目录
[前言:LangGraph 到底是个啥?🤔](#前言:LangGraph 到底是个啥?🤔)
[第一部分:LangGraph 核心基础🧩](#第一部分:LangGraph 核心基础🧩)
[1.1 状态(State):所有人的共享小本本 📝](#1.1 状态(State):所有人的共享小本本 📝)
[1.2 节点(Node):干活的小能手 🤖💪](#1.2 节点(Node):干活的小能手 🤖💪)
[1.3 边(Edge):怎么走,你说了算 🧭](#1.3 边(Edge):怎么走,你说了算 🧭)
[1.4 LangGraph构建大模型的问答流程 🧠✨](#1.4 LangGraph构建大模型的问答流程 🧠✨)
[第二部分:LangGraph 核心代理模式--- 智能体的三种"人设" 🎭](#第二部分:LangGraph 核心代理模式— 智能体的三种“人设” 🎭)
[2.1 路由代理(Router):聪明的"分拣员" 📬](#2.1 路由代理(Router):聪明的“分拣员” 📬)
[2.2 工具代理(Tool Calling Agent):会"摸鱼"但能自己找工具 🧰](#2.2 工具代理(Tool Calling Agent):会“摸鱼”但能自己找工具 🧰)
[2.3 自治循环代理(ReAct):推理 - 行动的迭代优化🔄](#2.3 自治循环代理(ReAct):推理 - 行动的迭代优化🔄)
[第三部分:LangGraph 长短期记忆机制🐟🐘](#第三部分:LangGraph 长短期记忆机制🐟🐘)
[3.1 短期记忆:基于Checkpointer的"对话录像带" 📼](#3.1 短期记忆:基于Checkpointer的“对话录像带” 📼)
[3.2 长期记忆:基于 Store 的"永不丢失的云笔记" ☁️](#3.2 长期记忆:基于 Store 的“永不丢失的云笔记” ☁️)
[第四部分:Human-in-the-Loop(HIL)--- "别着急,让我先问问老板" 👨💼](#第四部分:Human-in-the-Loop(HIL)— “别着急,让我先问问老板” 👨💼)
[第五部分:LangGraph 多智能体(Multi-agent)------ 组团开黑,五个位置各司其职 🎮](#第五部分:LangGraph 多智能体(Multi-agent)—— 组团开黑,五个位置各司其职 🎮)
[5.1 Single-Agent 的核心局限 🥲](#5.1 Single-Agent 的核心局限 🥲)
[5.2 Multi-agent 核心概念🧑🤝🧑](#5.2 Multi-agent 核心概念🧑🤝🧑)
[5.3 Multi-agent 实现方式](#5.3 Multi-agent 实现方式)
[总结:LangGraph ------ 智能体开发的"瑞士军刀" 🔪](#总结:LangGraph —— 智能体开发的“瑞士军刀” 🔪)
前言:LangGraph 到底是个啥?🤔
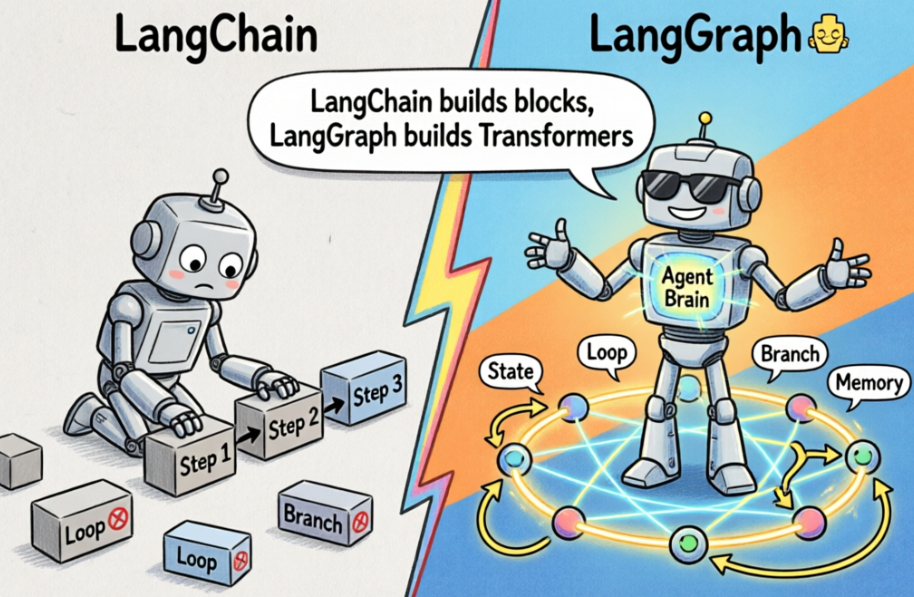
简单说:LangGraph 不是要"干掉"LangChain 的全新框架 ,而是 LangChain 家族里那个 "长了脑子的增强版小弟" ------专门用来搞定那些让普通 Chain 头秃的复杂智能体任务。🧠💥
对比一下你就懂了:
| 对比维度 | LangChain 🧱 | LangGraph 🕸️ |
|---|---|---|
| 核心架构 | 链(Chain),说白了就是直线或单向流水线,走完拉倒 | 图(Graph) ,核心是带循环的有状态图,能拐弯、能绕圈、能回头 👻 |
| 控制流 | 线性执行,一条道走到黑 🚂 | 原生支持循环、条件分支、并行,想怎么走就怎么走 🎮 |
| 状态管理 | 状态在链的组件间顺序传递,像接力棒 🏃 | 显式、共享的全局状态,所有节点都能看到、都能改 📝 |
| 适用场景 | 标准化、确定性流程:文档问答、数据提取、简单多步骤任务 → 好用的工具人 🛠️ | 复杂、有状态、非确定性工作流:多轮对话 Agent、决策模拟、多智能体协作、需要试错调整的任务 → 真正的智能体大脑 🧠✨ |
所以:LangChain 搭积木,LangGraph 造变形金刚🤖
第一部分:LangGraph 核心基础🧩
LangGraph 之所以能"活"起来,全靠三大灵魂要素:
-
状态(State) 📝
智能体的"记忆"和"当前心情"。所有节点都能读、能写,像共享的便签本。 -
节点(Node) 🟣
每个节点就是一个"能干活的单元",比如"思考"、"调用工具"、"回答问题"......你可以把它们想象成一个个小机器人 🤖。 -
边(Edge) 🔗
连接节点的那条路。普通边就是"做完 A 就做 B",条件边则是"如果今天周一,走左边;否则走右边"。超灵活~

三者合体 ,就变成了一个"有状态的智能体骨架":
能记住你上一句说了啥,能走循环,能自己决定下一步干啥。
不再是傻傻的直线流水线,而是一个会思考、会犹豫、会回头的小家伙。🧠💡
一句话总结:State 是记忆,Node 是手脚,Edge 是路线图 ------ 合在一起,就是能跑能跳能回头的 AI 智能体!🏃🔄
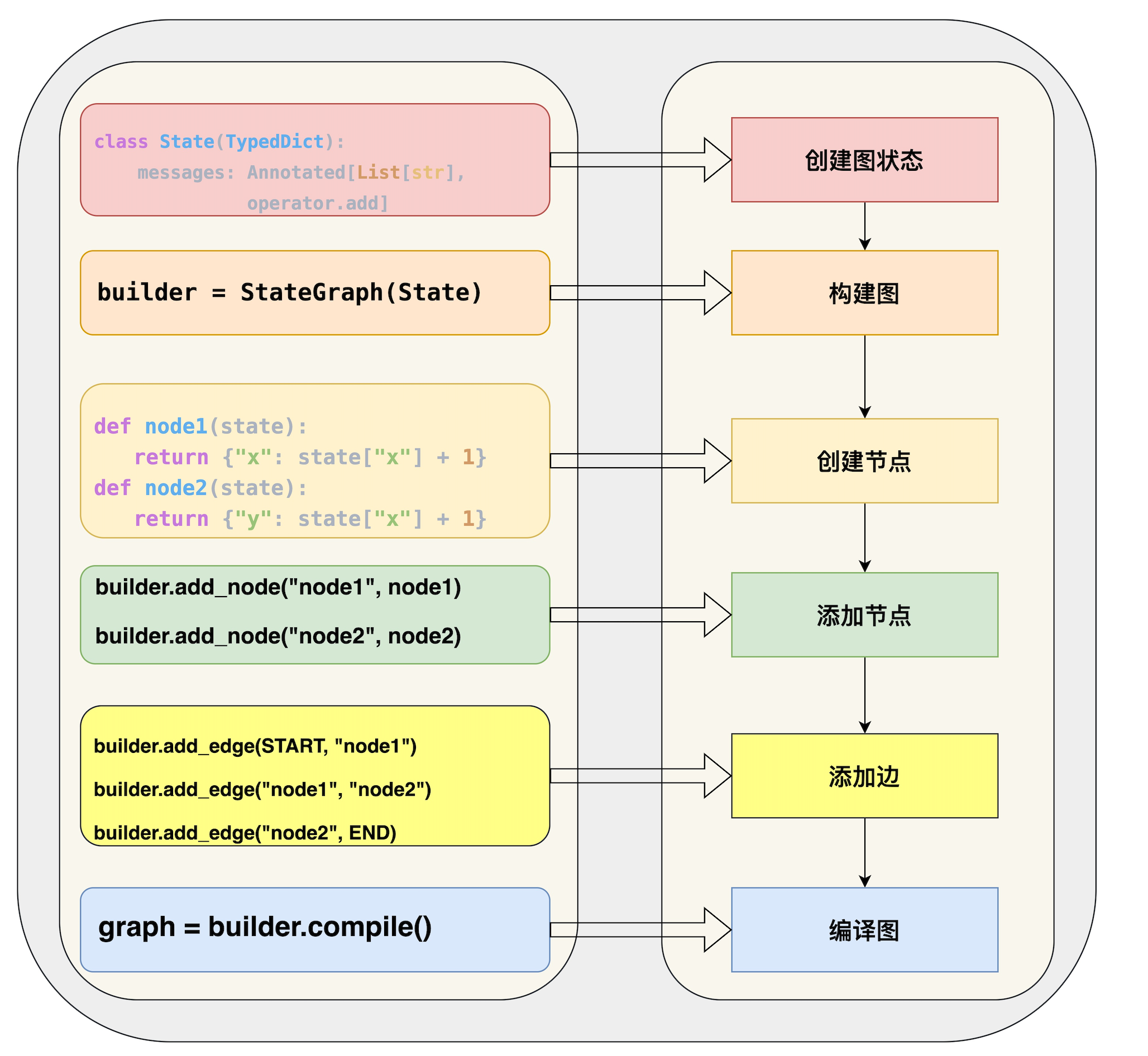
1.1 状态(State):所有人的共享小本本 📝
状态就是 LangGraph 中 所有节点都能读、能写 的公共数据区。它像一个放在桌子中央的"任务进度本",谁干了啥、中间结果、下一步要干啥......全写在上头。
✅ 支持跨节点数据流通与复用 ------ A 节点写,B 节点读,C 节点改,超级方便。
1. 状态定义的两种方式
(1)TypedDict ------ 轻量版,够用就行 🪶(Python 3.8+)
适合简单场景,只做最基本的类型提示,不装任何花哨依赖:
python
from typing import TypedDict, List, Optional, Annotated
import operator
class AgentState(TypedDict):
input: str # 用户原始问题
reasoning: List[str] # 中间推理过程,按步骤存储
tool_outputs: List[str] # 工具调用返回结果集合
answer: Optional[str] # 最终生成的答案
steps: Annotated[int, operator.add] # 执行步骤计数,支持自动累加(2)Pydantic ------ 生产环境推荐 🏭(功能更强)
支持数据验证、字段描述、默认值,还能动态加字段,干活更放心:
python
from pydantic import BaseModel, Field
from typing import List, Optional
class AgentState(BaseModel):
input: str = Field(description="用户原始查询文本")
reasoning: List[str] = Field(default_factory=list, description="智能体推理链路日志")
tool_outputs: List[str] = Field(default_factory=list, description="工具调用结果集合")
answer: Optional[str] = Field(default=None, description="最终响应答案")
steps: int = Field(default=0, description="任务执行步骤计数器")
class Config:
extra = "allow" # 允许动态添加额外字段,提升灵活性2. 状态管理进阶:Reducer 函数 ------ 状态怎么更新你来定 🎛️
Reducer 决定了 新状态怎么和旧状态融合。不同字段可以有不同的更新策略:
-
默认 Reducer:直接覆盖(适合单值字段)
-
operator.add:列表追加,比如把新的推理步骤拼到已有列表后面
python
class State(TypedDict):
messages: Annotated[List[str], operator.add]- add_messages (LangGraph 内置):智能合并消息,按消息 ID 去重 + 增量更新,多轮对话的神器 ✨
python
from langgraph.graph import add_messages
from typing import TypedDict, List
class MessageState(TypedDict):
# 按消息ID智能融合,重复消息自动覆盖,新消息追加
messages: Annotated[List[AnyMessage], add_messages]一句话:State 是智能体的"记忆裤兜",Reducer 决定了你怎么往里头塞东西 ------ 是直接换新的,还是在旧账本上追加新日记。🧦📖
1.2 节点(Node):干活的小能手 🤖💪
节点就是 一个能干活儿的函数。它读取状态,干点啥,再把状态改一改,返回给下一个节点。
✅ 输入输出都跟全局状态对齐 ------ 你用 State 传,它用 State 回。
✅ 支持同步/异步(想快就 async)
✅ 里面随便写:调 LLM、跑工具、算数据、if else 随便你。
示例:基础节点实现
python
def llm_inference(state: AgentState) -> AgentState:
"""LLM推理节点:基于用户输入与历史推理链路生成思考结果"""
prompt = f"用户问题:{state['input']}\n历史思考:{state['reasoning']}"
reasoning = llm.invoke(prompt).content
state["reasoning"].append(reasoning)
return state节点就像流水线上的工人:接过材料(State),加工一下,再传给下一个工人。👩🏭➡️👨🔧
1.3 边(Edge):怎么走,你说了算 🧭
边决定了 从当前节点下一步跳到哪个节点。它是 LangGraph 控制流的心脏。
两种边:
① 静态边 ------ 固定路线 🛤️
做完 A 永远走 B,没得商量。
python
# 推理后固定调用工具
workflow.add_edge("llm_inference", "tool_calling") ② 条件边 ------ 动态选择 🤔
根据当前状态(比如推理结果里有没有"需要查询"这几个字),现场决定下一步走哪条路。
python
def route_decision(state: AgentState) -> str:
"""基于推理结果决定下一步:需工具调用则跳转工具节点,否则直接生成答案"""
return "tool_calling" if "需要查询" in state["reasoning"][-1] else "answer_generation"
workflow.add_conditional_edges("llm_inference", route_decision)静态边像地铁 ------ 固定线路。条件边像导航 ------ 堵车了会自己换路。🚇➡️🗺️
1.4 LangGraph构建大模型的问答流程 🧠✨
第二部分:LangGraph 核心代理模式--- 智能体的三种"人设" 🎭
LangGraph 基于图结构,给你准备了三种"现成剧本"。从简单听话到自主狂飙,总有一款适合你:
-
路由代理:前台小姐姐,按问题类型转接不同专家 📞
-
工具代理:多才多艺的助理,自己判断用哪个工具 🛠️
-
自治循环代理:死磕型选手,想一步做一步,不行再回头 🤔➡️🏃➡️🔄

2.1 路由代理(Router):聪明的"分拣员" 📬
1. 核心机制
收到用户问题 → 分类 → 扔给对应的专业节点(技术/账单/退款...) → 各节点处理完再汇合。
就像医院挂号:发烧去内科,骨折去骨科,绝不分错。🩺
一句话 :if else 的究极进化体,但优雅得像交响乐指挥。
2. 示例代码:智能客服路由
python
from typing import Literal
from langgraph.graph import StateGraph, END
class RouterState:
user_query: str
query_type: Literal["tech_support", "billing", "general", "refund"] = None
history: list = []
response: str = None
def classify_query(state: RouterState) -> RouterState:
"""分类用户查询类型"""
query = state.user_query.lower()
if any(word in query for word in ["error", "bug", "crash", "install"]):
state.query_type = "tech_support"
elif any(word in query for word in ["payment", "invoice", "charge", "bill"]):
state.query_type = "billing"
elif any(word in query for word in ["refund", "return", "cancel"]):
state.query_type = "refund"
else:
state.query_type = "general"
state.history.append(f"查询分类为: {state.query_type}")
return state
def route_based_on_type(state: RouterState) -> str:
"""路由函数:根据查询类型选择路径"""
return state.query_type
# 构建路由图
workflow = StateGraph(RouterState)
# 添加分类节点
workflow.add_node("classify", classify_query)
# 添加专业处理节点
workflow.add_node("tech_support", tech_support_handler)
workflow.add_node("billing", billing_handler)
workflow.add_node("general", general_handler)
workflow.add_node("refund", refund_handler)
# 设置路由逻辑
workflow.add_conditional_edges(
"classify",
route_based_on_type,
{
"tech_support": "tech_support",
"billing": "billing",
"general": "general",
"refund": "refund"
}
)
# 各处理节点结束后统一到响应节点
for node in ["tech_support", "billing", "general", "refund"]:
workflow.add_edge(node, "format_response")
workflow.add_edge("format_response", END)
workflow.set_entry_point("classify")2.2 工具代理(Tool Calling Agent):会"摸鱼"但能自己找工具 🧰
通过将 LLM 与工具集绑定,让模型具备自主判断是否调用工具、调用哪个工具的能力,核心流程为:用户输入 → LLM 意图识别 → 工具调用 → 结果整合 → 生成答案。
1. 核心机制
-
工具定义 :使用
@tool装饰器或继承BaseTool类 -
绑定工具 :
bind_tools()让LLM知道可用工具 -
工具选择:LLM根据上下文动态选择合适工具
-
执行反馈:工具执行结果返回给代理进行下一步决策
2. 示例代码:天气信息查询代理
python
from typing import TypedDict, Annotated, Sequence
from langgraph.graph import StateGraph, END, MessageGraph
from langgraph.prebuilt import ToolNode, tools_condition
from langchain_openai import ChatOpenAI
from langchain.tools import tool
from datetime import datetime
# 1. 定义两个小工具
@tool
def get_weather(city: str, date: str = None) -> str:
"""获取城市天气信息"""
if date is None:
date = datetime.now().strftime("%Y-%m-%d")
weather_data = {
"北京": {"2024-01-15": "晴,-5~3°C"},
"上海": {"2024-01-15": "小雨,2~8°C"}
}
forecast = weather_data.get(city, {}).get(date, "暂无数据")
return f"{city}{date}天气:{forecast}"
@tool
def calculator(expression: str) -> str:
"""计算数学表达式"""
try:
result = eval(expression.replace("^", "**"))
return f"{expression} = {result}"
except:
return "计算错误,请检查表达式"
# 2. 绑定工具到 LLM
tools = [get_weather, calculator]
llm = ChatOpenAI(model="gpt-3.5-turbo")
llm_with_tools = llm.bind_tools(tools) # 🔑 关键一步:告诉 LLM 你有这些工具可用
# 3. 造一个极简的 MessageGraph
graph_builder = MessageGraph()
tool_node = ToolNode(tools)
graph_builder.add_node("model", llm_with_tools)
graph_builder.add_node("tools", tool_node)
graph_builder.set_entry_point("model")
graph_builder.add_conditional_edges("model", tools_condition) # 内置判断:要不要调用工具?
graph_builder.add_edge("tools", "model") # 工具跑完回到 model 再总结
agent = graph_builder.compile()🧠 小贴士 :
tools_condition自动检查 LLM 输出里有没有tool_calls,有就去tools节点,否则直接结束。太贴心了!
2.3 自治循环代理(ReAct):推理 - 行动的迭代优化🔄
1. 核心机制
ReAct = Reason (推理)+ Act(行动)。它不会一次性想完,而是:
观察 → 思考 → 行动 → 观察结果 → 再思考 → 再行动 ... 直到满意。
像你修 bug:看报错 → 猜原因 → 改代码 → 看效果 → 不行再改。🐞
2. 示例代码:天气信息查询代理(用 create_react_agent 一行搞定)
python
from langgraph.prebuilt import create_react_agent
from langchain_openai import ChatOpenAI
from langchain.tools import tool
# 1. 定义工具(假装搜索真实数据)
@tool
def search_web(query: str) -> str:
"""搜索网络获取信息"""
mock_data = {
"LangGraph": "LangGraph 是 LangChain 生态下的图计算框架,支持循环和状态",
"ReAct": "ReAct = Reasoning + Acting,通过思考-行动循环解决复杂问题",
"天气": "今天北京:晴,15~25°C"
}
return mock_data.get(query, f"关于 {query} 我找到了这些信息...... (模拟结果)")
@tool
def calculator(expr: str) -> str:
try:
result = eval(expr.replace("^", "**"))
return f"{expr} = {result}"
except:
return "算不了,检查表达式吧"
# 2. 创建 ReAct 代理(一行!)
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
react_agent = create_react_agent(llm, [search_web, calculator])
# 3. 用它来回答一个需要多步的复杂问题
response = react_agent.invoke({
"messages": [("human", "LangGraph 和 ReAct 有什么关系?顺便帮我算一下 2^10 + 365")]
})
print(response["messages"][-1].content)💡 ReAct 代理的内心独白 :
"第一步,我搜一下 LangGraph 是啥...... 哦,图计算框架。
第二步,我再搜 ReAct...... 哦,推理+行动。
第三步,它俩的关系? LangGraph 能完美实现 ReAct 模式啊!
第四步,用户还要算数,我掏出计算器...... 1024+365=1389。搞定!" 🎯
第三部分:LangGraph 长短期记忆机制🐟🐘
LangGraph 给你两套记忆系统:
-
短期记忆(Checkpointer):一个对话线程内,记得你上一句说了啥。像鱼的记忆,但只在当前聊天窗口有效。
-
长期记忆(Store):跨对话、跨用户,记住用户偏好、账号信息等。像大象,忘不掉。

3.1 短期记忆:基于Checkpointer的"对话录像带" 📼
1. 核心机制:检查点(Checkpointer)
在图执行的每个"超级步骤"后自动拍一张状态快照,按 thread_id 存储。同一个线程里,随时可以往前翻、往后跳,甚至"时光倒流"重新来过。
2. 核心实现类型
| 实现类 | 存储位置 | 适合谁 | 优点 |
|---|---|---|---|
MemorySaver |
内存 | 本地测试、玩一玩 | 快,零配置 |
SqliteSaver |
SQLite 文件 | 小项目、个人开发 | 持久化,不怕重启 |
PostgresSaver |
PostgreSQL | 生产环境、高并发 | 靠谱、分布式 |
3. 示例代码:带短期记忆的聊天机器人
python
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import StateGraph
# 1. 定义状态与节点(省略节点实现)
class ChatState(TypedDict):
messages: List[str]
step: int
# 2. 构建图(省略节点添加与边配置)
graph = StateGraph(ChatState)
# ... 配置节点与控制流 ...
# 3. 配置Checkpointer实现短期记忆
checkpointer = MemorySaver()
app = graph.compile(checkpointer=checkpointer)
# 4. 带线程ID的调用(线程ID用于隔离不同对话上下文)
config = {"configurable": {"thread_id": "user_123"}}
# 第一次调用:初始化状态
app.invoke({"messages": ["你好,我是用户"], "step": 1}, config=config)
# 第二次调用:可访问历史状态(如前序消息)
result = app.invoke({"messages": ["我刚才说了什么?"], "step": 2}, config=config)
print(result["messages"]) # 包含第一次调用的历史消息🗣️ 用户内心:哇,它居然记得我刚才说过名字!
3.2 长期记忆:基于 Store 的"永不丢失的云笔记" ☁️
1. 核心机制
Store 模块提供跨线程、跨会话的持久化存储能力,采用**「命名空间(Namespace)+ 键值对(Key-Value)」**的存储模型,支持存储用户画像、业务规则、历史任务结果等需要长期复用的数据,可在任意线程、任意节点中读取。
2. 核心特性
- 支持 JSON 序列化的任意数据类型
- 基于命名空间隔离不同类型数据(如用户画像、业务配置)
- 与 Checkpointer 协同工作,可在状态中引用长期存储数据
3. 示例代码:记住用户偏好,下次见面直接喊"简洁侠"
python
from langgraph.storage.in_memory import InMemoryStore
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import StateGraph
# 1. 初始化长期存储与检查点
long_term_store = InMemoryStore() # 生产环境可替换为RedisStore等分布式存储
checkpointer = MemorySaver()
# 2. 构建图并配置长短期记忆
graph = StateGraph(ChatState)
# ... 配置节点与控制流 ...
app = graph.compile(
checkpointer=checkpointer,
store=long_term_store # 传入长期存储模块
)
# 3. 存储长期数据(如用户偏好)
await long_term_store.aput(
namespace="user_profiles", # 命名空间:用户画像
key="user_123", # 键:用户ID
value={"preference": "喜欢简洁回答", "history_tasks": ["查询天气", "计算数据"]}
)
# 4. 在节点中读取长期数据(示例节点实现)
def user_profile_handler(state: ChatState) -> ChatState:
# 读取用户长期画像
profile = await long_term_store.aget("user_profiles", "user_123")
# 结合用户偏好生成响应
state["messages"].append(f"根据您的偏好,为您提供简洁回答:...")
return state🎯 应用场景:记住用户讨厌啰嗦 → 以后每次回答自动精简。跨对话有效!
第四部分:Human-in-the-Loop(HIL)--- "别着急,让我先问问老板" 👨💼
1. 核心机制 :
在图的某个节点前或后设置断点 (interrupt_before / interrupt_after),执行到那儿就暂停,等你人工审核或补信息。
底层依赖 Checkpointer 保存那一刻的状态,恢复时无缝衔接。

2. 核心实现流程
-
跑图 → 到断点停下 🛑
-
你调用
graph.get_state()看当前状态 👀 -
你调用
graph.update_state()塞入人工决策 ✍️ -
你调用
graph.invoke(None)恢复执行 🚀
3. 使用示例:敏感操作人工审核流程
python
from typing import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import MemorySaver
# 1. 定义状态结构
class AuditState(TypedDict):
user_input: str # 用户操作请求
model_response: Optional[str] # 系统响应
requires_approval: bool # 是否需要人工审核
human_feedback: str = "" # 人工反馈(approve/reject)
approved: bool = False # 审核结果
# 2. 核心节点实现
def analyze_request(state: AuditState) -> AuditState:
"""分析请求:判断是否为敏感操作"""
sensitive_keywords = ["删除", "转账", "修改密码", "注销账号"]
state["requires_approval"] = any(keyword in state["user_input"] for keyword in sensitive_keywords)
state["model_response"] = "该操作需人工审核" if state["requires_approval"] else "自动处理中"
return state
def human_review(state: AuditState) -> AuditState:
"""人工审核节点:处理审核结果"""
state["approved"] = (state["human_feedback"] == "approve")
state["model_response"] = "操作已批准" if state["approved"] else "操作被拒绝"
return state
def execute_operation(state: AuditState) -> AuditState:
"""执行操作节点:根据审核结果执行或拒绝操作"""
if state["approved"]:
state["model_response"] = f"已执行敏感操作:{state['user_input']}"
else:
state["model_response"] = "敏感操作未通过审核,已拒绝执行"
return state
# 3. 构建图
builder = StateGraph(AuditState)
builder.add_node("analyze", analyze_request)
builder.add_node("review", human_review) # 断点节点
builder.add_node("execute", execute_operation)
# 配置控制流
def route_by_approval(state: AuditState) -> str:
return "review" if state["requires_approval"] else "execute"
builder.add_edge(START, "analyze")
builder.add_conditional_edges("analyze", route_by_approval)
builder.add_edge("review", "execute")
builder.add_edge("execute", END)
# 4. 编译图并设置断点(依赖Checkpointer)
graph = builder.compile(
checkpointer=MemorySaver(),
interrupt_before=["review"] # 审核节点执行前暂停
)
# 5. 执行流程
config = {"configurable": {"thread_id": "audit_1"}}
# 第一步:触发敏感操作请求,执行至断点暂停
result = graph.invoke({"user_input": "转账1000元给用户A", "requires_approval": False}, config=config)
print(result["model_response"]) # 输出:该操作需人工审核
# 第二步:获取人工反馈并更新状态
snapshot = graph.get_state(config) # 获取断点状态
snapshot.values["human_feedback"] = "approve" # 模拟人工批准
graph.update_state(config, snapshot.values) # 更新状态
# 第三步:恢复执行(input设为None表示从断点继续)
final_result = graph.invoke(None, config=config)
print(final_result["model_response"]) # 输出:已执行敏感操作:转账1000元给用户A🧑💼 真实世界:删除生产数据库?先让技术总监在群里回个"同意"再继续。安全又合规。
第五部分:LangGraph 多智能体(Multi-agent)------ 组团开黑,五个位置各司其职 🎮
当单个智能体搞不定(比如既要分析数据,又要画图,还要写报告),那就上多智能体系统。
5.1 Single-Agent 的核心局限 🥲
| 痛点 | 描述 |
|---|---|
| 功能单一 | 一个模型没法同时是会计+厨师+律师 |
| 认知超载 | 工具太多时,模型会"精神分裂" |
| 容错性差 | 一个节点崩了,整个流程瘫痪 |
| 扩展性弱 | 加个新功能得改旧代码,牵一发动全身 |
多智能体就是分而治之,每个 Agent 只干自己最擅长的事,然后通过图协作。
5.2 Multi-agent 核心概念🧑🤝🧑
1. 定义
Multi-agent 系统是由多个独立智能体组成的协作网络,每个智能体聚焦特定领域(如数据分析、文档处理、业务决策),通过状态共享或消息传递实现协同,共同完成复杂任务。
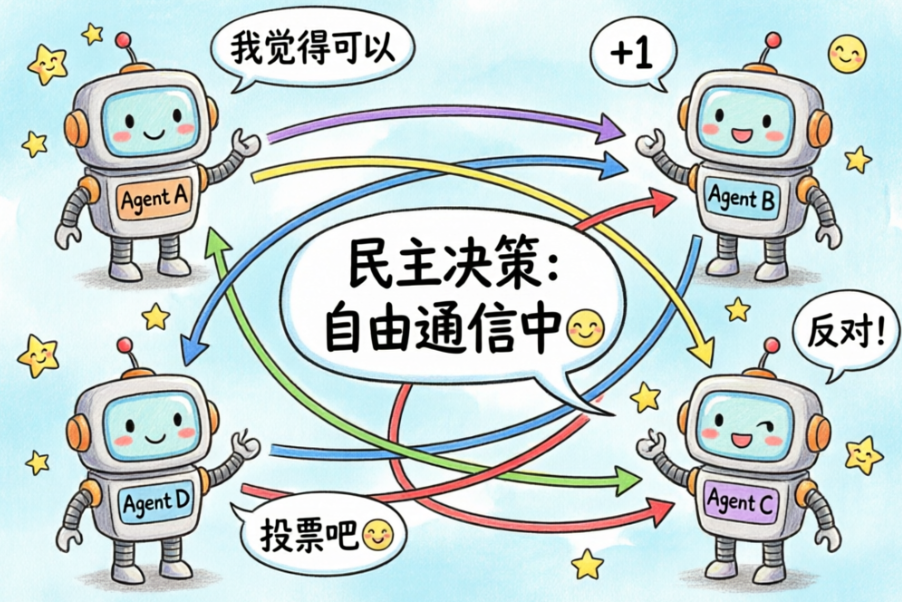
2. 通信架构
网络模式( NetWork**)**:代理自由通信,民主决策
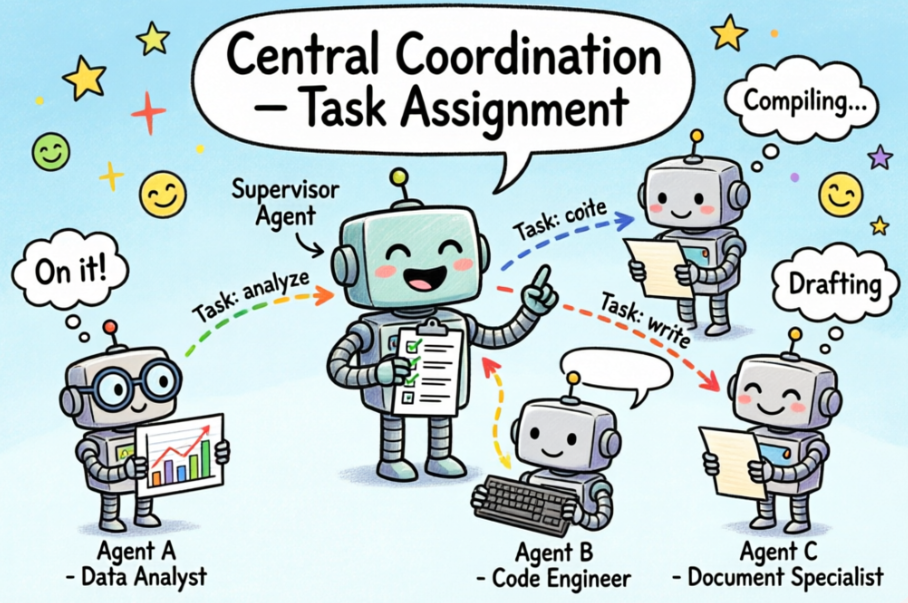
主管模式( Supervisor**)**:中央协调,任务分配
分层模式 :多级管理,逐级细化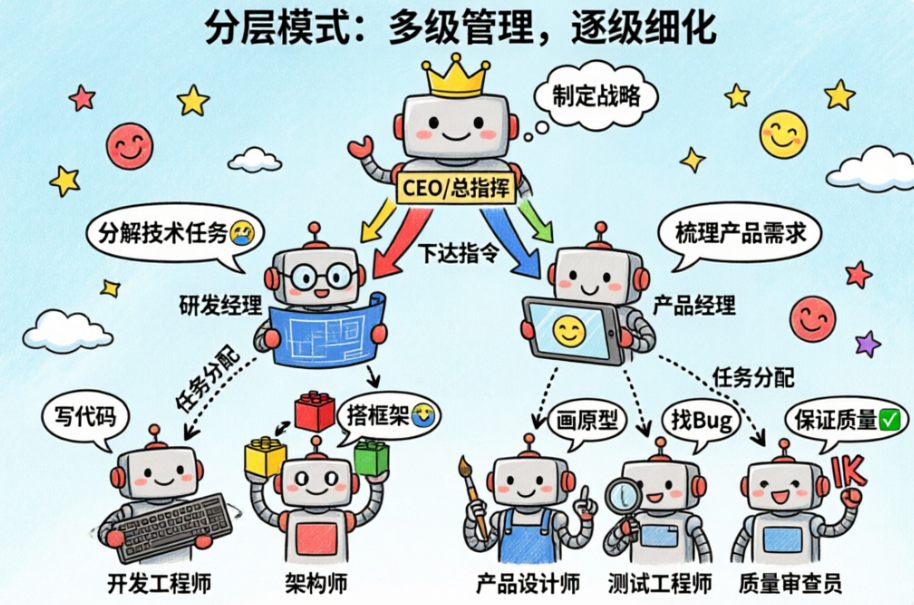
5.3 Multi-agent 实现方式
LangGraph 实现多智能体协作的核心是「状态传递」,即不同智能体(子图)通过共享状态或显式状态转换,实现数据交互。主要分为两种场景:
| 场景 | 特点 | 代码复杂度 | 适用场景 |
|---|---|---|---|
| 有共同键 | 状态直接传递,无需转换 | 简单 | 同构系统,各代理使用相同数据结构 |
| 无共同键 | 需要显式转换函数 | 复杂 | 异构系统,各代理有独立的数据模型 |
场景一:有共同状态键(简单,推荐 ✅)
所有 Agent 共用同一个 State 结构(或共享核心字段),状态直接传递,无需转换。
示例:任务拆解 → 数据分析 → 结果总结 流水线
python
from typing import TypedDict
from langgraph.graph import StateGraph
# 定义共享状态(所有智能体共用)
class SharedState(TypedDict):
task: str # 任务描述
messages: List[str] # 协作消息
results: dict # 各智能体执行结果
current_agent: str # 当前执行智能体
# 智能体1:任务解析代理
def task_parser(state: SharedState) -> SharedState:
state["messages"].append(f"解析任务:{state['task']} → 分解为数据分析+结果总结")
state["current_agent"] = "data_analyzer"
return state
# 智能体2:数据分析代理
def data_analyzer(state: SharedState) -> SharedState:
state["results"]["data_analysis"] = f"分析结果:{state['task']} 的核心指标为xxx"
state["messages"].append("数据分析完成,等待结果总结")
state["current_agent"] = "result_summarizer"
return state
# 智能体3:结果总结代理
def result_summarizer(state: SharedState) -> SharedState:
state["results"]["summary"] = f"最终总结:{state['results']['data_analysis']} → 业务建议xxx"
state["messages"].append("结果总结完成")
return state
# 构建多智能体协作图
workflow = StateGraph(SharedState)
workflow.add_node("task_parser", task_parser)
workflow.add_node("data_analyzer", data_analyzer)
workflow.add_node("result_summarizer", result_summarizer)
# 配置协作流程
workflow.set_entry_point("task_parser")
workflow.add_edge("task_parser", "data_analyzer")
workflow.add_edge("data_analyzer", "result_summarizer")
# 执行协作任务
result = workflow.invoke({
"task": "分析2024年Q3电商销售额趋势",
"messages": [],
"results": {},
"current_agent": "task_parser"
})
print(result["results"]["summary"])🚀 三行代码串起三个智能体:一个拆任务,一个算数据,一个写总结。各干各的,互不干扰。
场景二:无共同状态键(异构系统适配,稍麻烦 🧩)
当你有一个"老祖宗"写的 Agent B,它的 State 跟你的 A 完全不同。没关系,写两个转换函数 a_to_b 和 b_to_a 就行。
示例:Agent A(新系统)调用 Agent B(老古董)
python
from typing import TypedDict
from langgraph.graph import StateGraph
# 智能体A(父图)状态
class AgentAState(TypedDict):
user_query: str
processed_data: dict
status: str
# 智能体B(子图)状态(独立结构)
class AgentBState(TypedDict):
raw_input: str
analysis_output: str
is_completed: bool
# 状态转换函数:AgentA → AgentB
def a_to_b(state_a: AgentAState) -> AgentBState:
return AgentBState(
raw_input=state_a["user_query"],
analysis_output="",
is_completed=False
)
# 状态转换函数:AgentB → AgentA
def b_to_a(state_b: AgentBState, state_a: AgentAState) -> AgentAState:
state_a["processed_data"] = {"analysis": state_b["analysis_output"]}
state_a["status"] = "completed" if state_b["is_completed"] else "failed"
return state_a
# 智能体B核心逻辑
def agent_b_process(state: AgentBState) -> AgentBState:
state["analysis_output"] = f"异构智能体处理结果:{state['raw_input'].upper()}"
state["is_completed"] = True
return state
# 智能体A核心逻辑(整合AgentB)
def agent_a_process(state: AgentAState) -> AgentAState:
# 1. 状态转换:A → B
state_b = a_to_b(state)
# 2. 执行AgentB逻辑
state_b = agent_b_process(state_b)
# 3. 状态转换:B → A
return b_to_a(state_b, state)
# 构建父图(整合异构智能体)
workflow = StateGraph(AgentAState)
workflow.add_node("process", agent_a_process)
workflow.set_entry_point("process")
# 执行
result = workflow.invoke({
"user_query": "处理异构系统数据",
"processed_data": {},
"status": "pending"
})
print(result["processed_data"]) # 输出:{'analysis': '异构智能体处理结果:处理异构系统数据'}总结:LangGraph ------ 智能体开发的"瑞士军刀" 🔪
LangGraph 不是要取代 LangChain,而是给它装上了循环、状态、分支、记忆、人机协同、多智能体这些超级武器。
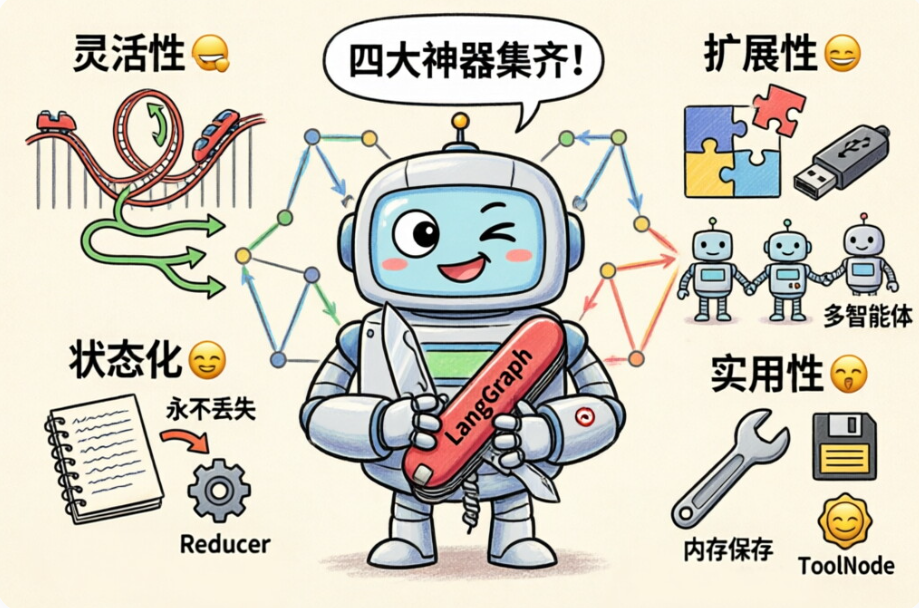
核心优势再强调一遍:
-
灵活性 🎢:图结构想怎么绕就怎么绕,循环分支并行随你画。
-
状态化 📦:全局共享状态 + 精细 Reducer,数据传递不再"传丢"。
-
扩展性 🧩:工具、多智能体、外部系统,插拔式接入。
-
实用性 🛠️:预置
ToolNode、create_react_agent、MemorySaver,开箱即用。
💬 一句话人话总结 :
如果你只想搭个"一问一答"的直线流水线,LangChain 就够了。
但如果你想造一个会记仇、会拐弯、会求助、会组团打副本 的智能体------
LangGraph 就是你的梦中情框。 😎
无论是构建智能客服、决策系统,还是多智能体协作平台,LangGraph 都能凭借其强大的图计算能力与生态兼容性,成为复杂智能体开发的优选框架。