1. 什么是RAG?
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种结合信息检索 与文本生成的技术。
核心思想 :在生成答案前,先从大规模知识库中实时检索相关信息,然后基于这些检索到的可靠证据来构建回答。这种方法有效提升了生成内容的准确性、时效性与可信度,同时显著减少了大模型产生"幻觉"或错误信息的风险。
RAG广泛应用于智能问答、文档摘要 和知识辅助决策等场景,成为增强大语言模型事实性与可靠性的关键技术。
1.1 RAG架构模式
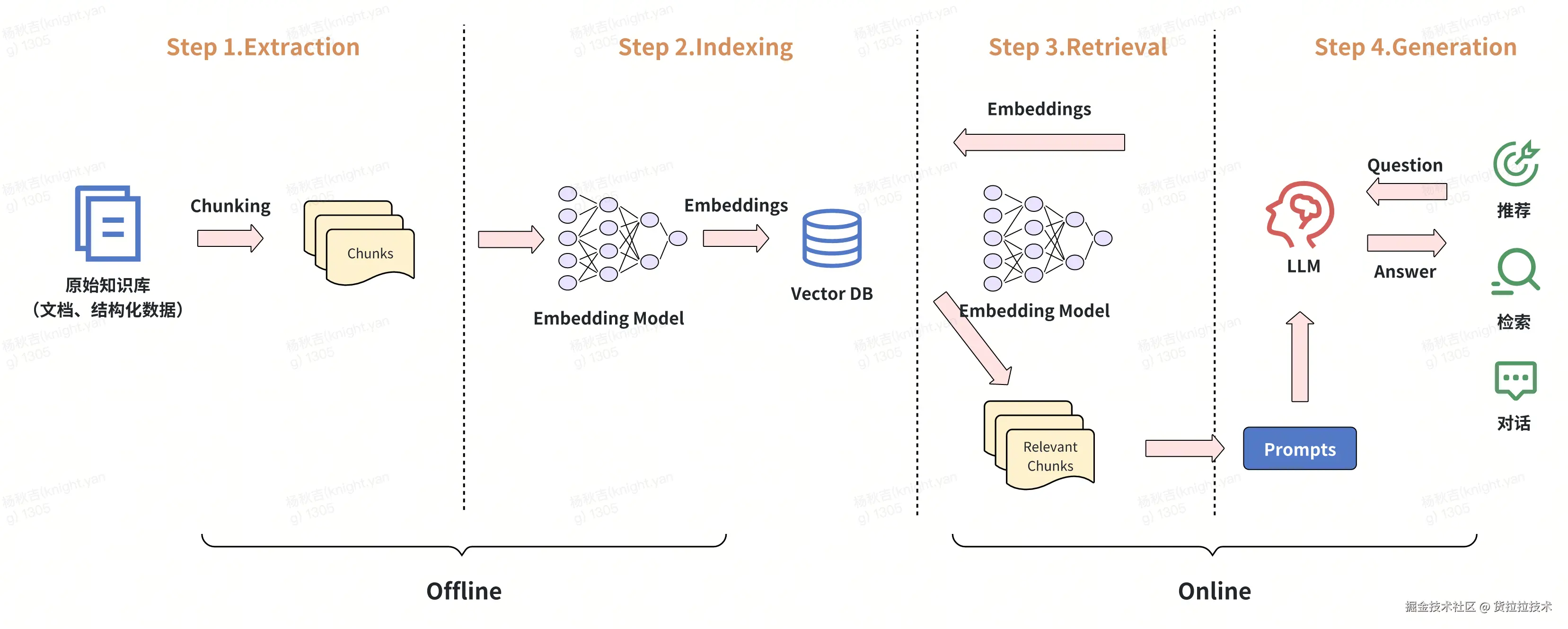
1.2 RAG的挑战
RAG系统没有银弹 ------ 不存在一种万能方案能解决RAG系统的所有问题。RAG虽通过检索外部知识提升生成可靠性,但仍面临多重挑战:检索的相关性与时效性难两全,向量召回易遗漏关键信息,复杂知识结构难适配,语义理解与真实需求间存在鸿沟。优化RAG需结合场景调参、改进检索算法、增强知识过滤,甚至融合大模型的推理能力,而非依赖单一技术突破。

1.3 怎么评价RAG系统?
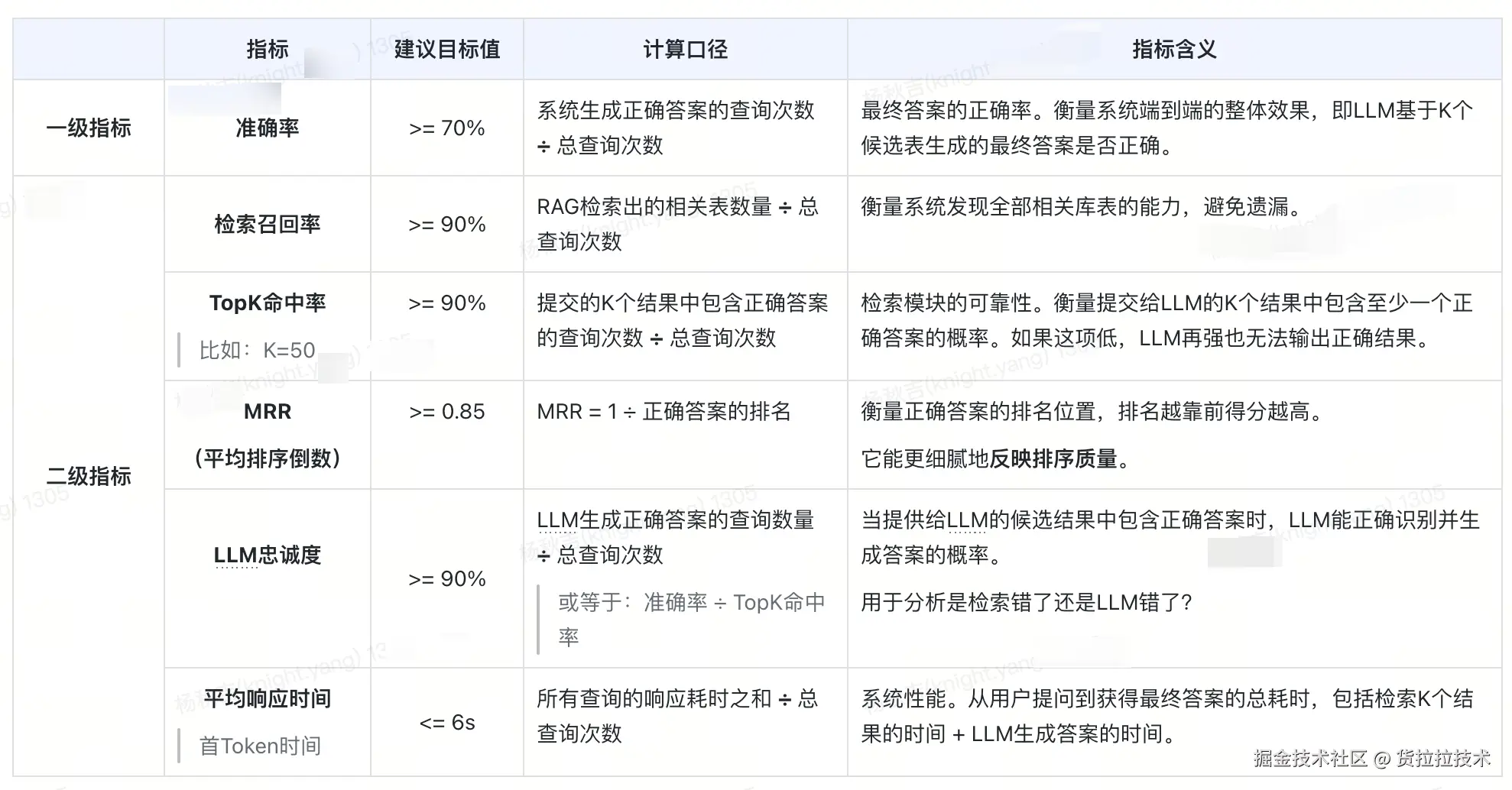
2. 什么是GraphRAG?
GraphRAG(Graph Retrieval-Augmented Generation) 是RAG的进阶架构,其核心创新在于引入知识图谱(Knowledge Graph) 来优化检索与生成过程。
与传统RAG基于向量检索文档片段不同,GraphRAG首先从海量数据中构建并存储一个结构化的知识图谱,通过图算法(如社区发现、中心性分析)来深度挖掘实体间的复杂关系与全局洞察。生成答案时,系统从图谱中检索相关的子图、模式或社区信息作为上下文。
这种方法极大地增强了对复杂问题的推理能力、隐藏关联的发现能力以及回答的系统性,特别适用于需要深度分析、趋势挖掘和跨源知识融合的战略决策场景。
2.1 引入Graph之后的RAG架构模式
引入Graph的增强型RAG模式,分离线和在线两阶段。
离线阶段:原始知识库经Chunking生成文本块,同时通过LLM知识抽取得到实体与关系;文本块经Embedding Model生成向量存入Vector DB,实体关系构建Graph索引存入Graph DB。
在线阶段:用户问题先经Embedding Model生成向量,结合向量检索与图检索,从Vector DB获取相关文本块,从Graph DB获取相关实体与关系;将这些信息整合成Prompt输入LLM生成答案,支持诸如:推荐、检索、对话这些场景。
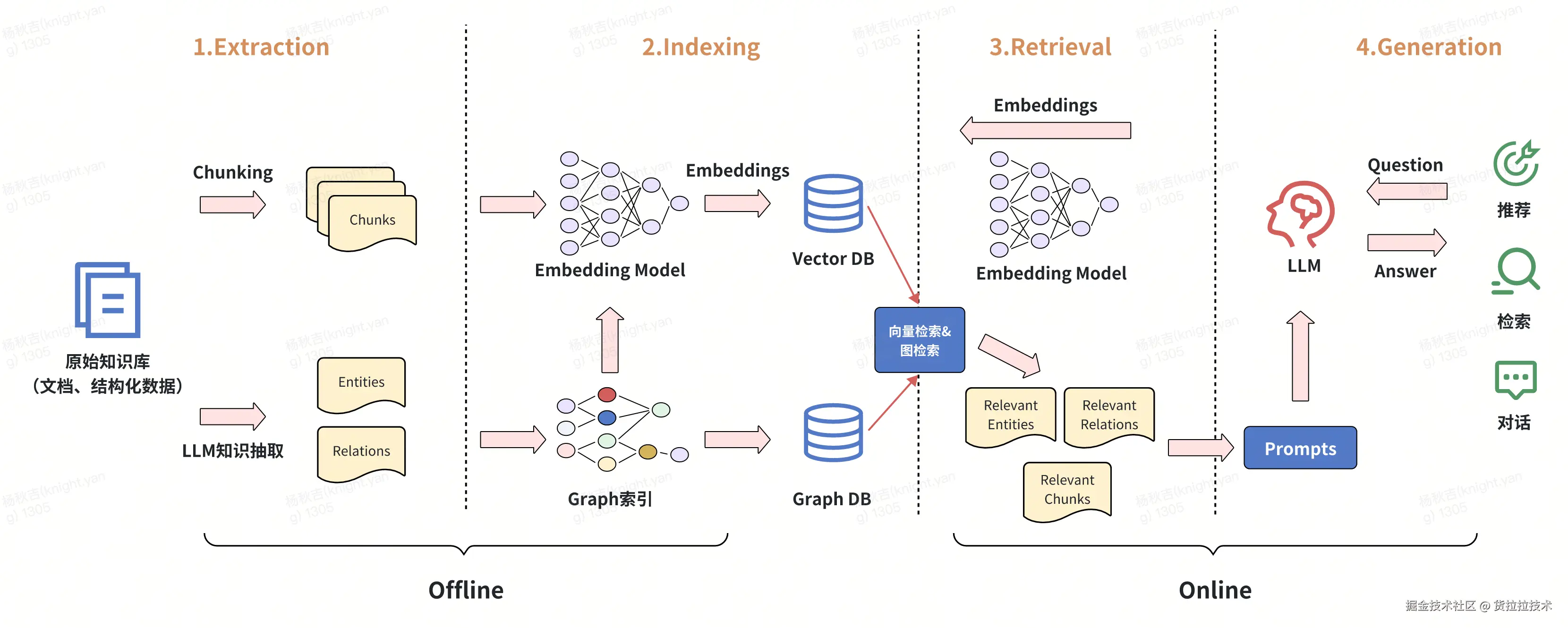
主流GraphRAG方案一般都具备以下核心特性:
- • 多索引结合:图索引、向量索引、全文索引
- • 混合检索:向量检索、全文检索、标量检索
- • 多跳推理:基于图索引的知识图谱,进行多步推理,解决复杂问题
2.2 GraphRAG vs. RAG
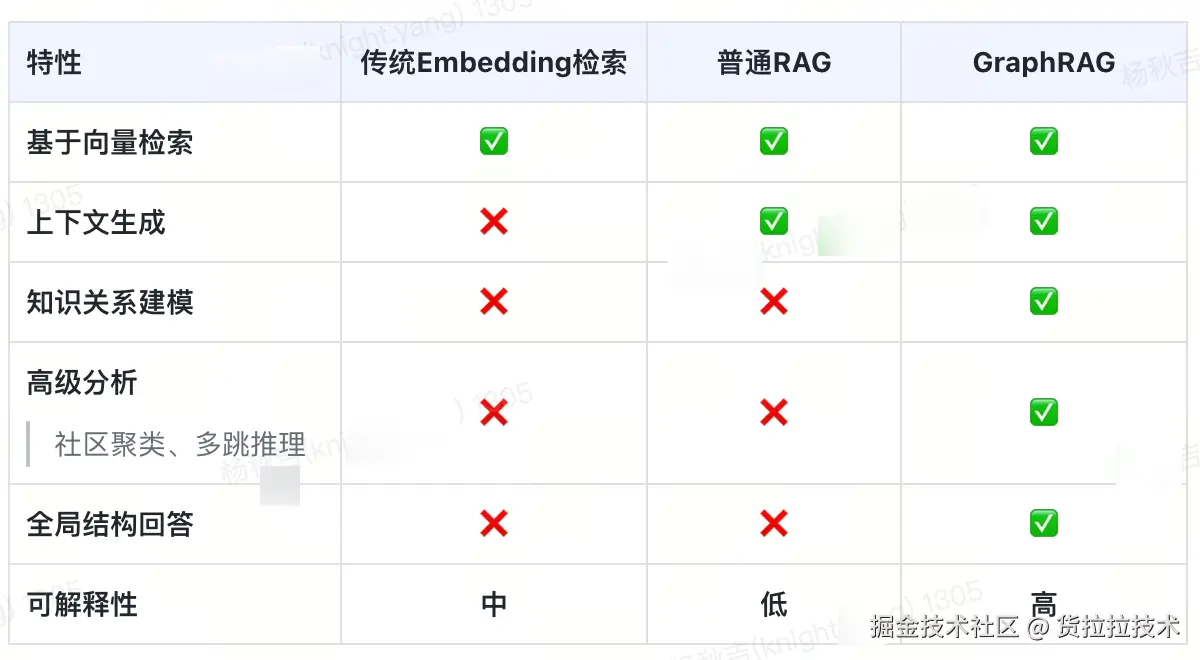
2.3 3种Graph-based RAG对比
Graph-based RAG有三类典型范式:GraphRAG(微软开源)、LightRAG与PathRAG。它们分别从知识挖掘、轻量化、路径推理三个核心维度突破传统RAG局限。针对不同业务场景的差异化需求,既可以按需选择适配的单一方案,也可通过方案间的灵活组合,发挥各自优势、形成协同效应,以更高效地满足复杂场景下的知识检索与推理需求。
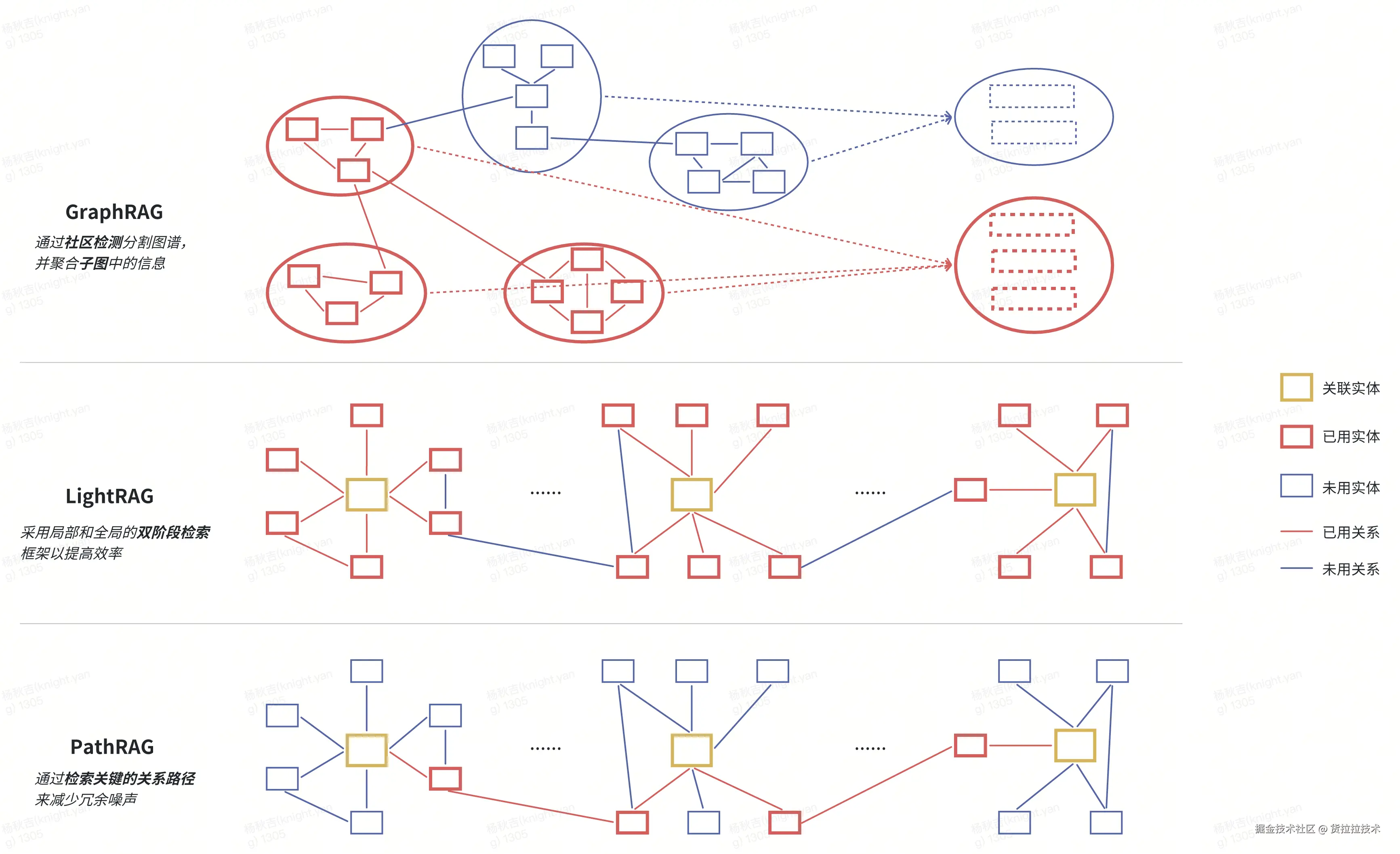
它们之间的详细对比:

3. AI元数据检索探索之路
3.1 业务背景
用户在找数过程中,由于需要用户具备一定程度的业务知识和技术知识,经常会遇到各种数据理解和使用上的疑问,需要频繁跟技术来回沟通。
随着LLM的出现和RAG的兴起,可以尝试利用RAG系统,有效的理解和处理复杂的元数据和业务知识,通过用户对话式问答的交互方式,降低用户找数门槛,减轻隐性的沟通负担,从而进一步提升数据检索的效率。
用户提问案例:
- • XXX数据/业务字段,在哪个表能找的到?怎么取,在哪获取?
- • XXX业务数据,在哪个表的,哪个字段?
- • XXX表里有XXX业务数据的字段吗?是哪个?
- • XXX的数据口径是什么?有没有说明?
- • XXX的业务含义是什么意思?
- • ......
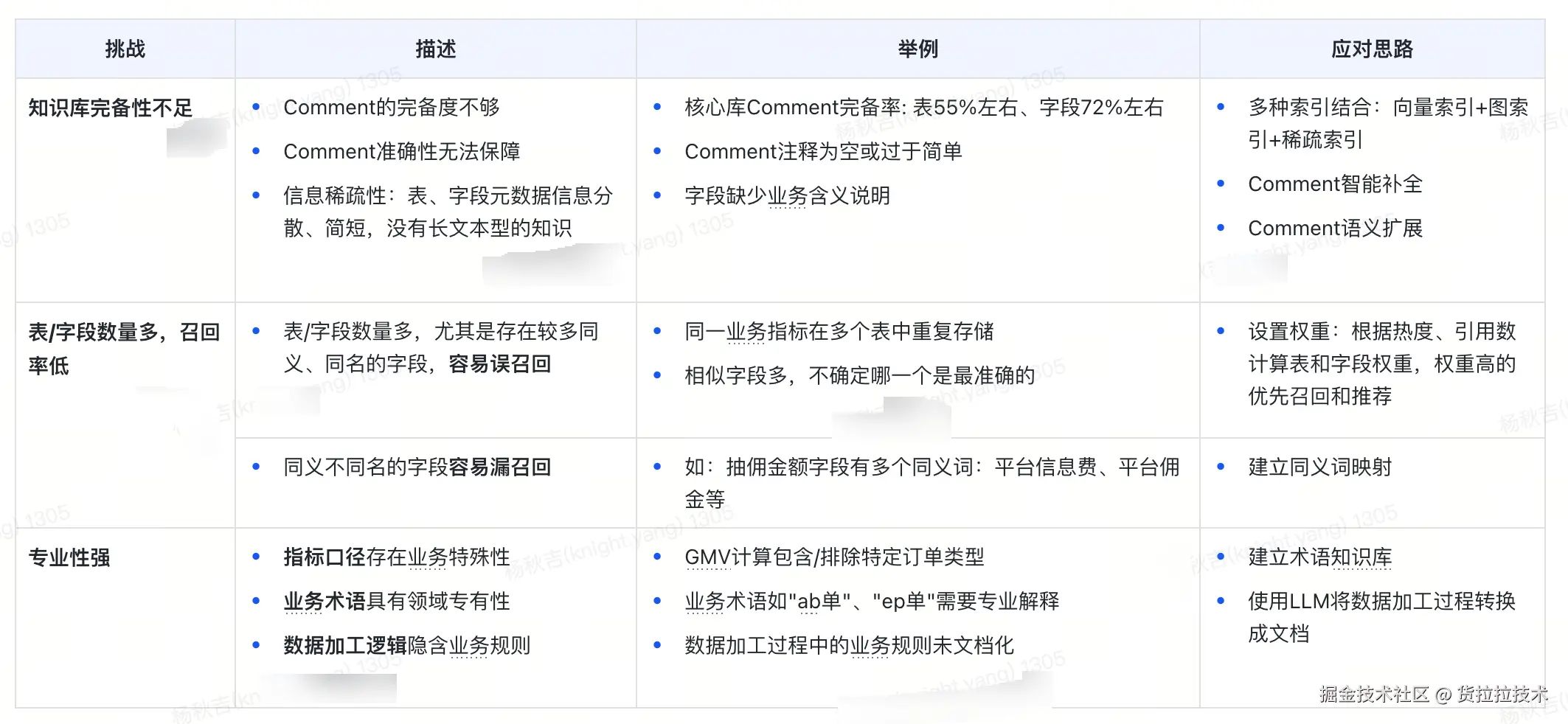
3.2 关键挑战
3.3 方案1.0 ------ Naive RAG
-
方案1.0 效果
- 整体效果未达预期目标
- 回答准确率仅55%;召回率/TopK命中率只有60%左右;
-
问题归因
❌ 知识库"营养不良" :仅包含库表schema+comment,缺乏业务背景、字段口径、数据血缘等关键信息
❌ 检索能力"单一薄弱" :仅依赖向量检索,面对同义词、多实体关联、表间关系等复杂问题时召回率拉胯
❌ 边界感"完全缺失" :无法识别超出知识库范围的问题,易输出误导性内容
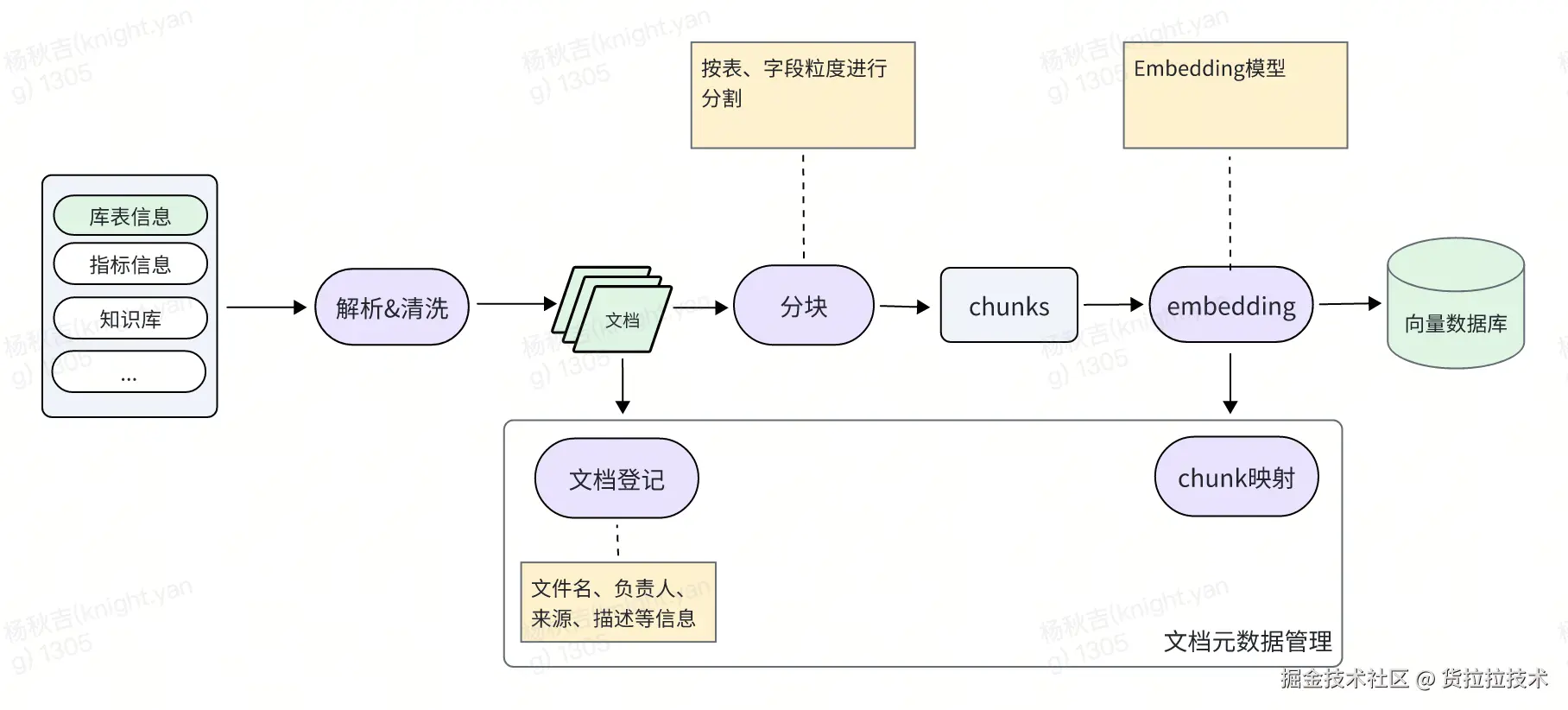
1) 索引流程
知识库导入流程如下:
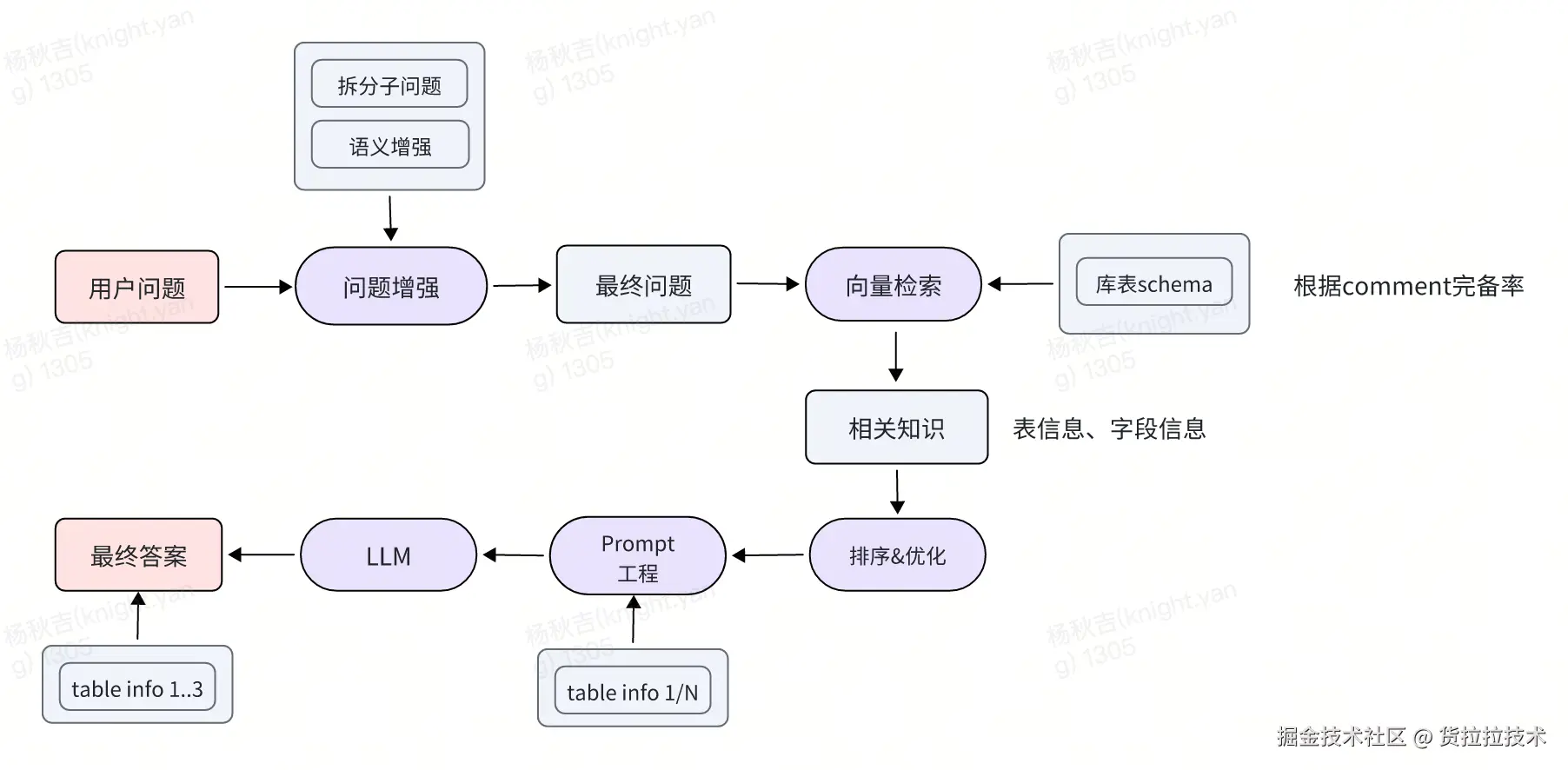
2) 检索流程
知识库检索&生成流程如下:
3) 分块(Chunking)方式
-
方式一(不采用):单个表作为一整个chunk
这种方式很好的保存了表的完整信息,但是会存在以下两个问题:
- 会导致在进行相似度匹配时,将用户问题中的关键字和整个表进行匹配,这样可能存在匹配度很高,但实际不是用户要查找的表的情况,如下所示。
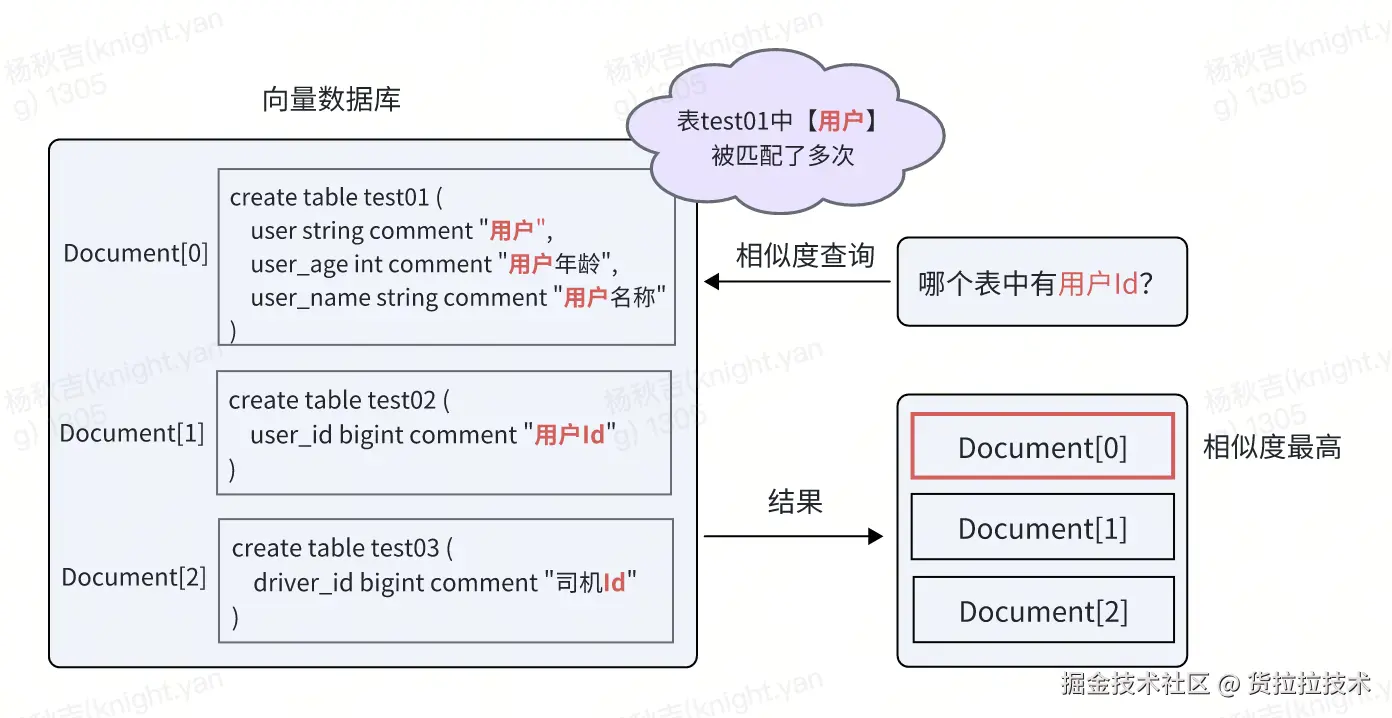
- 而整表文档作为上下文给到LLM,token长度很容易超限。
- 方式二(采用):单字段切割 能避免上述整表切割带来的两个问题;但同时要考虑chunk过多,可能影响查询性能
如下所示格式,在可按照单行/多行进行切割
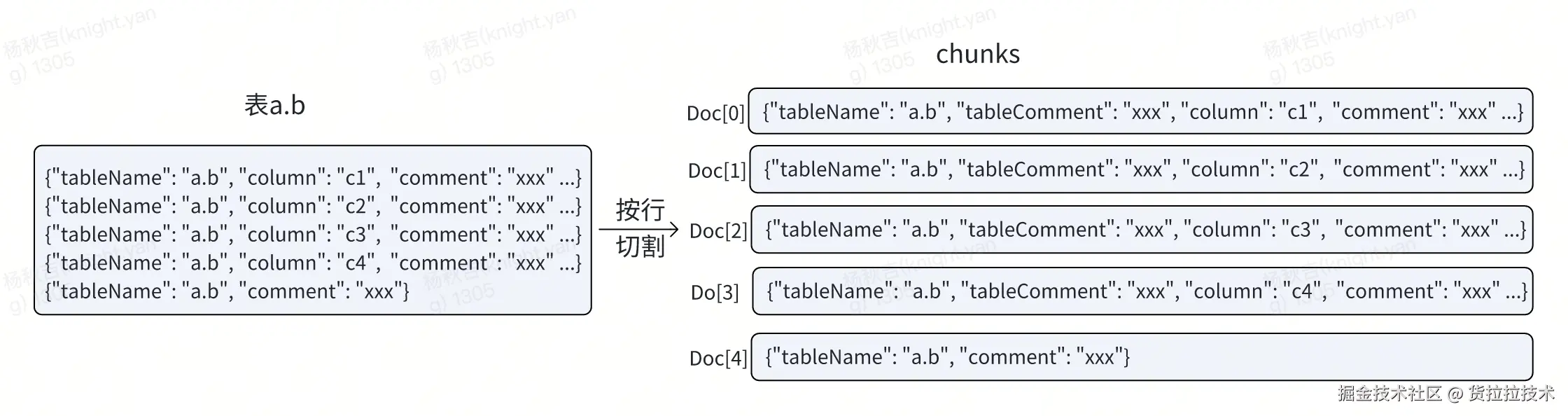
因此选择第二种切割方式更适合库表检索场景。
demo效果展示
json
1. 用户问题:xxx字段,在哪个表里能找到?
2. 向量数据库检索结果:
{"tableName": "table1", "column": "xxx", "type": "string", "comment": "xxx"};
{"tableName": "table1", "column": "xxx", "type": "bigint", "comment": "xxx"};
{"tableName": "table2", "column": "xxx", "type": "bigint", "comment": "xxx"};
{"tableName": "table2", "column": "xxx", "type": "bigint", "comment": "xxx"};
{"tableName": "table3", "column": "xxx", "type": "bigint", "comment": "xxx"};
{"tableName": "table2", "column": "xxx", "type": "bigint", "comment": "xxx"};
{"tableName": "table2", "column": "xxx", "type": "bigint", "comment": "xxx"};
{"tableName": "table3", "column": "xxx", "type": "bigint", "comment": "xxx"};
{"tableName": "table2", "column": "xxx", "type": "bigint", "comment": "xxx"};
{"tableName": "table2", "column": "xxx", "type": "bigint", "comment": "xxx"};
3. LLM生成答案:
xxx字段在"table1"这个表中可以找到4) 方案1.0的Badcase分析
下面是针对方案1.0的Badcase详细分析,核心问题主要集中在三个层面:
- 首先是知识召回环节存在不足,导致相关信息未能有效触达到LLM上下文;
- 其次是知识库本身的质量有待提升,内容准确性和覆盖度存在局限;
- 最后是边界问题,对需求范围的界定不够清晰,易引发处理偏差。
其中,知识召回问题的影响最为突出,其次是知识库质量问题,边界问题的影响相对较小。
具体Badcase示例:
- 语义不匹配
js
Q1: 哪张表能取到司机运送实际车型啊?
标准答案: 司机宽表xxx字段,该字段含义是【物理车型】
AI答案:<回答完全不相关的表和字段>
Q2: 大佬们,想问下哪里可以取到运脉上的司机卸货位置啊
标准答案:xxx表的xxx和xxx字段可以取到司机开始卸货的经度和开始卸货的纬度
AI答案:<不会回答"司机开始卸货的经度和开始卸货的纬度"相关字段>原因分析:
-
同义词匹配问题:【实际车型】无法和【物理车型】匹配,向量无法有效召回
-
业务口径匹配问题:【司机卸货位置】无法和【司机开始卸货的经度和开始卸货的纬度】匹配,向量无法有效召回
- 多问题/多实体/关系召回率低
js
Q1: 请问下这4个时间节点分别对应订单宽表哪个字段呀?司机到达发货地、司机完成装货、司机到达收货地、司机完成卸货
标准答案:xxx表有相关字段
AI答案:<只会回答其中1个或2个字段>
Q2:哪张表有存司机ID对应的手机号呢?
标准答案:你可以在table1、table2表中找到司机ID对应的手机号,其中xxx字段代表手机号。
AI答案:<可能会回答不知道>原因分析:
- 多实体召回问题:
- 向量召回无法精确召回所有实体
- 无法回答实体之间关联问题
- 无关信息干扰,回答不正确
无关信息会干扰向量召回精确度。
swift
Q1:想问下如果用户没有完单,但下单时候选择了专票,这种怎么取呢?我在你说的这个表没找到这类未完单但下单时收了专票服务费的订单
标准答案:xxx业务:table1、xxx业务:table2、字段:colomn1
AI答案:<会回答用户问题中后半句相关的内容>- 缺乏相关知识,胡乱回答
diff
Q1:你好,请问现在有实时订单表可以使用么?
标准答案:看看这个表xxx
AI答案:<回答不相关的表>
-- 注:这个例子中,实时订单表缺少comment和业务描述- 不存在相关表,胡乱回答
swift
Q1:需要xxx业务线的已取消订单司机实际行驶距离。我看有些报表有个xxx不知道哪个可用
标准答案:没有现成的表,需要加工才能取到
AI答案:<回答完全不相关的表和字段>3.4 方案2.0 ------ GraphRAG
元数据天然就具有知识图谱的表达方式和存储结构,方案2.0采用了Graph-based RAG的技术思路。经过深入研究和对比分析,LightRAG从复杂度、灵活性、可嵌入性等方面考虑,比较适合我们的场景
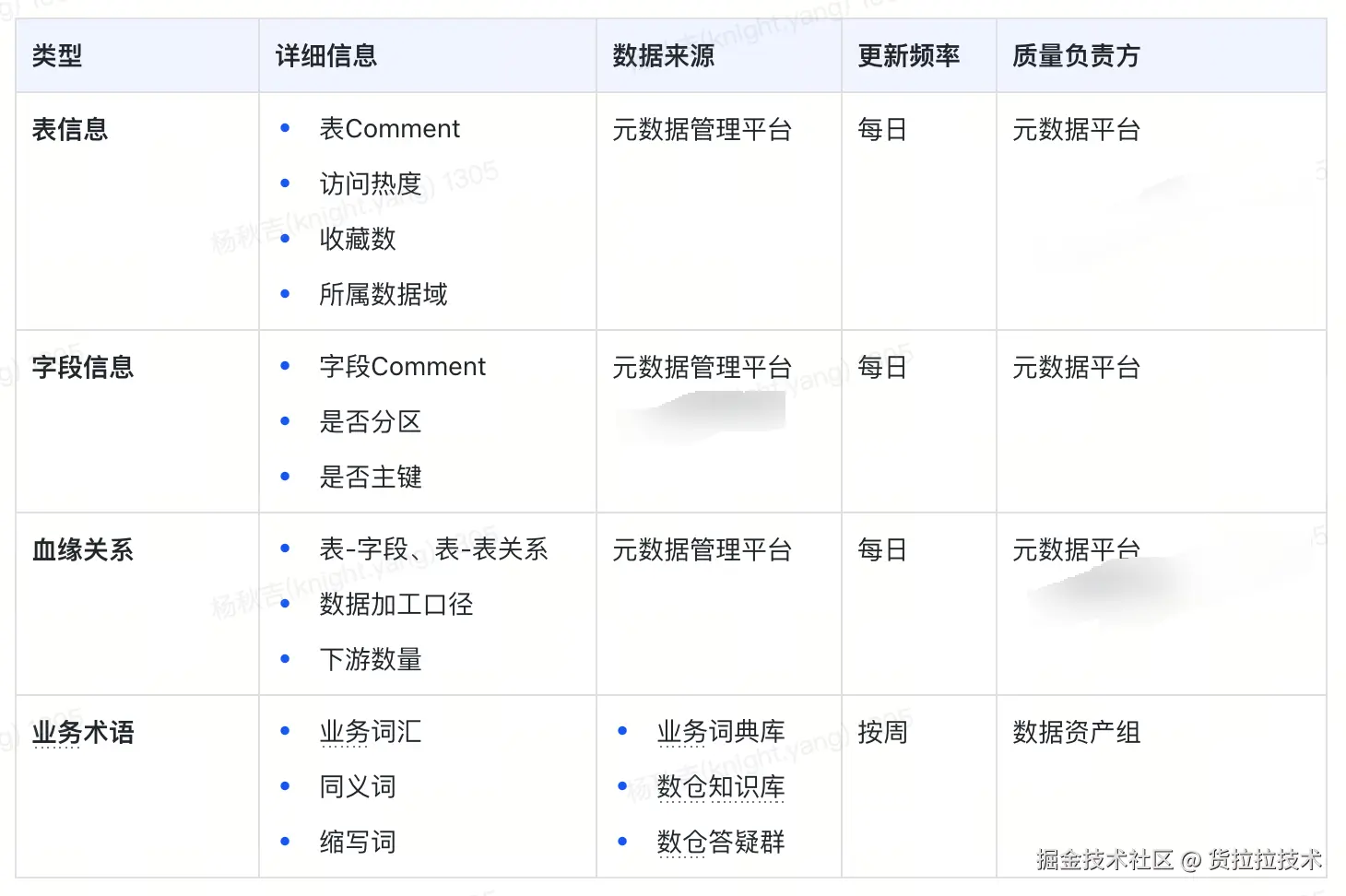
1)知识库
知识库拟采用渐进式扩展 的建设策略,从核心数据域(如订单域)开始验证效果,逐步扩展到全库范围。
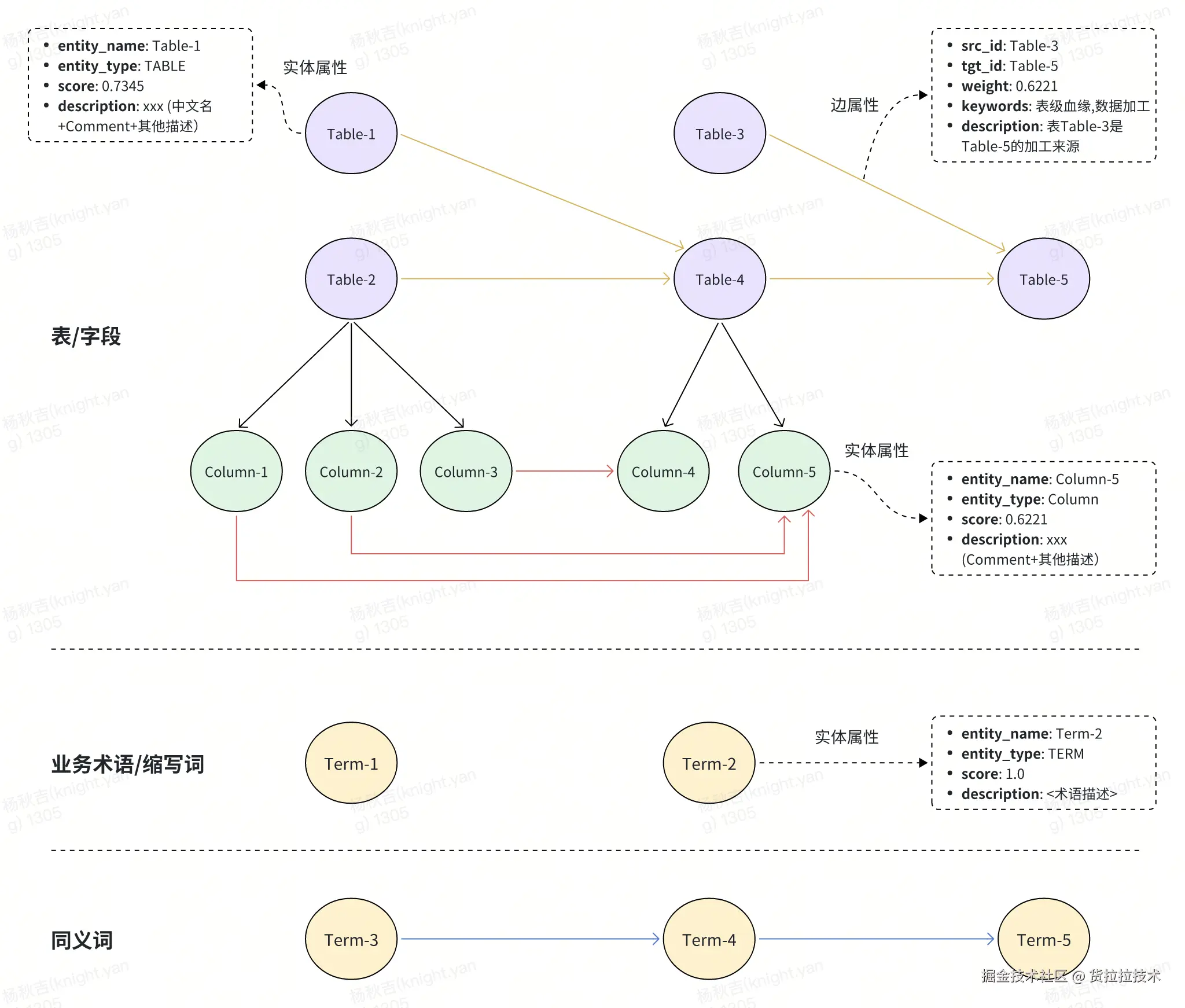
2)图存储设计
GraphRAG知识图谱按三类实体设计:1. 表/字段:以表为核心节点,关联字段及跨表血缘关系,实体含类型、描述等属性;2. 业务术语/缩写词:独立存储术语实体;3. 同义词层:通过边连接同义术语。
整体通过节点属性和关系边,构建结构化知识网络,支撑复杂关联检索。
3)向量存储设计
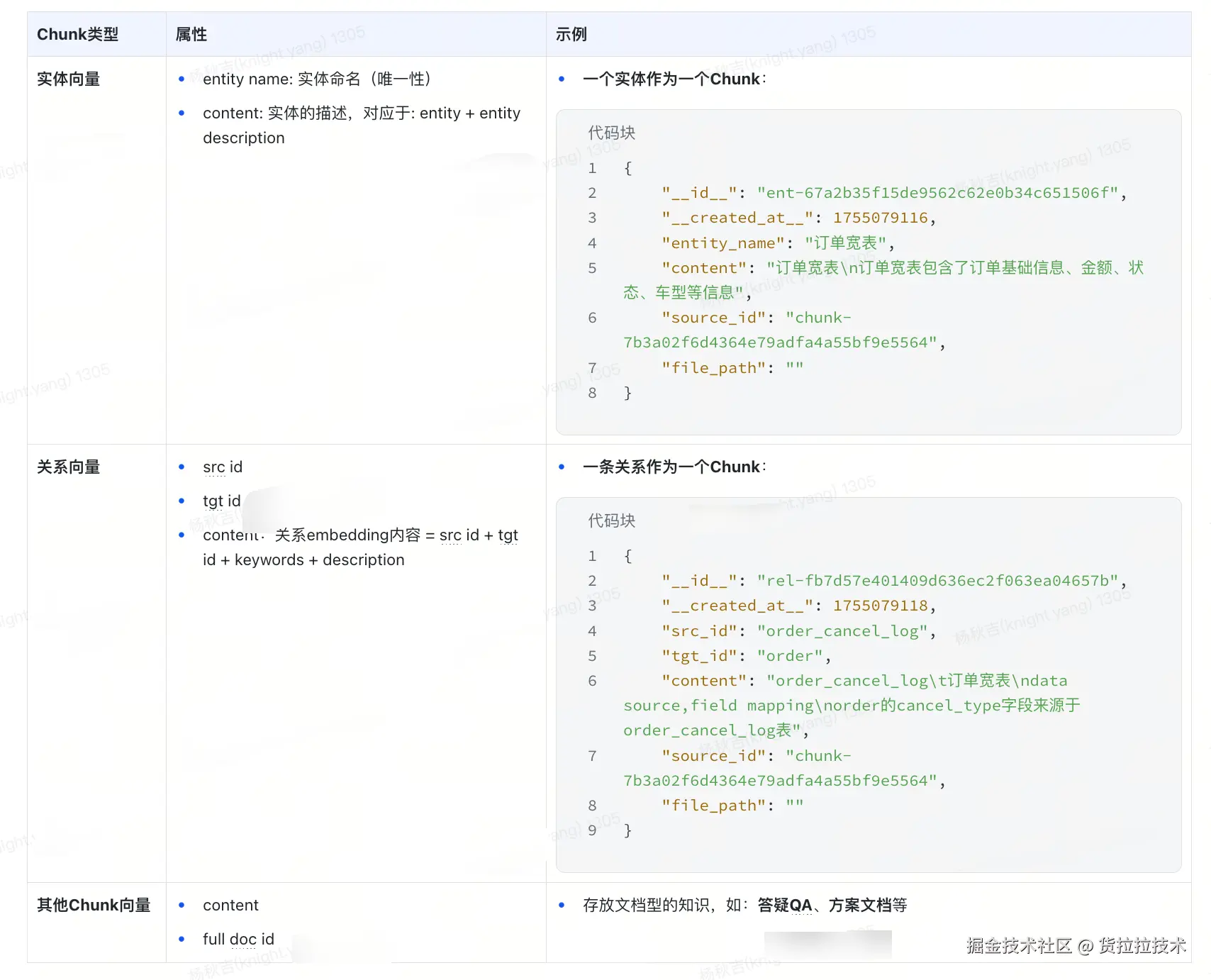
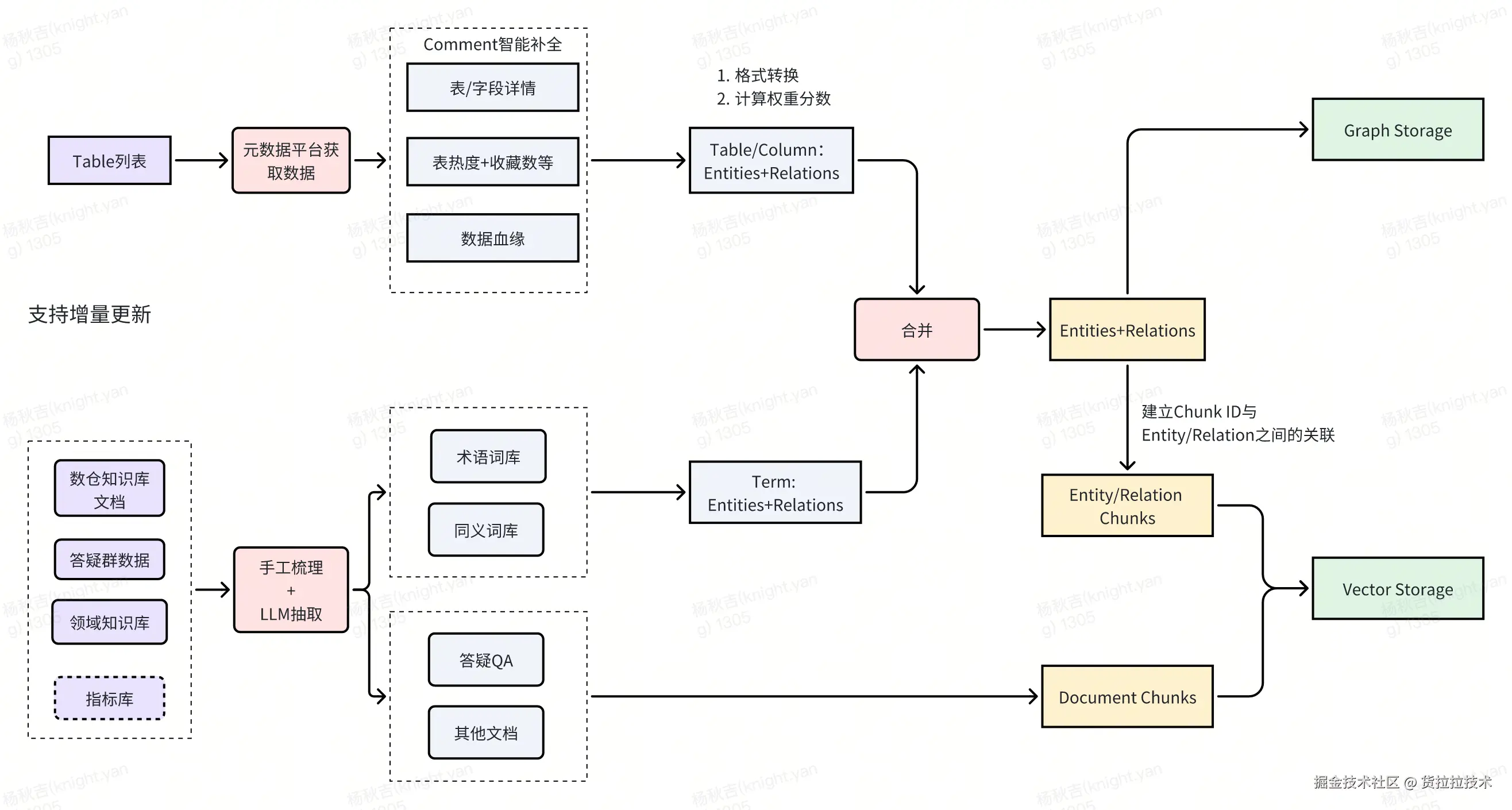
4)索引流程
知识库索引流程为多源知识库的索引构建方案:从Table集合开始、元数据管理平台获取表/字段详情、数据血缘等信息,经格式转换生成表/字段实体关系;同时通过手工梳理+LLM抽取数仓文档、领域知识等,生成术语、问答等实体关系。两类实体关系合并后,存入Graph Storage,并将实体关系与文档块关联存入Vector Storage。
由于每个实体都有唯一的名称,可以作为实体ID,这样就可以以实体ID作为主键,来实现知识索引库的增量更新。
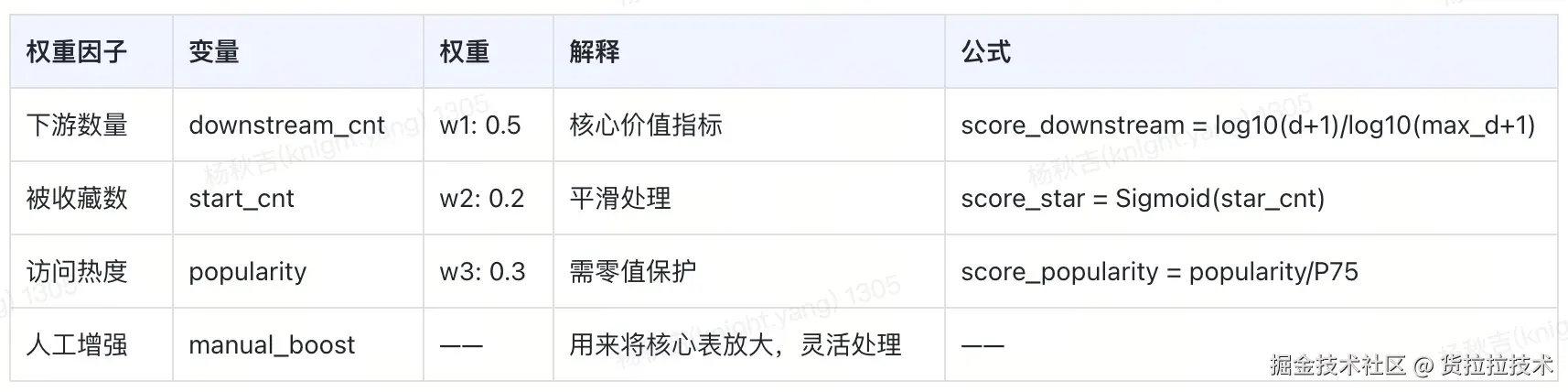
实体权重计算口径:
- 表分数 = manual_boost_1 * ( w1 × score_downstream + w2 × score_popularity + w3 × score_star )
- 字段分数 = manual_boost_2 × (w4 × base_score + w5 × table_factor)
- 术语词汇分数 = 1
各权重因子定义及计算公式如下:
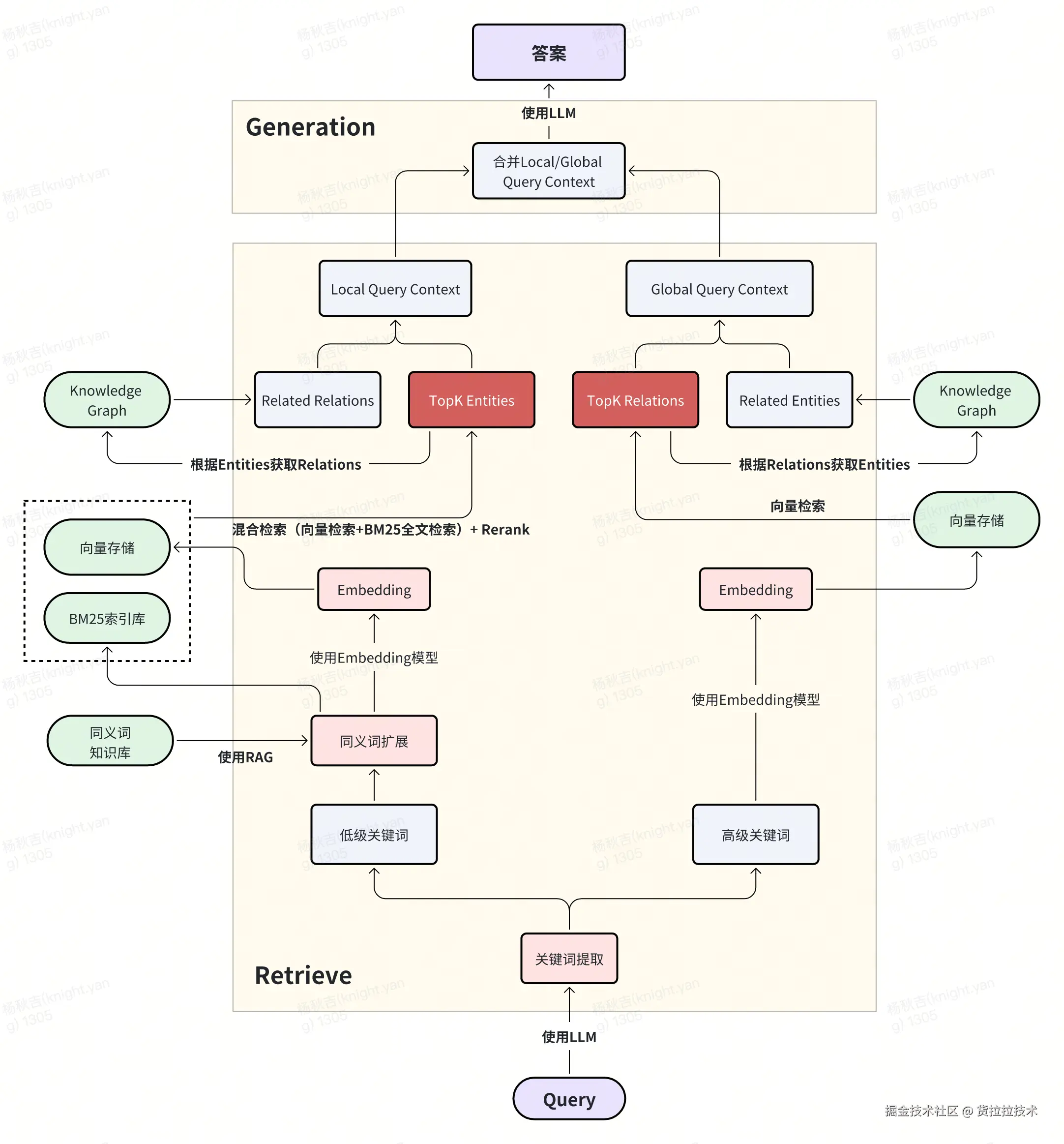
5)检索流程
用户Query经LLM提取高级和低级关键词,低级关键词结合同义词库扩展后,通过混合检索(向量检索+BM25检索)+重排得TopK实体,再关联知识图谱获取相关关系,形成Local Query Context;高级词经Embedding向量检索得TopK关系,关联图谱获相关实体,形成Global Query Context。两类上下文合并后输入LLM生成答案。
3.5 效果
-
问答质量有实质突破:整体准确率从56%提升至78%,其中知识召回率91%、TopK命中率90%、MRR 0.73;
-
业务场景提效明显:AI检索较传统关键词检索的渗透率已到达30%左右,直接为数仓答疑环节节省20%以上时间成本,有效地减少了重复沟通与信息检索耗时。
4. 后续工作
当前GraphRAG的实践已取得预期效果,但仍存在持续探索与优化的空间。接下来,我们将从以下几个方向推进,以进一步提升系统的准确率与用户体验:
-
检索能力升级:更强的混合检索,更准的结果排序
-
引入混合检索机制:将全文检索、标量检索与现有的向量检索结合,构建互补的检索体系,更好地覆盖专业术语、缩写以及长尾查询。
-
优化Rerank:持续优化实体权重模型,并引入更多业务相关指标(例如表重要性、字段使用频次)
-
-
持续完善知识库:打造更丰富的元数据生态
-
增强领域术语体系:使用AI自动发掘业务术语、同义词和数据口径,建设领域词典,解决"叫法不同但意义相同"的检索障碍。
-
智能元数据增强:探索语义扩展,将简短的字段名扩展为具有业务语义的自然语言描述,从而提升向量表示效果。
-
-
向Agentic迈进:探索Agentic RAG
- 具备规划能力:使用Agent的规划能力取代现在的固定工作流模式,优化检索效率和精准度
- 实现多跳推理:让系统能够自动把复杂问题拆分成多个子问题,通过多轮"检索---验证"循环,构建完整的推理链路。
- 增强交互能力:让系统具备"主动提问"的能力,在用户提问模糊或信息不足时主动澄清,从而提升最终回答的可靠性。
5. 结语
从RAG到GraphRAG的探索,最大的体会是:元数据检索,本质上是如何组织好现有的元数据。表、字段与业务术语之间的关联,只靠语义相似度很难稳定命中;把元数据建成图谱,用实体和关系一起召回,才能提升系统的召回率和准确率。在元数据场景里,RAG瓶颈往往不在大模型,而在检索和知识组织。
后续我们还会在混合检索、Rerank和知识库上继续优化,同时探索应用Agentic RAG的可能性。
从RAG到GraphRAG,既是架构升级,也是我们一直在回答的问题:怎么把企业里的数据知识,真正用起来。
如果你也在做元数据检索或GraphRAG,欢迎在评论区聊聊你的实践和踩坑~
关于本文作者
陈元 - 货拉拉RAG平台工程师
刘志鹏 - 货拉拉资深产品经理