Python爬虫入门
- 网络爬虫概述
- requests请求库
-
- [requests 介绍与安装](#requests 介绍与安装)
-
- [requests 介绍](#requests 介绍)
- [requests 安装](#requests 安装)
- [requests 基本使用](#requests 基本使用)
-
- [requests 使用3步骤](#requests 使用3步骤)
- [response 常见属性](#response 常见属性)
- 案例:实现
- [Beautiful Soup 解析库](#Beautiful Soup 解析库)
-
- [Beautiful Soup 介绍与安装](#Beautiful Soup 介绍与安装)
-
- [Beautiful Soup 介绍](#Beautiful Soup 介绍)
- [Beautiful Soup 安装](#Beautiful Soup 安装)
- BeautifulSoup对象介绍与创建
-
- BeautifulSoup对象
- [创建 BeautifulSoup 对象](#创建 BeautifulSoup 对象)
- 警告问题
- BeautifulSoup对象的find方法
-
- [find方法的作用: 搜索文档树](#find方法的作用: 搜索文档树)
-
- [案例: 根据标签名查找](#案例: 根据标签名查找)
- [案例: 根据属性查找](#案例: 根据属性查找)
- [案例: 根据文本查找](#案例: 根据文本查找)
- [Tag 对象介绍](#Tag 对象介绍)
-
- [Tag 对象常见属性](#Tag 对象常见属性)
- 正则表达式
-
- 正则表达式的概念与作用
- 正则表达式常见语法
- [re.findall() 方法](#re.findall() 方法)
- 正则表达式中的r原串的使用
- [案例: 提取最新的疫情数据的json字符串](#案例: 提取最新的疫情数据的json字符串)
- json模块
-
- json模块介绍
- [JSON 转换为 Python](#JSON 转换为 Python)
- [Python 转换为 JSON](#Python 转换为 JSON)
- [案例: 解析最新的疫情数据的json字符串](#案例: 解析最新的疫情数据的json字符串)
){kind=link}
网络爬虫概述
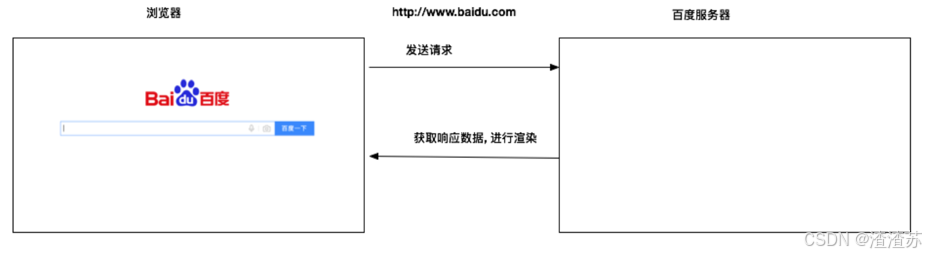
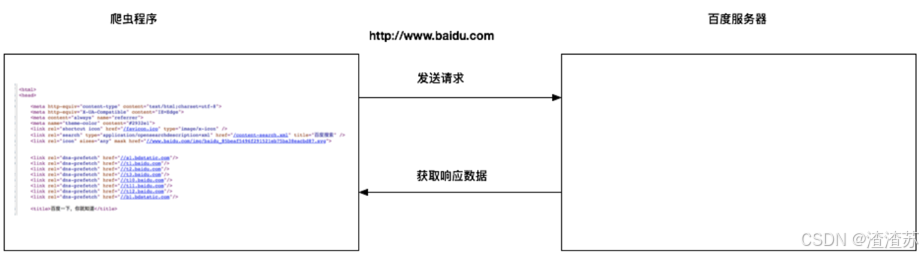
网络爬虫与浏览器的区别
网络爬虫的定义与作用
网络爬虫的定义
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟客户端发送网络请求,获取响应数据,一种按照一定的规则,自动地抓取万维网信息的程序或脚本
网络爬虫的作用
从万维网上获取, 我们需要的信息
requests请求库
requests 介绍与安装
requests 介绍
requests 是一个优雅而简单的 Python HTTP请求库
requests 的作用是 发送请求获取响应数据

requests 安装
在终端(命令行工具) 运行这个简单命令即可
bash
pip install requestsrequests 基本使用
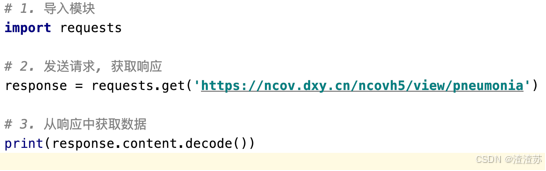
requests 使用3步骤
- 导入模块
- 发送get请求, 获取响应:
- 从响应中获取数据:

response 常见属性
- response.text : 响应体 str类型
- response.ecoding : 二进制转换字符使用的编码
- respones.content: 响应体 bytes类型

案例:实现
Beautiful Soup 解析库
Beautiful Soup 介绍与安装
Beautiful Soup 介绍
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库
Beautiful Soup 安装
bash
# 安装 Beautiful Soup 4
pip install bs4
# 安装 lxml
pip install lxml BeautifulSoup对象介绍与创建
BeautifulSoup对象
BeautifulSoup对象: 代表要解析整个文档树, 它支持 遍历文档树 和 搜索文档树 中描述的大部分的方法.
创建 BeautifulSoup 对象
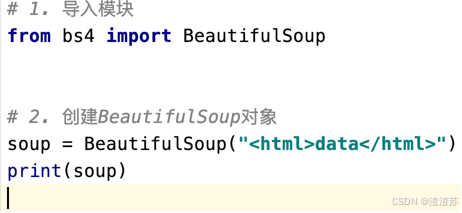
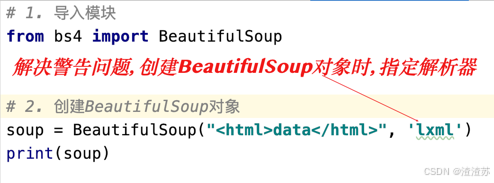
警告问题

解决警告问题
BeautifulSoup对象的find方法
find方法的作用: 搜索文档树
- find(self, name=None, attrs={}, recursive=True, text=None, **kwargs)
- 参数 name: 标签名
- attrs: 属性字典
- recursive: 是否递归循环查找
- text: 根据文本内容查找
- 返回
- 查找到的第一个元素对象

- 查找到的第一个元素对象
案例: 根据标签名查找

案例: 根据属性查找
需求: 获取文档中的 id 为 link1 的标签
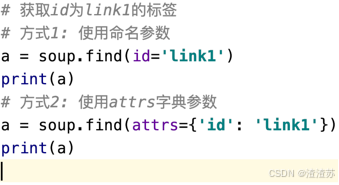
案例: 根据文本查找
需求: 获取文档中 文本 为 Elsie 的 标签文本

Tag 对象介绍
Tag对象对应于原始文档中的XML或HTML标签
Tag有很多方法和属性, 可用 遍历文档树 和 搜索文档树 以及获取标签内容
Tag 对象常见属性
- name: 获取标签名称
- attrs: 获取标签所有属性的键和值
- text: 获取标签的文本字符串

正则表达式
正则表达式的概念与作用
概念
正则表达式(regular expression) 是一种字符串匹配的模式(pattern).
作用
- 检查一个字符串是否含有某种子串
- 替换匹配的子串
- 提取某个字符串中匹配的子串
正则表达式常见语法

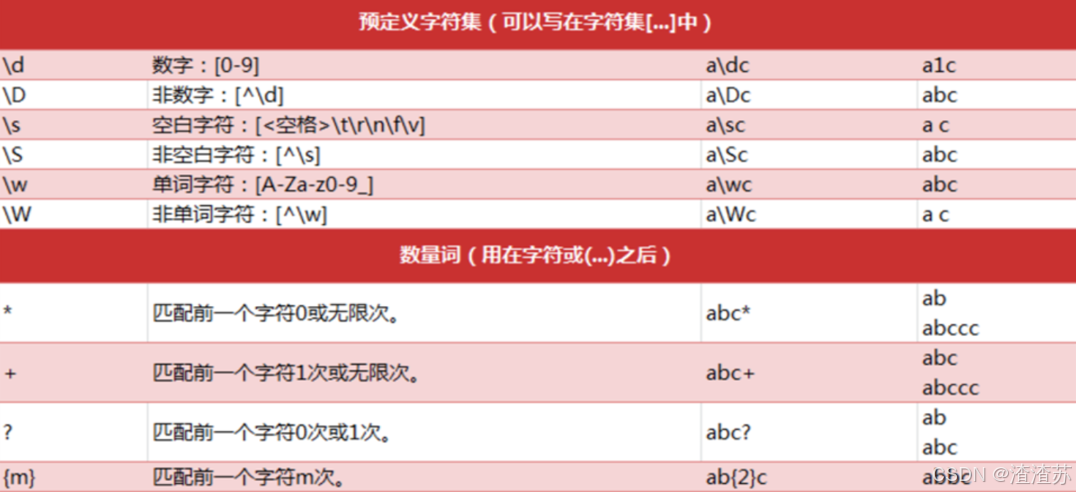
re.findall() 方法
API
- re.findall(pattern, string, flags=0)(重点)
- 作用:
- 扫描整个string字符串,返回所有与pattern匹配的列表
- 参数:
- pattern: 正则表达式
- string: 从那个字符串中查找
- flags: 匹配模式
- 返回
- 返回string中与pattern匹配的结果列表
- 举例:
- re.findall("\d","chuan1zhi2") >> "1","2"
看下面两句话结果一样吗 ?
python
rs = re.findall("a.+bc", "a\nbc", re.DOTALL)
print(rs)
rs = re.findall("a(.+)bc", "a\nbc", re.DOTALL)
print(rs)findall() 特点: (切记)
如果正则表达式中有没有()则返回与整个正则匹配的列表
如果正则表达式中有(),则返回()中匹配的内容列表, 小括号两边东西都是负责确定提取数据所在位置.
正则表达式中的r原串的使用
观察一下代码输出 ?
python
rs = re.findall("a\nb","a\nb")
print(rs)
rs = re.findall("a\\nb","a\\nb")
print(rs)
rs = re.findall("a\\\\nb","a\\nb")
print(rs)
rs = re.findall(r"a\nb","a\nb")
print(rs)结论:
正则中使用r原始字符串, 能够忽略转义符号带来的影响
待匹配的字符串中有多少个\,r原串正则中就添加多少个\即可
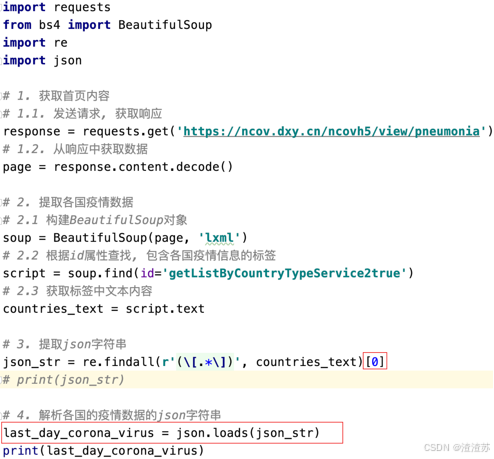
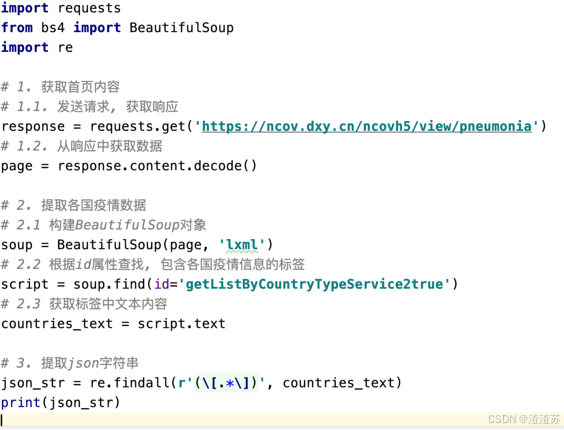
案例: 提取最新的疫情数据的json字符串
- 请求疫情首页内容
- 提取script标签中各国疫情信息
- 从各国疫情信息中提取各国疫情的json字符串
json模块
json模块介绍
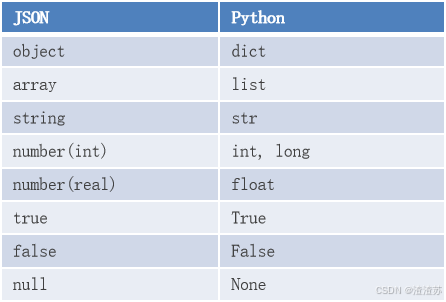
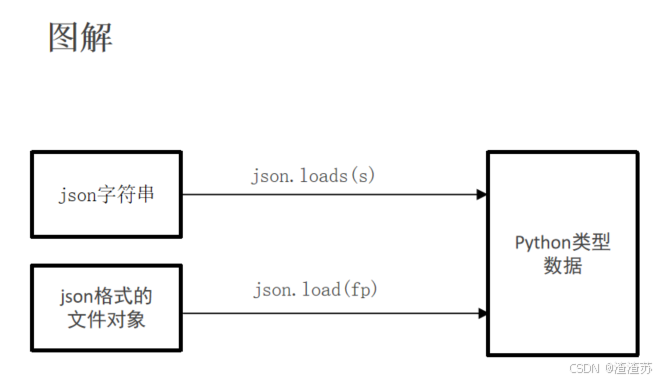
json模块是Python自带的模块, 用于json与python数据之间的相互转换.
JSON与Python数据类型的对应关系

JSON 转换为 Python
Python 转换为 JSON
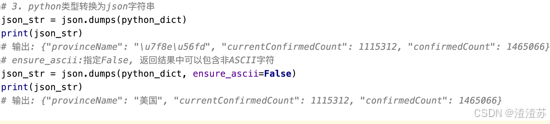
Python类型数据转换json字符串

Python类型数据以json格式写入文件

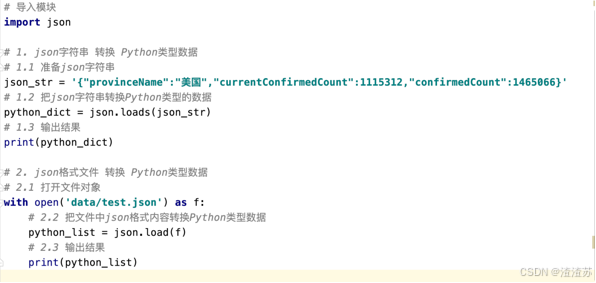
案例: 解析最新的疫情数据的json字符串
- 发送请求, 获取疫情首页
- 从疫情首页中提取各国疫情字符串
- 从各国疫情字符串中, 提取json格式字符串
- 把json格式字符串, 转换为Python类型