AI实践(10)Skills技能
Author: Once Day Date: 2026年3月18日
一位热衷于Linux学习和开发的菜鸟,试图谱写一场冒险之旅,也许终点只是一场白日梦...
漫漫长路,有人对你微笑过嘛...
全系列文章可参考专栏: AI实践成长_Once-Day的博客-CSDN博客
参考文章:
- Prompt Engineering Guide
- 提示词技巧 -- Claude 中文 - Claude AI 开发技术社区
- Documentation - Claude API Docs
- OpenAI for developers
- Skills(技能) -- Claude 中文 - Claude AI 开发技术社区
- 模式库:把工程经验沉淀为 Skills -- Claude 中文 - Claude AI 开发技术社区
- 持续学习:把会话复盘沉淀成 Skills -- Claude 中文 - Claude AI 开发技术社区
- Agent Skills - Claude API Docs
- Equipping agents for the real world with Agent Skills \ Anthropic | Claude
- 技能编写最佳实践 - Claude API 文档 --- Skill authoring best practices - Claude API
Docs- Skills | OpenAI API
- Specification - Agent Skills
- Claude Skills 完全指南:从入门到精通 - 知乎
- 火爆全网的Skills,看这一篇就够了!大家好,我是势必要把Skills咬烂嚼碎的码哥! Skills 最近火得一塌糊涂 - 掘金
- AI那些趣事系列117:从入门到实战:Claude Skills 彻底指南 ------ 让 AI 像专业助手一样精准干活-CSDN博客
文章目录
- AI实践(10)Skills技能
-
-
-
- [1. Skills介绍](#1. Skills介绍)
- [2. Skills公开仓库](#2. Skills公开仓库)
- [3. Skills工作原理](#3. Skills工作原理)
- [4. Skills结构](#4. Skills结构)
- [5. Skills最佳实践](#5. Skills最佳实践)
-
- [5.1 保持精简](#5.1 保持精简)
- [5.2 设定合理的自由度](#5.2 设定合理的自由度)
- [5.3 跨模型测试](#5.3 跨模型测试)
- [5.4 控制文件规模与引用深度](#5.4 控制文件规模与引用深度)
- [5.5 使用工作流拆解复杂任务](#5.5 使用工作流拆解复杂任务)
- [6. Skills评估与迭代](#6. Skills评估与迭代)
-
- [6.1 优先构建评估体系](#6.1 优先构建评估体系)
- [6.2 评估驱动开发](#6.2 评估驱动开发)
- [6.3 借助 Claude 迭代开发](#6.3 借助 Claude 迭代开发)
- [7. Skills代码执行](#7. Skills代码执行)
- [8. Skills实践](#8. Skills实践)
-
-
1. Skills介绍
Agent Skills 是一种模块化的能力扩展机制,用于增强 Claude 等大语言模型在特定领域的表现。每个 Skill 将指令、元数据以及可选资源(如脚本、模板等)打包为一个独立单元,当对话场景与其匹配时,模型能够自动加载并使用对应的 Skill。这一机制的核心目标,是将通用型 AI 代理转变为具备专业领域知识的"专家型"助手。
在传统的交互模式中,用户往往需要在每次对话开始时反复提供相同的背景信息、工作流程和约束条件。例如,一个团队若希望 Claude 始终遵循特定的代码审查规范,就不得不在每次新会话中重新描述这些规范。这种方式不仅效率低下,而且容易因遗漏或表述差异导致输出质量不稳定。Skills 的出现正是为了解决这一痛点------将领域知识固化为可复用的文件级资源,从根本上消除重复输入的负担。
Skills 与普通 Prompt 之间存在本质区别。Prompt 是会话级别的指令,作用于单次对话,适合处理一次性、临时性的任务;而 Skills 是文件系统级别的持久化资源,按需加载,能够跨会话生效。可以将两者的关系类比为函数调用中的"内联代码"与"库函数"------前者灵活但不可复用,后者封装良好且可在多处调用。
| 特性 | Prompt | Skill |
|---|---|---|
| 作用范围 | 单次会话 | 跨会话持久化 |
| 加载方式 | 手动输入 | 按需自动加载 |
| 可复用性 | 低 | 高 |
| 维护成本 | 每次重写 | 一次创建,持续使用 |
| 适用场景 | 临时任务 | 领域专业化 |
从实际收益来看,Skills 机制提供了三个方面的核心价值。
-
其一是专业化能力定制,通过为特定领域编写
Skill,可以使模型在代码开发、文档撰写、数据分析等垂直场景下表现出更高的准确性和一致性。 -
其二是降低重复劳动,团队成员无需各自维护冗长的提示词,共享的
Skill文件即可统一工作标准。 -
其三是能力的可组合性,多个
Skill可以协同工作,通过组合简单的模块构建出复杂的自动化工作流。
这种模块化的设计理念,与软件工程中"关注点分离"的思想一脉相承。每个 Skill 聚焦于一项具体能力,保持自身的内聚性,同时通过元数据声明与外部环境的接口关系。随着 Skill 数量的积累,整个 AI 代理的能力边界将逐步扩展,形成一个可维护、可演进的能力生态。
2. Skills公开仓库
随着 Skills 机制在开发者社区中的普及,围绕其生态已经形成了多个公开的共享仓库。这些仓库为用户提供了开箱即用的 Skill 资源,同时也为 Skill 的创作者搭建了分发与协作的平台。根据维护主体和定位的不同,当前主流的公开仓库大致可以分为官方市场和社区生态两类。
Anthropic 官方 Skills 市场是最具权威性的资源来源。该市场由 Anthropic 直接维护,收录的 Skill 经过官方审核,在质量和安全性方面有较高保障。官方市场通常会提供与 Claude Code 深度集成的安装方式,用户可以通过 /install-skill 等命令直接将 Skill 部署到本地项目中。对于初次接触 Skills 的开发者而言,官方市场是最推荐的起步资源。
GitHub 社区生态则是规模最大、覆盖面最广的分发渠道。大量开发者将自己编写的 Skill 以独立仓库或 monorepo 的形式托管在 GitHub 上,涵盖代码审查、测试生成、文档撰写、DevOps 流程等多种场景。这类仓库通常附带 README 说明和使用示例,用户通过 git clone 获取后,将 Skill 文件放置到项目的 .claude/skills/ 目录即可启用。由于缺乏统一的审核机制,使用前需自行评估其指令内容的合理性。
| 仓库 | 维护方 | 特点 | 获取方式 |
|---|---|---|---|
| Anthropic 官方市场 | Anthropic | 质量可靠,官方审核 | /install-skill 命令集成 |
| GitHub 社区生态 | 开源社区 | 数量丰富,覆盖广泛 | git clone 手动部署 |
| ObraSuperpowers | Obra 社区 | 聚焦工程实践,工具链完善 | 社区平台下载 |
| awesome-claude-skills | 社区策展 | 精选索引,分类清晰 | 链接导航至源仓库 |
| skillsmp | 社区市场 | 市场化运营,支持检索与评价 | 平台直接安装 |
ObraSuperpowers 是一个较为活跃的社区驱动项目,其定位偏向于工程实践场景,提供的 Skill 多与开发工作流、项目管理和自动化任务相关。该社区维护了相对完善的工具链支持,方便用户对 Skill 进行本地调试和版本管理。
awesome-claude-skills 遵循 GitHub 上经典的 awesome-list 模式,本身并不直接托管 Skill 文件,而是充当策展与索引的角色。维护者按照领域和用途对优质 Skill 进行分类整理,并提供指向源仓库的链接。这种聚合方式降低了开发者的搜索成本,适合在选型阶段快速浏览可用资源。
skillsmp 则采用了更接近传统应用市场的运营模式,提供 Skill 的检索、评分和安装功能。用户可以根据关键词、使用场景或社区评价筛选合适的 Skill,一定程度上弥补了纯 GitHub 生态中缺乏统一发现机制的不足。
3. Skills工作原理
Skills 的运行依赖于 Claude 所处的虚拟机环境。与纯文本形式的 Prompt 不同,Claude 在该环境中具备文件系统的访问能力,因此 Skill 可以作为一个目录结构存在,其中包含指令文件、可执行脚本和参考资料。这种组织方式类似于为新成员准备的入职指南------将所需的知识、流程和工具集中放置在一个可导航的文件体系中,由模型在运行时按需读取。
这种基于文件系统的架构带来了一个关键设计优势:渐进式信息披露 (Progressive Disclosure)。传统 Prompt 模式下,所有上下文信息必须在对话开始时一次性注入,这会大量消耗有限的上下文窗口。而 Skills 机制允许 Claude 分阶段按需加载信息,仅在实际需要时才读取对应的内容,从而显著提升了上下文的利用效率。
Skill 的内容按照加载时机的不同,划分为三个层级,每个层级承担不同的职责:
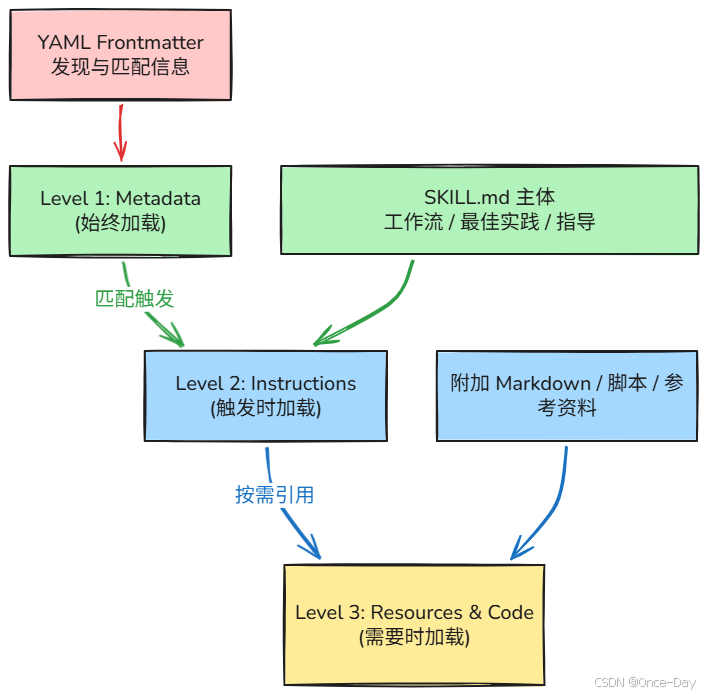
Level 1 --- Metadata ,此层级的内容始终被加载。每个 Skill 在 SKILL.md 文件头部通过 YAML frontmatter 声明元数据,包括名称、描述、触发条件等发现信息。Claude 在会话初始化时会扫描所有可用 Skill 的元数据,以判断当前对话场景是否与某个 Skill 相关。由于仅加载轻量的描述字段,这一阶段对上下文窗口的占用极小。一个典型的元数据声明如下:
yaml
---
name: code-review
description: Performs structured code review following team standards
trigger: When user asks for code review or submits a PR
tools: bash, read_file
---Level 2 --- Instructions ,当元数据匹配成功后,Claude 会进一步加载 SKILL.md 的主体部分。这部分包含过程性知识,即具体的工作流步骤、最佳实践准则和行为指导。其内容本质上是结构化的 Markdown 文本,描述模型在该场景下"应该如何思考和行动"。这一层级的设计使得 Skill 的核心逻辑与触发条件解耦,便于独立维护和更新。
Level 3 --- Resources and Code ,这是最细粒度的加载层级,仅在执行过程中按需引入。其包含三类资源:附加的 Markdown 指令文件(如 FORMS.md、REFERENCE.md),用于提供更专业的子流程指导;可执行脚本(如 fill_form.py、validate.py),Claude 通过 bash 工具调用这些脚本来完成确定性操作,避免将计算逻辑交由模型推理从而消耗上下文;以及静态参考资料,包括数据库 Schema、API 文档、模板文件等。
4. Skills结构
Skills 遵循开放的 Agent Skills Standard 规范。该标准定义了一套通用的 Skill 描述与组织格式,旨在使不同平台和工具链之间的 Skill 资源能够互相兼容。其核心思想是以文件系统目录作为 Skill 的封装边界,通过约定的文件命名和元数据格式实现自描述能力。遵循该标准编写的 Skill,不仅可以在 Claude Code 中使用,也具备向其他兼容 Agent 框架迁移的潜力。
每个 Skill 的入口文件是 SKILL.md,其结构由两部分组成:头部的 YAML frontmatter 和主体的 Markdown 正文。YAML frontmatter 用于声明元数据,对应前文所述的 Level 1 层级;Markdown 正文则承载具体的指令内容,对应 Level 2 层级。一个最小可用的 SKILL.md 文件结构如下:
markdown
---
name: your-skill-name
description: Brief description of what this Skill does and when to use it
---
# Your Skill Name
## Instructions
[Clear, step-by-step guidance for Claude to follow]
## Examples
[Concrete examples of using this Skill]YAML frontmatter 中有两个必填字段 :name 和 description。name 作为 Skill 的唯一标识符,在加载和引用时起到索引作用;description 则为模型提供语义层面的匹配依据,Claude 根据该字段判断当前任务是否应触发此 Skill。两个字段各自有明确的格式约束:
| 字段 | 约束条件 | 说明 |
|---|---|---|
name |
最长 64 字符 | 用作唯一标识 |
| 仅允许小写字母、数字和连字符 | 如 code-review、pdf-analyzer |
|
| 不得包含 XML 标签 | 防止注入风险 | |
不得使用保留词 anthropic、claude |
避免与官方资源冲突 | |
description |
不得为空,最长 1024 字符 | 供模型进行语义匹配 |
| 不得包含 XML 标签 | 同上 |
name 字段的命名约定值得注意。小写字母加连字符的格式(kebab-case)与常见的 npm 包名、Docker 镜像标签等命名规则保持一致,有利于在文件系统和命令行环境中无歧义地引用。禁止使用保留词的规则则确保用户自定义的 Skill 不会与 Anthropic 官方发布的资源产生标识冲突。
Markdown 正文部分通常包含 Instructions 和 Examples 两个核心章节。Instructions 提供清晰的分步指导,描述 Claude 在该 Skill 激活后应执行的具体流程;Examples 给出典型的使用场景和预期输出,帮助模型更准确地理解指令意图。在编写实践中,指令的表述应尽量具体且无歧义,避免使用模糊的修饰语。
当 Skill 涉及较复杂的功能时,单个 SKILL.md 文件可能不足以承载全部内容。此时可以将附加指令、脚本和参考资料组织为完整的目录结构:
markdown
pdf/
├── SKILL.md # 主指令文件(触发时加载)
├── FORMS.md # 表单填写指南(按需加载)
├── reference.md # API 参考文档(按需加载)
├── examples.md # 使用示例(按需加载)
└── scripts/
├── analyze_form.py # 工具脚本(通过 bash 执行,不注入上下文)
├── fill_form.py # 表单填写脚本
└── validate.py # 校验脚本在这个目录结构中,SKILL.md 是唯一的必需文件,其余均为可选资源。附加的 Markdown 文件(如 FORMS.md、reference.md)在 SKILL.md 的指令中通过文件路径引用,Claude 在执行过程中按需读取。scripts/ 目录下的脚本不会被注入到上下文窗口中,而是由 Claude 通过 bash 工具直接执行,其输出结果再回传给模型进行后续处理。
5. Skills最佳实践
5.1 保持精简
上下文窗口是一种共享资源。Skill 的内容与对话历史、系统指令以及其他已加载的 Skill 共同竞争有限的上下文空间。虽然并非每个 token 都会立即产生开销------启动阶段仅预加载所有 Skill 的元数据(name 和 description),SKILL.md 正文仅在 Skill 被触发时才读取,附加文件更是按需加载------但一旦 SKILL.md 被加载,其中的每个 token 都在与对话上下文争夺空间。因此,精简性是 Skill 编写的首要原则。具体而言,应避免在指令中堆砌冗余的背景解释,将重点放在可操作的步骤和明确的约束条件上。
5.2 设定合理的自由度
Skill 指令的详细程度应当与任务本身的脆弱性和可变性相匹配。一个实用的类比是将 Claude 想象为一个在路径上探索的机器人。
窄桥场景(低自由度):任务只有唯一正确的执行路径,偏离即会造成严重后果。此时应提供精确的操作步骤和严格的护栏约束。典型例子是数据库迁移脚本,必须按照严格顺序执行,任何步骤的遗漏或乱序都可能导致数据损坏。
开阔地带场景(高自由度):多条路径都能通向正确的结果,限制过多反而会降低效率。此时只需给出大致方向,信任模型自行选择最优策略。代码审查就是典型案例,最佳的审查重点取决于具体的代码上下文,过于僵化的检查清单反而会忽略真正关键的问题。
错误地为高自由度任务设定过多约束,会导致 Skill 变得冗长且不灵活;而对低自由度任务放松约束,则可能引发严重的执行错误。在编写前,先判断任务落在这个光谱的哪个位置,是设计合理 Skill 的关键前置步骤。
5.3 跨模型测试
Skills 本质上是对底层模型能力的增强层,其实际效果与所使用的模型密切相关。同一份 Skill 指令在不同模型上的表现可能存在显著差异------某些模型对隐含指令的理解更强,而另一些模型则需要更明确的步骤拆解。因此,在正式部署前,应使用所有计划适配的模型分别进行测试,确保 Skill 在各模型上都能稳定工作。
5.4 控制文件规模与引用深度
SKILL.md 应当充当"目录"的角色,像入职指南的目录页一样,为 Claude 提供全局概览并指引其在需要时查阅详细资料。在具体的规模控制上,需要遵循以下准则:
SKILL.md正文控制在 500 行以内,接近此限制时应将内容拆分到独立文件中- 所有引用文件应从
SKILL.md直接链接,保持引用深度为一层 - 超过 100 行的引用文件应在顶部添加目录索引
引用深度的限制源于 Claude 的实际读取行为。当遇到嵌套引用(即引用文件中又引用了其他文件)时,Claude 可能仅使用 head -100 等命令预览部分内容而非完整读取,导致信息缺失。将所有引用保持在一层深度,可以确保 Claude 在需要时能够读取完整的文件内容。对于超长的引用文件,顶部目录的作用在于即使 Claude 仅进行部分预览,也能感知到文件中全部可用信息的范围。
markdown
# 推荐:扁平引用结构
SKILL.md → FORMS.md ✅ 一层引用,完整读取
SKILL.md → reference.md ✅ 一层引用,完整读取
# 避免:嵌套引用结构
SKILL.md → FORMS.md → helpers.md ❌ 嵌套引用,可能部分读取5.5 使用工作流拆解复杂任务
当 Skill 涉及多步骤的复杂操作时,应将其拆解为清晰的顺序工作流。每个步骤应明确描述输入、操作和预期产出,避免步骤之间存在模糊的依赖关系。对于特别复杂的工作流,一种有效的策略是在指令中提供可勾选的检查清单,Claude 可以将其复制到回复中并逐项标记完成状态,这既帮助模型维持执行的完整性,也使用户能够直观地追踪进度。
markdown
## Deployment Workflow
- [ ] Step 1: Run test suite and confirm all tests pass
- [ ] Step 2: Generate changelog from commit history
- [ ] Step 3: Update version number in package.json
- [ ] Step 4: Build production artifacts
- [ ] Step 5: Run validation script `./scripts/validate.py`
- [ ] Step 6: Deploy to staging and verify这种检查清单模式在数据库迁移、发布流程、环境配置等对步骤完整性要求较高的场景中尤为适用。
6. Skills评估与迭代
6.1 优先构建评估体系
一个常见的误区是在动手编写 Skill 之前,先投入大量精力撰写详尽的指令文档。这种做法的风险在于,开发者可能基于主观假设去描述"想象中的问题",而非解决实际存在的缺陷。更合理的策略是先构建评估体系,再编写 Skill 内容。评估体系的存在确保每一条指令都有明确的验证标准,避免 Skill 陷入"文档膨胀而效果模糊"的状态。
6.2 评估驱动开发
评估驱动的 Skill 开发遵循一个从发现问题到验证解决方案的闭环流程,其核心思路与测试驱动开发(TDD)高度相似:先明确"什么是失败",再有针对性地编写解决方案。

第一步是识别缺陷。在不提供任何 Skill 的情况下,让 Claude 处理一组具有代表性的真实任务,仔细记录其失败的具体表现------是遗漏了关键步骤、使用了错误的工具调用方式,还是缺乏特定领域的上下文知识。这些记录构成了 Skill 开发的需求来源。
第二步是围绕这些缺陷创建至少三个评估场景,每个场景对应一个已观察到的具体失败模式。随后在无 Skill 条件下执行这些场景,记录模型的输出质量作为性能基线。基线的存在使后续的改进具备可量化的对比依据。
在基线确立之后,开始编写 Skill 指令。此阶段的关键原则是最小化------仅编写足以解决已识别缺陷的内容,抵制"预防性文档化"的冲动。每一条新增的指令都应能追溯到某个具体的评估场景。编写完成后,重新执行评估并与基线对比,未达标则继续调整指令,直到所有场景均通过。
这种方法从根本上约束了 Skill 的膨胀趋势。未经评估验证的指令往往是对需求的猜测,它们不仅增加上下文开销,还可能在某些场景下引入意外的干扰。
6.3 借助 Claude 迭代开发
Skill 开发中最高效的实践模式涉及两个 Claude 实例的协作。开发者与一个实例(称为 Claude A)合作设计和优化 Skill 的指令内容,然后由另一个独立实例(Claude B)在真实任务中测试这些指令。Claude A 扮演"指令作者"的角色,Claude B 则扮演"指令执行者"的角色。
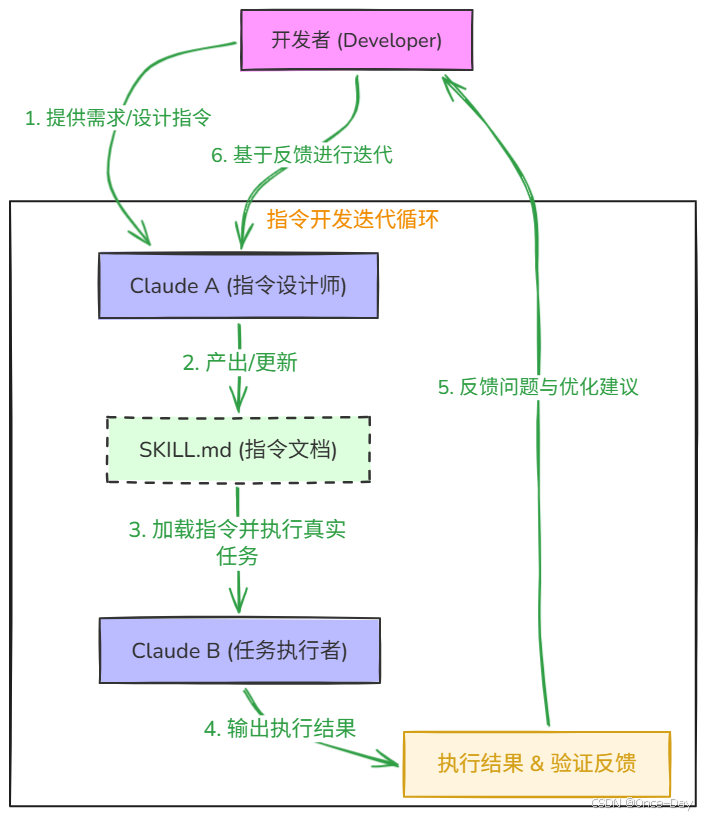
这种双实例模式之所以有效,是因为 Claude 模型本身对 Agent 指令的编写和解读具有双向理解能力------Claude A 能够预判什么样的表述方式最易于另一个 Agent 实例准确执行,同时能够根据 Claude B 的实际执行偏差快速定位指令中的歧义或遗漏。相比开发者独自反复修改和测试,这种协作方式显著缩短了迭代周期。
7. Skills代码执行
Skills 中的脚本承担着确定性计算任务,其执行结果会直接回传给 Claude 用于后续推理。因此,脚本的健壮性直接影响整个 Skill 的可靠性。一个核心设计原则是:脚本应自行处理错误条件,而非将异常抛回给模型。当脚本抛出未处理的异常时,Claude 收到的是一段错误堆栈信息,它需要消耗上下文去分析错误原因并决定下一步操作,这既浪费了上下文空间,也引入了不确定性。
良好的错误处理应当在脚本内部完成闭环------遇到可预见的异常时,提供合理的降级方案或默认行为,并通过标准输出告知 Claude 实际发生了什么。以文件处理为例:
python
def process_file(path):
"""Process a file, creating it if it doesn't exist."""
try:
with open(path) as f:
return f.read()
except FileNotFoundError:
# 文件不存在时主动创建,而非让调用方处理异常
print(f"File {path} not found, creating default")
with open(path, "w") as f:
f.write("")
return ""
except PermissionError:
# 权限不足时返回默认值,避免流程中断
print(f"Cannot access {path}, using default")
return ""这段代码对 FileNotFoundError 和 PermissionError 两种常见异常分别提供了降级策略。Claude 接收到的是清晰的状态描述(如 "File not found, creating default")而非 Python 的 traceback 输出,从而可以直接基于该信息继续执行工作流。这种模式应推广到所有 Skill 脚本中:网络请求应处理超时和连接失败,数据解析应处理格式异常,文件操作应处理路径不存在和权限不足等情况。
脚本中的配置参数同样需要审慎对待。John Ousterhout 在其软件设计理论中提出的 "voodoo constants" 问题在 Skill 场景下尤为突出------如果开发者自己都无法解释某个常量的取值依据,Claude 在执行时更无从判断该值是否适用于当前场景。每个配置参数都应附带简明的取值理由:
bash
# HTTP 请求通常在 30 秒内完成
# 较长的超时时间用于兼容慢速网络连接
REQUEST_TIMEOUT = 30
# 3 次重试在可靠性与速度之间取得平衡
# 大多数间歇性故障在第 2 次重试时即可恢复
MAX_RETRIES = 3对比两种风格的差异可以更直观地理解这一原则:
| 风格 | 示例 | 问题 |
|---|---|---|
| 不透明常量 | TIMEOUT = 30 |
无法判断 30 是经验值、规范要求还是随意设定 |
| 自文档化常量 | TIMEOUT = 30 # HTTP typical + slow network margin |
取值依据清晰,便于后续调整 |
| 不透明常量 | RETRIES = 3 |
无从评估是否适用于当前任务 |
| 自文档化常量 | RETRIES = 3 # Most transient failures resolve by retry 2 |
隐含了可调整的判断依据 |
注释中记录的不仅是"值是什么",更是"为什么选择这个值"。当 Claude 在不同的执行环境中运行脚本时,这些注释为其提供了评估参数适用性的依据。例如,如果任务涉及已知的高延迟 API,Claude 可以根据注释中"慢速连接"的说明合理判断是否需要调大超时值,而非盲目沿用默认配置。
8. Skills实践
8.1 目录结构
整个 Skill 的文件组织如下,遵循前文所述的扁平引用原则,所有资源文件均从 SKILL.md 直接引用:
markdown
cpp-code-review/
├── SKILL.md # 主指令文件
├── checklist.md # 审查检查清单
├── common-issues.md # 常见问题参考手册
└── scripts/
├── check_includes.py # 头文件依赖分析
└── count_complexity.py # 圈复杂度统计8.2 SKILL.md 编写
SKILL.md 作为入口文件,控制在 500 行以内,聚焦于工作流的整体编排:
markdown
---
name: cpp-code-review
description: >
Performs structured C/C++ code review focusing on memory safety,
coding standards, and performance. Trigger when asked to review
C or C++ source files, pull requests, or code changes.
---
# C/C++ Code Review
## Instructions
When asked to review C/C++ code, follow these steps in order.
Copy the checklist from `checklist.md` into your response and
check off items as you complete them.
### Step 1: Static Analysis
Run the include dependency check and complexity analysis:
python3 scripts/check_includes.py <target_directory>
python3 scripts/count_complexity.py <target_files>
Report any findings before proceeding.
### Step 2: Memory Safety Review
Examine the code for memory-related issues:
- Unmatched `malloc`/`free` or `new`/`delete` pairs
- Buffer overflows from unchecked array indexing or `strcpy`
- Use-after-free and dangling pointer risks
- Missing null checks after allocation
Refer to `common-issues.md` Section 1 for detailed patterns.
### Step 3: Coding Standards
Check adherence to project conventions:
- Naming consistency (variables, functions, types)
- Header guard correctness (`#pragma once` or `#ifndef` pattern)
- Const correctness for function parameters and member functions
### Step 4: Performance Considerations
Identify potential performance issues:
- Unnecessary copies in loops (prefer references or `std::move`)
- Repeated allocations that could be hoisted
- Algorithm complexity mismatches for data scale
### Step 5: Summary
Provide a severity-ranked list of all findings. Each finding must
include: file path, line number, severity (critical/warning/info),
and a concrete fix suggestion.
## References
- `checklist.md` --- Copy into response and track progress
- `common-issues.md` --- Detailed patterns for common C/C++ defects8.3 检查清单
checklist.md 提供可复制的工作流追踪模板,Claude 在审查过程中逐项标记:
markdown
# Code Review Checklist
- [ ] Static analysis scripts executed
- [ ] Include dependencies verified (no circular includes)
- [ ] Cyclomatic complexity within threshold (≤15 per function)
- [ ] Memory allocation/deallocation paired
- [ ] Buffer access bounds checked
- [ ] Null pointer checks present after allocation
- [ ] Naming conventions consistent
- [ ] Header guards present and correct
- [ ] Const correctness verified
- [ ] Unnecessary copies identified
- [ ] Algorithm complexity appropriate
- [ ] Summary with severity ranking produced8.4 辅助脚本
辅助脚本遵循"自行处理错误"和"自文档化常量"的原则。以圈复杂度统计脚本为例:
python
all_findings = []
for arg in sys.argv[1:]:
path = Path(arg)
if path.is_file():
all_findings.extend(analyze_file(path))
elif path.is_dir():
for ext in ('*.c', '*.cpp', '*.cc', '*.h', '*.hpp'):
for f in path.rglob(ext):
all_findings.extend(analyze_file(f))
else:
print(f"SKIP: {arg} is not a valid file or directory")
if not all_findings:
print("OK: All functions are within complexity threshold "
f"({COMPLEXITY_THRESHOLD})")
else:
print(f"FOUND: {len(all_findings)} function(s) exceed "
f"complexity threshold ({COMPLEXITY_THRESHOLD}):\n")
for f in sorted(all_findings, key=lambda x: -x['complexity']):
print(f" {f['file']}:{f['line']} --- "
f"{f['function']}() complexity={f['complexity']}")
if __name__ == '__main__':
main()该脚本的设计体现了几个关键实践:COMPLEXITY_THRESHOLD 和 BRANCH_KEYWORDS 两个常量均附带了取值依据的注释;FileNotFoundError 和 UnicodeDecodeError 在函数内部被捕获并输出 SKIP 标记,不会导致脚本崩溃;输出格式对 Claude 友好,以 OK 或 FOUND 开头明确传递分析结论,后续的条目按严重程度降序排列,便于模型优先处理高复杂度函数。
8.5 使用效果
当用户在 Claude Code 中发出类似 "review the src/ directory for C++ issues" 的指令时,Claude 根据 description 字段匹配到该 Skill,加载 SKILL.md 后按照工作流依次执行:先运行辅助脚本获取静态分析数据,再结合代码内容逐项完成检查清单,最终输出按严重等级排序的审查报告。整个过程中,脚本负责确定性的度量计算,Claude 负责需要语义理解的代码分析,两者各自发挥所长。

Once Day
也信美人终作土,不堪幽梦太匆匆......
如果这篇文章为您带来了帮助或启发,不妨点个赞👍和关注!
(。◕‿◕。)感谢您的阅读与支持~~~