https://github.com/myshell-ai/MeloTTS?tab=readme-ov-file
git clone https://github.com/myshell-ai/MeloTTS.git
cd MeloTTS
pip install -e .
python -m unidic download
from melo.api import TTS
# Speed is adjustable
speed = 1.0
device = 'cpu' # or cuda:0
text = "我最近在学习machine learning,希望能够在未来的artificial intelligence领域有所建树。"
model = TTS(language='ZH', device=device)
speaker_ids = model.hps.data.spk2id
output_path = 'zh.wav'
model.tts_to_file(text, speaker_ids['ZH'], output_path, speed=speed)他会自己下载模型 他有本地设置参数 但是我设置了 他也还需要其他的一些模型
#coding=utf-8
from melo.api import TTS
# Speed is adjustable
speed = 1.0
device = 'cpu' # or cuda:0
text = "更绝的是,当萧希希问起董事长女儿时,张浩竟然说那姑娘追了他四十五年,自己没答应,因为人长得太磕碜!这话让萧希希彻底怒了,她决定好好陪这个傻小子玩玩。可张浩还不知道,他骂得最狠的那个"丑姑娘",此刻就坐在他对面!这场身份悬殊的相遇,到底会擦出怎样的火花?张浩能发现眼前这个"麦当娜"的真实身份吗?"
model = TTS(language='ZH', device=device)
speaker_ids = model.hps.data.spk2id
output_path = 'zh.wav'
model.tts_to_file(text, speaker_ids['ZH'], output_path)
import soundfile as sf
au,sr = sf.read(output_path)
au = au * 1.5
sf.write('123.wav',au,sr)会报错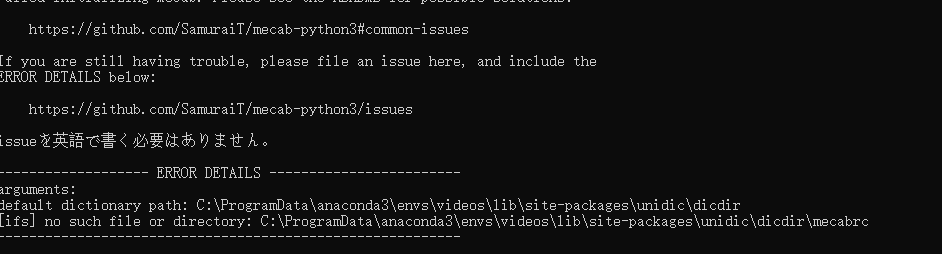
安装完整版
pip install unidic
下载词典(这一步需要联网,可能会慢)
python -m unidic download
必须开着代理才能用
所以
我的解决办法是 设置离线变量 并且在模型的时候需要配置path
我这里直接连接的软链接 huggingface-cli下载可以禁止软链接
model = TTS(language='ZH', device=device,use_hf=False,ckpt_path=r'C:\Users\Administrator\.cache\huggingface\hub\models--myshell-ai--MeloTTS-Chinese\snapshots\af5d207a364ea4208c6f589c89f57f88414bdd16\checkpoint.pth',config_path=r'C:\Users\Administrator\.cache\huggingface\hub\models--myshell-ai--MeloTTS-Chinese\snapshots\af5d207a364ea4208c6f589c89f57f88414bdd16\config.json')
#coding=utf-8
import os
# 设置所有已知的离线相关环境变量
os.environ['HF_HUB_OFFLINE'] = '1'
# os.environ['TRANSFORMERS_OFFLINE'] = '1'
# os.environ['HF_DATASETS_OFFLINE'] = '1'
# 如果你之前设置了 HF_ENDPOINT,可以保留,但离线模式开启后它应该不会生效
# os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from melo.api import TTS解决办法
大模型日常:支持中英混合及多语言文生语音的MeloTTS本地部署-CSDN博客
出现这个问题 就去删除掉重新下 或者执行这两个命令看看是不是提示已经下载好了的
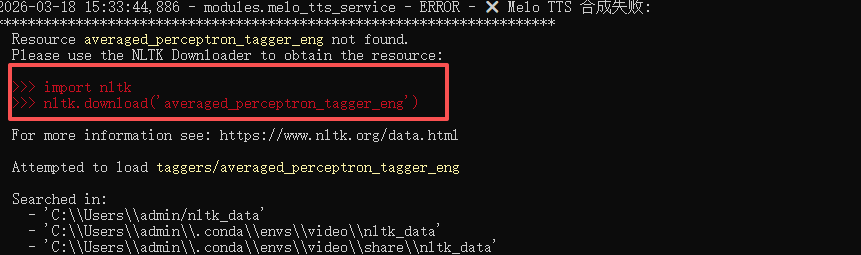
主要问题就是没下载这个模型

你或者直接运行这个命令下载这个模型
from melo.api import TTS
# Speed is adjustable
speed = 1.0
device = 'cpu' # or cuda:0
text = "我最近在学习machine learning,希望能够在未来的artificial intelligence领域有所建树。"
model = TTS(language='ZH', device=device)
speaker_ids = model.hps.data.spk2id
output_path = 'zh.wav'
model.tts_to_file(text, speaker_ids['ZH'], output_path, speed=speed)有时候这上面也还有一个目录 hub下面的删除掉