本瓜手上的是一台 M4 32G 内存的 mac,我看了一篇关于:4090 跑 Qwen 35b 模型(MoE)-0限制版本 的实战文章,所以,便想着记录一下,相关的对比情况:
| 项目 | Apple M4 | RTX 4090 |
|---|---|---|
| GPU算力 | ~20--25 TFLOPS | ~82 TFLOPS |
| AI Tensor算力 | ~100--150 TOPS | ~1300+ TOPS |
| 显存 | 共享内存 | 24GB GDDR6X |
| 带宽 | ~120--150 GB/s | ~1 TB/s |

最直接的结论:
4090 的 AI 推理算力大约是 M4 的 3~6 倍。
4090 是专门为 AI 训练 / 推理设计,M4 是通用 SoC,所以在深度学习框架(CUDA生态)下:PyTorch、TensorRT、vLLM,4090 都会更强。
但 Mac 有个很大的优势:统一内存架构(Unified Memory)。,在本地 LLM 推理中:Mac 可以GPU用一部分、CPU用一部分、自动共享

比如:40GB模型,Mac 32GB:GPU+CPU 可以混合跑。4090:显存只有 24GB ,必须:量化、offload CPU,否则放不进去。
Apple Silicon 的 统一内存架构 + Metal 推理,使得 Mac 在 本地 LLM 推理领域的性价比非常高。很多原本以为必须上 4090 的模型,其实在 Mac 上也能跑,只是速度不同。
下面这份榜单,按 实际可用性 + 能力上限 排序,专门针对 M4 32GB / M3 36GB / M2 32GB 这类配置。
备注:
排名依据:实际可运行、能力强度、速度体验、社区成熟度
运行环境默认:llama.cpp 、LM Studio 、Jan 、Ollama
模型格式:GGUF
第一梯队:最强可用模型
这类模型属于:能力接近云端模型,但本地还能跑。
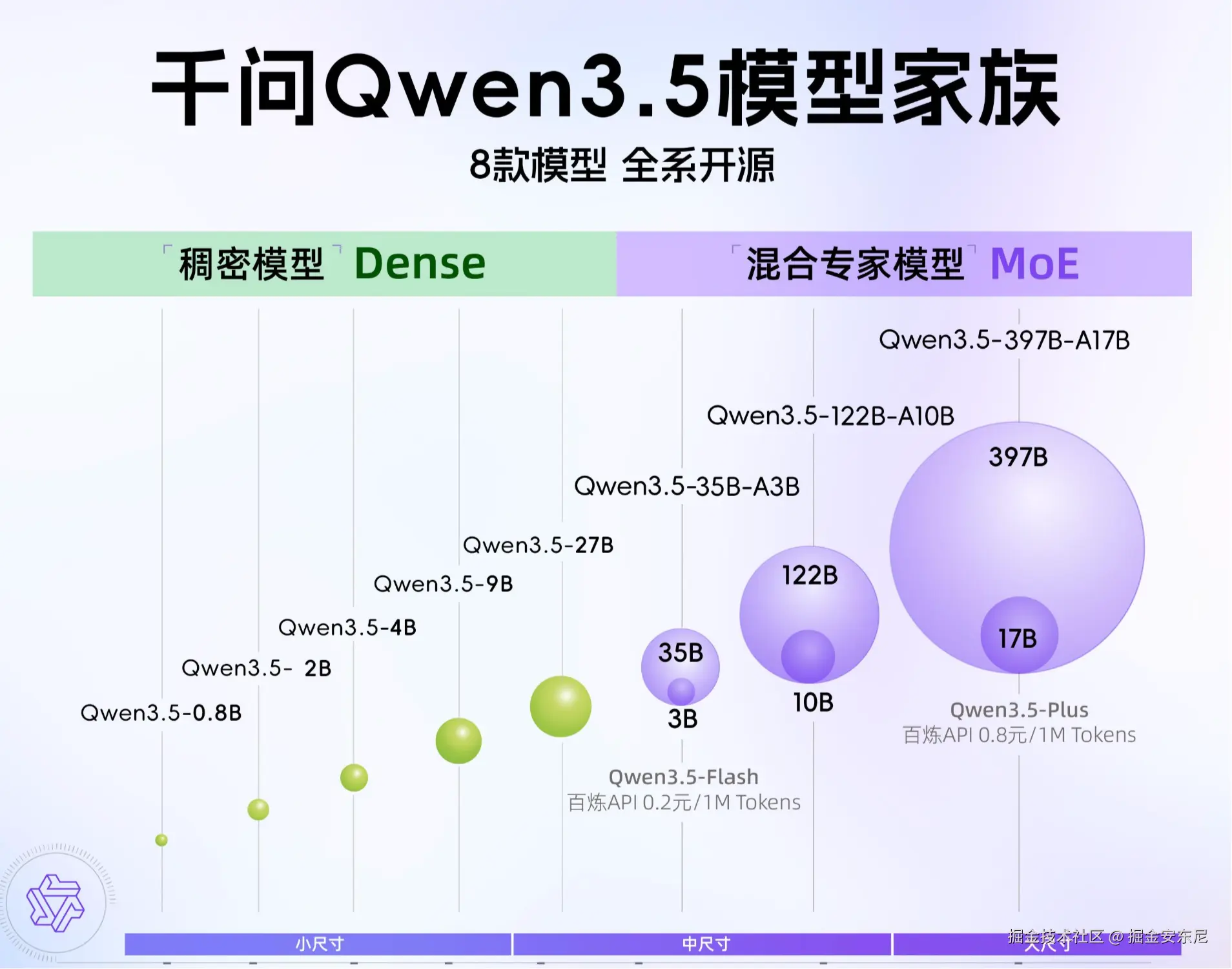
1️⃣ Qwen3.5 35B 系列(最推荐)
能力:极强推理、代码能力强、中文能力最强
推荐量化:
Q4_K_M占用:
≈ 20-24GB
体验:
- M4 32GB:可流畅运行
- tokens:≈ 10-20 tok/s
适合:
- 编程
- AI Agent
- 文档分析
- 长上下文任务
这是目前 Mac 上综合能力最强的一档模型。
2️⃣ Mixtral 8x22B(MoE)
这是目前非常经典的 MoE 模型。
结构:8个专家、每次激活2个
实际计算量:≈ 13B
推荐量化:
Q3_K_M占用:≈ 24GB+
特点:
- 推理强
- 写作能力强
- 非常稳定
很多人认为这是 最像 GPT-4 的开源模型之一。
3️⃣ DeepSeek V3 Distill 系列
DeepSeek 的蒸馏模型是近两年最火的。
优势:
- 数学
- 推理
- 代码
推荐版本:
DeepSeek-R1-Distill-Qwen-32B推荐量化:
Q4_K_M占用:≈ 22GB
体验:
Mac 上运行效果非常好。
第二梯队:速度与能力平衡
这类模型:
速度明显更快,但能力稍低。
4️⃣ Llama 3.1 70B(低量化)
70B 模型本身极强,但 Mac 必须低量化。
推荐:
IQ2_M占用:≈ 24-28GB
体验:
- 能跑
- 速度一般
优点:
知识面非常广。
5️⃣ Qwen2.5-14B
这是非常稳定的一个模型。
优点:
- 中文非常强
- 代码不错
- 推理稳定
推荐量化:
Q6_K占用:≈ 14GB
速度:
≈ 30 tok/s
非常适合作为:
日常 AI 助手。
6️⃣ Yi-34B
阿里之前投资的零一万物模型。
能力:
- 中文写作
- 逻辑
推荐量化:
Q4_K_M占用:
≈ 22GB
第三梯队:极致速度
这类模型:
小,但非常快。
7️⃣ Qwen2.5-7B
推荐量化:
Q8_0占用:8GB
速度:≈ 60 tok/s
适合:
- AI coding
- Agent
- 工具调用
8️⃣ Llama 3.2 3B
优点:
- 极快
- 低功耗
适合:
- AI终端
- 嵌入式
第四梯队:实验级模型
这类模型可以跑,但不推荐日常使用。
Llama-3-405B(分层)
需要:
- CPU offload
- 超慢
仅适合:
研究。
最终结论
Mac M4 最佳模型组合
| 场景定位 | 推荐模型 | 参数规模 | 推荐量化 | 内存占用 | 速度(tok/s) | 能力特点 | 适用任务 | 是否主力 |
|---|---|---|---|---|---|---|---|---|
| 编程主力 | Qwen3.5-35B | 35B(MoE) | Q4_K_M | 20--24GB | 10--20 | 强推理 + 强代码 + 中文强 | Copilot / Debug / Agent | ⭐⭐⭐⭐⭐ |
| AI助手 | Qwen2.5-14B | 14B | Q6_K | ~14GB | 25--35 | 稳定、泛用强、响应快 | 日常问答 / 办公 / RAG | ⭐⭐⭐⭐ |
| 超快Agent | Qwen2.5-7B | 7B | Q8_0 | ~8GB | 50--70 | 速度极快、可工具调用 | Agent / 自动化流程 | ⭐⭐⭐⭐⭐ |
| 推理增强 | DeepSeek-R1-Distill-32B | 32B | Q4_K_M | ~22GB | 10--18 | 数学/逻辑极强 | 推理 / 分析 | ⭐⭐⭐⭐ |
| 写作增强 | Mixtral 8x22B | MoE | Q3_K_M | 24GB+ | 12--20 | 文风好、结构强 | 内容生成 | ⭐⭐⭐⭐ |
| 大模型实验 | Llama3 70B | 70B | IQ2_M | 24--28GB | 5--10 | 知识广 | 研究 | ⭐⭐ |
现在,2026 年 3 月,Mac M4 + 32GB 它大致相当于:一台中端 AI 推理工作站,可以稳定运行:30B 级模型
能力已经远远超过:- ChatGPT 3.5 - 早期 Claude,而且:完全本地、离线运行。
这也是为什么越来越多开发者开始用 Mac 做 AI 本地实验室。
很多结果会非常出乎意料。