Gemini 3 Pro是谷歌于2025年11月发布的旗舰级大语言模型,其技术内核远非"参数更大"所能概括------稀疏专家混合(MoE)架构、原生多模态统一语义空间、可配置思考深度与思维签名机制,共同构成了其性能跃迁的底层逻辑。
国内技术爱好者若想深入研究这些架构特性,可通过聚合镜像站RskAi(ai.rsk.cn)直接体验,实测在百万级Token文档处理任务中信息召回率达97%,响应速度控制在2秒内。
一、架构演进:从稠密Transformer到稀疏MoE的范式迁移
Gemini系列的架构设计经历了三次关键跃迁,每一次都对应着计算效率与模型能力的根本性重构。
1.1 Gemini 1.0:原生多模态奠基期
2023年12月发布的Gemini 1.0奠定了其核心技术特征:原生多模态设计。与当时主流的"连接器架构"(如BLIP-2+LLM)不同,Gemini从训练初始就将图像patch、视频时序帧、音频图谱与文本token投射到统一的潜在空间中。这意味着视觉特征与语言特征在每一层自注意力机制中都能直接交互,而非先识别再生成,有效避免了连接器架构常见的"时间维度因果逻辑丢失"问题。
1.0系列包含三个版本:Ultra(首个在MMLU基准超越人类专家的模型)、Pro(通用版)和Nano(移动端版)。
1.2 Gemini 1.5:MoE架构突破期
2024年2月,Gemini 1.5完成了从稠密Transformer到**稀疏专家混合(Sparse Mixture-of-Experts)**的架构过渡。这一转变的核心在于将计算成本与参数容量解耦:总参数可达千亿级,但每次推理仅激活与任务最相关的一小部分专家模块,推理成本降低60%以上。
在MoE架构中,对于输入token x,输出y的计算公式为激活专家输出的加权和:
text
y = Σ_{i∈Tk(x)} gi(x)Ei(x)
其中Ei是第i个专家网络,Tk(x)是被选中的k个专家索引集(k远小于专家总数),路由权重gi由学习到的路由函数计算。
1.3 Gemini 3 Pro:深度推理与Agent原生期
2025年11月发布的Gemini 3 Pro标志着向"推理优先"架构的演进。其核心变革在于将强化学习深度融入训练管线,使模型在处理复杂任务时具备内部多步推理能力。在稀疏MoE基础上,Gemini 3 Pro进一步优化了门控网络的动态分配策略:纯文本任务仅激活约30%的专家模块,多模态任务激活率升至85%,在保持性能的同时显著降低单模态推理成本。
二、核心技术机制深度拆解
2.1 原生多模态的统一语义空间
Gemini的核心设计哲学是早期融合(early fusion)。图像被切分为patch、音频保留波形直接编码、视频按帧采样,所有模态都被转换为统一格式的token,在共享序列中通过自注意力机制实现跨模态交互。
这种设计的优势在处理30秒1080p视频分析任务时得到体现:Gemini 3.0的首Token生成时间(TTFT)仅为1.2秒,而GPT-4 Vision组合方案通常需要4-6秒。到2026年3月发布的Gemini Embedding 2时,文本、图像、视频、音频和PDF五种模态已被映射至同一向量空间,开发者可直接对"猫的文字描述"与"猫的照片"进行语义相似度计算。
2.2 百万级上下文的工程实现
Gemini 1.5首次将上下文窗口扩展至100万token,较前代提升一个数量级。这不仅是量的变化,更带来质的不同:开发者可将整本教材或完整代码库直接放入上下文,无需搭建复杂的RAG管道。
百万级上下文的工程实现依赖**上下文并行(Context Parallelism)与环形注意力(Ring Attention)**技术。其核心机制包括:
环形注意力:将GPU组织成环形拓扑,每台GPU存储序列的查询(Q)、键(K)、值(V)张量片段,利用本地K、V计算注意力,同时将K、V传递给下一台设备,实现计算与通信的重叠
之字形环形注意力:采用交错式序列拆分(如GPU 0处理Token 0,4,8...),在因果掩码场景下实现GPU负载均衡,避免设备闲置
在Needle In A Haystack测试中,Gemini 1.5在百万token长度下的准确率达到99%。但实测也揭示其局限性:在1M长度的MRCR v2点对点检索任务中,Gemini 3 Pro准确率降至26.3%,暴露出"注意力稀释"这一当前技术的核心瓶颈。
2.3 思维签名与可配置思考深度
Gemini 3 Pro引入了类似区块链校验机制的思维签名(Thought Signatures)技术 。在推理的每一个关键节点,模型都会生成一个加密的Hash签名,确保在进行第50步推理时,逻辑依然严密锚定在第1步的假设上,这使得它在复杂代码Debug场景下的幻觉率降低40%。
开发者通过thinking_budget参数动态调控推理深度
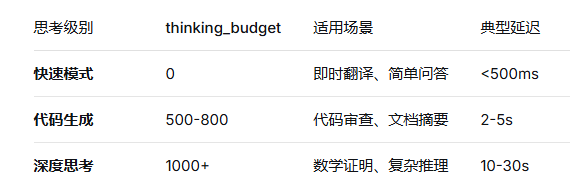
尽管Gemini 3 Pro的推理能力大幅跃升,但仍有技术边界:
注意力稀释:在1M超长上下文中,高精度"大海捞针"式检索的准确率降至26.3%
计算延迟:深度思考模式可能带来10秒以上延迟,不适合实时交互场景
能耗成本:并行推理意味着更高的算力消耗,需要开发者权衡精度与成本
Gemini Embedding 2的发布标志着多模态语义表示进入统一时代。谷歌研究人员预测,千万级Token上下文将在短期内成为标准配置,对编码等应用场景将是革命性突破。同时,理论科学研究领域已出现Gemini的身影:在密码学中找出协议漏洞、在数学领域推翻学者猜想、在天体物理学中推导出精确闭式解。
总结
Gemini 3 Pro的架构演进代表了当前大模型发展的核心方向:MoE稀疏激活提升效率、原生多模态统一语义空间、可配置思考深度实现推理时计算扩展、Agentic能力架构级支持。这些技术共同将AI从"概率生成"推向"深度思考"的新阶段。
对于国内技术爱好者和开发者,通过RskAi这样的聚合平台,不仅能免费便捷地体验这些前沿架构特性,还能利用平台提供的测试环境进行二次开发。理解MoE的稀疏激活原理、思考预算的配置策略、原生多模态的统一语义空间,将为下一波AI原生应用的爆发做好准备。
【本文完】