负载均衡是学习后端绕不开的核心知识点,它不仅能让我们的服务扛住流量洪峰,还能让服务器资源利用得更高效。
什么是负载均衡?
简单来说,负载均衡就是把一堆请求任务,均匀分配到多台服务器(或多个进程)上,避免某一台机器被压垮,而其他机器却在 "摸鱼"。
它的核心目标有两个:
- 优化响应速度:让每个请求都能快速被处理,减少用户等待时间。
- 避免单点过载:防止单个计算节点(服务器 / 进程)因为任务太多而崩溃,同时提升系统整体可用性。
在实际生产环境中,负载均衡是分层实现的,从用户请求进入到后端服务处理,每一层都有对应的负载均衡方案。
网络层的负载均衡
这一层是用户请求的第一道关卡,主要负责把海量流量分发到后端服务器集群。主要有:
-
DNS 负载均衡:把同一个域名解析到多个公网 IP,实现最顶层的流量分发。
-
CDN:把静态资源(图片、CSS、JS)缓存到全球节点,让用户就近访问,减轻源站压力。
-
LVS(Linux Virtual Server) :工作在四层(传输层),性能极高,能处理百万级并发,负责把流量转发到后端的 Nginx 集群。
-
Nginx:工作在七层(应用层),可以根据 URL、域名、请求头做更精细的流量分发,同时还能做静态资源缓存、反向代理、健康检查。
为了保证高可用,Nginx 通常会部署主备模式,主 Nginx 对外提供服务,备 Nginx 通过心跳检测监听主节点状态,一旦主节点挂掉,备节点会立刻接管 VIP(虚拟 IP),保证服务不中断。
应用层的负载均衡
当流量到达服务后,应用层同样需要实现负载均衡机制。
服务的负载均衡
Node.js 是单线程的,默认只能用一个 CPU 核心。如果想充分利用服务器的多核资源,就需要用到 Cluster 模块 ,它能让我们创建多个工作进程(Worker),共同监听同一个端口,实现进程级别的负载均衡。
js
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`);
// 根据 CPU 核心数 fork 工作进程
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
// 监听工作进程退出,自动重启
cluster.on('exit', (worker, code, signal) => {
console.log(`worker ${worker.process.pid} died`);
cluster.fork();
});
} else {
// Worker 进程创建 HTTP 服务
http.createServer((req, res) => {
res.writeHead(200);
res.end('hello world\n');
}).listen(8000);
console.log(`Worker ${process.pid} started`);
}cluster 模块采用主从架构,将进程分为两类:
Master 进程(主进程)
-
第一次执行脚本时,
cluster.isMaster为true,当前进程就是 Master。 -
它不处理具体的 HTTP 请求,只负责:
- 根据 CPU 核心数,
fork出多个 Worker 进程。 - 监听端口,接收客户端连接。
- 管理所有 Worker 进程的生命周期(比如监听 Worker 退出事件,自动重启)。
- 将接收到的请求,按照负载均衡策略转发给空闲的 Worker。
- 根据 CPU 核心数,
Worker 进程(工作进程)
- 由 Master 进程
fork出来,执行同一份脚本,此时cluster.isMaster为false。 - 每个 Worker 都有独立的内存空间和 V8 实例,互不干扰。
- 负责处理实际的业务逻辑(比如 HTTP 请求、数据库操作)。
- 多个 Worker 可以同时监听同一个端口(由 Master 进程统一调度)。
正常情况下,多个进程监听同一个端口会触发 EADDRINUSE 错误(端口被占用)。cluster 模块通过以下方式解决:
- Master 真正监听端口:只有 Master 进程会在操作系统层面绑定 8000 端口。
- Worker 逻辑监听 :Worker 调用
listen()时,并不会真正绑定端口,而是通过 IPC 通知 Master:"我准备好处理请求了"。 - 请求转发:当客户端连接到达时,Master 接收连接,再按照负载均衡策略,将连接转发给某个 Worker 处理。
Node.js 默认提供两种分发策略,默认的转发策略是 round-robin(轮询) ,
-
round-robin(轮询,默认,除 Windows 外)
- Master 进程负责监听端口,接收所有新连接。
- 按照循环顺序,将连接依次分发给各个 Worker 进程。
- 内置了防过载机制,避免某个 Worker 瞬间被大量请求压垮。
- 优点:分发均匀,实现简单,稳定性高。
- 缺点:Master 进程会成为转发的中间层,有轻微性能损耗
-
shared socket(共享 socket,Windows 默认)
- Master 进程创建监听 socket 后,将其发送给所有 Worker。
- Worker 直接从 socket 上接收连接,Master 不参与转发。
- 优点:理论上性能更高,少了一次转发。
- 缺点:依赖操作系统的调度算法,分发可能不均匀,在高并发下稳定性稍差。
你可以通过以下方式修改策略:
js
// 方式1:设置环境变量
process.env.NODE_CLUSTER_SCHED_POLICY = 'shared'; // 或 'rr'
// 方式2:在 setupMaster 中配置
cluster.setupMaster({
schedulingPolicy: cluster.SCHED_NONE // shared 模式
// schedulingPolicy: cluster.SCHED_RR // round-robin 模式
});这里需要注意的一点是每个 Worker 进程都是独立的 V8 实例,内存完全隔离。这意味着:
-
不能直接在进程间传递变量(比如全局对象、缓存)。
-
如果需要共享数据,必须通过:
- 外部存储(Redis、数据库)。
- IPC 通信(
process.send()/cluster.on('message'))。
RPC 与分布式负载均衡
当业务变得复杂,我们会把系统拆分成多个微服务(比如用户服务、订单服务、支付服务),这时候就需要远程过程调用(RPC) 来实现服务间通信,同时在服务调用层面做负载均衡。
什么是 RPC?
RPC(Remote Procedure Call)的核心思想是:让开发者像调用本地函数一样,调用远程服务器上的服务,不用关心底层网络通信细节。
它的完整流程是:
- 客户端(Client) :发起服务调用。
- Client Stub:把调用的方法名、参数等序列化成网络可传输的消息,然后找到服务端地址,发送请求。
- Server Stub:接收消息后反序列化,调用本地服务。
- 服务端(Server) :执行业务逻辑,返回结果给 Server Stub。
- 结果回传:Server Stub 把结果序列化后返回给 Client Stub,Client Stub 再反序列化后交给客户端。
client stub:客户端代理对象,帮你隐藏网络调用细节,让你调用远程服务,就像调用本地方法一样简单。
RPC 只是一种概念,具体实现需要依赖传输协议 (比如 TCP、HTTP)和序列化协议(比如 JSON、Protobuf)。
RPC调用过程与HTTP调用类似,区别在于HTTP的序列化/反序列化由浏览器或框架自动完成,而RPC需要显式的client stub和server stub处理层来处理传输协议和序列化协议。
也就是说,你既可以用HTTP,也可以用TCP来进行RPC调用。但是,底层系统常使用TCP而非HTTP作为传输协议,因为HTTP是应用层协议,内容较多影响性能。
那为什么 TCP 比 HTTP 性能更好,本质差在哪?
HTTP 是跑在 TCP 之上的应用层协议,自带一堆额外开销,直接用 TCP 等于去掉所有 HTTP 多余成本,裸连传输数据。
比如,HTTP 有 header 开销,TCP 没有,每次 HTTP 请求都要带:
diff
- 请求头 / 响应头(Cookie、User-Agent、Content-Type、Cache 等)
- 状态行
- 可能还有 gzip 解压、解析几百字节~几 KB 的纯开销,小接口尤其浪费。TCP 只传你真正要发的二进制 / 字符串,没有任何额外格式。
最直观对比,发一条 100 字节消息,HTTP总流量可能500~2000 字节,而TCP只发100 字节,延迟差距是几倍~几十倍。
另外, HTTP 是一问一答,是一种半双工通信,不能主动推送。TCP是全双工通信,服务器随时能推消息,不用等客户端问,适合聊天室、实时通知、游戏、监控,少了大量轮询请求,性能自然爆炸。
分布式 RPC 负载均衡是怎么做的呢?
答案是注册中心 + 服务发现。
核心流程如下:
- 服务注册 :服务提供方(Provider)启动后,把自己的 IP、端口、服务名等信息上报到注册中心(比如 ZooKeeper、Eureka、Nacos)。
- 服务发现:服务调用方(Consumer)启动时,会订阅注册中心,获取到目标服务的所有节点 IP 列表。
- 负载均衡:Consumer 拿到 IP 列表后,通过负载均衡算法(比如加权轮询、随机、最小连接数)选择一个节点,发起 RPC 调用。
- 健康检查:注册中心会定期检查 Provider 节点的健康状态,一旦某台机器挂掉,就会把它从可用列表中移除,并通知 Consumer。
这种模式的好处是:服务节点可以动态扩缩容,Consumer 无需感知底层服务的变化,注册中心会自动同步最新的服务列表。
总结一下:
从用户请求到后端服务,负载均衡贯穿了整个架构链路:
- DNS/CDN:最顶层的流量分发,减轻源站压力。
- LVS/Nginx:四层 / 七层负载均衡,把流量转发到后端服务器集群。
- Node.js Cluster:进程级负载均衡,充分利用多核 CPU,提升单机吞吐能力。
- RPC 服务发现:微服务间的负载均衡,实现服务的弹性扩缩容。
不同层级的负载均衡解决了不同的问题:
- 上层负载均衡解决机器级别的高可用,防止单台服务器故障影响全局。
- 下层负载均衡解决进程 / 服务级别的资源利用,让单机和微服务都能发挥最大性能。
负载均衡算法
在负载均衡的世界里,算法决定了请求如何被分发到后端节点。
负载均衡的算法主要分两类:
- 静态算法:不关心服务器当前状态,直接按固定规则分配(比如轮询、加权轮询),实现简单但不够灵活。
- 动态算法:会根据服务器的实时负载(CPU、内存、连接数等)动态调整分配策略,更智能高效,但需要节点之间通信,会有一点性能损耗。
下面来看三种最常用的算法:轮询(Round Robin)、源 IP 哈希(Source IP Hash)和最小连接数(Least Connection)。
轮询(Round Robin)
实现原理:依次轮询服务队列的节点列表,每次选择一个节点,调用非常均衡。一般通过当前下标+1对机器数量取模获取下一个节点下标。
比如,有6个客户访问时,那么对服务器数量取模,1/6 = 1,分配到1号机器, 2/6=2, 分配到2号机器.....,因为是对机器数量取模,所以总会找到一台对应的机器。
它的缺点是无法感知服务器真实负载情况,当某台服务器处理复杂请求时仍会继续分配新请求,导致承压过大。
为了应对节点性能不一致的场景,轮询算法进化出了加权轮询:
- 给每个节点设置一个权重值(比如性能好的节点权重设为 5,普通节点设为 2)。
- 分发请求时,权重越高的节点,被选中的次数越多。
- 例如:节点 A(权重 3)、节点 B(权重 1),分发顺序会是 A→A→A→B→A→A→A→B...,保证高权重节点承担更多流量。
源 IP 哈希(Source IP Hash)
源 IP 哈希算法通过哈希函数 ,将请求的源 IP 地址映射到固定的后端节点。
简单来说,让某个用户的请求一直转发到某台固定的服务器上。
- 提取请求的客户端 IP 地址(比如
192.168.1.100)。 - 对 IP 地址做哈希计算(比如
hash(192.168.1.100)),得到一个哈希值。 - 用哈希值对后端节点总数取模(
hashValue % nodeCount),得到目标节点的索引。 - 同一个 IP 地址的所有请求,都会被映射到同一个后端节点。
但是,这样会有一个问题,当机器数量减少时,会导致雪崩效应。
如下图:
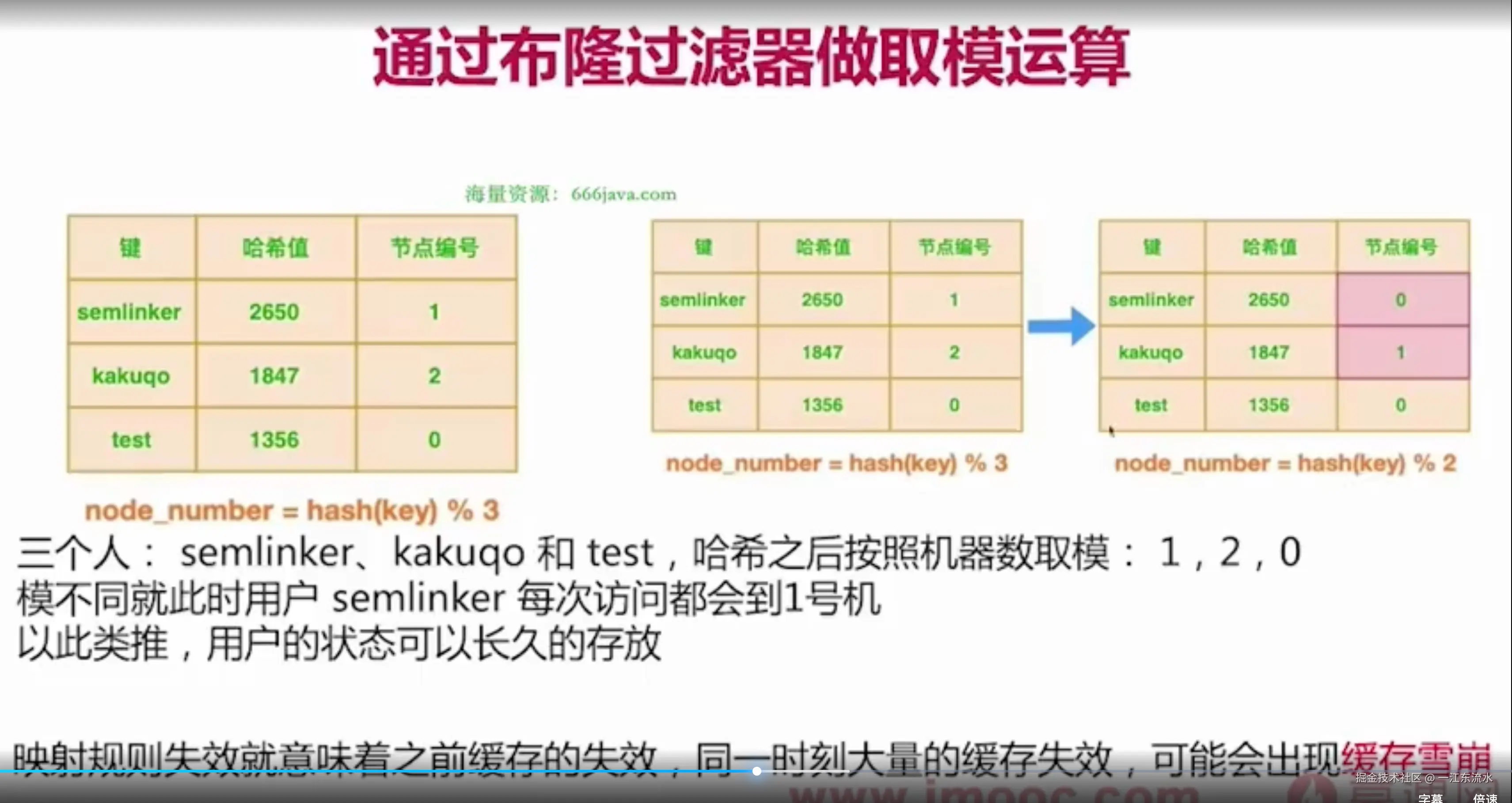
原来机器数量是3台,取模后对应访问的机器是1、2、0。但是现在有一台机器坏了,取模的分母变成了2,那么对应的机器就都变了,从而导致缓存雪崩。
为了解决节点增减时的 "雪崩效应",源 IP 哈希进化出了一致性哈希:
- 把所有节点和请求 IP 都映射到一个环形哈希空间上。
- 节点增减时,只会影响哈希环上一小部分请求的映射关系,大部分请求仍会被映射到原来的节点,避免大量会话失效。
了解即可。
最小连接数算法(Least Connection):智能选择最闲的节点
最小连接数算法是一种动态负载均衡算法 ,它会实时关注每个节点的当前连接数 ,把新请求分配给连接数最少的节点:
- 负载均衡器维护每个节点的 "当前活跃连接数"。
- 新请求到达时,遍历所有节点,找到当前连接数最少的那个。
- 将请求分配给该节点,并将其连接数 + 1;请求处理完成后,连接数 - 1。