微服务全面解析:架构、组件与底层原理
- [1. 微服务核心思想](#1. 微服务核心思想)
-
- [1.1 单一职责:每个服务只做一件事](#1.1 单一职责:每个服务只做一件事)
- [1.2 独立自治:服务自我管理](#1.2 独立自治:服务自我管理)
-
- [1.2.1 数据自治](#1.2.1 数据自治)
- [1.2.2 服务间通信](#1.2.2 服务间通信)
- [1.2.3 独立部署与升级](#1.2.3 独立部署与升级)
- [1.3 分布式系统特性及挑战](#1.3 分布式系统特性及挑战)
- [1.4 核心原理总结(便于记忆)](#1.4 核心原理总结(便于记忆))
- [2. Spring Cloud 微服务组件与原理](#2. Spring Cloud 微服务组件与原理)
-
- [2.1 服务注册与发现(Service Registry & Discovery)](#2.1 服务注册与发现(Service Registry & Discovery))
-
- [Eureka vs Nacos 心跳机制](#Eureka vs Nacos 心跳机制)
- [2.2 配置中心(Configuration)](#2.2 配置中心(Configuration))
- [2.3 服务间通信(Service-to-Service Communication)](#2.3 服务间通信(Service-to-Service Communication))
-
- [2.3.1 同步调用](#2.3.1 同步调用)
- [2.3.2 异步调用](#2.3.2 异步调用)
- [2.4 负载均衡(Load Balancing)](#2.4 负载均衡(Load Balancing))
- [2.5 熔断与容错(Circuit Breaker & Fault Tolerance)](#2.5 熔断与容错(Circuit Breaker & Fault Tolerance))
- [2.6 可观测性组件(Observability)](#2.6 可观测性组件(Observability))
- [2.7 全部串联记忆法](#2.7 全部串联记忆法)
- [3. Dubbo 微服务框架](#3. Dubbo 微服务框架)
-
- [3.1 Dubbo 核心组件与原理](#3.1 Dubbo 核心组件与原理)
- [3.2 Dubbo 通信与序列化原理](#3.2 Dubbo 通信与序列化原理)
- [3.3 Dubbo 与 Spring Cloud 对比](#3.3 Dubbo 与 Spring Cloud 对比)
- [3.4 Dubbo 核心原理串联记忆](#3.4 Dubbo 核心原理串联记忆)
- [4. 数据管理与一致性](#4. 数据管理与一致性)
-
- [4.1 数据库自治(Database Autonomy)](#4.1 数据库自治(Database Autonomy))
- [4.2 分布式事务(Distributed Transaction)](#4.2 分布式事务(Distributed Transaction))
-
- [4.2.1 Saga 模式(事件驱动事务)](#4.2.1 Saga 模式(事件驱动事务))
- [4.2.2 TCC 模式(Try-Confirm-Cancel)](#4.2.2 TCC 模式(Try-Confirm-Cancel))
- [4.3 缓存管理与一致性](#4.3 缓存管理与一致性)
-
- [4.3.1 缓存技术](#4.3.1 缓存技术)
- [4.3.2 缓存一致性策略](#4.3.2 缓存一致性策略)
- [4.4 全部串联记忆法](#4.4 全部串联记忆法)
- [5. 微服务架构整体图](#5. 微服务架构整体图)
- [6. 总结与核心原理回顾](#6. 总结与核心原理回顾)
-
- [6.1 服务自治(Service Autonomy)](#6.1 服务自治(Service Autonomy))
- [6.2 服务发现(Service Discovery)](#6.2 服务发现(Service Discovery))
- [6.3 服务通信(Service Communication)](#6.3 服务通信(Service Communication))
- [6.4 负载均衡(Load Balancing)](#6.4 负载均衡(Load Balancing))
- [6.5 容错与熔断(Fault Tolerance & Circuit Breaker)](#6.5 容错与熔断(Fault Tolerance & Circuit Breaker))
- [6.6 可观测性(Observability)](#6.6 可观测性(Observability))
- [6.7 配置管理(Configuration Management)](#6.7 配置管理(Configuration Management))
- [6.8 Dubbo 与 Spring Cloud 差异](#6.8 Dubbo 与 Spring Cloud 差异)
- [6.9 数据一致性(Data Consistency)](#6.9 数据一致性(Data Consistency))
- [6.10 运维与部署(Operations & Deployment)](#6.10 运维与部署(Operations & Deployment))
- [6.11 全链路串联记忆法](#6.11 全链路串联记忆法)
微服务是一种将单体应用拆分成多个独立服务的架构模式,每个服务聚焦单一业务功能,自主开发、独立部署和独立扩展。与传统单体应用相比,微服务具有高可维护性、高可扩展性和灵活的技术选型能力。
1. 微服务核心思想
微服务的核心理念可以概括为 "单一职责 + 独立自治"。这两个原则看似简单,但实际上包含了分布式系统设计中的很多关键知识点。理解这些底层原理,有助于掌握整个微服务生态和运行机制。
1.1 单一职责:每个服务只做一件事
-
概念:一个微服务应只负责单一业务功能,职责边界清晰。例如:
- 用户管理服务(User Service)只处理用户注册、登录、信息更新。
- 订单服务(Order Service)只处理订单创建、支付、查询。
- 支付服务(Payment Service)只负责交易处理和对账。
-
底层原理:
- 单一职责减少服务间耦合,使得代码结构简单、模块独立。
- 当业务发生变化时,只需修改相关服务,不会影响整个系统。
- 在部署时可以单独扩展高负载服务,例如订单服务高峰期,可以单独水平扩展实例,而不影响用户服务。
-
实例记忆法:
- 想象一个餐厅,每个厨师只负责一道菜。你不会让一个厨师同时负责前菜、主菜和甜点,否则容易出错、效率低。
- 用户服务 = 前菜厨师,订单服务 = 主菜厨师,支付服务 = 甜点厨师。每个厨师独立完成任务,同时可以协作上菜。
1.2 独立自治:服务自我管理
独立自治是微服务最核心的特性,它包含三个关键点:
1.2.1 数据自治
-
概念:每个微服务拥有自己的数据库和数据模型,不共享主数据库。
-
底层原理:
- 避免单体数据库的性能瓶颈和事务耦合。
- 服务更新不会影响其他服务的数据结构。
- 遇到跨服务数据操作时,需要分布式事务或最终一致性策略(如 Saga/TCC)。
-
示例:
- 用户服务使用 MySQL 存储用户信息
- 订单服务使用 PostgreSQL 存储订单信息
- 支付服务使用 Redis 缓存支付状态
- 当用户修改手机号时,只影响用户服务,不会直接影响订单或支付服务。
1.2.2 服务间通信
-
概念:服务通过网络调用协作,而不是直接调用代码或共享数据库。
-
底层原理:
- 使用 HTTP/REST、gRPC 或消息队列完成同步或异步调用。
- 引入调用链追踪(TraceID),确保请求在多个服务间可追踪。
- 异步消息可以降低耦合,提高吞吐量。
-
示例:
-
用户下单:
- 用户服务验证身份
- 订单服务创建订单
- 支付服务完成扣款
这一流程中,服务之间通过 REST API 或消息队列通信,而不是直接访问数据库。
-
1.2.3 独立部署与升级
-
概念:每个微服务可以独立部署和升级,无需整个系统停机。
-
底层原理:
- 利用容器化(Docker)和编排工具(Kubernetes)实现服务实例的弹性扩展。
- 版本控制和灰度发布允许不同实例运行不同版本,保证平滑升级。
-
示例:
-
支付服务优化支付逻辑,发布新版本时:
- 新版本实例先小范围上线(灰度)
- 确认无问题后再扩大到所有实例
- 用户服务和订单服务继续使用旧接口或兼容接口
这样实现零停机更新,提高系统可靠性。
-
1.3 分布式系统特性及挑战
微服务架构本质上是一个 分布式系统,因此必须考虑以下关键问题:
| 特性 | 说明 | 对策 |
|---|---|---|
| 通信可靠性 | 网络调用可能失败 | 重试、熔断、限流、消息队列异步 |
| 数据一致性 | 分布式数据难保证事务 | Saga、TCC、最终一致性 |
| 服务治理 | 服务实例动态变化 | 注册中心(Eureka/Nacos)、负载均衡 |
| 可观测性 | 调试分布式流程困难 | 日志集中化、指标监控、链路追踪 |
-
实例串联记忆:
-
想象微服务系统是一支足球队:
- 每个球员 = 一个服务(单一职责)
- 球员独立训练、独立技能(独立自治)
- 球员之间通过传球合作(服务通信)
- 教练观察全场(可观测性)
- 战术调整随时进行(独立部署、弹性扩展)
-
1.4 核心原理总结(便于记忆)
- 单一职责 = "一人一菜",职责清晰,减少耦合
- 数据自治 = "自带食材",独立数据库,避免共享风险
- 服务通信 = "传球配合",REST/gRPC/消息队列
- 独立部署 = "替换球员不影响全队",灰度发布、容器化
- 分布式特性 = "复杂比赛环境",需考虑可靠性、一致性、可观测性、治理
通过上面的比喻和实例,可以把微服务的核心思想 串联起来记忆:
每个服务像足球队的球员,每个球员负责单一技能,自带装备,通过传球协作,并且可以随时换人而不影响整体比赛,教练可以实时观测整个比赛过程。
2. Spring Cloud 微服务组件与原理
Spring Cloud 是基于 Spring Boot 的微服务生态系统,它提供了服务注册、配置管理、服务间通信、负载均衡、容错、监控等全套解决方案。理解 Spring Cloud,核心是把握 每个组件的职责、底层机制以及它们之间的协作。
2.1 服务注册与发现(Service Registry & Discovery)
-
Eureka:服务注册中心
-
功能:
-
服务启动时注册自身信息(IP、端口、服务名、健康状态)。
-
客户端通过轮询或订阅获取可用服务列表。
-
-
底层原理:
-
心跳机制:客户端定期向 Eureka 发送心跳,表示存活。
-
服务下线感知:心跳超时,服务被标记为不可用。
-
客户端缓存:客户端缓存服务列表,减少对注册中心的压力。
-
-
实例类比:
- 想象城市的出租车叫车系统:Eureka 相当于叫车中心,出租车注册位置和状态,用户(客户端)可以查询空闲车辆列表。
-
扩展点:
-
支持负载均衡和权重调度
-
支持高可用集群模式
-
-
-
Nacos/Consul:
-
增强版注册中心,除了服务注册,还提供:
-
配置管理
-
健康检查
-
权重调度
-
-
内部机制与 Eureka 类似,但更适合大规模微服务部署。
-
好,我给你再压一轮 ,只保留绝对不误导、可背、可面试 的版本。
下面这版已经是信息密度极限了。
Eureka vs Nacos 心跳机制
Eureka 依赖客户端心跳并在异常时暂停剔除,Nacos 健康判断更严格,默认及时剔除异常实例。
Nacos多了主动的服务端检查 以及 剔除策略不同
关键差异
| 维度 | Eureka | Nacos |
|---|---|---|
| 存活判断 | 客户端心跳 | 心跳 + 服务端检查 |
| 剔除策略 | 条件性剔除 | 默认剔除 |
| 自我保护 | 有 | 无 |
| 假活风险 | 有 | 低 |
| 取向 | AP | 偏 CP |
本质差别
Eureka 出问题时"先不删",Nacos 出问题时"先别用"。
Eureka 通过自我保护优先保证可用性,Nacos 通过更严格的健康检查优先保证服务发现的准确性。
2.2 配置中心(Configuration)
-
Spring Cloud Config / Nacos Config
-
功能:
-
集中管理服务配置
-
支持动态刷新(热更新)配置,服务无需重启
-
-
底层原理:
-
服务启动时从配置中心拉取配置。
-
配置变更通过 轮询 或 消息总线(Bus) 通知客户端刷新。
-
-
实例类比:
- 想象公司内部共享文档:所有团队成员都从文档中心获取最新政策和参数,文档更新后,团队可以实时同步。
-
扩展点:
-
可以管理多环境(开发/测试/生产)配置
-
支持加密敏感信息(如密码、秘钥)
-
-
2.3 服务间通信(Service-to-Service Communication)
2.3.1 同步调用
-
REST + Feign
-
Feign 是声明式 HTTP 客户端,内部封装了 Ribbon 负载均衡。
-
底层机制:
-
Feign 在调用接口时,会:
-
查询注册中心获取服务实例列表
-
根据负载均衡策略选择实例
-
使用 HttpClient 或 OkHttp 发起请求
-
返回结果给调用方
-
-
-
容错策略:
- 可以结合 Hystrix/Resilience4j 实现熔断、降级、重试
-
实例:
-
用户服务调用订单服务获取用户订单列表:
-
Feign 自动发现可用订单服务实例
-
发送 HTTP 请求
-
若订单服务响应慢,Hystrix 会触发降级逻辑返回默认数据
-
-
-
-
gRPC
-
高性能二进制 RPC,基于 HTTP/2 和 Protobuf
-
优势:
-
支持流式通信、低延迟
-
适合服务内部高频调用
-
-
实例:
- 游戏系统中,用户服务与战斗服务之间实时交互状态时使用 gRPC,减少网络开销
-
2.3.2 异步调用
-
消息队列(Kafka、RabbitMQ)
-
解耦服务,提高系统吞吐量
-
可靠性机制:
-
消息持久化
-
消息确认机制(ACK)
-
重试与死信队列
-
-
实例:
- 订单服务创建订单后发送"订单创建事件",支付服务异步消费进行支付处理
-
-
事件总线
-
发布-订阅模式,实现事件驱动架构
-
实例:
-
用户注册事件触发:
-
邮件服务发送欢迎邮件
-
积分服务发放注册奖励
-
-
-
2.4 负载均衡(Load Balancing)
-
客户端负载均衡(Ribbon/LoadBalancerClient)
-
客户端维护服务实例列表,按策略选择目标实例
-
优点:减轻服务端压力
-
策略:
-
轮询:均匀分配请求
-
随机:避免热点
-
权重:根据实例性能分配
-
最小连接数:动态选择空闲实例
-
-
实例:
-
用户服务调用订单服务 3 个实例:
-
轮询策略:请求均匀分配到实例 1、2、3
-
权重策略:高性能实例获得更多请求
-
-
-
-
服务端负载均衡(NGINX、Spring Cloud Gateway)
-
请求统一入口路由
-
可结合熔断、限流
-
实例类比:
- 入口大门(Gateway)负责分配进入不同部门的请求,保证每个部门负载均衡
-
2.5 熔断与容错(Circuit Breaker & Fault Tolerance)
-
Hystrix / Resilience4j
-
功能:
-
防止服务雪崩
-
提供降级、熔断、限流功能
-
-
底层机制:
-
每个请求独立线程或信号量隔离
-
动态监控失败率,触发状态机:
-
闭合(Close):正常请求
-
打开(Open):触发熔断,直接返回降级结果
-
半开(Half-Open):尝试恢复请求
-
-
-
实例:
- 支付服务宕机时,订单服务通过 Hystrix 返回"支付系统繁忙,请稍后再试"而不是阻塞整个请求链
-
2.6 可观测性组件(Observability)
-
日志收集:ELK(Elasticsearch + Logstash + Kibana)、Graylog
- 集中管理日志,支持搜索和告警
-
指标监控:Prometheus + Grafana
- 实时监控请求量、响应时间、错误率
-
分布式追踪:Zipkin / Sleuth / Jaeger
-
原理:
-
请求带 TraceID
-
每个服务记录调用耗时、状态
-
可视化展示调用链
-
-
实例:
- 用户下单请求跨用户服务、订单服务、支付服务,通过 TraceID 可以清楚看到哪个服务耗时最长、哪里出现异常
-
-
类比记忆:
-
日志 = 监控摄像头
-
指标 = 健康体检数据
-
分布式追踪 = GPS 定位,追踪请求路径
-
2.7 全部串联记忆法
可以用一个 餐厅服务类比来串联整个 Spring Cloud 组件:
-
服务注册中心(Eureka/Nacos)= 点餐系统,记录每个厨师(服务)的状态和可用性
-
配置中心(Config/Nacos)= 菜谱文档,随时更新参数
-
同步调用(Feign/REST) = 服务员直接去厨房下单
-
异步调用(MQ) = 下单放入队列,厨师按顺序处理
-
负载均衡(Ribbon/Gateway) = 前台引导客人去不同厨师窗口
-
熔断降级(Hystrix) = 某个厨师忙不过来时,提供备用方案(半成品)
-
可观测性(日志/监控/追踪) = 后厨监控摄像头 + 厨房报表 + 全程 GPS 定位
这样可以把 Spring Cloud 的各个组件 从注册、配置、通信、负载、容错到监控 一条线串起来,形成完整认知链。
3. Dubbo 微服务框架
Dubbo 是阿里巴巴开源的高性能 Java RPC 框架,擅长 服务提供者与消费者之间的远程过程调用(RPC) 。与 Spring Cloud 的 HTTP/REST 风格不同,Dubbo 更适合 高频率、低延迟、内部服务调用场景。
3.1 Dubbo 核心组件与原理
Dubbo 的架构由以下核心组件组成,每个组件在分布式系统中扮演不同角色:
-
Provider(服务提供者)
-
功能:
- 发布服务接口,实现具体业务逻辑
- 注册到注册中心,让消费者可发现
-
底层原理:
- 启动时生成本地代理对象(Stub)
- 注册中心保存服务元信息(接口名、IP、端口、协议、权重等)
-
实例:
- 订单服务作为 Provider 提供
createOrder()接口,供用户服务调用
- 订单服务作为 Provider 提供
-
-
Consumer(服务消费者)
-
功能:
-
通过注册中心发现 Provider
-
调用远程服务接口
-
-
底层原理:
-
消费者调用本地代理对象,代理负责封装调用请求(接口名、参数、序列化方式)
-
发送到 Provider,并等待结果返回
-
-
实例:
- 用户服务调用订单服务
createOrder()时,实际上调用的是本地 Stub,网络请求由框架透明处理
- 用户服务调用订单服务
-
-
Registry(注册中心)
-
功能:
-
服务注册和发现
-
支持 Zookeeper/Nacos 等
-
-
底层原理:
-
Provider 向注册中心注册服务,Consumer 订阅服务变化
-
注册中心维护服务列表、权重和状态,实现动态发现
-
-
实例:
- 注册中心相当于"服务黄页",用户服务查找订单服务接口,获取可用实例列表
-
-
Monitor(监控中心)
-
功能:
-
收集调用统计信息:耗时、QPS、异常率
-
支持运维优化和问题定位
-
-
实例:
- 监控发现某个 Provider 响应慢,可以调整权重或扩容实例
-
-
Container
-
功能:
-
启动服务的容器,支持多种部署方式
-
集成 Spring 或其他框架环境
-
-
实例:
- 订单服务在 Docker 容器中运行,同时注册到注册中心
-
3.2 Dubbo 通信与序列化原理
Dubbo 支持高性能通信协议和多种序列化方式:
-
通信协议
-
Dubbo Protocol:默认高性能二进制协议,适合内部高频 RPC
-
HTTP / gRPC:兼容外部访问或跨语言调用
-
-
序列化方式
-
Hessian:轻量级二进制序列化,跨语言
-
JSON:可读性高,适合调试
-
Protobuf:高性能二进制序列化,适合大规模数据交换
-
-
远程调用原理
-
Consumer 调用本地代理对象(Stub)
-
Stub 封装接口名、参数、序列化方式,生成网络请求
-
网络层通过 Dubbo Protocol 发送给 Provider
-
Provider 反序列化请求,调用实现类
-
返回结果,Consumer 反序列化并返回给业务方
-
-
实例类比:
-
想象 Consumer 是邮寄包裹的人,Stub 是打包员,Provider 是收件人,Registry 是邮局地址簿:
-
Stub 打包包裹(封装调用信息)
-
注册中心提供地址(Provider 地址)
-
包裹运输到 Provider(网络传输)
-
Provider 解包并处理(业务逻辑)
-
回传结果(返回值)
-
-
3.3 Dubbo 与 Spring Cloud 对比
| 特性 | Spring Cloud | Dubbo |
|---|---|---|
| 通信方式 | REST/gRPC | RPC(二进制协议) |
| 序列化 | JSON/Protobuf | Hessian/Protobuf |
| 负载均衡 | 客户端/服务端 | 内置策略:随机、轮询、最少活跃调用、权重 |
| 容错策略 | Hystrix/Resilience4j | 内置重试、容错、Failover |
| 配置方式 | 配置中心(Nacos/Config) | XML/注解 + 注册中心 |
| 架构风格 | HTTP 微服务 | RPC 微服务 |
| 适用场景 | 业务系统、异步消息 | 高频调用、低延迟内部服务 |
-
核心差异
-
Dubbo 偏向高性能内部 RPC,适合低延迟、高频调用场景
-
Spring Cloud 偏向 HTTP 风格,生态丰富,适合业务系统整合消息队列、监控和分布式事务
-
Dubbo 内置负载均衡和容错策略,而 Spring Cloud 需要 Ribbon + Hystrix/Resilience4j 组合
-
3.4 Dubbo 核心原理串联记忆
可以用"邮寄包裹"类比来记忆 Dubbo 调用流程和组件关系:
-
Provider = 收件人,负责接收包裹(请求)并处理(业务逻辑)
-
Consumer = 寄件人,调用本地 Stub(打包员)
-
Stub = 打包员,将请求封装成包裹
-
Registry = 地址簿,告诉寄件人如何找到收件人
-
Monitor = 邮局统计信息,记录送达时间、异常情况
-
Container = 邮局分发中心,保证包裹正常运行并管理服务实例
通过这个类比,可以把 Dubbo 的注册、调用、序列化、负载均衡、监控整个流程串成一条清晰的链路,方便理解和记忆。
4. 数据管理与一致性
在微服务架构中,每个服务独立管理自己的数据,保证自治性和解耦性,但同时带来 跨服务数据一致性和缓存一致性 的挑战。因此需要明确数据管理策略和分布式事务机制。
4.1 数据库自治(Database Autonomy)
-
概念:
-
每个微服务拥有独立数据库,不共享主数据库。
-
服务之间通过接口或消息传递数据,而非直接操作别的服务数据库。
-
-
底层原理:
-
数据自治保证服务 低耦合,避免修改一个服务影响其他服务。
-
服务可以选择最适合自己的数据库类型:
-
关系型:MySQL、PostgreSQL
-
非关系型:MongoDB、Cassandra
-
时序数据库:InfluxDB、ClickHouse(适合日志/监控)
-
-
避免单点瓶颈,提高系统可扩展性。
-
-
实例:
-
用户服务(User Service)管理用户信息的 MySQL
-
订单服务(Order Service)管理订单信息的 PostgreSQL
-
支付服务(Payment Service)使用 Redis 缓存支付状态
-
当用户修改手机号时,只影响用户服务数据库,不会直接影响订单或支付数据
-
-
记忆类比:
- 每个微服务 = 自己的仓库(数据库),别人想用你的货物必须走通道(接口),而不能直接闯入仓库。
4.2 分布式事务(Distributed Transaction)
跨服务操作可能涉及多个数据库或服务实例,传统单体应用的 ACID 事务无法直接支持,需要采用 分布式事务 或 最终一致性策略。
4.2.1 Saga 模式(事件驱动事务)
-
原理:
- 将一个全局事务拆分为多个本地事务,每个服务执行自己的事务后,发布事件触发下一个服务。
- 如果某个服务失败,会通过补偿事务回滚前面的操作,实现 最终一致性。
-
流程示例:
- 用户下单(订单服务创建订单)
- 扣减库存(库存服务执行本地事务)
- 支付扣款(支付服务执行本地事务)
- 若支付失败,发布补偿事件:退库存、取消订单
-
底层机制:
- 事件总线(Kafka/RabbitMQ)保证可靠传递
- 每个本地事务独立提交
- 补偿机制保证异常可恢复
-
类比:
-
想象制作披萨:
- 制作面团 → 放料 → 烤制 → 打包
- 若烤制失败 → 补救措施:重新放料或丢弃前一步的材料
- 保证最终披萨流程一致完成
-
4.2.2 TCC 模式(Try-Confirm-Cancel)
-
原理:
- Try:尝试执行操作,预占资源(如锁库存)
- Confirm:确认提交,正式生效
- Cancel:取消操作,释放资源
-
流程示例:
- 订单服务创建订单(Try)
- 库存服务锁定库存(Try)
- 支付成功 → Confirm 所有服务提交操作
- 支付失败 → Cancel 回滚资源
-
特点:
- 事务明确可控,适合对资源要求严格的场景
- 实现复杂,需要额外管理 Try 状态和资源锁
-
类比:
-
订餐抢座位:
- Try:临时锁定座位
- Confirm:确认预订,正式占用
- Cancel:放弃预订,释放座位
-
4.3 缓存管理与一致性
缓存是微服务性能优化的重要手段,但需要处理 缓存和数据库的一致性 问题。
4.3.1 缓存技术
-
Redis / Memcached
- 高性能内存数据库
- 提供快速读写,减轻数据库压力
4.3.2 缓存一致性策略
-
Cache Aside(旁路缓存)
-
应用先读缓存,缓存未命中再读数据库,写数据库后清理缓存
-
优点:实现简单
-
缺点:可能出现短暂脏数据
-
实例:
-
查询用户信息:
-
缓存未命中 → 查询数据库
-
写回缓存,下次命中直接返回缓存
-
-
-
-
Write-Through(写入直通缓存)
-
写操作同时更新数据库和缓存
-
优点:读缓存命中率高
-
缺点:写操作延迟增加
-
实例:
- 修改用户昵称 → 同时更新数据库和缓存,保证一致
-
-
Write-Behind(延迟写)
-
写操作先更新缓存,异步批量写入数据库
-
优点:提高写性能
-
缺点:缓存宕机可能丢数据,需要额外持久化机制
-
4.4 全部串联记忆法
可以用"餐厅管理系统"类比微服务数据管理:
-
数据库自治 = 每个餐厅分店管理自己的仓库
-
Saga 模式 = 订餐流程拆分:下单 → 配料 → 出餐,每步独立,但有补救机制
-
TCC 模式 = 订座流程:锁定座位 → 确认 → 放弃,严格控制资源
-
缓存策略:
- Cache Aside = 临时记账本,查不到再去总账
- Write-Through = 同步更新账本和总账
- Write-Behind = 先记账本,稍后同步到总账
通过餐厅类比,把数据库自治、事务机制和缓存策略串成一条完整认知链,方便理解和记忆。
这版内容涵盖:
-
数据库自治和服务独立性
-
两种核心分布式事务方案(Saga/TCC)
-
缓存策略和一致性机制
-
实例讲解 + 类比记忆
-
知识点串联成链
5. 微服务架构整体图
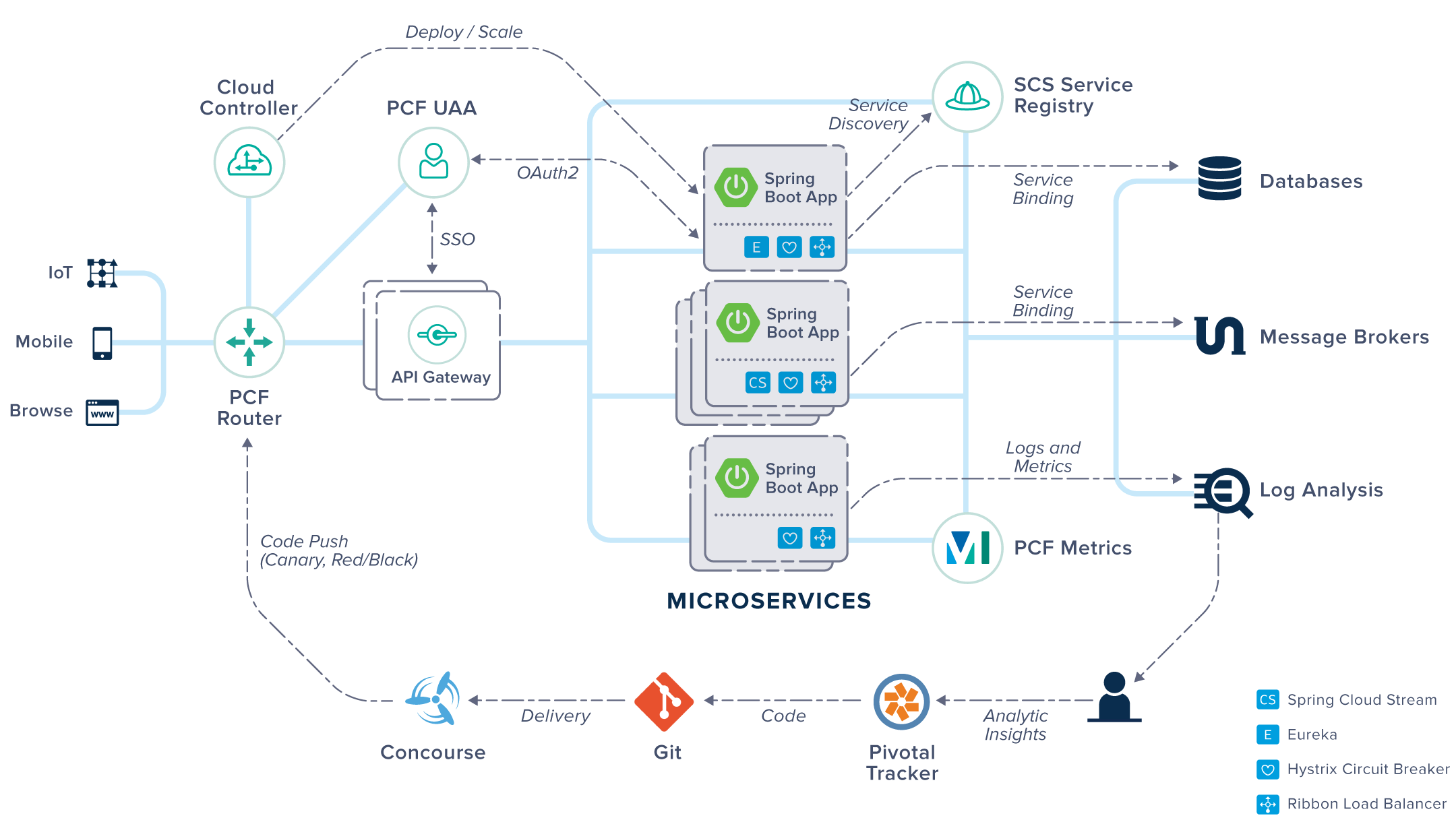
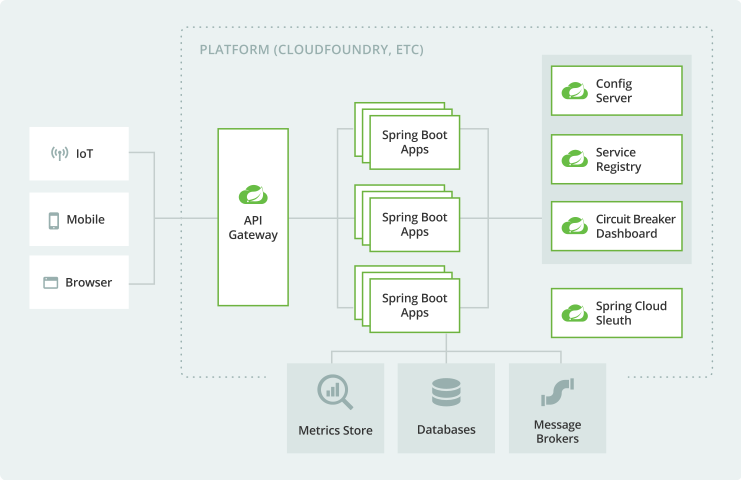
6. 总结与核心原理回顾
微服务架构本质是 一套高度解耦、自治的分布式系统设计模式。掌握它,需要从服务治理、通信、负载、容错、数据管理到运维部署,形成完整认知链。下面按逻辑顺序梳理核心原理和底层机制。
6.1 服务自治(Service Autonomy)
-
核心概念:
- 单一职责:每个服务只做一件事,业务边界清晰
- 独立数据:拥有自己的数据库和缓存
- 独立部署:服务可单独升级、扩展、回滚
-
底层原理:
- 服务自治降低耦合,允许团队独立开发和部署
- 避免单体数据库瓶颈,提高系统可靠性
-
实例:
- 用户服务、订单服务、支付服务各自独立数据库
- 订单高峰期,订单服务水平扩展,不影响用户服务
-
类比记忆:
- 每个服务 = 独立餐厅,独立管理食材、厨师和流程,其他餐厅不受影响
6.2 服务发现(Service Discovery)
-
核心组件:Eureka、Nacos、Zookeeper
-
底层原理:
- Provider 向注册中心注册自身信息(IP、端口、健康状态)
- Consumer 订阅服务变化,维护本地缓存
- 心跳机制保证服务状态及时更新
-
实例:
- 用户服务调用订单服务,通过注册中心获取可用实例列表
-
类比:
- 注册中心 = 城市黄页,告诉你每个餐厅的地址和状态
6.3 服务通信(Service Communication)
-
同步调用:
- REST(HTTP/JSON) + Feign + gRPC(HTTP/2 + Protobuf)
- 底层:客户端代理封装请求 → 网络传输 → 服务端解析 → 返回结果
- 实例:用户服务调用订单服务查询订单列表
-
异步调用:
- MQ(Kafka、RabbitMQ)、EventBus
- 原理:事件驱动,解耦服务,提高吞吐量
- 实例:订单创建事件触发支付服务扣款、库存扣减
-
类比:
- 同步 = 电话即时通话
- 异步 = 写信寄包裹,收件人稍后处理
6.4 负载均衡(Load Balancing)
-
客户端负载均衡:Ribbon/LoadBalancerClient
- 客户端维护服务列表,按策略(轮询、随机、权重、最小连接数)选择实例
-
服务端负载均衡:NGINX、Spring Cloud Gateway
- 统一入口路由请求,结合限流、熔断策略
-
实例:
-
用户服务调用 3 个订单服务实例:
- 轮询:请求均匀分配
- 权重:高性能实例分配更多请求
-
-
类比:
- 前台接待员引导顾客到不同餐厅窗口,保证各窗口负载均衡
6.5 容错与熔断(Fault Tolerance & Circuit Breaker)
-
组件:Hystrix、Resilience4j
-
功能:
- 熔断:请求失败次数超过阈值,短路调用
- 降级:提供默认结果
- 限流:控制并发请求,防止雪崩
-
底层原理:
- 每个请求隔离线程或信号量
- 动态监控失败率,触发状态机(闭合/打开/半开)
-
实例:
- 支付服务宕机 → Hystrix 返回"支付繁忙"提示而不是阻塞整个流程
-
类比:
- 厨师忙不过来 → 提供半成品或快速替代方案
6.6 可观测性(Observability)
-
日志:ELK/Graylog
-
指标监控:Prometheus + Grafana
-
分布式追踪:Zipkin/Sleuth/Jaeger
-
底层原理:
- 请求带 TraceID → 各服务记录耗时、状态 → 可视化调用链
-
实例:
- 用户下单跨用户、订单、支付服务,通过 TraceID 可定位瓶颈
-
类比:
- 日志 = 摄像头,指标 = 健康体检,追踪 = GPS 定位
6.7 配置管理(Configuration Management)
-
组件:Spring Cloud Config、Nacos Config
-
原理:
- 集中存储配置
- 动态刷新,服务无需重启
-
实例:
- 修改支付超时时间,所有支付服务实例即时生效
-
类比:
- 企业共享文档中心,所有团队成员实时同步政策和参数
6.8 Dubbo 与 Spring Cloud 差异
| 特性 | Spring Cloud | Dubbo |
|---|---|---|
| 通信方式 | REST/gRPC | RPC(二进制协议) |
| 序列化 | JSON/Protobuf | Hessian/Protobuf |
| 架构风格 | HTTP 微服务 | RPC 微服务 |
| 负载均衡 | 客户端/服务端 | 内置策略:轮询/最少活跃/权重 |
| 适用场景 | 业务系统、消息 | 高频调用、低延迟系统 |
-
记忆类比:
- Dubbo = 内部快递,二进制高效,适合高频短途传送
- Spring Cloud = HTTP 邮件,生态丰富,适合混合业务场景
6.9 数据一致性(Data Consistency)
-
分布式事务:
- Saga:事件驱动,最终一致性
- TCC:Try-Confirm-Cancel,严格控制资源
-
缓存策略:
- Cache Aside、Write-Through、Write-Behind
-
类比:
- Saga = 制作披萨拆分步骤,每步独立,但有补救机制
- TCC = 订座流程,锁定 → 确认 → 取消
- 缓存 = 临时记账本与总账同步策略
6.10 运维与部署(Operations & Deployment)
-
容器化:Docker + Kubernetes
- 独立部署、水平扩展
-
CI/CD 自动化
- Jenkins/GitLab CI 等自动构建、测试、发布
-
底层原理:
- 每个服务作为容器镜像部署 → K8s 管理副本、滚动更新
-
实例:
- 支付服务升级新版本 → 灰度发布到部分 Pod → 确认无异常再全量切换
-
类比:
- 每个餐厅分店独立运营,升级新菜品可以先在小店试吃,再推广到所有分店
6.11 全链路串联记忆法
可以把整个微服务体系用 餐厅运营类比 一条线串联:
- 服务自治 = 每个分店独立管理厨师、食材和流程
- 服务发现 = 黄页查询分店地址
- 通信机制 = 同步电话下单 / 异步传单
- 负载均衡 = 前台分流顾客
- 容错熔断 = 厨师忙时提供半成品或备用方案
- 可观测性 = 摄像头 + 健康体检 + GPS
- 配置管理 = 总部共享菜单和政策
- Dubbo vs Spring Cloud = 内部快递 vs HTTP 邮件
- 数据一致性 = 披萨制作补救 / 订座锁定机制
- 运维部署 = 容器化分店 + 自动化升级
通过餐厅类比,把微服务的全部核心原理、组件、机制形成一条 可视化的知识链,理解和记忆一目了然。