结合调研数据,核心比例结论先明确:仅 35% 的用户会主动反馈软件 "慢 / 难用",65% 的用户选择不反馈(含 "默默忍受" 或 "直接卸载") ,且不同场景下比例会有差异,具体拆解如下:
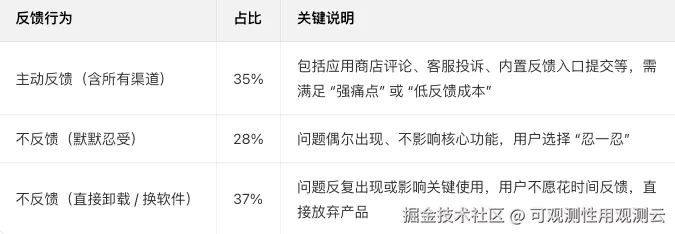
从上边结果来看,当我们加班加点把软件系统(一个 APP 或者一个 Java 微服务或者一个 Web 商城网站)开发好上线后,大部分用户不会主动反馈问题,系统再卡顿、体验再差,也很少会说,只会默默选择不用、卸载或离开。
那么如何解决这个问题呢?
系统 SLO------将 "系统好不好用、用户体验佳不佳" 的模糊感知,转化为可量化、可监控、可告警的 SLO 指标体系,再将 SLO 拆解为落地可测的 KPI,既解决领导对系统价值的量化判断难题,也摆脱 "靠用户反馈发现问题" 的被动局面。
| 名词 | 描述 |
|---|---|
| SLA | 即 Service-Level Agreement,服务等级协议,指系统服务提供者(Provider)对客户(Customer)的服务承诺。您可以对服务商的服务质量 SLA 评分,实时监测服务的达标率 |
| SLI | 即 Service Level Indicator,测量指标,指选择用于衡量系统稳定性的指标。观测云 SLI 支持基于监控器设定一个或多个测量指标 |
| SLO | 即 Service Level Objective,观测云进行 SLA 评分处理的最小单元,是一个时间窗口内 SLI 累积成功数的目标。而我们又经常把 SLO 转化为错误预算,用于计算可容忍的错误数,在每一个检测周期内出现异常事件的时间将在可容错时长中扣除 |
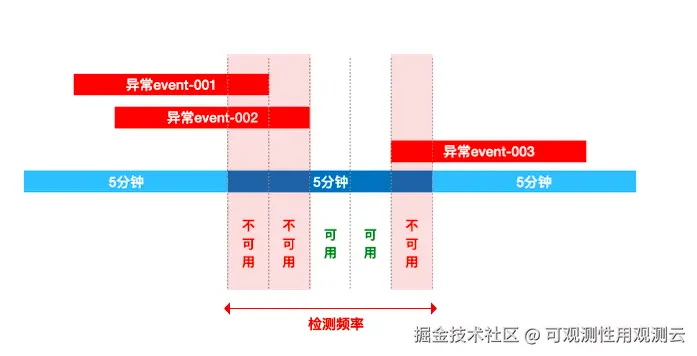
这里 SLO 全生命周期管理(定义、监控、告警、复盘)能力,能完美承接这套体系的落地,实现从 "被动救火" 到 "主动防控" 的转变,通过几个维度讲透如何基于 SLO 做系统量化评估,适配企业内所有业务系统 / 技术系统。
一、核心逻辑:SLO 是桥梁,连接 "用户体验" 与 "技术 KPI"
很多企业的痛点是技术指标与用户体验脱节:技术团队盯着 CPU、QPS 等纯技术指标,却不知道这些指标背后对应什么样的用户体验;领导判断系统好不好用,只能靠 "用户有没有投诉、业务有没有提需求",缺乏客观标准。
- SLO :站在用户 / 业务视角定义的服务等级目标,是 "系统好不好用" 的核心衡量标准(比如 "核心交易接口 99.99% 的请求在 200ms 内响应""页面 99.9% 的加载请求在 1.5s 内完成"),直接对应用户体验;
- KPI :站在技术视角拆解的落地指标,是实现 SLO 的具体技术保障(比如 "接口 99 分位响应耗时≤200ms""服务器 CPU 峰值利用率≤70%"),可通过直接采集监控;
这套体系的核心价值:
- 给领导量化判断依据:无需靠主观感受,打开 SLO 大盘,就能看到每个系统的 SLO 达成率、核心 KPI 达标情况,直接判断系统是否 "好用";
- 变被动为主动:对 SLO/KPI 做实时监控,一旦指标偏离阈值,提前触发告警,技术团队在用户感知到问题前就介入解决,彻底摆脱 "靠用户反馈发现问题" 的被动;
- 技术工作对齐业务价值:技术团队的工作不再是 "为了调优指标而调优",而是围绕 "达成 SLO、提升用户体验" 展开,所有技术优化都有明确的业务目标;
- 问题可归因、优化可验证:的全链路可观测能力(指标、日志、链路、追踪),能在 SLO 未达标时快速定位根因,优化后也能通过 SLO/KPI 的变化,量化验证优化效果。
二、体系搭建核心步骤:从用户视角出发,基于落地
2.1 明确用户视角的核心体验点
先对企业内所有系统做分层分类,明确每个系统的核心用户 (C 端用户 / 业务端用户 / 内部研发 / 运营)和用户最关注的体验点 ------ 这是定义 SLO 的基础,避免 SLO 与用户体验脱节。针对每个系统,梳理用户在使用系统时的核心动作 ,并提炼对应的体验诉求,这是 SLO 的 "用户侧源头"。
示例:
- 电商交易系统(C 端用户):核心动作是 "下单支付、商品查询、页面浏览",体验诉求是 "下单不卡顿、支付不掉线、页面加载快";
- 业务中台系统(业务研发用户):核心动作是 "调用接口、配置参数、查看返回结果",体验诉求是 "接口调用成功、响应快、参数配置生效及时";
- 运营后台(运营用户):核心动作是 "查询数据、导出报表、操作工单",体验诉求是 "数据查询不超时、报表导出快、操作不报错"。
2.2 基于 SLO 模型定义各系统的核心
以下三类 SLO 是的核心能力覆盖范围,无需二次开发,可直接在平台内配置监控、告警、复盘,也是最能反映 "系统好不好用" 的核心维度。
| SLO 类型 | 定义 | 对应用户体验 | 能力支撑 |
|---|---|---|---|
| 可用性 SLO | 统计周期内,系统 / 功能 / 接口可用时长占比(扣除计划内维护) | 系统 "不宕机、能正常访问",是用户体验的基础 | 主机监控、服务监控、心跳检测,精准统计可用 / 不可用时长 |
| 性能 SLO | 统计周期内,符合用户体验的请求响应占比(如 "200ms 内响应的请求占比") | 系统 "不卡顿、加载快",是用户体验的核心 | 接口监控、链路追踪、前端性能监控,按分位值 / 固定阈值统计性能达标请求占比 |
| 成功率 SLO | 统计周期内,系统 / 接口 / 功能成功执行的请求占比(如 "交易成功请求占比""页面加载成功占比") | 系统 "操作不报错、执行有结果",是用户体验的关键 | 日志分析、接口监控、业务埋点,精准统计成功 / 失败请求数 |
2.3 核心 SLO-KPI 拆解模型(基于采集能力,可直接复用)
结合的全维度可观测指标库 ,将 3 类核心 SLO 拆解为通用 KPI,不同系统可根据实际情况微调,所有 KPI 均可直接配置监控。
| 核心 SLO 类型 | 核心拆解 KPI | KPI 定义 | 采集方式 | 通用目标值(核心系统 / 一般系统) |
|---|---|---|---|---|
| 可用性 SLO | 系统服务运行率 | 统计周期内,系统核心服务正常运行时长 / 统计总时长 | 服务监控:采集服务启动 / 停止状态、心跳检测结果 | 核心≥99.99% / 一般≥99.9% |
| 可用性 SLO | 主机在线率 | 统计周期内,系统部署主机正常在线时长 / 统计总时长 | 主机监控:采集主机 CPU、内存、网络心跳,判定在线状态 | 核心≥99.99% / 一般≥99.9% |
| 性能 SLO | 接口 99 分位响应耗时 | 系统核心接口请求响应耗时的 99 分位值 | 接口监控 / 链路追踪:采集接口每次请求的响应耗时,计算分位值 | 核心≤200ms / 一般≤500ms |
| 性能 SLO | 页面首屏加载耗时 | 前端页面首屏内容渲染完成的平均耗时 | 前端性能监控:埋点采集页面加载各阶段耗时 | 核心≤1.5s(移动端)/ 一般≤3s |
| 性能 SLO | 数据库 99 分位读写耗时 | 核心数据库 SELECT/INSERT 操作的 99 分位耗时 | 数据库监控:采集数据库执行语句的耗时 | 核心≤50ms(读)/≤100ms(写) |
| 成功率 SLO | 核心接口成功率 | 统计周期内,核心接口成功请求数 / 总请求数 | 接口监控:按返回码(200 为成功)统计 | 核心≥99.99% / 一般≥99.9% |
| 成功率 SLO | 前端页面加载成功率 | 统计周期内,页面成功加载次数 / 总请求次数 | 前端监控 / 日志分析:统计页面加载失败(4xx/5xx)次数 | 核心≥99.9% / 一般≥99% |
| 成功率 SLO | 业务操作成功率 | 统计周期内,核心业务操作(交易 / 下单 / 导出)成功次数 / 总次数 | 业务埋点 / 日志分析:按业务日志关键字("成功 / 失败")统计 | 核心≥99.99% / 一般≥99.9% |
2.4 配置步骤
2.4.1 基础配置:确保能采集所有 KPI 数据
先完成数据采集接入,确保所有拆解的 KPI 都能被自动采集,无数据盲区 ------ 支持多维度采集方式,适配所有技术栈,操作简单:
- 基础设施采集:通过 Agent 接入主机、容器、云服务器,采集 CPU、内存、磁盘等主机 KPI;
- 服务 / 接口采集:通过 SDK/APM 接入微服务、HTTP 接口,采集接口响应耗时、成功率等 KPI;
- 前端采集:通过前端埋点 SDK,接入 H5/APP/小程序,采集页面加载耗时、成功率等 KPI;
- 中间件 / 数据库采集:通过专属插件,接入 Redis、MQ、MySQL、PostgreSQL,采集缓存命中率、数据库读写耗时等 KPI;
- 业务采集:通过自定义埋点 / 日志采集,接入业务操作成功率等自定义 KPI(支持日志关键字提取、自定义指标上报)。
2.4.2 核心配置:在定义 SLO,关联 KPI 指标
SLO 模块 支持自定义 SLO 规则、关联指标、自动计算 SLO 达成率,直接对接前面定义的 SLO,步骤如下:
- 登录平台,进入「SLO 管理」→「新建 SLO」;
- 填写 SLO 基本信息:名称、所属系统、SLO 类型(可用性 / 性能 / 成功率)、目标值、统计周期;
- 关联 KPI 指标:从指标库中选择已采集的 KPI,设置 SLO 计算规则(如 "成功率 SLO = 接口成功请求数 / 总请求数,排除压测流量标签");
- 设置SLO 告警阈值:建议设置 "预警阈值(如 99.9%)+ 告警阈值(如 99.8%)",提前触发预警,避免 SLO 达标率跌破目标;
- 保存并启用 SLO:将自动实时计算 SLO 达成率,关联的 KPI 指标发生变化时,SLO 达成率同步更新。
2.4.3 关键配置:设置分级告警,摆脱被动响应
基于的告警模块 ,为 SLO/KPI 设置分级告警规则 ,确保异常在用户感知前被发现,技术团队主动介入,核心是 "按 SLO 重要性分级,匹配不同的告警方式和响应时效":
| 告警等级 | 触发条件 | 告警方式(支持) | 响应时效 | 责任主体 |
|---|---|---|---|---|
| P0(紧急) | 核心系统核心 SLO 达成率跌破目标值(如 99.99%→99.5%),或核心 KPI 严重异常(如接口成功率骤降) | 电话 + 短信 + 企业微信 / 钉钉 @所有人 + 平台红字告警 | 5 分钟内响应,30 分钟内解决 | 技术负责人 + 核心研发 + 运维 |
| P1(重要) | 核心系统辅助 SLO/KPI 异常,或重要系统核心 SLO 达成率跌破预警阈值 | 企业微信 / 钉钉 @项目组 + 平台告警 | 15 分钟内响应,1 小时内解决 | 项目研发 + 运维 |
| P2(一般) | 重要系统辅助 SLO/KPI 异常,或一般系统 SLO/KPI 异常 | 企业微信 / 钉钉单聊通知责任人 + 平台告警 | 30 分钟内响应,2 小时内解决 | 对应模块研发 / 运维 |
2.4.4 最终呈现:打造可视化大盘,一键判断系统好坏
基于的可视化模块 ,打造3 级可视化大盘 ,满足领导、技术管理、一线研发 的不同查看需求,大盘支持实时刷新、钻取分析、多维度筛选,让 "系统好不好用" 一目了然。
三、AI 系统 SLO 落地案例
以下结合 AI 系统的实操案例,详细说明大盘搭建与 SLO 配置的完整流程(该案例已落地验证,可直接复用配置逻辑):
3.1 前置准备:统一规范与标签体系
为确保监控与 SLO 的统一性和可追溯性,首先建立标准化的标签与命名规范:
- 全局标签 :为 AI系统 配置专属全局标签(如
df_label=AI系统),关联service(服务名)、http_route(接口路由)、pod_name(容器名)等维度,便于指标筛选与聚合; - 命名规范:所有监控器、SLO、看板均以 "项目名开头",确保辨识度,例如 "智慧供应链服务请求错误率大于 80%""AI系统 "。
3.2 步骤 1:创建核心监控器(SLI 数据来源)
监控器是 SLO 的基础数据支撑(即 SLI,服务等级指标),需针对系统核心 KPI 配置监控规则,具体要求如下:
-
监控器配置维度:覆盖错误率、响应时间、请求量、资源使用率等核心场景,例如:
- 服务请求错误率监控:AI系统 请求错误率大于 80%(检测频率 1 分钟,检测区间最近 5 分钟);
- 响应时间监控:AI系统 平均响应时间大于 3 秒、P95 响应时间过长、响应时间突增;
- 业务异常监控:代理 24 小时未发货、请求数突增、请求失败率突增;
-
配置注意事项:避免选择高基数字段作为检测维度,防止告警过于宽松引发频繁告警;检测频率与区间可自定义(如 20m、2h、1d),核心指标建议按分钟级检测。
3.3 步骤 2:创建系统专属 SLO
基于已配置的监控器(SLI),创建项目组专属 SLO,实现 "监控指标→SLO 目标" 的关联:
- SLO 创建规则:每个项目组对应 1 个核心 SLO,直接关联第一步创建的监控告警(如错误率监控、响应时间监控),无需额外重复配置数据来源;
- SLO 命名格式:统一为 "xxxxSLO",例如 "AI系统 SLO",目标值设置为 95%(结合业务实际设定,全年 SLA 目标 99.7427%);
- 统计配置:采用最近 5 分钟作为检测区间,与监控器检测频率保持一致,确保数据同步性。
3.4 步骤 3:搭建三级可视化大盘
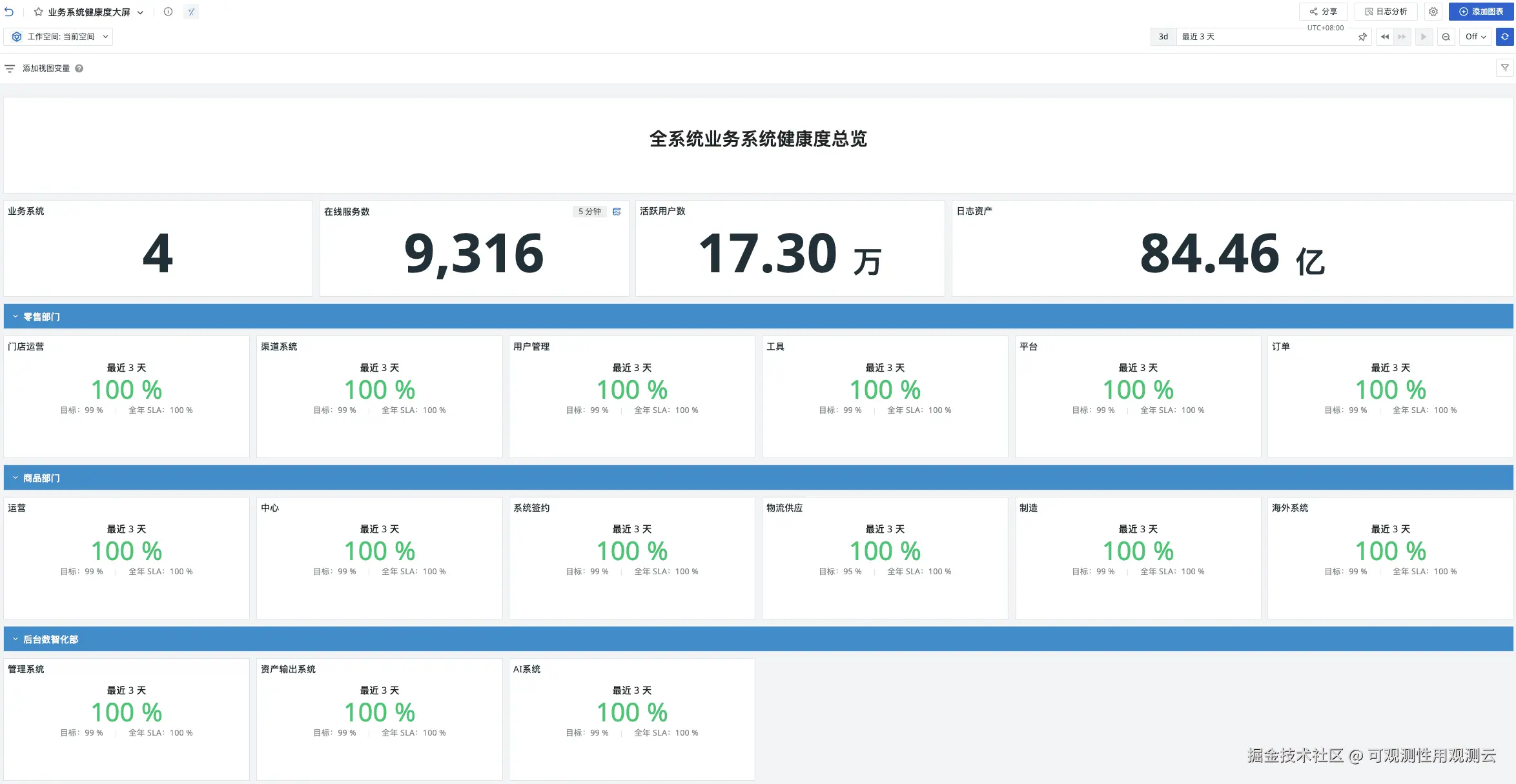
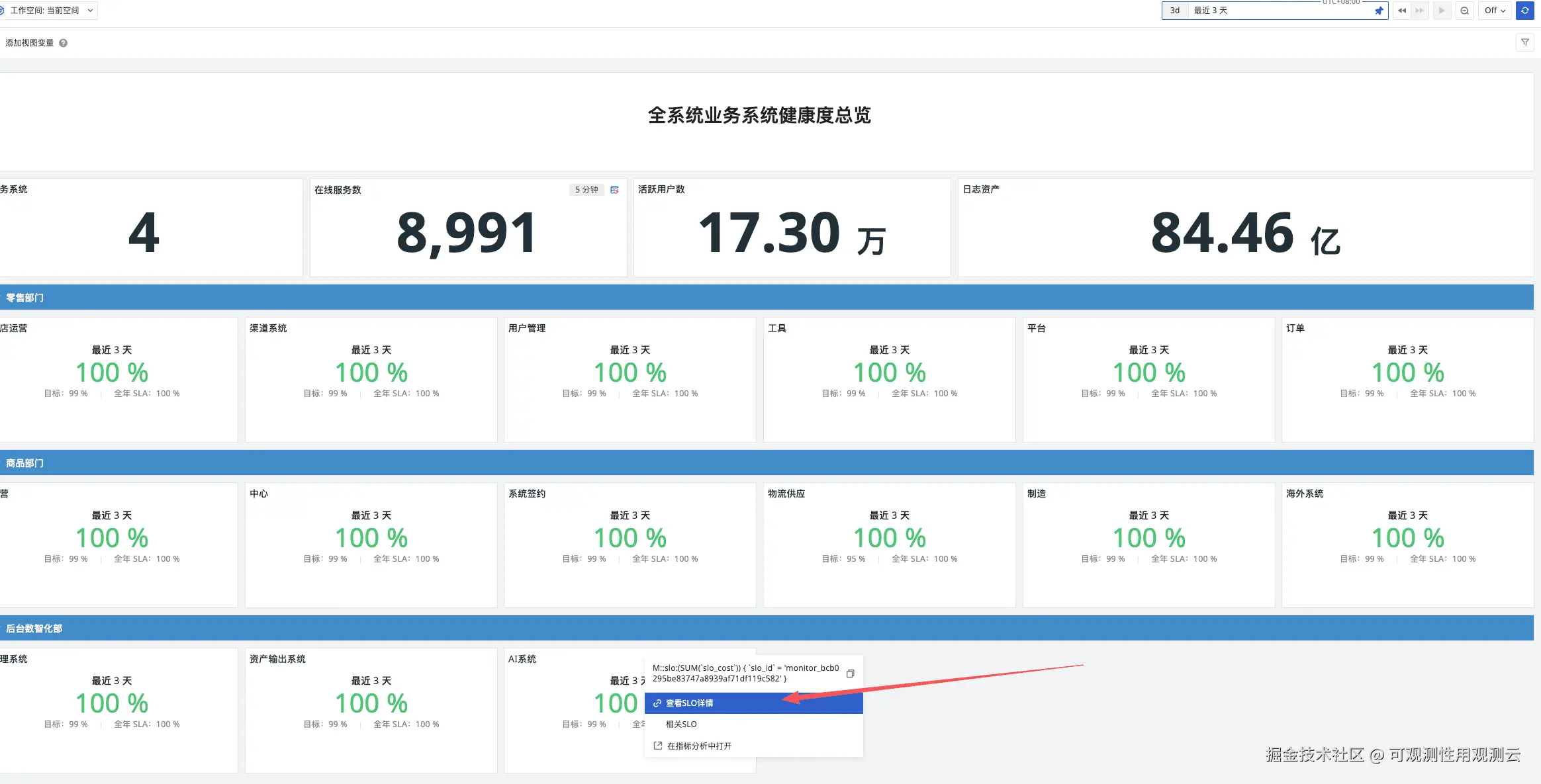
3.4.1 企业级总览大盘:xxx系统健康度大屏
- 核心功能:展示全公司所有系统的 SLO 达成率总览,包含 AI系统 在内的 17 个系统健康度数据(如 SLO 达成率、告警次数、请求量),核心指标(如 100% 达成率)突出显示,支持领导快速掌握全局状态;
- 配置要点:将 AI系统 纳入总览大盘,关联 "最近 5 分钟""全年 SLA" 两个时间维度,直观展示短期表现与长期稳定性(案例中该系统全年 SLA 达 99.7427%)。
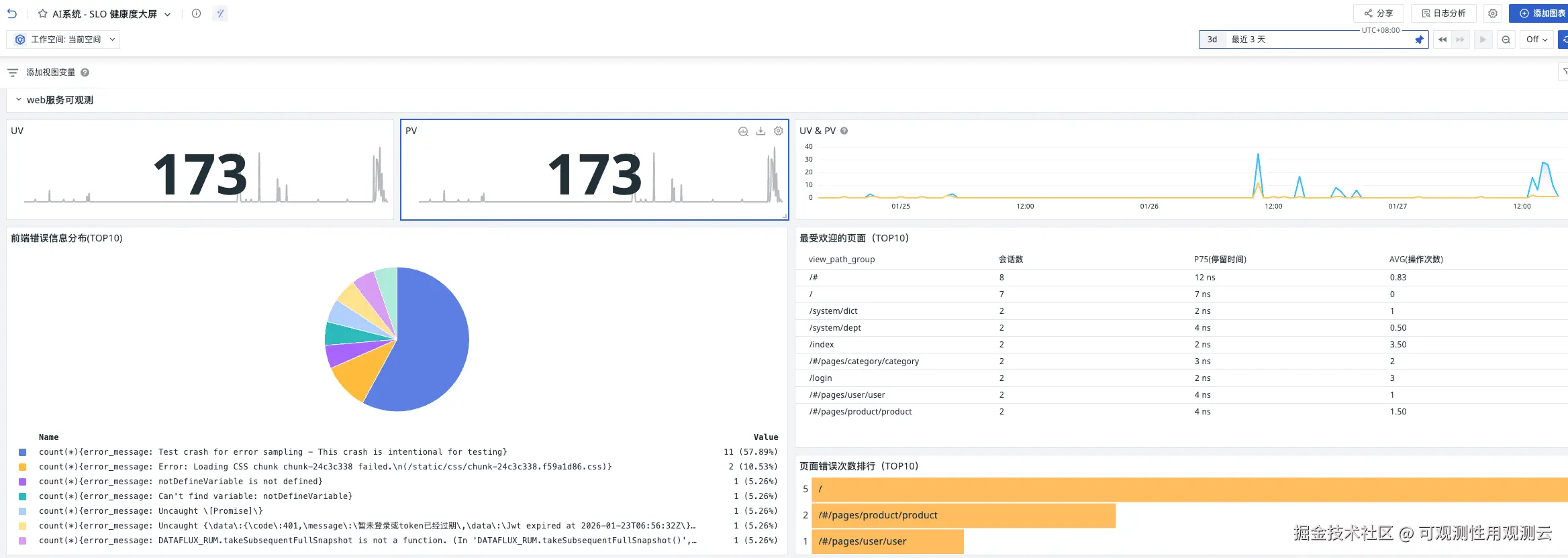
3.4.2 系统级详情大盘:AI系统 - SLO 健康度大屏
通过克隆基础看板并自定义修改,打造项目专属详情页:
- 视图变量修改 :将看板的视图变量替换为 AI系统 的专属信息(如
app_id、project); - 标题与内容规范:标题统一格式为 "大屏详情 - xxxx-SLO"(例:大屏详情 - AI系统 - SLO);
- 核心展示内容 :最近 5 分钟 SLO 达成率、全年 SLA、告警事件列表(关联
df_label=AI系统标签)、核心 KPI 趋势图(错误率、响应时间、请求量); - 交互配置:支持分页查看告警事件(默认 50 条),显示当前查询的起止时间,便于追溯异常时段。
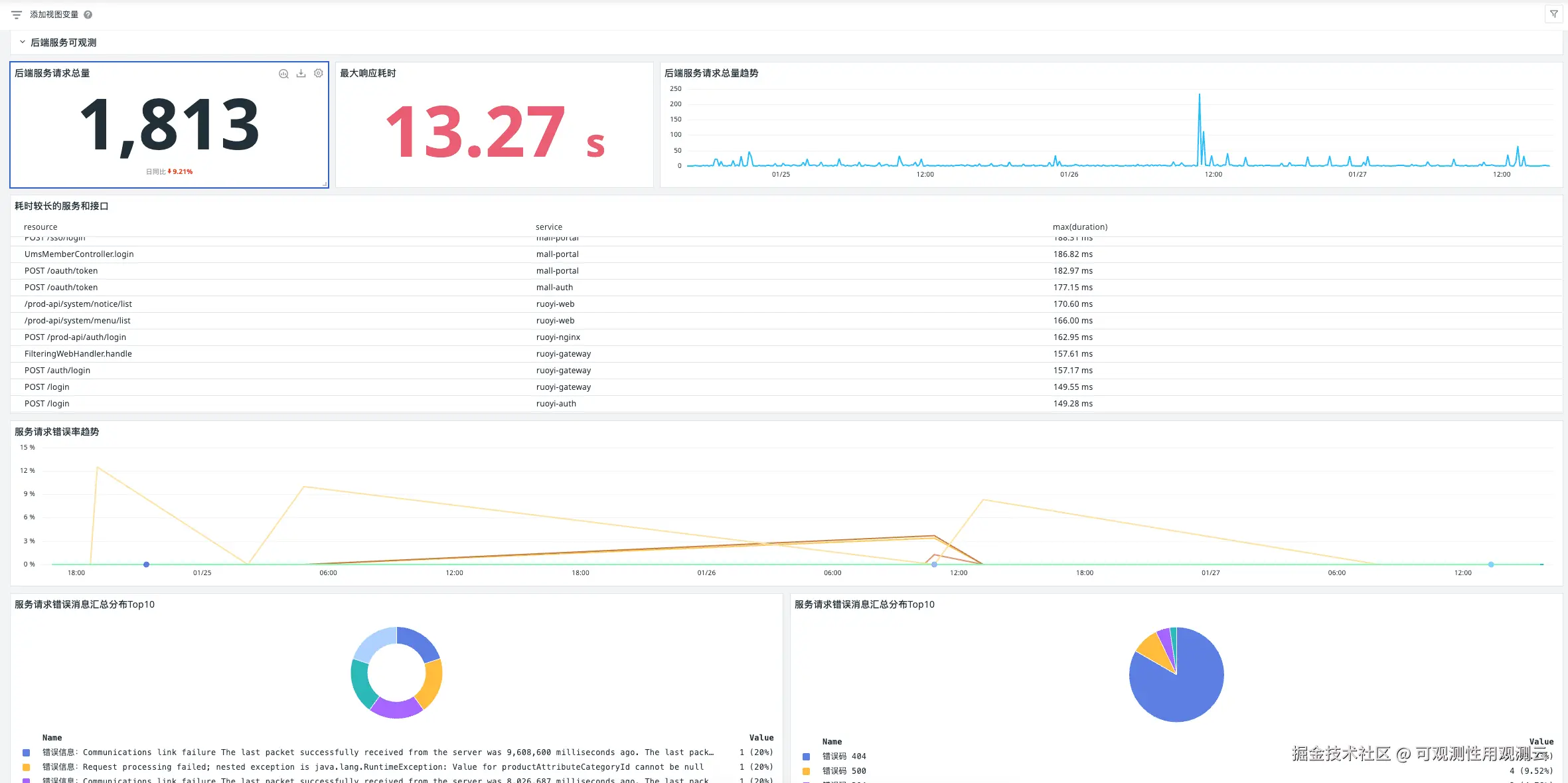
3.4.3 跳转链路配置
建立 "总览大盘→详情大盘" 的跳转链接:在《xxx系统健康度大屏》中,为 AI系统 的 SLO 指标配置跳转规则,点击后直接进入该系统的 SLO 详情看板,实现 "全局→局部" 的快速钻取。
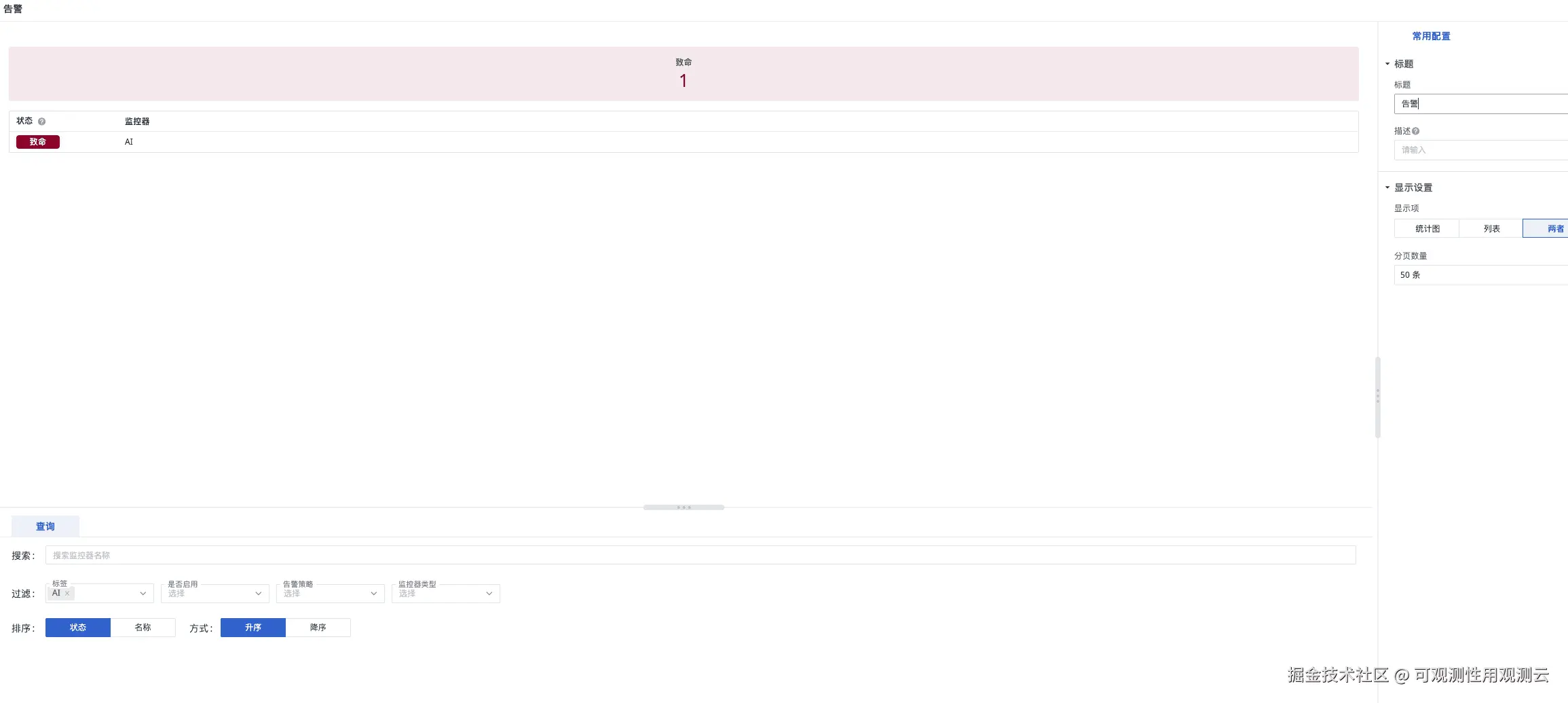
3.5 步骤 4:告警与 SLI 关联优化
- 告警 SLI 适配 :修改详情看板中告警模块的
df_label为系统全局标签(AI系统),确保告警事件仅展示当前系统相关内容,避免跨系统干扰; - 静默与抑制配置:结合的静默管理、告警策略管理功能,设置告警抑制规则,避免同一根因引发的告警风暴(如接口超时导致的错误率告警与响应时间告警,仅触发 1 条核心告警)。
3.6 案例落地效果
- 领导视角:通过《AI 系统健康度大屏》,1 秒查看 AI系统 的 SLO 达成率(如 100%)与全年 SLA,无需关注技术细节即可判断系统是否 "好用";
- 技术视角:通过详情看板,实时监控错误率、响应时间等核心指标,结合告警快速定位异常(如请求错误率突增),在用户反馈前介入解决;
- 管理视角:统一的命名与标签体系,便于跨项目对比与批量管理,17 个系统的健康度数据集中展示,简化运维管理成本。
3.7 大盘层级与核心展示内容
| 大盘层级 | 面向人群 | 核心展示内容(通用模板 +案例适配) |
|---|---|---|
| 企业级总览大盘 | 领导 / 技术负责人 | 所有系统 SLO 达成率、告警总览、Top3 异常系统 案例中展示 17 个系统的健康度数据,核心系统 SLO 达成率突出显示 |
| 系统级详情大盘 | 项目负责人 / 技术管理 | 单个系统 SLO 达成率、核心 KPI 趋势、告警记录、链路拓扑;案例中包含 AI系统 的错误率、响应时间、业务异常等维度 |
| 模块 / 接口级大盘 | 一线研发 / 运维 | 具体接口 KPI 实时数据、日志详情、链路追踪;案例中可钻取到单个接口的错误日志、Pod 运行状态 |
四、总结:基于 SLO,让系统评估有标准、问题响应变主动
基于 SLO 构建的系统量化评估体系,本质是用的技术能力,解决 "系统好不好用无法量化、问题发现靠用户反馈" 的企业痛点,核心价值体现在三个方面:
- 给领导的量化判断依据:的 SLO 总览大盘,让领导无需靠主观感受,一键掌握所有系统的状态,SLO 达成率高 = 系统好用、用户体验好,决策更有依据;
- 技术团队的工作方向标:所有技术工作都围绕 "达成 SLO、提升用户体验" 展开,技术优化不再是 "无的放矢",而是有明确的业务目标和用户价值;
- 从被动救火到主动防控:的实时监控、分级告警能力,让技术团队在用户感知到问题前就介入解决,彻底摆脱 "靠用户反馈发现问题" 的被动局面,提升用户体验的同时,也降低了业务损失。
后续的核心工作,就是按步骤落地配置,配套保障措施,持续复盘优化,让 SLO-KPI 体系成为企业评估系统、优化系统的 "标准工具",让每个系统的 "好用与否",都有明确的量化答案。