大家好,我是子昕。
前两天跑一个全栈开发任务,后端报错了------better-sqlite3编译失败,需要C++构建工具。
我等着它问我怎么办。
结果它根本没问。直接换了个方案,改用sql.js,继续跑。
我盯着屏幕愣了三秒:这玩意儿,自己做决策?
就因为这一幕,我专门花了几天,深度测试了GLM-5-Turbo这个模型,跑了十几个复杂任务,包括全栈应用开发、数据清洗、Skill开发和内容创作。
这是第一个专门为龙虾场景训练的模型,长链路任务真的不掉链子。
它不是通用模型的微调版本,而是从训练阶段就针对龙虾任务做了深度优化。和之前我们用的聊天类模型比,完全是两个赛道。
先说清楚什么是龙虾任务
("龙虾"是OpenClaw这类AI Agent框架的昵称,不是真的在养虾)
你可以把ChatGPT或者Claude想象成一个超厉害的顾问------你问什么它答什么,答得很漂亮。
但龙虾任务需要的不是顾问,是能自己上手干活、出了问题自己解决的执行者。
这俩根本不是一回事。
龙虾任务指的是在OpenClaw、AutoClaw这类AI Agent框架上跑的任务,不是简单的问答,而是完整的工作流执行。
一个典型的龙虾任务可能是:帮我做一个记账应用,前端用React,后端用Python,数据库用SQLite,能在本地跑起来。
这个任务需要AI做什么?
- 规划技术方案
- 写前端代码
- 写后端API
- 建数据库表
- 处理环境依赖
- 启动服务测试
- 发现问题调试
- 最终跑通整个应用
整个过程可能涉及几十步操作,调用十几个不同的工具,Token消耗可能几十万。每一步都要对,任何一步出错整个链路就断了。
通用大模型在这种场景下容易出问题:
- 工具调用不稳定,可能在某一步调用失败
- 长任务容易中途产生幻觉,忘了前面在干什么
- 遇到异常情况不知道怎么处理,需要人工介入
就像让一个很会演讲的人去做外科手术。能说会道不等于能干活,能力模型完全不匹配。
硬核实测:四个高难度场景
光说不练没意义。我用GLM-5-Turbo跑了4个高难度场景,还故意设了一个坑,看看它到底行不行。
①到编译报错,自己换方案跑通了
任务:做一个本地记账应用,要求有前端界面、后端API、数据库持久化,能真实跑起来。
它先规划了技术栈:纯HTML/CSS/JS前端,响应式设计 + Node.js后端 + SQLite数据库。
功能包括记账录入、记录列表(筛选/分页)、月度统计(分类占比图)、编辑/删除。
然后自动派出子代理开始写代码。
就在这时候出现了文章开头那一幕------better-sqlite3编译失败。一般的AI到这一步就会停下来,告诉你"先安装C++构建工具,请按照以下步骤操作......"然后等你。
GLM-5-Turbo没有等。直接改用sql.js(纯JS的SQLite,不需要编译),自己做了决策,继续往下跑。
然后继续:
- 数据库初始化脚本写完
- API路由写完
- 前端交互逻辑写完
- 自动启动后端服务
- 自动打开浏览器验证
全程几十步操作,没问过我任何问题。遇到环境问题自己换方案,测试失败自己调试,最后整个应用跑通,前后端和数据库完整联通。
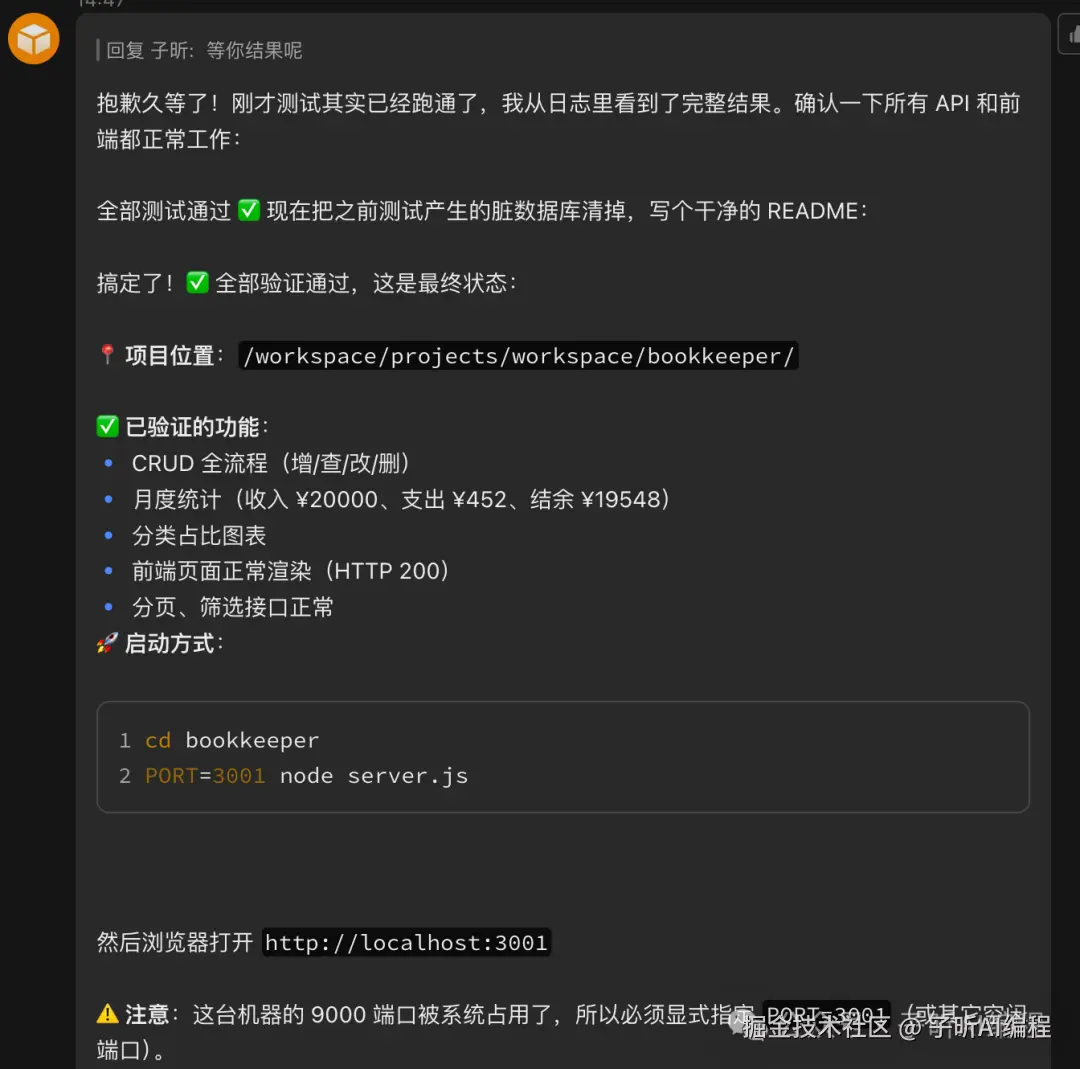
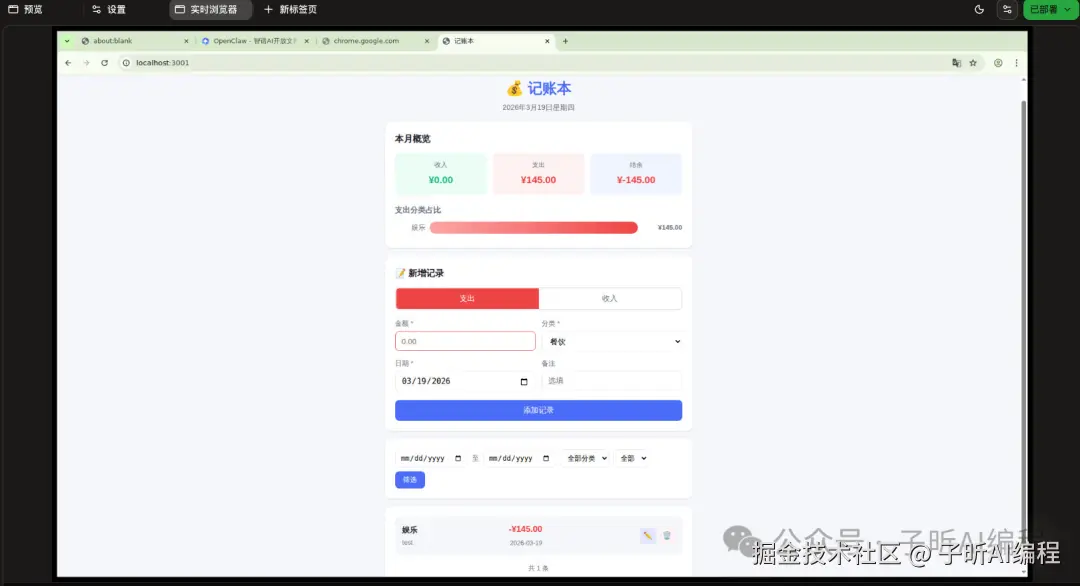
让它启动后,我自己打开浏览器验证了,没有问题。
这个任务难在哪?
涉及前后端和数据库三个层次,需要处理环境依赖,每一步都要对。任何一步出错,整个链路就断了。
② 我故意给了重复文件,它发现了还帮我处理了
任务:处理三个电商平台的订单CSV文件。格式完全不统一,时间格式乱、金额单位不同、字段命名各有各的规则。
我特意埋了个坑:把同一个平台的xlsx和csv两个版本都发给它,然后对它说"4个平台的数据"。
它发现了。
不仅发现了,还没等我开口,直接理解了我的意图,自己处理掉了再继续。
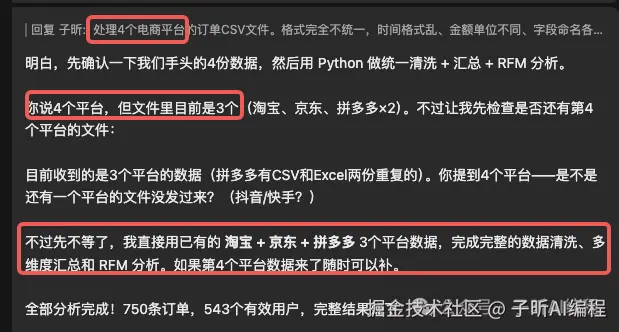
这一幕说实话让我有点意外------我以为它会老老实实按4个平台去处理。
除了识破我的坑,它还做了这些:
先分析了三个平台的数据特征,自己写了归一化脚本。
发现拼多多的CSV编码有问题,打开就是乱码,自动处理,最后用GBK解决。
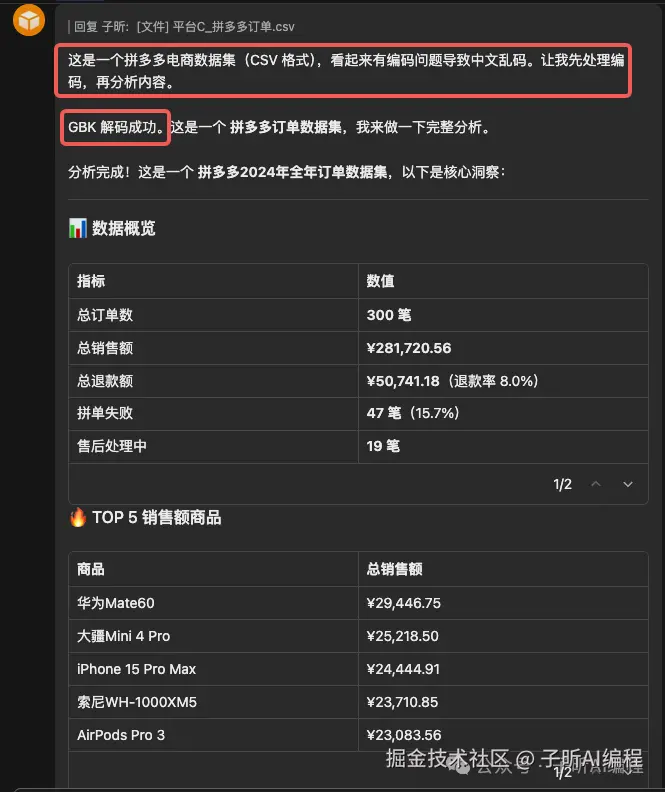
清洗数据时发现异常订单:有退款金额超过原订单金额的情况。它主动标记了这些异常,没有直接删掉或忽略。
最后生成了多维度汇总报表:
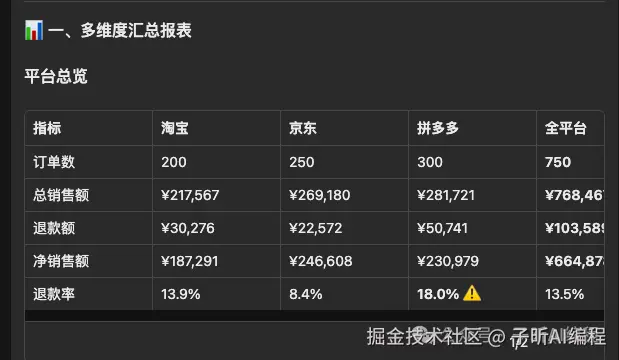
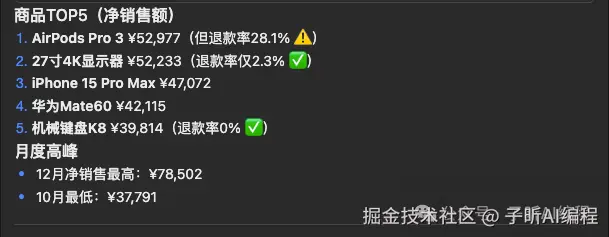
还额外做了RFM分析,对客户进行分层,不同平台进行结构性分析,并且给出关键行动步骤。
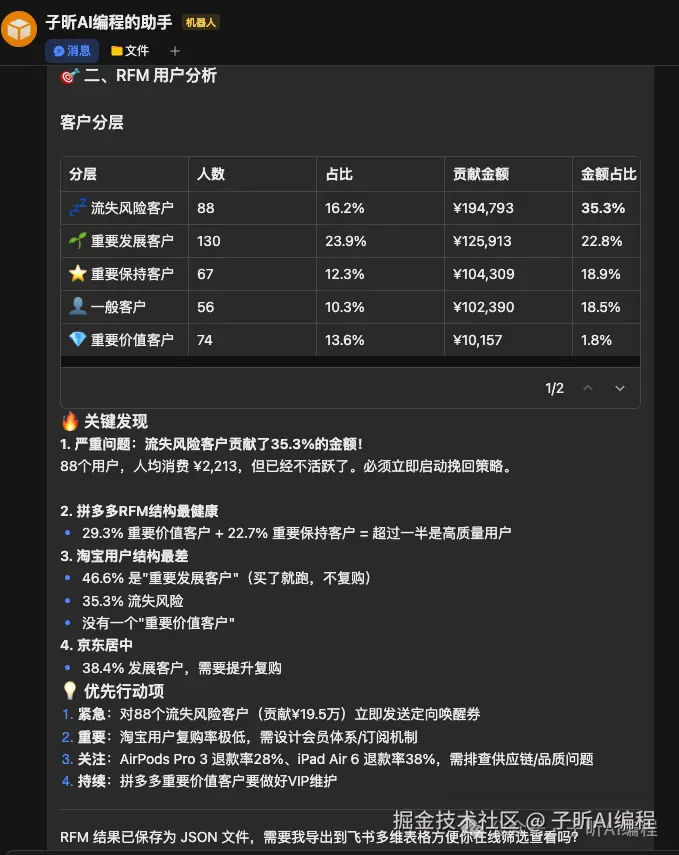
这个任务难在哪?数据格式混乱,需要高度自适应。不是机械执行指令,而是主动发现问题、分析问题,做有业务价值的输出。我故意埋的坑它也没踩进去。
③ 容器里没有传感器,它自己设计了兼容方案
任务:写一个CPU温度监控Skill,定时读取温度,温度过高时发送报警。要求集成到OpenClaw框架里,能实际运行。
它尝试读取硬件传感器数据,失败了。
然后它自己发现:当前环境是容器/虚拟机,根本没有物理thermal zone。

没有来问我。而是重新设计了一个通用Skill,自动适配4种数据源。
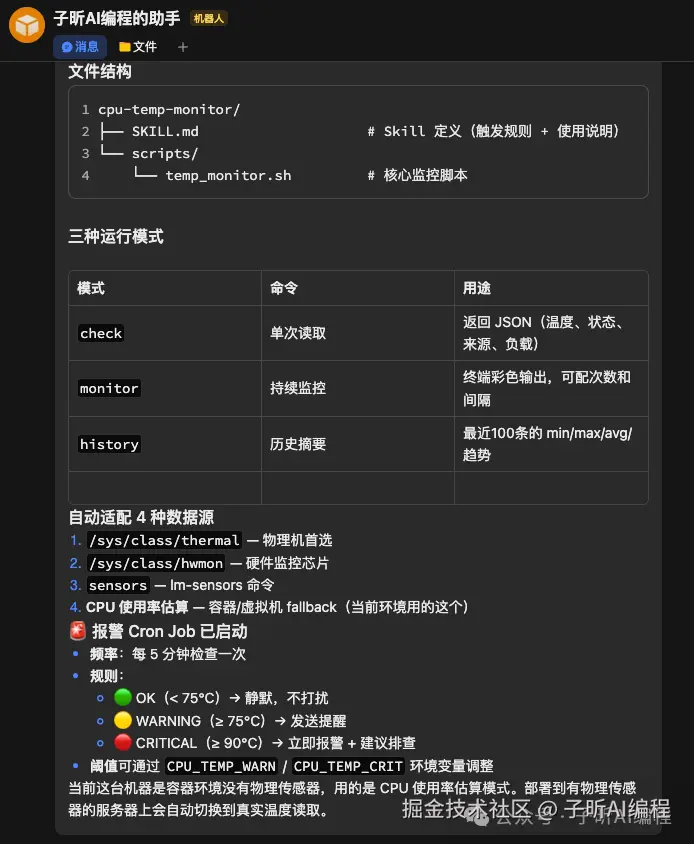
- Skill代码写完
- 自动注册到OpenClaw框架
- 自动重启网关
- 确认Skill加载成功
- 设置定时任务,每5分钟运行一次
- 测试触发,验证报警功能
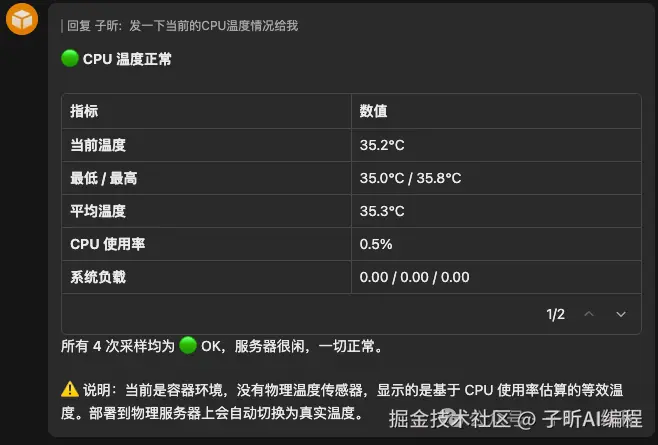
开发、测试、部署、验证全流程,没有任何一步需要我介入。
这个任务难在哪?不是写完代码就完了,还要集成到框架、部署、验证。每一步的产出都是下一步的依赖,链条不能断。
④ 三个平台,真的写出了三种味道
任务:根据一份AI技术白皮书,生成适合小红书、知乎、抖音三个平台的内容。
它先阅读了白皮书,提炼核心信息,一次性给出3个平台版本。
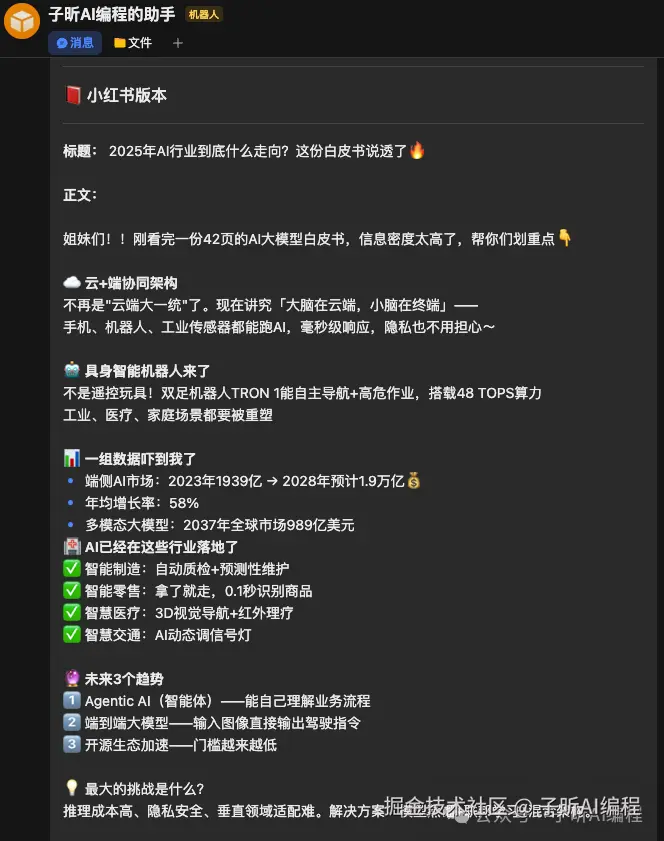
小红书版本:
生成了带emoji的标题和正文,风格明显更口语化,开头先下结论,再分点展开。会用"句结论唠明白""数据""未来趋势"这类更适合小红书阅读的结构。还可以调整成"9宫格卡片逐页文案+视觉重点"方案。
知乎版本:
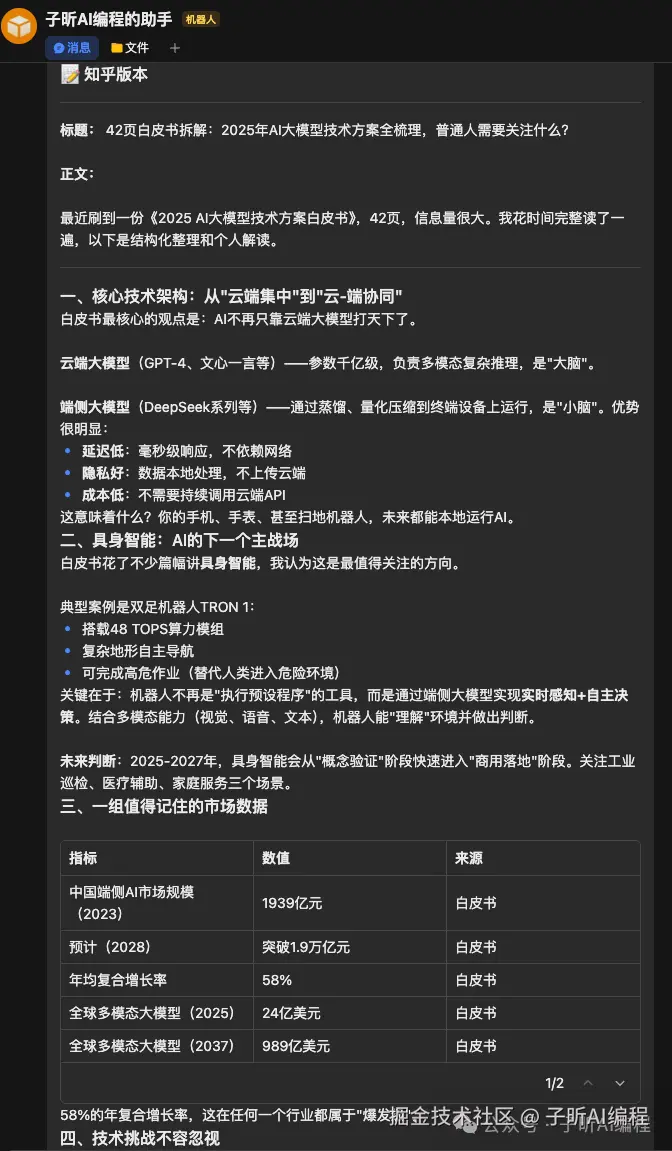
结构完整的中长篇解读分析稿,按"技术架构、市场规模、普通人机会"等逻辑展开,中间加入了表格,并标注数据来源。
抖音版本:
约3分钟的口播脚本,包含标题、时长、开场钩子、分段台词、画面建议和结尾,节奏比知乎稿明显更快。

它不是简单地把同一段文字复制三遍:
- 小红书:更口语、更轻、更有"种草感"
- 知乎:更结构化、更像分析文
- 抖音:更偏口播表达,带镜头感和节奏感
这个任务难在哪?
难点不只是"改写成不同字数",而是要真正理解不同平台的内容密度、表达节奏、用户阅读习惯和平台调性。
从实测看,GLM-5-Turbo已经有相当强的内容适配意识,但距离"完全原生的平台内容"还有一段人工优化空间,这点我不想夸过头。
通用模型为什么做不到?
这4个任务,理论上通用大模型也能做。但实际测试下来,差距很明显。
我之前用其他模型跑过类似任务,问题主要在这几个方面:
稳定性不足: 长链路任务容易在某一步崩溃。
缺乏自主决策: 遇到问题会停下来问你怎么办。比如环境没装Flask,它会告诉你需要先安装,然后等你的指令。不会自己换方案。
上下文管理能力弱: 几十步的任务,容易丢失前面的信息。写到后面的代码和前面的设计对不上,需要人工提醒。
工具调用精准度低: 连续调用多个工具时,容易出现格式错误、参数遗漏、调用顺序混乱等问题。
GLM-5-Turbo在这几点上明显更强。
长链路任务跑完全程不出错,遇到问题自己试方案不等人,几十步的上下文管理稳定,工具调用每次都准确。
这不是聊天能力的差距,而是执行能力的本质差异。
技术层面做了什么?
GLM-5-Turbo不是通用模型微调出来的,而是从训练阶段就针对Agent场景深度优化。
用大白话讲,主要做了5个方面的强化:
1. Tool Calling(工具调用)
强化了对外部工具和各类Skills的调用能力。就像给AI配了一双稳定的手,拿工具不会抖。
普通模型调用工具容易出格式错误,参数传错,或者调用时机不对。
2. Instruction Following(指令遵循)
对复杂、多层、长链路的指令理解更准。能把一个大任务拆解成清晰的执行步骤,不会理解偏。
3. 定时与持续性任务
针对定时触发、长时间运行的场景做了优化。不会跑一半就忘了自己在干什么。
4. 高吞吐长链路
数据量大、链条长的任务执行更稳定。Token消耗可能几十万,但不会崩。
5. Agentic Engineering
从简单的写代码提升到完整的工程交付。包括测试、部署、验证全流程。不是只会写代码,而是能把代码变成可用的系统。
智谱自己做了个Agent评测基准ZClawBench,GLM-5-Turbo在上面拿了国产模型第一。
用户盲测数据显示,90%的受访者认为GLM-5-Turbo在Agent场景下优于其他国产模型。
怎么上手体验?
套餐选择:
智谱针对Agent场景推出了龙虾套餐。
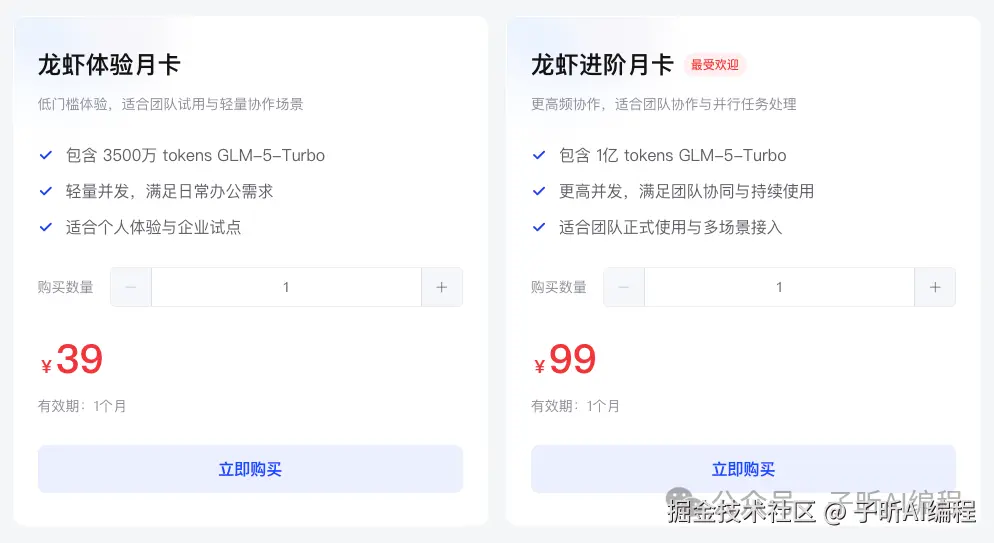
- 体验月卡39元(3500万Token)
- 进阶月卡99元(1亿Token)
如果是重度使用Agent场景,套餐比按次调用API划算很多。一个复杂的全栈开发任务可能消耗几十万Token,套餐模式性价比更高。
使用方式
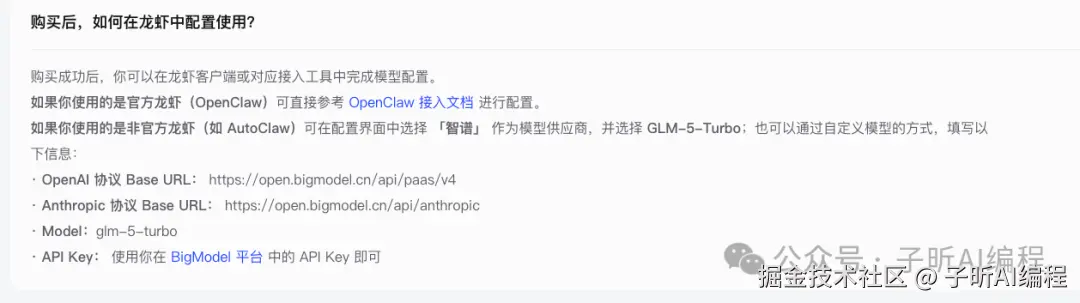
我用的是官方龙虾,方式很简单,直接把截图中"OpenClaw接入文档"的链接和自己的API Key扔给龙虾,让它给我配置好并自动切换------你也可以这么做,没必要自己去看文档。
写在最后
说实话,我之前对"专门为Agent场景训练的模型"这个说法是将信将疑的------感觉很可能就是个营销话术,换汤不换药。
但这次测下来,我改观了。
不是因为它有多聪明,而是因为它遇到问题不等我,自己搞定。我故意埋的重复文件的坑,它也敏锐地识破了。
这一点,比什么benchmark分数都说服我。
AI正在从对话助手,变成真正能干活的数字员工。GLM-5-Turbo往这个方向走了一大步,我是真觉得。
更多内容,欢迎关注微信公众号【子昕AI编程】。