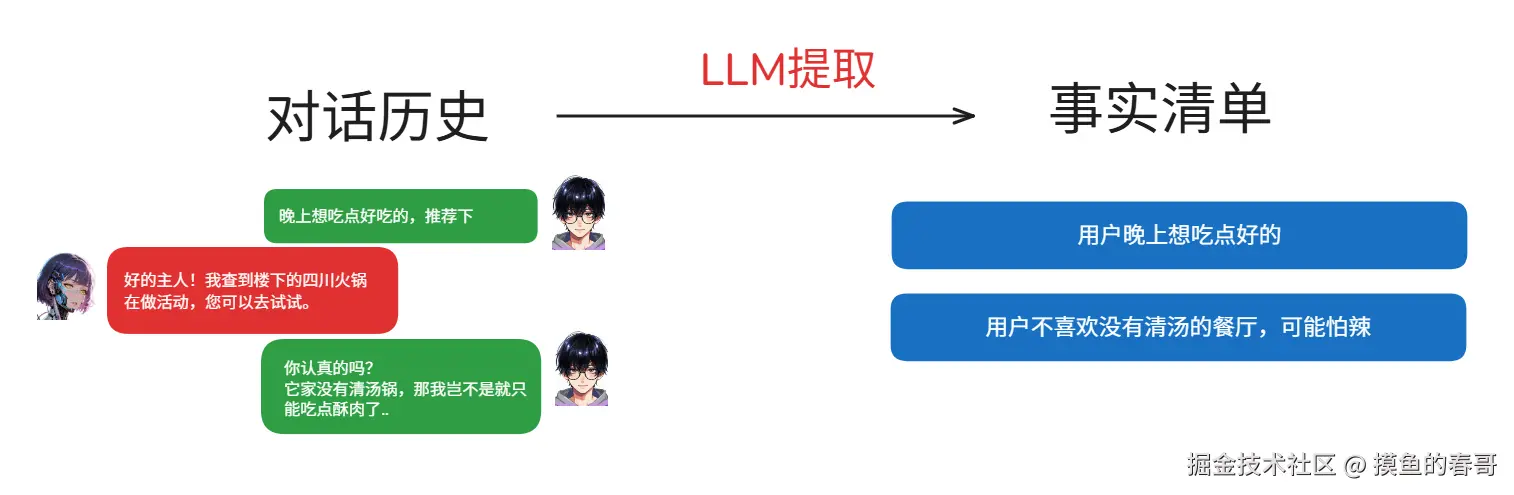
二、事实清单
事实,通常被翻译成fact。
事实清单的结构最为简单,效率最高,因此,它的使用范围也最广,目前 Agent 开发最受欢迎的记忆库都广泛采用了这种结构作为常规记忆的存放方式。
它的结构也非常简单:一个数组,每个元素都是字符串,表达着对事实的描述。
如:
python
fact_list = [
"用户在使用 Python",
"用户倾向于看官方文档而不是视频教程"
]这样的结构有很多优点:
- 提取性能好。它可以借助一些高性价比的模型来做快速的记忆提取,因为不需要复杂的JSON结构,因此效率。
- 提取更稳定。不需要LLM来组装复杂结构的JSON,因此结构出错或失败的概率也会大大减少。
- RAG友好。这样的结构天生适合做 Emedding 向量化,存入RAG数据库。
在第一节的示例的基础上,我们需要针对这种场景,制订更为清晰详实的System Prompt系统提示词,比如:
python
"""你是一个专业的信息提取专家,擅长从多轮对话的"言外之意"中,精准捕捉目标人物的隐性特征。
# [重要提示]:仅根据用户的信息生成事实内容,切勿包含助手或系统消息中的信息。
需要记住的信息类型:1.个人偏好 2.重要个人信息 3. 行程规划 4. 职业信息 5.其他与用户相关的信息
几个示例:
用户:嗨。
输出:{"facts":[]}
用户:嗨,我想在武汉找一家餐厅。
输出:{"facts":["正在寻找旧金山的餐厅"]}
用户:昨天下午 3 点,我与尤雨溪进行了会面。我们讨论了新项目。
输出:{"facts":["在昨天下午 3 点与尤雨溪会面,并讨论了新项目"]}
- 仅提取用户消息内容,忽略助手/系统消息
- 若无相关事实,则返回空列表
"""当然,别忘了传参里的 {"response_format": {"type": "json_object"}},这是稳定JSON结构的重中之重。
有人可能会问:{"facts":} 这一层不是多余吗?直接返回数组不是更简单更高效吗?
不不不,这里我建议最好加上,因为大家实践时发现,在有 {"response_format": {"type": "json_object"}} 时,LLM更喜欢输出 {} 开头解为的JSON,而不是 [] 数组结构。
demo我放在这里了,想尝试的直接去github上取源码实践比较省时间:github.com/zhangshichu...
如果用刚才的系统提示词,再次发起请求,LLM就会返回一个 "事实清单":
 这就完了吗?
这就完了吗?
如果你是一名经验老道的软件开发人员,可能已经在思考不同事实之间亦有不同。
- 想吃好吃的 ------ 这是短期目标。
- 不喜欢四川火锅 ------ 这是长期用户喜好。
作为一名老道的开发,你意识到,也许:我们应该在LLM梳理时,就完成这个分类。
没错,你成功解锁了目前市面上的另一种主流玩法:【分类事实清单】。
【分类事实清单】正好是事实清单的加强版本,它意味着"事实"可以进入更精细的管理范畴。
三、分类事实清单
如果你看过本系列教程教程的RAG相关课程的话,你一定有印象这样一个知识点:
目前主流的RAG数据库,通常不是简单的向量存储。而是关系型数据库存元数据,向量库存向量。
为什么我要在这里提这一点呢?
很简单,分类的本质就是:"元数据"。
假设,我们可以按如下结构获取到事实清单:
json
{
"facts": [
{
"content": "喜欢java的技术栈",
"category": "preference" // 喜好
},
{
"content": "想写一套后端管理系统",
"category": "short_term_goal" // 短期目标
}
]
}此时,相比于第一节未规定的一句话,我们具备了把"用户当前的目标"和"喜好"分开来看,选择性的采用不同策略存储的能力。
这是显而易见的:
- 暂时的目标可以临时存储
- 长期的个人喜好则可以采用RAG这种成本更高但更持久的方案。
这样做的好处实在太多了!
-
避免了:I/O 损耗与"垃圾数据"爆炸
- 短期目标的生命周期极短,可能两三轮对话后任务就结束了。如果存入数据库,你不仅要执行写入(Insert),还要在任务完成后执行删除(Delete)或状态更新(Update)。频繁的磁盘 I/O 对于这种用完即弃的数据来说是极大的性能浪费。如果不删除,数据库很快就会被一堆"帮我点杯咖啡"这样的过期垃圾塞满。
-
避免了:向量检索污染(RAG 灾难)
- 假设你把"本周五想去成都吃火锅"存入了向量数据库。过了三个月,用户问"我周末去成都玩,有什么建议?"。
- 此时,向量数据库做语义检索,很可能会把三个月前那个"本周五想去成都"的旧目标给召回给大模型。大模型拿到这个过期的上下文,就会产生严重的幻觉,以为用户这周五又要去成都。
-
状态管理的混乱
- 短期目标本质上是一个 "任务状态(State)",而不是一个"客观事实(Fact)"。
- 事实是静态的(如:用户不吃辣),而目标是动态的(如:待办 -> 进行中 -> 已完成)。数据库更擅长管事实,而不擅长管这种高频流转的状态。
实际的做法其实也很简单,只需要在系统提示词里明确你想要的JSON结构即可。
markdown
我们需要你将提取的事实进行分类(category),可选的分类标签如下:
1. preference (个人偏好、喜好习惯)
2. short_term_goal (短期目标、当前具体的任务或项目)
3. tech_stack (技术与工具栈、技能)
4. fact (客观背景事实)
请必须以严格的 JSON 格式输出,包含一个 `facts` 数组,每个元素包含 `content` (事实内容) 和 `category` (分类标签)。
示例:
用户:我想做一个后台管理系统,用Java。
输出:{{"facts": [{{"content": "想要开发后台管理系统", "category": "short_term_goal"}}, {{"content": "希望使用Java开发", "category": "tech_stack"}}]}}demo地址:github.com/zhangshichu...

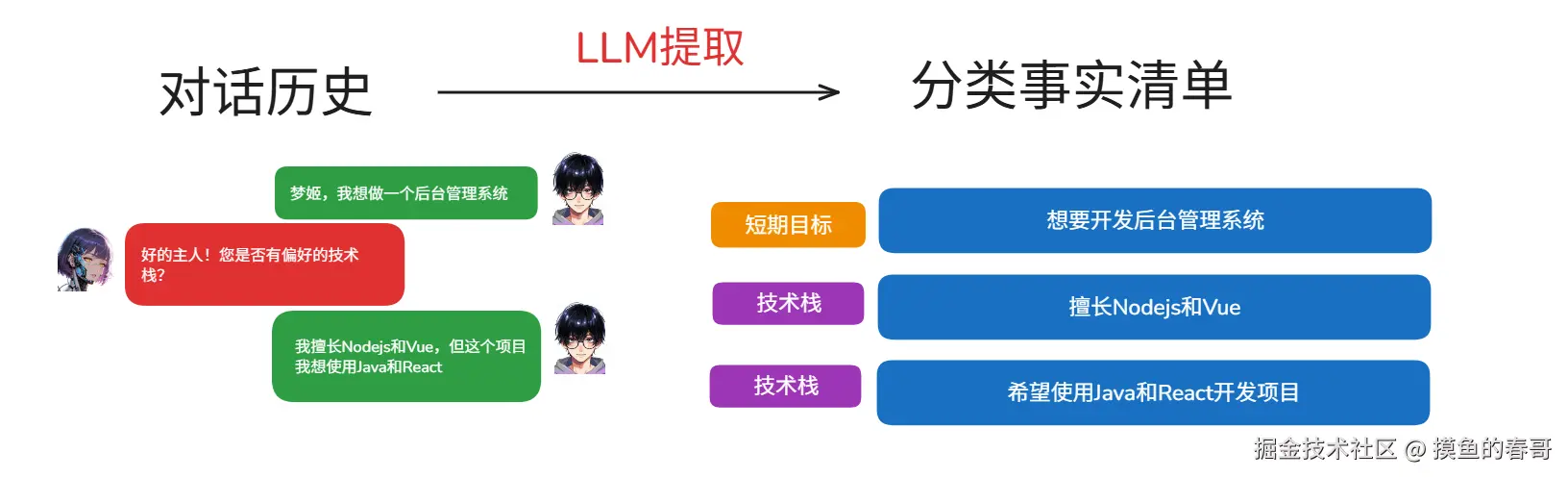
目前的主流做法是把"短期目标"择出来,放在内存里(比如LangGraph的状态里),可以在对话的持久化中留存,但不进入长期记忆。
python
class AgentState(TypedDict):
# 对话消息队列,短期目标会作为 Message 推入这里留存
messages: Annotated[list[BaseMessage], add_messages]
# 长期记忆事实队列(如偏好、技术栈),模拟后续存入 ChromaDB
long_term_facts: Annotated[list[dict], operator.add]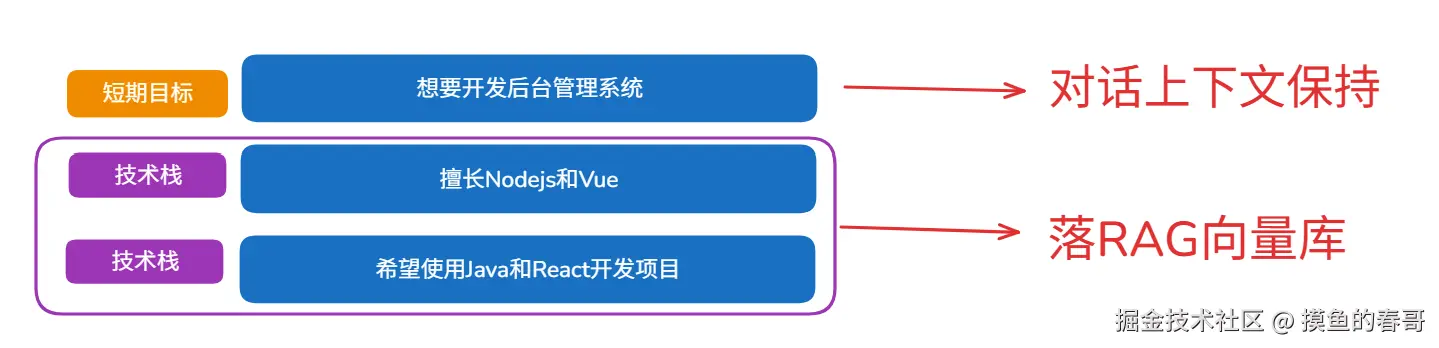
长期记忆事实队列,入库之后,在查询时,你也可以通过元数据标记混合检索提升效率。
python
results_tech = collection.query(
query_texts=["我想写一段随机生成敌人的代码,帮我参考一下环境"],
n_results=2,
where={"category": "tech_stack"}
)四、记忆压缩
当记忆无限制增长时,它就不再是财富,而是负担。
上一节,我们对记忆进行了分类,知道记忆通常有两类存储:
- 长期记忆存RAG 等高成本库
- 短期记忆存在内存里
但,它们同样都会面对一个巨大的问题:当记忆无限增长时,会带来哪些问题?
4.1 上下文 Messages 的记忆压缩
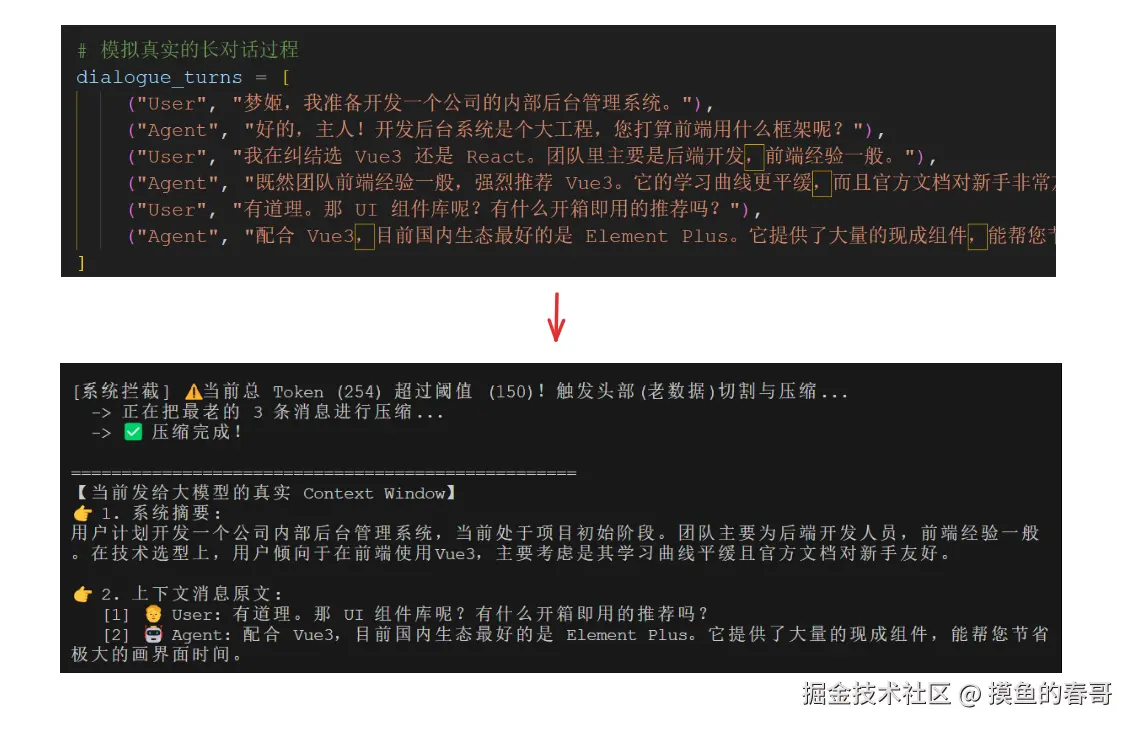
随着小李和"梦姬"日复一日的聊天,对话历史(History)会变得极其庞大。如果你把所有的聊天记录每次都塞进LLM的上下文(Context Window)里,会带来三个致命问题:
-
Token超限:直接撑爆模型的最大上下文长度,导致报错。
-
成本飙升:API的Token计费会随之呈指数级上升。
-
注意力涣散:即便是最先进的LLM,在面对超长文本时也会出现"大海捞针"般的遗忘现象(Lost in the Middle),抓不住重点。
针对上下文Messages不断增长的问题,最经典的压缩方式就是滚动摘要(Rolling Summary)。
一般来说,会设置两个预设的参数:
- 安全Token数(如 10k Token)
- 触发压缩Token数(如 20K Token)
每当上下文的Token数达到 20K 是,就对 10K - 20K 范围内的这10K Token进行压缩,生成【压缩后的记忆】
然后,把 安全范围内的 10K Token和【压缩后的记忆】拼装到一起,形成新的上下文 Messages。
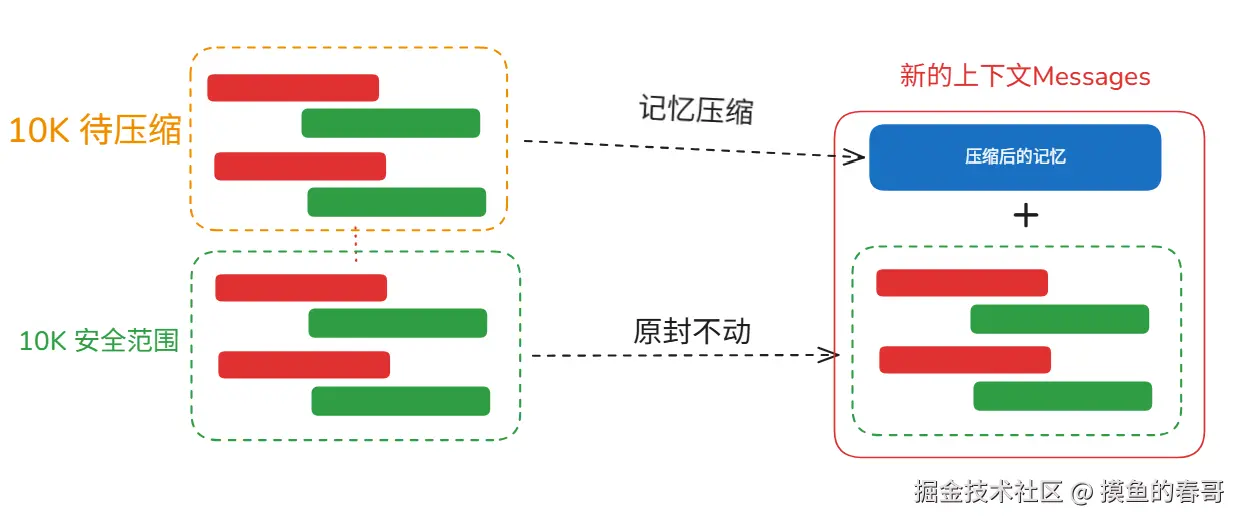
这样架构的好处在于:
- 远处的记忆不断压缩,能降低上下文长度
- 最近的聊天细节不会被磨灭
目前大家接触到的绝大部分Agent,其实都采用着这套方案,比如 Trae、Cursor 等。
Claude Code稍微特殊一点,它给出了 /compact 指令,允许用户主动参与"记忆压缩"的过程。
比如,你可以这样:
bash
/compact 完整保留项目启动命令相关的细节这样,在记忆压缩时,对用户重点关注的部分可以单独抽取出来,不做损失细节的压缩。
动手实践,先拟定一个对记忆进行提取的LLM System Prompt:
MARKDOWN
你是一个极其高效的记忆整理大师。
请根据【已有记忆摘要】和【需要被压缩的旧对话】,生成一份合并后的【最新记忆摘要】。
要求:
1. 提取讨论的核心背景、目标和关键信息。
2. 剔除废话和寒暄。
3. 如果已有摘要为空,直接总结旧对话即可。
【已有记忆摘要】:
{old_summary}
【需要被压缩的对话】:
{history_text}
请直接输出最新记忆摘要(纯文本):每次会话之前,都有限检查上下文,并进行压缩处理。
demo代码在此:github.com/zhangshichu...
4.2 RAG 内记忆的压缩(长期记忆的"降噪机制")
这才是高级 Agent 真正拉开差距的地方,也是很多教程避而不谈的深水区。
当你把提取出来的原子事实(Facts)不断存入 ChromaDB 等向量数据库后,RAG 系统不需要担心 Token 溢出(因为存在硬盘里),它面临的是 "检索污染"和"语义冗余"。
假设,小李是一名初学前端的开发者,他在和AI助理梦姬的对话里多次提到 Vue。
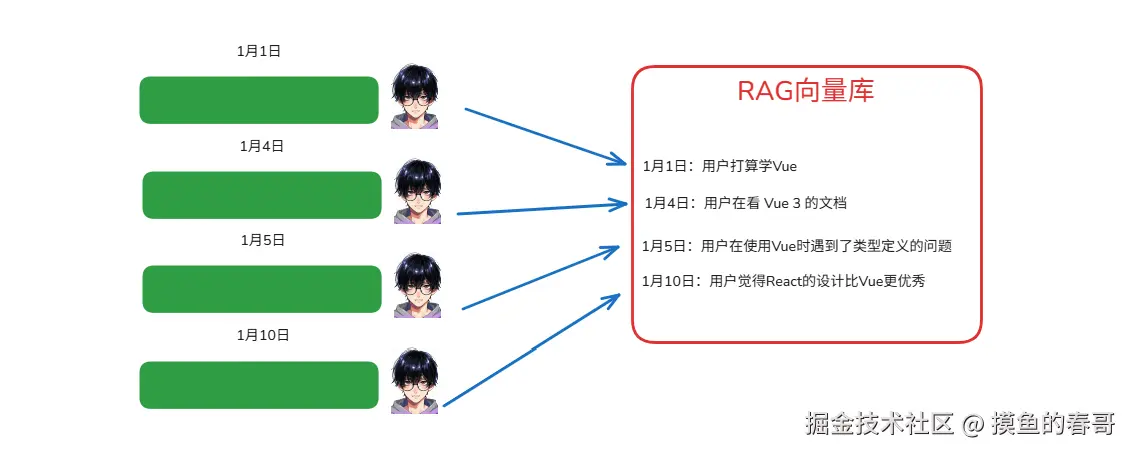
如果Agent不假思索地对对话内容进行信息提取,向量存储,那么长期来看,RAG向量库里一定充满了关于某些技术方向各种各样的"事实"。
这样一来,势必带来两个问题:
- 老生常谈的浪费Token
- 重要的信息被噪音掩盖
比如说,以上例子里,假若Agent的策略是只取RAG查询到的前3条,那就会漏掉 "1月10日:用户觉得React的设计比Vue更优秀" 可条可能严重影响技术栈选择的消息。
从而让你的AI-Agent看起来善忘且笨笨哒。
简单来说:
- 核心痛点:数据库里相似的垃圾碎片太多,导致向量检索(Similarity Search)时,召回的内容全是重复废话,甚至包含旧的冲突信息,导致 LLM 产生幻觉。
- 数据结构:散落在高维空间里的句向量(Embeddings)。
那么解决方案是什么呢?
答:异步压缩
和上下文Messages里需要实时处理不同,RAG里散落的知识点可能并不会那么明显地对当前的会话产生影响,所以可以异步处理。
比如每晚定时跑,或者当同一个分类下的事实超过 50 条时触发,把库里相似度极高的向量全部拉出来,扔给 LLM 执行聚合。
然后:
- 对老数据进行物理或逻辑删除
- 把聚合后的数据插入向量库
压缩后的新事实向量:
用户正在深度使用 Vue 3进行开发,涉及TypeScript功能,但目前认为React的设计更优秀。ok,思路顺了,则可以上手撰写简单的处理demo,让我们先设置System Prompt:
MARKDOWN
你是一个专业的记忆碎片整理大师。
你的任务是将长期积累的、存在冗余甚至冲突的【同类记忆碎片】,聚合成一条逻辑严密、反映最新状态的【高密度事实】。
【处理原则】:
1. 提取核心技术栈及最新偏好。
2. 识别并解决冲突(例如:如果过去喜欢A,现在喜欢B,请以时间线靠后的最新状态为准)。
3. 剔除无意义的日期流水账。
【待聚合的记忆碎片】:
{fragments}
请直接输出聚合后的新事实文本(纯文本,不加任何解释):并按照思路依次执行以下步骤:
- 按标签从RAG库取记忆
- 把记忆拼到一起
- 给LLM聚合
- 删除老记忆,插入新记忆
demo代码在这里:github.com/zhangshichu...
demo里,我设置的初始记忆如下: 
在提取后,只剩下一个精炼的记忆: 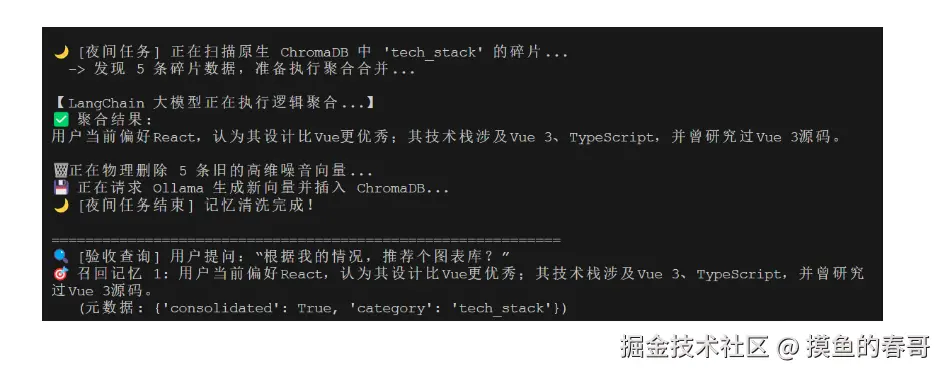
4.3 核心对比
| 维度 | 上下文 Messages 压缩 | RAG 内记忆压缩 |
|---|---|---|
| 主要目的 | 防 Token 溢出,降本增效 | 防检索污染,提升召回质量与逻辑一致性 |
| 处理对象 | 时间线上的原始对话记录 | 向量库里语义相似的独立事实片段 |
| 处理手段 | 截断历史 + 滚动摘要 | 相似度聚类 + 事实聚合 (Consolidation) |
| 执行时机 | 对话进行中(实时、同步拦截) | 业务低谷期(后台、异步批处理) |
五、小结
这一张,我们理解并实践了Agent记忆场景中最高频也最实用的两个场景:
- 信息提取
- 记忆压缩
但Agent记忆还有一些经典场景需要解锁,下节课我们解锁Agent记忆另外的一些经典玩法!
敬请期待!
