微调前期准备
下载qwen3.5-4B模型
shell
# 首先保证已安装git-lfs(https://git-lfs.com)
git lfs install
git clone https://modelers.cn/Qwen-AI/Qwen3.5-4B.git下载Llama-factory
shell
git clone --depth 1 https://gh.llkk.cc/https://github.com/hiyouga/LlamaFactory.git
微调环境搭建
我们依然是搭建一个miniconda
shell
#清除当前shell会话中的PYTHONPATH环境变量
unset PYTHONPATH
# 安装miniconda
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh
bash Miniconda3-latest-Linux-aarch64.sh
conda config --set auto_activate_base false
bash
#加载conda配置
source ~/.bashrc
# 接受main通道的条款
conda tos accept --override-channels --channel https://repo.anaconda.com/pkgs/main
# 接受r通道的条款
conda tos accept --override-channels --channel https://repo.anaconda.com/pkgs/r
# 创建python3.11环境
conda create --name LlamaFactory python=3.11 -y
conda activate LlamaFactory安装LlamaFactory环境依赖
shell
cd LlamaFactory
pip install -e .
# 可以安装 flash-linear-attention 获得训练推理加速效果
pip uninstall fla-core flash-linear-attention -y && pip install -U git+https://github.com/fla-org/flash-linear-attention
#因为我们使用的昇腾的npu的算力,所以我们还需要额外装一个torch-npu和decorator
pip install torch-npu == 2.10.0rc2
pip install decorator可以使用下面的命令验证是否安装成功:
shell
llamafactory-cli version
显示llamafactory的版本,则表示安装成功
完成环境的搭建之后我们还需要将昇腾的环境启动命令跑一遍,使用以下的命令
shell
source /usr/local/Ascend/ascend-toolkit/set_env.sh
source /usr/local/Ascend/nnal/asdsip/set_env.sh
source /usr/local/Ascend/nnal/atb/set_env.sh下载数据集
根据llamafactory的要求我们需要把数据集放到LlamaFactory/data
shell
cd LlamaFactory/data我们先下载数据集,数据集的制作的过程比较繁琐,这里我们使用准备好的数据集,大家也可以使用自己制作的数据集(这里我是拿的官方给的测试数据集):
shell
#下载数据集
git clone https://modelers.cn/chicheng/mllm_robot.git
# 移动数据集到LlamaFactory/data文件夹
cd mllm_robot
mv mllm_robot.zip /home/openmind/LlamaFactory/data
#然后我们到LlamaFactory/data目录来解压数据集
cd LlamaFactory/data
# 解压
python3 -c "import zipfile; zipfile.ZipFile('mllm_robot.zip').extractall()"
修改 dataset_info.json 文件,将我们刚刚下载的数据集添加进去
shell
"mllm_robot": {
"file_name": "mllm_robot.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages",
"images": "images"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant"
}
},
"mllm_robot_en": {
"file_name": "mllm_robot_en.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages",
"images": "images"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant"
}
},
模型微调
训练脚本准备
因为魔乐社区的体验空间是终端的形式,我们现在暂时无法使用LlamaFactory的Web_UI,使用我们需要写一个训练的yaml文件
yaml
# 模型参数
model_name_or_path: /home/openmind/Qwen3.5-4B # 或您的本地模型路径
template: qwen3_5 # 模型模板
trust_remote_code: true # 对于Qwen模型通常需要
# 训练参数
stage: sft # 监督微调
do_train: true
finetuning_type: lora # 使用LoRA
lora_target: q_proj,k_proj,v_proj,o_proj # LoRA作用模块 (可按需调整)
dataset: mllm_robot,mllm_robot_en # 使用两个数据集 (用逗号分隔)
learning_rate: 1.0e-4
num_train_epochs: 5.0
per_device_train_batch_size: 1 # 根据显存调整 (使用多卡可以自行调整这里)
gradient_accumulation_steps: 16 # 确保总batch_size合适
bf16: true # 昇腾910B支持bf16,可开启以节省显存
# 输出参数
output_dir: /home/openmind/Qwen3.5-4B/lora/train_Qwen3.5-4B # 与教程对应的输出目录
logging_steps: 10
save_steps: 500
overwrite_output_dir: true
# 硬件与分布式相关
fp16: false # 已启用bf16,关闭fp16避免冲突
ddp_timeout: 180000 # 分布式超时设置命令解释的内容:
shell
# ==================== 模型参数 ====================
model_name_or_path: /home/openmind/Qwen3.5-4B
# 模型路径:可以是本地路径(如本例),也可以是 Hugging Face 模型 ID(例如 "Qwen/Qwen2.5-7B")
# 如果从 Hugging Face 下载,确保网络通畅且有权访问。
template: qwen3_5
# 对话模板:根据模型系列选择,常见值:
# - qwen3_5: 通义千问 Qwen3.5 系列
# - qwen: 通用 Qwen 系列(包括 Qwen1.5/2/2.5)
# - llama3: Llama-3 系列
# - default: 基础模板(若不确定可先用此)
# 模板影响输入格式(如角色标签、系统消息等),选错可能导致训练异常。
trust_remote_code: true
# 是否信任远程代码:对于 Qwen、ChatGLM 等使用自定义模型结构的模型,必须设为 true。
# ==================== 训练参数 ====================
stage: sft
# 训练阶段:sft 表示监督微调(Supervised Fine-Tuning)
# 其他可选值:
# - pt: 预训练(Pretraining)
# - rm: 奖励建模(Reward Modeling)
# - dpo/kto/orpo: 偏好优化
# - ppo: 强化学习微调(需额外配置)
do_train: true
# 是否执行训练:设为 true 时进行训练;false 时仅评估或推理。
finetuning_type: lora
# 微调方法:
# - lora: 低秩适配(参数高效,显存友好)
# - full: 全参数微调(需更多显存)
# - freeze: 冻结部分层,仅训练最后几层
# - oft: 正交微调(另一种参数高效方法)
lora_target: q_proj,k_proj,v_proj,o_proj
# LoRA 作用的目标模块(以逗号分隔)。
# 不同模型模块名不同,常用选项:
# - q_proj, k_proj, v_proj, o_proj: 注意力层的线性层(适用于 Qwen/Llama)
# - gate_proj, up_proj, down_proj: MLP 层(若需增加参数量)
# - all: 所有线性层(参数量大,需注意显存)
# 可根据需要增删模块,例如仅微调注意力层:q_proj,v_proj
dataset: mllm_robot,mllm_robot_en
# 训练数据集名称(多个用逗号分隔)。
# 这些名称必须在 data/dataset_info.json 中预先定义。
# 定义示例(在 dataset_info.json 中):
# "mllm_robot": {
# "file_name": "mllm_robot.json",
# "formatting": "sharegpt",
# "columns": {"messages": "messages", "images": "images"},
# "tags": {"role_tag": "role", "content_tag": "content", "user_tag": "user", "assistant_tag": "assistant"}
# }
# 数据集文件需放在 data/ 目录下,格式参考官方文档。
learning_rate: 1.0e-4
# 初始学习率。LoRA 通常用 1e-4 左右,全量微调用 1e-5。
# 可根据收敛情况调整,过大可能导致不收敛,过小则训练缓慢。
num_train_epochs: 5.0
# 训练轮数(epoch)。一轮表示完整遍历一次训练集。
# 根据数据集大小和任务复杂度调整,过小可能欠拟合,过大可能过拟合。
per_device_train_batch_size: 1
# 每张 NPU/GPU 卡的 batch size。
# 根据显存大小调整:显存充足可增大(如 2,4),显存不足则保持 1。
# 多卡时,总 batch size = per_device_batch_size × 卡数 × gradient_accumulation_steps。
gradient_accumulation_steps: 16
# 梯度累积步数。用于模拟更大的 batch size,不增加显存占用。
# 总 batch size = per_device_batch_size × 卡数 × gradient_accumulation_steps。
# 例如:单卡 batch=1,累积 16 步 → 实际 batch size = 16;
# 双卡 batch=1,累积 16 步 → 实际 batch size = 32。
# 根据训练稳定性和收敛速度调整,通常保持总 batch size 在 16~64 之间。
bf16: true
# 使用 bfloat16 混合精度训练(节省显存,加速)。
# 昇腾 910B 支持 bf16,可开启。若硬件不支持,需改为 false 并使用 fp16 或 fp32。
# ==================== 输出参数 ====================
output_dir: /home/openmind/Qwen3.5-4B/lora/train_Qwen3.5-4B
# 训练输出目录,用于保存:
# - 模型检查点(checkpoint-xxx)
# - 训练日志(trainer_log.jsonl)
# - 最终 LoRA 权重(adapter_model.safetensors)
# 确保路径可写,且无重要文件(若 overwrite_output_dir 设为 true 则会清空)。
logging_steps: 10
# 每隔多少步打印一次训练日志(显示 loss、学习率等)。方便监控训练状态。
save_steps: 500
# 每隔多少步保存一次检查点。保存的文件可用于恢复训练或后续推理。
# 若设为 0 则禁用保存。
overwrite_output_dir: true
# 若输出目录已存在,是否覆盖。设为 true 可自动清空旧文件,避免手动删除。
# 若为 false 且目录存在,程序会报错退出。
# ==================== 硬件与分布式相关 ====================
fp16: false
# 是否使用 float16 混合精度。此处已启用 bf16,故设为 false,避免冲突。
# 若硬件不支持 bf16,可改用 fp16,并确保同时关闭 bf16。
ddp_timeout: 180000
# 分布式训练时进程间通信的超时时间(秒)。用于防止通信卡死。
# 180000 秒约 50 小时,足够长时间训练。若网络不稳定可适当增大。
# 仅在多卡训练时生效,单卡可忽略。使用单卡训练命令:
shell
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train train_qwen_robot.yaml
多卡训练命令:
我们新建一个终端,在终端上运行:
shell
npu-smi info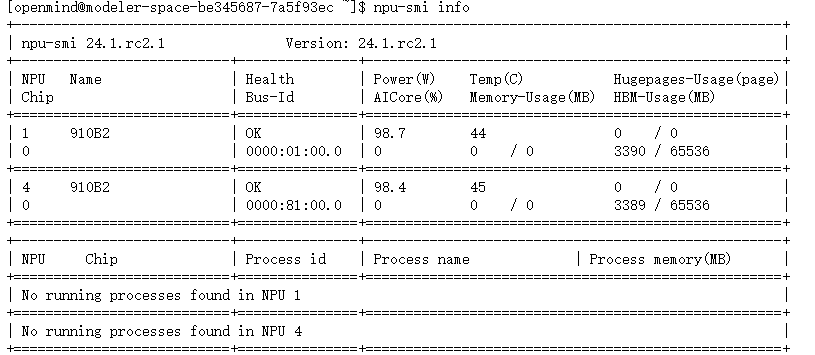
可以看到 NPU 卡的设备编号分别是1,4
shell
WANDB_MODE=disabled FORCE_TORCHRUN=1 CUDA_VISIBLE_DEVICES=1,4 llamafactory-cli train ./train_qwen_robot.yaml对比训练前后的模型
拉起加载原始模型权重:
shell
CUDA_VISIBLE_DEVICES=1 llamafactory-cli api \
--model_name_or_path /home/openmind/Qwen3.5-4B \
--template qwen3_5 \
--finetuning_type lora使用下面的命令去提问,查看输出内容:
shell
curl -X POST http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "Qwen3.5-4B",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "data:image/png;base64,'$(base64 -w 0 /home/openmind/LlamaFactory/data/images/robotera_1.png)'"
}
},
{
"type": "text",
"text": "请识别并描述图片中的机器人及其特征"
}
]
}
],
"max_tokens": 512,
"temperature": 0.1
}'输出内容
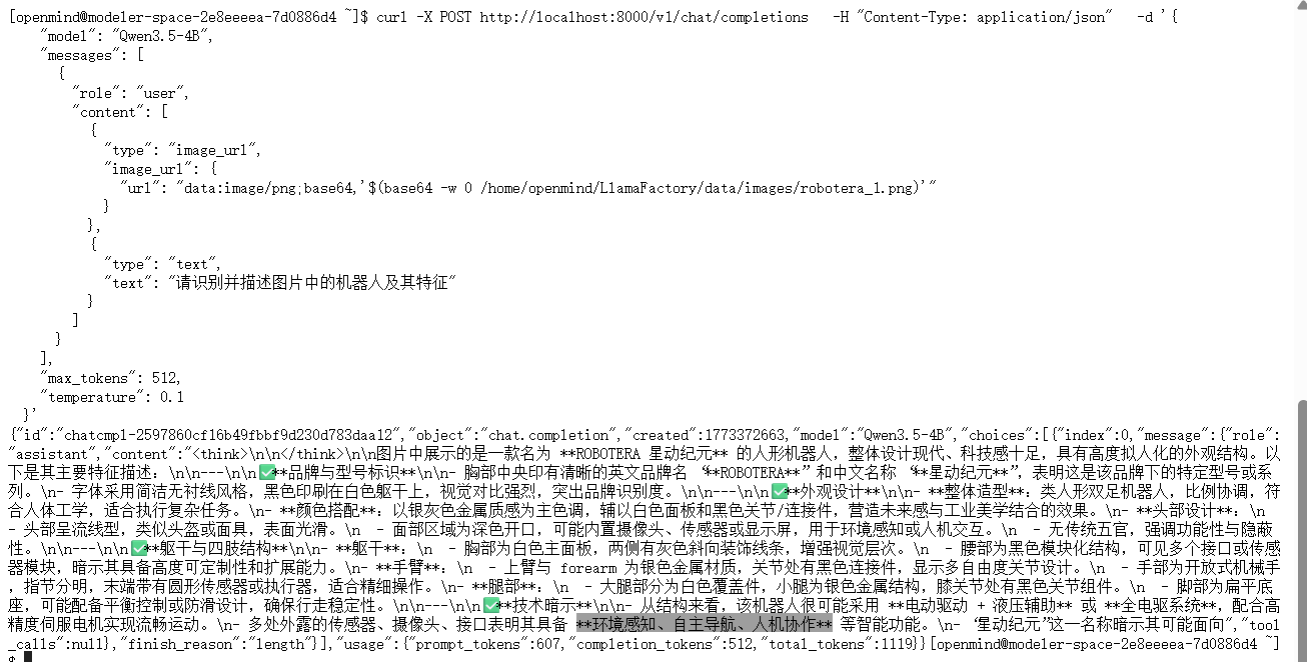
拉起加载lora权重的模型
shell
CUDA_VISIBLE_DEVICES=1 llamafactory-cli api \
--model_name_or_path /home/openmind/Qwen3.5-4B \
--adapter_name_or_path /home/openmind/Qwen3.5-4B/lora/train_Qwen3.5-4B \
--template qwen3_5 \
--finetuning_type lora依然是使用上面curl命令的内容去提问,查看输出
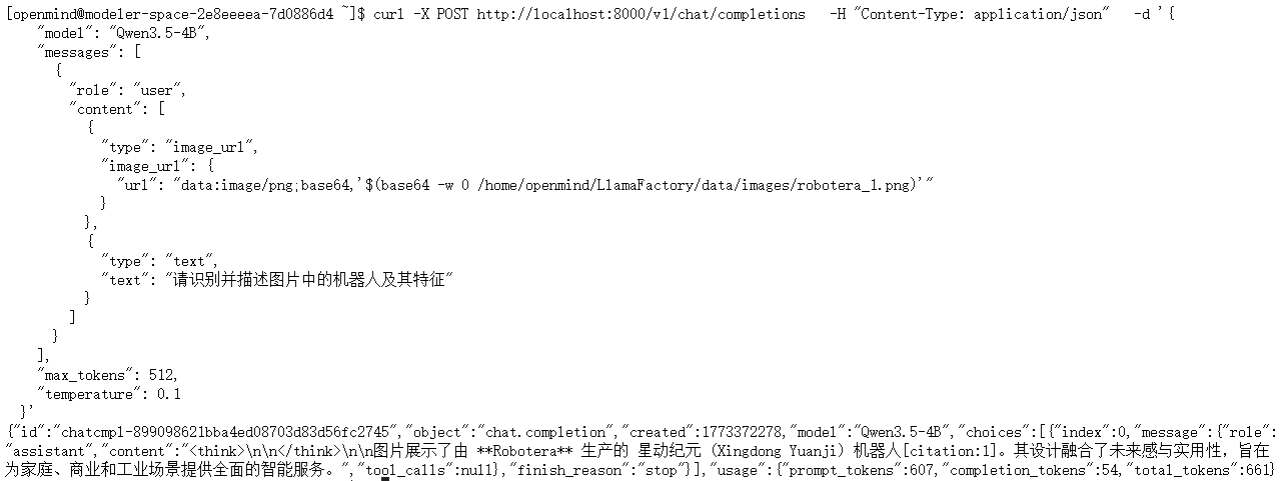
LLaMA-Factory YAML 参数大全:
https://modelers.cn/blogs/chicheng/208/issues?blogId=208
启动 Web UI命令:
shell
llamafactory-cli webui点击返回的 URL 地址,就可以进入 Web UI 页面。
可能出现的问题
如果使用llama-factory命令的时候出现找不到命令的时候,可以在终端运行下面的命令:
shell
# 若执行llama-factory的相关提示找不到命令,需设置一下变量,将包路径添加至环境变量中
export PATH="/home/openmind/.local/bin:$PATH"
export PATH="/usr/local/bin:$PATH"