支持的系统和架构
- 计划支持的宿主系统为
macOS/Linux, 暂无计划支持Windows - 计划支持的目标系统为
macOS/iOS/Android - 计划支持的宿主架构和目标架构均为
X64/ARM64 - 计划支持
C/C++/Objective-C/Objective-C++/Swift/Rust/Golang等语言
混淆能力
- 数据加密
- CE 只设计字符串混淆
- 控制流混淆
- 函数级混淆
- 指令级混淆
- 其他
SLLVM的特点
目前活跃开源OLLVM项目有: 原版OLLVM, Hikari, Hikari-LLVM15, Pluto, Polaris-Obfuscator, goron, Arkari, o-mvll, ...
SLLVM和其他OLLVM()的区别主要在以下方面:
- 支持Release编译, 在Release下编译时混淆不会被编译器还原
- 抗'改数据段属性只读'攻击, 在
IDA中设置数据段为只读后混淆不会被还原 - 对已有的混淆功能加固+去特征, 由于
OLLVM已经被广泛使用, 很容易被特定脚本/Angr/AI针对(笔者也自行开发过通用还原脚本) - 在混淆大工程和使用header-only头文件时不会内存爆和长时间编译卡死
配置
在很多实际项目中, 由于以下原因无法对整个项目完全混淆:
- 项目较大, 依赖较多, 或使用了很多
header-only的库, 混淆了很多不需要混淆的代码, 导致编译出来的二进制过大 - 项目较大, 依赖较多, 使用了平坦化(或其他方式)混淆了很多不需要混淆的代码, 导致编译时间过久甚至卡死
- 混淆了复杂算法, 导致运行时耗时比正常大很多, 一般使用平坦化后耗时会增加10%以上
- 混淆过多可能不允许上架
AppStore/GooglePlay等
实际操作时, 常常需要根据模块/函数的重要性使用不同程度的混淆, 因此需要配置策略来指定哪些模块/函数需要用哪种混淆, 而开源的OLLVM常见设置策略的方式如下:
- 对需要混淆的模块单独指定命令行参数, 如
-llvm -fla, 这种方式兼容所有支持LLVM命令行参数的编译器前端 - 使用环境变量指定混淆参数
- 对需要混淆的函数指定注解, 如
__attribute((__annotate__(("fla"))))(新式语法[[clang::annotate("fla")]]), 这种方式仅支持C/C++,Objective-C和其他语言均不支持 - 对需要混淆的函数指定标记函数, 如下所示, 这种方式支持
Objective-C
objc
extern void hikari_fla(void);
@implementation foo2:NSObject
+(void)foo{
hikari_fla();
NSLog(@"FOOOO2");
}
@end以上方式均有局限性, 或对代码改动太大, 或无法控制到函数粒度, 或只支持特定语言。本项目使用配置文件(sllvm.json)来指定需要混淆的函数和模块, 兼容大部分编译器前端及开发语言。
一级/二级字段
log_level全局日志等级, 字符串类型, 可选字段, 默认无日志, 可选值:info|debugsrc_root源文件路径, 字符串类型, 可选字段, 默认为当前目录, 一般无需指定policies策略列表, 分为 模块级策略 和 函数级策略, 模块级策略有module,policy字段而无func字段, 函数级策略同时有module,func,policy字段module正则表达式, 用于匹配模块路径func正则表达式, 用于匹配函数名, 对于C++函数会Demangling再匹配policy字符串类型, 值为policy_map的某个key
policy_map策略索引, 用于在policies指定, 每个策略名对应一个字典, 字典字段如下:base继承的基策略名, 模块级或函数级策略, 字符串类型, 可选字段, 值为policy_map的某个keydump输出中间代码类型(sllvm_dump目录下), 模块级或函数级策略, 字符串数组类型, 默认空, 可选值:ir,mmd,asmenable_std启用C++标准库函数混淆, 模块级策略, 布尔类型, 可选字段, 默认禁用以减少兼容问题
函数级策略
enable_ce启用CE混淆ce_size_min最小字符串长度ce_size_max最大字符串长度ce_algo加解密算法ce_mode_stack字符串基于栈解密
enable_fla启用FLA混淆fla_probBasicBlock混淆比例fla_force_reg增加混淆强度fla_use_igv增加混淆强度fla_use_dyn增加混淆强度fla_use_rcf增加混淆强度fla_blk_size增加混淆强度fla_invoke_op兼容异常处理方式
enable_bcf启用BCF混淆bcf_probBasicBlock混淆比例bcf_complex表达式复杂度bcf_use_var使用变量构造表达式
enable_ecf启用ECF混淆ecf_probBasicBlock混淆比例
enable_fw启用FW混淆fw_loop_min函数嵌套层数最小值fw_loop_max函数嵌套层数最大值fw_exclude排除的子函数
enable_fcc启用FCC混淆fcc_num调用约定数量(模块级)fcc_type调用约定类型(模块级)fcc_narg_reg寄存器传参个数(模块级)
enable_ibr启用IBR混淆ibr_probBasicBlock混淆比例ibr_use_igv增加混淆强度ibr_use_dyn增加混淆强度
enable_icall启用ICALL混淆icall_use_igv增加混淆强度, 默认开启icall_use_dyn增加混淆强度
enable_igv启用IGV混淆igv_use_dyn增加混淆强度
enable_svc启用SVC混淆svc_usr_ir增加混淆强度
enable_split启用SPLIT混淆split_maxsize拆分指令数
enable_inline启用INLINE混淆enable_sec启用SEC混淆sec_ad_probFunction反调试插入比例sec_usr_ir增加混淆强度
一个典型的SLLVM配置文件sllvm.json如下:
json
{
"log_level": "info",
"policy_map": {
"mod_pol": {
"dump": ["ir"],
},
"func_pol": {
"enable_ce": true,
"ce_size_min": 5,
"ce_size_max": 128,
"ce_algo": 0
}
},
"policies": [
{
"desc": "模块级策略",
"module": ".*",
"policy": "mod_pol"
},
{
"desc": "函数级策略",
"module": ".*",
"func": ".*",
"policy": "func_pol"
}
]
}支持的混淆方式
字符串加密
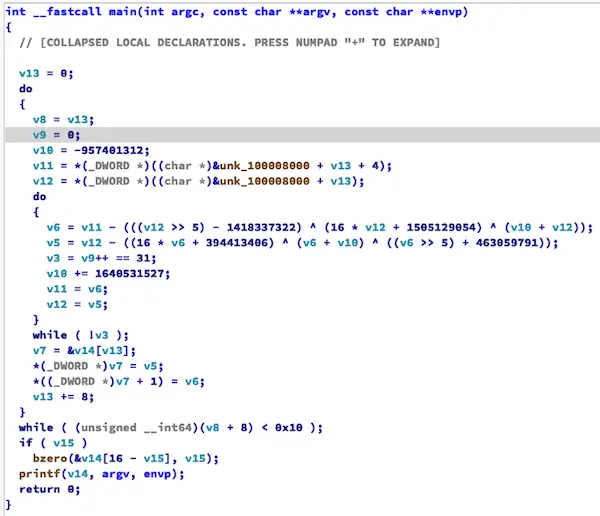
目前SLLVM的CE支持arm64/arm64e, 支持Objective-C常量字符串, 支持栈解密ce_mode_stack, CE是函数级混淆而非Hikari的模块级, 因此可以对指定函数中的所有字符串做混淆, 这样在处理header-only更方便.
与Hikari的区别:
- 支持XOR以外的加密算法
- 支持栈解密(
ce_mode_stack)
ce_algo
用于设置加解密算法, 目前支持30种算法, 复杂度介于XOR-AES之间, 取100则随机算法
ce_mode_stack
用于控制是否在栈上解密字符串. 若ce_mode_stack未开启, 则采取和Hikari同样的方式处理. Hikari字符串混淆, SLLVM的ce_mode_stack(S)模式, 基于C++模板元的字符串混淆, 这三种方式对比如下:
| 项 | Hikari |
SLLVMS模式 |
C++模板元 |
|---|---|---|---|
| 加密位置 | 静态区 | 静态区 | 静态区/立即数 |
| 解密时机 | 函数头 | 函数头 | 引用前 |
| 解密位置 | 静态区 | 栈区 | 栈区 |
| 需要改源码 | N | N | Y |
| 复杂算法 | 支持 | 支持 | 不适合 |
说明:
- 解密时机,
Hikari在函数头处解密且解密一次, 其他OLLVM系项目有的是在初始化函数解密的, 这种方式的缺点是解密一次即在静态区出现明文 - C++模板元方式只支持C++, 其他语言如Rust也有针对性的第三方库实现类似功能, 都需要对源码做变化
注意:
- 目前
OLLVM系没有实现对字符串混淆进行栈解密的, 因为字符串常量的本质是静态数据, 难以在IR层判断字符串是否可能发生逃逸. - 在
SLLVM中启用ce_mode_stack后字符串会从静态数据降级为栈数据, 因此有特殊使用方式.
展示
c
int main(int argc, char** argv) {
printf("hello sllvm\n");
return 0;
}CE静态区
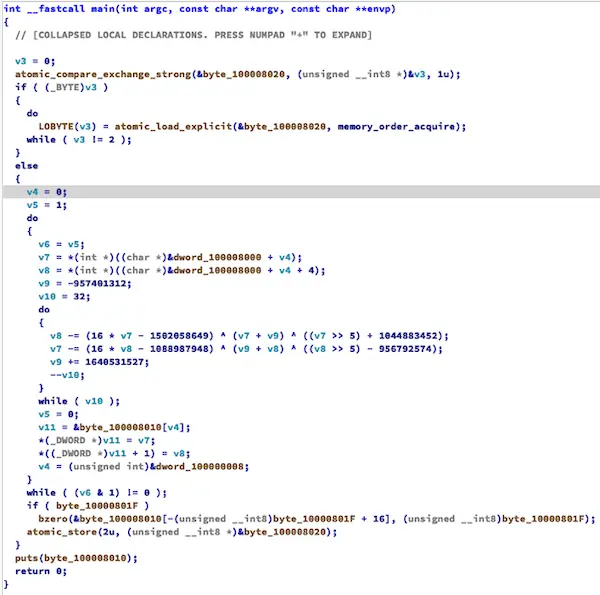
CE栈区
控制流平坦化
将控制流从顺序执行转换为switch-case循环执行, 与Hikari的区别:
- 弱化了大量
FLA特征(状态变量/入度/分发块/单循环) Hikari无法处理有异常处理的函数, 而SLLVM可以通过指定fla_invoke_op选择处理方式
展示
c
int main(int argc, char** argv) {
if (argc <= 0) {
printf("not possible\n");
} else if (argc == 1) {
printf("no args\n");
} else {
printf("%d args\n", argc - 1);
}
return 0;
}FLA全开

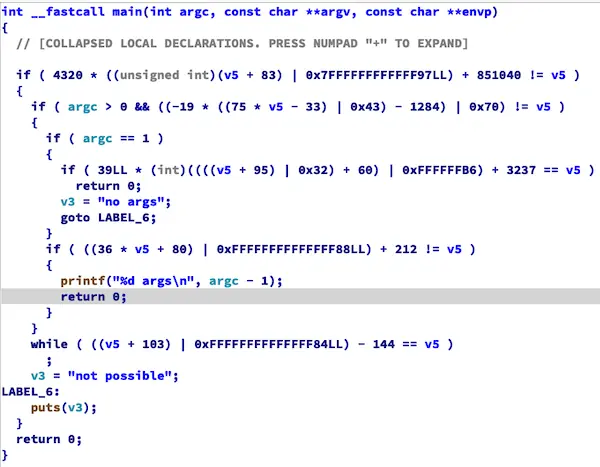
控制流伪造
向顺序执行的控制流插入条件恒假的条件分支, 与Hikari的区别:
- 混淆不会在Release下编译时被编译器还原
- 混淆不会因为在
IDA中设置数据段只读而被还原(依赖bcf_use_var)
展示
c
int main(int argc, char** argv) {
if (argc <= 0) {
printf("not possible\n");
} else if (argc == 1) {
printf("no args\n");
} else {
printf("%d args\n", argc - 1);
}
return 0;
}BCF常量
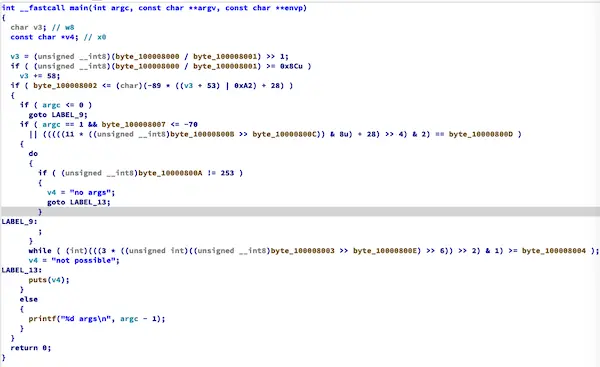
BCF变量
控制流另类混淆
全新的混淆思路, 可以对抗Angr等工具跟踪
函数嵌套
对指定函数直接调用的子函数执行嵌套, 与Hikari的区别:
- 混淆不会在Release下编译时被编译器还原
调用约定混淆
对常规C调用约定转换为随机调用约定, 改变参数和返回值所用寄存器, 目前只实现ARM64的部分
fcc_num指定随机CallingConv的数量fcc_type指定自定义CallingConv的类型, 取值如下- 0 仅使用
X0~X8 - 1 仅使用整数寄存器
- 2 仅使用浮点寄存器
- 10 使用任意寄存器
- 0 仅使用
fcc_narg_reg寄存器最大传参个数, 其余参数用栈传递
展示
c
static int test(int a0, int a1, int a2, int a3, int a4) {
printf("a0=%d\n", a0);
printf("a1=%d\n", a1);
printf("a2=%d\n", a2);
printf("a3=%d\n", a3);
printf("a4=%d\n", a4);
return a0 + a1 + a2 + a3 + a4;
}
int main(int argc, char** argv) {
test(argv[0][0], argv[0][1], argv[0][2], argv[0][3], argv[0][4]);
return 0;
}FCC使用X8(X8,X1,X6,...)

FCC使用D26(D26,D2,X15,...)

间接跳转
与Hikari的区别:
- 混淆不会在Release下编译时被编译器还原
ibr_use_igv和Hikari的indibran-enc-jump-target类似, 结合ibr_use_dyn可以进一步增加混淆强度
展示
c
int main(int argc, char** argv) {
if (argc <= 0) {
printf("not possible\n");
} else if (argc == 1) {
printf("no args\n");
} else {
printf("%d args\n", argc - 1);
}
return 0;
}IBR全开

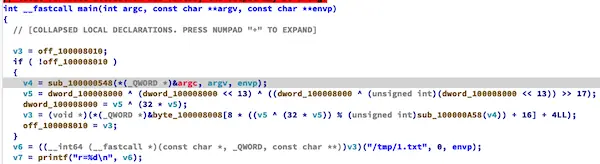
系统调用混淆
将系统调用函数转SVC
展示
c
int main(int argc, char** argv) {
int r = access("/tmp/1.txt", 0);
printf("r=%d\n", r);
return 0;
}SVC基础
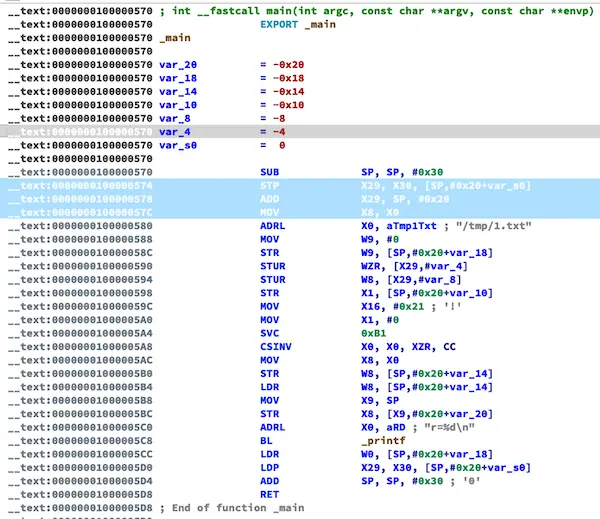
SVC自定义1
拆分指令
将函数指令拆分到整个模块的随机地址
展示
c
void test(int argc) {
if (argc <= 0) {
printf("not possible\n");
} else if (argc == 1) {
printf("no arg\n");
} else {
printf("%d args\n", argc - 1);
}
}
int main(int argc, const char** argv) {
if (argc <= 0) {
printf("not possible\n");
} else if (argc == 1) {
printf("no arg\n");
} else if (argc == 2) {
printf("1 arg\n");
} else {
printf("%d args\n", argc - 1);
}
return 0;
}SPLIT全开

内联子函数
将指定函数的所有子函数内联到当前函数中
安全防护
将反调试逻辑插入到函数中