
导读
多模态3D全景分割是自动驾驶与机器人感知的关键技术,但模型一到新地点、新天气或新时段就会明显退化,而目标域标注又贵又慢。
PanDA是第一个直面这个问题的框架------在无目标域标签的条件下,让多模态(LiDAR + RGB)全景分割模型跨域泛化。它用 非对称多模态丢弃(AMD)模拟真实世界的传感器退化,用 双专家伪标签精炼(DualRefine)融合3D几何与2D视觉大模型的先验来修复不完整、不可靠的伪标签。在 nuScenes 的昼夜、晴雨、洲际地点以及 SemanticKITTI → nuScenes 四种域偏移下,PanDA 的 PQ 分别比 Baseline 提升 +8.4%、+8.9%、+13.2%、+53.3%。该工作被作者称为"首个面向多模态3D全景分割的UDA研究"。
论文信息
-
标题:PanDA: Unsupervised Domain Adaptation for Multimodal 3D Panoptic Segmentation
-
作者:Yining Pan, Shijie Li, Yuchen Wu, Xulei Yang, Na Zhao
-
骨干模型:IAL (ICML 2025)
-
任务:多模态(LiDAR+RGB)3D全景分割的无监督域适应
一、为什么多模态3D全景分割需要域适应?
3D全景分割同时识别可数的"物"(车、行人)和不可数的"stuff"(道路、植被),是自动驾驶与机器人交互的基础能力。最新多模态方法在单一域内表现亮眼,但一旦跨域就会大幅退化:
-
晴天 → 雨天:LiDAR 点云变稀疏
-
白天 → 夜晚:图像质量骤降
-
波士顿 → 新加坡:地理、建筑、植被结构剧变
-
64线 LiDAR → 32线 LiDAR:传感器差异巨大
这些变化打破了现有模型对"两种模态始终可靠"的假设,导致跨模态融合崩塌。直接套用语义分割的UDA方法(如置信度阈值过滤生成伪标签)用于全景分割,会产生碎片化的实例掩码和模糊的边界,严重损害"物"与"stuff"的分割质量。PanDA 正是在这一空白上建立的第一个 mm-3DPS UDA 框架。
二、PanDA 框架:Mean Teacher + 非对称多模态丢弃
PanDA 基于 Mean Teacher 范式,师生网络结构完全相同(均用 IAL),教师权重由学生通过指数移动平均(EMA)更新。在源域,PanDA 用非对称多模态丢弃(AMD) 模拟模态退化;在目标域,用**双专家伪标签精炼(DualRefine)**修复伪标签,再以此监督学生模型。整体训练损失包含源域全景损失、源域辅助语义损失、目标域全景损失和师生一致性损失。
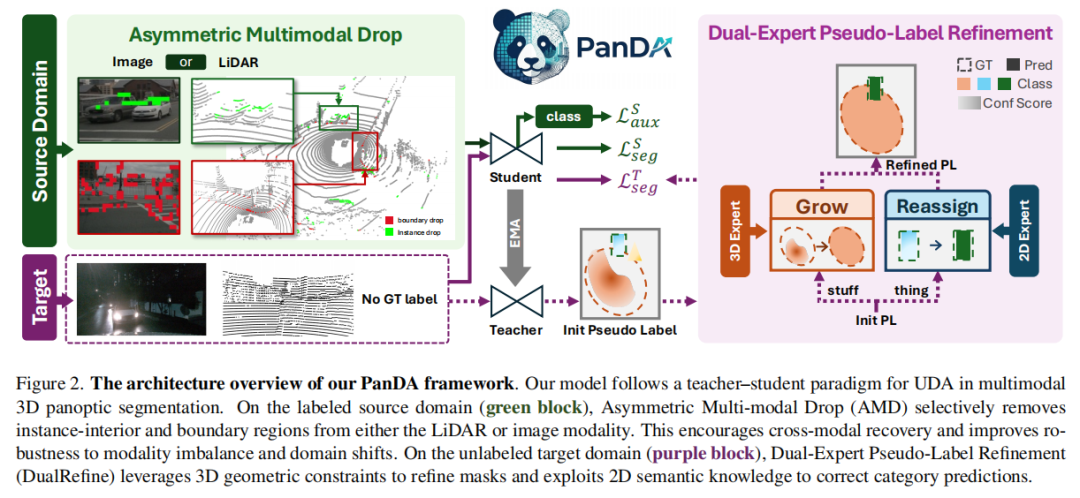
图片来源于原论文
AMD 的核心思路 是:既然目标域中某模态可能不可靠,那就在源域人为制造模态不平衡。对每一帧,以 0.5 的概率随机选择 LiDAR 或图像之一进行结构化丢弃,且丢弃并非随机,而是专门针对全景分割最重要的两类区域:
-
边界丢弃:图像用 Canny 边缘检测定位边界 patch,以 (r_{\mathrm{bd}}^{\mathrm{2D}}=0.5) 的比例将其置零;LiDAR 根据体素标签不一致性检测几何间断,以 (r_{\mathrm{bd}}^{\mathrm{3D}}=0.7) 丢弃这些体素的特征(保留坐标)。
-
实例丢弃:选定"物"实例,在图像中以 (r_{\mathrm{ins}}^{\mathrm{2D}}=0.5) 随机遮盖内部 patch;在 LiDAR 中则找到实例投影到同一 patch 的点簇,以相同比例置零点特征。
这种"边界+内部"的双维度丢弃迫使模型在缺失关键信息时,仍能依靠另一模态恢复出完整实例和清晰边界,从而增强跨域鲁棒性。而且,同一套 AMD 超参数在所有四种域偏移下均适用,无需域特异的增强设计。为强化掩码建模,学生模型还额外附加了 2D 与 3D 辅助语义分割头,用交叉熵损失监督。
三、双专家伪标签精炼:让伪标签又完整又正确
在目标域,教师模型首先生成初步全景预测,然后经过类别感知的过滤:对"stuff"类使用逐点自适应阈值保留高置信点,对"物"类则计算每个实例的平均置信度,以 (\tau_{th}=0.63) 的全局阈值过滤低置信实例。这一步骤虽然降噪,却会导致 stuff 掩码出现空洞、边界断裂,以及部分保留实例类别错误。
DualRefine利用两类域不变专家来逐一修复这些问题:
-
阶段一:Grow ------ 基于3D几何超点扩展 stuff
从 LiDAR 中提取几何超点 (\mathcal{G})(RANSAC 地平面分离 + HDBSCAN 聚类),为每个截断的 stuff 掩码寻找 IoU ≥0.5 的最佳匹配超点 (g^*),然后合并掩码与超点。冲突时优先保留扩展后的 stuff,从 thing 掩码中切除重叠区域。这一步利用的是三维形状的连续性,不受天气、光照等外观域变化的影响,能够有效恢复被过滤掉的连续路面和植被。
-
阶段二:Class Reassignment ------ 基于2D视觉大模型重分类 thing
引入视觉超点 (\mathcal{Q})(Grounding DINO + SAM 的 2D proposal 投影至 3D),为每个 thing 实例匹配 IoU ≥0.5 的视觉超点 (q^*)。当实例的平均置信度 (\bar{\mathbf{S}}(k)) 低于视觉超点的置信度且小于上限 (t_{\mathrm{cls}}=0.2) 时,用视觉大模型的语义标签覆盖原预测。这让模型即使在目标域的物体外观大幅变化时,也能获得正确的类别标签。
最终,经过 Grow 和 Reassign 两步精炼的伪标签被用来监督学生模型,实现从残缺到完整、从错误到可靠的跨越。
四、实验与消融分析
实验覆盖四种域偏移:USA→Singapore(地点)、Sunny→Rainy(天气)、Day→Night(时间)、SemanticKITTI→nuScenes(跨数据集,64线→32线,德国→新加坡)。Baseline 为仅在源域训练后直接评估,上界包括 Oracle‑Target(目标域全监督)和 Oracle‑Joint(双域全监督)。
主要结果
与 Baseline 相比,PanDA 的 PQ 提升幅度如下:
| 域偏移 | Baseline PQ* | PanDA 提升 (PQ) |
|---|---|---|
| USA → Singapore | -- | +13.2% |
| Sunny → Rainy | -- | +8.9% |
| Day → Night | 64.7 → 73.1 | +8.4% |
| SemanticKITTI → nuScenes | -- | +53.3% |
注:Baseline 绝对数值在预印本中仅 Day→Night 写明为 64.7%,其余以提升百分比形式给出。

图片来源于原论文
DualRefine 消融
消融实验验证了 DualRefine 两个阶段的互补性:
| 配置 | Sunny→Rainy ΔPQ | Day→Night ΔPQ | 第三个域偏移 ΔPQ |
|---|---|---|---|
| 仅置信度过滤(无精炼) | −0.3 | −2.1 | -- |
| 完整 DualRefine | +1.9 | +1.3 | +2.6 |
单纯的置信度过滤甚至会在某些域偏移下导致性能下降;Grow 与 Reassignment 分别使用均有收益,两者结合在所有域偏移下取得最高增益,证明 3D 几何与 2D 视觉先验高度互补。
参数敏感性
伪标签起始过滤阈值 (\tau_{th}) 和重分类阈值 (t_{cls}) 在较宽范围内均能保持稳定的 PQ,方法对这些关键超参数具有较强的鲁棒性。
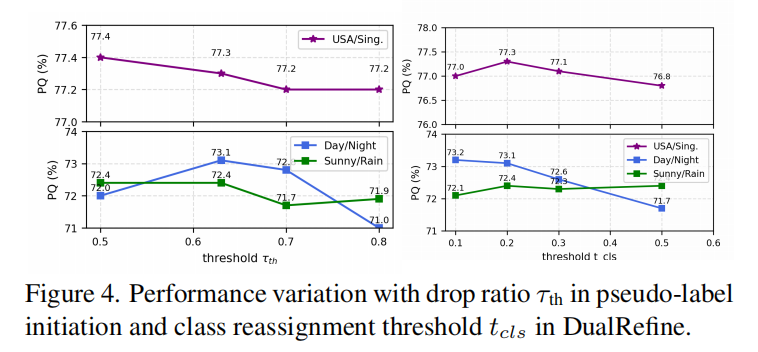
图片来源于原论文
五、总结与思考
PanDA 用 AMD 在源域模拟退化 和 DualRefine 在目标域精炼伪标签两大创新,首次将多模态3D全景分割推入无监督域适应轨道。其核心贡献可浓缩为两点:结构化的"边界+实例"丢弃比随机遮罩更能锻造跨模态恢复能力;3D 几何超点修 stuff、2D 视觉大模型修 thing,两种域不变先验缺一不可。
几点值得进一步思考:
-
极端联合退化:目前 AMD 每次只退化单一模态,但暴雨+黑夜等场景可能双模态同时劣化,未来需扩展至双边变异。
-
DualRefine 的冲突处理:Grow 阶段 stuff 与 thing 冲突时无条件偏向 stuff,是否会吞没紧贴建筑的车辆?这一先验在不同场景下的普适性有待验证。
-
推理效率:DualRefine 涉及 RANSAC 聚类和 VFM 推理,论文未给出推理延迟数据,自动驾驶实时系统部署需要更轻量的工程化设计。
-
所提策略的迁移性:"结构化丢弃 + 几何/视觉双专家精炼"的模式,对其他多模态感知任务的 UDA 也具有借鉴意义。
-
