目录
到面的,本来hr说的是笔试+技术面+hr面,结果技术面完,临时加了一轮远程技术面。
笔试
-
volatile关键词能保证读写操作的原子性吗?如果不能,请举例说明。
豆包答 -
VO/POJO/PO/DTO 区别
答:
POJO:简单 Java 对象,无继承 / 实现限制;
PO:持久化对象,与数据库表一一对应;
VO:视图对象,用于前端展示层数据封装;
DTO:数据传输对象,用于层间数据传递
-
String str1 = "hello";
String str2 = "he" + "llo";
String str3 = "he" + new String("llo"); str1 == str2 和 str1 == str3的结果 ?
答:true false。因为str2为编译期常量拼接,与str1指向常量池同一对象;str3为运行时拼接,生成新堆对象。
-
以下代码能正常运行吗:
java
public class NULL {
public static void haha() {
System.out.println("hello world");
}
public static void main(String[] args){
((NULL)null).haha();
}
}我答的是 "不能,空指针异常",结果错了。豆包:haha()是静态方法,静态方法属于类而非对象,(NULL)null).haha()不会抛空指针,程序能运行,输出hello word
-
序列化:

豆包答:
错误点 1:Shape类未实现Serializable接口,其成员变量name不会被序列化(父类无序列化能力时,子类仅序列化自身属性)。
错误点 2:static String type = "Circle"是静态变量,序列化仅保存对象状态,静态变量属于类,不会被序列化。
正确结论:仅radius会被保存到文件,name、color、type均不会。
-
思维题之池塘倒水:

答:
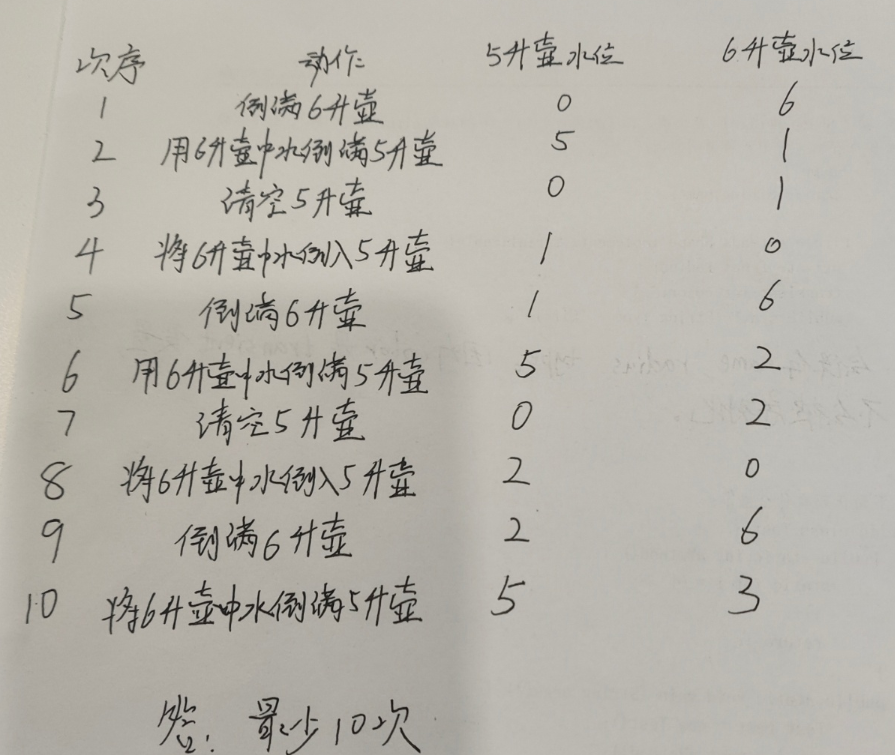
-
编程实现一个泛型栈:

豆包说:泛型数组初始化错误:
Java 中不能直接创建泛型数组 new Tlen,会编译报错,正确方式是用 (T\[\]) new Objectlen 强转。我在IDE中试了一下确实如此:

第一轮技术面
-
Q:项目用的哪个大模型平台?
豆包A:比如 科大讯飞的星火大模型 、智谱清言(GLM)、llama:

以及 InternVL(由上海人工智能实验室开发的多模态大模型)。
-
- Q:你们相当于对外提供了一个ai agent服务吗?
豆包A:项目更接近「AI 生成服务 / 多模态能力平台」,而非AI Agent 服务。AI Agent特点在于「自主任务规划、多步骤自动化执行、上下文记忆」等。
- Q:你们相当于对外提供了一个ai agent服务吗?
-
描述一下你架构设计的思路
参考答案:业务驱动、演进式架构。
项目初期业务规模不大,核心是快速验证AIGC能力在服饰、汉服等垂直场景的落地,所以我选择 SpringBoot + 单体架构,快速完成从 0 到 1 的原型开发。这个阶段强行拆应用层、领域层是过度设计。
后续拆分微服务:
把「流程部分」抽成应用层 ,「规则部分」封装在领域层 。
应用层负责流程编排,可以调用多个服务、跨领域协作,比如下单时串联订单、库存、支付,统一控制事务、异常和对外接口,它是对外的、灵活的。
而领域层只封装本服务内部的核心业务规则、状态流转和业务不变量,绝对不跨服务调用,保证每个微服务的领域逻辑自治、稳定、内聚。
这么设计的目的很明确:应用层对外变,领域层对内稳。
-
描述下你项目的难点
我提到了webflux流式接口。现在想想其实可以展开说说webflux流式接口,对于普通接口的优点:(参考豆包)
-
资源利用率极致提升 (最核心的技术优势)
普通同步接口(Spring MVC)是线程阻塞模型:每一个请求占用一个线程,直到接口完全处理完并返回结果,线程才释放。如果遇到慢 IO(比如数据库查询、调用第三方接口、大数据计算),线程会一直阻塞等待,导致线程池被占满,新请求无法处理。
WebFlux 基于响应式非阻塞模型(Reactor 框架):
少量线程(通常等于 CPU 核心数)就能处理大量并发请求,线程不会因为等待 IO 而阻塞;
流式返回时,数据「边计算、边返回」,不需要等全量数据生成后再占用线程返回,进一步降低线程资源消耗。
面试举例:我们系统有个报表接口,单次查询要处理 10 万 + 数据,用 MVC 同步接口时,并发 50 就会占满 200 个线程池,新请求直接超时;换成 WebFlux 流式返回后,只用 8 个核心线程就能支撑 200 + 并发,服务器 CPU / 内存使用率下降了 60%。
-
彻底解决「长耗时接口超时 / 体验差」问题
普通接口是一次性返回全量数据,如果数据量大 / 计算久(比如 30 秒以上),前端会超时、白屏,用户体验极差;即使没超时,用户也要等全部数据加载完才能看到结果,无法感知进度。
WebFlux 流式接口是分段推送数据:
后端计算出一部分数据,就立刻推送给前端,前端可以实时渲染(比如报表一行行展示、日志一条条输出);
配合前端 EventSource/SSE 或 WebSocket,还能实时展示「处理进度」(比如 "已处理 50%"),大幅提升用户体验;
-
适配「大数据量 / 实时数据流」场景
比如支持背压(Backpressure):

-
限流
参考答案[1](#1):Sentinel 的限流和熔断,底层都是基于滑动时间窗口做实时统计。熔断是统计窗口内的 异常率、慢调用率,达到阈值就把熔断器打开,暂时禁止调用下游,等过一段时间再半开试探,恢复正常再关闭。
-
你觉得对于架构师来说最重要的是什么?
我提到了功能性需求和非功能性需求。豆包提示:还有做正确的取舍[2](#2)。架构没有完美方案,只有合适的方案。比如:
性能 vs 复杂度
实时性/可用性 vs 一致性
开发速度 vs 扩展性
-
作为架构师,你怎样对需求做分解。
-
又问到项目的难点。事后总结:1,长连接稳定性,通过心跳检测进行连接保活。2,与传统同步编程的 "一个线程干到底" 完全不同,SSE+WebFlux 开发中,最大的痛点是 Reactor 异步模型导致线程自动切换,发生各种卡顿、阻塞的现象[3](#3):

-
你的编码规范性如何,你有哪些比较好的习惯?举例说明,你认为哪些写法可读性好,或者比较优美[4](#4)
代码规范:
命名与注释:让代码 "自解释",命名遵循 "见名知意 + 领域统一" 原则,拒绝拼音 / 无意义缩写,注释只解释 "为什么" 而非 "是什么";
异常处理:拒绝 "吞异常" ,按异常类型分级处理,关键异常携带上下文;
代码结构:单一职责 + 分层清晰,一个方法只做一件事(不超过 80 行),复杂逻辑拆分为小方法;
好习惯:
边界校验:所有外部输入(接口参数、用户输入、第三方返回)必做非空 / 范围校验;
版本控制:小步提交 + 注释清晰。代码提交遵循 "一个功能 / 一个 Bug 一次提交",提交注释按 "类型:内容" 格式(如feat:新增订单取消功能、fix:修复订单金额计算错误),避免大段代码一次性提交。
回答第二问:
提高代码复用
避免硬编码 + 魔法值
- 有用过策略模式吗?[5](#5)
策略模式(Strategy Pattern)是一种行为设计模式,该模式定义了一系列算法,并将每一个算法封装起来,使它们可以相互替换,且算法的变化不会影响使用算法的客户。
策略模式的核心思想是将算法的实现与使用分离,使得算法可以独立于客户端而变化。通过定义一个策略接口,不同的具体策略类实现该接口,从而提供不同的算法实现。客户端可以根据需要选择不同的策略类来执行相应的算法。
例如,在一个排序系统中,可以定义一个排序策略接口,不同的排序算法(如冒泡排序、快速排序等)作为具体的策略类实现该接口。在运行时,客户端可以根据数据的特点选择合适的排序策略。
策略模式的优点包括:满足开闭原则,增强了代码的可扩展性,新增策略时无需修改现有代码;使得算法的切换更加容易,客户端可以动态地选择不同的策略。
策略模式的缺点是会增加系统的类数量,因为每个策略都需要一个具体的类来实现。
-
用数据结构实现一个千万级的定时器
复盘:如果不考虑「取消 / 修改定时器」功能,只考虑两最基本功能:+定时器,和定时执行,则考虑小根堆或有序数组。
-
有用过原生的tcp ip写过代码吗?如果tcp连接出问题了,有大量的连接time-wait,要怎么去查?
参考答案[6](#6):
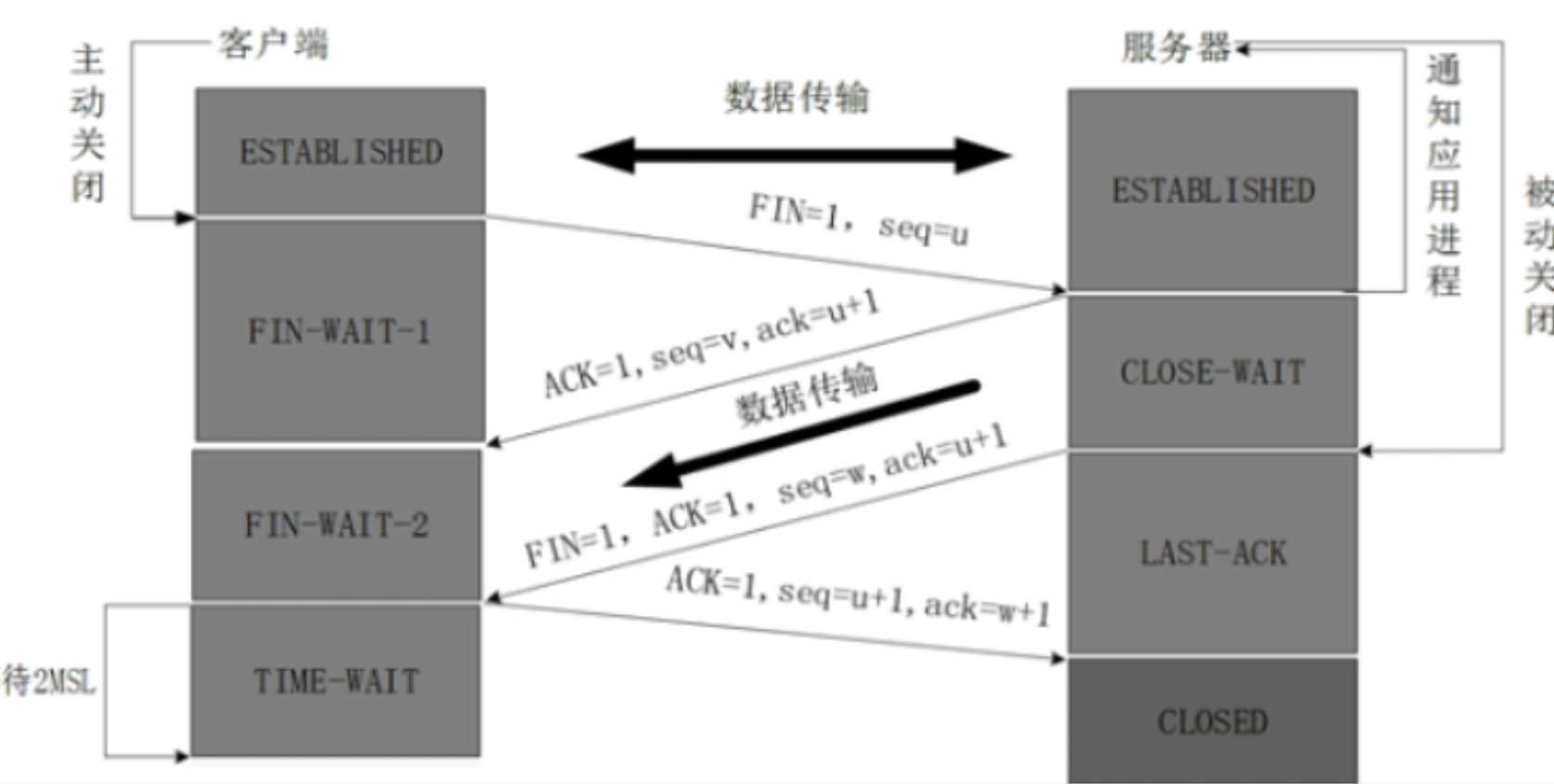
TIME_WAIT 是 TCP 四次挥手的最后一个状态:主动关闭连接的一方(通常是客户端)会进入 TIME_WAIT,默认持续 2MSL(MSL 是报文最大生存时间,Linux 默认 1 分钟,Windows 默认 4 分钟)。
典型原因举例:
服务端主动关闭连接(比如设置了连接超时,强制断开),导致服务端成为 TIME_WAIT 的产生方。
短连接滥用:HTTP 1.0 默认短连接,客户端每次请求都新建TCP连接,请求完成后关闭,高并发下瞬间产生大量 TIME_WAIT;
代码缺陷:客户端 / 服务端未复用连接,每次请求都new Socket() + close(),且未设置连接池
- 作为架构师,你怎么跟你的下属以及其他团队沟通你设计的成果?你们会写正式的设计文档吗,文档一般包含什么内容
第二轮技术面
-
10亿个整数ID,可能需要对它做一些判断等操作,用什么数据结构存储合适?假如这些整数都是Long类型,你估算下要占多少内存。一个Long对象多少字节?了解bitset吗?RoaringBitmap呢?
参考答案:
bitmap[7](#7)(位图),一种典型的非比较类排序算法,时间复杂度:O(n+M)(n是元素个数,M是数值范围).
java.util.BitSet是 Java 中对 Bitmap 思想的具体实现,基于long\[\]数组实现。
Java原生的BitSet其实存不下他要求的这些Long数据。
RoaringBitmap(咆哮位图)是对传统 Bitmap(位图)的高性能压缩优化实现,专为解决「稀疏整型 ID 存储 / 查询」场景的内存浪费问题而生,尤其适配海量 Long 类型 ID 的存储(如本题),是 Java大数据生态中处理海量整型 ID 的首选数据结构之一。
-
有没有用过Meta的ByteBuff?如果你读文件,你想快速在用户空间访问磁盘缓存,可能会用到这些数据结构。
-
Java应用中的内存抖动指什么?怎样避免?怎样复用对象 ?
豆包[8](#8):
1) 复用高频临时对象(避免重复创建)
1.1:ThreadLocal 缓存轻量对象(适合 StringBuilder、SimpleDateFormat 等)
1.2:对象池复用重量级对象(适合 ByteBuffer、ByteBuf、数据库连接等)。我:池化为了复用[9](#9)
-
Spring Controller层所有这些接口都支持并发,这跟对象复用其实是有矛盾的。Spring是如何避免这种矛盾的?
豆包[10](#10):SpringMVC每个请求由独立的线程处理。Spring 内置RequestContextHolder,基于 ThreadLocal 存储请求上下文(HttpServletRequest、用户信息等),保证了「线程间隔离」。
-
做架构时有没有用过流式处理(Stream API)?有没有改用流式处理的例子,Java哪里用流式处理比较多
豆包[11](#11): 数据过滤与转换(替代循环判断);集合数据的多维度统计;并行处理(利用多核 CPU 提升性能);
与函数式接口(Predicate/Function/Consumer)结合,将业务逻辑抽象为可复用的函数,提升代码复用性;