🔍 故障本质分析
这是 Oracle 联机重做日志(REDO LOG)损坏导致的数据库启动失败,具体是:
核心错误
ORA-00742: Log read detects lost write in thread 1 sequence 28 block 817
→ 日志读取时检测到丢失写(lost write),线程 1、序列号 28、数据块 817 处的 REDO 日志内容损坏 / 丢失。
ORA-00312: online log 1 thread 1: '/u01/app/oracle/oradata/ORCL11G/redo01.log'
→ 明确指出损坏的是第 1 组联机重做日志文件 redo01.log。
故障场景数据库在异常宕机后尝试启动,需要用 redo01.log 完成崩溃恢复,但该日志文件已损坏,Oracle 无法读取必要的重做信息来保证数据一致性,因此拒绝打开数据库。
🛠️ 根本原因
存储层问题:底层磁盘 / 存储阵列出现 IO 错误、坏块或短暂中断,导致 REDO 日志写入不完整(丢失写)。
系统异常:服务器突然断电、内核 panic、Oracle 进程被强制杀死等,导致 REDO 日志未完全刷盘。
文件系统问题:文件系统 corruption 或挂载异常,损坏了 redo01.log 文件。
⚠️ 关键结论
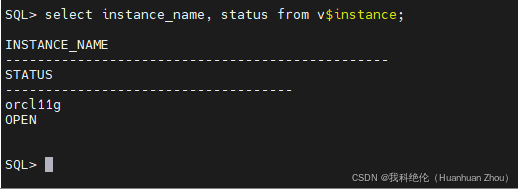
这是严重的存储 / 日志损坏故障,无法通过简单的 alter database open 解决。
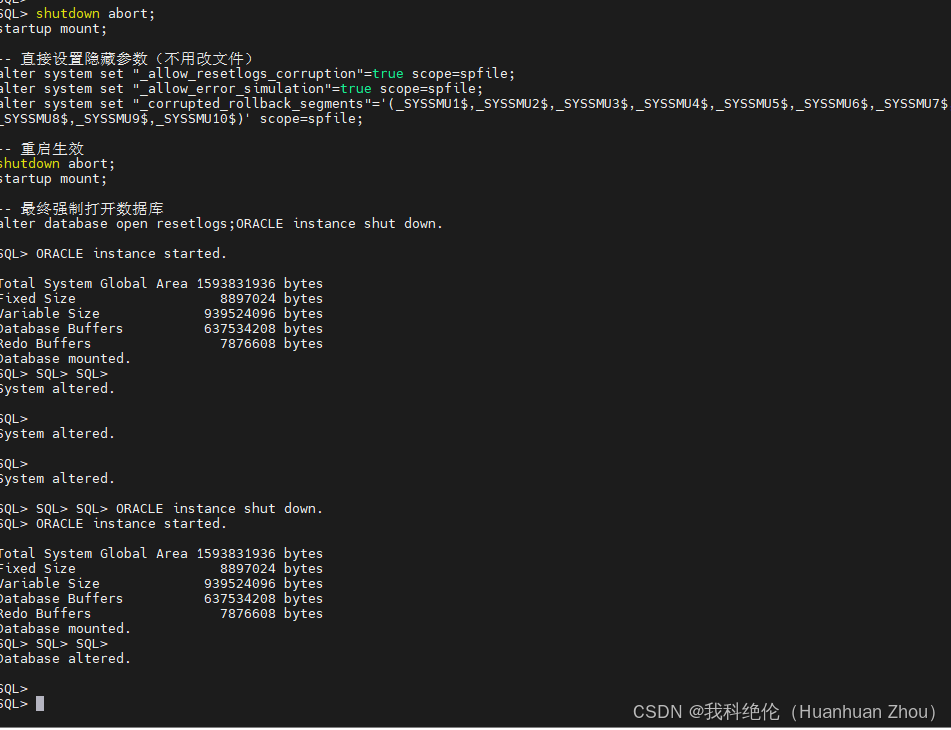
问了豆包,豆包发我的命令,我试着执行,竟然成功了
bash
shutdown abort;
startup mount;
-- 直接设置隐藏参数(不用改文件)
alter system set "_allow_resetlogs_corruption"=true scope=spfile;
alter system set "_allow_error_simulation"=true scope=spfile;
alter system set "_corrupted_rollback_segments"='(_SYSSMU1$,_SYSSMU2$,_SYSSMU3$,_SYSSMU4$,_SYSSMU5$,_SYSSMU6$,_SYSSMU7$,_SYSSMU8$,_SYSSMU9$,_SYSSMU10$)' scope=spfile;
-- 重启生效
shutdown abort;
startup mount;
-- 最终强制打开数据库
alter database open resetlogs;