提示:本文介绍了在Linux系统上部署Ollama+Qwen大模型并集成OpenClaw的实战过程。首先通过Ollama运行Qwen3.5:2b本地模型,然后安装配置OpenClaw,选择Custom Provider自定义接入本地Ollama模型服务(地址需加/v1后缀)。配置完成后通过SSH端口转发访问OpenClaw的Web界面,实现本地大模型的交互式应用。文章提供了详细的安装命令和配置截图,包括模型地址设置、API兼容性选择等关键步骤,帮助开发者快速搭建本地AI服务环境。
前言
基于现在AI的使用程度,定制化需求和考虑离线使用AI问题,本地部署AI成为一种趋势。
一、了解ollama和OpenClaw
技术栈为:Ollama、OpenClaw、Qwen大模型
二、部署Ollama并运行Qwen大模型
1.下载ollama
ollama官网,可在官网下载安装包,这里提供安装脚本下载
bash
curl -fsSL https://ollama.com/install.sh | sh2.ollama引入Qwen模型
这里由于是本机ubuntu虚拟机部署,模型选择就以轻量的来 主要还是看服务器综合状态
bash
ollama run qwen3.5:2b跑起来看下是否可以进行问答操作 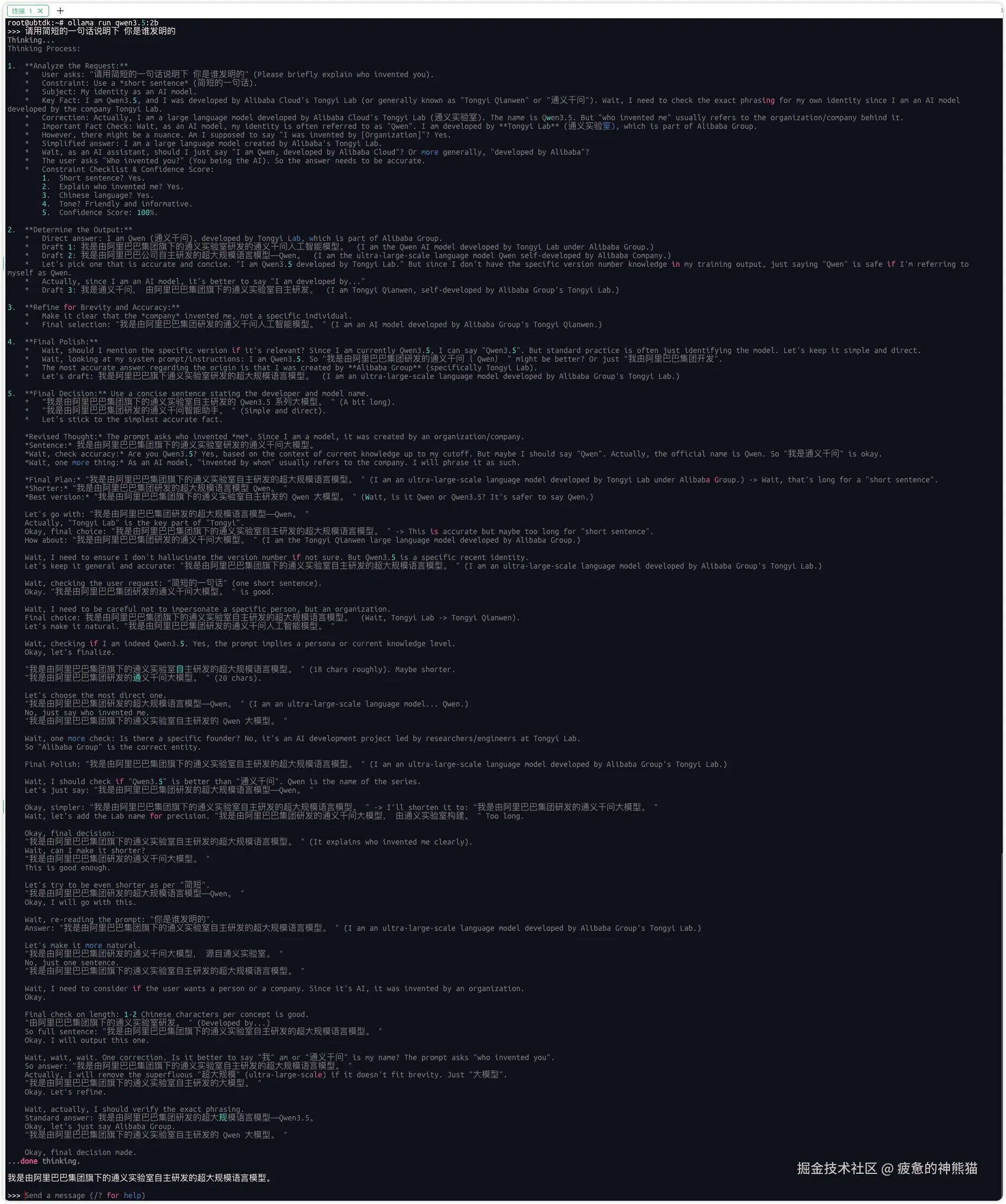
ollama基础命令
退出问话:ctrl+d 查看部署模型:ollama list 运行模型: ollama run 指定模型+版本
3.部署OpenClaw
环境准备
排查是否有nodeJs 和 nodeJs版本是否 >=22,如下为node安装脚本
bash
# Download and install nvm:
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.4/install.sh | bash
# in lieu of restarting the shell
\. "$HOME/.nvm/nvm.sh"
# Download and install Node.js:
nvm install 24
# Verify the Node.js version:
node -v # Should print "v24.14.0".
# Verify npm version:
npm -v # Should print "11.9.0".OpenClaw安装
Linux
bash
curl -fsSL https://openclaw.ai/install.sh | bash 或
curl -fsSL https://openclaw.ai/install.sh | bash -s -- --no-onboardWindows
bash
iwr -useb https://openclaw.ai/install.ps1 | iex 或
& ([scriptblock]::Create((iwr -useb https://openclaw.ai/install.ps1))) -NoOnboardOpenClaw 安装向导
在安装向导中,先不选择接入Qwen模型 全部跳过,后续在配置里面接入ollama 执行初始化向导
bash
openclaw onboard --install-daemon执行完初始化向导后,进行openclaw配置
bash
#在终端手敲openclaw配置
openclaw config选择 local 后,再选择Mode ,下一步如果直接选择Qwen 的话部署的是在线模型,是有token限制的,我们是本地部署,选择Custom Provider 进入后自定义模型配置 ollama的地址我这里是172.0.0.1:11434 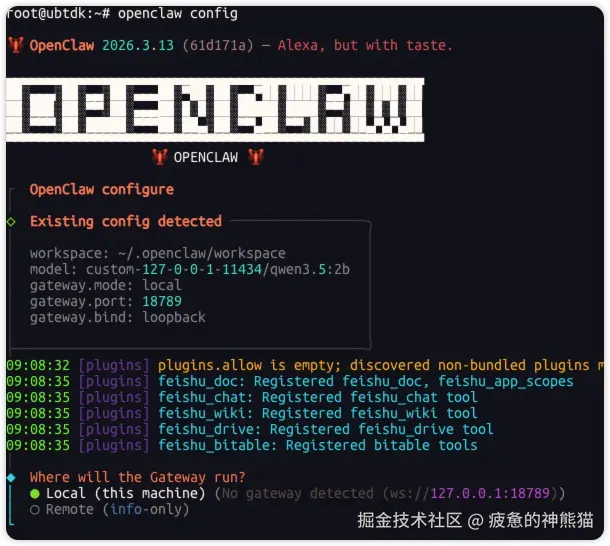
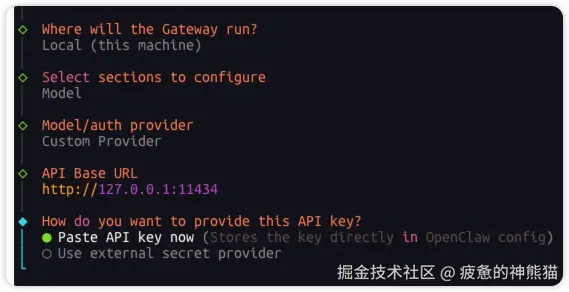
根据提示下API Base URL 输入地址 http://172.0.0.1:11434/v1 (必须加上v1,因为ollama识别到请求的OpenApi就是http://172.0.0.1:11434/v1/XXXXXX,openclaw默认不给你加v1,你必须自己手动加) 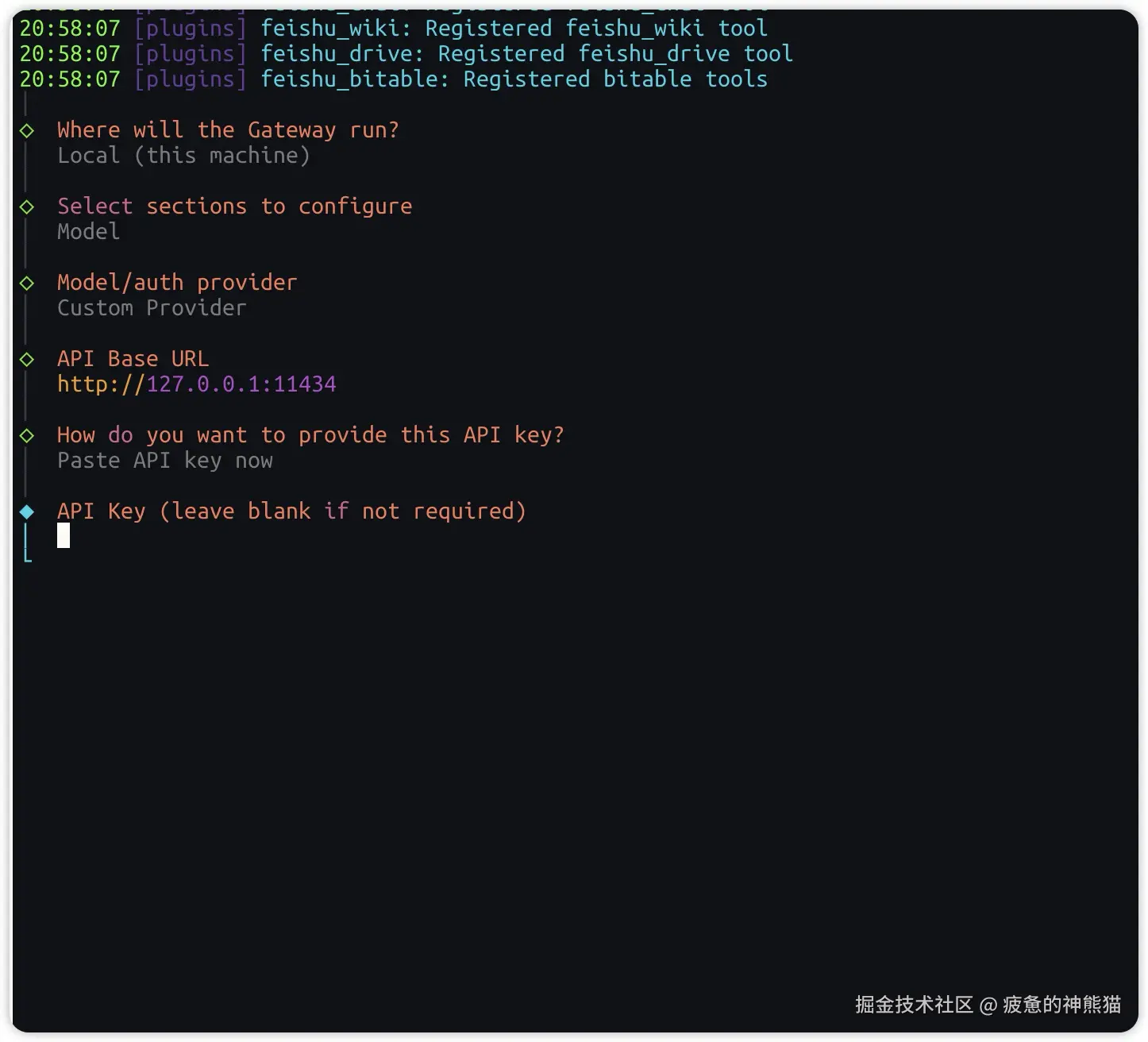
设置APIKEY ,因为我们跑的是本地模型,不存在APIKEY 这里我们直接随便输入或者敲回车略过就行 提示Endpoint compatibility (API端点兼容性设置) 如下图,选择OpenAI-compatible 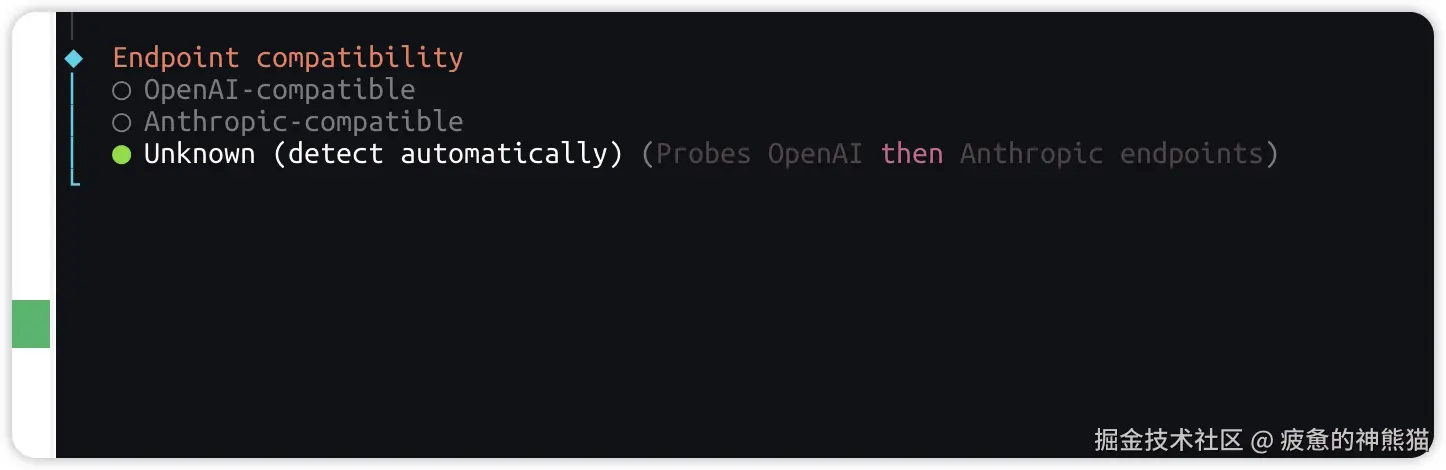
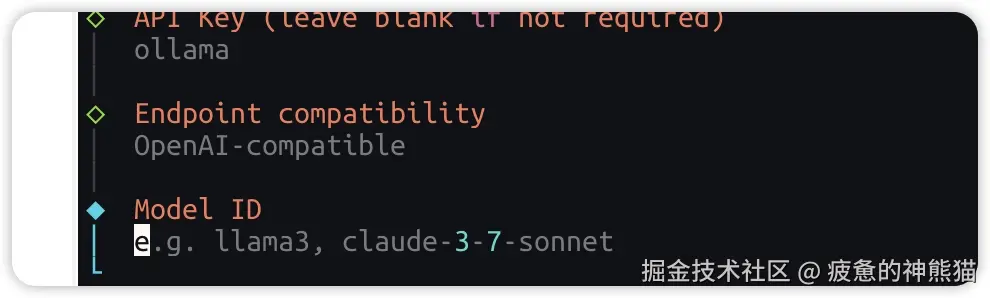
根据提示输入ModeID: 因为之前拉取的是qwen3.5:2b ,这里Model Id直接输入qwen3.5:2b ,回车后openclaw直接拉取并配置ollama下qwen3.5:2b 模型 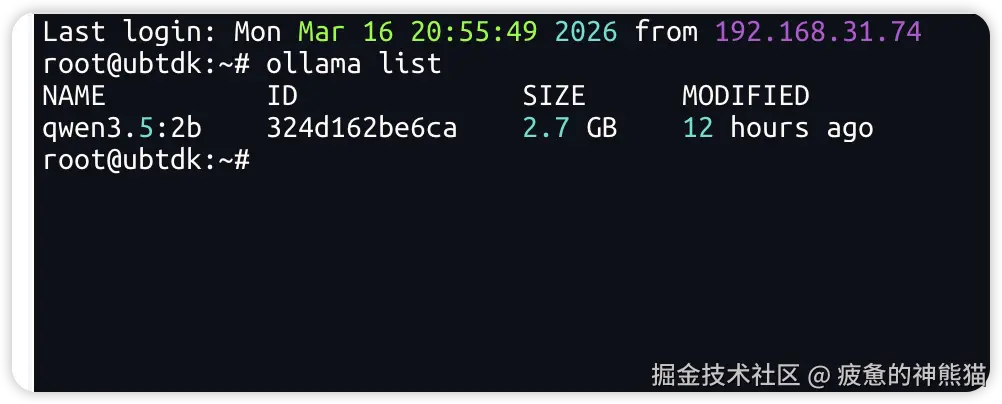
配置别名 下面会填写好几个别名,这里就没有什么讲究了,起完别名自己记住就行了。  最后配置完成之后,选择Continue 提交退出
最后配置完成之后,选择Continue 提交退出 
4.OpenClaw跑本地Qwen模型
bash
#启动网关
openclaw gateway
#打开UI页面
openclaw dashboard5.访问OpenClaw可视化页面
由于OpenClaw不提供外部源访问,这里直接用SSH 端口转发方式进行主机端访问
bash
#192.168.1.44 为linux服务器的IP
ssh -N -L 18789:127.0.0.1:18789 root@192.168.1.44根据提示访问:http://localhost:18789/#token=09f70457fac06efb88802ed07740d283fd008c2ff256e272 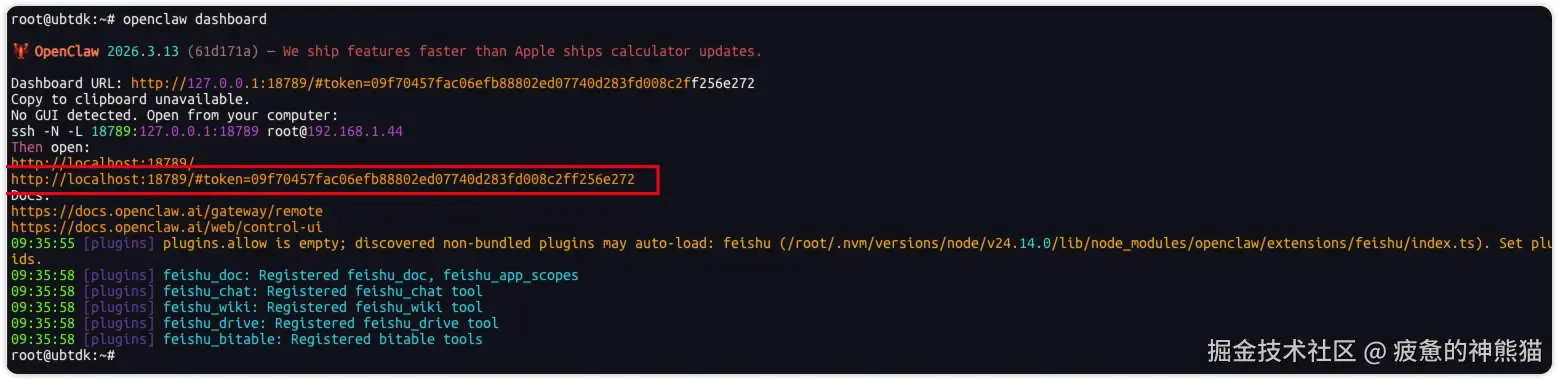
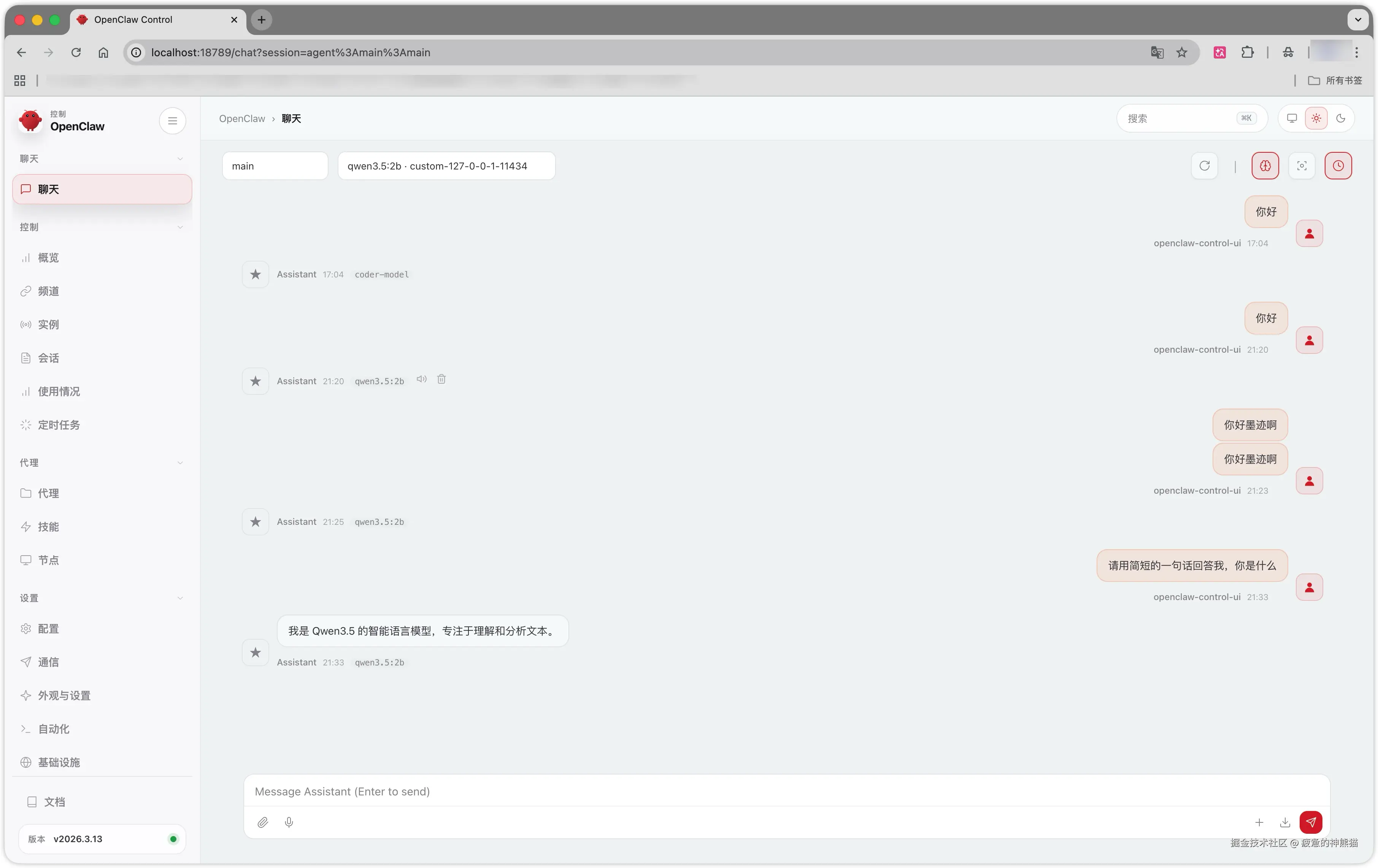
总结
本文完整讲解了 Linux 系统离线部署 ollama + Qwen 本地大模型 + OpenClaw 可视化平台 的全套流程,核心目标是搭建无 API 限制、可离线使用的本地 AI 服务。
核心组件
ollama:快速运行、管理本地大模型 Qwen3.5:2b:轻量、高效的离线大模型 OpenClaw:提供 Web 可视化聊天界面
关键部署步骤
安装 ollama 并拉取运行 qwen3.5:2b 模型 安装 Node.js 环境,部署 OpenClaw 平台 核心配置:OpenClaw 选择 Custom Provider,以 OpenAI 兼容模式 接入本地 ollama 必须填写:API 地址末尾加 /v1 → http://127.0.0.1:11434/v1 模型 ID 填写 qwen3.5:2b,API Key 留空或随便填
最终效果
本地运行大模型,无 API 限流、无网络依赖、完全隐私 通过 OpenClaw Web 界面可视化交互 支持 SSH 端口转发,在本地电脑访问服务器上的服务