论文标题:ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory
1.核心痛点
目前的 LLM Agent 往往是"健忘"的。虽然它们可以执行任务,但通常无法从过去的交互历史中学习:
重复错误 :遇到类似坑时,依然会掉进去
浪费洞察 :之前的成功经验或失败教训用完即弃,没有沉淀下来
现有记忆机制的局限 :目前的记忆方法要么只存原始流水账, 检索困难切噪声大,要么只存成功的流程(忽略了从失败中学习的重要性)
2.核心解决方案:ReasoningBank
作者提出了一种新的记忆框架 ReasoningBank ,它的核心逻辑不再是简单的"存储记录",而是"提炼策略"
存什么? 存储可泛化的推理策略 (Generalizable Reasoning Strategies)
怎么来? Agent 会自我复盘,从 成功 和 失败 的经验中提取出"为什么做对了"或"为什么做错了"的高层逻辑
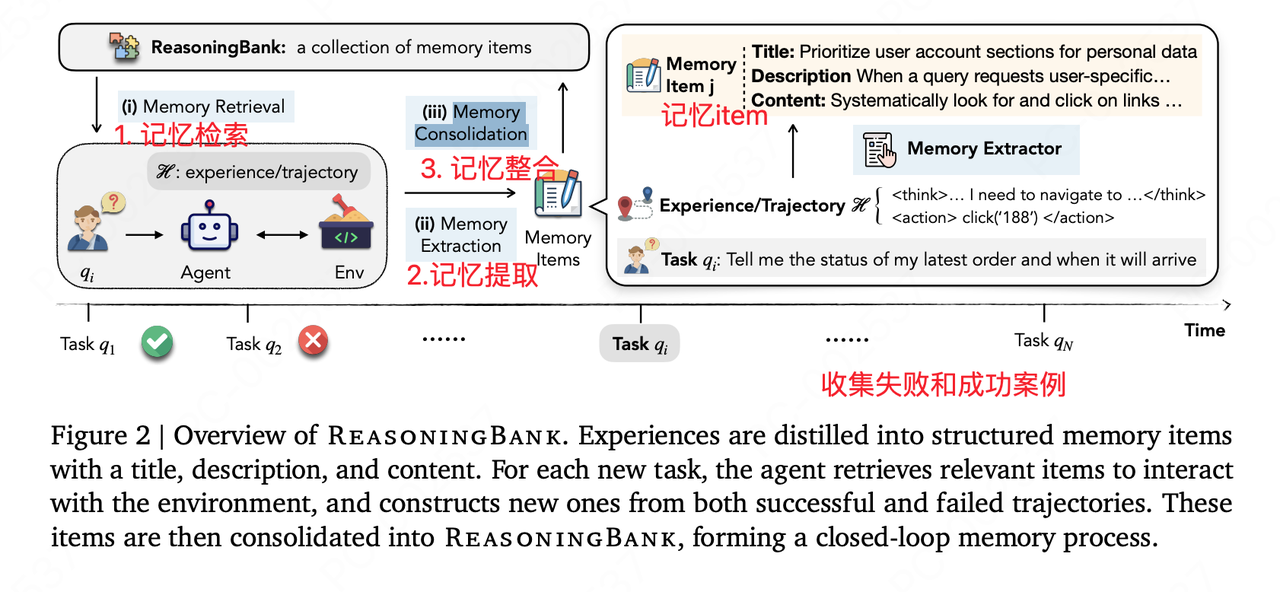
怎么用?
检索 (Retrieve) :遇到新任务时,先查 ReasoningBank 里的相关策略
指导 (Inform) :用这些策略指导当前的行动
更新 (Integrate) :任务结束后,将新的感悟再次提炼并存回库中,实现 自我进化
ReasoningBank 的工作流程是一个闭环系统,分为三个主要阶段:
阶段一:经验生成与判别 (Experience Synthesis)
Agent 尝试执行任务
系统会对执行结果进行自动判别(Self-judgment),区分出 Successful Trajectories (成功轨迹) 和 Failed Trajectories (失败轨迹)
关键点 :它不仅关注成功,也高度重视失败,因为失败往往包含更强的负反馈信号
阶段二:记忆提炼 (Memory Distillation)
这是论文的核心创新点。系统不会直接存储原始的轨迹(因为太长且包含噪声)
它使用一个更强的模型(或 Agent 自身的反思能力)来复盘
Input :任务描述 + 成功/失败的轨迹
Process :分析为什么成功?或者在哪一步做错了?
Output :生成一段精炼的 Reasoning Memory (推理记忆) 。例如:"在搜索 GitHub 仓库时,不要只看第一页结果,应该检查 README 文件确认是否是官方库。"
阶段三:记忆检索与利用 (Retrieval & Utilization)
当遇到新任务时,Agent 首先检索 ReasoningBank
Retriever :使用语义检索(Embedding 相似度)找到最相关的过往"推理记忆"
Context :将这些提取出来的"经验教训"放入 Prompt 中
Action :Agent 带着这些"前辈的智慧"去执行新任务,从而避开已知陷阱,复用成功套路
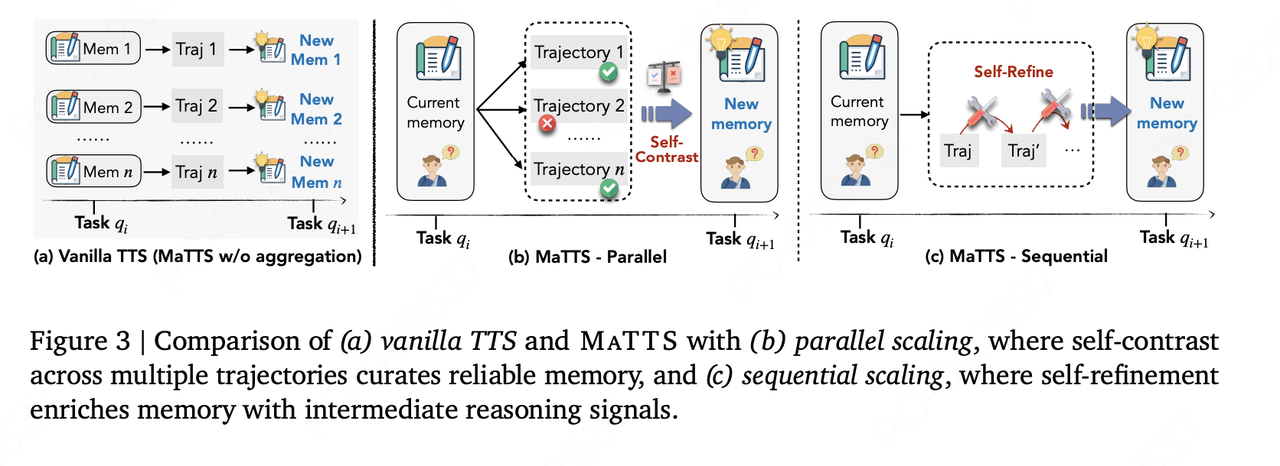
3.内存感知的测试时扩展:MaTTS (Memory-aware Test-Time Scaling)
为了让 Agent 进化得更快,论文还提出了 MaTTS 机制。这是一种测试时扩展 (Test-time Scaling) 方法
原理 :既然经验能提升能力,那就通过增加推理时的计算量(Compute),让 Agent 在测试时主动生成大量多样化的交互路径(模拟各种尝试)
作用 :
生成多条轨迹,然后独立地为每条轨迹生成记忆,其效果并不足够好
自我对比,通过大量试错,产生丰富的对比信号 (Contrastive Signals) (即:这样做行,那样做不行),这些信号能帮助 Agent合成更高质量的记忆策略
正向循环 :更好的记忆 -> 指导更有效的 Scaling -> 产生更好的经验 -> 更好的记忆
总结:不改动大模型,通过记忆的方式,收集案例,从成功和失败的经验中学习
参考资料:
https://arxiv.org/pdf/2509.25140
ReasoningBank:让Agent通过「推理记忆」自我进化
论文源码部分
原论文未提供代码,我们结合两个非官方的实现进行理解,着重看第一个
https://github.com/thakshak/ReasoningBank
https://github.com/Lanerra/reasoning-bank-slm
ReasoningBank 是一个 Python 库,为 LLM
驱动的智能体提供记忆框架。它允许智能体从过去的经验(无论是成功还是失败)中学习,以改进未
来任务的性能。该项目是基于研究论文《ReasoningBank: Scaling Agent Self-Evolving with
Reasoning Memory》的实现。
核心功能
- 经验蒸馏:自动将原始智能体轨迹蒸馏为结构化、可复用的推理模式
- 从成功和失败中学习:捕获成功尝试中的有效策略和失败中的预防性教训
- 可插拔的记忆后端:提供 ChromaDB 和 JSON 两种记忆存储后端
- LangChain 集成:提供无缝集成的 LangChain 记忆类
- 记忆感知测试时缩放(MaTTS):支持并行和顺序缩放以增强智能体学习
项目目录结构
python
ReasoningBank/
├── .github/
│ └── workflows/
│ └── ci.yaml # GitHub Actions CI 配置
├── docs/
│ ├── Makefile # Sphinx 文档构建
│ ├── make.bat # Windows 文档构建脚本
│ └── source/
│ ├── conf.py # Sphinx 配置文件
│ └── index.rst # 文档索引
├── examples/
│ ├── config.yaml # 示例配置文件
│ └── simple_usage.py # 简单使用示例
├── reasoningbank/
│ ├── __init__.py # 包初始化,导出核心类
│ ├── core/
│ │ ├── __init__.py
│ │ ├── agent.py # 智能体执行器创建
│ │ ├── bank.py # 核心类,协调记忆存储、蒸馏和检索
│ │ └── matts.py # MaTTS 实现(并行和顺序缩放)
│ ├── distillation/
│ │ ├── __init__.py
│ │ └── distill.py # 轨迹蒸馏函数
│ ├── integrations/
│ │ ├── __init__.py
│ │ └── langchain/
│ │ ├── __init__.py
│ │ └── memory.py # LangChain 记忆集成
│ ├── memory/
│ │ ├── __init__.py
│ │ ├── base.py # 记忆后端抽象接口
│ │ ├── chroma.py # ChromaDB 记忆后端实现
│ │ └── json.py # JSON 文件记忆后端实现
│ └── utils/
│ └── config.py # 配置加载工具
├── tests/
│ ├── test_bank.py # ReasoningBank 类测试
│ ├── test_integration.py # 集成测试
│ └── test_memory.py # 记忆后端测试
├── .gitignore # Git 忽略文件配置
├── config.yaml # 主配置文件
├── design.md # 设计文档
├── LICENSE # MIT 许可证
├── pyproject.toml # 项目元数据和依赖
├── README.md # 项目说明文档
├── requirements-dev.txt # 开发依赖
├── requirements.md # 依赖说明
├── requirements.txt # 运行时依赖
├── setup.py # 安装脚本
└── tasks.md # 任务清单(AWS Kiro 风格)我们从以下的几个方面阅读整个源码
- 配置和工具
- reasoningbank/utils/config.py
这个文件定义了置加载机制,将yaml文件读取成python的字典格式
python
"""Configuration management for the ReasoningBank library."""
import yaml
from typing import Dict, Any
def load_config(config_path: str = "config.yaml") -> Dict[str, Any]:
"""
Loads the configuration from a YAML file.
Args:
config_path (str): The path to the configuration file.
Returns:
Dict[str, Any]: A dictionary containing the configuration settings.
"""
with open(config_path, "r") as f:
return yaml.safe_load(f)- config.yaml - 可配置项
主要包括vector db后端类型,这里设置为chroma db,
集合名称
json memory的文件
embedding模型,这里使用的是transformers的all-MiniLM-L6-v2模型,一个384维的文本转向量模型
大模型配置, 使用的是本地配置的ollama, 模型是gemma3:270m,一个小参数量支持本地部署的模型,只有270M的参数
yaml
# Default configuration for the ReasoningBank library
# Memory backend settings
memory:
# The type of memory backend to use. Options: "chroma", "json"
backend: "chroma"
# Settings for the ChromaDB backend
chroma:
collection_name: "reasoning_bank"
# Settings for the JSON backend
json:
filepath: "memory.json"
# Embedding model settings
embedding_model:
# The embedding model to use. Options: "gemini-embedding-001", "sentence-transformers"
model_name: "embeddinggemma:300m"
# The name of the sentence-transformer model to use, if model_name is "sentence-transformers"
st_model_name: "all-MiniLM-L6-v2"
# LLM settings
llm:
# The LLM provider to use. Options: "ollama", "langchain.llms.Fake"
provider: "ollama"
# The model to use, if the provider is "ollama"
model: "gemma3:270m"2. 记忆接口和实现
- reasoningbank/memory/base.py - 定义 MemoryBackend 抽象接口
这个文件定义了记忆的抽象类,主要包含两个函数,add函数,把一批的memory item加入到记忆后端中,和query函数,传入query_embedding, 返回前k个最相关的memory item
python
"""Abstract base classes and implementations for memory backends."""
import abc
from typing import List, Dict
class MemoryBackend(abc.ABC):
"""
Abstract base class for memory backends.
This class defines the interface that all memory backends must implement.
It provides a standardized way to add and query memories, ensuring that
different storage solutions can be used interchangeably.
"""
@abc.abstractmethod
def add(self, items: List[Dict]):
"""
Adds a list of memory items to the backend.
Args:
items (List[Dict]): A list of dictionaries, where each dictionary
represents a memory item to be added.
"""
raise NotImplementedError
@abc.abstractmethod
def query(self, query_embedding: List[float], k: int) -> List[Dict]:
"""
Queries the backend for the k most similar items.
Args:
query_embedding (List[float]): The embedding of the query.
k (int): The number of most similar items to retrieve.
Returns:
List[Dict]: A list of the top k most similar memory items.
"""
raise NotImplementedError- reasoningbank/memory/json.py - 最简单的实现,易于理解
实现了以json文件的方式存储和查全的记忆后端
python
"""JSON file memory backend."""
import json
from typing import List, Dict
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
from .base import MemoryBackend
class JSONMemoryBackend(MemoryBackend):
"""
A simple memory backend that stores memories in a JSON file.
This implementation is intended for testing and development purposes. It
stores memories in a simple JSON file and uses cosine similarity to perform
queries. It is not recommended for production use due to performance
limitations.
"""
def __init__(self, filepath: str):
"""
Initializes the JSONMemoryBackend.
Args:
filepath (str): The path to the JSON file where memories will be
stored.
"""
# 初始化记忆后端
self.filepath = filepath
self.data = self._load()
def _load(self) -> List[Dict]:
"""
Loads memories from the JSON file.
从json文件中加载记忆
"""
try:
with open(self.filepath, "r") as f:
return json.load(f)
except FileNotFoundError:
return []
def _save(self):
"""
Saves memories to the JSON file.
保存记忆到json文件
"""
# 这里使用的w模式,每次会清空文件写入json
with open(self.filepath, "w") as f:
json.dump(self.data, f, indent=4)
def add(self, items: List[Dict]):
"""
Adds a list of memory items to the JSON file.
Args:
items (List[Dict]): A list of memory items to add.
"""
# 将一个List的记忆item直接append到记忆数组,并保存到文件
self.data.extend(items)
self._save()
def query(self, query_embedding: List[float], k: int) -> List[Dict]:
"""
Queries the JSON file for the k most similar items using cosine
similarity.
Args:
query_embedding (List[float]): The embedding of the query.
k (int): The number of results to return.
Returns:
List[Dict]: A list of metadata dictionaries for the k most similar
items.
"""
if not self.data:
return []
# 获取每条记忆Item的embedding
embeddings = np.array([item["embedding"] for item in self.data])
# query embedding
query_embedding_np = np.array(query_embedding).reshape(1, -1)
# 计算query和记忆item embedding的余弦相似度
similarities = cosine_similarity(query_embedding_np, embeddings)[0]
# 获取前k条最相似记忆的下标
top_k_indices = np.argsort(similarities)[-k:][::-1]
# 返回top k的记忆item
return [self.data[i]["metadata"] for i in top_k_indices]- reasoningbank/memory/chroma.py - 完整的向量存储实现
基于chromadb实现的向量库后端(基于内存),集成自MemoryBackend类实现了add和query函数
python
"""ChromaDB memory backend."""
import chromadb
from typing import List, Dict
import uuid
from .base import MemoryBackend
class ChromaMemoryBackend(MemoryBackend):
"""
A memory backend that uses ChromaDB for storage.
This class provides an implementation of the MemoryBackend that uses
ChromaDB to store and retrieve memories. It is suitable for production
environments where a scalable and efficient vector database is required.
"""
def __init__(self, collection_name: str = "reasoning_bank"):
"""
Initializes the ChromaMemoryBackend.
Args:
collection_name (str): The name of the ChromaDB collection to use.
"""
# 向量库客户端
self.client = chromadb.Client()
# 创建向量库集合(表)
self.collection = self.client.get_or_create_collection(
name=collection_name
)
def add(self, items: List[Dict]):
"""
将记忆item添加到chromadb的集合中,每个记忆item包括
embedding: memory item的embedding
metadata: 一个包含title, description, content的字典
document: 记忆item的具体内容
Args:
items (List[Dict]): A list of memory items to add.
"""
# chromadb是按列存储的,先把记忆item中的每一项加入到list中
ids = []
embeddings = []
metadatas = []
documents = []
for item in items:
ids.append(str(uuid.uuid4()))
embeddings.append(item["embedding"])
metadatas.append(item["metadata"])
documents.append(item["document"])
# 调用api直接添加
self.collection.add(
ids=ids,
embeddings=embeddings,
metadatas=metadatas,
documents=documents,
)
def query(self, query_embedding: List[float], k: int) -> List[Dict]:
"""
在ChromaDB集合中查询k个最相似的memory item
Args:
query_embedding (List[float]): The embedding of the query.
k (int): The number of results to return.
Returns:
List[Dict]: A list of metadata dictionaries for the k most similar
items.
与查询向量最相似的 k 条记忆项的元数据(metadata)列表
"""
# 调用检索的query函数,直接返回与query embedding最相似的前k个记忆item
results = self.collection.query(
query_embeddings=[query_embedding], n_results=k
)
"""
self.collection.query() 是 ChromaDB 的查询方法,返回一个字典,通常包含以下键:
'ids':匹配项的 ID 列表(嵌套列表)。
'embeddings':匹配项的嵌入向量列表(嵌套列表,可选)。
'metadatas':匹配项的元数据列表(嵌套列表)。
'documents':匹配项的文档内容列表(嵌套列表)。
'distances':匹配项与查询向量的距离列表(嵌套列表)
因为传入的 query_embeddings=[query_embedding] 是一个列表(即使只有一个查询向量),所以返回的 metadatas 是一个外层列表,其中每个元素对应一个查询向量的结果。
results["metadatas"] 的结构为:
[[metadata_1, metadata_2, ..., metadata_k]]
results["metadatas"][0] 的含义
[0] 取出外层列表的第一个(也是唯一一个)元素,即内层列表 [metadata_1, metadata_2, ..., metadata_k]
如果查询没有返回任何结果(例如集合为空或相似度计算无匹配),results["metadatas"] 可能为 None 或空列表
add 方法中添加的 ids、embeddings、documents 以及 ChromaDB 自动计算的 distances 都不会被返回
results = self.collection.query(...)
# 返回一个包含多个字段的列表,每个元素是字典
metadatas = results['metadatas'][0]
documents = results['documents'][0]
distances = results['distances'][0]
return [
{'metadata': m, 'document': d, 'distance': dist}
for m, d, dist in zip(metadatas, documents, distances)
]
这里只返回metadata
"""
return results["metadatas"][0] if results["metadatas"] else []核心阶段(理解主要功能)
3. 轨迹蒸馏
- reasoningbank/distillation/distill.py - 如何将原始轨迹转换为记忆
python
"""Distillation functions for processing agent trajectories."""
from typing import List, Dict, Any
import json
# A placeholder for a generic LLM interface.
# In a real implementation, this would be a more specific type,
# for example, a LangChain BaseLanguageModel.
LLM = Any
def judge_trajectory(trajectory: str, query: str, llm: LLM) -> bool:
"""
Judges whether a trajectory was successful or not using an LLM.
使用LLM判断轨迹是否成功, 返回一个bool类型的结果,True: success,表示轨迹成功地解决了问题
False: 未能解决问题
This function sends a prompt to a language model to evaluate if the given
trajectory successfully addresses the query. It is a simple binary
classification (Success/Failure).
Args:
trajectory (str): The sequence of actions and observations from the agent.
这里的轨迹是agent的一系列动作和观察
query (str): The initial task or question for the agent.
提交给agent的初始任务的问题
llm (LLM): The language model to use for the judgment.
用于judge的llm模型
Returns:
bool: True if the trajectory is judged as successful, False otherwise.
"""
# LLM As a Judge 这里的提示语写的较为简单,只包含了任务描述,目标输出和输入,没有判定成功和失败的标准
# 给定以下查询和轨迹,确定轨迹是否成功地解决了查询。回答"成功"或"失败"。
prompt = f"""
Given the following query and trajectory, determine if the trajectory successfully addresses the query.
Respond with "Success" or "Failure".
Query: {query}
Trajectory:
{trajectory}
"""
response = llm.invoke(prompt)
return "success" in response.lower()
def distill_trajectory(
trajectory: str, query: str, llm: LLM, is_success: bool
) -> List[Dict]:
"""
Distills a raw trajectory into a list of structured memory items.
将原始轨迹提取为结构化记忆项列表。
根据轨迹是否成功,此功能提示语言模型,用于提取关键的推理步骤、策略或经验教训。
输出期望是一个表示记忆项列表的JSON字符串。
Based on whether the trajectory was successful, this function prompts the
language model to extract key reasoning steps, strategies, or lessons learned.
The output is expected to be a JSON string representing a list of memory items.
Args:
trajectory (str): The agent's trajectory.
query (str): The initial query.
llm (LLM): The language model for distillation.
is_success (bool): Whether the trajectory was successful.
Returns:
List[Dict]: A list of distilled memory items, each with a title,
description, and content. Returns an empty list if
the LLM response cannot be parsed.
提取的记忆项目列表,每个项目都有一个标题,描述和内容。如果满足以下条件,
则返回空列表无法解析LLM响应。
"""
# 这里根据之前判定的轨迹是否成功,分别使用两个prompt来提取记忆item, 记忆item的输出是一个
# JSON字符串,包括一个标题、一个简短的描述和内容
if is_success:
prompt = f"""
The following trajectory was successful in addressing the query.
Distill the key reasoning steps and strategies into a few memory items.
Each memory item should have a title, a short description, and content.
Format the output as a JSON string representing a list of dictionaries. For example:
[
{{
"title": "Example Title",
"description": "A short description.",
"content": "The detailed reasoning steps."
}}
]
Query: {query}
Trajectory:
{trajectory}
"""
else:
prompt = f"""
The following trajectory failed to address the query.
Analyze the failure and distill the lessons learned into a few memory items.
Each memory item should have a title, a short description, and content describing the pitfall and how to avoid it.
Format the output as a JSON string representing a list of dictionaries. For example:
[
{{
"title": "Example Pitfall",
"description": "A short description of the error.",
"content": "A detailed explanation of the mistake and how to avoid it in the future."
}}
]
Query: {query}
Trajectory:
{trajectory}
"""
# 调用大模型获取记忆item
response = llm.invoke(prompt)
# 直接使用json.loads对LLM的json输出进行安全解析
try:
distilled_memories = json.loads(response)
# 如果解析成list, 直接返回蒸馏后的记忆memory列表
if isinstance(distilled_memories, list):
return distilled_memories
except json.JSONDecodeError:
# If parsing fails, return an empty list.
return []
return []- 核心类
- reasoningbank/core/bank.py - 主要的 ReasoningBank 类,协调所有组件
python
"""Core components for the ReasoningBank library."""
import json
from typing import Any, List, Dict
from ..memory.base import MemoryBackend
from ..distillation.distill import judge_trajectory, distill_trajectory
from ..utils.config import load_config
from ..memory.chroma import ChromaMemoryBackend
from ..memory.json import JSONMemoryBackend
from sentence_transformers import SentenceTransformer
from langchain_community.llms import FakeListLLM
# Placeholder for a generic Embedding Model interface.
# The user would provide a model with an `embed_documents` method.
EmbeddingModel = Any
LLM = Any
class ReasoningBank:
"""
The core class for the ReasoningBank library.
ReasoningBank库的核心类。
Orchestrates memory storage, distillation, and retrieval. It integrates a
memory backend, an embedding model, and a language model to provide a
comprehensive solution for managing and utilizing agent experiences.
协调内存存储、提取和检索。它集成了一个内存后端、嵌入模型和语言模型,以提供
管理和利用代理体验的综合解决方案。
Attributes:
memory_backend (MemoryBackend): The backend used for storing and
retrieving memories.
embedding_model (EmbeddingModel): The model used for generating
embeddings for text.
llm (LLM): The language model used for judging and distilling
trajectories.
"""
def __init__(self, config_path: str = "config.yaml"):
"""
Initializes the ReasoningBank from a configuration file.
Args:
config_path (str): The path to the configuration file.
"""
# 加载配置
self.config = load_config(config_path)
# 初始化记忆后端
self.memory_backend = self._init_memory_backend()
# 初始化embedding模型
self.embedding_model = self._init_embedding_model()
# 初始化大模型
self.llm = self._init_llm()
def _init_memory_backend(self) -> MemoryBackend:
"""
Initializes the memory backend based on the configuration.
根据配置初始化内存后端
"""
backend_type = self.config["memory"]["backend"]
if backend_type == "chroma":
# chromadb 向量库后端
return ChromaMemoryBackend(
collection_name=self.config["memory"]["chroma"]["collection_name"]
)
elif backend_type == "json":
# json记忆后端
return JSONMemoryBackend(
filepath=self.config["memory"]["json"]["filepath"]
)
else:
raise ValueError(f"Unknown memory backend type: {backend_type}")
def _init_embedding_model(self) -> EmbeddingModel:
"""
Initializes the embedding model based on the configuration.
基于配置初始化emebedding模型
"""
model_name = self.config["embedding_model"]["model_name"]
if model_name == "gemini-embedding-001":
# In a real implementation, this would initialize the Gemini client.
# For now, we'll use a placeholder that has the same `encode` method
# as SentenceTransformer for compatibility.
# This is a mock for testing purposes.
# 在实际实现中,这将初始化Gemini客户端。
# 现在,我们将使用具有相同"encode"方法的占位符
# 作为兼容的句子转换器。
# 这是一个用于测试目的的模拟
return SentenceTransformer("all-MiniLM-L6-v2")
elif model_name == "sentence-transformers":
# 基于sentence transformers 加载embedding模型
st_model_name = self.config["embedding_model"].get(
"st_model_name", "all-MiniLM-L6-v2"
)
return SentenceTransformer(st_model_name)
else:
raise ValueError(f"Unknown embedding model: {model_name}")
def _init_llm(self) -> LLM:
"""
Initializes the language model based on the configuration.
根据配置初始化语言模型。
"""
# This is a placeholder for a more complex LLM initialization.
# In a real application, this would involve loading the specified LLM
# from a library like LangChain.
provider = self.config["llm"]["provider"]
# 本地ollama模型
if provider == "ollama":
from langchain_community.llms import Ollama
return Ollama(model=self.config["llm"]["model"])
elif provider == "langchain.llms.Fake":
# 为了演示使用了一个假的llm模型
responses = [
"Success",
json.dumps(
[
{
"title": "Fake Memory",
"description": "A fake memory",
"content": "This is a fake memory.",
}
]
),
]
return FakeListLLM(responses=responses)
else:
raise ValueError(f"Unknown LLM provider: {provider}")
def add_experience(self, trajectory: str, query: str):
"""
Adds a new experience to the bank.
添加一条新的经验到bank中
This method takes a trajectory and a query, judges the trajectory's
success, distills it into memory items, generates an embedding for the
query, and stores the entire experience in the memory backend.
该方法采用轨迹和query,判断轨迹的成功,将其提炼成记忆项,为
并将整个体验存储在内存后端。
Args:
trajectory (str): The sequence of actions and observations that
constitute the experience.
行动和观察序列组成的经验
query (str): The initial query or task that the agent was trying
to solve.
需要agent尝试解决的 原始query
"""
# 输入trajectory和query, 判断轨迹是否成功
is_success = judge_trajectory(trajectory, query, self.llm)
# 蒸馏记忆
distilled_items = distill_trajectory(
trajectory, query, self.llm, is_success
)
if not distilled_items:
return
# 为query生成embedding
query_embedding = self.embedding_model.encode(query)
# Prepare the experience for storage.
# We serialize the distilled_items to a JSON string to comply with
# ChromaDB's metadata limitations.
# 准备经验存储的json格式,包括embedding, metadata, 和document(原始query)
# 这里的embedding是query的embedding, 后序检索同样使用query embedding进行检索
experience_to_add = {
"embedding": query_embedding.tolist(),
"metadata": {
"query": query,
"trajectory": trajectory,
"distilled_items": json.dumps(distilled_items),
},
"document": query,
}
# 将经验添加到记忆后端
self.memory_backend.add([experience_to_add])
def retrieve_memories(self, query: str, k: int = 1) -> List[Dict]:
"""
Retrieves the top k most relevant memories for a given query.
检索给定query的前k个最相关的记忆项
Args:
query (str): The query to retrieve relevant memories for.
k (int): The number of memories to retrieve.
Returns:
List[Dict]: A list of the top k most relevant memories.
"""
# query embedding
query_embedding = self.embedding_model.encode(query)
# 检索topk相似的记忆item(metadata)
return self.memory_backend.query(query_embedding.tolist(), k)- MaTTS 算法
- reasoningbank/core/matts.py - 并行和顺序缩放实现
MaTTS 算法是原文中提出的一个创新点,原文说一个query一个answer得到记忆不是最好的,需要对一个query进行多次采样,生成不同(成功和失败)的答案,进行自我对比,生成对比信号,并提炼memory, ,从而提升模型的学习能力,这里多次采样是并行;
python
from typing import Any
from .bank import ReasoningBank
from .agent import format_memories_for_prompt, create_agent_executor
# A placeholder for a generic agent execution function.
# In a real implementation, this would be a proper agent class or function.
AgentExecutor = Any
def parallel_scaling(
query: str, k: int, reasoning_bank: ReasoningBank, agent_executor: AgentExecutor
) -> str:
"""
Implements parallel scaling MaTTS.
Generates k trajectories in parallel, learns from them, and synthesizes a
final answer.
实现并行缩放MaTTS。
并行生成k个轨迹,从中学习,并合成一个最终答案。
"""
# 1. Retrieve initial memories to guide the parallel generation.
# 检索memory
initial_memories = reasoning_bank.retrieve_memories(query, k=1)
# 格式化memory
formatted_memories = format_memories_for_prompt(initial_memories)
# 2. Generate k trajectories in parallel.
# In a real implementation, this could be done with asyncio or threading.
# 并行同时生成k条trajectory
trajectories = []
for _ in range(k):
trajectory = agent_executor.invoke(
{"memories": formatted_memories, "query": query}
)
trajectories.append(trajectory)
# 3.将新的经验,trajectory和query加入到reasoning bank中,用于学习, 一条query对应多条trajectory
for trajectory in trajectories:
reasoning_bank.add_experience(trajectory, query)
# 4.根据生成的轨迹合成最终答案
trajectories_str = "\n---\n".join(trajectories)
# 选取最优的trajector
synthesis_prompt = f"""
Given the following query and {k} proposed trajectories, select the best
one or synthesize a final answer.
Query: {query}
Trajectories:
{trajectories_str}
"""
# 大模型返回answer
final_answer = reasoning_bank.llm.invoke(synthesis_prompt)
# 返回最终的answer
return final_answer
def sequential_scaling(
query: str, k: int, reasoning_bank: ReasoningBank, agent_executor: AgentExecutor
) -> str:
"""
Implements sequential scaling MaTTS.
Iteratively refines a single trajectory k times.
实现顺序缩放MaTTS。
迭代优化单个轨迹k次。
"""
trajectory = ""
# 迭代优化单个轨迹k次
for _ in range(k):
# 1. 检索记忆以指导当前的优化步骤
memories = reasoning_bank.retrieve_memories(query, k=1)
# 格式化memory
formatted_memories = format_memories_for_prompt(memories)
# 2. Run the agent for one step of refinement.
# The agent is prompted to refine the existing trajectory.
# 系统会提示代理优化现有轨迹, 提炼现有轨迹来更好地回答query
refinement_prompt = f"""
Based on the following memories, refine the current trajectory to
better answer the query.
Memories:
{formatted_memories}
Query: {query}
Current Trajectory:
{trajectory}
Refined Trajectory:
"""
# 我们为精化提示创建了一个新的代理执行器
# 更复杂的实现可能使用单个代理
# 它可以处理初始生成和细化
refinement_agent = create_agent_executor(reasoning_bank.llm)
# 传入现有trajectory和query, 使用新的代理执行器生成提炼后的trajectory
trajectory = refinement_agent.invoke(
{"memories": formatted_memories, "query": refinement_prompt}
)
# 3. 将最终轨迹和query添加到推理库中
reasoning_bank.add_experience(trajectory, query)
# 4. 返回最终的轨迹
return trajectory扩展阶段(理解集成)
- 智能体集成
- reasoningbank/core/agent.py - 智能体执行器
主要包括一个流水线式的回答问题的pipeline和记忆格式化函数
python
"""Agent-related functionalities for the ReasoningBank library."""
from langchain_core.prompts import PromptTemplate
from langchain_core.language_models.base import BaseLanguageModel
from langchain_core.runnables import RunnableSequence
from langchain_core.output_parsers import StrOutputParser
from typing import List, Dict
def create_agent_executor(llm: BaseLanguageModel) -> RunnableSequence:
"""
Creates a simple agent executor for generating trajectories.
This function sets up a basic chain that takes a set of memories and a query,
and generates a response that represents the agent's thought process or trajectory.
This is intended for demonstration and testing purposes.
创建一个简单的代理执行器来生成轨迹。
此函数建立一个基本链,该链包含一组记忆和一个query,
并生成表示代理的思维过程或轨迹的响应,这是用于演示和测试目的。
Args:
llm (BaseLanguageModel): An instance of a LangChain compatible language model.
LangChain兼容语言模型的实例。
Returns:
RunnableSequence: A LangChain RunnableSequence configured to generate trajectories.
配置为生成轨迹的LangChain RunnableSequence。
"""
# 提示语,给定记忆,回复用户的query
template = """
You are a helpful assistant.
Based on the following memories, answer the user's query.
Memories:
{memories}
Query: {query}
Your response is a trajectory of your thought process.
Trajectory:
"""
prompt = PromptTemplate(input_variables=["memories", "query"], template=template)
# 使用langchain链的方式生成答案
return prompt | llm | StrOutputParser()
def format_memories_for_prompt(memories: List[Dict]) -> str:
"""
Formats a list of memory dictionaries into a string suitable for a prompt.
将内存字典列表格式化为适合提示的字符串
Args:
memories (List[Dict]): A list of memory dictionaries, where each dictionary
is expected to have 'title', 'description', and 'content' keys.
记忆字典列表,其中每个字典应具有"title"、"description"和"content"键
Returns:
str: A formatted string of memories, or a message indicating that no
relevant memories were found.
格式化的记忆字符串,或表示没有的消息找到了相关的记忆。
"""
if not memories:
return "No relevant memories found."
return "\n---\n".join(
f"Title: {m.get('metadata', {}).get('title', 'N/A')}\nDescription: {m.get('metadata', {}).get('description', 'N/A')}\nContent: {m.get('document', 'N/A')}"
for m in memories
)- LangChain 集成
- reasoningbank/integrations/langchain/memory.py - LangChain 记忆类
python
from typing import Dict, Any, List
from reasoningbank.core.bank import ReasoningBank
class ReasoningBankMemory:
"""A LangChain memory class that uses the ReasoningBank."""
reasoning_bank: ReasoningBank
memory_key: str = "history" # The key for the memory variables.
def __init__(self, reasoning_bank: ReasoningBank):
# 传入reasoningbank类
self.reasoning_bank = reasoning_bank
@property
def memory_variables(self) -> List[str]:
"""
The list of memory variables.
记忆变量列表
"""
return [self.memory_key]
def load_memory_variables(self, inputs: Dict[str, Any]) -> Dict[str, Any]:
"""
Load the memory variables.
加载记忆变量
"""
import json
# We'll use the first key in the inputs dict as the query.
# This is a simplification; a more robust implementation might
# have a more explicit way of defining the query.
# 使用inputs dict的第一个key作为query
query = next(iter(inputs.values()))
# 检索记忆
retrieved_experiences = self.reasoning_bank.retrieve_memories(query, k=1)
# 获取所有蒸馏的记忆item
all_distilled_items = []
for experience in retrieved_experiences:
# distilled_items is a JSON string, so we need to parse it.
distilled_items = json.loads(experience.get("distilled_items", "[]"))
all_distilled_items.extend(distilled_items)
# 组装记忆到prompt
formatted_memories = "\n---\n".join(
f"Title: {item['title']}\nDescription: {item['description']}\nContent: {item['content']}"
for item in all_distilled_items
)
# 返回memory_key和记忆str组成的字典
return {self.memory_key: formatted_memories}
def save_context(self, inputs: Dict[str, Any], outputs: Dict[str, str]) -> None:
"""Save the context of a chain run to the ReasoningBank."""
# 保存一条经验到reasoning bank
query = next(iter(inputs.values()))
trajectory = next(iter(outputs.values()))
self.reasoning_bank.add_experience(trajectory, query)
def clear(self) -> None:
"""Clear the memory."""
# This is not directly supported by the current ReasoningBank design,
# as the bank is meant to be persistent.
# A possible implementation would be to clear the memory backend.
pass- 包入口
- reasoningbank/init.py - 了解对外导出的 API
实践阶段(运行示例)
- 示例代码
- examples/simple_usage.py - 运行示例,验证理解
- examples/config.yaml - 示例配置
如何使用reasoningbank
python
from reasoningbank import ReasoningBank
import os
def run_example():
"""A simple example of how to use the ReasoningBank library."""
# 使用config.yaml文件初始化ReasoningBank
bank = ReasoningBank(config_path="examples/config.yaml")
# Add an experience
# 包括trajectory: 思考,行动,观察
trajectory = (
"1. Thought: I need to find the capital of France. "
"2. Action: Search for 'capital of France'. "
"3. Observation: The capital of France is Paris."
)
query = "What is the capital of France?"
# 添加一条经验
bank.add_experience(trajectory, query)
print("Experience added to the memory bank.")
# 检索memory
retrieved_memories = bank.retrieve_memories(
"What is the main city in France?", k=1
)
print("\nRetrieved memories:")
for memory in retrieved_memories:
print(f" Title: {memory['title']}")
print(f" Description: {memory['description']}")
print(f" Content: {memory['content']}")
# Clean up the example memory file
if os.path.exists("example_memory.json"):
os.remove("example_memory.json")
if __name__ == "__main__":
run_example()本地运行需要修改config.yaml配置文件中的
- memory后端类型,
- embedding模型路径, 这里使用本地下载好的bge-base-zh(不同的embedding模型检索结果可能有差异)
- 本地ollama部署,或者大模型api,我这里使用的是api
config.yaml配置如下:
yaml
# Example configuration for the ReasoningBank library
memory:
# backend: "json"
# json:
# filepath: "example_memory.json"
backend: "chroma"
# Settings for the ChromaDB backend
chroma:
collection_name: "reasoning_bank"
embedding_model:
model_name: "/workspace/pretrain_model/bge-base-zh"
llm:
provider: "openai"bank.py的改动
python
import json
from typing import Any, List, Dict
from ..memory.base import MemoryBackend
from ..distillation.distill import judge_trajectory, distill_trajectory
from ..utils.config import load_config
from ..utils.request_llm import CustomLLM
from ..memory.chroma import ChromaMemoryBackend
from ..memory.json import JSONMemoryBackend
from sentence_transformers import SentenceTransformer
from langchain_community.llms import FakeListLLM
# Placeholder for a generic Embedding Model interface.
# The user would provide a model with an `embed_documents` method.
EmbeddingModel = Any
LLM = Any
class ReasoningBank:
"""
The core class for the ReasoningBank library.
Orchestrates memory storage, distillation, and retrieval. It integrates a
memory backend, an embedding model, and a language model to provide a
comprehensive solution for managing and utilizing agent experiences.
Attributes:
memory_backend (MemoryBackend): The backend used for storing and
retrieving memories.
embedding_model (EmbeddingModel): The model used for generating
embeddings for text.
llm (LLM): The language model used for judging and distilling
trajectories.
"""
def __init__(self, config_path: str = "config.yaml"):
"""
Initializes the ReasoningBank from a configuration file.
Args:
config_path (str): The path to the configuration file.
"""
# 加载config
self.config = load_config(config_path)
# 初始化memory后端
self.memory_backend = self._init_memory_backend()
# 初始化embedding模型
self.embedding_model = self._init_embedding_model()
# 初始化llm
self.llm = self._init_llm()
def _init_memory_backend(self) -> MemoryBackend:
"""Initializes the memory backend based on the configuration."""
backend_type = self.config["memory"]["backend"]
if backend_type == "chroma":
return ChromaMemoryBackend(
collection_name=self.config["memory"]["chroma"]["collection_name"]
)
elif backend_type == "json":
return JSONMemoryBackend(
filepath=self.config["memory"]["json"]["filepath"]
)
else:
raise ValueError(f"Unknown memory backend type: {backend_type}")
def _init_embedding_model(self) -> EmbeddingModel:
"""Initializes the embedding model based on the configuration."""
model_name = self.config["embedding_model"]["model_name"]
if "bge" in model_name.lower() or "m3e" in model_name.lower():
return SentenceTransformer(model_name)
elif model_name == "gemini-embedding-001":
# In a real implementation, this would initialize the Gemini client.
# For now, we'll use a placeholder that has the same `encode` method
# as SentenceTransformer for compatibility.
# This is a mock for testing purposes.
return SentenceTransformer("all-MiniLM-L6-v2")
elif model_name == "sentence-transformers":
st_model_name = self.config["embedding_model"].get(
"st_model_name",
"all-MiniLM-L6-v2"
)
return SentenceTransformer(st_model_name)
else:
raise ValueError(f"Unknown embedding model: {model_name}")
def _init_llm(self) -> LLM:
"""
Initializes the language model based on the configuration.
"""
# This is a placeholder for a more complex LLM initialization.
# In a real application, this would involve loading the specified LLM
# from a library like LangChain.
provider = self.config["llm"]["provider"]
if provider=="openai":
return CustomLLM()
elif provider == "ollama":
from langchain_community.llms import Ollama
return Ollama(model=self.config["llm"]["model"])
elif provider == "langchain.llms.Fake":
# For demonstration purposes, we use a fake LLM.
responses = [
"Success",
json.dumps(
[
{
"title": "Fake Memory",
"description": "A fake memory",
"content": "This is a fake memory.",
}
]
),
]
return FakeListLLM(responses=responses)
else:
raise ValueError(f"Unknown LLM provider: {provider}")添加大模型api, 在ReasoningBank/reasoningbank/utils/request_llm.py文件下定义CustomLLM类
python
from openai import OpenAI
import time
import requests
import json
class CustomLLM(object):
def __init__(self):
self.URL = "http://deepseek.vip/api/v1/llm/generate"
self.HEADERS = {'Content-Type':'application/json'}
self.API_KEY = "your_api_key_here"
self.MODEL_TYPE="deepseek-v3.2"
self.client = OpenAI(
api_key=self.API_KEY,
base_url=self.URL,
)
def invoke(self, prompt, retry=2):
"""
调用模型API
"""
for i in range(retry):
try:
completion = self.client.chat.completions.create(
model=self.MODEL_TYPE,
messages=[
{
"role": "user",
"content": prompt,
}
],
temperature=0.1,
top_p=0.9
)
if not completion:
time.sleep(3)
continue
return completion.choices[0].message.content
except Exception as e:
print(f"error: {e}")
time.sleep(3)
return None使用json作为memory后端的执行结果
python
## judge 结果
is_success=True
## memory distill结果
prompt:
The following trajectory was successful in addressing the query.
Distill the key reasoning steps and strategies into a few memory items.
Each memory item should have a title, a short description, and content.
Format the output as a JSON string representing a list of dictionaries. For example:
[
{
"title": "Example Title",
"description": "A short description.",
"content": "The detailed reasoning steps."
}
]
Query: What is the capital of France?
Trajectory:
1. Thought: I need to find the capital of France. 2. Action: Search for 'capital of France'. 3. Observation: The capital of France is Paris.
## distill response:
[
{
"title": "Direct Search for Country Capitals",
"description": "Use a search engine to retrieve the capital of a country by querying its name.",
"content": "When asked for the capital of a country (e.g., France), perform a direct search using the phrase 'capital of [Country Name]' to obtain the correct answer (e.g., Paris)."
}
]
## 蒸馏的记忆
distilled_items=[{'title': 'Direct Search for Country Capitals',
'description': 'Use a search engine to retrieve the capital of a country by querying its name.', 'content': "When asked for the capital of a country (e.g., France), perform a direct search using the phrase 'capital of [Country Name]' to obtain the correct answer (e.g., Paris)."}]
Experience added to the memory bank.
## 检索出来的memory
retrieved_memories:
[{'query': 'What is the capital of France?',
'trajectory': "1. Thought: I need to find the capital of France. 2. Action: Search for 'capital of France'. 3. Observation: The capital of France is Paris.", 'distilled_items': '[{"title": "Direct Search for Country Capitals", "description": "Use a search engine to retrieve the capital of a country by querying its name.", "content": "When asked for the capital of a country (e.g., France), perform a direct search using the phrase \'capital of [Country Name]\' to obtain the correct answer (e.g., Paris)."}]'}]
Retrieved memories:
1,{'title': 'Direct Search for Country Capitals', 'description': 'Use a search engine to retrieve the capital of a country by querying its name.', 'content': "When asked for the capital of a country (e.g., France), perform a direct search using the phrase 'capital of [Country Name]' to obtain the correct answer (e.g., Paris)."}
Title: Direct Search for Country Capitals
Description: Use a search engine to retrieve the capital of a country by querying its name.
Content: When asked for the capital of a country (e.g., France), perform a direct search using the phrase 'capital of [Country Name]' to obtain the correct answer (e.g., Paris).使用chroma db作为记忆后端的执行结果
python
is_success=True
prompt:
The following trajectory was successful in addressing the query.
Distill the key reasoning steps and strategies into a few memory items.
Each memory item should have a title, a short description, and content.
Format the output as a JSON string representing a list of dictionaries. For example:
[
{
"title": "Example Title",
"description": "A short description.",
"content": "The detailed reasoning steps."
}
]
Query: What is the capital of France?
Trajectory:
1. Thought: I need to find the capital of France. 2. Action: Search for 'capital of France'. 3. Observation: The capital of France is Paris.
distill response:
[
{
"title": "Identify the Query Intent",
"description": "Recognize the question requires factual retrieval.",
"content": "The query asks for a specific capital city, indicating a need to retrieve a well-established fact from reliable sources."
},
{
"title": "Execute Search for Capital Information",
"description": "Use a direct search strategy to obtain the answer.",
"content": "Performing a search for 'capital of France' leverages common knowledge databases or search engines to quickly validate the answer."
},
{
"title": "Confirm Answer from Observation",
"description": "Validate the response against the observed data.",
"content": "The observation clearly states 'The capital of France is Paris,' confirming the answer without ambiguity."
}
]
distilled_items=[{'title': 'Identify the Query Intent', 'description': 'Recognize the question requires factual retrieval.', 'content': 'The query asks for a specific capital city, indicating a need to retrieve a well-established fact from reliable sources.'}, {'title': 'Execute Search for Capital Information', 'description': 'Use a direct search strategy to obtain the answer.', 'content': "Performing a search for 'capital of France' leverages common knowledge databases or search engines to quickly validate the answer."}, {'title': 'Confirm Answer from Observation', 'description': 'Validate the response against the observed data.', 'content': "The observation clearly states 'The capital of France is Paris,' confirming the answer without ambiguity."}]
Experience added to the memory bank.
retrieved_memories: [{'distilled_items': '[{"title": "Identify the Query Intent", "description": "Recognize the question requires factual retrieval.", "content": "The query asks for a specific capital city, indicating a need to retrieve a well-established fact from reliable sources."}, {"title": "Execute Search for Capital Information", "description": "Use a direct search strategy to obtain the answer.", "content": "Performing a search for \'capital of France\' leverages common knowledge databases or search engines to quickly validate the answer."}, {"title": "Confirm Answer from Observation", "description": "Validate the response against the observed data.", "content": "The observation clearly states \'The capital of France is Paris,\' confirming the answer without ambiguity."}]', 'query': 'What is the capital of France?', 'trajectory': "1. Thought: I need to find the capital of France. 2. Action: Search for 'capital of France'. 3. Observation: The capital of France is Paris."}]
Retrieved memories:
1,{'title': 'Identify the Query Intent', 'description': 'Recognize the question requires factual retrieval.', 'content': 'The query asks for a specific capital city, indicating a need to retrieve a well-established fact from reliable sources.'}
Title: Identify the Query Intent
Description: Recognize the question requires factual retrieval.
Content: The query asks for a specific capital city, indicating a need to retrieve a well-established fact from reliable sources.
2,{'title': 'Execute Search for Capital Information', 'description': 'Use a direct search strategy to obtain the answer.', 'content': "Performing a search for 'capital of France' leverages common knowledge databases or search engines to quickly validate the answer."}
Title: Execute Search for Capital Information
Description: Use a direct search strategy to obtain the answer.
Content: Performing a search for 'capital of France' leverages common knowledge databases or search engines to quickly validate the answer.
3,{'title': 'Confirm Answer from Observation', 'description': 'Validate the response against the observed data.', 'content': "The observation clearly states 'The capital of France is Paris,' confirming the answer without ambiguity."}
Title: Confirm Answer from Observation
Description: Validate the response against the observed data.
Content: The observation clearly states 'The capital of France is Paris,' confirming the answer without ambiguity.源码阅读建议
- 按依赖关系阅读:先读被依赖的模块(如 base.py),再读依赖它的模块
- 边读边运行:配合 examples/simple_usage.py 调试理解
- 关注接口设计:重点理解 MemoryBackend 的 add() 和 query() 方法
- 理解数据流:追踪 add_experience() 从轨迹到存储的完整流程
关键数据流 在bank.py的add_experience函数
用户调用 add_experience(trajectory, query)
↓
judge_trajectory() - 判断是否成功
↓
distill_trajectory() - 蒸馏为结构化记忆
↓
embedding_model.encode() - 生成向量
↓
memory_backend.add() - 存储到后端
总结
- reasoningbank 实现了向量后端,llm judge,经验存储,记忆检索,prompt增强等一系列功能,使得agent能够从过去交互等成功和失败的案例中学习。
- 可以收集成功和失败案例,从提炼的记忆增强prompt,提供了一个不错的Agent效果优化思路。
- 作为学习的项目,llm judge 和经验提取的提示词写的过于简单,工业界的judge prompt业务会更加复杂,其次工程方面也有很多改进的地方,记忆item的设计只有title, content, description, 可以设计得更复杂,包括提取的实体(用于关键词检索)等,如向量库应该是持久化到磁盘的,没有相似记忆item的记忆整合更新形成长期的经验(需要人工审核),记忆冲突处理,可以参考A-mem这篇文章。
- MaTTs代码过于简略,生成成功和失败对比信号,应该是基于学习学习中比较重要的一步,不仅要知道做错了,还要从成功的案例学习;前期可以收集这种成功和失败的案例,后期用于强化学习偏好DPO学习。