在使用OpenClaw的过程中,我想通过语音给OpenClaw发消息,有好几种方式:
- 语音转文本,在发送之前就通过飞书识别好了内容,把文本发给OpenClaw
- 直接发送语音文件,让OpenClaw识别语音文件
一次偶然使用了第二种,OpenClaw告诉我不能识别。我就想让OpenClaw增加识别语音的能力。于是我就开始动工了。
启动语音识别的后台FunASR
使用之前搭建的FunASR服务,让OpenClaw调用FunASR服务,将音频转为文字。参考:本地部署通义FunASR服务进行语音识别, 本地部署通义FunASR服务(中)
由于我用的websocket服务,并且修改了部分服务端代码。我将最新的代码上传到这里:https://github.com/tinygone/FunASR。
修改内容:
- FunASR\runtime\python\websocket\funasr_wss_server.py:主要增加日志,方便调试,部分代码有微调
- FunASR\runtime\python\websocket\funasr_wss_client.py:主要为了调试,可以不用
启动准备工作:
conda create -n faenv python=3.12.9
conda activate faenv
git clone https://github.com/tinygone/FunASR.git
cd FunASR
conda activate faenv
pip3 install -e ./
# 安装必要的组件,如果已经安装了就可以忽略
# 安装modelscope,自动下载模型
pip install modelscope
# 设置环境变量:MODELSCOPE_CACHE="目标地址"
# 安装pytorch,特别的加上了torchaudio
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu130
# 更新transformers
pip install -U transformers
pip install tiktoken
pip install websockets
pip install pyaudio
# 安装ffmpeg,不是一行命令就能搞定,参考之前的材料启动服务器,这样服务器就启动好了:
# host 可以换成服务器的ip,但还是建议用0.0.0.0,这样能在tailscale环境下使用
python .\funasr_wss_server.py --host 0.0.0.0 --port 10095构建识别流程
飞书发送音频文件时gog格式,如果直接给FunASR识别,识别不出来。所以要先转换为wav格式。
给OpenClaw增加相关的Skill和处理脚本。文件地址在:https://github.com/tinygone/openclaw-feishu-voice-skill
包括2部分内容:
- voice-handle skill,要放到
~/.openclaw/skills/目录 - speech-to-text 处理脚本,要放到
~/.openclaw/middleware/目录下
确保Agent能够识别Skill,并且OpenClaw所在的环境已经启动。
如果没有配置好Skill,此时可以通过飞书发送语音消息给OpenClaw的Agent。会受到类似的消息,下面是收到一个16秒的音频文件。
[media attached: /home/band/.openclaw/media/inbound/xxx.ogg (audio/ogg; codecs=opus) | /home/band/.openclaw/media/inbound/7c570ea2-4b9a-4105-a8c9-26d8e7047a24.ogg]
To send an image back, prefer the message tool (media/path/filePath). If you must inline, use MEDIA:[https://example.com/image.jpg](https://example.com/image.jpg) (spaces ok, quote if needed) or a safe relative path like MEDIA:./image.jpg. Avoid absolute paths (MEDIA:/...) and ~ paths --- they are blocked for security. Keep caption in the text body.
ou_xxx: {"file_key":"file_xxx","duration":16000}如果Skill已经配置好,且客户端(OpenClaw所在的电脑)、FunASR服务端均正确运行,就会受到类似下面的消息。
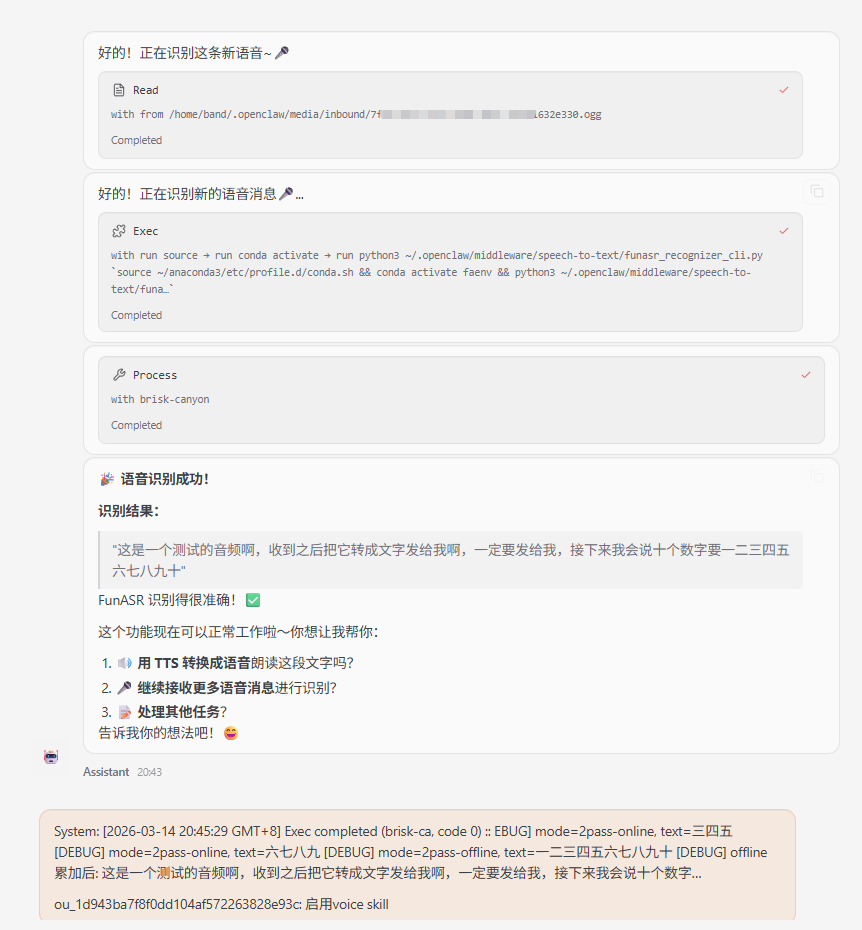
实测下来,GLM-5模型、Ollama本地运行的qwen3.5:9b,均能正常运行。有了FunASR服务,未来只要有音频都可以交给OpenClaw,帮我识别成文字。