背景
分布式系统中,zooKeeper是**++协调++** 组件,承担着维护配置信息、命名服务、分布式锁和集群管理等关键职责。此前深入分析了jraft,有选主,分布式存储特性,可嵌入应用,减少部署资源,但欠缺了zookeeper的"协调"特性,会话,watcher,临时节点。分析zookeeper,了解会话,watcher源码原理,补全分布式系统的技术特性,为后续增强jraft为嵌入分布式协调提供技术储备。
关键词
electionEpoch:每执行一次leader选举,electionEpoch就会自增,用来标记leader选举的轮次
peerEpoch:每次leader选举完成之后,都会选举出一个新的peerEpoch,用来标记事务请求所属的轮次
zxid:事务请求的唯一标记,由leader服务器负责进行分配。由2部分构成,高32位是上述的peerEpoch,低32位是请求的计数,从0开始。所以由zxid我们就可以知道该请求是哪个轮次的,并且是该轮次的第几个请求。
lastProcessedZxid:最后一次commit的事务请求的zxid
技术架构
zookeeper的技术架构图
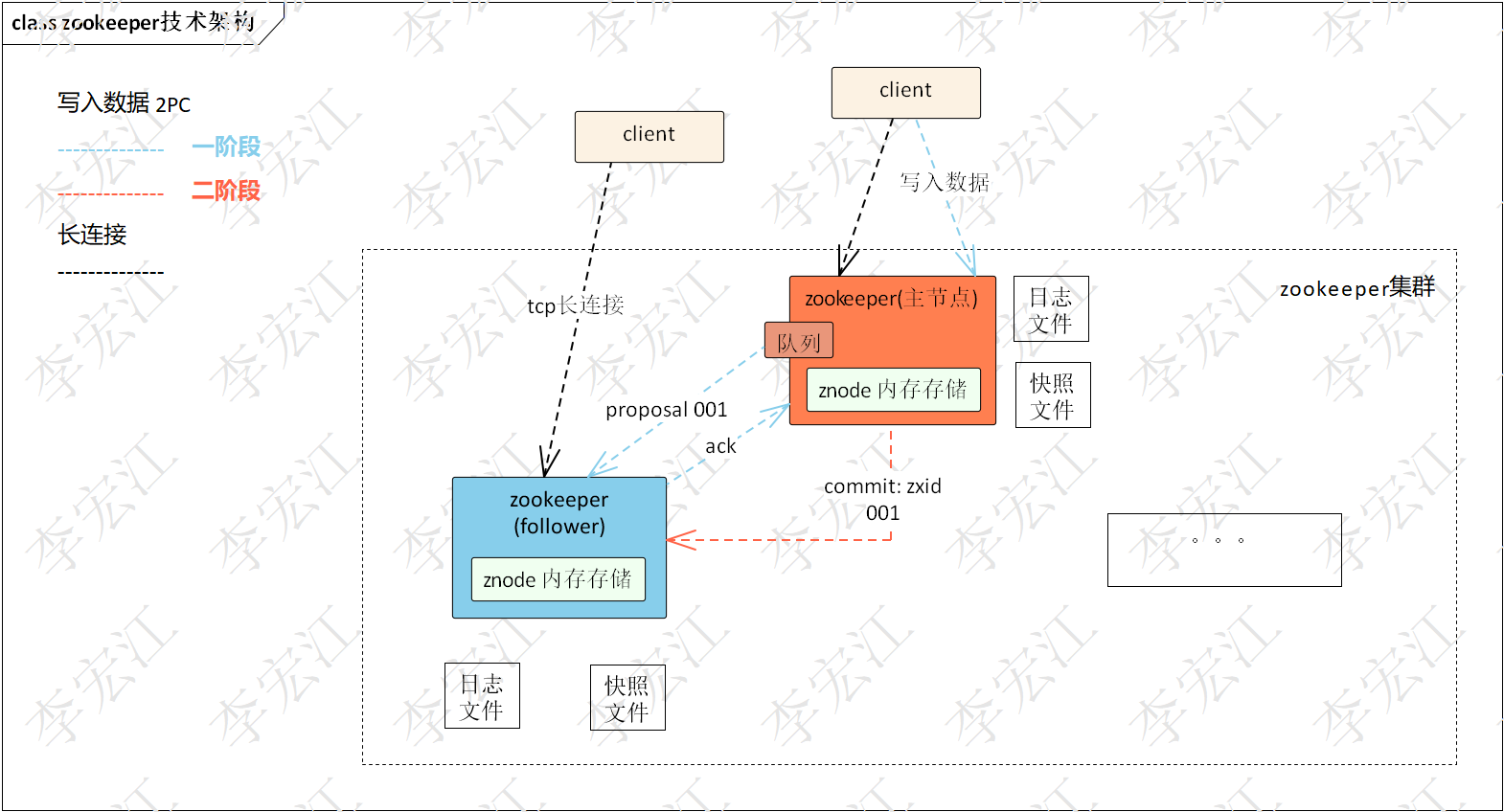
- zookeeper集群 由多个zookeeper 服务器节点组成,其中一个leader节点,若干follower节点,还有observer,只能读,而且observer不参与选举
- 客户端 (client) 外部的应用程序或服务,通过 TCP 长连接与 ZooKeeper 集群通信,数据读写和变更监听。
- Leader: 集群中的主节点,负责处理所有的写请求,并协调 Follower 节点的数据同步。
- Follower: 集群中的从节点,负责处理读请求,接收并应用 Leader 发送的更新提案,以保持数据一致性。
- znode: zooKeeper节点内存中维护的数据树结构,zooKeeper存储数据的基本单位。
- 日志文件: zooKeeper节点将数据变更操作持久化到本地磁盘的日志文件中,用于故障恢复。
- 快照文件: zooKeeper节点在日志文件达到500条日志(可配置),打包成快照文件,
- 两阶段提交: zab处理client的请求,先封装为Proposal,Leader广播Proposal,各个Follower返回ACK响应,Leader收到过半Follower的ACK响应后再广播Commit消息,Follower进行提交。与之前分析的dledger日志复制类似, 主节点复制到副节点过半,新日志提交点提交给状态机,应用写入。
逻辑架构
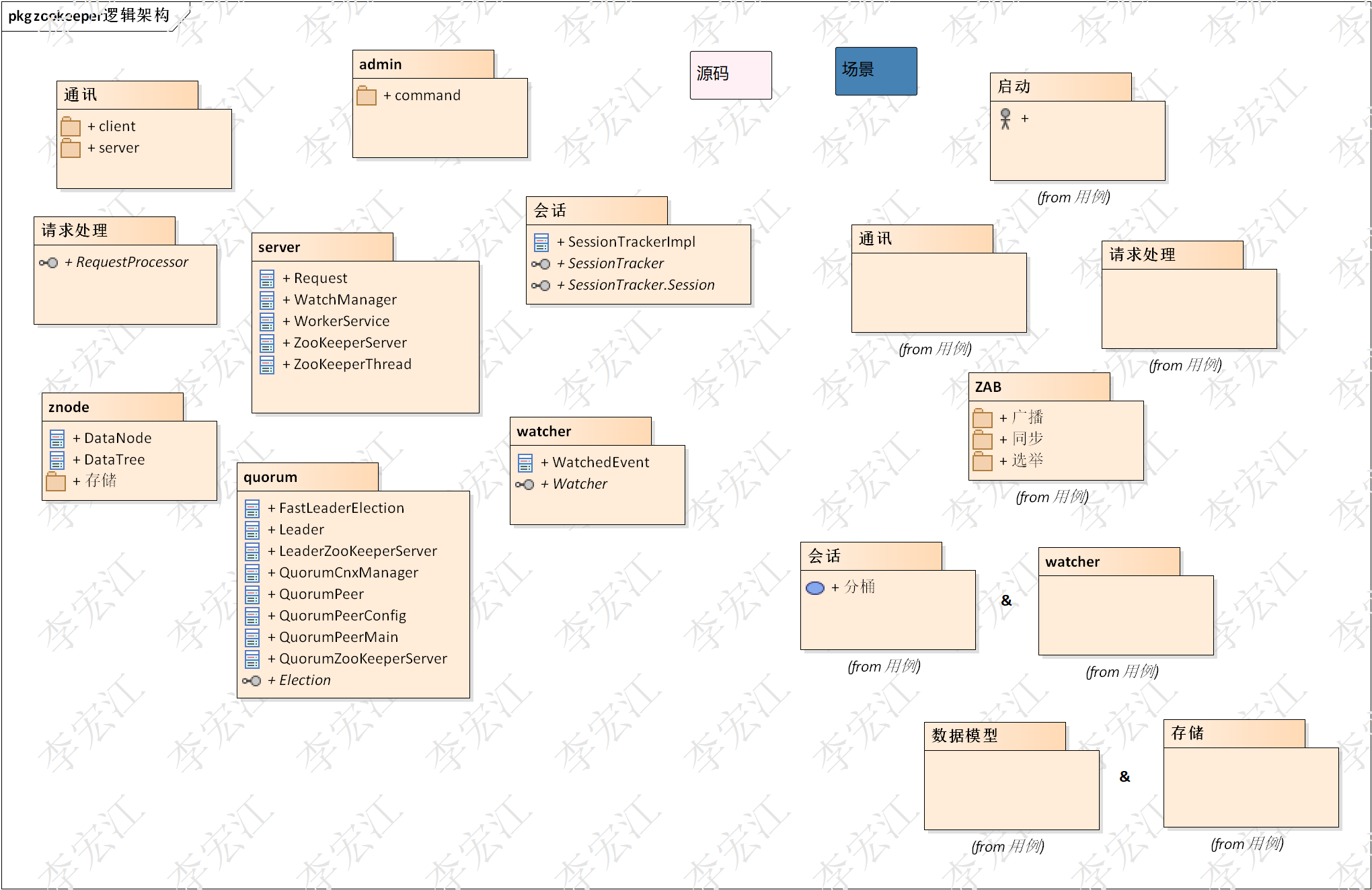
上图左边是zookeeper的源码包, 右边是场景
源码包
admin 嵌入的http服务,有JettyAdminServer实现,处理client的请求
通讯组件 rpc服务,处理rpc client的请求,服务端之间的网络通信
server/ 请求处理 负责请求处理
会话和watcher 会话,临时节点,watcher
quorum 分布式组件包
znode 和存储
场景
启动分析zookeeper启动,组件初始化
请求处理/Serverzookeeper通讯组件有nio,netty实现,系列不深入分析nio,netty,重点放在处理请求,延申到会话
ZAB 一致性的核心协议,包括选主,同步,广播,集群管理
会话/watcher
数据模型/存储
启动
本节分析zookeeper启动,zookeeper启动有两种模式,单机和集群,这里分析集群启动
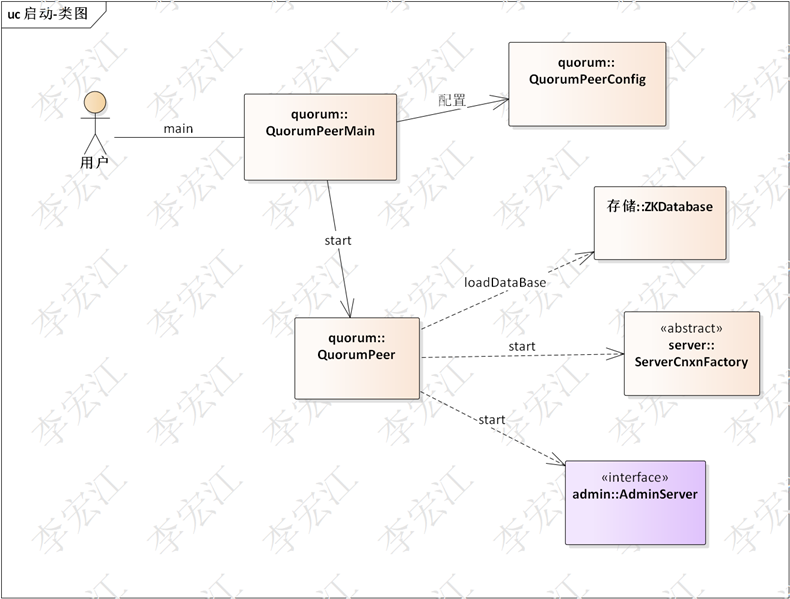
上图zookeeper启动参与的类图
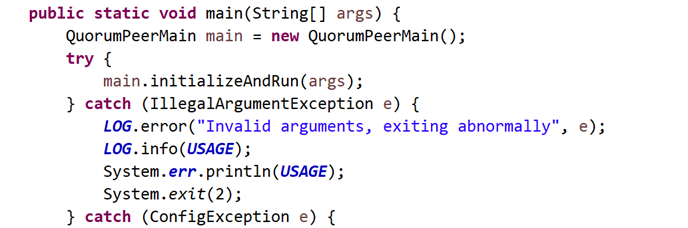
首先进入QuorumPeerMain的main方法
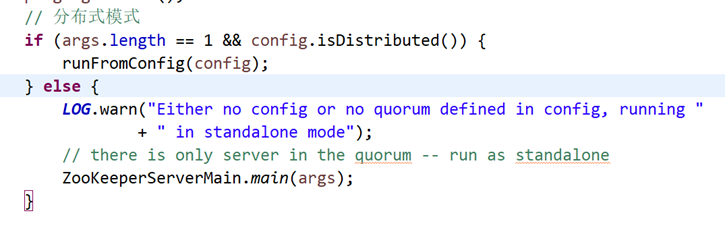
QuorumPeerMain的initializeAndRun,读入配置,其中config.isDistributed()是否分布式模式,就是说runFromConfig是分布式启动模式
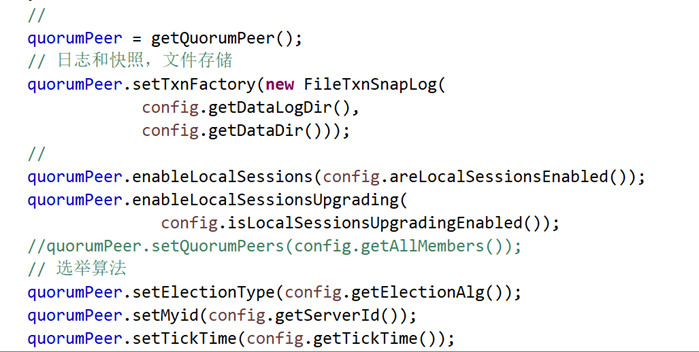
runFromConfig方法,主要是构建和初始QuorumPeer,该类实现ZAB协议的主体,个人觉得QuorumPeer的初始化就是从config读取配置,还不如config直接扔给QuorumPeer
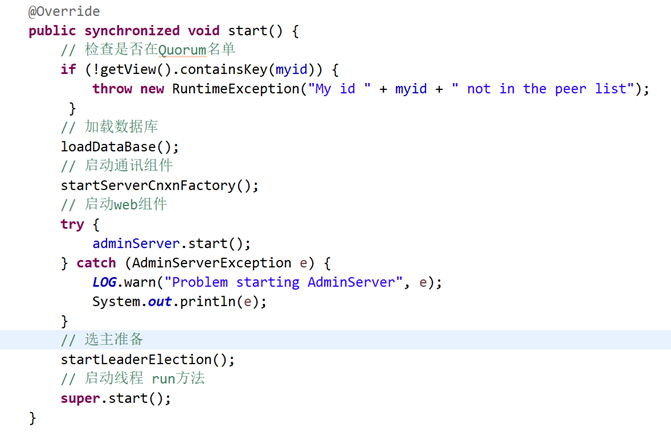
最后启动QuorumPeer,初始化组件
检查本节点是否在Quorum名单
获取QuorumVerifier,这个类关系到分布式的一个关键功能,集群节点管理,将在系列的ZAB中分析
加载数据库
做两个事情,
一,ZKDatabase载入本地的快照,重建内存znode,将在系列的znode模型,存储,日志和快照中分析
二,在本地文件读出currentEpoch和acceptedEpoch,将在系列的ZAB中分析
启动web服务和rpc服务
web服务和rpc服务可以理解为通讯适配,最终请求处理server完成
准备选主
方法名start,实际是从配置中获取选主算法,目前FastLeaderElection,其他注释为废弃
最后启动QuorumPeer,QuorumPeer是线程实现,其run方法正是ZAB的实现,将在系列的ZAB中分析
NEXT
系列(一)-架构,启动  本文
本文
系列(二)-ZAB 选主,发现和同步,广播(两阶段提交),集群管理
系列(三)-通讯组件和请求处理
系列(四)-会话,watcher
系列(五)-znode模型,存储和快照
> curator