一. 引入哈希表
1. 红黑树存在哪些局限性?
在上一篇中,我们学习了基于红黑树的 std::map。它很优雅,能让数据始终保持有序,查找的时间复杂度是 O(log N)。但在某些极端场景下,我们并不在乎元素的顺序(比如:统计一本书里每个单词出现的次数,或者在海量用户 ID 中判断某个 ID 是否存在)。此时,我们只想要极致的快
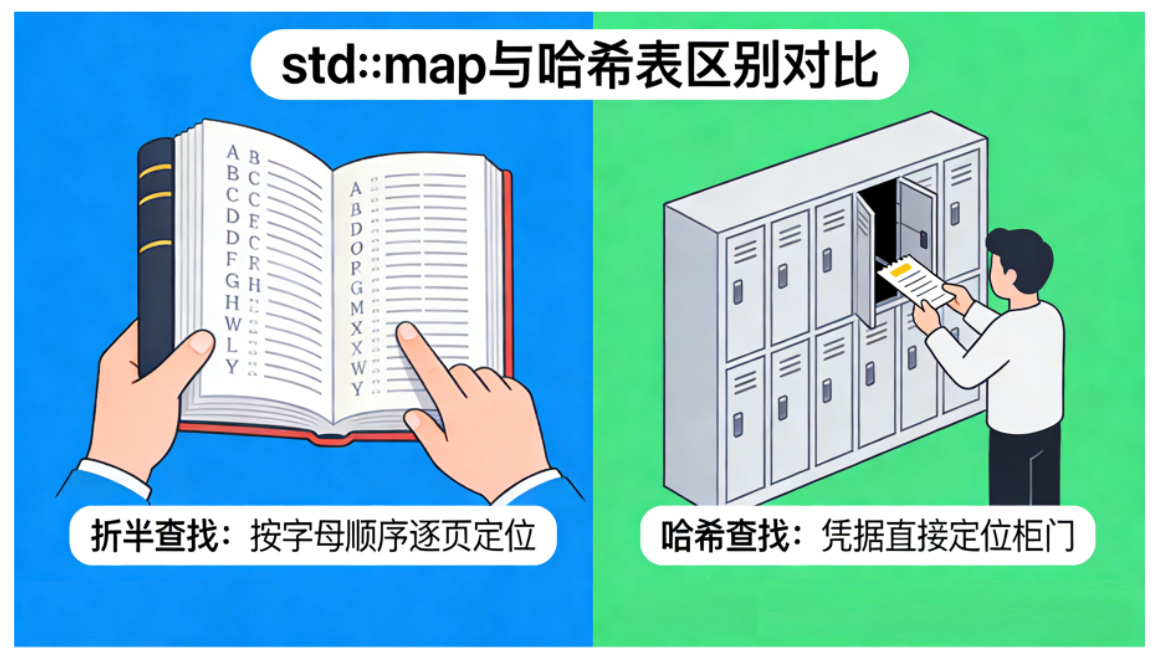
如果说 std::map 是一本按字母顺序排列的字典,你找单词需要一页页翻(折半查找);那么哈希表(Hash Table)就像是超市里的储物柜:你拿着凭据,对应的柜门直接弹开
2. 直观理解哈希表(Hash Table)
哈希表的本质是:映射
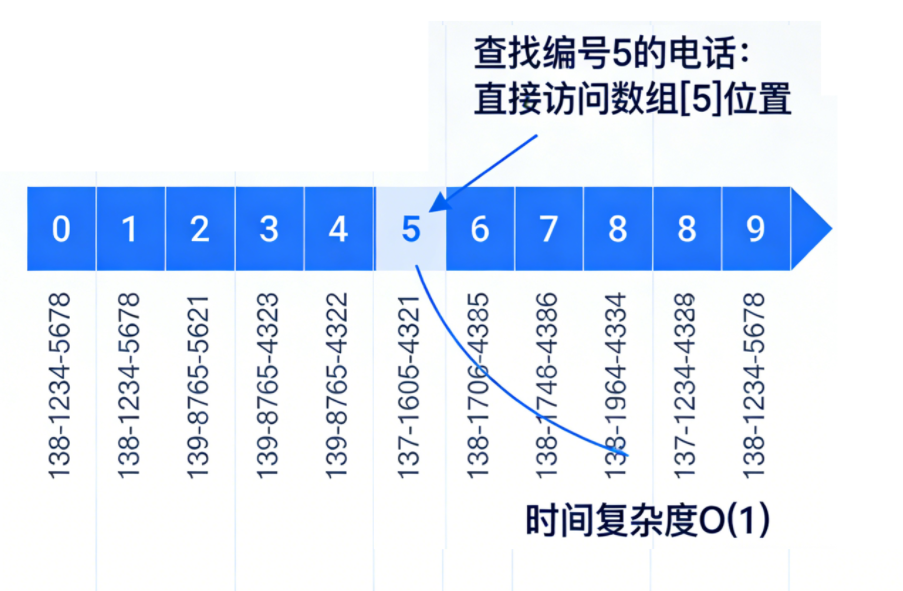
想象一个极其简单的场景:我们要存 10 个人的电话号码,且他们的编号正好是 0 到 9
我们只需要开辟一个长度为 10 的数组,编号是几,就存到数组的第几个位置。查找时,复杂度是 O(1) ------ 这就是哈希表的理想场景
但在现实中,我们的 Key(键)可能是复杂的字符串、巨大的整数甚至是自定义对象。哈希表通过两个核心步骤把这些复杂的 Key 变简单:
-
哈希函数 (Hash Function):把任意复杂的 Key 转化成一个数字(下标)
-
桶 (Bucket):数组中存放数据的位置
C++ 标准库中的 std::unordered_map 和 std::unordered_set 正是这种思想的工业级实现
-
unordered:意味着它不保证遍历顺序,存进去的顺序和输出的顺序可能完全不同
-
map / set:依然保持着键值对映射或唯一集合的功能
它保证在平均情况下,插入、删除、查找全都是 O(1)
二. 本质和对比
上一篇我们探讨过,std::map 的底层采用红黑树实现,就像一支排列有序的队伍,每个元素都有明确的位置顺序。相比之下,std::unordered_map 更像一个精心设计的仓库系统,数据被智能地分配到不同区域(桶/Bucket),虽然表面看似无序,但检索效率却非常高
底层逻辑的不同
-
std::map(基于红黑树实现):通过键值比较进行定位,每次查找需要进行 O(log N) 次比较操作
-
std::unordered_map(基于哈希表实现):通过哈希函数直接计算存储位置,在理想情况下可实现常数时间复杂度 O(1) 的快速访问
1. 核心差异对照表
为了更直观的感受,我整理了这张对比表:
| 特性 | map / set | unordered_map / set |
|---|---|---|
| 底层实现 | 红黑树 (有平衡性的二叉搜索树) | 哈希表 (开链法处理冲突) |
| 元素顺序 | 严格有序(默认升序) | 无序(遍历顺序不可预测) |
| 查找/增删效率 | O(log N) (稳定) | 平均 O(1),极坏情况 O(N) |
| 内存开销 | 较低(每个节点仅需左右指针) | 较高(需维护 Bucket 数组及扩容) |
| 对 Key 的要求 | 必须定义 operator< (比大小) | 必须有 hash 函数和 operator== |
| 迭代器 | 双向迭代器(可自增/自减) | 前向迭代器(仅能自增) |
(决策场景)
什么时候选 std::map
-
需要有序数据:比如需要按从小到大的顺序打印成绩单
-
需要范围查找:比如查找年龄在 20 到 30 岁之间的所有用户(利用 lower_bound)
-
对稳定性要求高:红黑树的性能非常稳定,不会像哈希表那样因为冲突突然变慢
什么时候选 std::unordered_map
-
追求极致速度:如果只是单纯地想根据 ID 查名字,且数据量很大,无脑选 unordered 系列
-
不关心顺序:只要能存能取,谁先谁后无所谓
-
频繁的增删查改:在 LeetCode 的大多数算法题中,unordered_map 通常是提速的首选
这里有个小坑:
如果使用自定义的结构体(比如 Point {int x, y;})做 map 的 Key,那么只需要重载 < 操作符就行
但如果你想用它做 unordered_map 的 Key,你不仅要重载 ==,还得自己写一个 hash 函数(或者告诉编译器怎么算这个结构体的哈希值)
2. 为什么哈希表对 key 要求严格
在使用 std::map 时,我们只需要给 Key 提供一个 operator<(告诉编译器怎么比大小)就够了。但换成 std::unordered_map,编译器会要求更多:它必须支持 Hash 函数 和 operator==
这是为什么?
Hash 函数与 operator==
想象一下我们去健身房存包
- Hash 函数(找柜子):当你把钥匙(Key)交给管理员,他通过一个公式(Hash Function)计算出一个数字。这个数字决定了你的包应该放在哪一排柜子(Bucket)
如果没有 Hash 函数,管理员就不知道该把包往哪放
- operator==(确认身份):由于柜子数量有限,偶尔会出现两个不同的 Key 计算出同一个数字(哈希冲突)。这时,同一个柜子里可能会塞进两个包。当你回来取包时,管理员需要对比包上的标签,确认哪一个才是真正属于你的
如果没有 operator==,即便找到了柜子,管理员也没法在冲突的一堆包里认出你的那一个
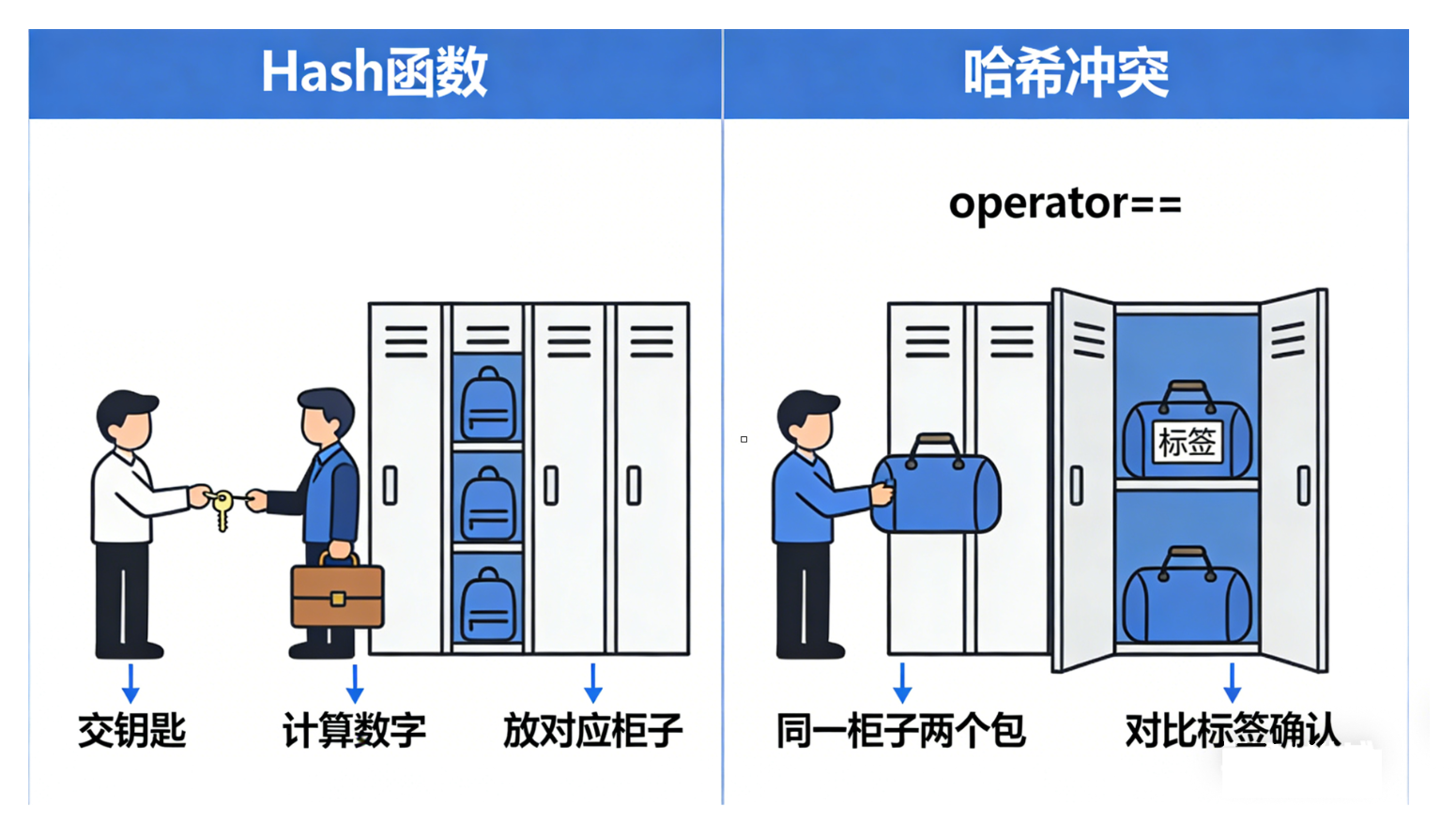
Hash 函数负责确定数据的位置(定位桶),而 operator== 则用于识别数据的唯一性(处理冲突)
3. 为什么只支持前向迭代器
这是一个非常经典的问题。std::map 的迭代器是双向的(可以 ++ 也可以 --),但 std::unordered_map 的迭代器通常只能前向(只能 ++)
这背后的原因藏在它们的底层内存布局里:
-
红黑树(有序):是一个连通的树状结构。每一个节点都知道自己的父节点、左孩子和右孩子。通过这种结构,我们可以轻松地找到前一个比我小的或后一个比我大的元素,因此支持双向遍历
-
哈希表(无序) :底层本质上是一个数组 + 链表 (或其他处理冲突的结构)
迭代器在遍历时,是先遍历完数组的一个桶(Bucket 0),再跳到下一个桶(Bucket 1)而为了节省空间和保持效率,哈希表中的冲突链表通常是单向链表(Single Linked List)。在单向链表中,节点只知道自己的下一个(Next)是谁,根本不知道上一个是谁
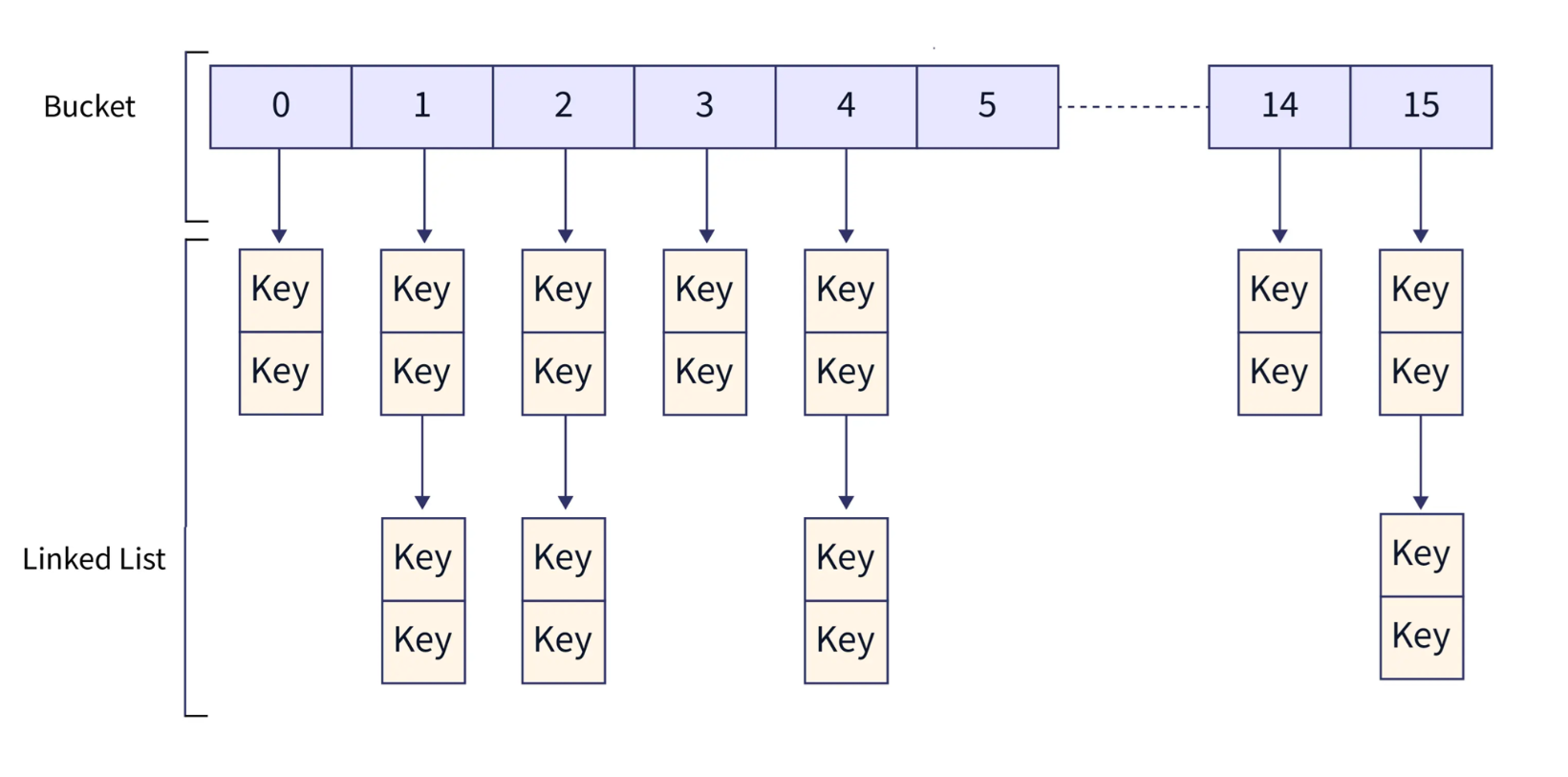
如果要支持双向迭代器,哈希表就必须把底层的单向链表改成双向链表,或者维护一个极其复杂的全局顺序表。为了追求极致的 O(1) 查找速度和较低的内存开销,C++ 标准库选择了放弃后退功能,只提供单向迭代器(Forward Iterator)
三. API 使用
unordered_map 和 unordered_set 的 API 高度相似。为了简洁,下面主要以 unordered_map<string, int> 为例
我们可以把 API 分为四个维度:初始化、插入、查找、删除
1. 初始化
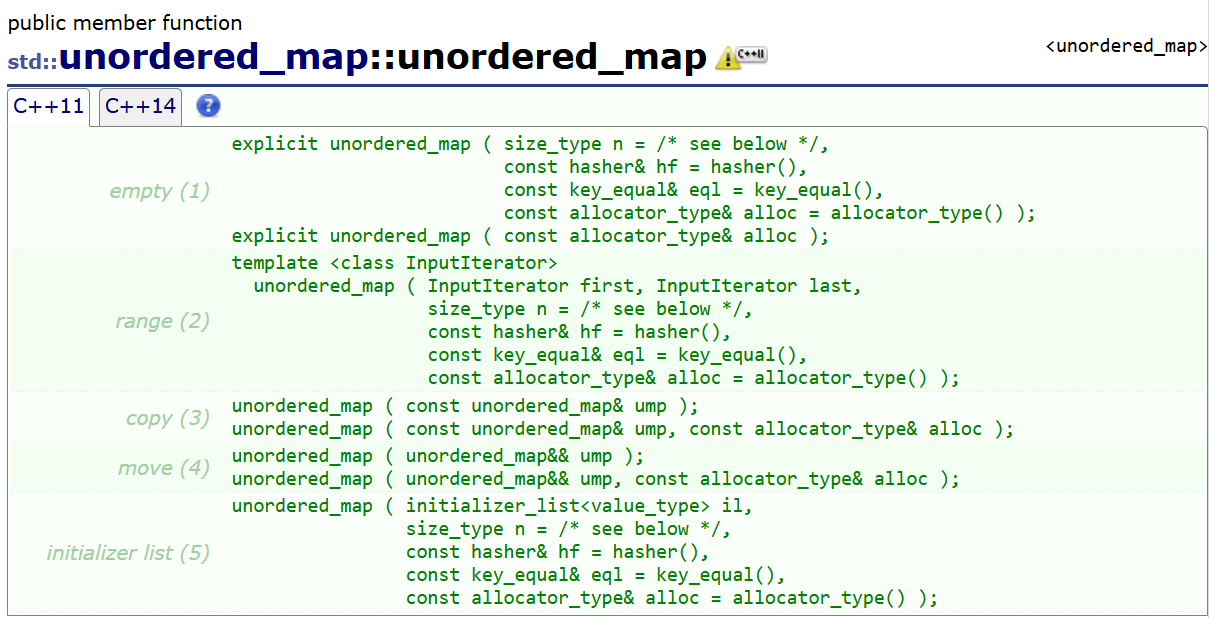
unordered_map 提供了非常灵活的构造方式。参考标准库的定义,我们可以将初始化归纳为以下几类:
1. 空构造(Empty)
这是最基础的构造方式。文档中显示它可以接受一个 size_type n 参数
cpp
// 1. 完全空构造,使用默认初始容量
std::unordered_map<std::string, int> map1;
// 如果你预知要存 100 个元素,可以直接给个初始大小
std::unordered_map<std::string, int> map2(100);2. 区间构造(Range Constructor)
如果已经有一个现成的数据源(比如数组、vector 或另一个 map),你可以利用迭代器区间直接搬运数据
cpp
std::vector<std::pair<std::string, int>> vec = {{"Apple", 1}, {"Banana", 2}};
// 通过迭代器区间构造
std::unordered_map<std::string, int> map3(vec.begin(), vec.end());常用于将其他容器的数据快速转换为哈希表,实现 O(1) 的查找能力
3. 拷贝与移动构造(Copy & Move)
这是标准容器的常规操作
cpp
std::unordered_map<std::string, int> original = {{"Key", 1}};
// 拷贝构造:创建一个完全一样的副本
std::unordered_map<std::string, int> copy_map(original);
// 移动构造:将 original 的资源转移走,original 变为空
std::unordered_map<std::string, int> move_map(std::move(original));4. 列表初始化(Initializer List)
这是 C++11 引入的语法糖,也是目前代码里见得最多的,因为它直观得像是在写配置文件
cpp
std::unordered_map<std::string, int> map4 = {
{"C++", 1985},
{"Java", 1995},
{"Python", 1991}
};5. 自定义哈希与比较
从上面的截图中可以看到,构造函数后面还有 hasher 和 key_equal 等参数
虽然 90% 的场景下我们都使用默认值,但如果你需要用自定义结构体作为 Key,你就需要在这里传入自定义的哈希规则
cpp
// 伪代码示例:传入自定义的哈希对象
auto my_map = std::unordered_map<MyStruct, int, MyHasher>(10, MyHasher());2. 插入元素
标准库主要支持三种数据插入方式:insert、emplace 和 operator\[\]
1. operator\[\]
这是 map 特有的功能,set 并不支持此特性。
如果 Key 存在,则修改 Value;如果 Key 不存在,则直接创建一个新的键值对。如果只是想查询某个 Key 在不在,误用了 \[\] 会导致哈希表莫名其妙多出一个元素(Value 为该类型的默认值)
cpp
std::unordered_map<std::string, int> scores;
// 1. 插入或修改
scores["Alice"] = 100;
// 2. 危险操作:仅仅是访问一个不存在的 Key
int temp = scores["Unknown"];
// 此时 scores 内部已经多了一个 {"Unknown", 0}!2. insert
insert 接受一个 std::pair 或初始化列表。如果 Key 已存在,insert 什么都不做(插入失败);如果 Key 不存在,则插入。它需要先构造好一个 pair 对象,然后再拷贝或移动到哈希桶中
cpp
// 使用 pair 插入
scores.insert(std::pair<std::string, int>("Bob", 90));
// 使用初始化列表(更常用)
scores.insert({"Charlie", 85});3. emplace
自 C++11 起,emplace 成了高性能代码的首选。与 insert 一样,如果 Key 已存在则插入失败。它利用了模板的可变参数,直接在容器内部构造 pair 对象。它避免了先创建一个临时 pair 再拷贝进去的过程
注意它不需要大括号 {}
cpp
// 推荐做法:直接传参数,不需要构造 pair 对象
scores.emplace("Dave", 92);除了 operator\[\] 直接返回引用外,insert 和 emplace 都会返回一个 pair:
-
first:指向该元素的迭代器
-
second:一个 bool 值,true 表示插入成功,false 表示 Key 已存在
cpp
auto [it, success] = scores.emplace("Alice", 99);
if (!success) {
std::cout << "Alice 已经存在,分数为:" << it->second << std::endl;
}3. 查找元素
1. find()
find() 是最经典的查找方式。它返回一个迭代器,如果找到了,迭代器指向对应的键值对;如果没找到,它会返回 map.end()
cpp
auto it = scores.find("Alice");
if (it != scores.end()) {
// 找到了
std::cout << "Alice 的分数是:" << it->second << std::endl;
} else {
std::cout << "没找到 Alice。" << std::endl;
}2. count()
对于 unordered_map 来说,Key 是唯一的,所以 count() 的返回值只可能是 0(不存在) 或 1(存在)
cpp
if (scores.count("Bob")) {
std::cout << "Bob 在名单里。";
}3. at()
at() 是一个只读操作,且非常严格。如果 Key 存在:返回值的引用。如果 Key 不存在:它不会插入新元素,而是直接抛出异常 (std::out_of_range)
cpp
try {
int s = scores.at("Unknown");
} catch (const std::out_of_range& e) {
std::cout << "捕获到异常:Key 不存在!" << std::endl;
}4. 删除元素
unordered_map 的删除主要依靠 erase(),它非常灵活,支持三种不同的删除方式:
-
按 Key 删除:最常用。返回删除的元素个数(对于 unordered_map 只有 0 或 1)
-
按迭代器删除:当你已经通过 find() 拿到了位置,直接删除效率最高
-
清空整个容器:使用 clear()

cpp
std::unordered_map<std::string, int> scores = {{"Alice", 90}, {"Bob", 80}, {"Charlie", 70}};
// 1. 直接按 Key 删
scores.erase("Alice");
// 2. 配合 find 删除
auto it = scores.find("Bob");
if (it != scores.end()) {
scores.erase(it); // 此时 scores 里只剩 Charlie
}
// 3. 一键清空
scores.clear();实战题目 1:和为 K 的子数组 (LeetCode 560)
题目描述:
给你一个整数数组 nums 和一个整数 k ,请你统计并返回该数组中和为 k 的子数组的个数
子数组是数组中元素的连续非空序列
示例 1:
输入:nums = [1,1,1], k = 2
输出:2示例 2:
输入:nums = [1,2,3], k = 3
输出:2核心算法思想:前缀和的转化
我们定义 prei 为从索引 0 到 i 的所有元素之和。那么,任何一个连续子数组 j, i 的和可以表示为:
我们的目标是找到满足以下公式的组合
将等式变换一下
换句话说,当遍历到第i个位置时,当前的前缀和为prei。此时只需查询哈希表:在之前的所有前缀和中,有多少个值恰好等于 prei - k
代码实现
cpp
class Solution {
public:
int subarraySum(vector<int>& nums, int k) {
// key 为前缀和的值,value 为该前缀和出现的次数
std::unordered_map<int, int> mp;
// 【重要核心】:初始化!前缀和为 0 默认出现了 1 次
// 代表从开头到当前位置正好和为 k 的情况:pre[i] - 0 = k
mp[0] = 1;
int count = 0;
int pre = 0; // 记录当前前缀和
for(auto& e : nums)
{
pre += e;
if(mp.find(pre - k) != mp.end())
count += mp[pre - k]; // 如果存在,则把出现的次数累加进结果中
// 将当前前缀和存入map
mp[pre]++;
}
return count;
}
};注意:mp0 = 1 的作用
这是很多人会漏掉的一行。 为什么要加它?如果数组第一个元素正好就是 k。此时 pre = k,我们需要查找 pre - k = 0 是否存在。如果没有 mp0 = 1,这个符合条件的子数组就会被漏掉。它代表从数组下标 0 开始的子数组这种特殊情况
复杂度分析
1. 时间复杂度:O(N)
这里的 N 是数组 nums 的长度
我们只对数组进行了一次 for 循环遍历。
在每次循环内部,我们主要做了以下三件事:
-
变量累加(pre += x):O(1)
-
哈希表查找(mp.find()):哈希表在平均情况下的查找复杂度为 O(1)
-
哈希表插入/更新(mppre++):平均复杂度同样为 O(1)
N 次循环 * 单次常数级操作 = O(N)
2. 空间复杂度:O(N)
我们定义了一个 std::unordered_map 来存储前缀和及其出现的次数。如果数组中每一个位置计算出的前缀和都是唯一的(例如数组元素全是正数),哈希表最多会存储 N + 1 个键值对(包括初始化的 {0, 1})
空间开销随数据量线性增长,即 O(N)
实战题目2:LRU 缓存 (LeetCode 146)
题目描述:
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
-
LRUCache(int capacity) 以正整数作为容量 capacity 初始化 LRU 缓存
-
int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1
-
void put(int key, int value) 如果关键字 key 已经存在,则变更其数据值 value ;如果不存在,则向缓存中插入该组 key-value 。如果插入操作导致关键字数量超过 capacity ,则应该逐出 最久未使用的关键字
核心难点
LRU 缓存要求实现两个功能,且时间复杂度必须都是 O(1)
-
get(key):如果 Key 存在,返回其值,并将该 Key 标记为最近使用
-
put(key, value):插入或更新值。如果缓存满了,删除最久未使用的元素
矛盾点在于哈希表虽然查找快 (O(1)),但它没有顺序,没法知道谁是最久的。双向链表调整顺序快 (O(1)),但它查找慢 (O(N))
解题思路:哈希表 + 双向链表
我们可以将两者结合:用双向链表维护使用顺序,用哈希表实现快速定位
哈希表的 Value 存的不再是简单的整数,而是指向链表节点的迭代器 (Iterator)。这样我们就能通过哈希表直接定位到链表中的具体位置,从而在 O(1) 内完成删除和移动操作
cpp
class LRUCache {
public:
int _capacity;
// 双向链表:存储 {key, value},最近使用的放在 head,最久不用的在 tail
list<pair<int, int>> _cache;
// 哈希表:key 指向链表节点的迭代器
unordered_map<int, list<pair<int, int>>::iterator> _mp;
LRUCache(int capacity) :_capacity(capacity) {}
int get(int key) {
if(_mp.find(key) == _mp.end()) return -1;
// 将该节点移到链表头部,表示最近使用
// splice 可以在 O(1) 内移动节点而不涉及内存拷贝
_cache.splice(_cache.begin(), _cache, _mp[key]);
return _mp[key]->second;
}
void put(int key, int value) {
// 情况 1:Key 已存在,更新值并移到头部
if(_mp.find(key) != _mp.end())
{
_cache.splice(_cache.begin(), _cache, _mp[key]);
_mp[key]->second = value;
return;
}
// 情况 2:Key 不存在,检查容量
// 容量满了,删除最久未使用的数据
if(_cache.size() == _capacity)
{
int removeKey = _cache.back().first;
_mp.erase(removeKey);
_cache.pop_back();
}
// 插入新元素到头部
_cache.emplace_front(key, value);
_mp[key] = _cache.begin();
}
};std::list::splice 是 C++ 标准库中 list 容器的高效操作接口。该接口通过调整指针指向来实现链表节点的位置移动,整个过程不涉及元素拷贝或销毁操作。由于 std::list 的特性,只要节点未被删除,指向它的迭代器始终保持有效。这一特性确保了我们可以安全地将 list::iterator 存储在 unordered_map 中
复杂度分析
- 时间复杂度 :get 和 put 均为 O(1)
哈希表负责 O(1) 查找定位。双向链表负责 O(1) 节点搬运
- 空间复杂度 :O(capacity)
我们需要同时在链表和哈希表中维护最多 capacity 个元素
总结
总的来说,std::unordered_map 是 C++ 给追求极致性能的开发者的加速器,它通过牺牲有序性和额外的内存空间换取了平均 O(1) 的惊人速度。然而,在实际工程中必须警惕哈希冲突导致性能退化到 O(N) 的极端情况,并习惯为自定义 Key 手动提供 hash 函数和 operator==。一个成熟的 C++ 开发者应当具备这样的直觉:在数据量大且无序要求的算法场景(如两数之和、LRU)中首选 unordered 系列,并养成提前使用 reserve() 规避重哈希(rehash)开销的好习惯;而如果需要遍历有序数据或稳定的性能曲线,请继续使用红黑树(std::map)
