Prompt提示词设计工程:从原则到实战的系统性方法论(附模板与调试工具)
摘要:本文基于Prompt Engineering系统化知识框架,深度解析提示词设计的五大核心模块:从基本原则到少样本学习,从角色定义到A/B测试优化。提供可直接落地的代码模板、评估指标体系和调试工具链,助你构建工业级提示词工程能力。
关键词:Prompt Engineering、Few-Shot Prompting、Chain-of-Thought、角色提示、上下文管理、A/B测试、提示词优化
一、提示词设计基本原则:金字塔底座
1.1 明确性与简洁性(Clarity & Conciseness)
黄金法则:LLM对模糊指令的容错率远低于人类,需在"信息量"与"歧义排除"间找平衡。
明确性三要素:
- 具体动词:避免"分析",使用"对比优缺点"、"提取关键实体"、"生成JSON格式"
- 输出格式:明确指定JSON/XML/Markdown/表格,减少解析成本
- 约束条件:字数限制、风格要求(学术/口语)、禁止内容清单
简洁性边界:
❌ 低效提示:"请你帮我看一下这个代码,我觉得可能有点问题,你帮我分析一下哪里不对,然后给我一些建议好吗?"
✅ 高效提示:"审查以下Python代码,识别潜在的性能瓶颈和安全漏洞,按严重程度分级输出,格式:级别 行号 问题描述 优化建议"
1.2 任务分解方法(Task Decomposition)
复杂任务需拆解为可验证的子任务链:
md
┌─────────────────────────────────────────────────────────────┐
│ 任务分解流程(以代码生成示例) │
├─────────────────────────────────────────────────────────────┤
│ 原始任务:开发一个带权限控制的博客系统 │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Step 1: 数据库设计 │ │
│ │ • 用户表(角色字段) • 文章表(作者外键) • 权限表 │ │
│ └─────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Step 2: API接口定义 │ │
│ │ • 认证接口(登录/注册) • CRUD接口(带权限校验装饰器) │ │
│ └─────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Step 3: 前端页面 │ │
│ │ • 登录页 • 文章列表(只读) • 管理后台(需admin角色) │ │
│ └─────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘提示模板:
md
你是一位资深[角色]。请将以下复杂任务分解为3-5个可独立执行的子任务:
任务:[描述]
要求:
1. 每个子任务需明确输入输出格式
2. 标注子任务间的依赖关系
3. 估计每个子任务的复杂度(高/中/低)1.3 上下文提供技巧(Context Provision)
上下文类型与注入策略:
| 上下文类型 | 适用场景 | 注入位置 | 示例 |
|---|---|---|---|
| 背景知识 | 领域特定任务 | 系统提示(System Prompt) | "你是一位熟悉RISC-V架构的嵌入式工程师..." |
| 参考文档 | 基于文档问答 | 用户消息前 | "基于以下技术文档回答问题:文档内容" |
| 历史记录 | 多轮对话 | 对话历史拼接 | 维护对话窗口,保留关键决策点 |
| 外部数据 | 实时数据查询 | 工具调用结果 | 通过Function Calling注入数据库查询结果 |
上下文窗口管理:
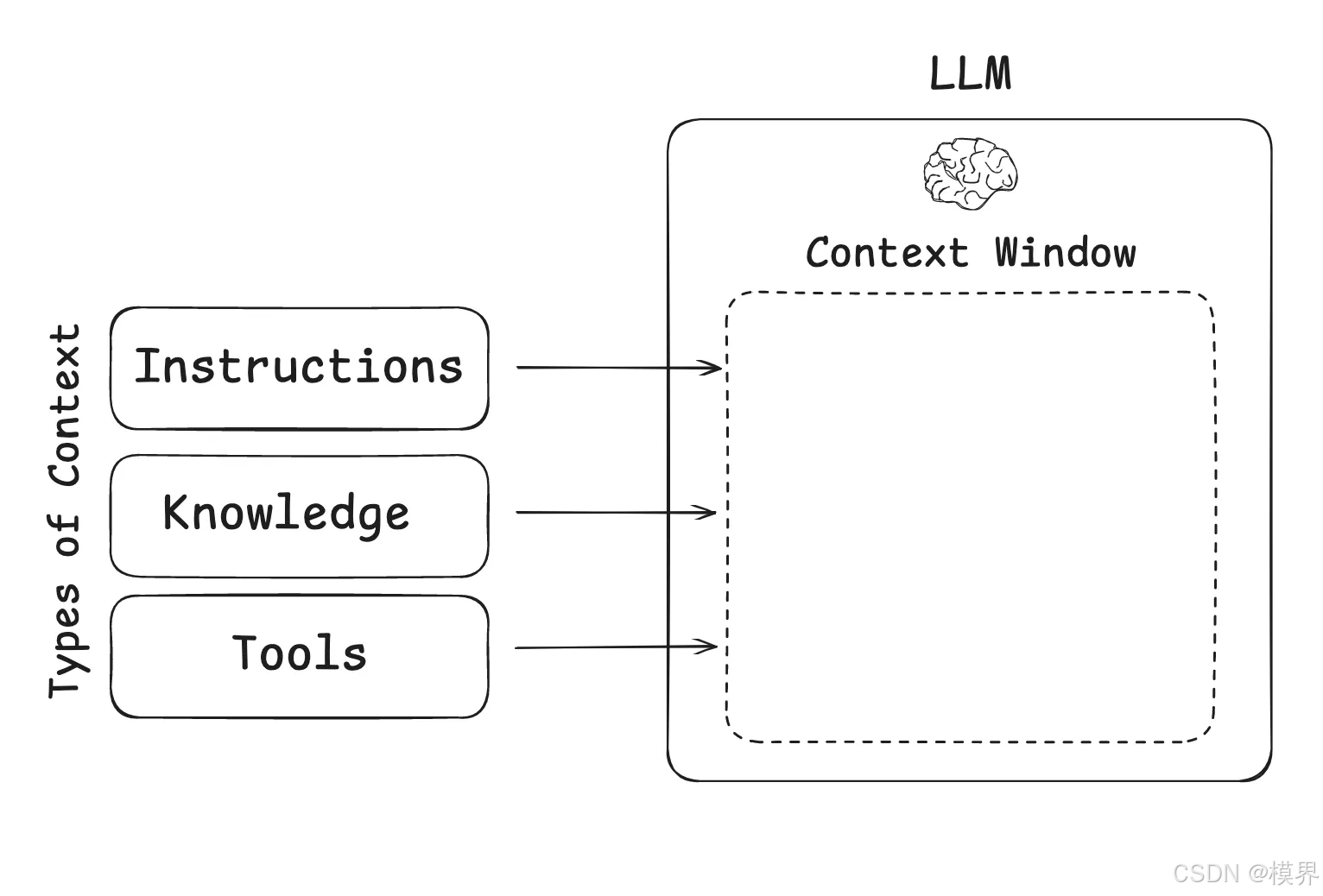
二、零样本与少样本提示:从Zero到Few的跃迁
2.1 零样本提示(Zero-Shot)
定义:不提供示例,直接通过指令描述任务。
适用场景:
LLM已具备该任务的预训练知识(如通用翻译、基础代码生成)
任务边界清晰,无需特定格式约束
零样本提示模板:
md
将以下中文技术文档翻译成英文,保持专业术语准确:
输入:[中文文本]
要求:
- 保留所有Markdown格式
- 代码注释不翻译
- 输出仅包含翻译结果,不添加解释2.2 少样本提示(Few-Shot)
核心机制:通过1-5个高质量示例,让模型理解隐含的映射关系。
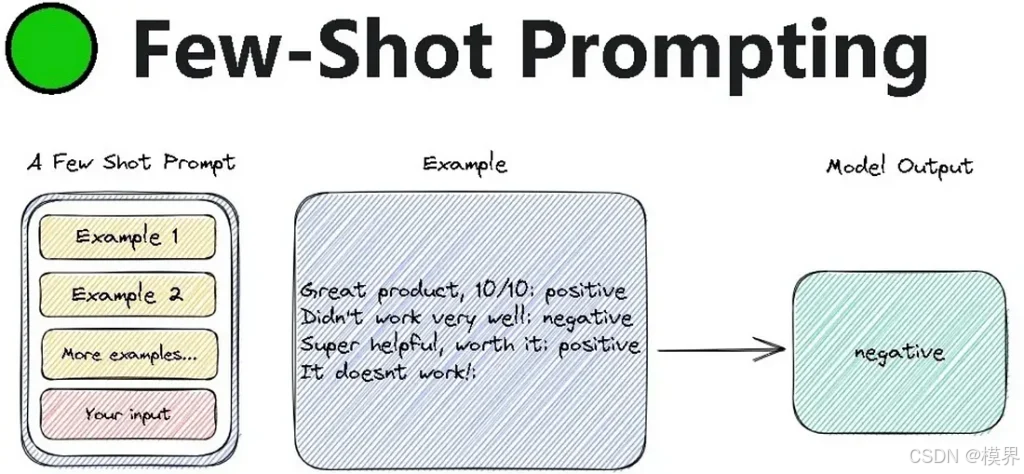
结构范式:
md
任务描述:[明确任务目标]
示例1:
输入:[具体输入]
输出:[期望输出]
示例2:
输入:[具体输入]
输出:[期望输出]
现在请处理:
输入:[实际输入]
输出:少样本提示模板(情感分析示例):
md
判断以下产品评论的情感倾向(正面/负面/中性),仅输出标签。
评论:"这个手机的电池续航太惊艳了,一整天不用充电!"
标签:正面
评论:"物流很慢,包装破损,但产品本身还行。"
标签:中性
评论:"完全不能用,开机就死机,浪费钱。"
标签:负面
评论:"界面设计很人性化,但价格有点贵。"
标签:2.3 样本选择策略(Example Selection)
质量 > 数量:1个高质量示例 > 3个模糊示例
选择原则:
- 覆盖边界情况:包含典型case和极端case(如空输入、超长输入)
- 一致性:示例风格与期望输出严格一致(如JSON格式示例中不能混有自然语言)
- 多样性:示例间差异度足够,避免模型过拟合到特定模式
动态样本检索(RAG增强):
md
┌─────────────────────────────────────────────────────────────┐
│ 动态少样本提示架构 │
├─────────────────────────────────────────────────────────────┤
│ 用户Query ──► 向量检索 ──► 相似历史问答对Top-K │
│ │ │ │
│ │ ▼ │
│ │ [示例1, 示例2, ..., 示例K] │
│ │ │ │
│ ▼ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 组合提示词 │ │
│ │ 系统指令 + 动态示例 + 用户当前问题 │ │
│ └─────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ LLM推理 │
└─────────────────────────────────────────────────────────────┘三、角色提示与上下文管理:精准控制的艺术
3.1 角色定义方法(Role Definition)
角色提示公式:
md
你是一位[专业领域]的[专家级别],拥有[具体经验]。
你的任务是[任务描述]。
你的回答风格应该[风格描述]。
限制条件:[约束清单]角色设计维度:
| 维度 | 描述 | 示例 |
|---|---|---|
| 身份 | 职业/角色 | 资深Python架构师、儿科医生、法律顾问 |
| 经验 | 工作年限/项目经历 | 10年微服务架构设计经验、处理过1000+临床病例 |
| 风格 | 表达方式 | 严谨学术型、通俗科普型、幽默轻松型 |
| 约束 | 行为边界 | 不生成可执行代码仅提供伪代码、不提供医疗建议仅作科普 |
高级技巧:多重角色协作
md
角色1(批判者):审查以下代码的安全漏洞
角色2(优化者):提出性能优化建议
角色3(文档编写者):生成API文档
请分别扮演以上三个角色,对同一代码进行三轮分析,最后综合输出报告。3.2 上下文长度控制(Context Length Control)
长文本处理策略:
- 滑动窗口(Sliding Window):保留最近N轮对话,丢弃早期内容
- 摘要压缩(Summarization):对早期对话进行LLM摘要,保留关键决策点
- 关键信息提取(Key-Value Memory):将关键实体(如用户名、偏好设置)存入键值对,每次请求前置
上下文截断策略:
md
当前Token数: 3500/4096 (85%)
触发策略:
├── 优先移除: 早期系统提示中的冗余说明
├── 次级移除: 用户确认过的历史对话轮次
├── 保留重点: 当前任务关键参数、用户约束条件
└── 紧急处理: 当达到95%时,对历史记录进行LLM摘要压缩3.3 动态上下文调整(Dynamic Context Adjustment)
自适应上下文机制:
- 任务识别阶段:先让模型识别任务类型,再加载对应领域的上下文
- 实时反馈调整:根据用户反馈("太详细了"/"太简略了")动态调整上下文中的示例复杂度
- 记忆分层:区分短期记忆(当前会话)和长期记忆(用户画像),动态加权
四、提示词优化技巧:数据驱动的迭代
4.1 迭代测试方法(Iterative Testing)
PDCA循环在Prompt Engineering中的应用:
md
┌─────────────────────────────────────────────────────────────┐
│ 提示词迭代优化循环 │
├─────────────────────────────────────────────────────────────┤
│ │
│ Plan(设计) ────────┐ │
│ • 编写初始提示词 │ │
│ • 定义成功标准 │ │
│ │ │ │
│ ▼ │ │
│ Do(执行) ──────────┤ │
│ • 批量测试(100+样本) │ │
│ • 记录输出结果 │ │
│ │ │ │
│ ▼ │ │
│ Check(检查) ───────┤ │
│ • 对比期望输出 │ │
│ • 识别失败模式 │ │
│ • 误差归类 │ │
│ │ │ │
│ ▼ │ │
│ Act(优化) ─────────┘ │
│ • 针对失败模式修改提示词 │
│ • 增加示例或约束条件 │
│ • 回到Plan阶段 │
│ │
└─────────────────────────────────────────────────────────────┘4.2 提示词评估指标(Evaluation Metrics)
自动化评估维度:
| 指标 | 计算方法 | 工具 |
|---|---|---|
| 语义相似度 | 使用Sentence-BERT计算输出与参考答案的余弦相似度 | sentence-transformers |
| JSON合规率 | 检查输出是否符合指定JSON Schema | jsonschema |
| 幻觉检测 | 使用RAGAS或自定义事实核查Prompt验证事实准确性 | LangChain Eval |
| 风格一致性 | 对比输出与示例风格的KL散度 | 自定义分类器 |
| 延迟/成本 | 记录Token消耗和响应时间 | OpenAI API日志 |
人工评估维度:
- 用性(Helpfulness):是否解决用户问题
- 流畅性(Fluency):语言是否自然
- 安全性(Safety):是否包含有害内容
4.3 A/B测试实践(A/B Testing)
提示词版本对比框架:
实施步骤:
- 控制变量:仅修改提示词中的一个变量(如示例数量、角色描述)
- 流量分配:将测试集随机分为A/B两组(各50%)
- 统计显著性:使用卡方检验或t检验判断差异是否显著(p<0.05)
- 胜出版本迭代:将获胜版本设为新的Baseline,继续下一组A/
A/B测试记录模板:
md
测试日期: 2026-03-13
测试目标: 提升JSON输出合规率
变量: 在提示词末尾增加"必须输出合法JSON,不要添加注释" vs 无此约束
样本量: 每组200条
指标结果:
- 版本A(有约束): 合规率 94%, 平均延迟 1.2s
- 版本B(无约束): 合规率 67%, 平均延迟 1.1s
结论: 版本A显著优于版本B(p<0.01),采用版本A五、常见错误与调试方法:排错手册
5.1 歧义提示处理(Ambiguity Resolution)
常见歧义类型:
| 歧义类型 | 表现 | 解决方案 |
|---|---|---|
| 指代不明 | "它"、"这个"指代不清 | 强制使用完整名词 |
| 边界模糊 | "长文章"多长算长? | 量化定义(>1000字) |
| 多义词汇 | "苹果"(水果/公司) | 添加上下文("苹果公司") |
| 缺少主语 | "分析一下" | 明确分析对象和分析维度 |
调试技巧:追问法
当模型输出不符合预期时,在提示词后追加:
md
请解释:
1. 你理解的任务目标是什么?
2. 你使用了哪些输入信息?
3. 你为什么选择这种输出格式?5.2 输出不一致解决(Consistency Issues)
温度参数(Temperature)调控:
- Temperature=0:确定性输出,适合代码生成、事实问答
- Temperature=0.7-1.0:创造性输出,适合文案创作、头脑风暴
提升一致性的方法: - 种子固定:设置seed参数确保可复现
- Self-Consistency采样:多次采样,投票选择最常见答案(适用于逻辑推理题)
- 输出格式强制:使用JSON Schema或正则表达式约束输出结构
思维链(Chain-of-Thought)提升推理一致性:
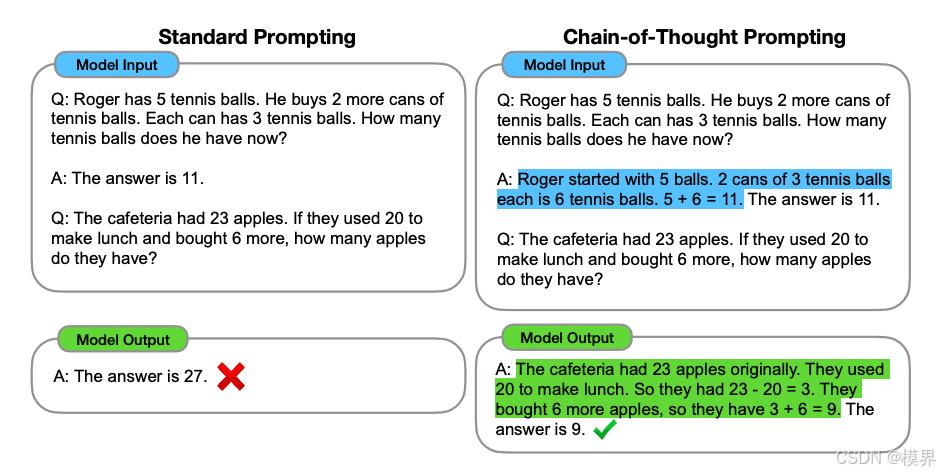
CoT提示模板:
md
问题:一个水箱有5个进水管,同时打开需要6小时注满;有3个出水管,同时打开需要10小时排空。
如果同时打开2个进水管和1个出水管,需要多久注满?
请按以下步骤解答:
1. 计算单个进水管的效率
2. 计算单个出水管的效率
3. 计算2进1出的净效率
4. 计算注满时间
逐步思考并给出最终答案。5.3 提示词调试工具(Debugging Tools)
工具链推荐:
| 工具 | 功能 | 适用场景 |
|---|---|---|
| LangSmith | 追踪、监控、评估提示词链 | 生产环境LLM应用 |
| PromptLayer | 版本管理、A/B测试、性能监控 | 团队协作优化 |
| OpenAI Playground | 快速迭代测试、参数调优 | 原型设计阶段 |
| Weights & Biases | 实验追踪、超参数搜索 | 系统化提示词工程 |
| Helicone | 成本分析、延迟监控 | 成本控制场景 |
调试检查清单(Checklist):
md
□ 是否使用了最新版模型?
□ 提示词是否包含必要的上下文?
□ 示例是否覆盖了边界情况?
□ 输出格式约束是否明确?
□ 是否测试了对抗性输入(越狱、提示注入)?
□ 延迟和成本是否在可接受范围内?
□ 是否记录了版本变更历史?六、总结:提示词工程能力矩阵
md
┌─────────────────────────────────────────────────────────────┐
│ Prompt Engineering 能力成熟度模型 │
├─────────────────────────────────────────────────────────────┤
│ │
│ Level 5 (专家级) │
│ • 设计多Agent协作提示词架构 │
│ • 构建自动化评估与优化流水线 │
│ • 掌握对抗性提示防御技术 │
│ │
│ Level 4 (进阶级) │
│ • 熟练运用Few-Shot与CoT技术 │
│ • 建立A/B测试与数据驱动优化体系 │
│ • 管理复杂长上下文与记忆机制 │
│ │
│ Level 3 (熟练级) │
│ • 使用角色提示提升输出质量 │
│ • 掌握任务分解与多步骤推理 │
│ • 能够调试并解决常见错误 │
│ │
│ Level 2 (基础级) │
│ • 编写明确、简洁的指令 │
│ • 理解Zero-Shot与Few-Shot区别 │
│ • 使用基础格式约束(JSON/Markdown) │
│ │
│ Level 1 (入门级) │
│ • 直接提问,无结构化设计 │
│ • 不了解上下文管理 │
│ • 依赖单次尝试,无迭代优化 │
│ │
└─────────────────────────────────────────────────────────────┘- 仅供学习参考,请勿用于商业用途。*