资料来源:小林coding:https://www.xiaolincoding.com/
TCP 模型分几层
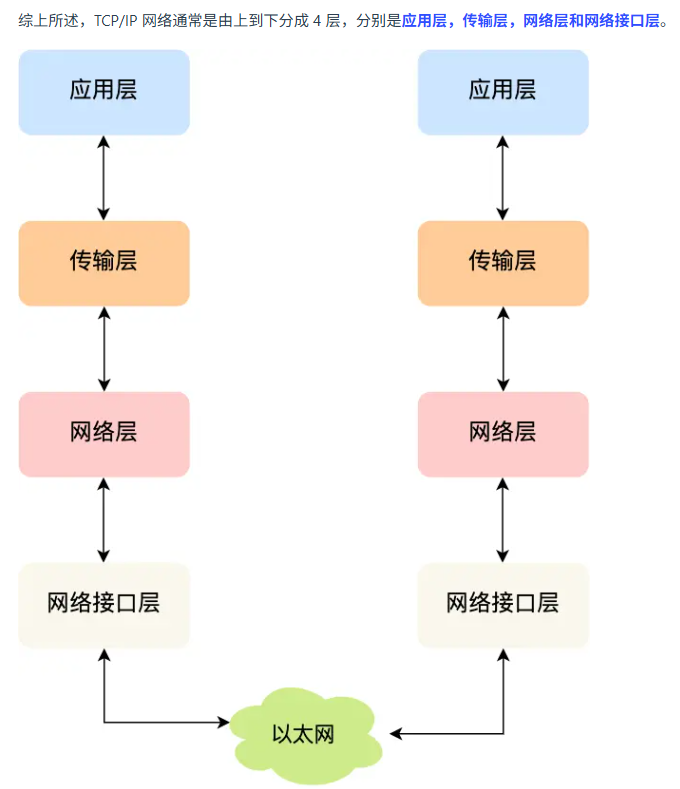
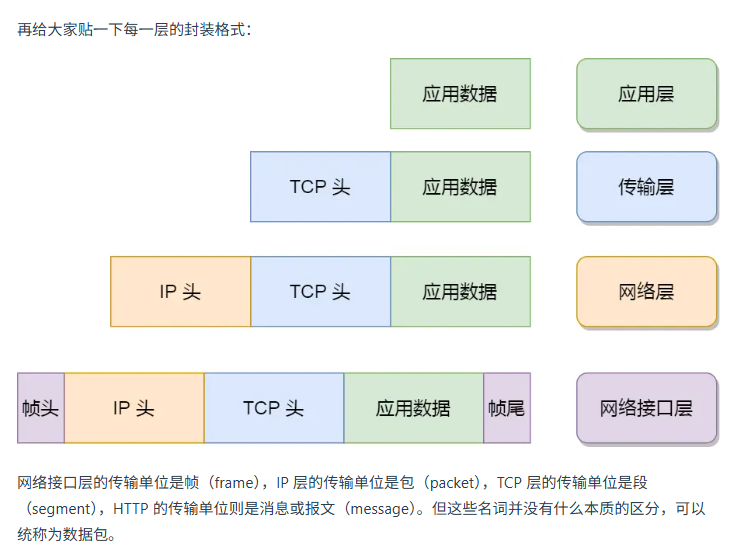
TCP 协议分成应用层,运输层,网络层,网络接口层。其中应用层是工作在用户态的,剩下三层都是工作在内核态的。
应用层
应用层采用的协议是 HTTP ,FPT,DNS 等协议。
传输层
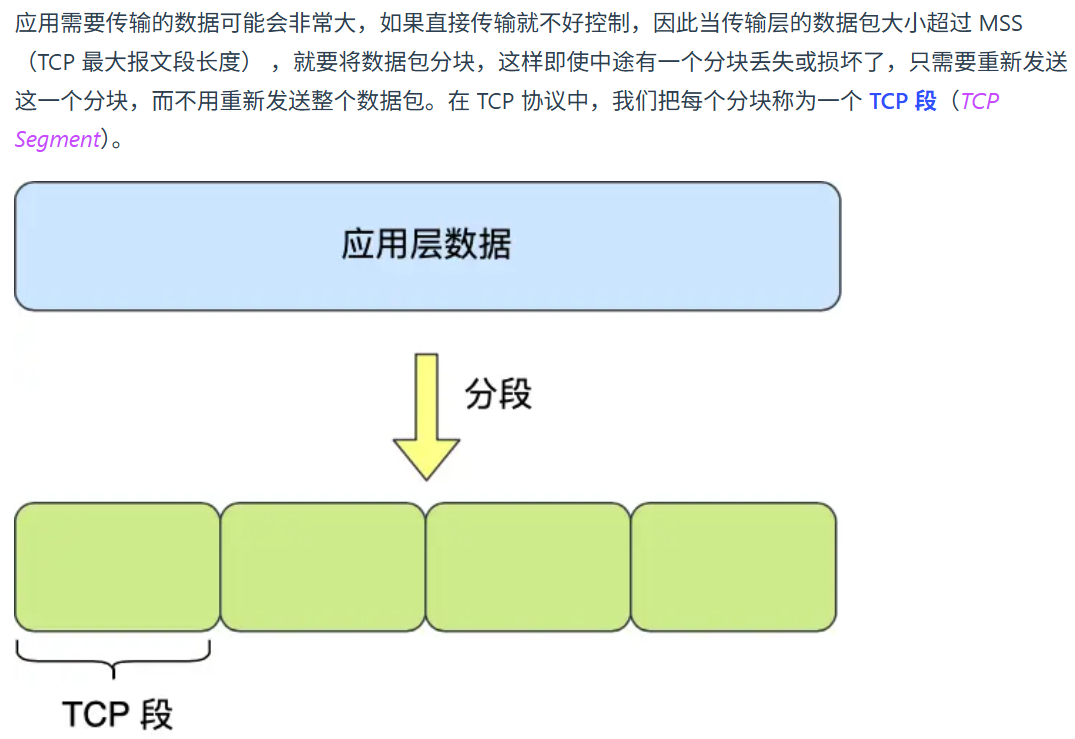
传输层最重要的就是 TCP 和 UDP 两个协议。UDP 将消息打包在一起发送,不像 TCP 是基于字节流的。TCP 有许多特性如流量控制,超时重传,拥塞控制,这样能更加可靠地传输数据。相比之下 UDP 就没有那么可靠。
网络层
网络层主要就是 IP 协议。
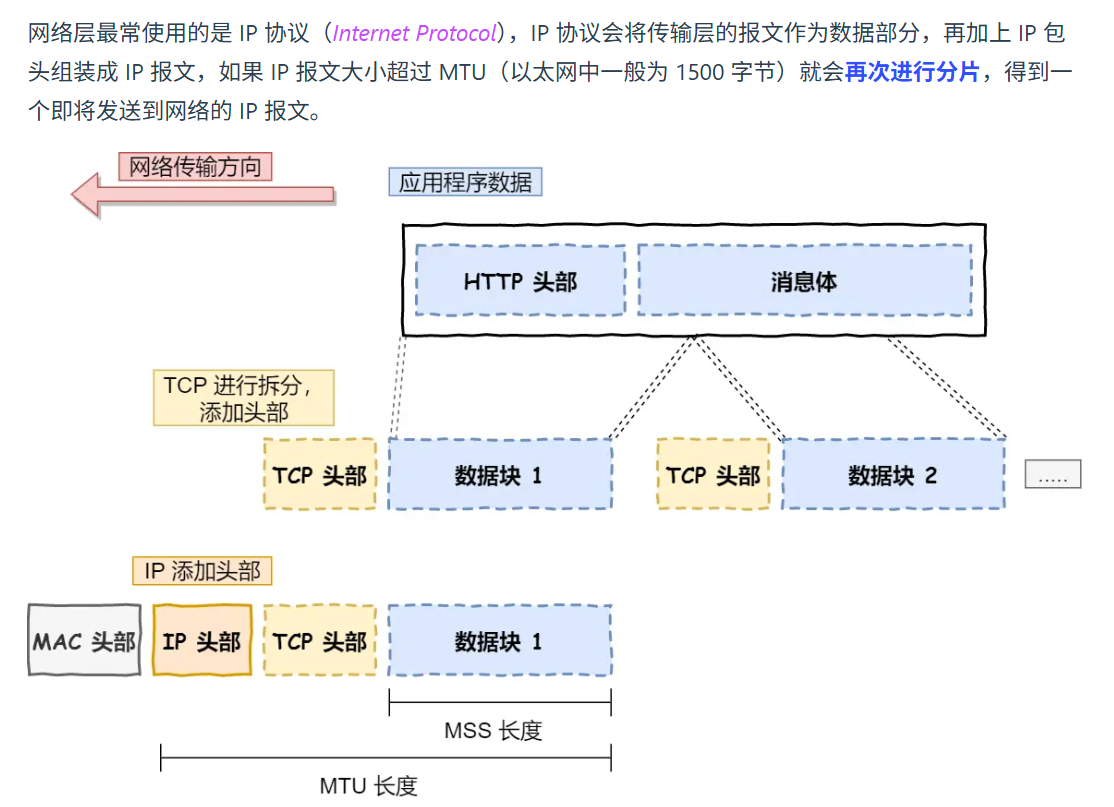
用 IP 地址为设备进行编号,IP 地址分两部分,第一部分是网络号,第二部分是主机号。网络号标记目标设备属于哪个子网,主机号标注是子网下的哪个主机。可以配合子网掩码按位与来获得目标地址。
键入网址到网址显示发生了什么
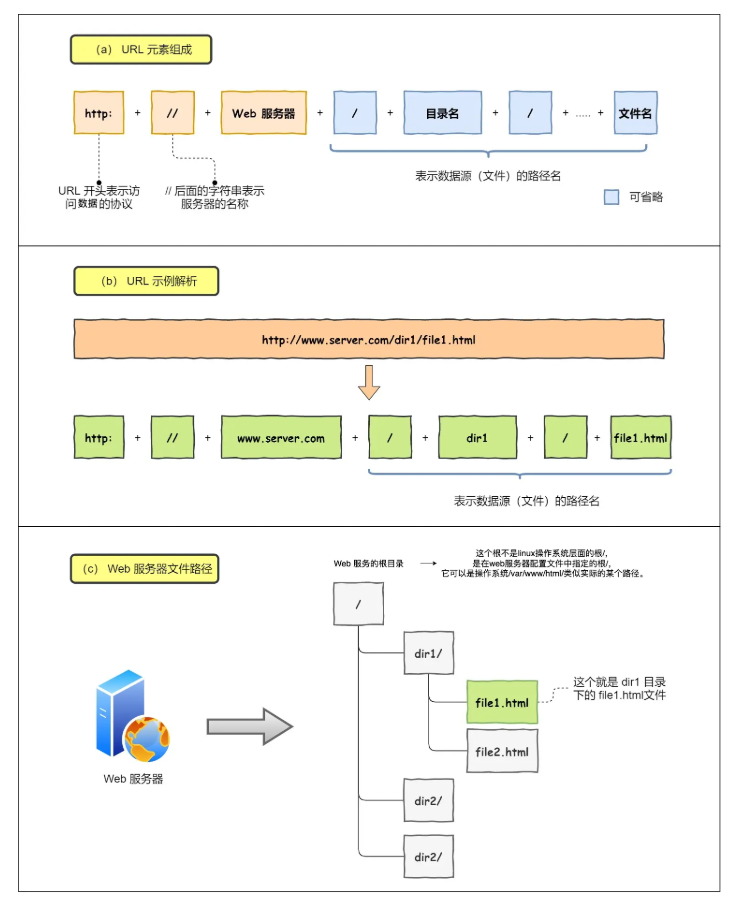
第一步:解析 URL
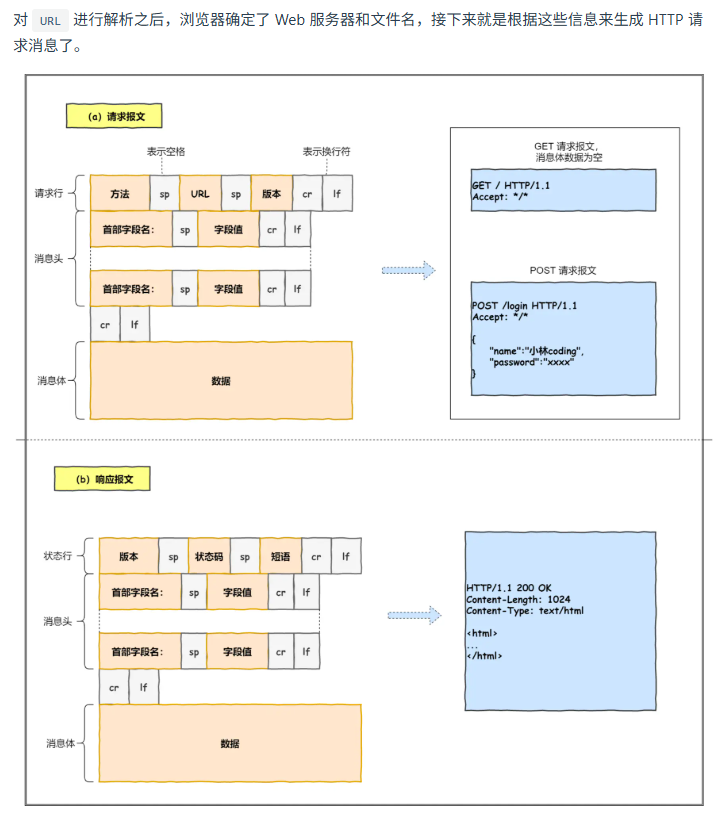
第二步:生成 HTTP 请求
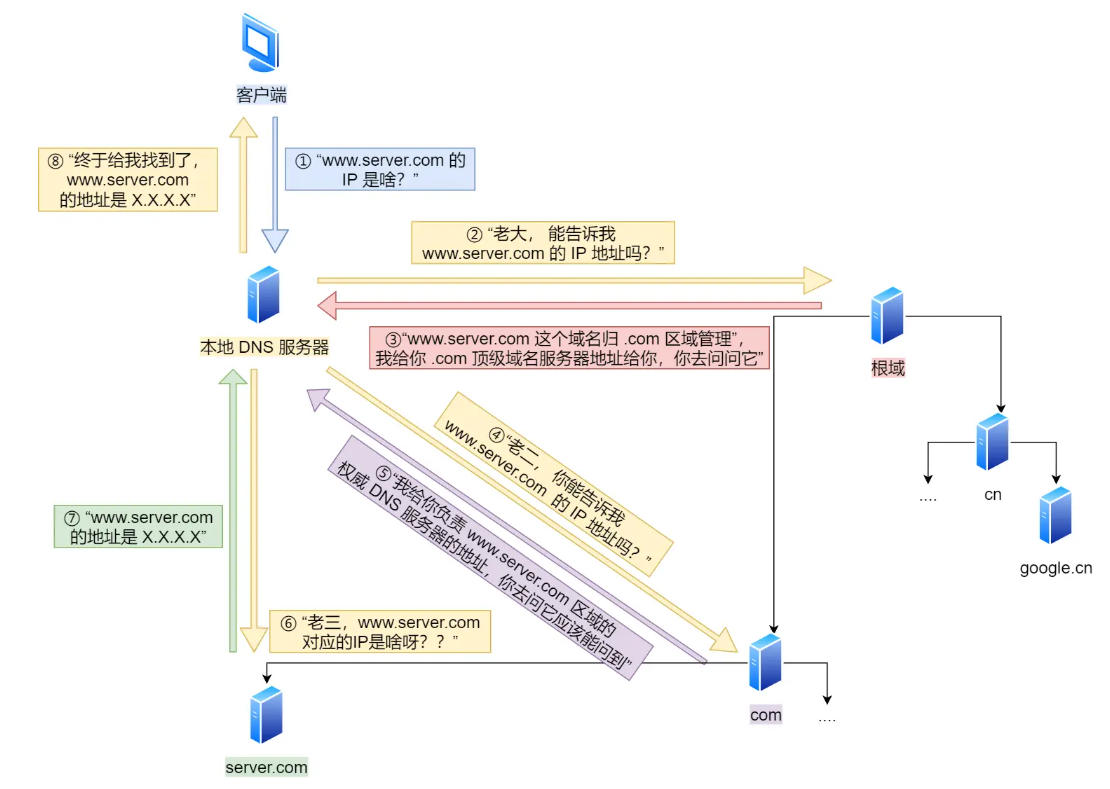
第三步:根据 URL 中的网址去 DNS 服务器中查找对应的 IP 地址
第四步:建立 TCP 连接进行发送
TCP 三次握手建立连接。
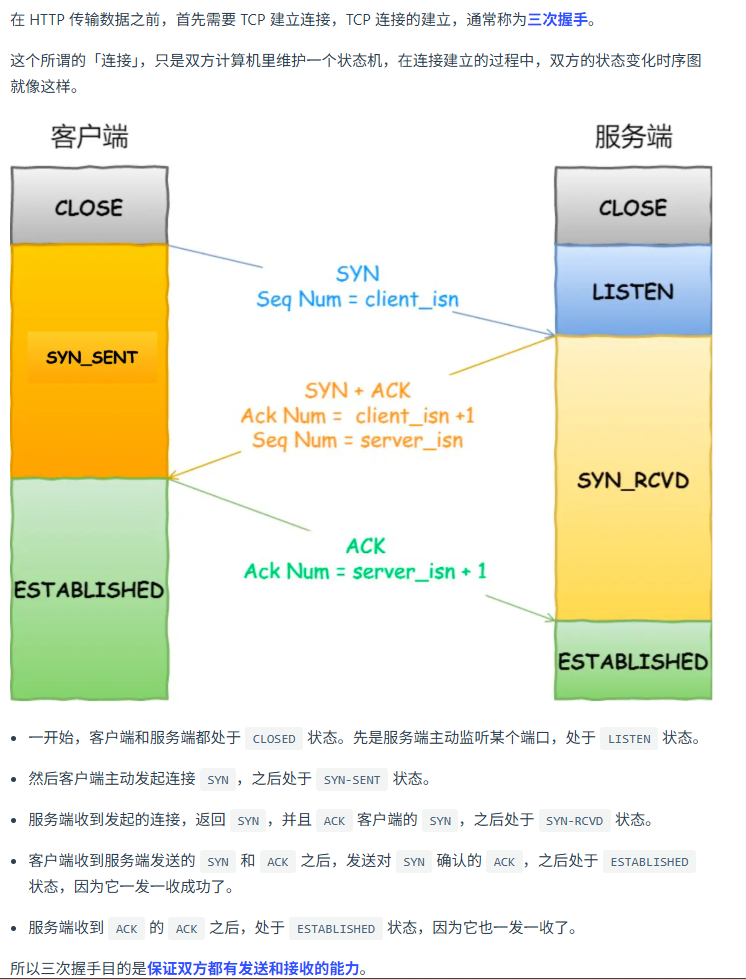
第五步:服务器接受响应并返回数据,客户端解析返回数据
HTTP 状态码为 2 开头是返回成功,3 开头是重定向到新地址,4 开头是出现错误。
第六步:渲染网页或下载数据
HTTP 是什么
HTTP 定义
超文本传输协议。超文本指的是 HTML 这种包含链接、图片、音频、视频、甚至复杂交互脚本的文本。HTTP 的最初目的就是为了传输这些"超越普通文本"的内容。
HTTP 常见状态码

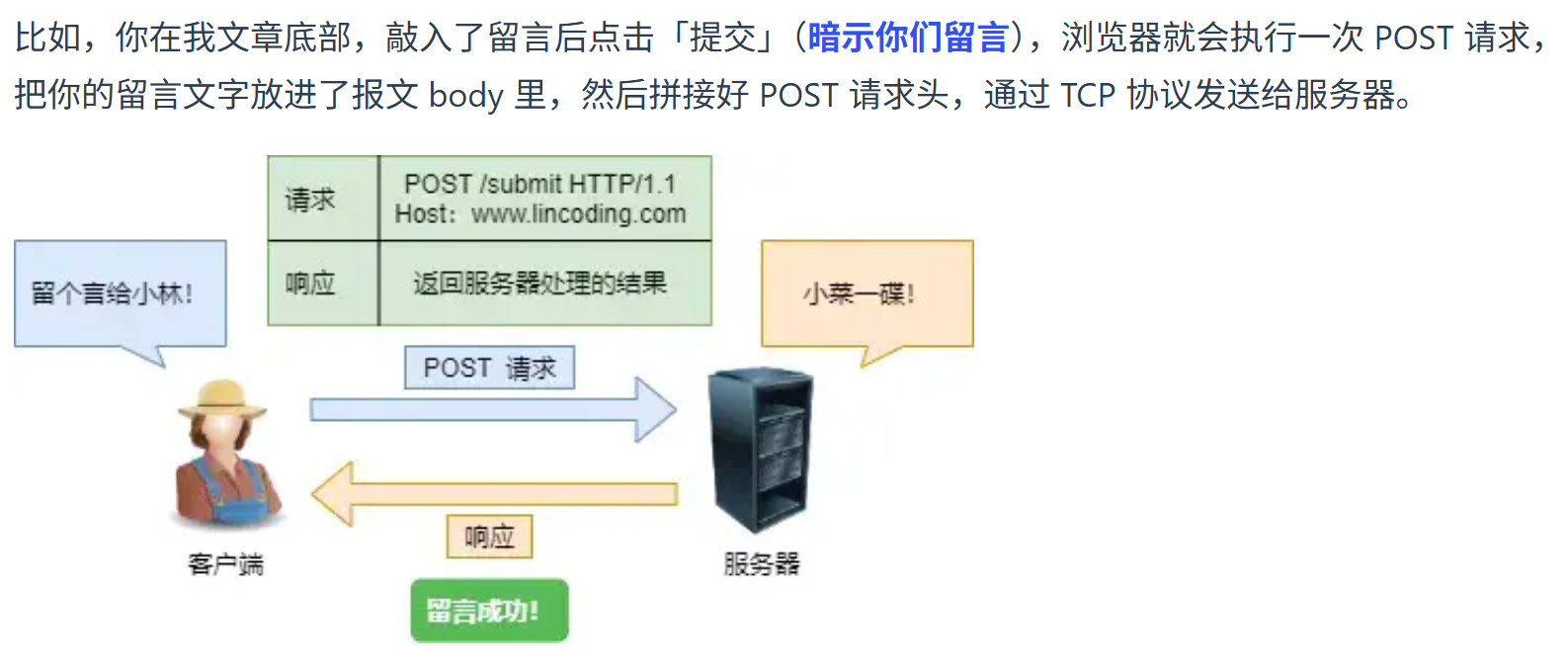
GET 和 POST 请求
GET 从语义上来说是请求服务器中的资源,比如客户端要一个网页,那么就请求服务器把这个网页返回给你。POST 从语义上来说是请求服务器对你提交的资源进行处理,比如说你提交了一个文件,希望服务器对这个文件进行处理。下面是一个例子。POST 会新增或者提交数据。
HTTP 缓存技术
强制缓存
当浏览器请求资源时,首先会检查本地缓存。如果命中强制缓存,浏览器直接使用 本地副本,甚至不向服务器发送任何请求。
核心字段:
-
Cache-Control (HTTP/1.1,推荐):通过
max-age设置资源有效期。- 例如:
Cache-Control: max-age=31536000(代表该资源在一年内都有效)。
- 例如:
-
Expires (HTTP/1.0,老旧):指定一个绝对的过期时间点。
- 缺点:如果客户端和服务器时间不一致,会导致缓存失效。
协商缓存
如果强制缓存失效了(比如超过了 max-age),浏览器就必须去问问服务器:"我手里的这份旧文件,还能继续用吗?"这就是协商。
如果没变:服务器返回 304 Not Modified,不带报文主体。浏览器继续用旧的。
如果变了:服务器返回 200 OK,并带上全新的数据。
HTTP1.1
HTTP 1.1 支持长连接
HTTP 1.0 是每次传输都需要进行 TCP 连接,需要三次握手,HTTP 1.1 支持长连接,一旦 TCP 连接建立,就可以在同一条管道上连续发送多个请求。
HTTP 1.1 支持虚拟主机
在 1.1 之前,协议假设一个 IP 地址只对应一台物理服务器(一个网站)。
改进:引入了必须携带的 Host 请求头字段。
意义:现在一台服务器可以同时托管成千上万个网站(虚拟主机)。
HTTP/1.1 强制要求所有请求必须包含 Host 字段。这使得一台物理服务器可以同时托管成千上万个不同的网站,即使它们共享同一个 IP 地址。下面举一个例子。
具体流程如下:
浏览器端:你想访问 www.apple.com,浏览器解析出 IP 是 1.2.3.4。
建立连接:浏览器连接到 1.2.3.4 的 80 端口。
发送请求:
服务器处理:服务器(比如 Nginx 或 Apache)收到请求。它一看 Host 字段是 www.apple.com,就会去对应的文件夹里找苹果公司的网页;如果是 Host: www.banana.com,它就去另一个文件夹找香蕉公司的网页。
HTTP 1.1 支持管道化
管道化是指在信息发送时可以连续发送好几个信息,而不是发送第一个之后必须等待第二个回来才能发送第二个。
HTTP 1.1 存在队头堵塞
HTTP 1.1 可以连续发好几个请求,但是在响应上存在队头堵塞。比如说现在服务器要响应 A,B,C,其中 A 要花时间特别长,B 和 C 不用花那么长的时间,B 和 C 仍然要等待不能立刻响应,而是要等待 A 响应完成之后。
HTTPS 是什么
HTTP 是超文本传输协议,信息明文传输,容易被窃取。HTTPS 引入了 SSL/TLS。HTTP 是无状态的协议,HTTPS 是由 SSL + HTTP 构建的可进行加密传输,身份认证的网络协议。HTTPS 需要数字证书,HTTP 不需要。HTTPS 和 HTTP 使用的端口号不同,HTTP 是 80,HTTPS 是 443.
如何理解是 TCP 面向字节流协议
UDP 会将一个完整的消息发送出去。而 TCP 则不是,TCP 有可能一条消息被分成好几份,那么就需要在接受时知道自己接受的是从哪里到哪里的消息,也就是消息的范围。
因为 TCP 是字节流,没有边界,所以会产生"粘包"现象:
场景:你连续发送了两条消息:"Hello" 和 "World"。
结果:接收方可能一次性读到了 "HelloWorld",它不知道这两句话从哪里断开。
解决方法: 由于 TCP 协议层不帮你分包,应用程序必须自己定义边界。常见的办法有:
固定长度:规定每条消息固定 100 字节。
分隔符:在消息末尾加回车换行符(如 HTTP 协议)。
长度前缀:在消息头先写上"本条消息长度为 5 字节",然后再发"Hello"
下面是一个粘包的例子:
TCP 连接建立(三次握手)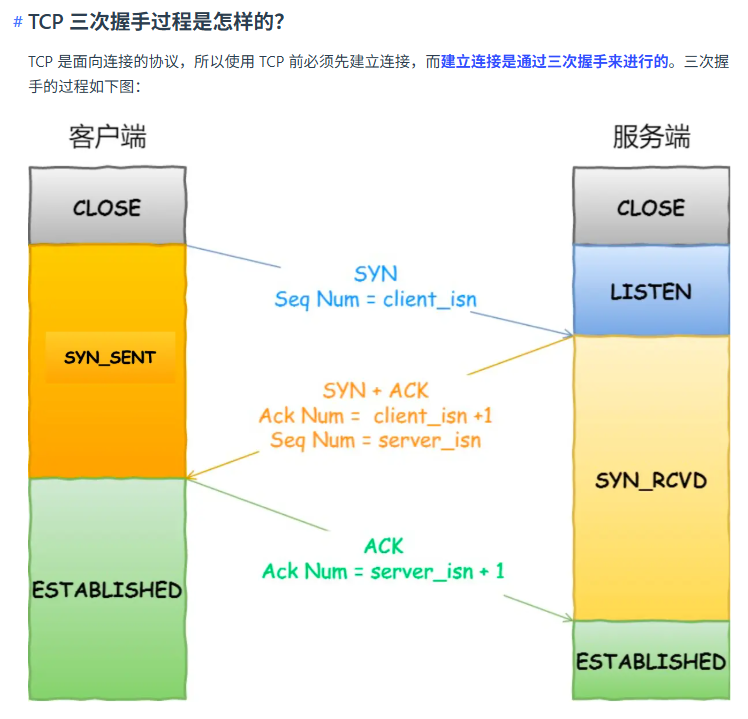
注意里面的 Ack_Num 和 Seq_Num.
TCP 连接断开(四次握手)
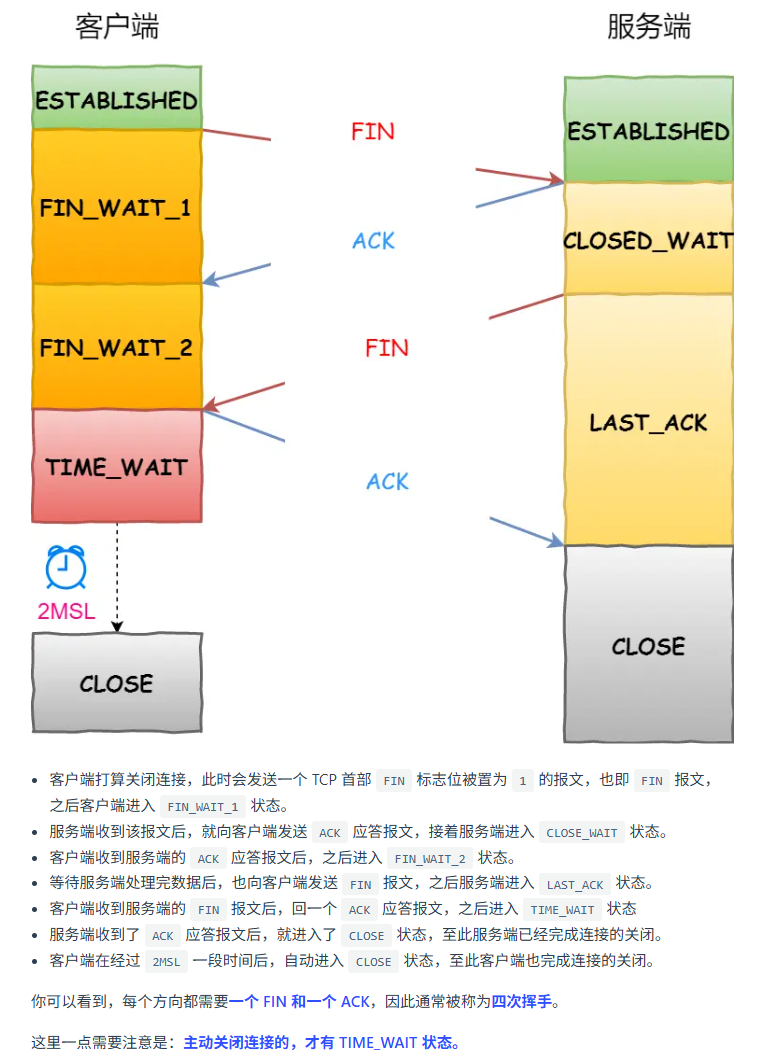
TCP 重传
超时重传
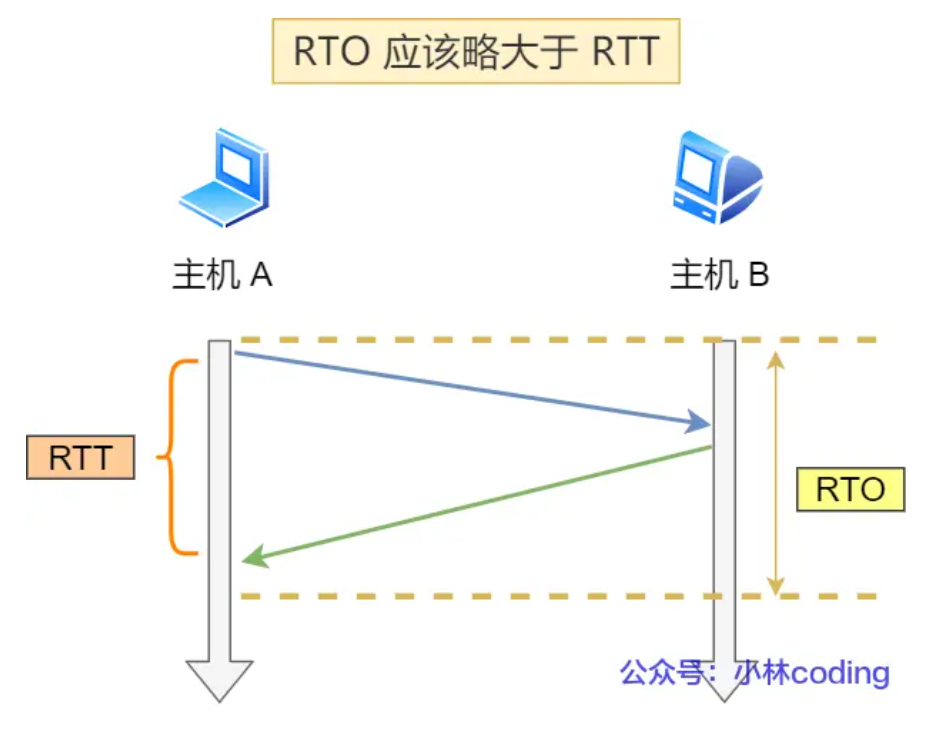
以时间为驱动,当客户端在一定时间内没有收到回复时就认为丢包了,启动重传。RTT:客户端正常一次发送接受的时间。 RTO:启动重传的时间,就是说客户端在发送之后的 RTO 秒内没有收到回复,认为它超时了启动重传。 RTO 应该设置的略大于 RTT,如果 RTO 设置的太大,那么会浪费时间,设置的太小又会引发不必要的重传,加重网络负担。
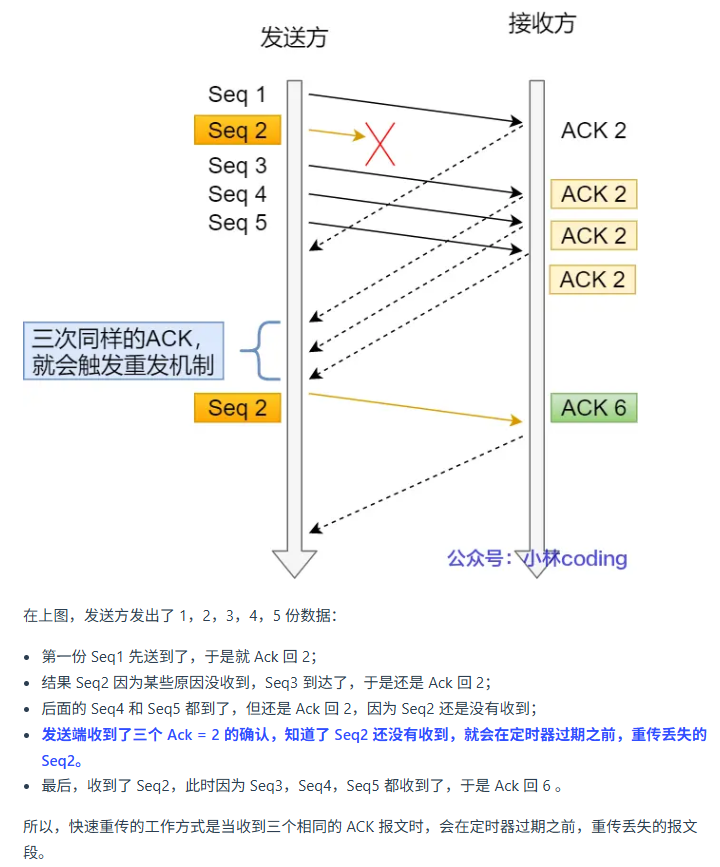
快速重传
快速重传是基于数据的重传。比如一个数据重发了三次仍然没有收到回复,那么认为它丢包了,启动重传。
SACK 方法(选择性确认)
上面的快速重传存在一个问题,那就是已知 ACK2 传送了三次,那么接下来是重传一个,还是重传所有。Seq 2 肯定没有收到,但是 Seq 3, Seq 4 和后面的有可能收到,那么是否需要把他们也进行重传呢?由此引出了 SACK 方法,也就是选择性确认。
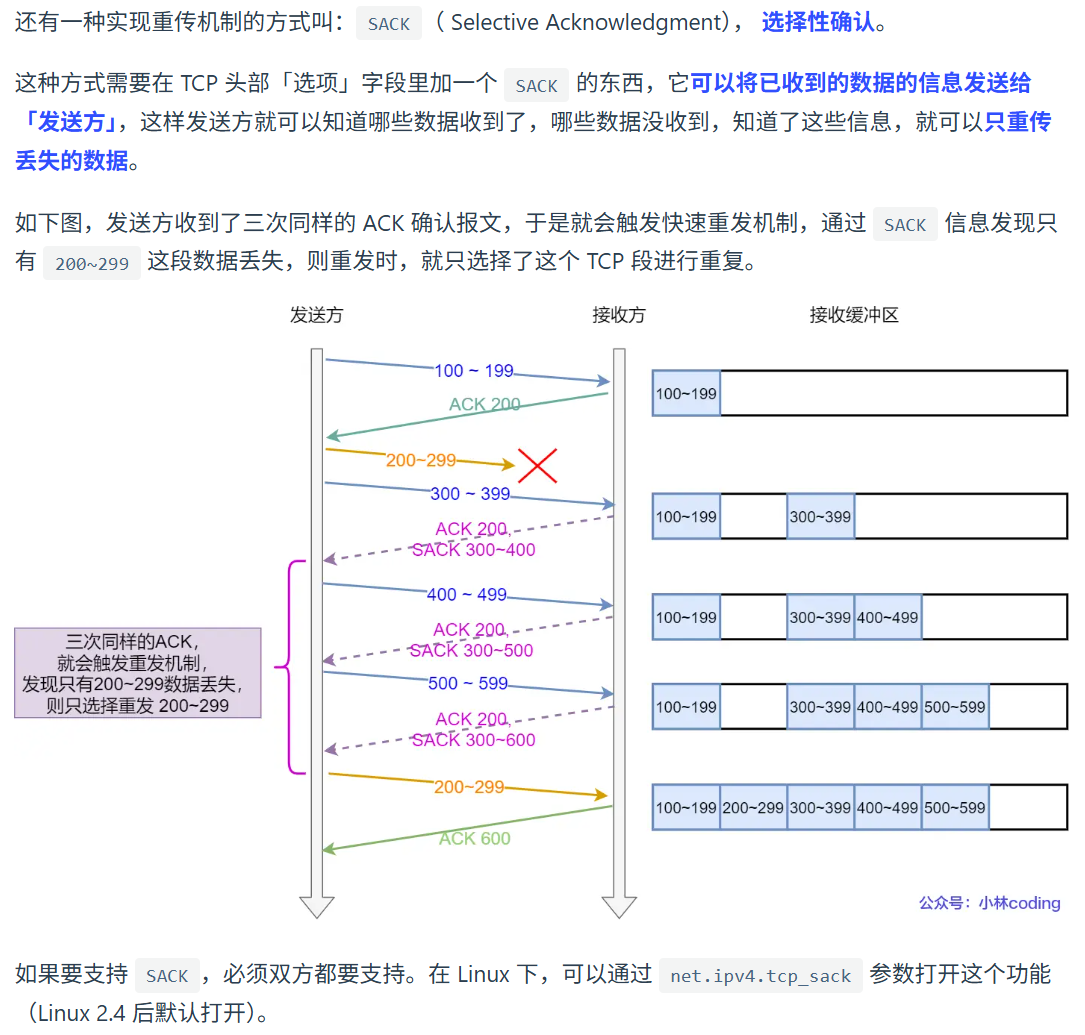
SACK 就像是接收方给发送方发了一份**"已收到货物的清单"**。
在 TCP 报文头的 Options(选项) 字段中,SACK 会记录已经收到的、但不连续的数据块(即"空洞"之后的"孤岛")。
TCP 滑动窗口
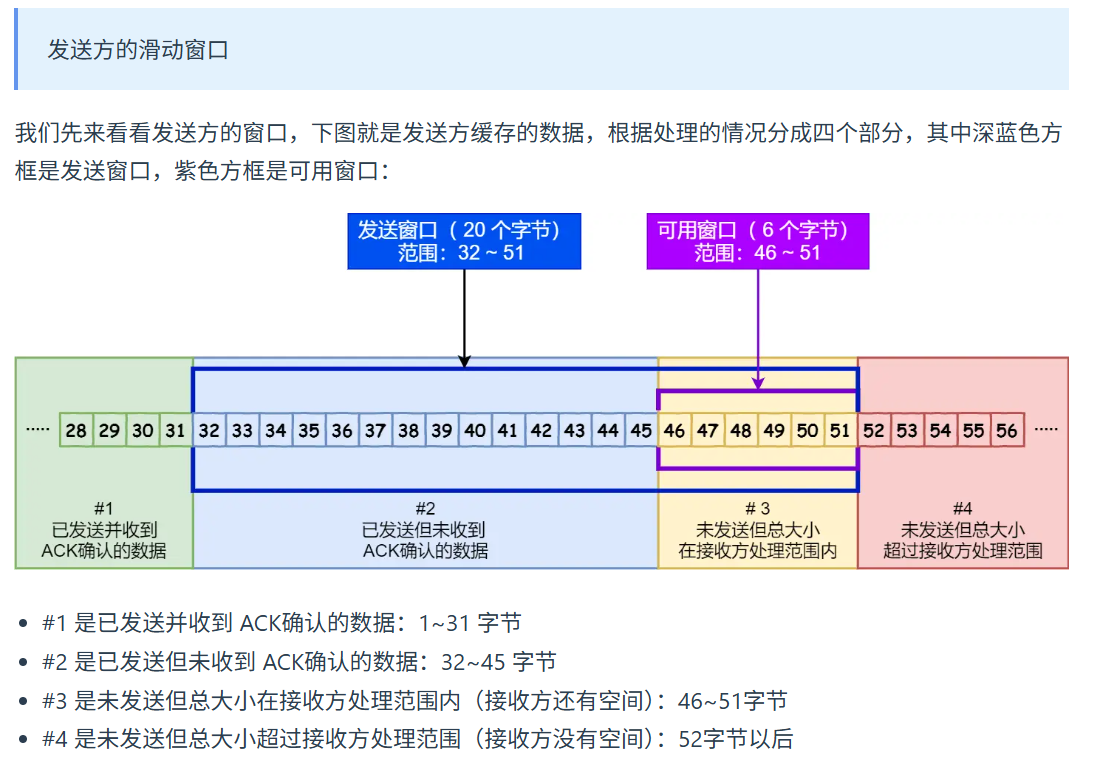
发送方的滑动窗口
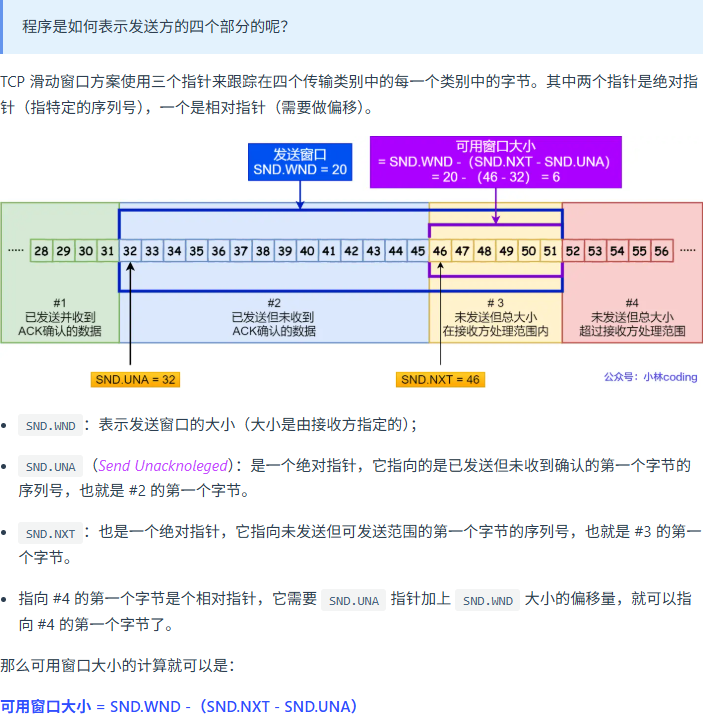
接受方的滑动窗口
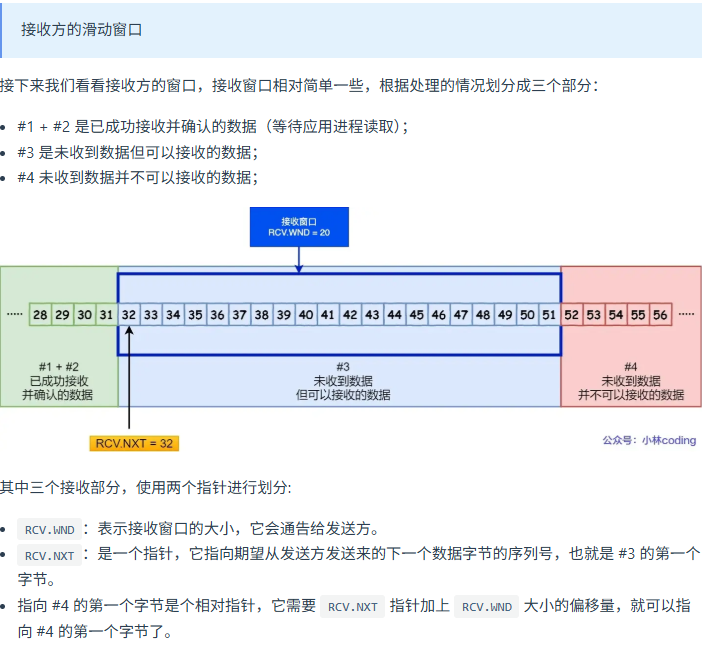
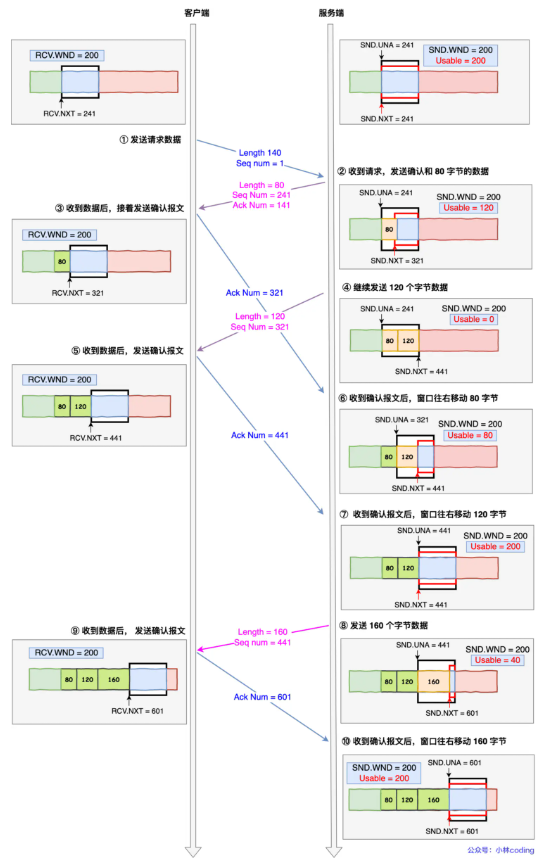
TCP 流量控制
流量控制就是接受方和发送方沟通,让发送方不要发送的太快,因为接受方不一定接受得过来。把下面这张图看懂就明白流量控制的模型了。
窗口关闭
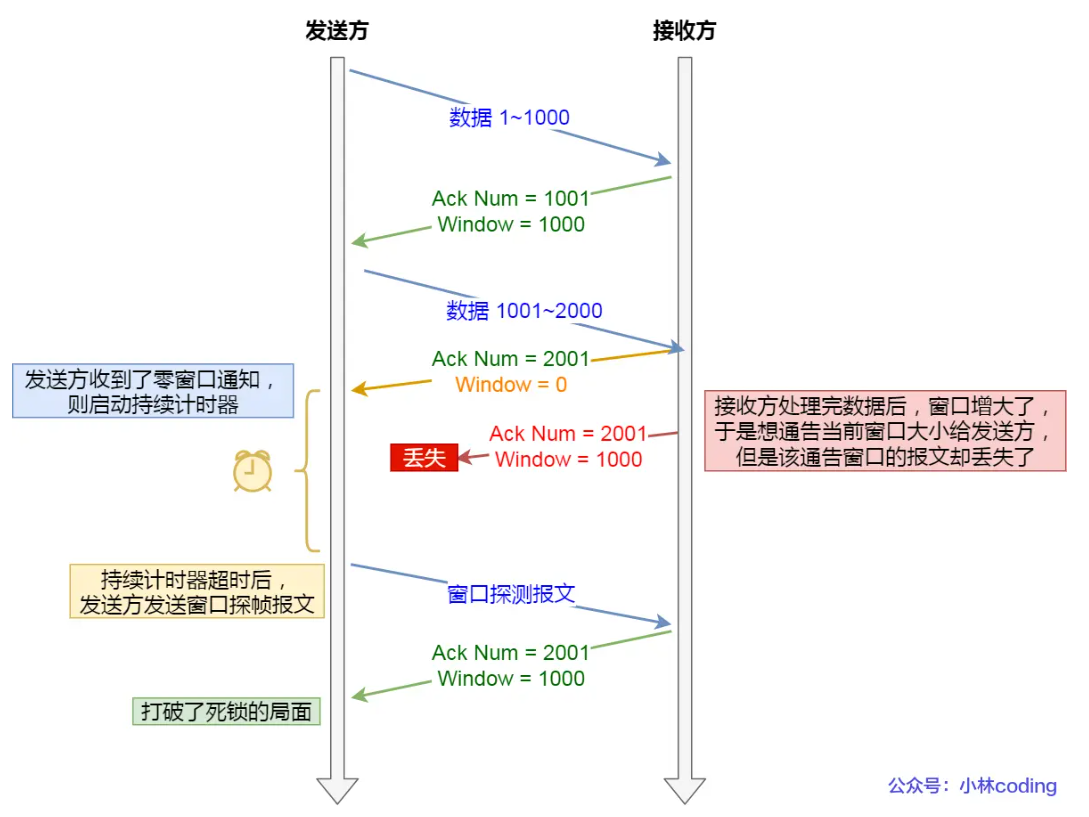
窗口关闭是指接受方因为处理数据不及时,导致窗口越变越小,最后窗口为 0 导致窗口关闭。窗口关闭时接受方会给发送方发一个信号,告知窗口关闭。窗口关闭可能会导致死锁现象,比如在接受方告知发送方窗口关闭之后,发送方会等待接受方将数据处理完之后再发。接受方处理完之后会发一个 ACK 给接受方,如果这个 ACK 丢失了,那么就会陷入死锁,接受方和发送方互相等待。
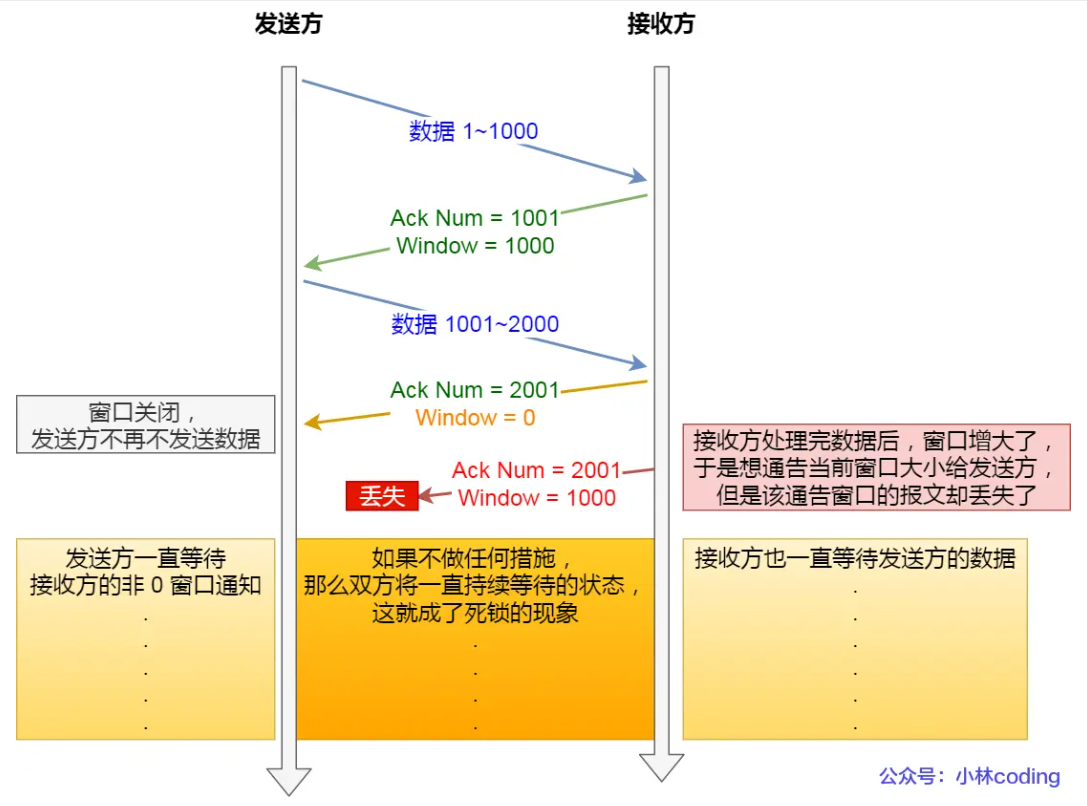
这种死锁如何解决呢?解决办法是设置一个持续计数器,当收到窗口为 0 时开始计时,持续计数器超时时给对方发一个请求,要求返回窗口大小,如果窗口大小仍然为 0,继续等待,如果不是则开始通信。
糊涂窗口
糊涂窗口现象是指随着窗口越变越小,发送方一次发送的数据也越来越少,最后一次只发送几个字节。TCP 的报头都有 40 个字节,结果实际发送的有用数据就几个字节,导致资源浪费。解决办法有两个:1.让接受方不存在通知发送方小数据的情况 2.发送方避免发送小数据
接受方不通告小窗口
这个只要设定一个数值,当窗口大小小于这个数值时将窗口大小设置为 0 ,停止发送就可以了。
发送方避免发送小数据
只要满足下面任意一条 ,就可以发;否则就缓存等着:
- 已经发出去的所有数据,都收到 ACK 了;
- 要发送的数据已经攒到一个最大报文段(MSS)大小;
- 到了超时时间(一般 200ms 左右),必须发。
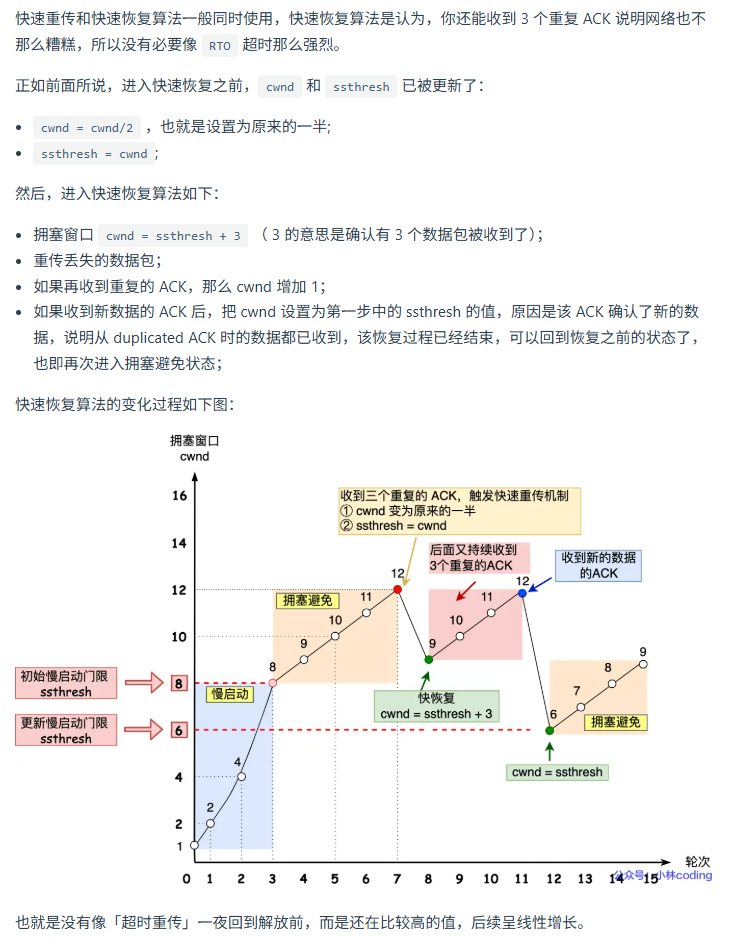
TCP 拥塞控制
拥塞控制是发送时考虑整个网络的情况,不要一直发把网络堵上。
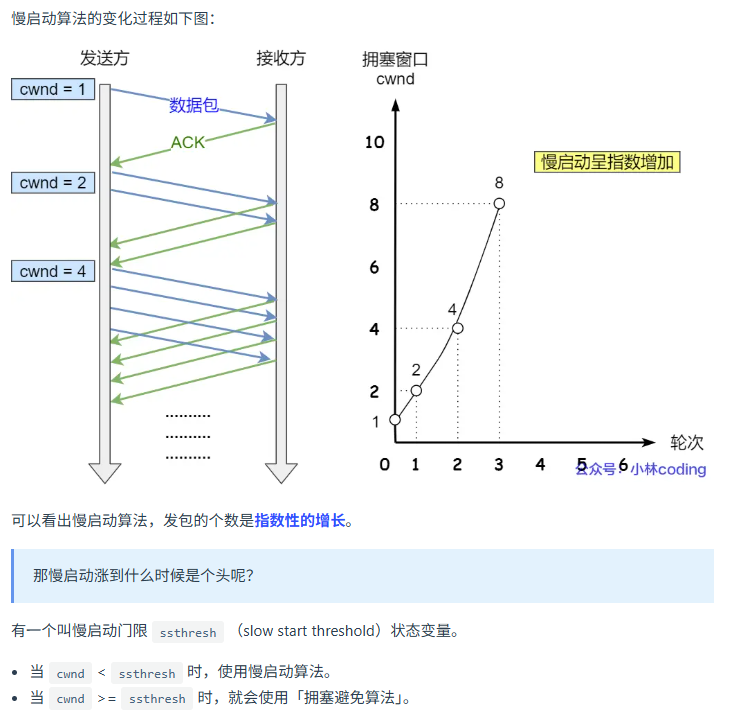
慢启动
在拥塞窗口小于慢拥塞门限前,拥塞窗口按指数增长。
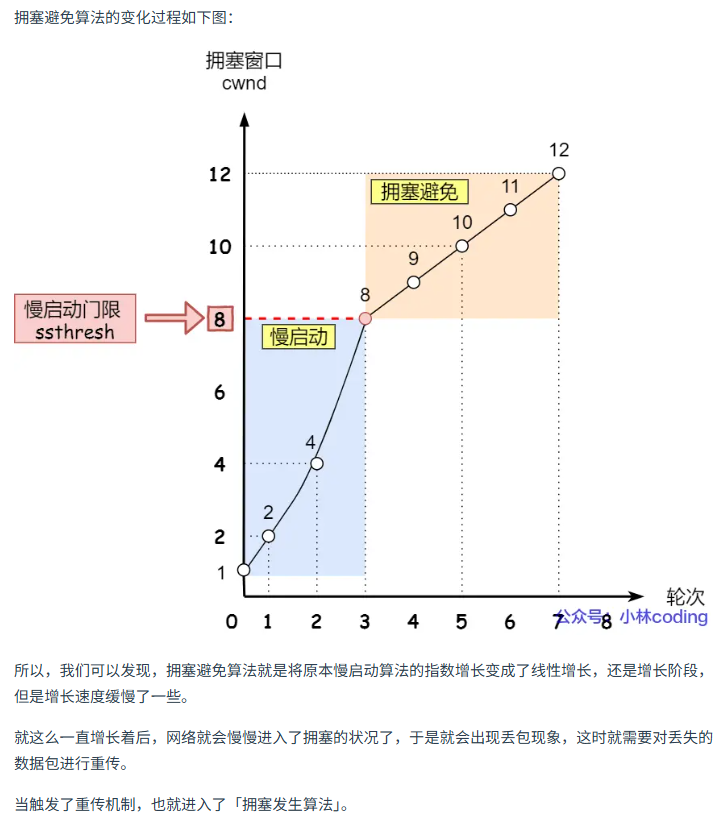
拥塞避免
当达到慢拥塞门限时,拥塞窗口按照线性增长,直到出现超时重传。
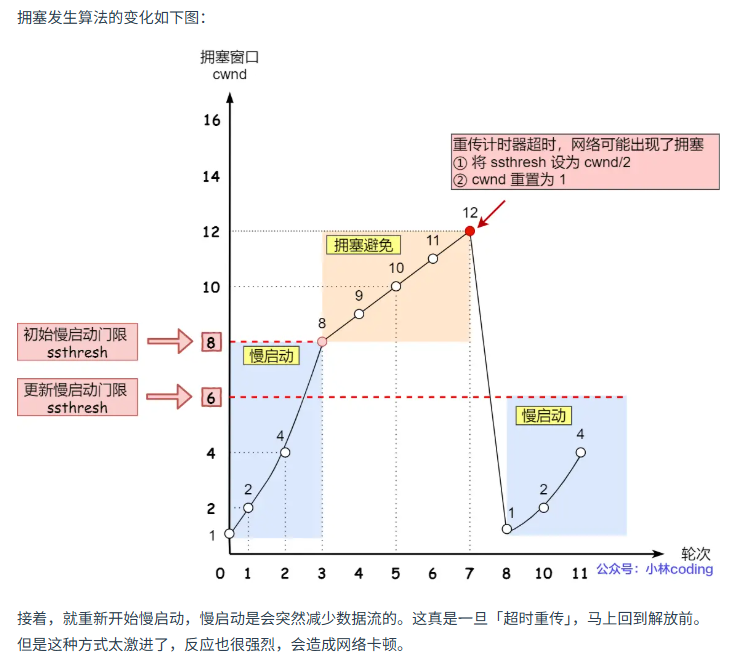
拥塞发生
发生超时重传
快速重传和快速恢复