记录大厂日常开发中 SQL Explain 命令中的常见字段,方便快速查阅,绝对的一线经验和实践。
本文参考:
- https://developer.aliyun.com/article/1150833?spm=a2c6h.24874632.expert-profile.252.10a0105aEudzbN
- https://developer.aliyun.com/article/1150834?spm=a2c6h.24874632.expert-profile.251.10a0105aEudzbN
select_type
一条大的查询语句里面可以包含若干个SELECT 关键字,每个SELECT关键字代表着一个小的查询语句,这个字段主要用来表示每个查询语句的查询类型
常用的枚举如下:
| 名称 | 描述 |
|---|---|
| SIMPLE | 简单的查询(没有使用UNION 或者子查询(subqueries) |
| PRIMARY | 主键查询 |
最常见的就是 SIMPLE 类型了
type
代表 SELECT 语句的查询方法,
完整的访问方法如下:system,const,eq_ref,ref,fulltext,ref_or_null,index_merge,unique_subquery,index_subquery,range,index,ALL
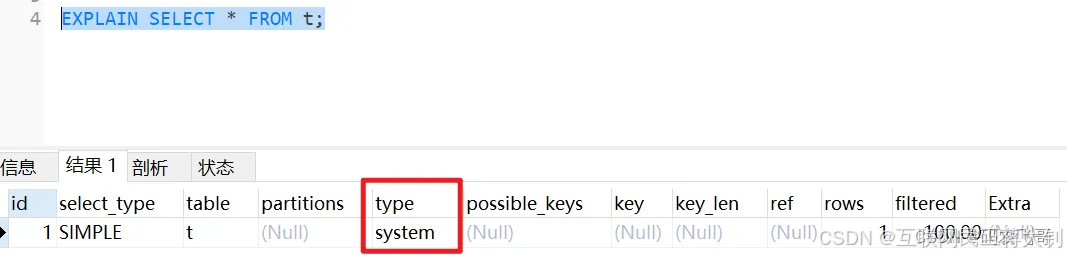
system
当表中只有一条记录 并且该表使用的存储引擎的统计数据是精确的,比如MyISAM、Memory、那么对该表的访问方法就是system。比方说我们新建一个MyISAM表,并为其插入一条记录。
const
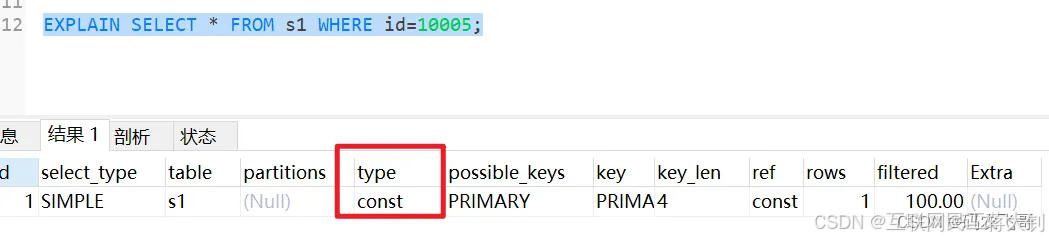
const 表示通过索引一次就找到,const用于比较primary key或者unique索引,因为只需匹配一行数据,所以很快,如果将主键置于where列表中,mysql就能将该查询转换为一个const。
当我们根据主键或者唯一二级索引列与常数进行等值匹配时,对单表的访问方法就是const。
eq_ref
唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或者唯一索引扫描。
ref
非唯一性索引扫描,返回匹配某个单独值的所有行。

ref_or_null
当对普通二级索引进行等值匹配查询,该索引列的type值就可能是ref_or_null。

range
只检索给定范围的行,一般就是在where语句中出现了 between、<、>、in等的查询。这种索引上的范围扫描比全表扫描要好。只需要开始于某个点,结束于另一个点,不用扫描全部索引。

Index
Full index Scan,index与ALL区别为index类型只遍历索引树,ALL 会遍历全表。Index 会相对快些,因为索引文件通常比数据文件小,但最后整体效率也不高。

ALL (全表扫描)
ALL: Full Table Scan,遍历全表以找到匹配的行

type(访问类型)是sql查询优化中一个很重要的指标,结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
其中比较重要的几个做了加粗处理,SQL性能优化的目标:至少要达到range级别,要求是ref级别,最好是const级别(阿里巴巴开发手册要求)
rows
这个概念得和 filtered 搭配着看,之前我就是一直混淆,所以奋而想写这篇文章记录下。从 SQL Server 服务器 + InnoDB 整个存储引擎架构上理解这个概念,总结就是:
存储引擎返回给 SQL Server 的扫描记录条数,
再剖析下,从存储引擎返回的记录,可以走表索引,也可以不走表索引,对应就是 key 也是有可能非空的。那我们在进行索引优化实践时,既要保证查询走索引(type = ref),同时走索引的情况下,rows 越小越好,这样子表明索引的过滤效率高。
索引精确查找
这里key1='z' 可以直接通过索引精确查找,所以预估的rows为1。

范围查找
这里key1>'z' 可以不能通过索引精确查找,所以预估的rows大于1,这里的rows值为398。

filtered
从前面 rows 返回记录的基础上,SQL 服务器进一步地还会过滤一遍记录,最终返回给客户端。这个代表的就是最终返回给客户端条数占 rows 条数的比例。

结合上面的 case,key1 走存储引擎的索引过滤返回了 398 条记录,AND common_field 走不了索引了,是在 SQL 服务器过滤的(在 Extra 里的 Using where 也体现),最终过滤出来只有 10% 的记录符合条件。